풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
네트워크 정리-Chap 3-전달 계층
Chapter 3. 전달 계층(Transport Layer)
- 3.1 Introduction and Transport-Layer Services
- 3.2 Multiplexing and Demultiplexing
- 3.3 Connectionless Transport: UDP
- 3.4 Principles of Reliable Data Transfer
- 3.5 Connection-Oriented Transport :TCP
Computer Networking: A Top-Down Approach(Jim Kurose, Keith Ross)의 강의를 정리한 내용입니다.
( Jim Kurose Homepage )student resources : Companion Website, Computer Networking: a Top-Down Approach, 8/e
Transport layer는 application layer와 network layer 사이에 있는 계층으로, 각기 다른 host에 돌고 있는 application 간의 의사소통을 맡고 있다.
이번 챕터에서는 transport layer의 기본과 TCP, UDP 프로토콜들의 원리에 대해서 알아볼 것이다.
핵심적인 기능인 의사소통 뿐만 아니라 혼잡을 피하기 위한 transmission rate 조절방법도 알아볼 것이다.
3.1 Introduction and Transport-Layer Services
Transport layer는 다른 호스트 내부의 application 간의 논리적 연결을 담당하며, 이 뜻은, 호스트 사이의 여러 router, swtich 등 물리적 연결 요소를 배제하고 연결하게 해준다는 의미이다.
아래 fig 3.1과 같이 Transport layer는 end system에만 주로 구현되며, application단의 message를 segment라고 불리우는 packet으로 바꾸거나 segment에서 message를 추출해 의사소통하게 해준다.
이때, transport layer header를 추가하거나, 데이터 크기에 따라 여러 segment로 나누고, 추가로 network layer의 datagram으로 encapsulate 되서 전달된다.
보통 프로토콜로 UDP, TCP가 주로 쓰이며, 이 둘은 각각 다른 특성을 가진 서비스를 application에게 제공해준다.
3.1.1 Relationship Between Transport and Network Layers
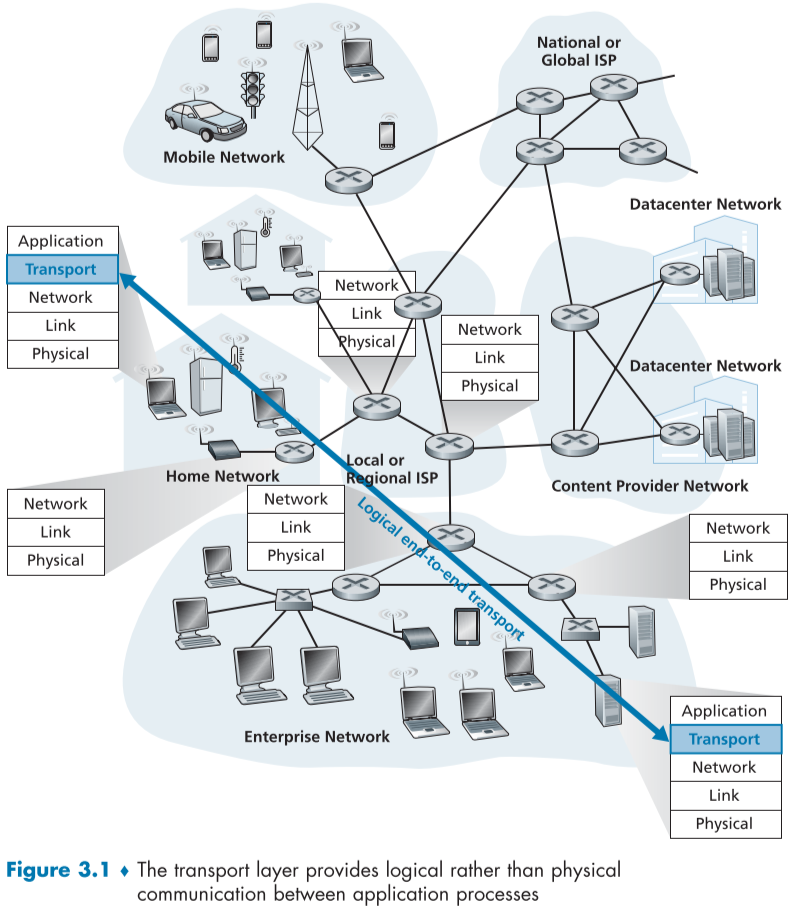
network layer와 transport layer의 일은 각각 현실로 비유하자면, 집(host) 간의 연결을 해주는 우체국(network layer protocol)과 받은 편지(application message)를 집안에 해당하는 사람(process)에게 나눠주는 형제(transport layer)로 비유한다.
이때, 편지 나눠주는 형제들은 우체국이 어떤 경로로, 어떤 절차를 걸쳐 해당 집으로 왔는지 관심없고, 실제로 해당 일을 하는데 필요하지 않다.
또한, 형제에 따라 시간과 정성을 들여 정확히 확인하여 편지가 잃어버리지 않게 하거나 잘못 전달되지 않게 하는 형제(TCP)도 있고, 그저 온 편지를 바로 전달만 해주는 형제(UDP)도 있을 것이다, 이는 흔히 프로토콜의 차이로 비교되곤 한다.
또한, transport layer가 제공할 수 있는 서비스는 network layer 측에서 제공해주지 않으면 대부분 제한된다.
예를 들어, transport 측에서 최대 대역폭을 정해주어도, network layer 측에서 넘겨버리면 의미가 없다.
대부분이라 한 이유는, packet 암호화나 전송 신뢰성 보장(reliable transfer) 같이 network 측에서 제공하지 않아도 제공되는 서비스도 있다.
3.1.2. Overview of the Transport Layer in the Internet
앞서 말했듯이 Transport layer protocol은 크게 TCP(Transmission Control Protocol)와 UDP(User Datagram Protocol)로 나뉘며 둘 중에 하나를 골라 application을 만들거나 socket을 생성한다.
참고로, RFC 등지에서는 TCP의 packet을 segment, UDP의 packet을 datagram이라고 표현하는 경우가 많으나, datagram은 network layer 층에서의 packet을 의미하기도 하므로, 우리는 Transport layer의 packet을 segment로 고정해 부르기로 한다.
나중에 배울 Network layer의 IP는 unreliable, best-effort deliver service이는 전송 결과와 데이터 정합성을 보장하지 않음을 의미한다.
이때 UDP 또한, IP 처럼 unreliable service이므로, UDP와 IP가 결합된 서비스는 데이터의 전송이 보장되지 못하지만, TCP는 보장이 된다.
UDP는 multiplexing, demultiplexing 그리고, error checking 서비스 만을 제공하며, TCP는 거기에 추가로 reliable data transfer와 congestion control(혼잡 제어) 서비스를 추가로 제공한다.
congestion control(혼잡 제어)는 개개인 process나 host의 이득이 아닌, 전체 network의 공평하고 효율적인 네트워크 자원 공유를 위한 것이며, 이를 위해 TCP의 경우 전송이 제한되곤 하지만, UDP는 이러한 제한으로 부터 자유롭다.
우리는 제공하는 서비스들의 일반적인 버전과 TCP가 제공하는 버전을 차례대로 설명하여 비교할 것이다.
예를 들어, 우리는 먼저 일반적인 reliable data transfer를 설명하고, TCP가 적용한 reliable data tranfer를 비교할 것이다.
3.2 Multiplexing and Demultiplexing
transport layer multiplexing, demultiplexing은 Network layer의 host-to-host 통신을 연장하여 process-to-process 통신으로 확장해준다.
이는 마치 집에 도착한 뭉탱이의 편지를 각자 적절한 사람에게 나눠주는 것과 같다.
이때, transport layer가 직접 Application에게 주는 것이 아니라, socket(위의 방문)이라는 application 계층과 transport layer 계층 사이에 있는 인터페이스를 통해서 준다.
각 socket은 한 host에 여러개가 존재할 수 있으므로, socket마다 고유한 식별자(Port)를 가지며, socket 또한 UDP, TCP 등의 사용하는 프로토콜이 존재한다.
이때 뭉탱이(datagrams)의 편지(segment)를 나누어(segment로 변환) 편지 받는이(segment의 source port number field)를 확인한 뒤 적절한 사람(application)의 방문(socket) 앞에 놔주는 것이 demultiplexing이며, 반대로 여러 사람들이 방문(socket) 앞에 놓아둔 편지를 수거하여 받는 사람(segment의 desination port number field)을 확인한 뒤 우체통(network layer)로 보내는 것을 multiplexing이라고 한다.
이때 사람의 종류(application의 protocol, FTP, TELNET, HTTP etc…)는 신경쓰지 않는다.
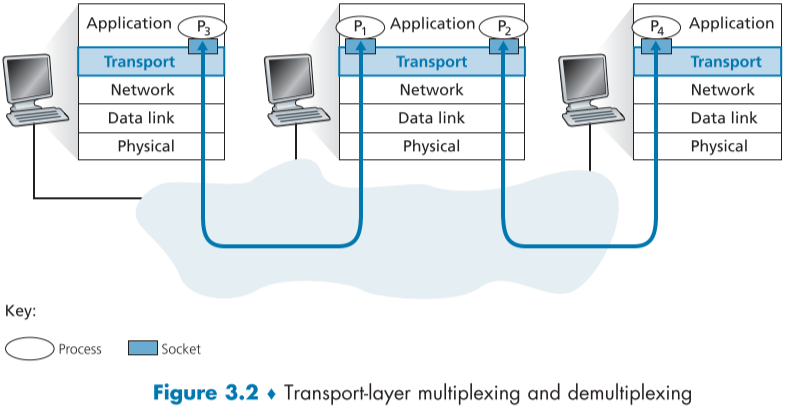
위에서 설명한 socket의 고유한 식별자를 port라고 하며, segment에 적혀있는 송신자와 수신자의 port 번호를 각각 source port number field, destination port number field라고 한다.
각 port는 16 bit, 0~65535까지의 범위를 가지며, 0~1023까지의 1024개를 well-known port numbers라고 해서, 필수적인 application들이 미리 점유하고 있으므로 사용하면 안된다.(예를 들어 HTTP : 80, FTP :21, SMTP :25) 최신 버전은 RFC 3232에서 확인.
이외의 port 번호는 application 개발시 자유롭게 활용 가능하다.
위에서 설명한 내용과 그림은 UDP를 기준으로 한 multiplexing/demultiplexing이며, TCP의 경우 조금 다르다.
Connectionless Multiplexing and Demultiplexing
clientSocket = socket(AF_INET, SOCK_DGRAM)
위는 UDP socket을 생성하는 python 코드이며, 이때 socket의 port 번호는 1024~65535 중 알아서 생성된다.
clientSocket.bind((' ', 19157))
만약 특정 주소로, 특정 port 번호로 바꾸고 싶다면 위와 같은 bind 함수를 사용하면 된다.
보통 개발시에, applicatino이 server side인 경우 특정 port를 지정하고, client side의 경우 자동으로 할당되도록 만든다.
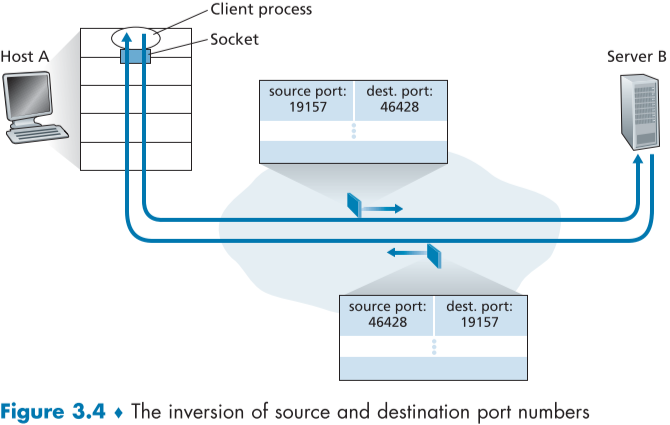
UDP socket은 desination IP address와 destination port number의 값에 따라 구별되며, 이에 따라, UDP segment가 source IP address와 source port number가 달라도 앞의 두 값이 같으면 같은 socket으로 들어가게 된다.
source IP address와 source port number의 경우, 데이터를 수신받은 socket이 segement를 돌려주는 용도로 사용한다.
python 코드의 경우 recvfrom() 코드를 이용해 source address를 받은 뒤, 응답을 돌려줄 수 있다, (
Chap 2.7.UDPServer.py
참조)
Connection-Oriented Multiplexing and Demultiplexing
TCP Socket과 UDP Socket의 차이점 중 하나는 , TCP socket은 desination IP address와 destination port number, source IP address와 source port number, 총 4개의 값에 따라 구별된다는 점이다.
TCP segment가 도착한다면 위의 4개 필드에 따라 적절한 TCP socket으로 보내지게 된다.(단, 처음으로 도착한 handshaking segment의 경우, source IP address와 source port number가 달라도 TCP connection을 수립하기 위해 어플리케이션 마다 할당된 동일한 TCP Welcome Socket에 들어가게 된다.)
즉, TCP의 경우 desination IP address와 destination port number가 같은 TCP socket이 여러개 있을 수 있다.
자세한 내용은 2.7 절의 TCPServer.py 부분을 참고하자.
clientSocket = socket(AF_INET, SOCK_STREAM) # client측 TCP 소켓 생성
clientSocket.connect((serverName,12000)) # 서버측과 TCP 연결
connectionSocket, addr = serverSocket.accept() # 서버측에서 TCP 연결이 생성될때 까지 기다리는 함수
TCP 서버는 이러한 TCP 소켓에 의한 연결을 address에 따라 구분하여 아래 그림처럼, 여러개 동시에 생성하고 유지할 수 있다.
이러한 port 번호는 system 관리자가 켜져있는 application의 종류를 확인하는데도, 공격자가 보안 취약점이 있는 application을 공격하는데도 유용하다.
nmap이나 port sanner같은 program으로 이러한 port들의 상태를 알 수 있고 이는
3.5.6장
에 더 자세히 다룰 것이다.
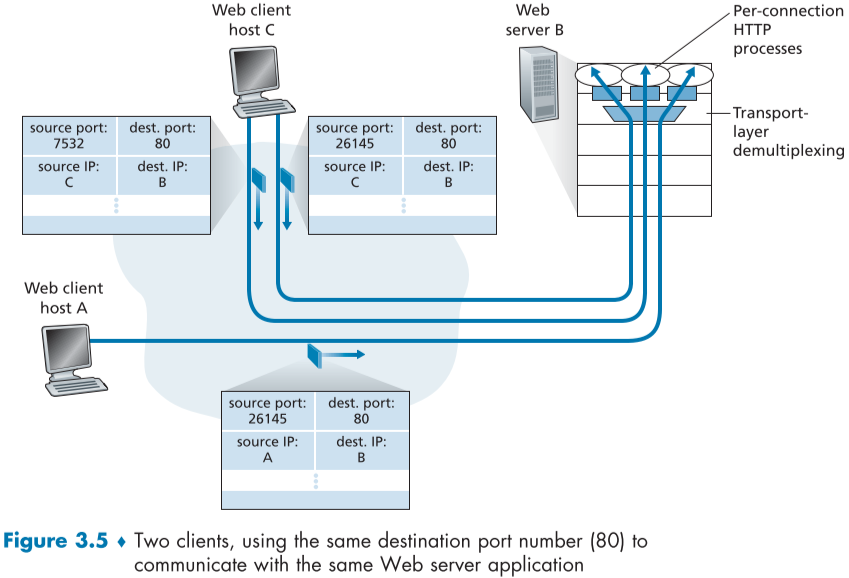
Web Servers and TCP
실제로는, 위 그림과 달리 최신 고성능 web server들은 하나의 프로세스에 여러 thread를 생성하여 각각 연결마다 socket을 형성하므로 실제 process 마다 socket이 할당되지는 않는다.
만약 HTTP 연결이 non-persistent HTTP 라면, 매 request-response 마다 새로 connection이 생성되므로 socket이 형성되고 사라질 것이다. 이는 OS의 기술 덕분에 악영향이 반감되긴 하지만, web Server에 성능상 안좋은 영향을 끼친다.
3.3 Connectionless Transport: UDP
만약 TCP의 여러 기능을 사용하지 않는 새로운 프로토콜을 사용하고 싶거나, 새로 프로토콜을 만들어보고 싶다면 UDP를 사용하면 된다.
UDP는 앞서 설명했듯이 reliable transfer와 congestion control 기능 등이 존재하지 않고, multiplexing\demultiplexing, 오류 검사 기능 정도만 있는 대신, 다음과 같은 장점을 가지고 있다.
- 혼잡 제어 무시, 절차, 비연결성 통신으로 인한 비교적 가벼운 오버헤드와 빠른 전송 속도, 정보손실이 일어나도 괜찮되, 빠른 반응이 필요한 서비스에 UDP가 많이 이용된다.
- 연결 설립 과정 없음(no connection estalishment) TCP의 3 handshaking 같은 과정이 없어 DNS나 QUIC 같은 속도를 중요시 여기는 프로토콜을 만드는 데 UDP가 기반이 되곤 한다.
- 연결 상태 없음(No connection state), TCP는 해당 연결 상태인 buffer, congestion control parameters, sequence, ack number 등을 저장해둬야한다. UDP는 해당 하지 않으므로 저장할 정보가 적어 비교적 더욱 많은 연결을 세울 수 있다.
- packet header 크기가 작음. TCP 는 20 byte의 header를 가지고 UDP는 8 byte의 header를 가진다.
많은 중요한 정보가 TCP로 만들어지지만, SNMP(network management 정보) 같이 네트워크가 혼잡한 상황에서도 보낼 수 있게끔 필요한 경우에도 UDP가 사용된다.
많은 multimedia application들이 특유의 손실 가능한 특성과, real time성 때문에, UDP로 만들어지지만, UDP를 보안상 문제삼아 block 시켜놓은 방화벽 대비나 네트워크 성능의 증가로 TCP 또한 충분하게 사용되고 있다.
또한, UDP는 네트워크 혼잡 제어를 하지 않으므로, 과용되면, 커다란 UDP 패킷 손실과 다른 TCP 연결의 제한을 가져올 수 있으며, 이를 막기 위해 UDP 뿐만 아니라 여러 Protocol들을 공통적으로 congestion control을 강제할 수 있는 방법이 연구되고 있다.
물론 UDP 또한, reliable transfer 등의 서비스를 넣을 수 있는 방법이 있는데, 먼저 첫번째는 QUIC 처럼, UDP 기반의 새로운 프로토콜을 만드는 것이고, 두번째는 application layer 단에서 그러한 서비스 기능을 넣는 것이다.
이러한 개발 과정은 아주 복잡하고 힘든 과정이겠지만, 데이터의 신뢰성을 보장하면서 congestion control을 피해 이기적으로 이득을 볼 수 있다.
3.3.1 UDP Segment Structure
RFC 768에 정해져 있는 UDP segement 구조는 아래와 같다.
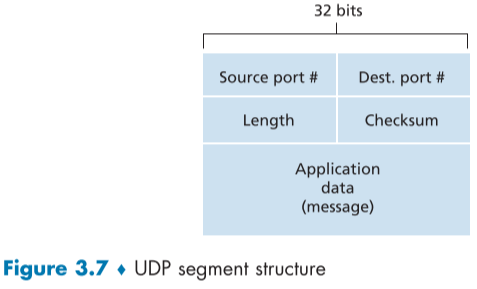
Application message를 payload로 가지고 있는데, 예를 들어 DNS는 query message나 response message가 될 것이며, streaming audio application에서는 audio smaple이 될 것이다.
헤더는 오직 4개의 field로 이루어져 있으며, 하나에 2 byte, 총 헤더 크기 8byte(32bit)를 차지한다.
- source port, dest port field는 host에서 segment가 알맞은 socket으로 들어가게 해준다.
- Length field는 헤더와 데이터를 포함한 전체 UDP segement의 크기를 적어주어, 다음 메시지와의 경계를 알려준다.
- Checksum field는 segment가 전송 도중에 오류가 생겨 변했는지 검사해준다. IP header에도 비슷한 역할을 하는 필드가 있다.
3.3.2 UDP Checksum
checksum은 UDP segment의 어느 부분이 noise나 router의 오류 등으로 변했는지 검사할 수 있다.
송신측 UDP에서 모든 16bit 단어들의 합에 자릿수를 넘어가는 값은 첫째 자리에 다시 더해주고,(wrap around) 나온 결과값의 1의 보수 값을 구한다.
이렇게 구한 값을 segment header 필드에 저장하여 checksum으로 이용한다.
\((1)\left\{\begin{matrix}
0110011001100000\\
0101010101010101\\
1000111100001100\\
\end{matrix}\right.\ \ \ \ \ \
(2)\left\{\begin{matrix}
0110011001100000\\
0101010101010101\\
\overline{1011101110110101}\\
\end{matrix}\right.\ \ \ \ \ \
(3)\left\{\begin{matrix}
1011101110110101\\
1000111100001100\\
\overline{0100101011000010}\\
\end{matrix}\right.\)
(1) 이렇게 3 단어가 포함됬다고 가정하고
(2) 1번째와 2번째 단어 합산
(3) 2번째와 3번째 단어 합산한 결과값이 checksum이다. (이때, 자릿수가 넘어가는 값이 첫째 자리에 더해졌다.)
1의 보수는 모든 자리의 0은 1로, 1은 0으로 바꾼 것으로, 최종 결과로 1011010100111101이 checksum이 된다.
receiver 측에서는 이러한 checksum과 나머지 16bit word를 더하면 자연스럽게 1111111111111111이 되며, 이는 오류가 없다는 의미이다.
만약 다른 값이 나온다면 segment 어딘가에 오류가 있었다는 뜻이다.
Ethernet protocol 같은 다른 layer protocol들 또한 오류 검사를 제공함에도 불구하고, 중복하여 해당 서비스를 제공하는 이유는,
-
모든 장비가 모든 layer를 구현하는 것도 아니며, 또 구현된 layer의 protocol이 오류 검사를 제공하지 않을 수도 있으며,
- 예를 들어, IP 프로토콜 또한 체크섬을 가지고 있지만, TCP는 ATM 같은 IP 이외의 네트워크 계층 위에 구현될 수 도 있다.
- 애시당초 IP 데이터그램 헤더의 인터넷 체크섬 필드는 IP 헤더값들의 오류만 해결해주고 데이터부분은 포함하지 않는다.
-
link layer 측에서 오류 검사(link-by-link error)를 완료해도 router에 저장되어 있는 중(in-memory error)에 오류가 생겨날 수 도 있다.
이러한 중복 서비스 제공은 system 설계시의 end-end principle 또한 지킨다.
end-end principle은 저레벨에서 기능을 제공하는 것이 좀 더 고레벨에서 제공할 때보다 더욱 비용이 적게 들거나 안들 수도 있다는 것이다.
다만, UDP는 에러를 체크한 뒤, 잘못될 경우 수정이나 재전송 요청 없이 버려버리거나, 주의를 표하고 그대로 넘긴다.
3.4 Principles of Reliable Data Transfer
Reliable data transfer은 transport layer 뿐만 아니라 link layer와 application layer에도 구현되곤 하므로, TCP 만의 방법 뿐만 아니라 일반적인 방법을 배워보자.
신뢰할 수 있는 channel이 존재한다면, 전송되는 데이터는 bit가 바뀌거나 잃어버리거나, 순서가 바뀌는 경우가 없으며, 이는 신뢰적 데이터 전송 프로토콜(reliable data transfer protocol)인 TCP가 application에 지원하는 기능이다.
문제는 RDT(Reliable Data Transfer)를 구현해야하는 layer보다 저레벨의 layer가 비신뢰적 데이터 전송 기반이면 힘들어지며, 심지어 그러한 layer들이 구현된 router와 link-layer 장비를 네트워크 상 여러번 거쳐야 한다면 더욱 힘들다. (ex) TCP layer 밑의 IP layer는 데이터 전송을 신뢰할 수 없다.)
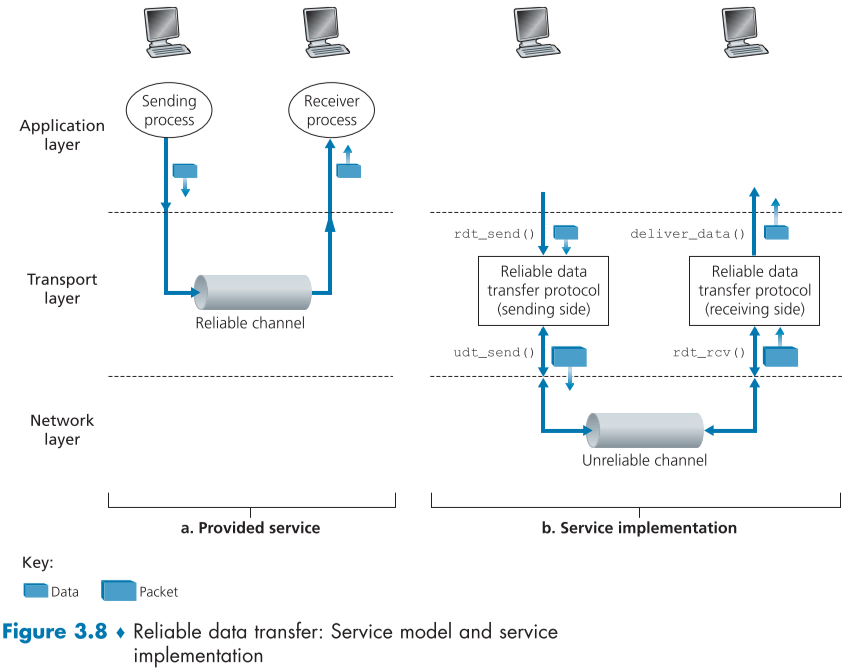
그러한 신뢰할 수 없는 channel 들을 상단의 그림처럼 하나의 Unreliable channel로 놓고 우리는 그 양끝단 송신측과 수신측에 적용될 신뢰 데이터 전송 프로토콜을 생각해봐야 한다.
이때 그림처럼 통신은 일방향 통신(unidirectional data transfer)라고 가정하고,
송신 Application측이 데이터를 reliable data transfer protocol(RDT)로 보낼 때의 기능을 rdt_send(),
수신측 RDT가 Unreliable data transfer(UDT)로 부터 데이터를 주고 받을 때의 기능을 rdt_rcv(),
송신측 RDT측이 UDT측과 데이터를 주고 받는 부분을 udt_send(),
마지막으로 수신측 RDT가 Application에게 데이터를 주는 부분을 deliver_data()
라고 가정하겠다.
3.4.1. Building a Reliable Data Transfer Protocol
Reliable Data Transfer over a Perfectly Reliable Channel: rdt1.0
먼저 UDT측의 데이터 전송이 완전히 신뢰할 수 있는 경우를 FSM(finite-state machine)을 통해서 살펴보고, 이를 rdt 1.0 이라고 하겠다.
파란 화살표는 transition 화살표로, 한 상태에서 다른 상태로 이동함을 의미한다. (현재는 상태가 하나밖에 없으므로 자기자신으로만 이동한다.)
파란화살표 옆의 수평선의 윗 부분은 해당 transition을 일으키는 이벤트를 의미한다.
수평선 아랫부분은 이벤트가 일어났을 때 생기는 행동들을 의미한다.
$\Lambda$(람다)가 있는 경우에는 아무런 활동이나 이벤트가 일어나지 않았음을 의미한다.
점선 화살표는 FSM의 초기 상태를 의미한다.
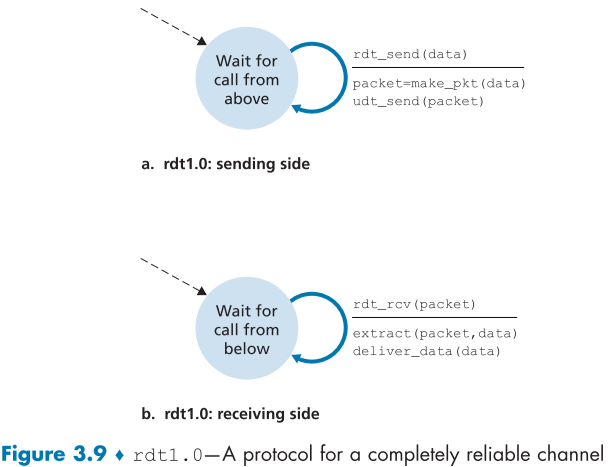
먼저 송신측 상위 layer에서 데이터를 받아 데이터가 들어있는 패킷을 만들고(packet=make_pkt(data)), 해당 패킷을 UDT 채널로 보내(udt_send(packet))는 rdt_send(data)가 실행된다.
- 이는 실제로는 상위 layer에서 실행하는 함수 일 것이다.
그 다음 수신측 RDT가 UDT로부터 해당 packet을 받고 data를 추출해내서(extract(packet, data)) 상위 layer로 보내(deliver_data(data))는 rdt_rcv(packet)이 실행된다.
간단한 예제이며, data나 packet의 단위가 변하거나, packet이 흐름이 수신측에서 송신측으로 역전되는 경우가 없다.
또한, 통신간에 문제가 없으므로, 수신측의 특별한 재요청이 없고, 송신과 수신의 처리속도가 같다고 가정하여, 어느 한쪽이 기다릴 필요도 없다.
Reliable Data Transfer over a Channel with Bit Errors: rdt2.0
이번에는 전송, 전파, buffer 간에 bit error가 생길 수 있다고 가정하되, packet의 순서는 바뀌지 않는다고 가정해보자.
사람들은 대화할 때, 잘듣지못한 부분은 다시 말해달라고 요청하고, 잘들었을 경우 맞장구 쳐준다.
이러한 부분을 통신에 활용하면, 통신 시, positive acknowledgment(OK), negative acknowledgment(다시 말해 줘)가 필요하다는 것을 알 수 있다.
이러한 재전송 기반 프로토콜을 ARQ(Automatic Repeat reQuest) protocol 이라고 한다.
이러한 ARQ의 필수적인 3가지 기능은 다음과 같다.
- 에러 탐지 : UDP의 checksum과 같이, 에러를 탐지 및 수정 하기 위해 사용된다. 보통 추가적인 bit를 할당해 에러를 체크한다.
- 수신자 피드백 : 1 bit(ack or nak)짜리 packet을 송신자 측으로 보내 받은 message의 상태를 보고, 이를 통해 수신자측이 메시지를 잘 받았나 확인 가능
- 재전송 : 위의 피드백을 받은 송신자가 packet을 재전송 여부를 파악함.
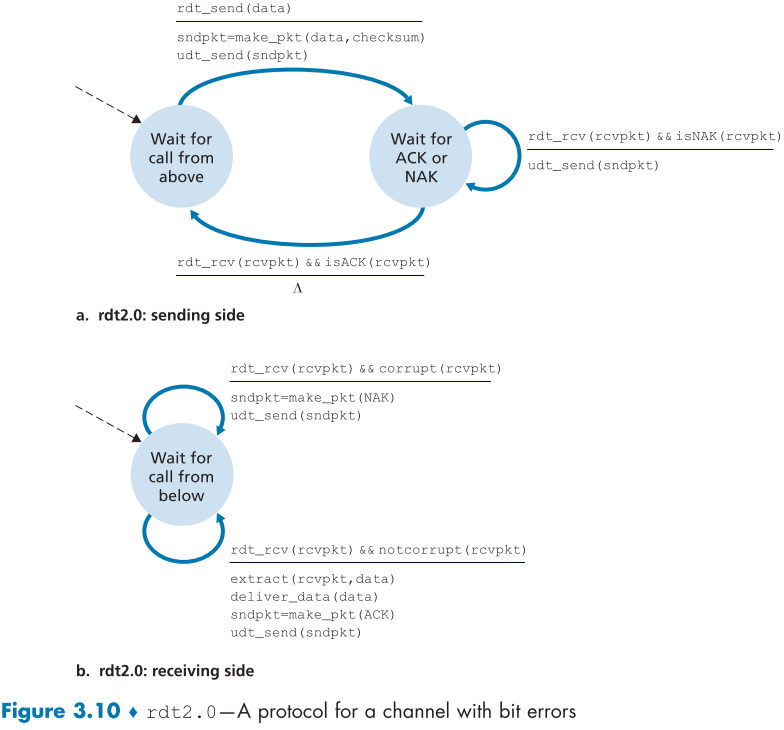
위의 fig 3.10은 rdt2.0 재전송을 보여주고 있다.
송신 측에 상태가 하나늘어 2개가 되었는데,
-
상위 layer로 부터 데이터를 기다리는 상태와
-
packet을 보낸 뒤 수신 측으로부터 피드백을 기다리는 상태
이며, rdt_send(data) 이벤트가 생기면 1에서 2로 transition되며, 이때, 데이터와 checksum이 존재하는 패킷을 형성하고 udt_send(sndpkt)로 UDT로 packet을 보낸다.
이후 b로 전환 된 뒤, 송신자는 ACK나 NAK packet을 기다리게 되고,
- ACK가 오게되면, sender는 packet을 제대로 보낸 것으로 확인하고 1 상태로 다시 전환된다.
- NAK가 오게되면, udt_send(sndpkt)가 다시 실행되고 2 상태로 다시 전환된다.
- 주의할 점이, 2로 전환되면 1로 전활될 때까지(ack를 받을때까지) 상위 layer에서 데이터를 줘도 받지 못한다. 이러한 protocol을 stop-and-wait protocol이라 한다.
수신측은 rdt2.0에도 여전히 상태가 1개이며, 수신자는 packet을 받고, 상태를 확인하고(rdt_rcv(rcvpkt) && corrupt(rcvpkt)) ACK나 NAK를 돌려준다.
rdt2.0의 단점은 ACK, NACK packet 또한 손실이나 변질될 수 있다는 점이며, 이를 막기위해
- 다시 ACK, NACK를 보내라고 요청 : 하지만 이 방법은 그렇게 다시 보내라는 요청 또한 망가질 수 도 있으며, 그런 요청 또한 다시 보내다 보면, 어떤 요청을 다시 보내야 될지 모른다.
- ACK, NACK에 checksum을 아주 많이 넣어주어 오류 검사 뿐만 아니라 오류 수정도 가능하게 한다 : 하지만 packet이 아예 손실되는 경우는 방지할 수 없다.
- 망가진 ACK, NACK가 오거나 아예 안오기 시작할 때 무조건 다시 data packet 보내기 : 그렇게 다시 온 data packet이 이전 packet의 중복인지, 아니면 새로운 packet인지 수신자 측에서 알 수 없다.
위와 같은 단점들이 있고, 이러한 단점을 해결하기 위한 방법으로 패킷에 sequence number를 추가해줄 수 있다.
만약, sender가 이전에 보냈던 packet을 다시 보냈다면, sequence number가 이전에 받았던 packet과 같거나 작을 것이고,
sender가 새로운 packet을 보냈다면, sequence number가 새로운 진행된 sequence number를 가지고 있을 것이다.
stop-and-wait 방식인 현재는 아직 ACK와 NACK에 sequence number가 필요없다(마지막에 보낸 packet의 ACK일테니까!)
다음은 sequence number 기능을 첨가한 rdt2.1 버전의 figure다.
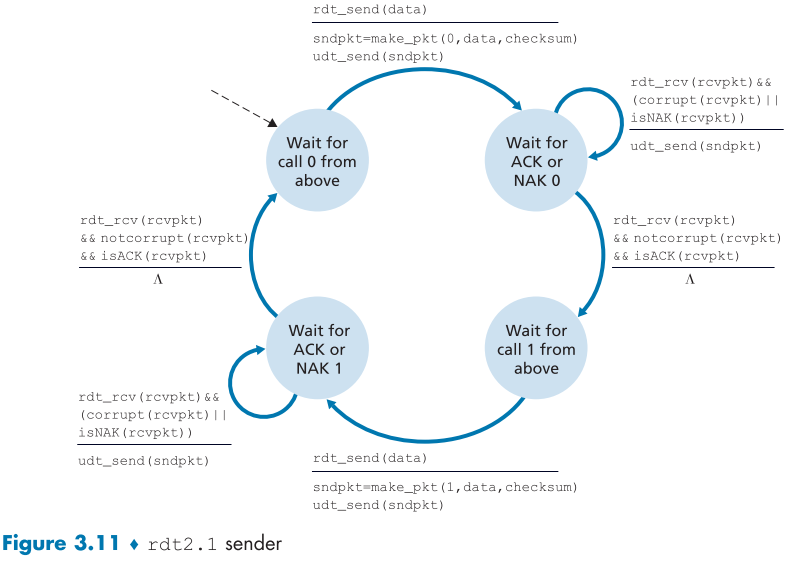
rdt2.1에서는 sequence number가 추가되어 sender, receiver 전부 상태가 2배로 늘어나고 복잡해졌다.
여기서 0번 packet은 보내야될 packet, 1번 packet은 앞으로 보낼 packet을 의미한다.
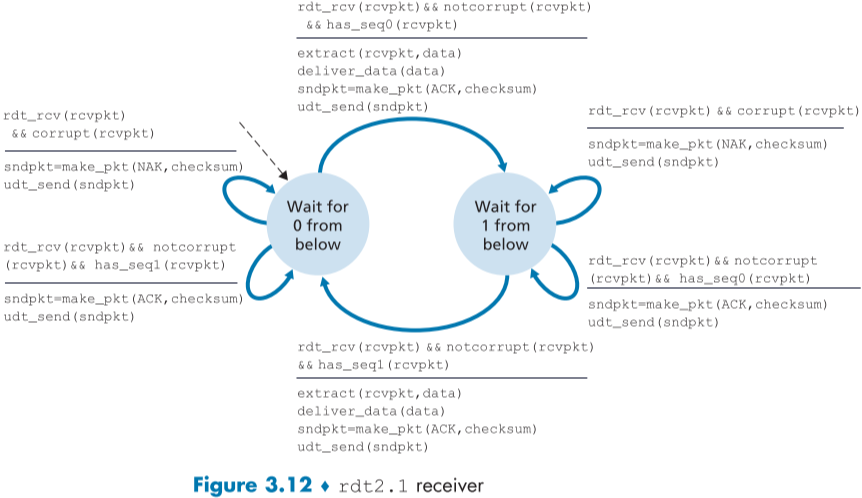
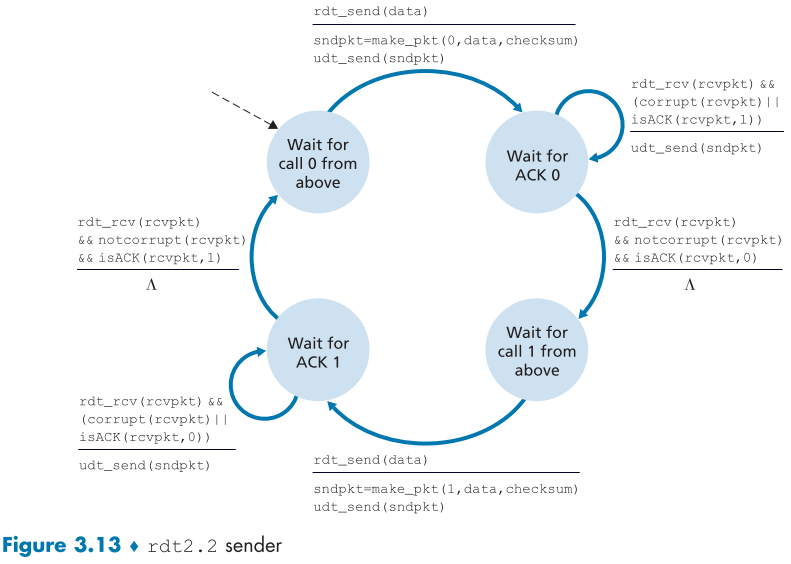
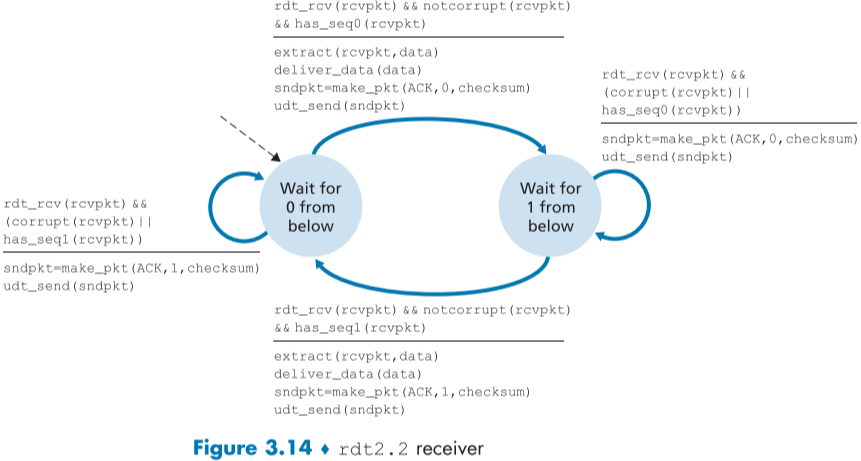
rdt 2.2에서는 rdt2.1과 달리 NACK packet가 존재하지 않는다.
대신에 이때는 수신자측이 제대로 받았다는 의미로 ACK packet을 보내고, packet을 다시 보내라는 의미로 마지막에 제대로 받은 packet에 대한 ACK를 다시 보낼 것이다.
만약, 서로 다른 packet 둘을 보낸 송신자측이 똑같은 sequence number의 ACK packet(duplicated ACKs)을 둘 받았다면, 중복된 ACK packet의 대상 packet은 제대로 보내졌고 나머지 하나는 아니라는 것을 알 수 있다.
즉, rdt2.2 부터는 ACK packet에도 sequence number가 추가되며, 이는 해당 ACK의 대상이 되는 packet의 Sequence number이다.
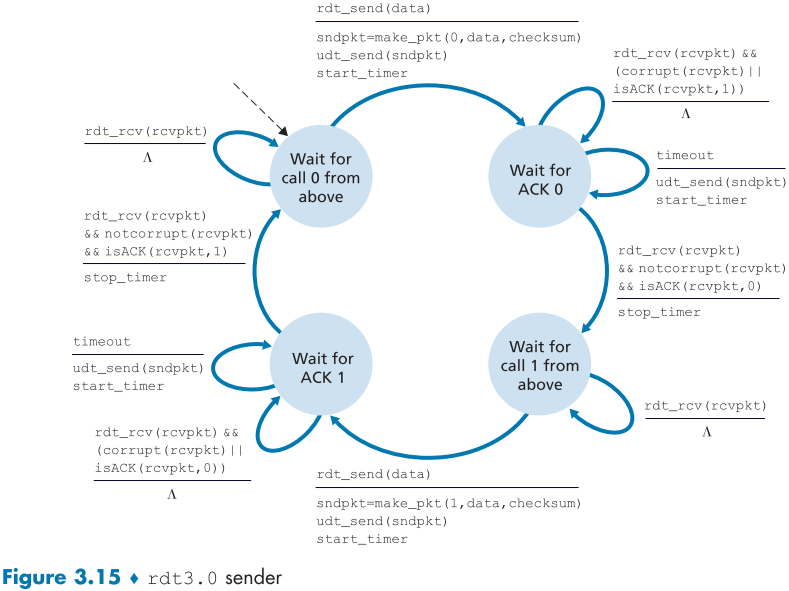
Reliable Data Transfer over a Lossy Channel with Bit Errors: rdt3.0
rdt3.0에서는 packet의 완전한 손실 또한 추가로 고려한다.
해결해야할 문제는
- packet 손실을 어떻게 알아챌 것인가?
- packet 손실을 어떻게 해결할 것인가?
이다.
2번째 문제는 우리가 이미 도입한 기능들(checksum, sequence numbers, ACK packets, retransmissions) 등으로 해결 가능 하지만
1번째 문제는 Countdown timer를 만들어, data packet이나 ack packet이 보내질 때, 시간을 설정하고, 일정 시간까지 response가 돌아오지 않으면, 재전송하는 방식으로 해결한다.
이때의 응답 한계 시간을 설정하는 것이 중요하며, RTT와 기타 buffer 시간을 고려해서 설정해야 하는데, 너무 길면 에러 수정까지 오래 걸려 설정하기 힘들다.
rdt3.0은 packet의 sequence number가 0 아니면 1 두가지로 구분되기 때문에 alternating-bit protoocol 이라고도 한다.
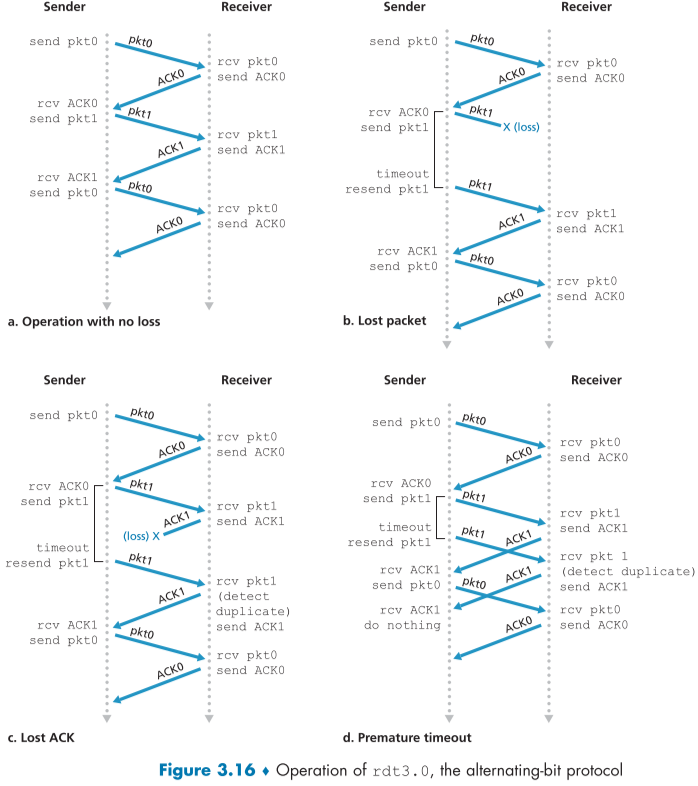
3.4.2 Pipelined Reliable Data Transfer Protocols
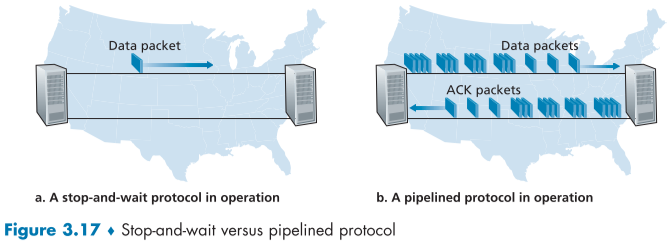
위의 rdt3.0은 기능적으로 문제없지만, stop-and-wait 방식 특유의 패킷을 하나씩 보내기에는 너무 느리다는 성능적 문제가 있다.
예를 들어 미국 서부와 동부 사이의 RTT를 30ms, 8000bit짜리 packet을 처리하는데 8 micro초가 걸린다면
\[d_{trans}=\frac{L}{R}=\frac{8000\ bits}{10^9\ bits/sec}=8\ microseconds\]ACK packet이 다시도착하는 시간과 동시에 다음 packet을 보내는데 걸리는 시간은 30.008ms 이후가 되고,
이때 실제로 sender가 기다리는 시간과 일하는 시간의 비율은 다음과 같다.
\(U_{sender}=\frac{L/R}{RTT+L/R}=\frac{.008}{30.008}=0.00027\)
sender 측이 일하는 시간보다 대부분의 시간을 Ack packet을 기다리는데 쓰게 된다.
심지어 이 시간은 호스트 사이의 네트워크에 속한 장비들의 processing delay와 queueing delay를 제외한 값이므로, 실제 1Gbps link에서 옮길 수 있는 data는 200kbps도 채 안될것이다.
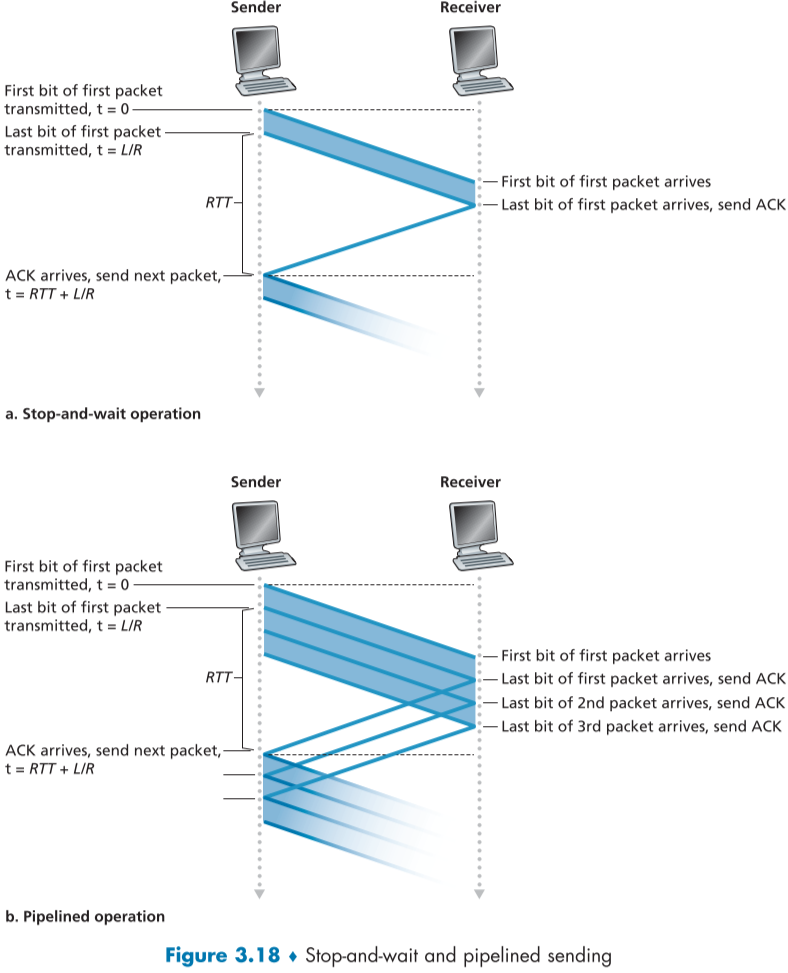
이러한 비효율을 막기 위해 Ack packet이 올때까지 기다리지 않고 특정 갯수의 packet들을 한꺼번에 보낸뒤 한꺼번에 받아내는 Pipelining(fig 3.18)이 가능하다
Pipelining은 다음과 같은 변화를 가져온다.
- ack Packet이 아직 오지 않았더라도 packet을 생성하면서 sequence number를 줄 수 있어야한다.
- 아직 Ack Packet이 오지않은 packet들은 재전송해야할 수 있으므로, 버리지않고 Buffer에 저장해두어야 한다.
- 준비해야하는 sequence number 범위나 buffering 방법들이 데이터 전송 결과(실패, 손실, 딜레이 등)에 따라 바뀌어야 한다.
- 이 방법의 기본적인 접근 방법은 Go-Back-N과 selective repeat가 존재한다.
3.4.3 Go-Back-N (GBN)
Go-Back-N(GBN) protocol은 sender 측이 acknowledgment를 기다리지 않고도 최대 지정한 N개의 packet을 보낼 수 있게 해준다.
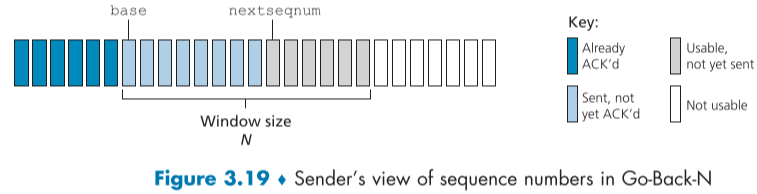
위의 그림은 GBN에서의 seq num의 범위에 대한 그림이다.
base는 아직 확인되지않은 가장 오래된 packet의 seq num이고, nextseqnum은 아직 사용하지 않은 가장 작은 seqnum이다.
범위 [0, base-1]까지는 이미 확인이 끝난 보낸 packet들이고, [base, nextseqnum-1]은 전송했지만 아직 ack되지 않은 packet들이다.
[nextseqnum, base+N-1]은 data가 상위 layer에서 현재로 도착 즉시 사용할 수 있는 seq number이다. 마지막으로 base +N 부터 끝까지 pipelining 과정 중에 아직 ack되지 않은 packet이 ack 되기 전까지 사용 불가능한 seq num이다.
전송과 ack 도착이 진행되면서 window size N은 크기는 그대로 인채 점점 뒤로 옮겨가게 된다.
이러한 GBN protocol을 sliding-window protocol 이라고도 한다.
패킷을 무제한으로 보낼 수 없고 윈도우 사이즈 N으로 제한을 둔 이유는 네트워크의 혼잡을 제어하기 위해서이다.
seq num header가 packet에서 k bit 크기를 차지한다면, 최대 0~$2^k-1$까지의 seq num을 가질 수 있고 이는 많은 문제를 야기시킨다.
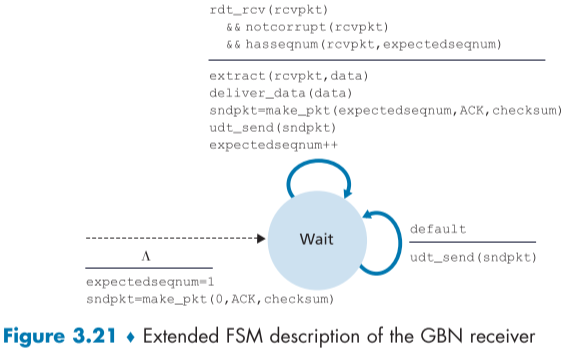
아래의 fig 3.20과 fig 3.21은 rdt 3.0의 동작에 대한 FSM이다.
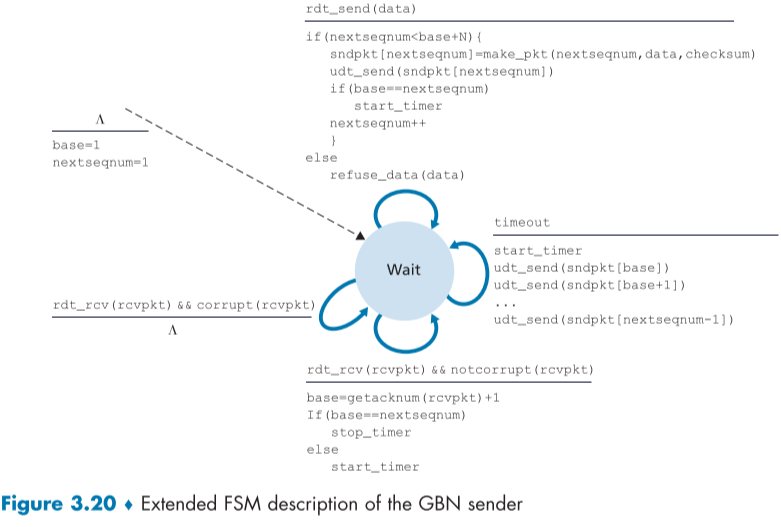
GBN sender에게는 3개의 일이 생겨나는데
- 상위 계층에서의 발동, upper layer에서 data를 보내면 먼저, window을 살펴보고, window에 남은 seq num이 있다면, packet을 생성한 뒤, 보내고, 만약 더이상 남은 seq num이 없다면, ack packet이 돌아와 window에 자리가 남을 때까지, buffer에 data를 저장해 두거나, upper layer와 연동(세마포어, flag)하여 자리가 남을 때만 data를 보내도록 설정한다.
- Ack packet 받아들이기, cumulative acknowledgment: seq N 번째 ACK는 이전 packet들의 ACK를 대신 한다. 만약 N 번째 packet 이전의seq N-m 번째 패킷이 전송 실패였다면, seq N-(m-1)번 ACK까지만 왔을 것이므로, seq N번째 ACK가 왔다는 건, 그 이전의 packet은 제대로 받았다는 의미이다.
- 타임아웃 이벤트,Go-Back-N 프로토콜에서는 여러 packet을 보내지만 Timer는 가장 오래된 unacked packet 하나에만 설정된다. 만약 Timeout이 된다면, sender 측은 모든 unacked packet들을 버리고 다시 재전송한다, 만약 가장 오래된 unacked packet이 ack된다면, 새롭게 찾은 가장 오래된 unacked packet에 Timer를 처음부터 다시 설정한다. 만약 더이상 unacked된 packet이 없다면 타이머는 멈춘다.
또한 GBN에서는 수신자 측에서 seq 순서가 이상하게 먼저 도착하거나 늦게 도착한 packet들은 정상적인 packet이여도 버리는데, 이를 통해 수신 측은 순서에 어긋난 패킷은 다 버리고, 다음 seq num(expectedseqnum)만 기억하면 되는 등, buffer 관리를 단순하게 할 수 있고, 송신측은 window의 범위와 nextseqnum등의 변수를 관리해야 한다.
아래 그림처럼, window size에 따라 seq num 증가와 그에 따른 sender 측의 송신이 제한되며, 만약 이전 packet이 성공적으로 송신되었다면, 그때부터 window 범위를 높은 번호로 옮기면서 seq num을 늘릴 수 있다.
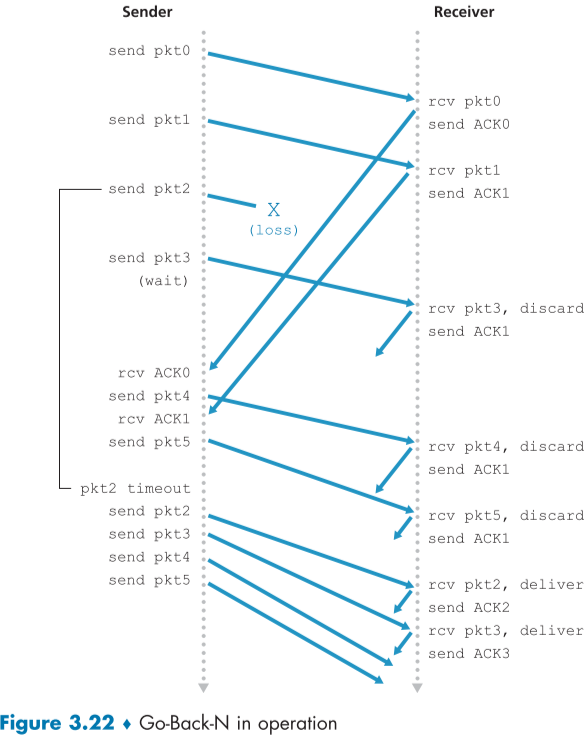
3.4.4. Selective Repeat (SR)
위에서 설명했던 Go-Back-N에서 순서에 어긋난 packet은 해당 packet seq num 이상의 packet들은 정상 전송하여도 전부 버리는 것을 막기 위해 Selective Repeat (SR) 방법을 이용할 수 있다.
해당 TCP receiver가 Selectective Acknowledgment를 사용할 수 있으면 TCP option header 마지막 자리쯤 8bit로 sack permitted (0100 xxxx) 표시가 되있음
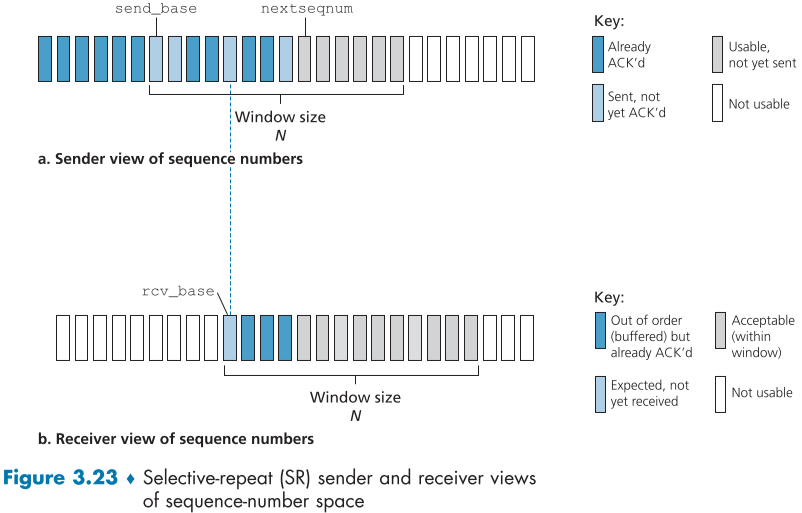
SR 수신자는 마치 송신자처럼 직접 기록하는 윈도우를 주시하며, 기존에 버리던 순서가 어긋난 packet들을 전부 buffer에 저장해두고, 순서에 맞지않은 packet들이 끼워질때까지 기다렸다가 한꺼번에 상위 계층로 보낸다.
- 하지만 이때, 수신자와 송신자의 윈도우 범우 크기는 같지만, 가르키고 있는 범위는 다를 수 있다. fig 3.23 참조
-
상위 계층에서 데이터 수신, GBN에서의 활동과 동일함.
-
타임 아웃, GBN과 다르게 이번에는 각 packet 별로 논리적으로 생성된 timer가 실행되며, 타임아웃된 해당 packet만 재전송된다.
-
ACK 수신, ACK packet을 받으면 해당 ACK packet이 알려준 seq number의 packet만 성공한 것으로 윈도우에 기록, 만약 send_base(윈도우의 가장 처음에 있는 packet)이 ack되었다면, 윈도우 범위를 다음 ack안된 packet으로 옮기고, 새로 생긴 window 범위 내에서 아직 안보낸 packet을 전송한다.
- 윈도우 범위 [rcv_base, rcv_base+N-1](즉, 윈도우 범위 전체)에 존재하는 seq num를 가진 packet을 받고 각각마다 ACK 되돌려주기.
만약 해당 packet이 순서에 맞지않는다면 Ack는 보내되, 상위 계층으로 보내지 않고 buffer해둔다.
만약 해당 packet의 seq num이 rcv_base(즉, 받아야했던 순서의 packet)이라면 해당 seq num에 연속된 숫자를 가진 buffer된 packet들을 순차적으로 상위 계층에 보내고, receiver window를 보낸 만큼(=buffer 되지않은 seq num까지) 윈도우를 옮긴다.
- 예를 들어, packet 2가 아직 도착하지 않았고 3,4,5가 이미 도착해 buffer 된 상태였다면, 2가 도착하면, 2,3,4,5는 상위 계층으로, window는 seq num 6을 시작 지점으로 바꿀 것이다.
- [rcv_base-N, rcv_base-1] 범위(=윈도우 사이즈 만큼 앞으로 이동한 범위의 이미 ack했던 seq num)의 packet이 오면, 이전에 ACK를 보냈어도 ACK를 또 다시 보내줘야한다.
- 왜냐하면, 송신자의 윈도우 입장에서는 해당 ack packet이 손실, 변형 등의 이유로 받지 못해, Timeout되어 다시 보낸 것일 수도 있으므로, 다시 확인시켜야한다.
- 그 외의 packet은 그냥 무시한다.
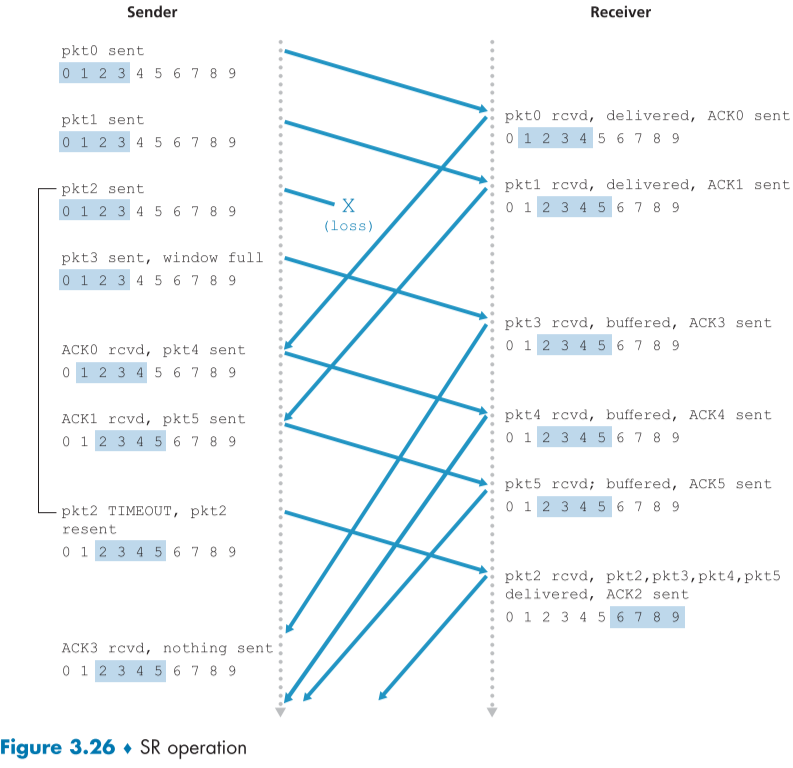
하지만 이때, window size의 크기 제한으로 인해 문제가 생길 수 있다.
예를 들어 아래 fig3.27의 시나리오를 살펴보면,
(a)
-
sender는 0, 1, 2 번째 패킷을 보냈고 잘 도착했지만, ACK가 손실되어 ack를 하지 못했다.
-
하지만 receiver는 이미 0, 1, 2 패킷을 받고 윈도우 범위를 3,0,1로 옮겼다.
- 여기서는 header의 sequence number bit의 한계로 0~3까지의 수가 한계이므로, 넘어가면 0으로 돌아오게 된다.(일순한다 표현하겠다.)
-
하지만 sender의 0번은 ack를 받지 않았으므로 timeout되면 다시 seq num 0의 packet을 보내게된다.
-
receivier는 이렇게 새롭게 도착한 0번 seq num packet을 새로 윈도우를 옮겨서 생긴 0번 packet이라고 착각한다.
즉, sender의 0번 packet과 receiver의 0번 packet이 달라지는 문제가 생긴다.
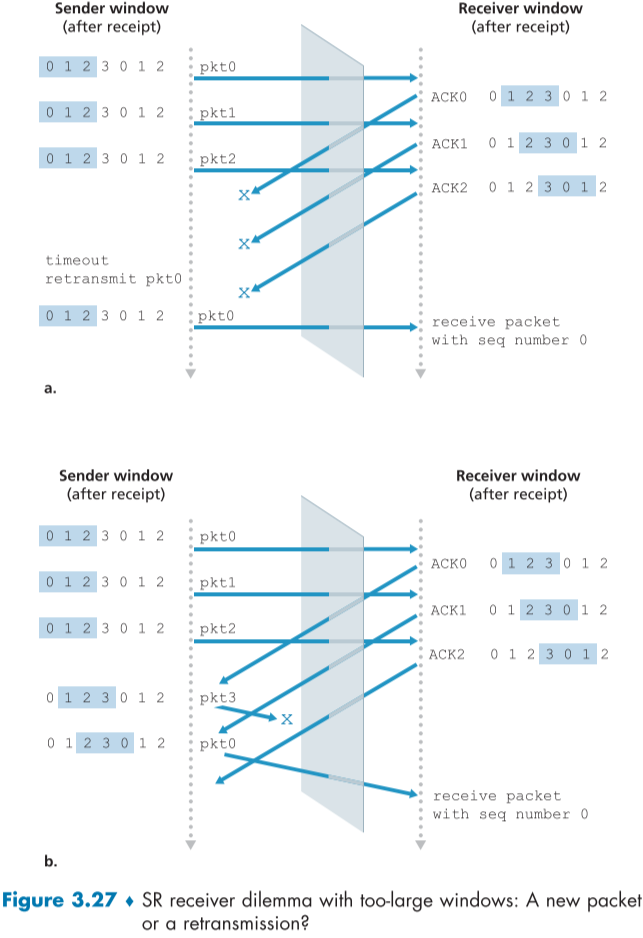
이러한 문제를 해결하기 위해 window size 크기와 sequence number 범위를 다르게 하는 방법을 사용할 수 있다.
window size 크기를 sequence number 범위의 절반 이하로 설정하면 SR에서 이 문제를 해결할 수 있다.
수신자가 현재 rcv base에서 윈도우 사이즈 크기 이전 범위 미만의 packet은 무시하도록 설정해놨기 때문에 해당 문제를 막을 수 있다.(fig 3.25 3번)
예를 들어 위의 (a) 시나리오의 윈도우 사이즈를 3, seq number 범위를 6으로 늘릴 경우, recevier가 필요한 새로운 packet은 4,5,6이고, 받은 packet은 0번일테니, 그저 ack를 다시 한번 보내주면 된다.
아래는 지금까지 배운 RDT의 요약이다.
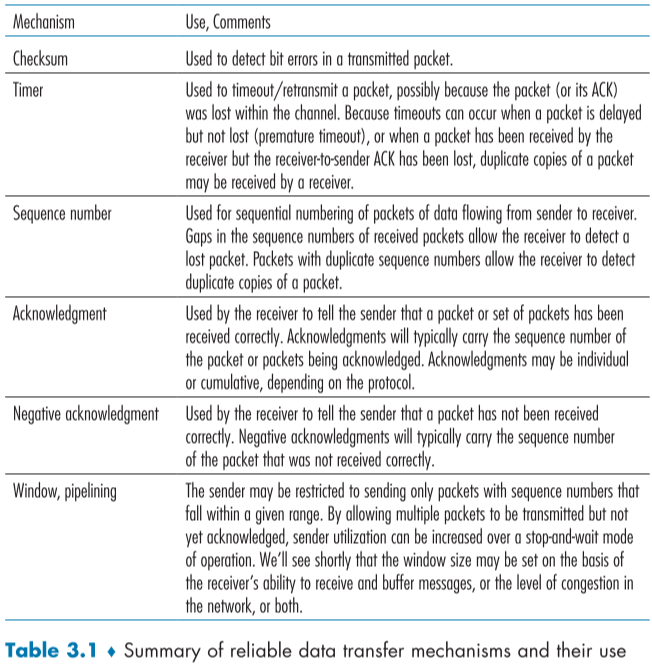
| 메커니즘 | 사용 |
|---|---|
| Checksum | 전송된 packet의 오류 검사에 활용 |
| Timer | Time out하여 packet을 재전송하는데 사용, ACK packet, 또는 데이터 packet가 UDT 내부에서 사라졌을 수 있으므로, 다시 보내 확인한다. |
| Sequence number | packet에 순차적인 번호를 부여하는데 사용, 이 순차적 번호를 이용해 중간에 없어진 번호는 손실된 packet이라고 추측하고, 중복된 packet은 버리게 할 수 있다. |
| Acknowledgement | sender에게 packet이 잘 도착했다고 응답하는데 사용, ACK packet에는 응답 하려는 seq number가 적혀있으며, 프로토콜에 따라 cumulative ACK, individual ACK일 수 있다. |
| Negative acknowledgement | sender에게 packet이 도착하지 않았다고 응답하는데 사용, 보통 도착해야했던 seq number를 적어놓는다. |
| Window, pipelining | 여러 packet을 ack가 확인되지 않아도 동시에 보내게 하여 하나 하나 보내는 stop-and-wait 방식에 비해 성능을 늘릴 수 있다. window size는 sender와 receiver의 역량, buffer 사이즈, 네트워크 혼잡 상황 등에 따라 정한다. |
이러한 packet reorder 문제는 모든 packet이 순차적으로 도착하는 하나의 물리적 도선의 연결에서는 일어날 수 없다.
하지만 실제로는 packet들이 여러 host간의 연결과 buffering을 거쳐 도착하므로, 실제로 일어날 수 있다.
예를 들어 sender 측에서 3번 packet(3-가)을 보내고 ack (3-A)를 기다리는데, 타임 아웃 때까지 도착하지 않아, 3번 packet(3-가-dup)을 결국 재전송하였고, 결국 ack(3-B)를 받아냈다고 치자.
그후 10분 뒤, 다시 sequence number가 일순하여 3번 packet(3-나)을 보냈는데, 이후, 손실된 줄 알았던 ack(3-A)가 10분만에 도착하면, 3-나 packet은 receiver가 ack를 보내지 않아도 ack되게 된다.
실무에서는 일순 전에 해당 seq num의 관련 packet(3-가, 3-가-dup, 3-A, 3-B)가 네트워크에 존재하지 않는다고 확실할 때, 일순된 seq num을 사용(3-나)할 수 있도록 제한하여 해결한다.
바로, packet을 보낼 때, packet TTL(time to live, packet의 최대 수명 시간)을 정해서 보낸 뒤, 이를 넘은 packet은 버려지도록 설정하는 것이다.
예시를 들면 3-가 packet를 보낸지 TTL 시간만큼 시간이 지난다면, 3-나 packet를 보내도 3-가 관련 packet은 전부 없어져있을 것이다.
TCP의 고성능 네트워크에서는 TTL을 3분으로 제한하였고, 이 방법이 packet reordering 문제를 해결한다고 [sunshine 1978]에서 증명하였다.
3.5 Connection-Oriented Transport :TCP
연결 중심, 신뢰가능 데이터, transport layer 프로토콜인 TCP에 대해 알아보자 (RFC 793, RFC 1122, RFC 2018, RFC 5681)
3.5.1 The TCP Connection
TCP의 연결은 circuit switching의 TDM이나 FDM을 의미하는 것이 아니라, 두 host 간에 연결 상태를 저장하는 것을 의미한다.
TCP는 end-to-end 통신이므로, host 사이의 network에는 아무런 상태가 저장되지 않는다.
TCP는 양측이 서로 동시에 통신 가능한 full-duplex service이며, 1 대 1 대화인 point-to-point이다,
- 한명이 여러명에게 송신하는 multicasting은 불가능하다
먼저, client process 측에서 server process 측으로 TCP 연결을 요청하면서 시작되며 코드는 다음과 같다.
clientSocket.connect((serverName, serverPort))
이때, client 측에서 한번, server 측에서 한번, 마지막으로 client 측에서 한번 더 총 3번의 특별한 segment를 보내게 된다.
처음 두번은 payload가 없으며, 3번째에는 data를 포함하고 있다.
이 과정을 three-way handshake라고 한다.
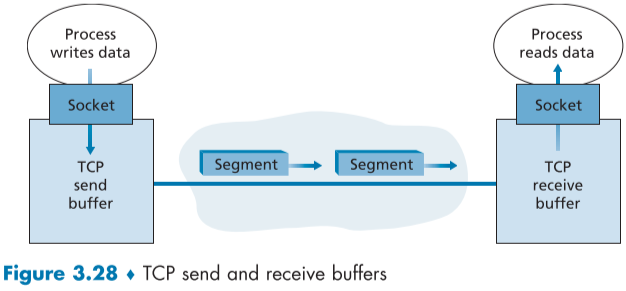
TCP 연결이 생성되면 두 연결 사이에는 버퍼가 형성되며, 원하는 시간에 버퍼에 application측의 data를 저장하거나 application 측에 전달하면서 상위 layer와 통신한다.
-
버퍼는 sender와 receiver 양측에 전부 존재하며, congestion control에 활용되기도 한다.
-
이때 통신하는 packet을 TCP segment라고 하며, IP datagram에 encapsulate 된다.
이때 최대 segment 크기 제한값을 MSS(Maximum Segment Size)라고 부르며, 이 값은 host 간의 Link-layer 계층을 지나칠 수 있는 한계 크기(Maximum Transmission Unit, MTU)가 TCP/IP header(보통 40 bytes) + segment 크기에 맞게 정한다.
-
Ethernet과 PPP의 MTU는 1500bytes 지만 TCP와 IP 헤더크기가 20+20bytes 이므로 보통 1460bytes로 MSS를 잡는다.
-
네트워크상 지나치는 모든 Link 계층에서의 MTU 값은 path MTU라고 하며, 이를 기반으로 하는 MSS도 있다.
-
MSS는 segment에 들어갈 수 있는 application layer data의 최대 크기 값를 의미하지, header가 포함된 TCP segment의 최대 크기를 의미하지 않는다.
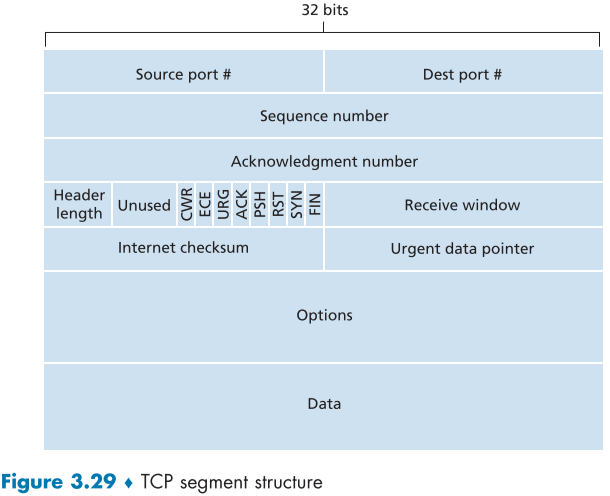
3.5.2 TCP Segment Structure
TCP segment의 크기가 정해져있으므로 MSS 이상의 대용량 데이터는 여러 segment로 나뉘어 전송하게 된다.
하지만 언제나 MSS 크기인 것은 아니고 필요에 따라 (Telnet, ssh)1 byte 까지 줄어들때도 있다.
| field name | using | size(bit) total 20 bytes |
|---|---|---|
| source and destination port numbers | multiplexing/demultiplexing | 16, 16 |
| Internet checksum | error check | 16 |
| sequence number | reliable data transfer service | 32 |
| acknowledgement number | reliable data transfer service | 32 |
| receive window | flow control, recceiver 측이 받을 수 있는 bytes 수 | 16 |
| header length | 32bit word 기준 TCP header의 길이, 보통 20 bytes | 4 |
| options | 길이나 존재 여부가 선택적, sender-receiver 간 MSS 조율, window size 변경 | optional, variable |
| flag-ACK | acknowledgement의 값이 정상적인가? | 1 |
| flag-RST | connection 수립 시 사용 | 1 |
| flag-SYN | connection 수립 시 사용 | 1 |
| flag-FIN | connection 종료 시 사용 | 1 |
| flag-CWR | 혼잡 상황 알림 | 1 |
| flag-ECE | 혼잡 상황 알림 | 1 |
| flag-PSH | receiver에게 이 segment data를 바로 upper layer로 보내게 함. (실무에서 사용 안함) | 1 |
| flag-URG | sender 측 application layer에서 urgent segment로 지정했음을 의미. (실무에서 사용 안함) | 1 |
| Unused | 사용 안하는 4 bit 값, 나중에 버전이 올라가면 추가하기 위한 빈 공간 | 4 |
| Urgent data pointer | urgent data 값의 마지막 byte의 pointer 주소값. (실무에서 사용 안함) | 16 |
| data | payload, Application layer에서 보내준 데이터값 | MSS |
Sequence Numbers and Acknowledgment Numbers
Sequence Numbers과 Acknowledgment Numbers field는 TCP header 중 데이터 신뢰 전송(Reliable Data Transfer) 구현을 위한 가장 중요한 부분이다.
TCP는 byte 번호를 기준으로 segment를 구별하지, 일정한 segment별로 나누어 구분하지 않는다.
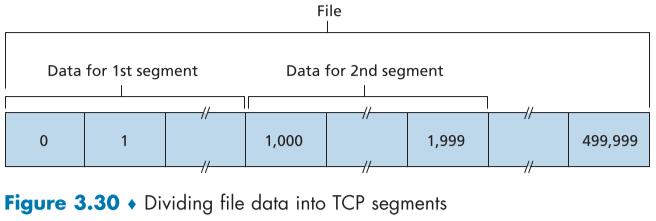
이해를 쉽게하자면, segment의 sequence 번호는 data의 첫번째 byte-stream 의 번호이다.
아래 fig3.30 예시를 들자면, 최대 segment size(MSS)가 1000byte이고, 500000byte의 데이터가 총 500개의 segment로 나뉘어 전송되어야 하는 상황이라면, 첫번째 segment는 sequenc num이 0, 두번째 segemet의 seq num은 1000, 그다음은 2000이 되는 식이다.
Acknowledgement number의 경우, 연결상대 host에게 다음에 올것으로 예상되는 byte의 번호를 넣어 ack한다.
위의 예시를 다시 들자면, bytes 0~999까지인 첫번째 segment를 받은 상태에서 돌려줘야할 ack segement의 acknowledgment number는 1000이 될 것이다.
2번째 segment를 받았다면 다음은 2000을 ack num으로 써야한다.
참고로 TCP는 가장 큰 acknowledgment number에 해당하는 ack segment가 오면 그 이하의 bytes 들은 자동으로 ack한걸로 치는 위에서 언급했던 cumulative acknowledgment를 이용한다.
만약, acknowledment에 맞지않는 out-of-order(순서에 맞지 않은) bytes를 가진 segment가 먼저 온다면, TCP를 구현하는 개발자 입장에서 2가지를 중 하나의 방법을 고를 수 있게 되어있다.
- 맞지 않는 순서의 segment는 그냥 버린다
- 구현이 쉽고 이해가 쉬운 방법
- 맞지 않는 순서의 segment도 buffer에 포함하고 있다가, 원하던 segment가 도착하면 함께 처리한다.
- 구현이 어렵지만 성능상 효율적인 방법
또한, sequence number의 시작 번호를 0으로 가정하고 설명했지만, 실제로는 이전 TCP 연결이나 통신의 seq number 오류를 피하기 위해 랜덤으로 정해진다.
- 이때 sequence number는 양방향 통신 특성상 각각 host에 하나씩 있다.
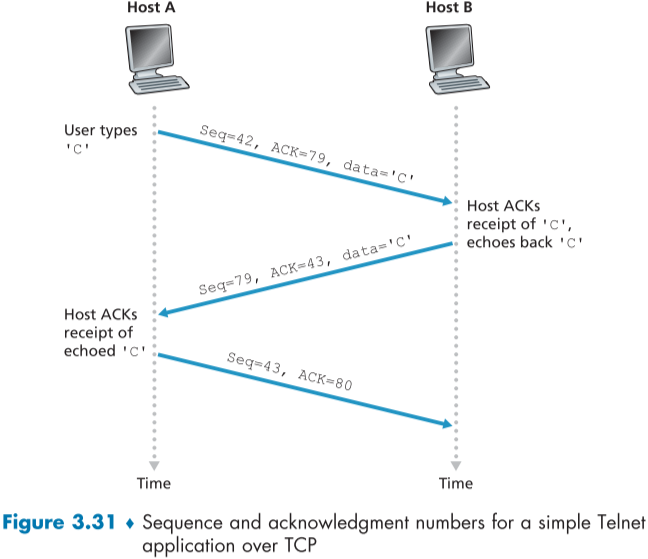
Telnet: A Case Study for Sequence and Acknowledgment Numbers
Telnet(RFC854)는 원격 로그인에 사용되는 TCP 사용하는 application layer protocol이다.
민감한 정보를 포함하여, data가 암호화되지 않고, eavesdropping attack 같은 공격에도 취약하여 최근에는 SSH protocol에 밀리는 추세이다.
Telnet client가 화면상에 글자(character)를 입력하면 매 글자마다 server측에 전달되어 입력되고, 또 그 출력물을 client에게 돌려주는 형식이다.
fig 3.31의 예시를 보자면 먼저 글자 C를 입력하면, 랜덤으로 정한 seq 대로 seq와 ack가 정해진 segment가 전달되고, 이 출력물을 되돌려주는 겸 ack를 진행하기 위해 서버측에서 data c와 seq, ack를 포함한 채로 segment를 돌려준다. 이런식으로 ack 정보가 data를 포함한 segment에 겸사겸사 얹혀 가는 것을 piggybacked이라고 한다.
그 다음, 세번째로 client 측에서 server측에서 보내준 데이터를 ack하기 위해 다시 segment를 보낸다. 이때 모든 segment들은 sequence number를 포함해야하기 때문에 data payload가 없어도 seq number가 1 증가한채로 전달된다.
3.5.3 Round-Trip Time Estimation and Timeout
TCP는 rdt 통신을 위하여 timer를 쓴다.
timer의 설정값은 최소 rtt보다 더 커야하지만, 처음 rtt는 어떻게 설정하는가? 모든 segment마다 timer를 설정해야하나? RTT 보다 얼마나 더 커야하는가? 등의 의문점이 있다.
이러한 것을 이야기 해볼것이며, 자세한 내용은 [Jacobson 1988], [RFC 6298]에서 볼 수 있다.
Estimating the Round-Trip Time
먼저 타이머 설정을 위한 RTT는 sampleRTT들에 관한 식을 통해 구하는데, sampleRTT는 전체 segment의 평균값으로 구하지 않고, 대부분은 segment을 이미 한번 보냈지만 현재 ack되지 않은 segment의 RTT를 하나 sampling 해서 구한다. 이때, 한번 재전송한 segment는 보내지 않고, 오직 한번만 보낸 경우에만 샘플링 대상이 된다.(왜냐하면, 재전송된 segement에 대한 ack가 아니라 첫번째 전송했엇던 segment의 늦게 도착한 ack으로 잘못 측정될 수도 있으므로)
이렇게 구한 sampleRTT에서 TCP에서 사용하는 EstimatedRTT를 구하며, 이러한 EstimatedRTT 매번 다음과 같은 식으로 갱신된다.
\[EstimatedRTT = (1-\alpha)\cdot EstimatedRTT+\alpha\cdot SampleRTT\\ recommended\ \alpha = 0.125\] \[EsimatedRTT = 0.875\cdot EstimatedRTT+0.125\cdot SampleRTT\]평균 값으로 구하지 않는 이유는, 최신의 네트워크 상태를 반영한 최신 sampleRTT에 좀더 가중치를 주기 위해서이다. 이렇게 최신 가중치를 주는 평균 방법을 exponential weighted moving average(EWMA)라고 한다.
이전에 측정했던 SampleRTT의 영향은 매 갱신시마다 줄어들게 된다.
아래 figure는 Estimated RTT의 예시이다.
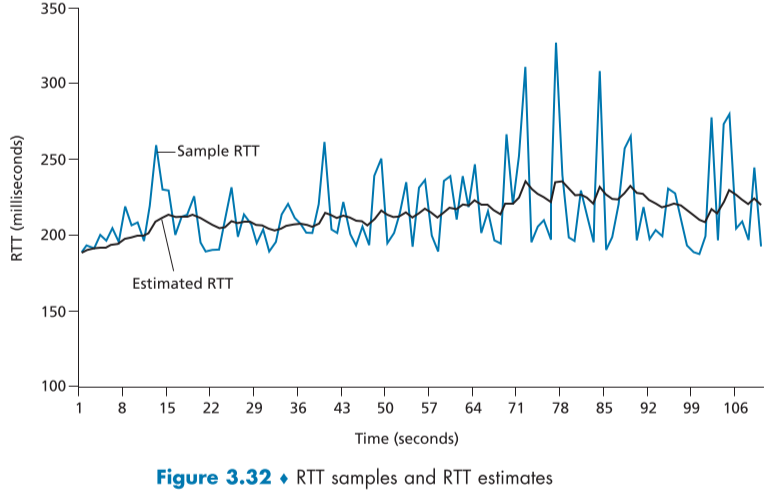
DevRTT는 EstimatedRTT와 SampleRTT를 이용한 추가적인 RTT로, 네트워크 상황을 가늠할때 쓴다. 주로 네트워크 상황이 안정적일 때는 값이 작고, 네트워크 상황이 들죽날죽일 때는 커진다.
Principles in practice
일부 버전의 TCP에서는 3개 이상의 중복된 ACK NUM를 받으면 해당 segment seq num 다음의 segment를 손실로 치고 다시 보내는 NAK 메커니즘을 이용해서 타이머보다 빠르게 재전송을 판단한다.
또한, 전송한 segment 중 아직 ack 되지 않은 segment를 통해 flow-control과 congestion control이 이루어진다.
Setting and Managing the Retransmission Timeout Interval
Timeout Interval은 EstimatedRTT 보다는 충분히 커야 하므로 다음과 같은 식으로 구한다.
\[TimeoutInterval = EstimatedRTT + 4\cdot DevRTT\]EstimatedRTT 기준으로, 네트워크 상황이 들죽날죽이면 더욱 여유를 주고, 네트워크 상황이 안정적이면 마진을 적게 주기 위해 DevRTT를 이용한다.
최초 샘플링이 되지 않았을 때의 initial TimeoutInterval은 1초로 추천된다(RFC6298)
또한, timeout이 생겨나면 EstimatedRTT가 측정될 때까지 TimeoutInterval을 2배로 늘렸다가, 나중에 제대로 측정된 값을 쓴다.
3.5.4 Reliable Data Transfer
TCP는 unreliable한 서비스인 IP와 그 이하의 layer 위에 쌓아올린 reliable data tranfer protocol로, buffer 내부의 전송받은 byte stream이 정상적인 순서의 손실되지 않아야한다.
TCP는 timeout을 측정할 때 여러 timer를 이용하지않고, 오직 하나의 재전송 타이머만 사용하며 이를 single-timer recommendation 이라고 한다.
우리는 TCP sender가 timeout을 이용해 segment의 손실을 방지하는 것, 그리고 나중에 추가로 중복 ack segment로 방지하는 법을 배울 것이다.
아래의 코드 fig3.33은 TCP sender의 동작을 pseudocode로 나타낸 것이다. 동작은 크게 application으로 부터 데이터 받아오기, 타이머 timeout, ACK 받아내기 로 나뉜다.
/* TCP는 혼잡과 흐름 제어에 영향을 받지 않고, MSS 보다 작은 데이터를 전송해야 하며, 단방향 통신만 한다는 가정 */
NextSeqNum=InitialSeqNumber
SendBase=InitialSeqNumber
loop (forever) {
switch(event)
event: 1. application layer에서 데이터 받음
NextSeqNum의 seq num을 가진 TCP segment 생성
if (타이머가 설정되어있지 않으면)
타이머 시작
segment IP layer로 넘김
NextSeqNum=NextSeqNum+length(data)
break;
event: 2. 타임 아웃 in TimeoutInterval
아직 ack 되지않고 가장 작은 seq num을 가진 segment 재전송
타이머 재시작
break;
event: 3. y값을 가진 Ack 도착
if (y > SendBase) {
SendBase=y
if (아직 ack 되지 않은 segment가 있다면){
타이머 시작
}
}
break;
} /* end of loop forever */
A Few Interesting Scenarios
우리가 만든 간단한 TCP 모델은 미묘함이 있다.
우리가 만든 모델의 동작을 알 수 있는 간단한 시나리오 몇개를 보자.
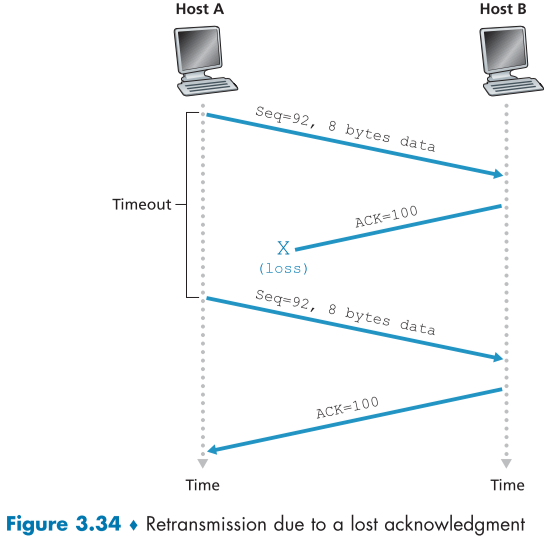
먼저 아래 그림에 묘사된 시나리오 1이다.
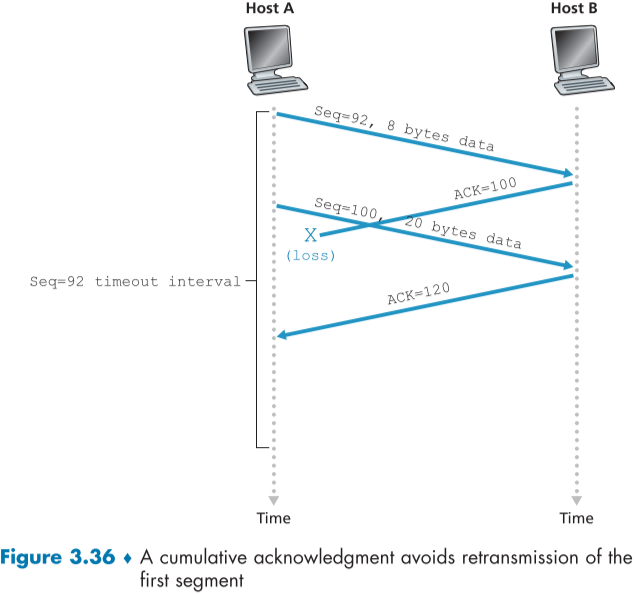
중간에 ACK segment가 유실되면서 Timeout 시간이 지나면서 같은 data의 segment를 한번 더 보내는 상황이다.
같은 내용을 받은 Host B는 해당 segment를 버린다.
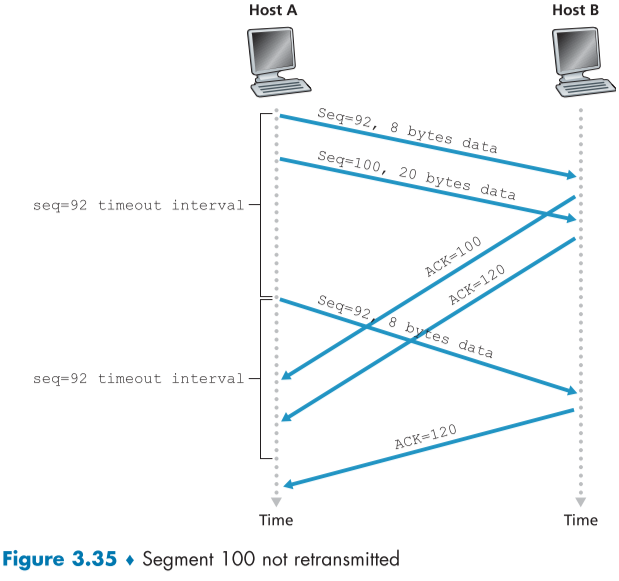
아래 그림은 시나리오 2번째이다.
2개의 세그먼트를 보냈지만 첫번째 segment의 timeout 시간 이후에 ack가 늦게 도착하여 첫번째 segment를 다시 보내는 상황이다.
마지막으로 아래는 세번째 시나리오이다.
첫번째 segment의 ack가 손실되어 도착하지 않았지만 두번째 Ack가 도착하여 cumulative ack 특성을 가진 TCP는 굳이 첫번재 segment의 ack를 다시 보내달라 하지 않는다.
Doubling the Timeout Interval
널리 구현되어 있는 실제 TCP에서의 동작을 알아보자
우리는 TimeInterval을 EstimatedRTT와 DevRTT로 구한다고 했었지만
실제로는 Timeout이 발생할 때마다, 다음 unacked segment 부터는 TimeInterval을 2배로 적용시키고, Timeout 이벤트 이외의 이벤트가 발생하면,(pseudo code에서 1,3번) EstimatedRTT와 DevRTT로 TimeInterval을 설정하는 방법을 쓴다.
예를 들어, 초기 TimeInterval이 1초였고, Timeout이 발생했다면, 해당 segment를 재전송하고, TimeInterval을 2초로, 만약 또 다시 Timeout이 발생했다면 4초로 2배씩 늘리는 것이다.
이를 통해 기초적인 혼잡 제어(congestion control)이 가능한데, 자주 Timeout이 발생한다는 것은 네트워크 상황이 좋지 않다는 의미이며, 점점 TimeInterval을 늘려 재전송하는 segment 빈도를 줄여 네트워크 상황이 개선될 수 있기 때문이다.
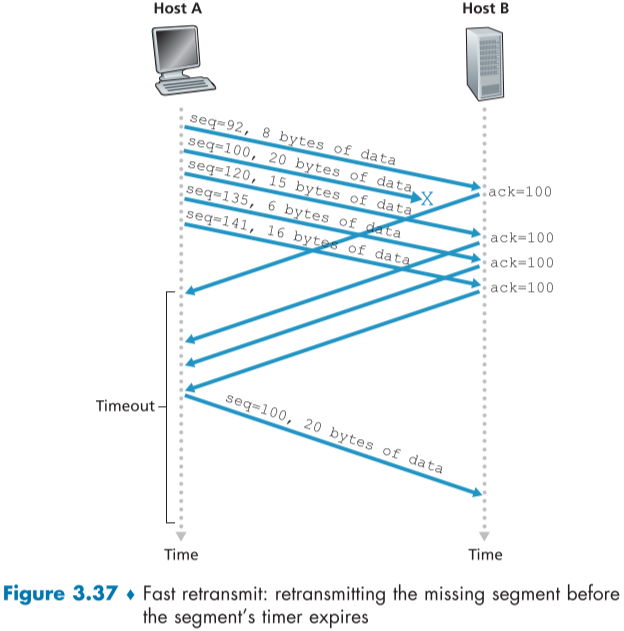
Fast Retransmit
Timeout이 발생되면 재전송하는 현 시스템에는 기나긴 TimeInterval 시간을 기다려야 재전송이 되므로, end-to-end delay가 커진다는 단점이 있다.
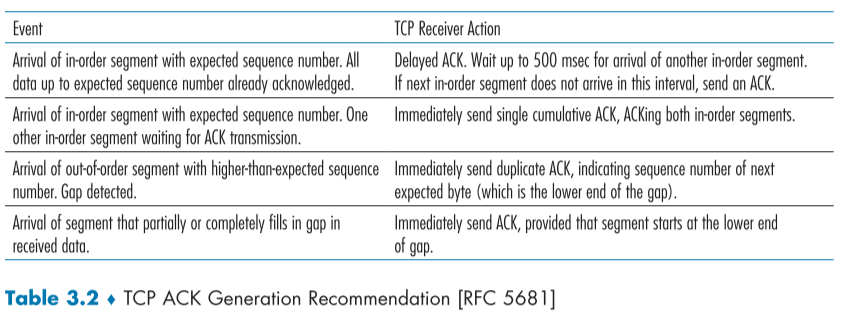
이를 duplicate ACK(중복 ACK)로 sender 측에서 더 빠른 시간에 segment의 손실을 알아챌 수 있다.
duplicate ACK는 이미 Ack가 끝난 segment의 ACK segment가 다시 온 것을 의미한다.
아래 표는 segment 도착 이벤트 시 receiver의 활동이다.
| 이벤트 | TCP 수신측 활동 |
|---|---|
| 수신측에 순서에 맞는 segment가 예상된 seq num을 가지고 도착, 이전의 segment 들은 이미 ACK 된 상태 | 지연된 ACK. 500msec 동안 다음 순서의 segment를 기다리고, 오지 않으면 이전 segment까지의 ACK 전송 |
| 수신측에 순서에 맞는 segment가 예상된 seq num을 가지고 도착, 송신측에서 몇몇 segment들이 ACK를 기다리는 상태 | 즉시 최신의 cumulative ack 전송하여 순서에 맞는 모든 segment를 ack하게 함 |
| 수신측에 예상보다 높은 순서의 seq num을 가진 segment가 순서에 맞지 않게 빨리 도착, buffer에 들어가면서 중간에 window에 갭이 생김 (= 중간 segment가 손실 됬다는 의미) | 이전에 보냈던 seq num을 가진 중복 ack를 보냄. 예를 들어 3번 segment까지 오고, 이후, 8번 segment가 왔다면 3번에 대한 ack를 보냄(갭의 처음 바로 앞 번호) |
| 위의 이벤트에 의해 window에 갭이 있던 상태에서 갭을 전부 혹은 일부 채워줄 수 있는 segment 도착 | 즉시 가장 첫 갭의 마지막 세그먼트에 대한 ack를 하나 보냄. |
duplicate ack(중복 ack)는 총 3개의 중복 ack, 즉 총 4개의 같은 ACK가 돌아 왔다면, 그 경우 Timer가 남은 경우에도 fast retransmit을 실시하게 된다.
굳이 1~2개의 중복 ack가 아니라 3개의 중복 ack인 이유는 그 이전 중복 ack는 segment의 유실이 아닌 그저 늦게 도착하는 것일 수 도 있기 때문에 3번까지 더 기다려 주는 것이다.
아래는 fast transmit의 예시이다.
event: 3. y ack num을 가진 ack 받음
if (y > sendBase) {
sendBase = y
if (아직 ack 안된 segment가 있다면){
타이머 설정
}
}
else{ /* y값이 중복인 ack를 받을 경우 */
y의 중복 ack 갯수를 하나 늘림
if (중복된 ack 갯수가 3개 이상이 됬을때){
/*TCP fast retransmit*/
y번 segment 재전송
}
}
break;
ACK 수신 시의 event(3번 이벤트)을 위의 코드로 바꿔야 한다.
이러한 TCP 재전송 메커니즘의 효과는 30년의 세월 동안 현실에서 증명되었다.
Go-Back-N or Selective Repeat?
TCP는 순수하게 GBN 방식도, 순수하게 SR 방식도 아니며 둘을 절충한 selective acknowledgment 방식이다.
TCP는 cumulative ack를 사용하여 segment 일일이 ACK를 확인하는 방식은 GBN과 비슷하지만, ACK 되지않아 손실된 걸로 판단된(타이머로 인한 것이든, 중복 ACK로 인한 것이든) segmentn 만 재전송 요청한다는 점은 n 부터 전송한 마지막 segment인 N까지를 전부 재전송하는 방법인 GBN과 다른 SR 방법과 비슷하다.
- 심지어 만약 제한 시간 이내에 ack n+1 이상을 받게되면 그마저 재전송하지 않는다.
3.5.5 Flow Control
TCP에서 flow-control service란, application이 사정상 data를 늦게 가져가 receiver buffer가 가득차는 것을 막기 위해 sender 측에 전송량을 낮추도록 하는 것이며,
congestion-control은 중간 네트워크 상황이 나빠지지 않도록, sender 측에 전송량을 낮추도록 하는 것이다.
이 둘은 비슷하지만, 다른 목적을 가지고 있고, 사람들이 많이 혼동하고 혼용하기도 한다.
이번에는 flow-control에 대해서 알아보기 위해 TCP service가 순서에 맞지 않게 도착한 segment는 전부 버린다고 가정한다.
TCP에서 송신자는 receive window 라는 변수를 가지고 있어 이를 통해 전송량을 조절한다. 또한 TCP는 양방향 통신 (full-duplex)이므로 양 측에 각각 상대를 위한 receive window를 가지고 있다.
Host A가 TCP를 통해 대용량 파일을 Host B에 보낸다고 가정하자.
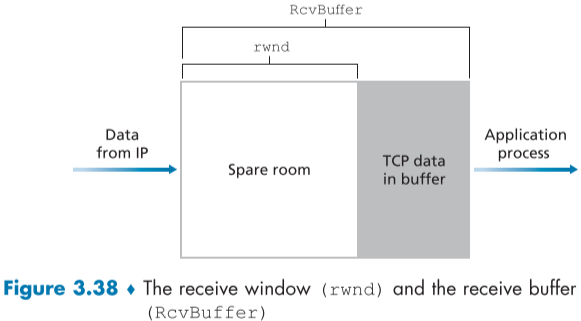
Host B는 receiver buffer overflow를 방지하기 위해 버퍼 크기를 RcvBuffer로 정하고, 두 가지 변수를 정한다.
- LastByteRead: application이 buffer에서 data를 빼간 bytes의 크기
- LastByteRcvd: sender가 buffer에 data를 전송한 bytes의 크기
overflow가 일어나지 않으려면 다음과 같이 위 두 변수의 차가 buffer 크기를 넘으면 안된다.
$LastByteRcvd - LastByteRead \leq RcvBuffer$
receive window, 변수명 rwnd는 buffer에서 남은 공간을 의미한다.
$rwnd = RcvBuffer - [LastByteRcvd - LastByteRead]$
rwnd 값은 시간에 따라 동적으로 바뀌며, 아래는 그 rwnd를 그림으로 표현한 것이다.
이렇게 recevier는 sender에게 보내는 segement들(주로 ack) header에 rwnd 값을 넣어 보내어 flow-control이 이루어진다.
sender는 LastByteSent와 LastByteAcked라는 두 변수를 이용해 현재 보냈지만 acked 되지 않은 segment의 bytes양(LastByteSent - LastByteAcked)을 체크한 뒤 이 값이 rwnd 값보다 작게 유지된다면, buffer overflowing이 일어나지 않는다고 확신한다.
$LastByteSent - LastByteAcked\leq rwnd$
하지만 문제가 하나 있는데, rwnd가 0이 되는 순간과 receiver가 더이상 ack를 보낼 segment도 없게되는 순간이 겹칠 경우, sender 측에서는 rwnd가 0이라 더 이상 segment를 보낼 수 없고, receiver 측은 sender가 segment를 보내지 않아, ack를 보낼게 없어 더이상 rwnd가 자리가 생겨도 알려줄 수 없는 상황이 생긴다.
이때를 방지하기위해 rwnd가 0이라고 보고 받는 순간부터 sender 측은 1 byte 짜리 더미 데이터가 포함된 segment를 주기적으로 보내고, receiver 측은 이에 ack를 보내면서 rwnd를 주기적으로 sender 측에 보고한다.
UDP의 경우 이러한 flow control이 없어, socket에 한계인 buffer에 멈춤 없이 제공되며, process가 빨리 처리하지 않으면 overflow가 일어난다.
3.5.6 TCP Connection Management
TCP 연결(Threeway handshake)의 방법을 아는 것은 SYN food attack 같은 취약점 공격 관련 보안 방지 및 connection delay 인지 등의 이유로 중요하다.
-
먼저 client TCP 측에서 server측에 특별한 segment를 보낸다. 이 segment는 SYN header가 1로 설정되어 있고, 추가로, client 측에서 랜덤하게 설정한 sequence number(client-isn)가 sequence number field에 적혀있는 data가 없는 segment (SYN segment)이다.
- 이미 종료된 이전 TCP 연결 등에서 늦게 도착하는 segment 등의 영향으로, sequence number가 겹치는 것을 막기 위해 랜덤으로 시작 seq num(ISN)을 정한다.
- 초기설정 sequence number를 정하는 방법은 보안적인 측면에서 고려해서 고르기도 한다.[CERT 2001-09; RFC 4987]
-
SYN segment가 서버측에 도착하게 되면 서버측은 해당 연결을 위한 buffer와 variable을 할당하고, connection-granted segment(SYNACK segment)를 준비한다. 이 SYNACK segment를 만드는 과정은 먼저
- segment를 생성한 뒤, syn header 값을 1로 만든다.
- SYN segment의 segment header에서 client_isn 값을 가져와 client_isn + 1값을 acknowledment field에 넣어주고,
- 서버측의 시작 sequence number(=server_isn)을 설정해준 뒤, server_isn 값을 sequence number field에 넣고 client 측에 재전송한다.
-
Client 측에서 SYNACK segment를 받고 나서, 마찬가지로 buffer와 variable을 설정한다. 이후 client host가 새로운 segment를 만드는데,
- SYNACK segmen에 포함되있던 server_sin+1 값을 acknowledgment field에 넣고,
- SYN header 값은 0으로 넣고
- payload에 server에 주려던 data를 넣고 sequence number를 client_isn+ data bytes만큼 증가시킨 뒤, 서버측에 다시 전달해 Threeway handshake을 완성한다.
이후로는 SYN bit가 0으로 설정된 segment로 서로간에 통신한다
이 과정을 통해 서로 통신 준비가 완료됬음을 확인할 수 있으며 3번의 통신이 이루어지는 위 과정을 Three-way handshake라고 부른다.
- 어째서 세번인가?, 이 과정은 서로에게 seq number 설정값과 buffer 준비를 하고, 됬냐고 물어보는 과정, 쉽게 말해 서로에게 통신 준비가 완료됬냐고 물어보는 과정이다.
- 즉, A와 B가 서로, “나 이렇게 통신 준비 완료했어”, 그리고 “알았어 확인했어” 두 메시지를 주고 받는 것이다.
- 2명이 2개의 메시지, 총 4개의 메시지를 주고받아야 한다.
- 이때 B의 “나 이렇게 통신 준비 완료했어(SYN segment)”와 “알았어 확인했어(SYNACK segment)”는 굳이 두 메시지로 나누지 않고 하나로 보내도 된다.
- 그래서 A의 SYN, B의 SYN과 SYNACK, 마지막으로 A의 SYNACK, 3개의 메시지가 필요하므로 3번 진행한다.
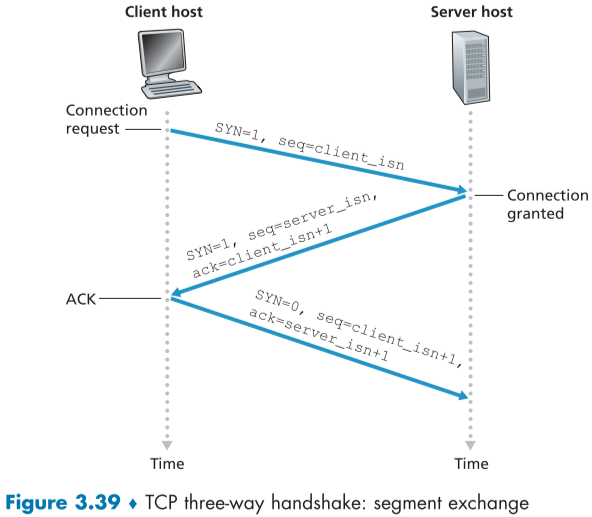
위 그림은 TCP의 three-way hand shake를 그림으로 표현한 것이다.
만약, Connection을 종료하고 싶다면, 아래의 3.40 처럼 four-hand shake로 끝내게 되는데,
- client 측에서 연결 종료를 신청, FIN header가 1인 특별한 segment 서버측에 전송
- Server측에서 위의 segment에 대한 ack segment 전송, 이후 Interval Time 만큼 시간을 기다렸다가 server 측에서 종료
- Server측에서 다시 1번에서 보냈던 FIN segment 전송
- client 측에서 위의 segment에 대한 ack segment 전송, 이후 Interval Time 만큼 시간을 기다렸다가 client 측에서 종료
으로 양측 간의 연결에 대한 모든 자원을 해제하게 된다.
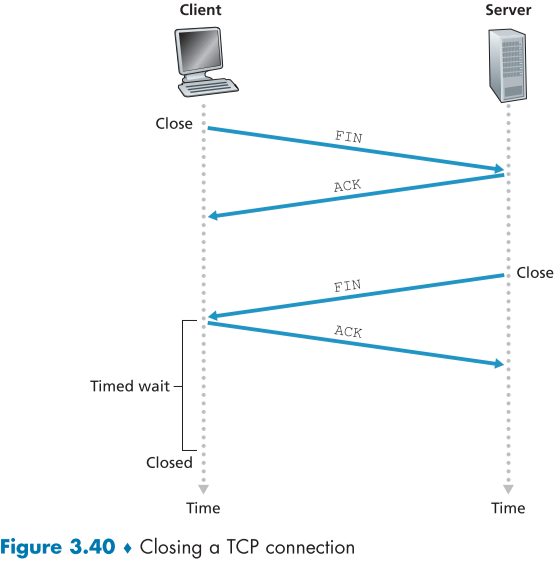
TCP 연결 중에는 각 호스트가 TCP states(TCP 상태)를 기반으로 행동하며, 아래는 client TCP 측에서의 TCP 상태 그림이다.
| 상태명 | 설명 |
|---|---|
| CLOSED | 아직 아무 TCP 연결도 되어있지 않은 상태, server에 SYN segment를 보내 SYN_SENT 상태로 바뀐다. |
| SYN_SENT | SYN segment를 보낸 뒤 server로부터 SYNACK segment를 기다리는 상태, SYNACK segment가 도착하면 ESTABLISHED 상태로 바뀐다 |
| ESTABLISHED | TCP client와 TCP server가 서로 data segment를 주고 받을 수 있는 단계, Client가 FIN segment를 보내면 FIN_WAIT_1 상태로 바뀐다. |
| FIN_WAIT_1 | client가 FIN segment를 보낸 뒤, server측으로 부터 ACK segment를 기다리는 상태, 서버측으로 부터 ack segment를 받으면 FIN_WAIT_2 상태로 바뀐다. |
| FIN_WAIT_2 | client가 ACK segment를 받고, server 측의 FIN segment를 기다리는 상태, 서버측으로부터 FIN segment를 받으면 TIME_WAIT 상태로 바뀐다. |
| TIME_WAIT | TIME_WAIT 상태에서는 서버측에 ACK segment를 보내고 구현에 따라 30초~2분 정도 기다렸다가 CLOSED 상태로 바뀐다. CLOSED 상태로 바뀌면 할당했던 buffer, variable 등의 자원을 풀어버리고 새로운 TCP 연결을 할 수 있다. 이때 잠시 시간을 기다리는 이유는 혹시 보낸 ACK segment가 유실되면, Server 측에서 다시 FIN segment를 보낼 것이며, ACK segment를 재전송 해주기 위해서이다. |
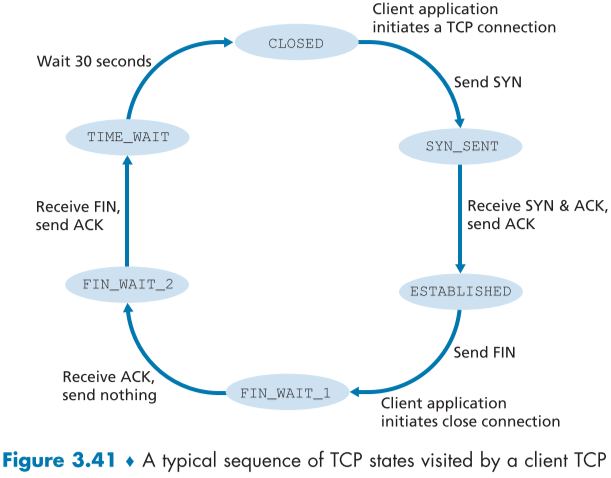
아래는 TCP 연결의 server side 측이다.
TCP 연결이 불가능한 port로 보낸 TCP 관련 segment들의 응답으로 RST segment를 받게 된다.
RST segment, 또는 Reset segment는 RST header bit가 1인 TCP segment로 “해당 socket은 TCP 통신 불가능합니다”라는 의미를 가지고 있다.
만약 UDP socket이 아닌 socket으로 UDP segment를 보내면, UDP는 특별한 ICMP datagram을 응답으로 받는다.
Nmap port Scanning Tool을 통해 TCP, UDP 연결 등을 확인해 볼 수 있다.
host를 정하고 랜덤한 port, 예를 들어 6789 port에 보내보면 다음과 같은 3가지 반응 중 하나가 올 것 이다.
- TCP SYNACK segment 반환, 해당 host의 해당 port가 TCP 연결을 지원 중 이라는 의미이다. nmap 상에서 “open”이 반환.
- TCP RST segment 반환, 해당 host의 해당 port가 application이 돌아가고 있지 않은 빈자리란 의미이다. 이 정보를 통해 공격자들이 해당 port에 firewall이 없어 보안적으로 취약함을 알 수 있다.
- 아무것도 반환되지 않음. firewall이나 기타 이유로 SYN segment가 막혔음을 의미한다.
THE SYN FLOOD ATTACK
이전에 TCP 연결은 보안에 취약하다는 이야기를 한 적이 있다.
그중에 DOS 공격의 일종인 SYN FLOOD ATTACK은 TCP 연결 수립 과정의 맹점에 의해 생긴 보안 취약점이다.
주 방법은 공격자가 해당 서버에 짧은 시간에(TCP는 연결이 수립되지 않은면 ACK segment를 1분 정도 기다린다. ) 끊임 없이 SYN segment를 보내게 되면, 서버는 끊임없이 buffer와 variable을 할당하고, 수많은 SYNACK segment를 보내고 ACK를 기다리게 되는데, 공격자는 ACK를 보내 연결을 수립해주지 않는다.
그 결과, 공격자는 별다른 자원이 필요없지만, 서버측에서는 결국에 자원의 한계에 도달해 정상적인 사용자들은 TCP 연결이 불가능하게 된다.
이를 해결하기 위해 SYN cookie(RFC 4987)이 여러 OS에 구현되었다.
- Server 측에서 SYN segment를 받으면 먼저 buffer와 variable을 할당하지 않고, SYN segment의 Source/Destination IP address/ port number와 server만의 sercret number, 총 5개의 값의 hash function의 결과 값을 initial sequence number를 만든다. 이를 cookie라고 한다. 이 값을 SYNACK segment에 넣어 client 측에 보낸다. 이때 서버측은 cookie 값이나 SYN의 상태 정보를 저장하지 않는다.
- 정상적인 사용자라면 client 측에서 서버로 ACK segment를 돌려보낸다. 이때, ACK segment의 acknowledgement number - 1의 값이 이전에 보냈던 SYNACK segment의 cookie(=initial seqeunce number) 값이므로, ACK segment의 Source/Destination IP address/ port number와 server만의 sercret number로 다시 hash function을 돌린 뒤, 이 값이 ACK segment의 acknowledgment number - 1인지 비교하여, 해당 client가 이전에 통신한 사람이 맞는지 확인하고, 그 다음 서버의 자원을 할당하여 TCP 연결을 해준다.
- 이때, 만약 client측에서 ack가 돌아오지 않는다면, 잠시 뒤, TCP 연결을 종료하고, 이때 이전에 서버 자원 할당이 되지 않았으므로, SYN FLOOD ATTACK의 피해는 없게 된다.
3.6 Principles of Congestion Control
congestion control의 방법과, congestion의 원인, 증상 등을 알아보자.
3.6.1 The Causes and the Costs of Congestion
3가지 상황의 네트워크 혼잡 시나리오를 원인과 비용을 기준으로 알아보자
Scenario 1: Two Senders, a Router with Infinite Buffers
아래 그림처럼 HOST A, B가 각각 $\lambda_{in}\ bytes/sec$ 속도로 공통된 Router를 거쳐 데이터를 전송하고 있으며, 이때 router의 buffer는 무한대이고, outgoin link의 전송 속도는 최고 R 이라고 가정한다.
에러 조정이나 혼잡 제어, 흐름 제어 기능이 전혀 없고, 추가적인 header overhead 또한 존재하지 않은 이상적인 상황이라고 가정한다면,
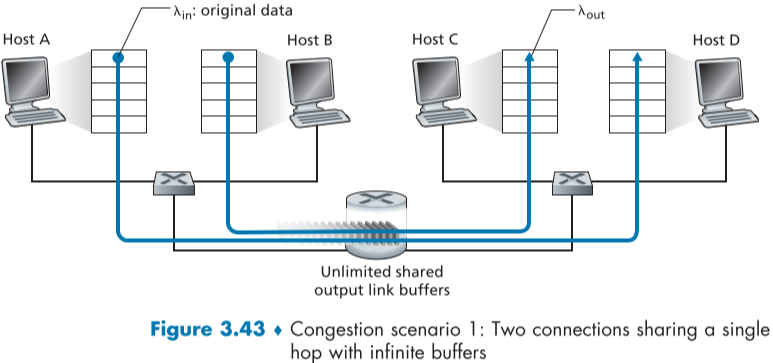
fig.3.44와 같은 그래프를 볼 수 있다.
왼쪽은 각 연결 별 throuhput 그래프이고, 오른쪽은 각 연결별 delay 그래프이다.
throuhput은 각 연결별 전송속도가 R/2에 가까울 수록 효율이 좋다. 두 호스트가 합쳐서 라우터의 최대 속도인 R을 100% 활용하기 때문이다.
하지만 delay 관점에서는 R/2에 가까워질 수록 패킷의 평균 delay가 무한대로 치솟는다. buffer가 무한대이므로 packet이 버려지지 않고, 계속 packet이 queue에 들어가는 속도가 나가는 속도보다 많아지면서 delay가 점점 증가하기 때문이다.
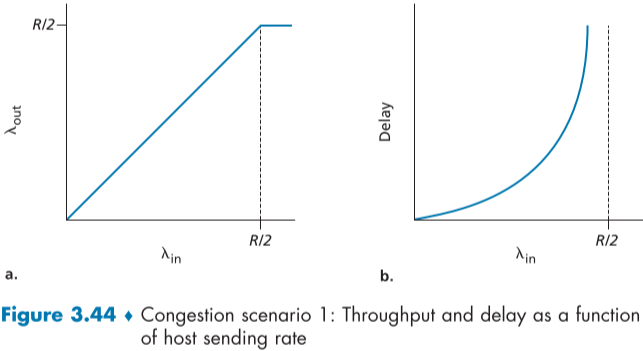
물론 무한대로 전송할 경우에 해당하는 delay이지만, 이상적인 상황임에도 불구하고 상당한 비효율을 보임을 알 수 있다.
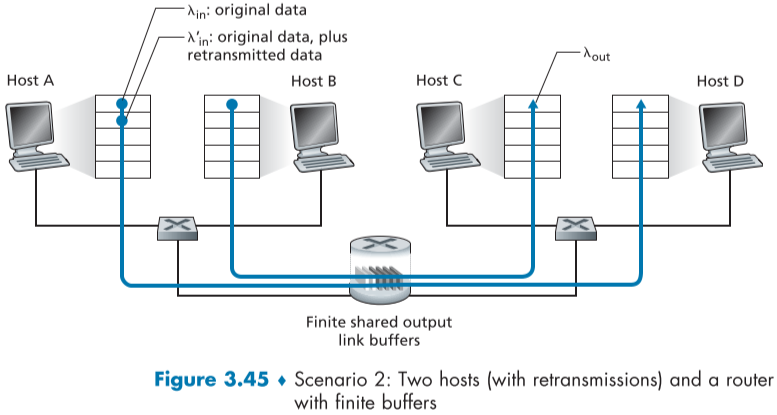
Scenario 2: Two Senders and a Router with Finite buffers
이번에는 위와 같은 상황이나 두가지 가정을 바꾸었다.
- router의 buffer 크기가 한정되있다.
buffer 크기를 넘은 packet은 queuing되지 않고 버려지게 될 것이다.
- 각 연결은 reliable data transfer로, packet이 손실되면 재전송을 시도할 것이다.
이때, 기존의 data transfer 속도와 재전송 packet의 전송 속도를 포함해서 $\lambda^{‘}_{in}$ bytes/sec 라고 하자.
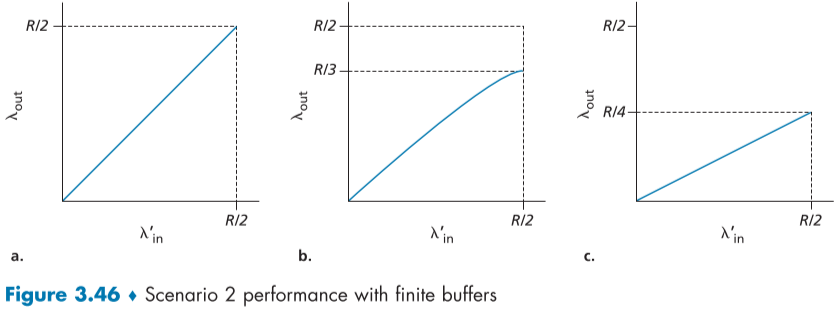
아래 그림의 (a)는 버퍼가 비어있을 당시만 재전송이 이루어질 때,
(b)는 packet이 손실됬다고 확실히 생각되는 것만 재전송이 이루어질 때,
(c)는 packet이 delay된것도 재전송이 이루어질 때의 그래프이다.
각각 최고속도가 R/3, R/4로 줄어드는 것을 알 수 있다.
왜냐하면, 손실된 packet 재전송 속도에도 속도를 할당 또는 손실되지 않고 제대로 간 packet도 손실됬다고 생각하고 전송 속도를 할당했기 때문이다.
Scenario 3 : Four Senders, Routers with Finite Buffers, and Multihop Paths
먼소린지 잘 모르겠음 ㅡㅡ
4개의 host가 다른 host와 2 hop 만큼 떨어져 통신하는 예제이다.
아래의 예제처럼 $\lambda_{in}$는 data throughput이고, $\lambda_{in}^{‘}$는 재전송 throughput을 포함한 throughput이다.
Host A-C 연결은 Host D-B 연결과 router R1을 공유하고, Host B-D 연결과 router R2를 공유한다.
$\lambda_{in}$ 가 충분히 작아 buffer overflow가 가끔씩 일어나며, throughput은 비슷한 부하를 제공한다.
$\lambda_{in}$가 조금 늘어나면, 그에 따라 throughput은 조금 늘어나고 여전히 buffer overflow는 가끔씩 일어난다.
즉 $\lambda_{in}$가 늘어나면, 그에 따라 $\lambda_{out}$도 늘어난다.
반대로 $\lambda_{in}$가 아주 큰 경우를 가정해 보면, R1과 R2를 거친 A-C 트래픽은 크기와 상관 없이 R1과 R2 사이의 최대 트래픽인 R이 최대치이다.
만약 B-D 연결의 $\lambda_{in}^{‘}$가 아주 크다면 B-D 연결의 R2에서의 지분이 A-C에서보다 커지게된다.
왜냐하면, B-D 연결 지분이 A-C 연결보다 더욱 많은 부하를 주며 더 많은 지분을 차지하게 되기 때문이다.
B-D 연결 지분이 계속 커지다보면 A-C연결의 지분은 0에 가까워질 것이다.
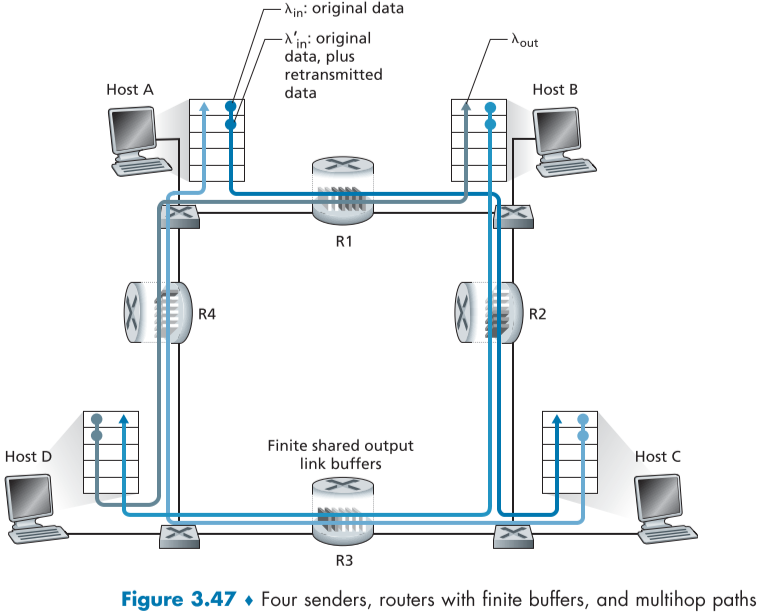
이러한 가정에 의한 결과 그래프는 아래와 같다.
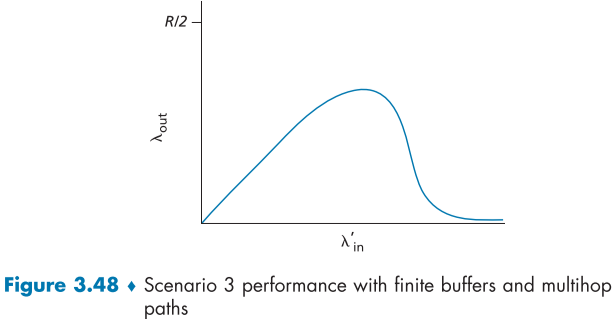
위와 같이 부하가 한계에 다다르지 않아도 throughput이 크게 줄어드는 이유는 한 router가 처리한 packet이 다음 router에서 버려지면 이전 router가 한 노력이 버려지는 꼴이기 때문이다.
이를 막기 위해 각 router는 packet 처리 우선순위를 두어, 여러 router를 지나왔던 packet에 우선순위를 주어 처리하는 방법을 고려할 수 있다.
여기서 우리는 네트워크의 혼잡에 의해 packet이 버려지면, 해당 packet을 처리하는데 사용한 이전 router들의 자원이 낭비된다는 것을 알 수 있었다.
3.6.2 Approaches to Congestion Control
실무에서 혼잡 제어를 위한 2가지 방법과 자세한 네트워크 구조와 혼잡 제어 protocol에 대해서 알아보자.
우리는 혼잡 제어 방법을 network layer에서 transport layer에 도움을 주냐 아니냐로 구분할 수 있다.
- End-to-End 혼잡 제어 : network layer에서 transport layer에 도움을 주지 않는 방법으로, TCP가 IP의 도움을 받지않게 할 수 있도록 선택한 방법이다. 주로 TCP segment의 손실(타임 아웃이던, dupliacated ack이던)을 네트워크 혼잡의 전조로 보고, window size를 줄여서 해결하며, 추가로 최근에는 segement의 RTT delay를 이용하는 방법도 있으며, 알아볼 것이다.
- Network 지원 혼잡 제어: router 측에서 network 혼잡 상태를 sender와 receiver에게 제공하는 방법이다. 단순히 하나의 bit로 제공하는 방법(IBM SNA, DEC DECnet, ATM network)도 있고, 좀더 복잡한 방법도 있다. ATM Avilable Bite Rate(ABR)의 혼잡 제어 방법의 경우, router 측에서 sender에게 outgoing link의 최대 sending rate를 알려주기도 한다. 대부분의 TCP/IP 구조에서 사용하진 않지만, 일부 서비스는 구현에 따라 사용하기도 한다.
- Network에서 혼잡 상태를 Host에게 알려주는 방법도 2가지가 있다. (fig.3.49)
- router 측에서 sender 측에게 직접적으로 packet을 보내 알려주는 방법(Direct network feedback): 이때 보내는 packet을 choke packet이라고 한다.
- rotuer가 sender가 보내는 packet의 field를 수정한 뒤, 이 수정된 packet을 받은 receiver측에서 sender측에게 혼잡 상황을 알리도록 하는 방법(Network feedback via receiver): 좀더 자주 사용되는 방법이며, delay가 RTT 시간 만큼 걸린다.
- Network에서 혼잡 상태를 Host에게 알려주는 방법도 2가지가 있다. (fig.3.49)
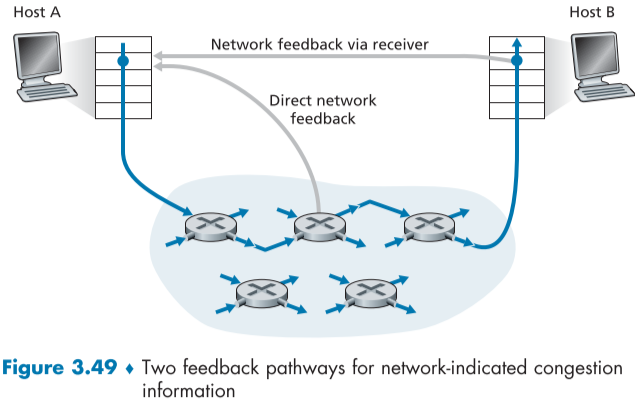
3.7 TCP Congestion Control
TCP는 위에서 설명한 IP 측의 도움을 받지 않는 End-to-End 제어를 이용하는 방식이 일반적이지만, 최근에는 2번째의 IP측의 도움을 받는 방법도 사용한다.
먼저 classic한 혼잡 제어 방법 그리고, 최근의 혼잡 제어 방법을 알아보고, 마지막으로 혼잡한 상황의 network 의 자원을 공평하게 나누는 것에 대한 transport 층의 어려움을 알아보자.
3.7.1 Classic TCP Congestion Control
TCP는 각 sender 측이 네트워크 혼잡 정도에 따라 전송량을 줄이게끔 하는 방법을 사용하고 있다.
여기서 세가지 궁금증이 생기는데,
- TCP sender 측은 어떻게 전송량을 줄이는가?
- TCP sender 측은 어떻게 receiver 측과 사이의 network 혼잡을 알 수 있는가?
- TCP sender 측은 network 혼잡에 따라 얼마나 전송량을 줄여야 하는가?(또는 이를 위한 알고리즘은 무엇인가?)
이에 대해 알아보자.
우리는 이전에 TCP 연결을 위해 receive, send buffer, LasyByteRead, rwnd 같은 여러가지 connection state가 필요하다고 배웠다.
여기에 추가로 TCP 혼잡 제어를 위해 congestion window(cwnd)를 이용한다.
cwnd는 TCP sender에게 traffic의 한계를 제한하는데, 구체적으로 sender측에서 ack되지 않은 데이터의 양을 cwnd와 rwnd 사이 값으로 제한한다.
$LastByteSent-LastByteAcked\leq \min{cwnd,\ rwnd}$
먼저, 흐름 제어를 제외하고 혼잡 제어 측면만 보기 위해 몇가지 가정을 하자면,
TCP receiver buffer는 충분히 커서 receive-window의 제한은 무시할수 있으며, sender 측의 ack 되지 않은 data의 양은 cwnd에 의해 제한되며, sender 측은 언제나 receiver 측에 보낼 데이터가 있다고 가정한다.
loss와 packet transmission delay(router가 packet을 적절한 outer link에 적재하는 시간)가 무시할 만큼 적을 때, 매 통신의 왕복시 마다, sender는 갱신된 cwnd bytes 만큼만 보낼 수 있다. 즉, $cwnd/RTT\ bytes/sec$만 보낼 수 있는 것이다.
먼저 congestion이 일어나지 않은 이상적인 상황을 생각해본다면, TCP 연결은 ack segment가 도착할때마다, congestion window size(cwnd)의 크기를 늘린다. 만약 어떤 이유로 ack segment가 도착할 때까지의 delay가 발생한다면, 해당 delay 만큼, congestion window size가 증가의 속도가 늦춰질 것이다.
TCP는 이렇게 ack segment가 도착할 때마다 congestion window size를 늘리는 행동을 발현(clock, triagger)하며 이를 self-clocking라고 한다.
그렇다면 도착할 때 마다 어떤 속도로 올려야 할까? 너무 빠르면 congestion을 유발할 것이고, 너무 느리면 비효율적일것이다.
이런 것을 정하기 위해 TCP는 이러한 기본 가이드라인을 따른다.
- segment가 손실됨은 혼잡함을 의미하므로, segment가 손실되면 전송 속도를 낮춰야한다.
- acknowledged segment가 도착함은 성공적으로 통신이 됬음을 의미하며, ack가 도착하면 전송 속도를 늘려야한다.
- 대역폭 측정(Bandwidth probing), 각각의 ACK와 loss는 네트워크 혼잡의 신호로 사용된다. 보통은 loss가 생기기 전까지 천천히 올리다가, loss가 생기면 전송속도를 늦추는 방식을 사용한다. 이러한 과정은 네트워크 내의 TCP간에 비동기적으로 실시된다.
이러한 가이드라인으로 TCP congestion-control algotrithm이 탄생하였다. [Jacobson 1988, RFC 5681]
이 알고리즘은 크게 (1) slow start, (2) congestion avoidance, (3) fast recovery 세 부분으로 나뉘어져 있다.
특히, (1), (2)는 TCP에 필수적으로 사용되며, (3)은 추천되는 부분이다.
Slow Start
TCP 연결 시작시, cwnd의 값은 1 MSS라는 작은 값으로 시작한다. MSS가 500bytes, RTT가 200msec라면, 초기 sending rate는 20kbps이다.
이후, slow-start 상태가 되어, 보낸 segment에 첫 acknowledgement가 돌아올 때마다 1 MSS 씩 늘리게 된다.
아래 그림의 예시를 보면 첫 ack가 도착하면 2개의 segment를 보내고, 그 뒤에 2개가 도착하면 4개를 보내는 것을 알 수 있다.
이를 통해 slow-start 상태에는 매번 손실이 없다는 가정 하에, 2배씩 전송량을 늘리는 것을 알 수 있다.
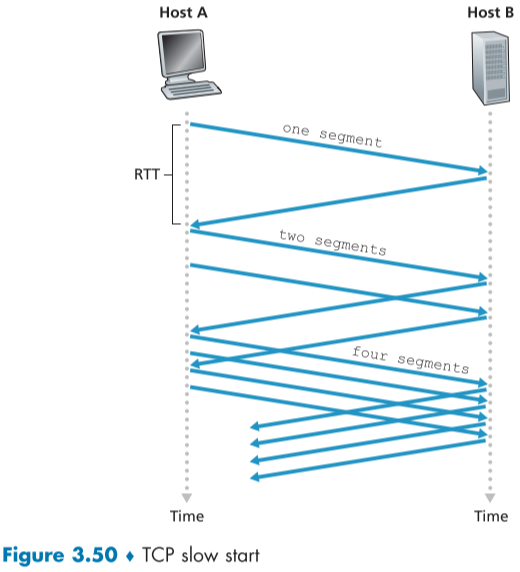
이러한 slow start 상태를 끝내는 이유는 총 3가지가 있다.
- timeout에 의한 loss event 발생 : 즉시 ssthresh(slow start threshold)라는 값을 현재 cwnd/2로 설정하고, cwnd 값을 1 MSS로 바꾸고 다시 slow start 시작
- 증가하던 cwnd값이 ssthresh 이상의 값의 됨 : 2배씩 늘리던 slow start 상태에서 벗어나 아래 설명할 congestion avoidance 상태로 바뀐다.
- Three duplicate ack에 의한 loss event 발생 : TCP의 fast retransmission 활동 후 아래에 설명할 fast recovery 상태로 전환
Congestion Avoidance
congestion avoidance 시기에 들어가면 cwnd는 2배가 아니라 1 MSS 씩 상승한다.
구체적으로 예시를 들자면, 만약, MSS가 1460bytes, cwnd 14600bytes 였다면, 이전에 10개의 segment를 보냈다는 의미이며, ack segment가 하나 도착 할때마다 1/10 MSS, 즉 146 byte씩 cwnd를 증가시킨다.
이러한 선형 cwnd 증가인 Congestion Avoidance 상태는 이후 loss를 만나면 slow start 때와 같이 ssthresh에 현재 cwnd/2값을 저장하고 1MSS로 바꾸고 slow start 상태로 바뀐다.
만약 3 duplicated ack로 인해 loss를 측정했다면, ssthresh를 cwnd의 절반으로 기록하고, cwnd를 1 MSS가 아닌 절반+3MSS(duplicated ack로 인해 상태 변화 됬음을 알리기 위해 더함) 으로 바꾼 뒤, 아래의 fast-recovery 상태로 바뀐다.
아래는 TCP congestion control의 FSM이다.
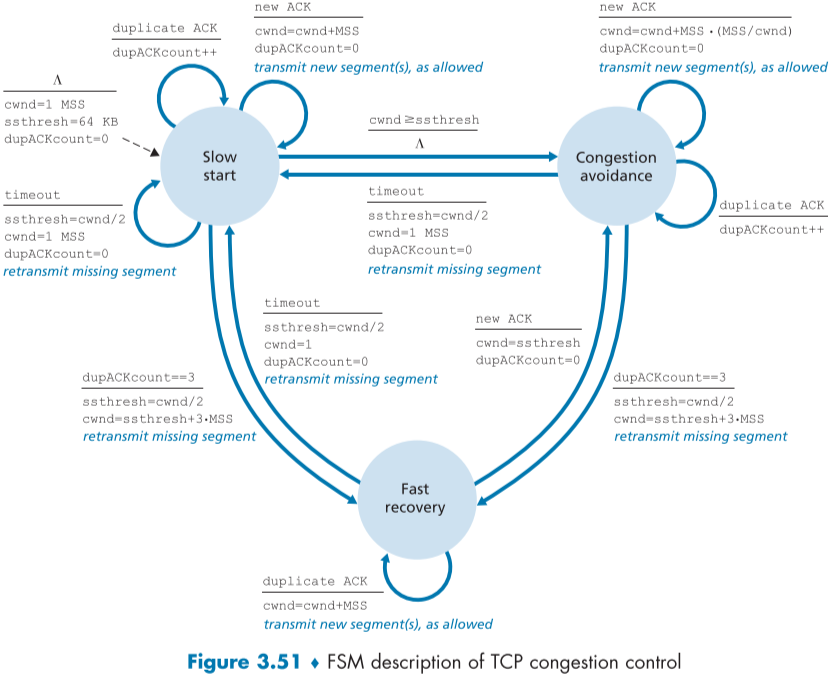
Fast Recovery
fast recovery에서는 fast-recovery에 들어가게 유발한 동일한 segment에 대한 duplicated ack 하나당 cwnd 값이 1 MSS 씩 상승한다.
예를 들어, cwnd가 12이고, duplicated ack가 3개 들어왔다면, 12/2 + 3 = 9로 cwnd가 시작된다.
이때 cwnd값만 그러하고, ssthresh값은 여전히 이전 값 그대로이다.(cwnd의 절반 값으로 fast recovery를 시작했었다.)
만약, Fast Recovery 상태에서 fast retransmission으로 손실된 걸로 판단한 segment에 대한 Ack가 들어온다면 cwnd 값을 ssthresh 값으로 바꾼 뒤, congestion avoidance 상태로 들어간다.
만약, Fast Recovery 상태에서 Timeout이 일어난다면, 평소와 같이 ssthresh는 cwnd/2로, cwnd는 1 MSS로 바꾼 뒤 slow-start 상태로 변경된다.
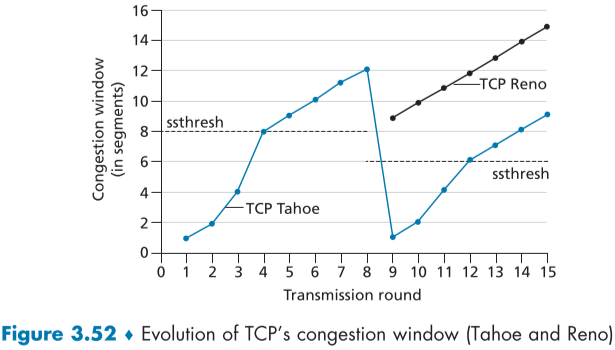
fast recovery는 TCP 구현에 있어 추천되지만, 필수는 아니며, 초기버전 TCP인 TCP Tahoe의 경우, Timeout, Duplicated ACK 둘다 관계없이 slow-start 상태로 들어가지만, 좀더 최신 버전인 TCP Reno의 경우 fast recovery가 구현되어있다.
아래 Fig.3.52를 보면 TCP Reno와 TCP Taho를 비교할 수 있다.
(8라운드에 duplicated ack가 3개 들어왔다는 가정이며, 검정색 Reno의 9라운드 이전 그래프는 Tahoe와 같은 그래프이다.)
TCP Splitting을 이용한 cloud service 성능 향상
많은 서비스들이 클라우드의 서버를 이용해 사용자들에게 서비스를 제공한다.
양질의 서비스를 제공하기 위해 빠른 응답이 필요한데, 이때, 해당 서버와 사용자간의 거리가 멀면 화면을 보여주는게 너무 느려지곤 한다.
예를 들어, 검색 결과 정보의 크기가 보통 TCP 연결의 window 사이즈의 3배 만하다고 가정하면, 사용자는 서버측에 정보를 얻기 위해 TCP 연결 1번 + 3번 segment 왕복에 의해 총 4RTT 만큼의 시간을 기다려야 한다.
이는, 서버가 가까울 대는 상관없지만 멀면 아주 긴 시간을 기다려야 할 것이다.
이를 막기 위해 1. Frontend server를 사용자에게 가까이 둘것, 2. TCP splitting을 이용할 것 을 통해 해결할 수 있다.
TCP splitting은 client는 가까운 Front-end 서버에 요청을 하고, Front-end 서버는 영구 지속 TCP 연결을 backend 서버와 연결하면서, 높은 MSS의 연결망을 이용해 backend와 연결하면 Window size를 크게 유지할 수 있다.
기존에 4RTT가 걸리던 검색 결과가, $4RTT_{frontend}+1RTT_{backend}+processing\ time$ 만큼 걸리게 된다.
유저와 frontend가 충분히 가까우므로 앞의 부분을 0으로 무시하고, processing time 또한 생략하면 1RTT 만큼의 시간이 걸리게 된다.
이렇게 TCP 연결 하나 짜리를 여러개로 나누는 것을 TCP spliiting이라고 한다.
이러한 TCP splitting은 안정적이고 성능좋은 연결이 추가되고, 기존의 client-frontend 구간은 짧아져 segment 손실이 적어 retransmission rate로 낮아지는 효과가 있다.
현재 여러 CDN과 cloud service가 제공하고 있다.
TCP Congestioini Control: Retrospective
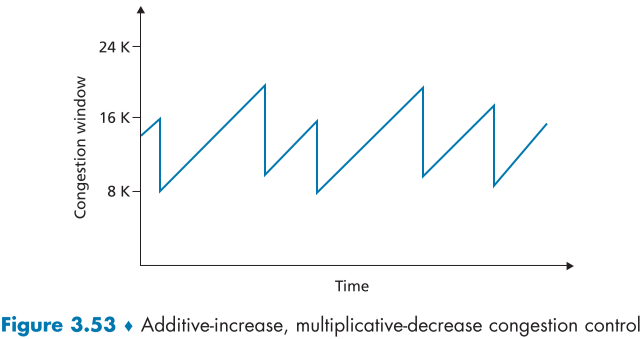
시작시 slow-start 상태로 시작 하지 않고, cwnd가 선형으로 1MSS 씩 증가하며, triple duplicate ack로 인한 loss로 cwnd가 절반으로 줄어든다고 가정하면, 아래와 같이 톱니 모양의 그래프가 나오는데 이러한 이유로 additive-increase, multiplicative decrease(AIMD) 형태의 혼잡제어라고 불리운다.
선형으로 증가하며 가능한 최대의 window 크기를 찾다, 혼잡이 야기될 것 같으면 절반으로 줄어들며 최적의 대역폭을 찾는 모양새이다. 이러한 AIMD 알고리즘은 이후, 수많은 공학적 시야와 실험을 통해서 꽤나 효과적임이 검증되었다.[Kelly 1998, Srikant 2012].
TCP Cubic
앞선 TCP Reno의 AIMD의 cwnd를 절반으로 줄이는 방법, 심지어 아예 1MSS 줄이는 초기버전 TCP Tahoe 등이 너무 조심스럽게 접근하는 것은 아닌가 하는 생각이 들 수 있다. 이전에 혼잡하지 않은 경계선까지는 빠르게 접근한 뒤, 이후로 천천히 증가하는 편이 효율적여 보인다.
이러한 생각으로 만들어진 것이 TCP CUBIC인데, TCP Reno와의 차이점은 congestion avoidance 상태가 다음과 같이 다른다.
- $W_{max}$가 혼잡이 관측되는 최대 cwnd라고 하고, K를 TCP CUBIC의 window 크기가 loss 관측없이 $W_{max}$에 도달하는 시간이라고 하자. K는 여러 변수의 변화에 따라 바뀔 수 있으며, 짧을 수록 좋다.
- CUBIC 에서는 cwnd의 증가속도를 현재 시간 t와 K 사이의 거리의 세제곱에 비례하여 설정한다. 즉, $W_{max}$에 멀수록 급격하게 증가하며, 가까울수록 천천히 증가하여 $W_{max}$에 가까울 수록 조심해진다
- 만약 loss가 관측되지 않은 채로 시간 t가 K 보다 커지게 되면, CUBIC은 cwnd를 급격하게 증가시켜 새로운 congestion 한계를 탐색하게 된다.
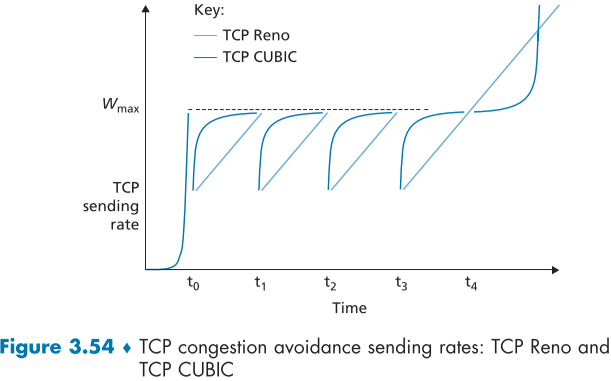
위 fig.3.54를 보면, Reno와 CUBIC를 비교할 수 있으며, Reno의 경우가 좀더 효율적임을 알 수 있다.
현재 실무에서는 TCP CUBIC을 Reno보다 좀더 선호한다.
Macroscopic Description of TCP Reno Throughput
TCP Reno에서의 평균적인 전송량(average throughput)을 알아보자.
먼저 timeout으로 인한 slow-start 상태는 전체 상태 중에 아주 짧은 시간만 지속되므로 무시한다.
window size를 w bytes, 이라 할때 TCP의 전송속도는 w/RTT이며, 매 RTT마다 w를 1 MSS씩 상승시켜 loss를 찾게 된다.
W를 loss가 생긴 뒤의 w 값이고 거의 일정하다고 가정할 때, TCP의 transmission rate는 W/(2RTT) ~ W/RTT 사이이다.
loss event가 발생하면 시간이 W/RTT로 줄어들며, 매 RTT 마다 1MSS/RTT 만큼 증가하며 이를 계속 반복한다.
이를 통해 다음과 같은 식을 알 수 있다.
$average\ throughput\ of\ a\ connection = \frac{0.75\cdot W}{RTT}$
이를 통해서 loss rate와 가능한 bandwidth에 관한 식도 도출할 수 있다.
3.7.2 Network-Assisted Explicit Congestion Notification and Delayed-based Congestion Control
최근에는 IP와 TCP 기능이 확장되면서 network가 TCP sender과 receiver에게 직접적으로 혼잡 상태를 신호할 수 있게 되었고, 추가로 packet delay를 이용해 혼잡 제어가 가능한 방법도 제안되었다.
Explicit Congestion Notification
Explicit Congestion Notrification(ECN)[RFC 3168]은 TCP, IP가 함께 연관된 인터넷에서 사용되는 네트워크 지원 혼잡 제어의 한 형태이다.
network layer의 packet인 IP datagrame의 header에 Type of Service field에 2bit(0~3, 총 4가지 표현)을 통해 혼잡 관련 정보를 알릴 수 있다.
ECN bit의 첫번째는 해당 router가 혼잡을 겪고 있는가에 대한 표시로 사용된다. 이를 표시하여 recevier 측에 혼잡을 알리고, sending host에게도 알리도록 만든다. 이러한 혼잡 상황은 RFC 문서에 정의되지 않았으므로 router 별로 서비스 제공자가 판단하여 설정해줘야 하며, 보통 loss가 발생하기 직전을 혼잡 상황으로 놓는다.
ECN bit의 2번재 bit는 router에게 sender-receiver host가 ECN을 지원함을 알리는 bit 이다.
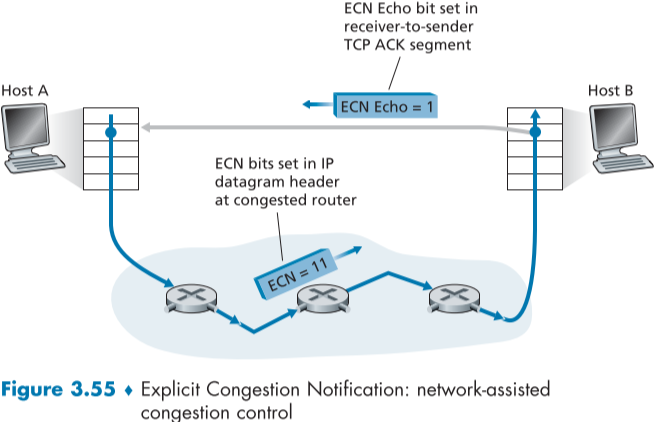
위의 Fig.3.55에서 예시를 보자면, TCP의 receiver 측에서 ECN bit가 혼잡으로 설정되어 있는 datagram을 받으면, receiver 측은 sender측에게 TCP header의 ECE(Explicit Congestion Notification Echo) bit를 ACK segment에 넣어 알려준다. sender 측은 이를 확인하고, cwnd를 절반으로 줄이고, 다음에 보낼 예정인 TCP segment header의 CWR(Congestion Window Reduced, CWR 줄였음) bit를 1로 넣는다.
TCP를 계승한 다른 transport-layer 프로토콜들 또한 ECN을 활용한다. Datagram Congestion Control Protocol(DCCP)의 경우, ECN을 활용해 적은 오버헤드, 혼잡 제어, UDP 같은 비신뢰성 데이터 통신을 제공한다. DCTCP(Data Center TCP)와 DCQCN(Data Center Quantized Congestion Notification) 또한 ECN을 이용하며, 최근에는 많은 서버들이 ECN을 지원한다.
Delay-based Congestion Control
packet loss가 일어나기 전에 혼잡을 탐색할 수 있는 또 다른 방법은 packet의 delay를 이용하는 것이다.
TCP Vegas에서 sender 측은 모든 acknowledged된 segment의 RTT를 측정한다. 이때 최소 RTT(=가장 빨리 돌아온 segment의 RTT)를 $RTT_{min}$라고 하자.
이는 네트워크 경로가 혼잡하지 않고, queuing delay가 가장 적었음을 의미한다. 이때의 congestion window size를 cwnd라고 할 때, throughput은 cwnd/$RTT_{min}$이라고 하며, 아마 다른 RTT에 비해 가장 큰 값일 것이다.
만약 현재의 측정되고 있는 RTT가 $RTT_{min}$에 가까워진다면, 네트워크의 상황이 좋다는 의미이므로 cwnd를 늘려도 되며, 반대로 점점 멀어진다면 혼잡해가고 있다는 의미이므로 cwnd를 줄이게된다.
자세한 사항은 [Brakmo 1995]에서 알 수 있다.
TCP Vegas는 “keep the pip just full, but no fuller” 원칙에 따라, 최대한 자원을 활용하되 bottlenet link의 역량을 넘어서지 않게끔 설계되었다.
BBR 혼잡 제어 protocol[Cardwell 2017]은 TCP Vegas에서 아이디어를 얻어 BBR을 지원하지 않는 TCP sender들과도 공평하게 경쟁할 수 있게 끔 설계되었다.
Google은 사적인 B4 network에서 CUBIC을 BBR로 대체하였다. 이외에도 TIMELY, Compound TCP(CTCP), FAST 등의 dealy based TCP congestion control protocol이 존재한다.
3.7.3 Fairness
K 개의 TCP 연결이 최대 전송속도가 R인 link를 공유한다면, 가장 이상적인 각각의 전송속도는 R/K일 것이다. 하지만 우리가 사용하는 TCP의 AIMD 알고리즘이 정말 그러한 공평함을 제공할 것인가?[Chiu 1989]
이를 알아보기 위해 가정을 하나 해보자.
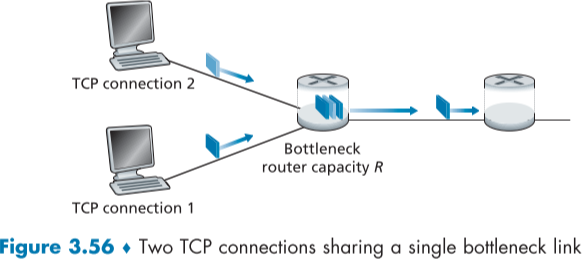
아래 그림 fig3.56처럼 두개의 같은 MSS와 RTT를 가진 TCP 연결이 하나의 link를 공유하며 이때의 병목 router의 최대 전송속도는 R이다. 다른 TCP, UDP 연결 등은 존재하지 않으며, slow-start state는 무시하고 언제나 CA mode(AIMD)로 동작한다고 하자.
이들의 이상적인 전송속도는 R/2일 것이다.
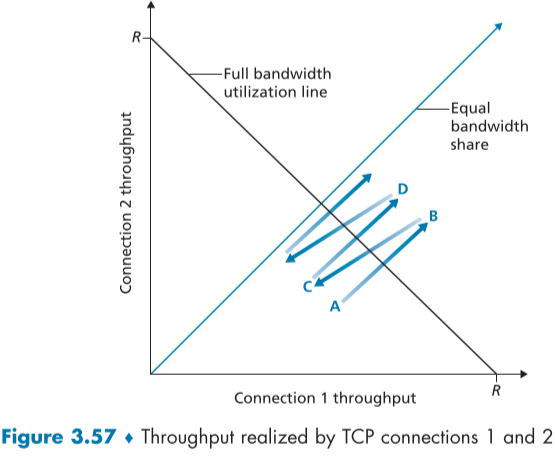
두 TCP 연결의 throughput에 대한 그래프로 표현하자면 아래 fig.3.57이며, 이상적인 상황은 최대한 자원을 활용하면서(검은색), 동일한 자원이 분배되는(파란색) 정 가운데 교차점 부분이다.
만약 불공평한 지점 A에서 시작한다면 두 TCP 연결은 서로 서서히 같은 비율로 (1MSS) cwnd를 올릴 것이고, 결국 최대 활용 가능 지점(검은색 선)을 넘어 B로 이동할 것이다.
B로 이동한다면, 두 TCP 연결은 loss를 관측할 것이고, 이에 따라 둘다 절반으로 cwnd를 줄여 C지점으로 이동할 것이다. 이때 중요한 점은 더욱 큰 cwnd(=더욱 빠른 전송속도)를 가지던 TCP 연결이 절대값으로 더욱 크게 전송속도가 깎인다는 점이다.
C지점에서도 두 TCP 연결은 A지점같이 행동하며, cwnd가 줄어든 비율은 다르지만, 오르는 cwnd량(1MSS)은 같으므로, 이를 무한히 반복하다보면 결국에 공평한 지점에 도달하게 된다.
| time round (loss ocurred over 15)(add 1MSS/sec) | 1 | 2(loss) | 3 | 4 | 5(loss) | 6 | 7 | 8 | 9 | 10(loss) fair point | 11 | 12 | … |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TCP 1 (start cwnd 9)(unit: MSS) | 9+1 | (11+1)/2 = 6 | 6+1 | 7+1 | (8+1)/2 = 4 | 4+1 | 5+1 | 6+1 | 7+1 | (8+1)/2 = 4 | 4+1 | 5+1 | … |
| TCP 2 (start cwnd 4)(unit: MSS) | 4+1 | (6+1)/2 = 3 | 3+1 | 4+1 | (5+1)/2 = 3 | 3+1 | 4+1 | 5+1 | 6+1 | (7+1)/2 = 4 | 4+1 | 5+1 | … |
이는 그래프 어느 지점에 시작해도 같은 결과가 나온다!
하지만 이러한 결과는 이상적인 상황에서만 그러하며, 실제로는 application의 병렬 TCP 연결 요청, UDP packet, RTT의 차이(작은 RTT일 수록 빠르게 대역폭을 선점하여 전송 속도를 더욱 크게 가져가는 경향[Lakshman 1997]) 공평하게 공유하지 않는다.
Fairness and UDP
혼잡 제어에서 벗어난 일정한 전송속도가 필요하고, packet loss를 피하기 위해 전송속도를 제한하는 것보다 차라리 packet이 loss 되도록 하는 것이 좋다고 생각하는 많은 multimedia application 들은 TCP 대신 UDP를 사용한다.
이로 인해 TCP 혼잡제어가 힘들어지고, 심지어 UDP가 많아지면 TCP는 완전히 통신 불가할 수도 있다.
이러한 UDP의 불공정성을 막기 위해 여러가지 연구가 이루어지고 있다.[Floyd 1999, Floyd 2000, Kohler 2006, RFC 4340]
Fairness and Parallel TCP Connections
만약 UDP의 불공정성을 막는다고 해도 불공정성이 완전 해결되지 않는데, TCP 베이스 application 들이 TCP 연결 분배기(TCP Connection splitter)를 이용해다중 병렬 연결(multiple parallel connection)을 이용하면 연결 수에 비례하여 한 호스트가 더욱 많은 비율의 대역폭을 가질 수 있다.
예를 들어 10개의 Host가 각각 1개의 TCP 연결을 가지는 대역 R의 link의 경우 R/10 씩 대역폭이 할당되지만, 만약 11번째 사람이 10개의 TCP 병렬 요청을 하면 해당 사람이 전체의 R/2의 대역폭을 가지고 나머지 10사람이 R/10으로 줄어들게 된다.
이러한 다중 병렬 연결은 주로 웹 브라우저가 여러 object들을 동시에 가져올 때 많이 사용한다.
3.8 Evolution of Transport-Layer Functionality
UDP와 TCP가 대세이고, 이 둘에 대해서만 알아봤지만, 네트워크의 발달에 따라 이 둘에 맞지 않은 서비스를 제공하기 위해 새로운 protocol, 개량된 protocol 또한 개발되었다.
현재 웹에서 가장 인기 있는 TCP는 CUBIC과 CTCP이지만, 무선 환경을 위한 TCP, 고성능 네트워크을 위한 TCP, Data center를 위한 TCP 등 여러가지가 있다.
심지어 packet acknowledgement 방법이나 3 way handshake 방법이 다른 TCP 등 우리가 공부해왔던 “TCP”의 특징이 전혀 다른 TCP도 많으며, 사실, TCP라고 이름 붙인 protocol들의 공통점은 같은 TCP segment format을 공유한다는 점과, 그들간에 공평하게 경쟁한다는 점뿐이다.
QUIC: Quick UDP Internet Connections
만약, TCP의 잡다한 기능이 필요없거나 조금 다른 기능이 필요하지만, UDP 처럼 아무런 기능이 없으면 안되는 새로운 protocol로 application service를 만들고 싶다면 QUIC(Quick UDP Internet Connection)[Langley 2017, QUIC 2020]이 제격이다.
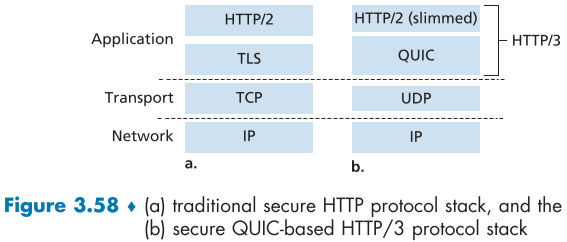
QUIC는 UDP를 기반으로 만들어졌으며, 간편화된(slimed) HTTP/2, secure HTTP를 위해 고안된 더욱 성능이 좋고 application layer protocol(transport가 아님을 주의!)이다.
이미 구글 등 여러 웹 서비스에서 사용중이며, 데이터 신뢰성 전송, 혼잡 제어, 연결 관리 등의 기능을 가지고 있다.
아래는 현재 TCP 기반 웹과 QUIC 기반과 간단화된 HTTP/2를 이용한 HTTP/3 버전의 웹의 구조 비교이다.
HTTP/3에서도 사용 예정인 QUIC의 주요 기능은 다음과 같다.
- 연결 중심, 보안성
- TCP와 마찬가지로 QUIC는 통신 이전에 호스트간의 연결과 handshake가 필요하다. 이때 이 연결을 구별하는 수단은 source와 destination connection ID로 구별하며, 모든 packet들은 암호화되며, handshake 과정에 인증 과정과 암호 과정이 있다.
- 또한 이전에 사용한 TCP, TLS connection 과정중에 많은 RTT가 필요했던 TCP, TLS 구조보다 더욱 빠른 연결을 자랑한다.
- 데이터 흐름(Streams)
- QUIC는 한 연결 안에 application 레벨의 multiplxed(다중화)될 수 있는 데이터 흐름을 제공한다. 이러한 데이터 흐름은 연결이 생성된 후 빠르게 추가할 수 있으며, 각 데이터 흐름은 양 QUIC Host간의 데이터 신뢰(reliable), in-order(패킷 순서가 맞는), bi-directional(양방향 통신)을 제공한다.
- Web으로 따지면 각 object(사진, 영상, 글, 등)마다 데이터 흐름을 생성할 수 있으며 각 Connection이 connection ID로 구분 되듯이, 각 stream은 stream ID로 구분할 수 있고, 이 두 ID가 QUIC packet header에 적히게 된다. 크기가 작다면 UDP 기반의 segment에 여러 데이터 흐름의 데이터가 적재될 수도 있다.
- 이는 4G/5G 망에 자주 사용되는 Stream Control Transmission Protocol(SCTP)에서 이 먼저 고안한 방법이다.
- 데이터 신뢰, TCP-friendly, 혼잡제어 데이터 전송
- 아래 fig.3.59와 같이 QUIC는 각 데이터 흐름마다 데이터 신뢰성을 보장한다.
- fig.3.59(a)의 HTTP 같은 경우, 하나의 TCP connectino에서 여러 request가 보내지면서, 신뢰성과 동시에 순서의 정합성을 보장해야했다. 그래서 request packet 하나가 손실되면, 해당 손실된 packet이 다시 재전송될 때까지 이후 순서의 packet들은 기다려야 했다(HOL blocking problem).
- 하지만 QUIC는 각 stream마다 순서의 정합성을 보장하므로, 여러 stream을 열어놓고 하나의 stream이 손실되면 다른 stream은 미리 적재되고 application 측에 전달될 수 있다.
- QUIC는 TCP와 비슷한 acknowledgment 메커니즘으로 데이터 신뢰성을 보장한다.
- QUIC의 혼잡제어는 TCP NewReno를 기반으로 조금의 변경을 가해서 만들었으므로, loss detection가 congestion control algorithm이 TCP와 비슷하다.
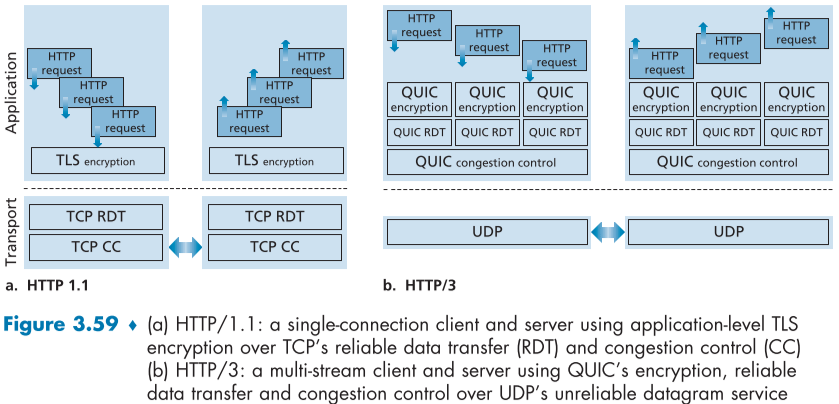
QUIC의 주목할 점은 application layer임에도 reliable data transfer와 congestion controll을 제공한다는 점이다. QUIC의 개발자는 이러한 변화가 TCP, UDP 보다 더욱 빠르게 application data를 업데이트 할 수 있다고 한다.
3.9 Summary
_articles/computer_science/network/네트워크 정리-Chap 3-전달 계층.md