풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
네트워크 정리-Chap 2-응용 계층
- 2.1 Principles of Network Applications
- 2.1.1. Network Application Architectures
- 2.1.2. Processes Communicating
- The Interface Between the Process and the Computer Network
- 2.1.3. Transport Services Available to Applications
- 2.1.4. Transport Services Provided by the Internet
- 2.1.5 Application-Layer Protocols
- 2.1.6 Network Applications Covered in This Book
- 2.1.1. Network Application Architectures
- 2.2 The Web and HTTP
- 2.3 Electronic Mail in the Internet
Computer Networking: A Top-Down Approach(Jim Kurose, Keith Ross)의 강의를 정리한 내용입니다.
( Jim Kurose Homepage )student resources : Companion Website, Computer Networking: a Top-Down Approach, 8/e
Chapter 2. Application Layer
페이스북, 웹 메일, 인터넷 쇼핑, MMORPG, 뉴스 웹사이트 등 수많은 인터넷 어플리케이션의 덕분에 많은 사람이 필요성을 느끼고 인터넷을 사용하면서 커다란 규모를 이루게 되었다.
이번 챕터에서는 network application layer의 개념과 구현 측면으로 바라보며, Web, e-mail, DNS, P2P file distribution, video streaming을 살펴보고 TCP와 UDP, Socket interface에 대해서 알아본다.
2.1 Principles of Network Applications
각 Application은 다른 end system의 application과 소통하여 서비스를 제공한다.
이때, Application layer가 구현되어 있지 않은 end system이나, 다른 host의 하위 Layer의 프로그램들과는 소통할 수 없다.
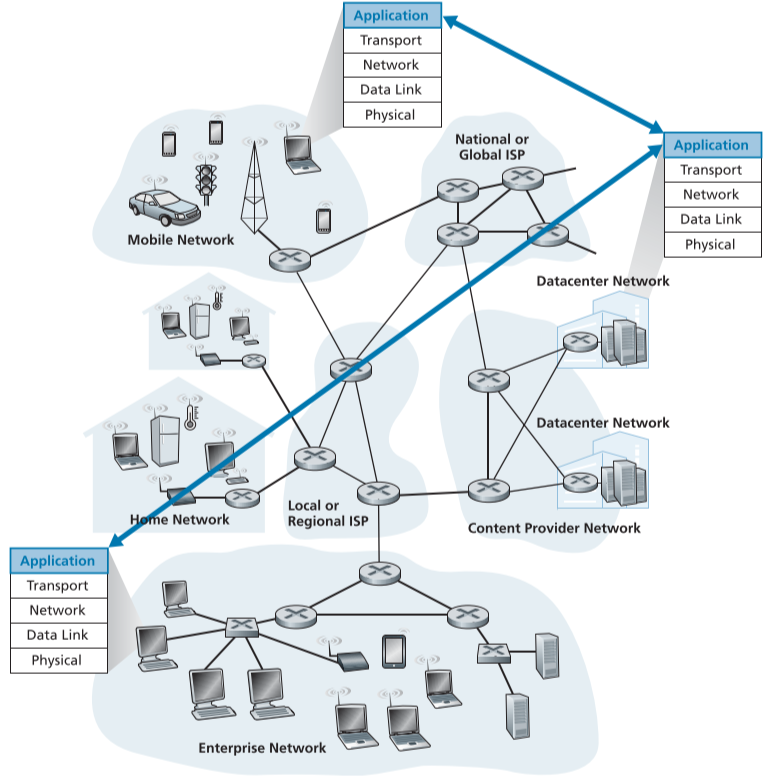
2.1.1. Network Application Architectures
Application 계층의 구조는 Network 전체의 구조인 기존의 5계층과는 다르며, 비교적 좀더 유연한 선택이 가능하며, 정형화되지 않은 서비스를 제공한다.
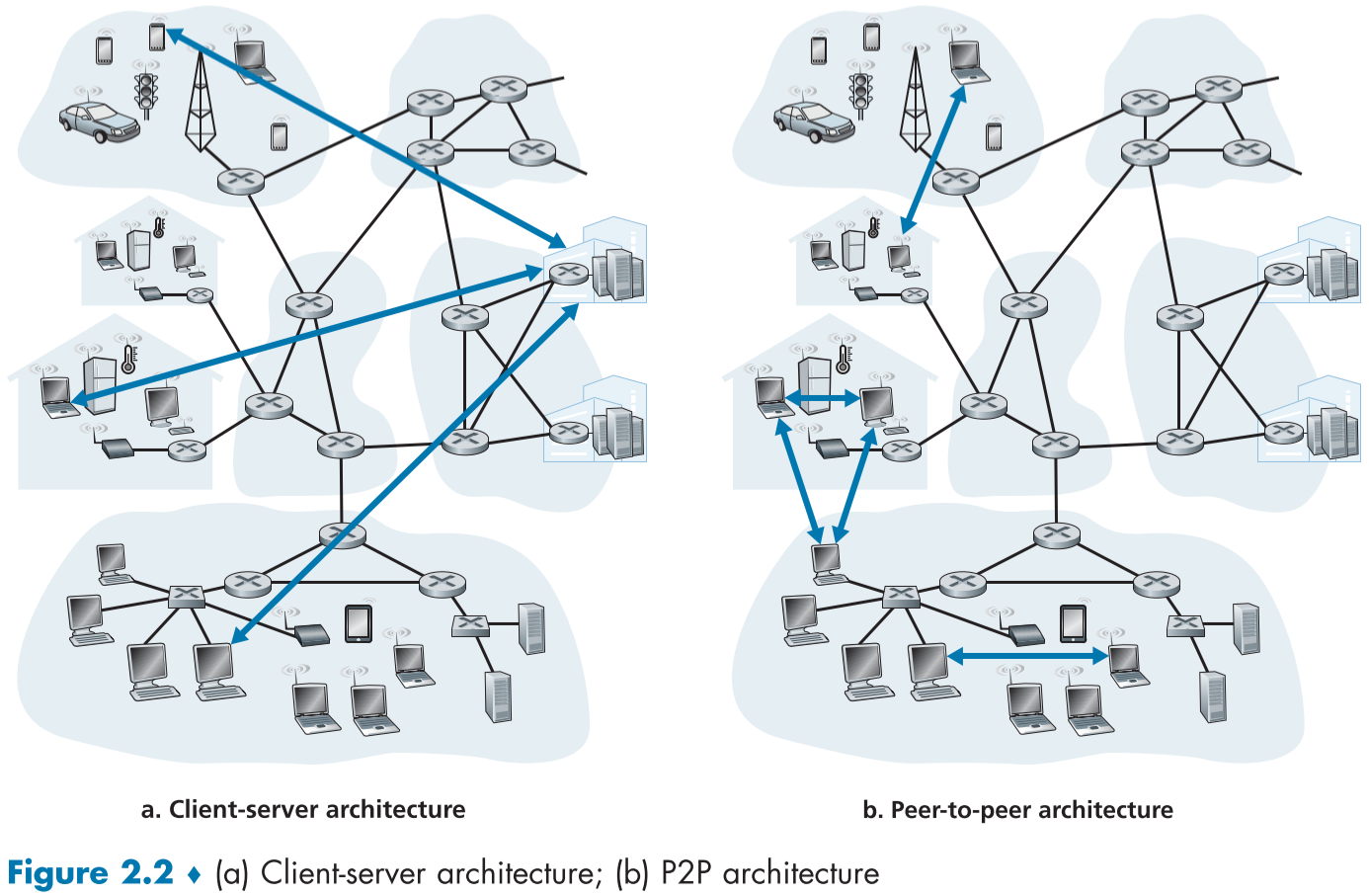
예를 들어, Application의 End system 간의 통신 구조는 크게 2가지로 나뉜다.
- Client-server architecture : client의 요청에 응답해주는 언제나 켜져 있으며, 고정된 주소값을 가진 server와 사용자로부터 요청을 받아 처리하고 서버에서 결과를 받아 다시 사용자에게 반환해주는 client로 나뉜다.
- 절대로 client 간은 통신하지 않으며, FTP, Web, Telnet, e-mail 등이 존재한다.
- 하나의 서버로는 수많은 요청을 처리할 수 없으므로, 보통 Data center에 수많은 서버를 생성해서 서비스하며, 이때 연결과 bandwidth 유지를 위한 막대한 유지비가 든다.
- P2P(peer-to-peer) architecture : dedicated server를 거의 또는 전혀 사용하지 않고, 사용자의 host(컴퓨터, 스마트폰 등) 또는 Peer라고 불리우는 application 간의 직접 연결을 통해 서비스를 제공한다.
- self-scalability(자기확장성) : 사용자가 늘어나면 비용이 늘어나는 Client-Server 구조와 달리, 사용자가 늘음은, 동시에 서버 연결과 자원을 제공해 줄 Peer가 늘어남을 의미하므로, 이용 가능 대역폭과 연결 수의 한계가 늘어나게 된다.
- 단, 비집중화된 구조로 인한, 보안, 성능, 신뢰성 저하 문제는 풀어야할 과제이다.
2.1.2. Processes Communicating
각 호스트에서 어떻게 여러 프로그램을 돌릴 수 있는지는 OS의 시점에서 보면 알 수 있다.
program, OS에서는 Process라고 부르는 작업의 단위에 작업을 할당하며 이루어지며, 각 Process간의 통신은, OS가 지원하는 Process 통신(interprocess communication) 을 통해 가능하다.
하지만 우리가 궁금한 것은, 네트워크를 통해 연결된 다른 End system 간에 속해있는 Process간 통신이며, 이는 네트워크를 통한 message 교환을 통해 통신이 이루어지게 된다.
Client and Server Processes
Client와 Server는 어떻게 구분될까?
단순히 packet을 송신하느냐 수신하느냐로 구분할 경우, 만약 사용자가 홈페이지에 파일을 업로드하면 서버가 되게 된다.
Client와 Server의 정의는,
의사소통을 위해 세션을 요청하면 Client,
기다리다가 요청이 들어오면 세션을 시작하면 Server이다.
예를 들어, 서로 간에 거의 구분이 없는 P2P 구조에서는, Peer B에게 세션을 요청한 Peer A가 Client, Peer A를 위해 세션을 열어준 Peer B가 Server인 셈이다.
The Interface Between the Process and the Computer Network
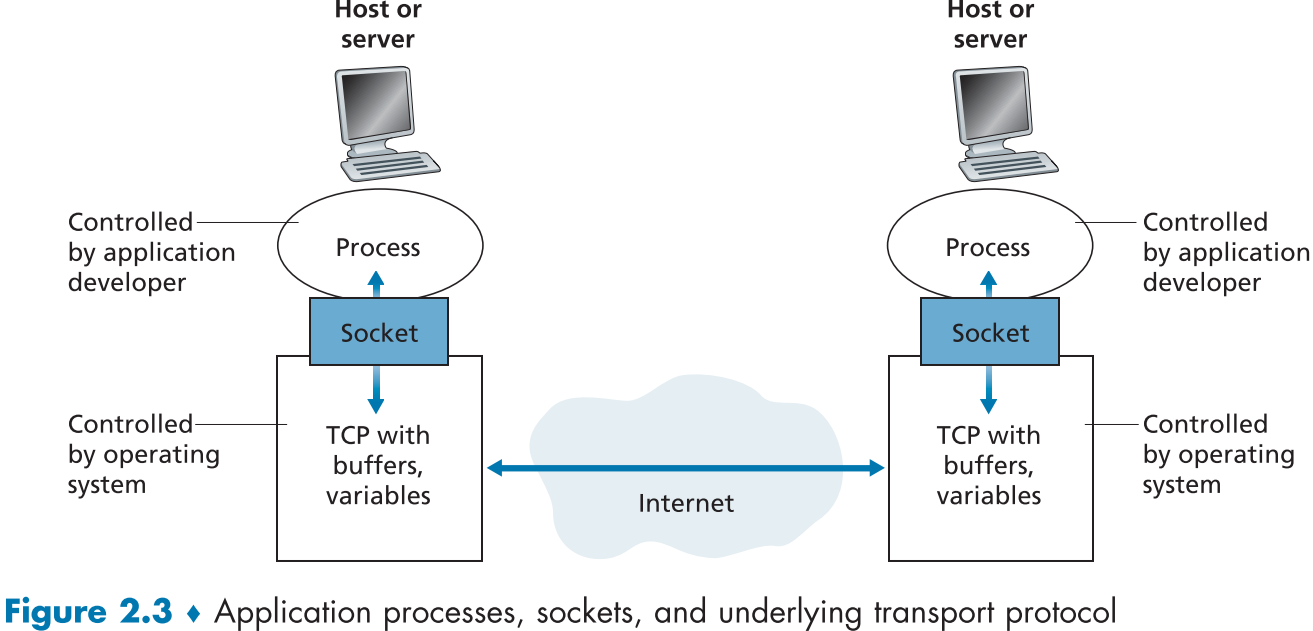
위에 설명한 네트워크를 거리에 둔 다른 End system 간의 Process가 상호작용하기 위해서는, Socket을 이용해야한다.
Socket은 Network와 Application의 상호작용을 위해 제공하는 일종의 API(Application Programming Interface)로, Transport Layer와 Application Layer 사이에 걸쳐있으며, Application Layer 측의 socket의 모든 기능과 Protocol을 통해서 Transport Layer 측의 socket의 일부 기능(사용할 transport protocol, 최대 buffet 사이즈, sement size 등)을 제공받아 Application을 만들 수 있다.
Addressing Processes
소포가 목적지에 도착하기 위해 주소지와 수령자 이름이 필요한 것처럼, message가 도착 process에 도착하기 위해서는
- host의 주소
- host 내부의 process 중에서 process의 식별 번호
가 필요하다.
1은 IP 주소를 통해 이루어지며, 2는 Port 번호를 통해서 주어지게 된다.
IP 주소는 32 bit 번호로 이루어져 있으며, port number는 2^16개의 번호가 할당된다.
web server의 80번가, SMTP 매일 서버의 25번처럼 유명한 process 들은 미리 포트번호가 정해져있기도 하다.
2.1.3. Transport Services Available to Applications
socket은 앞서 말하듯이 transport-layer protocol을 제공하며, application 구현 시, 적절한 protocol을 선택하여 구현해야한다.
예를 들어, 소포를 비행기로 보낼지, 기차로 보낼지 장단점을 고려해 선정하는 것과 같다.
이러한 Protocol의 차이는 대략 4가지로 구분할 수 있다.
Reliable Data Transfer(데이터 전송 보장)
데이터가 해당 Process에 손실 없이 도착하는 것을 보장하는 특징을 Reliable Data Transfer(데이터 전송 보장)이라고 한다.
주로 금융 정보나, 파일 전송 처럼 손실이 존재해서는 안되는 응용 프로그램에에 필요한 특성이며,
반대로 영상, 음성 전송 처럼 어느 정도 데이터 손실이 존재해도 상관 없어 Reliable Data Transfer Protocol이 필요없는 프로그램을 loss-tolerant applications라고 한다.
Throughput(전송 속도)
데이터의 최소 Throughput(전송 속도)가 보장되는 특성을 의미한다.
최근의 영상, 음성, 전화 멀티미디어 응용프로그램이 해당되며, 이러한 특성이 필요한 프로그램을 bandwidth-sensitive application이라고 한다.
몇몇 프로그램은 최소 전송속도를 맞추지 못하면 잠시 서비스를 포기(32kbps > 인터넷 전화 연결불가)하거나, 품질을 낮추는 방식(영상 화질 옵션, 더욱 낮은 용량의 encoding rate 사용)을 이용한다.
또한, 네트워크 상황에 따라 필요한 Throughput(전송 속도)을 가변적으로 변경 가능한 프로그램을 elastic applications이라고 하며, 파일전송, 웹 문서 전송, 메일 전송 프로그램 등이 포함된다.
Timing(전송 도착 시간)
전송 시작 시간과 도착 시간의 차이를 보장이 필요한 경우도 있다.
예를 들어, 화상 회의나 온라인 게임 중의 지연은 부자연적인 서비스를 초래할 수 있다. 이러한 application을 real-time application이라고 한다.
파일 전송처럼, 전송시간 delay가 늦어어도 되는 경우는 non-real-time application이라고 한다.
Security(보안성)
정보의 기밀 성을 유지해야 하는 경우도 있다.
주로, data encryption과 data integrity, end-point authentication을 통하여 packet이 감시, 탈취되는 상황에도 기밀성을 유지할 수 있다.
2.1.4. Transport Services Provided by the Internet
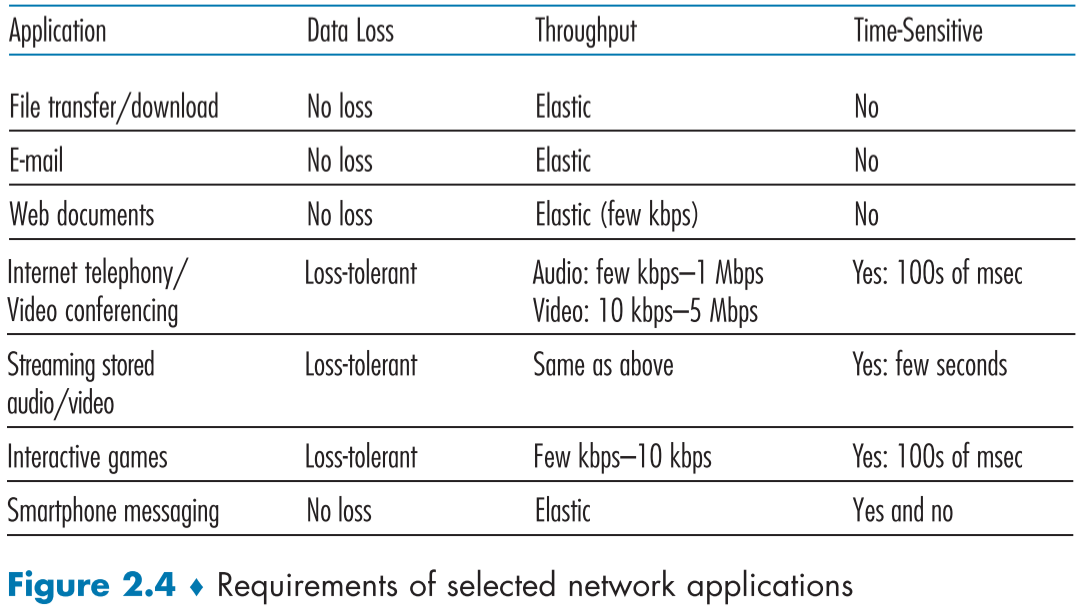
사람들이 많이 사용하는 TCP/IP 환경에서 보통 TCP와 UDP, 2가지의 Transport layer Protocol을 선택할 수 있다.
위의 표와 같이 자신의 어플리케이션 조건을 고려하여 선택한다.
TCP Services
TCP는 다음 두가지 서비스를 제공한다.
- Connection-oriented service :
- clinet와 server간의 통신이 일어나기 전에, 소켓간의 handshaking 절차(일종의 통신 가능 확인)를 거친 뒤, TCP connection이 형성되게 한다.
- 이렇게 형성된 connection을 통해 쌍방향 통신이 가능하게 하고, packet들의 쇄도를 방지할 수 있게 한다.
- Reliable data transfer service:
- 통신 간의 전송 동안의 packet의 변질 방지와 손실 방지, 중복 방지를 보장한다.
- 추가적으로, 양 application 간의 이득은 없지만, 전체적인 network 상황 개선을 위해 congestion-control(혼잡 제어)가 이루어져, sender와 receiver가 최대로 전송, 수신할 수 있는 패킷의 양을 제어할 수 있다.
UDP Services
추가적인 서비스를 최소한으로만 제공하는 경량 Protocol이다.
혼잡제어, 데이터 전송 보장 등이 존재하지 않아, 제약을 줄이고, 커스터마이징 하거나, 성능을 늘릴 수 있지만,
전송이 보장되지 않거나, packet 순서등이 변경될 수 있다.
추가적으로, 암호화, data integrity, end-point authentication 등을 제공하여 보안성을 늘린 TCP-enhanced-with-TLS(Transport Layer Securty)이 존재하며, TCP의 업그레이드 버전이라고 보면 되며, UDP를 기반으로 만들어졌다.
새로운 소켓 API와 Library를 통해 구현한다.
Services Not Provided by Internet Transport Protocols
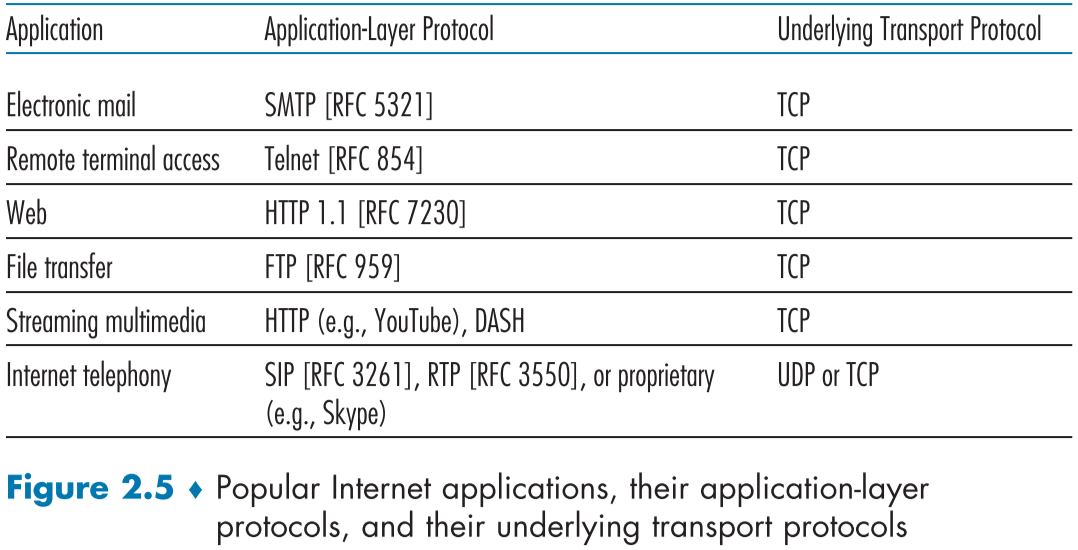
우리가 앞서 말했던 보안성, 데이터 전송 보장을 보장할 수 있지만, 다른 특성 2개, 최소 전송 속도와 도착시간은 보장하지 못한다.
현대까지 개발된 Prtocol 중에는 저러한 특성을 보장하는 Protocol은 없으며, 네트워크 환경의 개선에 의한 빠른 전송 속도와 도착시간을 보장없이 사용되고 있다.
위 fig2.5 경우, 보통 사용되는 protocol들이 적혀있다.
이렇나 보장이 필요한 어플리케이션(인터넷 전화, 화상회의, 게임 등)들은 packet의 overhead를 줄이고, congestion control에서 자유롭게 되기 위해, UDP를 이용하는 경우가 많으나, 일부 방화벽 등에 의해 UDP가 차단되는 경우에 대비하여 TCP로도 통신 가능하도록 하도록 옵션을 제공하는 어플리케이션이 많다.
2.1.5 Application-Layer Protocols
Application Layer Protocol에서는 다음과 같은 것을 결정한다.
-
메시지 타입 (ex) request, response message)
-
message packet의 field들, field들의 역할
-
위의 field에 들어갈 값들
-
message를 주고 받을 시간과, 방법에 대한 규칙
HTTP 같이 RFC에 공개 되어있는 Application-Layer Protocol도 존재하지만 Skype의 상용 프로토콜 처럼 공개되지 않은 경우도 있다.
또한, 많은 Application들은 단순히 Application-layer protocol 뿐만 아니라 여러 layer의 protocol로 이루어져 있다.
Netflix의 경우, 페이지를 보여주기 위한 HTTP 부터, 스트리밍을 위한 DASH 까지 여러 Layer, 여러 Protocol로 이루어져있다.
2.1.6 Network Applications Covered in This Book
수많은 Protocol이 존재하지만 그 중 에서 HTTP, FTP(E-mail), DNS, P2P, CDN에 대해서 알아보자.
2.2 The Web and HTTP
과거 연구용, 학습용, 군용으로 제한적으로 나마 쓰이던 인터넷 기술은 WWW(world wide web), 웹 이라는 어플리케이션의 등장과 함께 대중으로 퍼져나갔다.
특히, 수동적인 자세로 정보를 접할 수 있던 라디오, TV와 달리, 원하는 시간에 원하는 정보를 쉽게 접근하고, 생산해 배포할 수 있게 해주는 웹은 오늘 날에 점점 수요가 늘고 있다.
2.2.1 Overview of HTTP
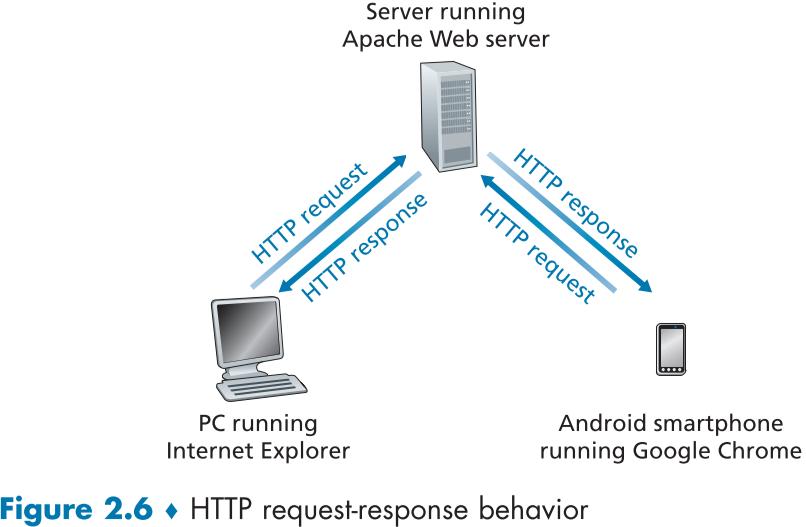
HTTP(HyperText Transfer Protocol)은 client, server side 양쪽에 구현되는 웹의 application-layer-protocol이다.
web page(또는 document)는 object로 불리우는, 일종의 파일(HTML, CSS, JPEG 이미지, Javascript file, video 등)들로 이루어져있으며,
대부분의 웹사이트는 URL로 주소를 표시하며, URL은 base HTML URL (hostname)과 다른 object들의 URL(path name)로 이루어져 있다.
\[\underset{base URL,\ hostname}{\underbrace{http://www.someSchool.edu}}\underset{path\ name,\ reference\ url}{\underbrace{/someDepartment/picture.gif}}\]Web application은 보통 client side는 Web browser(chrome이나 인터넷 익스플로러)가 맡으며, Sever side는 Web server(Apache, Spring)들이 맡는다.
HTTP는 메시지의 구조와 메시지 교환방식을 정의하며, TCP 연결을 기반으로 진행된다.
대략적인 방식은 사용자가 웹페이지를 요청하면, 브라우저가 socket을 통해 TCP 연결로 HTTP 요청 메시지를 보내고, 서버는 socket을 통해 TCP 연결로 부터 요청(request) 메시지를 받고 object 파일이 포함되어있는 HTTP 응답(response) 메시지를 다시 socket을 통한 TCP 연결 반대편의 브라우저에게 보내주는 방식이다.
또한, HTTP는 TCP의 특징인 전송 보장으로, 확실히 메시지가 전달되며, 추가적으로 client의 상태를 저장하지 않는 stateless protocol의 성격을 띈다.
예를 들어, client가 같은 요청을 2번 보내도, 서버는 첫번째 요청을 기억하지 못하므로, 이미 해당 정보를 Client가 받아갔다고 해도, 같은 정보를 한번 더 전송하게 된다.
처음 개발된 HTTP/1.0, 2020년대의 주류인 HTTP/1.1, 최근 지원중인 HTTP/2가 존재한다.
extra : HTTP Authentication
_http://frontier.userland.com/stories/storyReader$2159_에서 발췌
HTTP protocol은 서버측의 접근 인가를 위한 간단한 framework를 가지고 있다.
만약, 특정한 credential 정보를 제공하지 않으면 401 Unauthorized response를 돌려주도록 할 수 있다.
크게 2가지 scheme이 있는데,
- Basic Access Authentication
유저명과 암호를 입력하여 접속하는 방법,
첫 접속 시도시 돌려받는 401 Unauthorized response message에 다음과 같은 header가 추가되어 있다.

해당 페이지는 "Basic" 방법으로 접근 제어가 되어있고, 보호되고 있는 realm(일종의 보안 지정 지역?)의 key:value 값이 존재한다.
이후, 브라우저는 유저명과 암호명을 물어보게 되고, 입력된 정보를 이용해 bas64로 인코딩한 뒤 다음과 같은 헤더에 포함하여 request message를 다시 보내게 된다.
서버는 base64 decoding을 거친 뒤, 유저병과 암호를 비교하고, 맞을 경우, 요청한 페이지를 response 해준다.
이 방법은 간단하지만 패킷 도청에 유출된다는 단점이 있다.
이를 막기 위해 아래 MD5 암호화를 통해 유저명과 암호를 숨길 수 있지만, 그저 도청자가 해쉬된 암호를 해독하지 않고, 그냥 해쉬 결과값 통째로 보내는 방법으로 뚫을 수 있다.(replay attack)
- Digest Access Authentication
위의 보안 취약점을 막기 위한 방법으로, 두번째 방법은 추가적으로 nonce를 이용한다.
nonce는 각 401 response 마다, WWW-Authenticate header에 추가되어 있는, 이전에 사용된 적 없는 유일한 값으로, 사용자는 다음과 같은 식으로 nonce를 이용해 새로 request를 보내게 된다.
A1 = string.hashMD5 (username + ":" + realm + ":" + password)
A2 = string.hashMD5 (paramTable.method + ":" + paramTable.uri)
requestdigest = string.hashMD5 (A1 + ":" + nonce + ":" + A2)
nonce 값은 이번 response에서만 유효했던 값이므로, 감청자가 위의 패킷을 replay attack으로 똑같이 보낸다고 하더라도, nonce 값이 중복되어 버려지게 된다.
이외에도 digest 방법은 3자의 메시지 body 조작을 막는 방법이 마련 되어 있다.(RFC 2617)
HTTP 보안은 아쉽게도, digest 방법을 사용해도 비밀번호를 제외한 다른 정보들은 여전히 감청 가능한데다, 공격자의 서버 사칭을 막을 수 없고, 일부 브라우저들은 제대로 지원하지 않는 경우도 있다.
2.2.2 Non-Persistent and Persistent Connections
client는 server와 통신할 때, 어플리케이션의 성격에 따라 요청 메시지를 한꺼번에 여러개, 주기적으로 하나씩, 또는 간혈적으로 필요시마다 메시지를 보내게 된다.
이때 중요하게 고려해야 할 점으로, TCP 연결을 요청때마다 서로 열어야하는가? 혹은 TCP 연결을 계속 열어놓은 채로 통신해야하는 가이다.
전자는 non-persistent connections, 후자는 persistent connections라고 부른다.
보통은 후자 persistent connection이 기본 값이지만, 장단점을 알고 비교해보자.
HTTP with Non-persistent Connections
비지속성 연결(Non-persistent Connections)에서는 웹사이트가 1개의 base html file과 10개의 image로 이루어져있다면, 총 11번의 TCP 연결을 개폐하게 된다.
HTTP/1.0의 경우 비지속성 연결을 기본으로 하며, 브라우저 설정에 따라 최대 message 갯수 만큼 통신 후 닫게 끔 설정하여 속도를 늘릴 수도 있다.
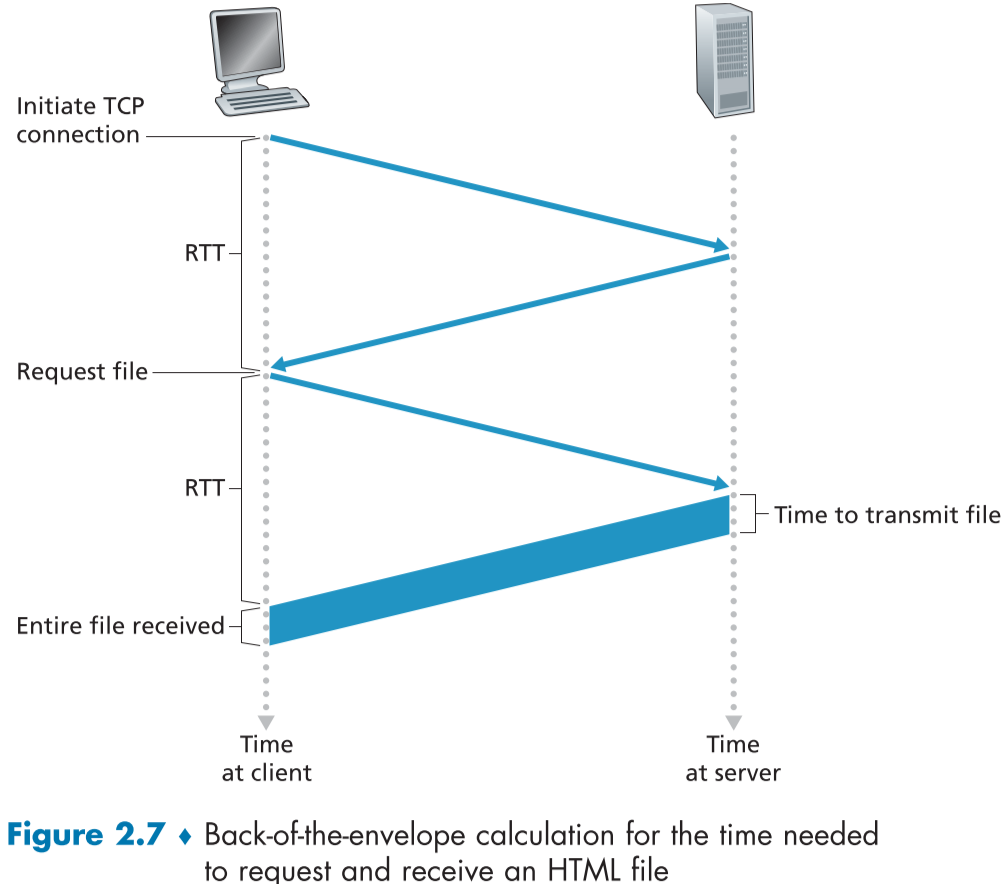
packet이 client side에서 출발해서 server side에 도착한 뒤 돌아오는데 걸리는 시간을 RTT(round-trip time)이라고 하면,
연결을 시작할 때, connection을 만들기 위해 3way handshake를 통하여 연결을 수립하고, 목적인 file의 경우 이후, response message로 보내지게 된다.
이 과정을 통해 총 걸리는 시간은 2RTT + file transmission time 만큼의 시간이 걸리게 된다.
비 지속성 연결(Non-persistent Connections)의 경우 2가지의 단점을 가지고 있다.
먼저 매 오브젝트마다 연결이 생성되므로, TCP buffer와 TCP variable이 Client와 Server 양측에 저장되어 기억되어야 한다는 점이다.
이는, 다음에 보내야될 파일이 뭔지 기억하기 위함이며, (HTTP는 stateless 이므로 기억하지못하므로), 이는 양측, 특히 서버에 큰 부담이 될 것이다.
두번째 단점은 매 message 마다 2RTT 만큼의 handshaking 과정의 딜레이가 추가로 생긴다는 점이다.
HTTP with Persistent Connections
하지만 HTTP/1.1 부터 지원하는 지속성 연결(Persistent Connections)을 사용하면, 위에 예시로 든 11개의 object message 전부를 연속된 resonse message를 순차적으로 보내는 pipelining 방법을 통해 한번의 연결만에 받을 수 있을 뿐만 아니라, 설정한 timeout interval 내에 새로운 request를 보내면 다음 오브젝트들 또한 한번에 받을 수 있어 비교적 성능이 더 좋아질 수 있다.
2.2.3. HTTP Message Format
HTTP message의 포맷은 request, response 두개이며, 이는 RFC 1945, RFC 7230, RFC 7540에 정의되어있다.
HTTP Request Message
GET /somedir/page.html HTTP/1.1\c\n
Host: www.someschool.edu\c\n
Connection: close\c\n
User-agent: Mozilla/5.0\c\n
Accept-language: fr\c\n
ASCII 문자로 구성되어 있어, 사람이 읽을 수 있으며, 케리지 리턴과 줄바꿈(lf)으로 구분된 여러 줄로 이루어져있다, request message가 적혀있는 절대 필수의 request line인 가장 첫번째 줄을 제외하고는 나머지 부가적인 정보로 선택적으로 더욱 정보를 추가할 수 있으며, 이를 header lines라고한다.
request line은
- method field
- URL field
- HTTP version field 총 3부분으로 나뉘어져있다.
method field는 GET, POST, HEAD, PUT, DELETE로 이루어져 있다.
GET이 가장 많이 사용되며, 보통 browser가 object를 request할때 사용한다.
URL field는 보통 작업이 이루어지는 object의 url을 의미한다.
version field는 말그래도 HTTP의 버전을 의미한다.
header line은
-
Host : 헤더의 경우는 object를 포함하는 host를 적는데, 이 부분은 나중에 web proxy cache를 위해 필수이다.
-
Connection: close header는 포함할 경우, 이 request에 response한 뒤, TCP 연결을 종료하게 해준다.
-
User-agent: header는 브라우저 타입과 사용 유저에 대한 정보를 적는다. 서버는 이를 보고, 각 버전이나 브라우저에 따라 호환되는 다른 object를 보내줄 수 있다.
-
Accept-language: header는 유저의 사용 희망언어를 구별하여, 서비스를 제공한다.
이 외에도 수많은 헤더를 추가할 수 있다.
request Message format 좀더 자세히 살펴보면 아래 그림과 같다.
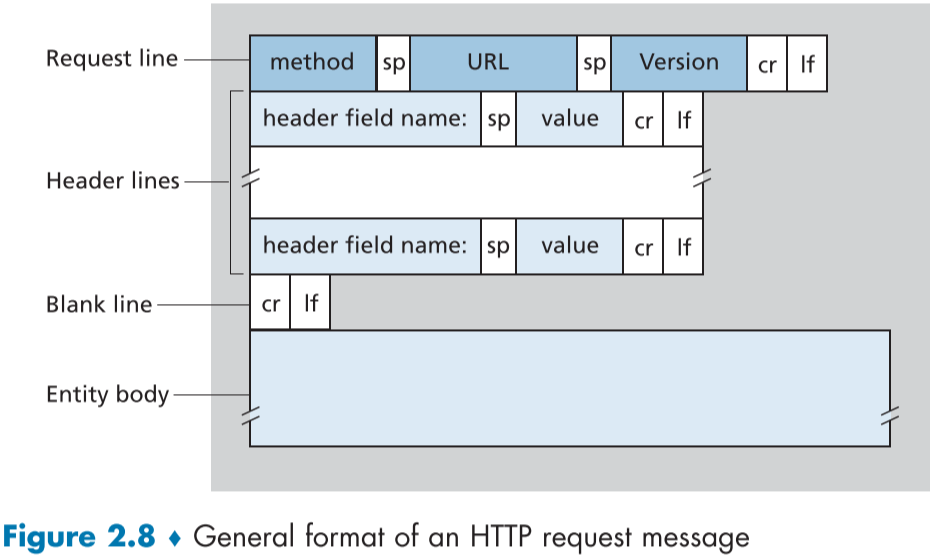
Entity body의 경우, 현재 GET method 에서는 비어있지만, POST method에서는 유저가 form에 작성한 정보가 들어간다(로그인 아이디, 암호화된 비밀번호 등…)
하지만 보안이 중요하지 않은(들켜도 되는 정보, 예를 들어 검색 단어, 조회하고 싶은 글의 번호) 경우에는 GET 요청에, URL 뒤에 변수를 삽입하여 요청 메시지를 보내기도 한다. (ex)www.somsite.com/animalsearch?monkeys&maxsearch?3)
-
HEAD method의 경우 GET과 비슷하나, 요청한 object를 반환하지 않는다. 보통 개발자가 디버깅을 위해 사용한다.
-
PUT method의 경우, 보통 object를 서버에 upload할 때 사용한다.
-
DELETE method의 경우, 웹 서버에서 object를 지우는데 사용한다.(자신의 글, 회원 탈퇴 등)
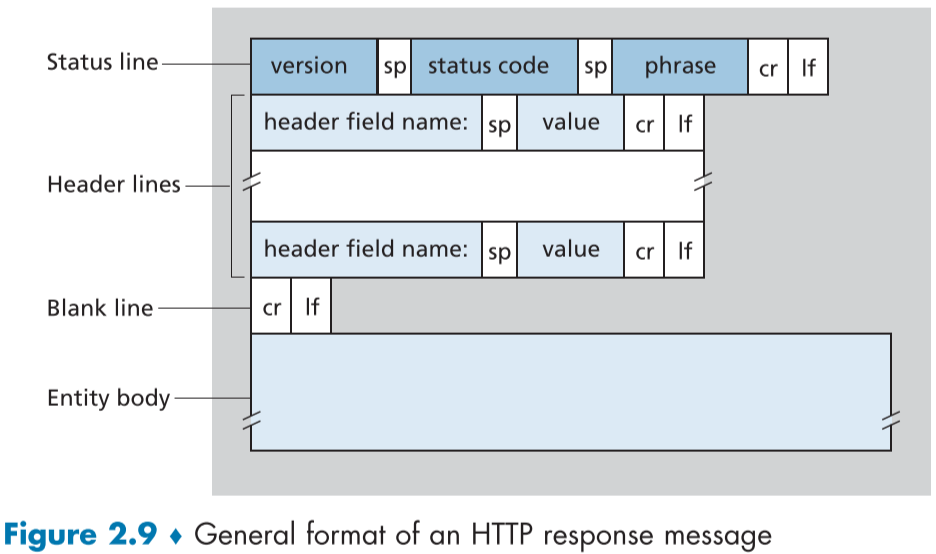
HTTP Response Message
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(entitiy body data field~)
위에서 본 request message의 response message 예시이다.
역시나 세가지 부분으로 나뉜다.
- status line
- header line 여섯줄
- entitiy body : request된 object data가 들어가는 자리
status line 또한 세 부분으로 나뉘며, 각각, Protocol version, status code, status message가 공백 문자로 나뉜다.
header line을 다시 살펴보자면,
-
Connection: close는 해당 메시지를 전달 받은 뒤, TCP 연결이 끊겼음을 의미하며,
-
Date: 헤더는 server에서 해당 message를 보낸 시각이며,
-
Server: 헤더는 서버의 종류를 알려주고, request message의 User Agent 헤더와 비슷한 역할을 한다.
-
Last-Modified 헤더는 Object의 최신 생성시간이나 수정 시간을 알려주며, 이는 local client나 network cache server(proxy server) caching에 사용된다.
-
Content-Length: 헤더는 전체 사용된 bytes의 길이를 의미한다.
-
Content-Type: 헤더는 entitiy body에 담긴 object의 type을 알려준다.
status code의 경우 예시를 들면 다음이 있다.
-
200 OK : 요청에 대한 정상 응답, 문제 없음
-
301 Moved Permantly: 해당 요청을 위한 URL이 예전에 변경됬을 시, 응답되는 코드, 새로 변경된 URL 정보가 있는 Location : Header 필드가 포함되어 있으며, client는 보통 자동으로 해당 URL로 재요청을 하게 됨.
-
400 Bad Request: server가 이해할 수 없는 요청에 대한 응답, 보통 request message 자체에 오류가 있을 때 발생
-
404 Not Found: 해당 하는 object나 document가 server에 존재하지 않음.
-
505 HTTP Version Not Supported : 해당 하는 HTTP protocol 버전을 서버가 지원하지 않을 경우 발생.
telnet 명령어를 통해 쉽게 message를 살펴볼 수 있지만, 자세한 것은 과제와 wireshark에서 참조
2.2.4.User-Server Interaction:Cookies
HTTP의 Stateless 특성은 간단한 서버 디자인과 높은 성능을 가져왔지만, 때때로, 유저 특화 서비스나 보안을 위해 request message를 구분해야할 필요가 있다.
이는 HTTP의 Cookie를 이용해 해낼 수 있으며, 대다수의 상용 웹사이트에서 사용하고 있다.
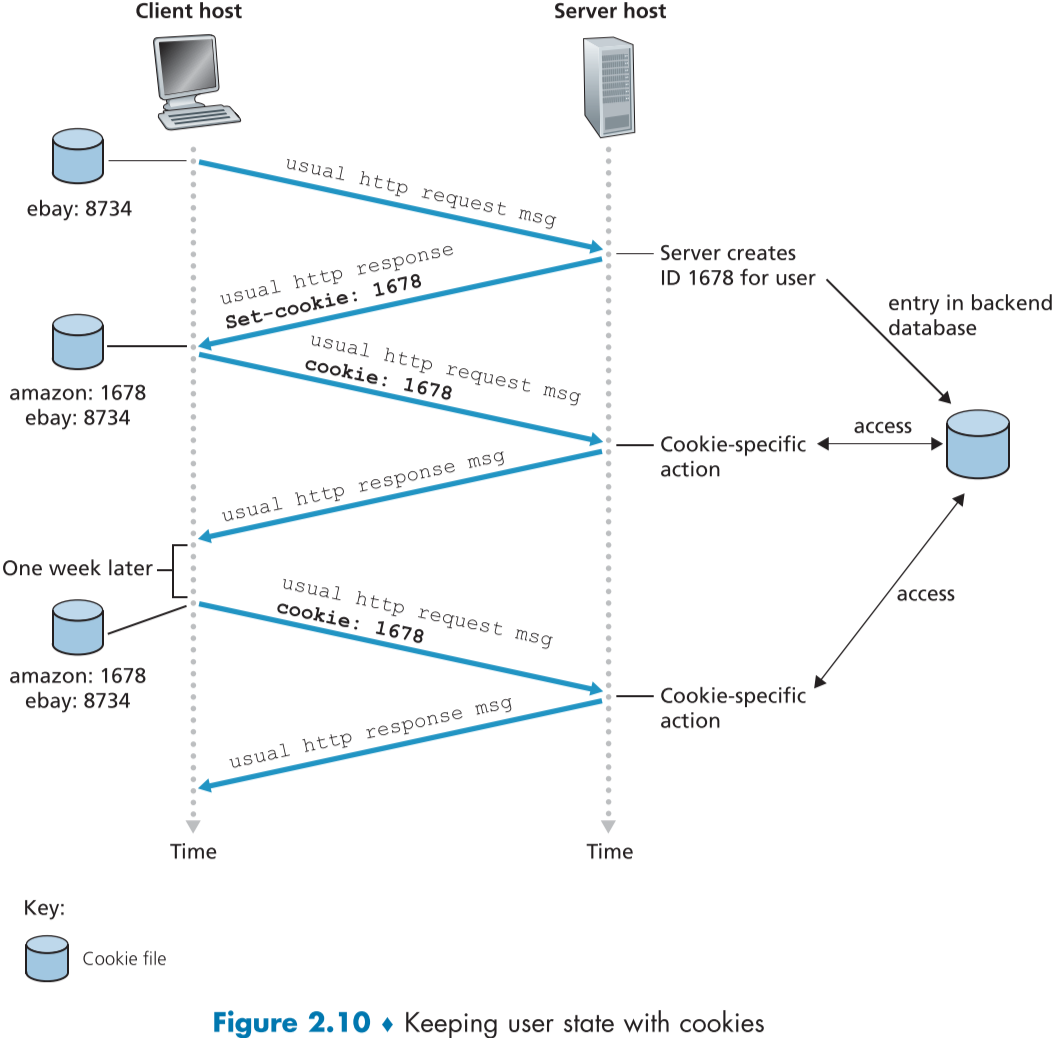
쿠키의 설정은 다음 4개의 상호작용으로 이루어진다.
- HTTP response message의 cookie header
- 서버가 처음 들어온 손님을 위한 유니크 번호가 적혀있는 쿠키를 헤더(Set-cookie)에 포함해 전달한다.
- DB에 유저의 정보를 입력한다.
- HTTP request message의 cookie header
- 유저가 사이트 내에서 한 행동들이 cookie 헤더가 있는 request에 의해 보내지고 DB에 기록된다.
- 사용자의 end system에 존재하고, browser에서 관리하는 cookie 파일
- 시간이 지난 후, 다시 유저가 사이트에 방문할 때, 브라우저에서 cookie 파일을 가져와 request message에 포함한다.
- backend server database
이러한 cookie는 유저 맞춤형 서비스(장바구니, 추천 시스템)나 편의성 개선(자동 로그인) 등이 가능해지지만, 대신 유저 privacy 침해나 보안 관련 이슈가 있을 수 있다.
2.2.5.Web Caching
Web cache 또는 proxy server는 web server 이전 단계에서 HTTP request 들을 처리하는 network entity이다.
고유의 저장공간과 response object의 복제본을 가지고 있으며, 이를 통해 request들을 웹 서버 대신 처리하게 된다.
웹 브라우저의 설정으로 생성할 수 있으며, 보통은 ISP 측에서 구매, 설치한 뒤, browser에 단체로 설정해 놓는다.
마치, client이자, web 서버처럼 진행되게 되는데, 절차를 살펴보면,
-
브라우저 <-> Web cache 간의 TCP Connection 생성
-
브라우저가 Web cache로 Request 요청
3-1.만약 요청한 object의 copy가 존재한다면, browser에게 response 전송
3-2. 만약 요청한 object의 copy가 없다면, origin server와 TCP connection 생성
- 이후 web cache가 origin server에 request 요청하여 object를 response로 받아옴.
- 이후, web cache는 client에게 response로 object를 보내주고, 이를 local storage에 저장.
이를 통해 응답 시간을 크게 줄일 수 있고, server와 client 사이의 대역폭 병목현상을 크게 줄일 수 있다. 뿐만 아니라 소속 ISP와 인터넷 전체의 Traffic에도 긍정적인 영향을 주어 ISP 내의 전체적인 Application 들의 성능 향상으로 이어진다.
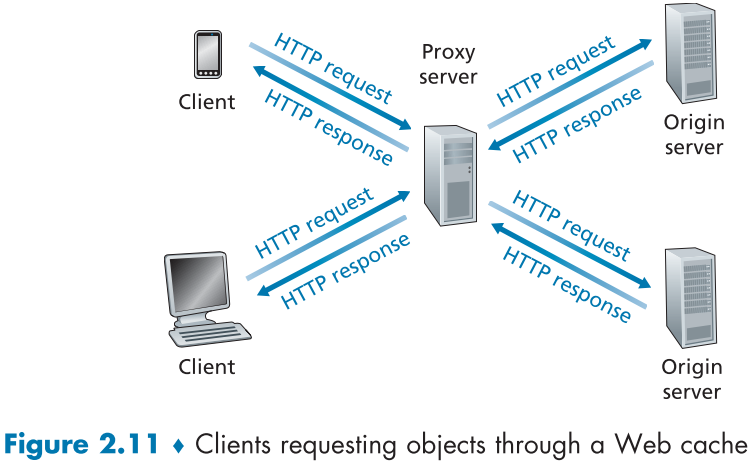
예를 들어 아래 같은 경우 delay 시간이 길어지면, 15Mbps access link 를 고비용 고성능 유선으로 업그레이드 vs cache 서버 설치로 저비용 완화를 할 수 있다.
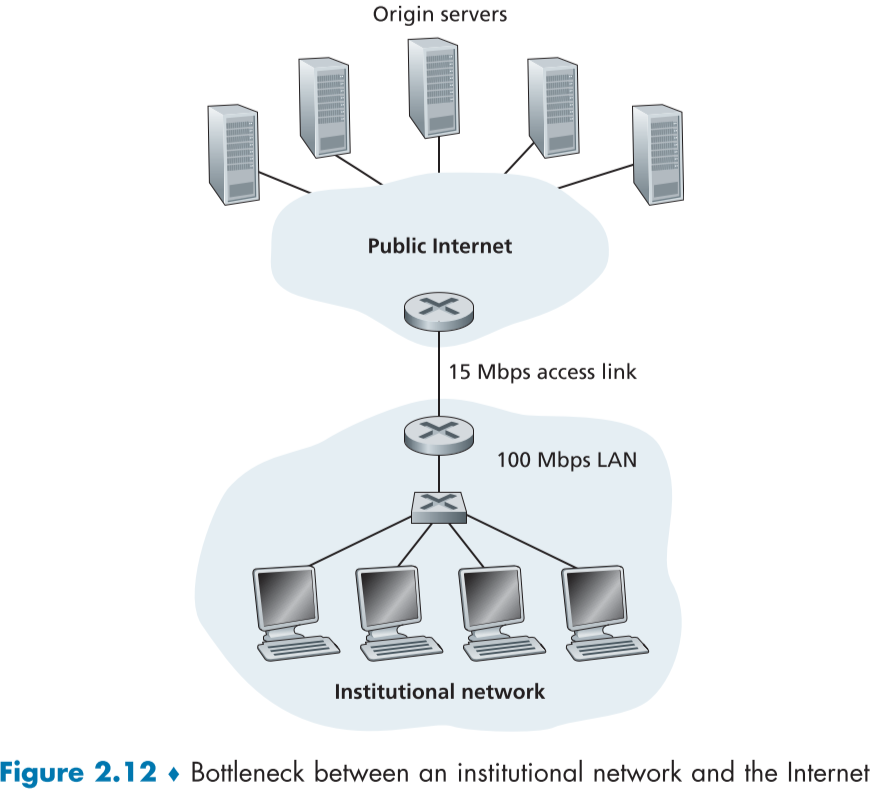
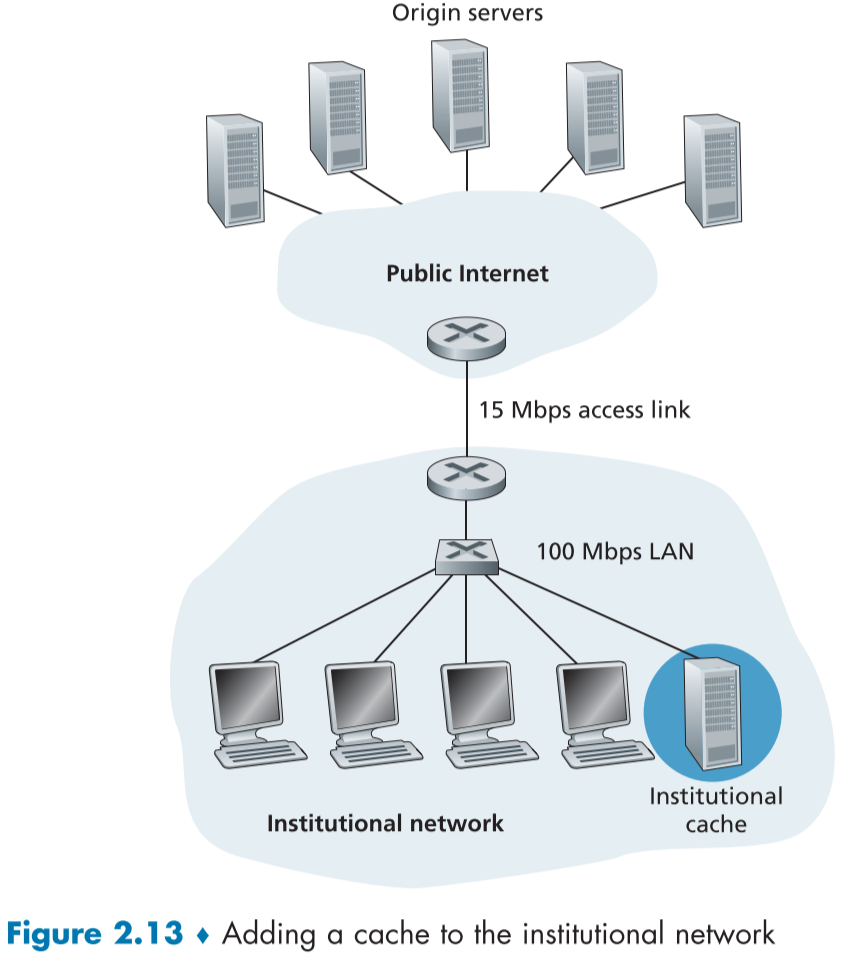
특히 최근에는 Content Ditribution Networks(CDNs)가 발달되면서 cache가 더욱 중요해졌으며, Dedicated CDN과 Shared CDN으로 나뉘어진다.
The Conditional GET
web cache의 문제점 중 하나는, 저장한 object가 outdated(stale)됬을 수도 있다는 점이다.
즉, cache된 뒤로, 원본 데이터가 바뀌면, 값이 업데이트 되야한다.
이때 Conditional GET을 이용하면 object가 업데이트 됬는지 확인할 수 있다.
먼저 web cache가 서버로 부터 object를 받고 저장할 때, response message에서 Last-Modified: 헤더의 최신 업데이트일을 함께 저장한다.
그 뒤, client에서 web cache로 해당 object의 요청이 있을 때, cache는 다음과 같은 Conditional Get request message를 보낸다.
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 9 Sep 2015 09:23:24
위 처럼, If-modified-since: 헤더가 있는 Get 요청이, condional Get이며, 해당 헤더에 존재하는 오브젝트의 last-modified 값을 가져와 넣는다.
만약 서버에서 해당 If-modified-since 날 이후로 변화가 있다면, 평범한 response message의 entitiy body 부분에 업데이트된 object를 돌려줘 갱신하게 한다.
만약 변화가 없다면, 다음과 같은 304 Not Modified 돌려주며, entitiy body에는 아무것도 넣지 않는다.
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
(empty entity body)
위 메시지가 돌아왔다면, 여전히 최신 데이터이므로, 그냥 caching된 object를 사용하면 된다.
2.2.6. HTTP/2
2015년에 발표되어 현재 전체 40% 웹사이트들이 지원하고 있는 protocol로, 하나의 TCP 연결로, 여러 request, response를 받기(multiplexing, 다중화: 여러 소켓으로 여러 request, response 받는 것), request 우선순위, HTTP header 압축, server push 등을 이용해 latency를 줄이는 것이다.
하나의 TCP 연결로 하나의 웹페이지를 받는다는 것은, 서버측의 socket의 점유 수를 페이지당 하나로 줄이고, 이로 인해 network bandwidth를 공평하게 받을 수 있음을 의미한다.
- 즉 기존에는 한 웹페이지가 여러 소켓(=연결)을 사용했었다. (아래 4번째 문단 참조)
하지만 HTTP/2는 HOL(Head of Line) blocking 문제를 해결하기 위해 아래의 Framing을 고안했다.
HOL blocking 문제의 예시를 들자면, 하나의 커다란 용량을 가진 비디오가 웹페이지 상단에 먼저 로딩되고, 그 외에 작은 용량의 댓글, 이미지 등이 다음에 로딩되야 하는 순간에, 용량이 큰 비디오를 먼저 로딩하느라 다른 작은 용량의 댓글 이미지 등이 먼저 로딩됬으면 빨리 컨텐츠를 보여줄 수 있었음에도, 어쩔 수 없이 비디오 로딩 이후에 로딩 되는 현상(user-perceived delay)을 의미한다.
HOL Blocking은 단순히 HTTP 뿐만 아니라 다른 통신 protocol (ex) switch에서의 packet outlink )에도 사용된다. 총체적으로 이야기하자면, 내가 더 빨리 갈 수 있는 데, 느린 앞 사람 때문에 기다리는 현상이다.
기존의 HTTP/1.1은 이 HOL 문제를 막기 위해 각 object마다 TCP 연결을 열어 해결할 수 있었지만, 이렇게 되자, sever 측의 socket을 순간적으로 많이 사용할뿐만아니라, 한 TCP 연결당 network bandwidth를 배정하기 때문에, 부당하게도, 컨텐츠가 많을 수록 대역폭을 많이 할당받는 문제가 발생됬다.
HTTTP/2 Framing
위의 HOL blocking을 막기위해 HTTP/2 에서는 각 response message들을 일정 용량 크기의 frame 여러개로 나누는 Framing을 사용한다.
예를 들어 다른 것보다 100배 용량이 큰 영상은 frame 200개, 나머지 작은 object들은 frame 2개로 나눈뒤, 번갈아가며 frame을 삽입하여 보낸다.
비디오의 frame 1개, 작은 object1 frame 1개, 작은 object2 frame 1개 이런식으로 세트를 만든 뒤 보내면, 비디오 frame 2번째를 보내는 시점에 다른 object들은 마지막 frame을 집어넣으므로, 전송이 완료된다.
이는 HTTP/2의 가장 중요한 기능으로, protocol의 sublayer 하나를 추가하여 보낼 때의 message framing과 받을 때의 message reassembling을 진행한다.
보통 헤더 field는 frame 1개, entity body는 용량에 따라 여러개로 만든 뒤, binary encoding을 진행하여 보낸다.
binary encoding은 해석이 쉽고, frame을 좀 줄일 수 있으며, error에도 좀더 강하다.
Response Message Prioritization and Server Pushing
먼저 메시지 우선순위(Message Prioritization) 기능은 request의 우선순위를 조정해 성능 향상을 노릴 수 있다.
우선 순위를 request 시 설정해 보내는 것으로, response에 담길 데이터의 순위를 지정할 수 있다.
1~256까지 가능하며, 높을 수록 우선이며, 높은 우선순위의 request가 요청한 frame들이 먼저 담겨져온다.
두번째 기능은 server pushing으로, 하나의 요청에 여러 응답 메시지를 보낼 수 있는 기능으로, 이것을 이용하면, request가 요청한 내용을 바탕으로 필요로 할 것 같은 다른 object들 또한 함께 보내는 것이 가능해, 더 빠른 로딩이 가능하다.
마지막 기능은 huffman coding을 이용한 header 압축으로, request를 연속으로 보낼 때, 이전 메시지와 겹치는 헤더는 보내지 않아 용량을 압축할 수 있다.
HTTP/3
QUIC는 UDP protocol을 기반으로 새로 제정되는 중인 transport protocol이다.
QUIC는 기존에 HTTP가 가지고 있던 message multiplexing, per-stream flow control, low-latency connection 등의 기능을 포함한다.
HTTP/3는 이 QUIC를 기반으로 만들어지고 있으며, 덕분에 더욱 심플하고 능률적인 디자인이 가능하다.
2.3 Electronic Mail in the Internet
E-mail은 인터넷의 태동기 때부터 생겨나, 인기가 유지되고 있는 application이다.
E-mail은 현실 편지와 같이 두 사용자가 같은 시간에 활동할 필요없는 비동기 매체이며, 현실 편지보다 더욱 빠르고, 보내기 편하며, 값싸며, 첨부, 내부 사진, Hyperlink, HTML 등의 기능을 제공한다.
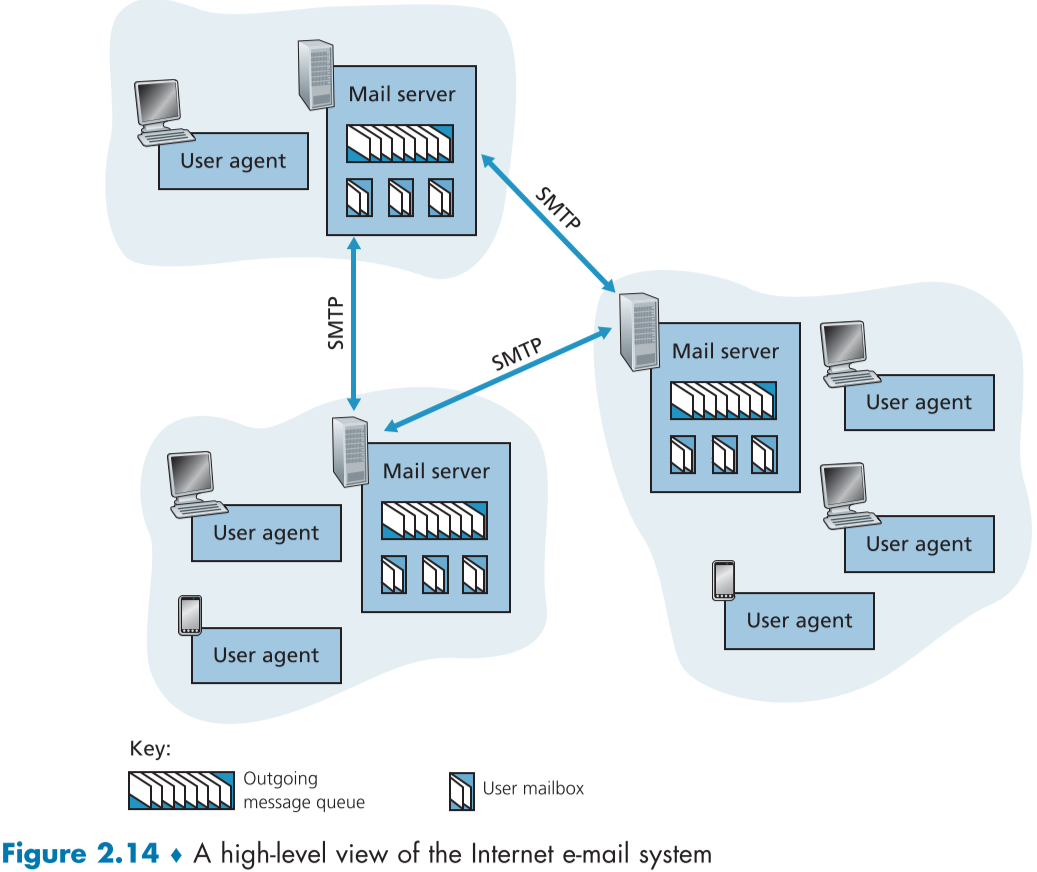
Mail server는 e-mail system의 핵심으로, 사용자 개인 mailbox와, mail message queue, SMTP protocol을 이용한 메시지 통신하는 역할을 맡는다.
mail message queue는 수신받은 상대의 mail sever의 문제로 전송에 실패했을 때, 해당 메시지를 보관하고 특정 주기마다(보통 30분) 재전송을 시도한다. 여러번 재전송이 실패하면 queue에서 message를 삭제하고 송신하려던 사용자에게 알려준다.
SMTP는 인터넷 전자 메일을 위한 기본적인 application layer 프로토콜로, TCP 기반의 데이터 신뢰 보장 서비스를 송신자와 수신자 mail server 간에 제공한다.
client side인 송신자측 mail server와 server side인 수신자측 mail server로 나뉘며, SMTP를 사용하기만 한다면 뱡항에 따라 서로 바뀔 수 있다.
2.3.1 SMTP
RFC 5321로 제정된 SMTP는 HTTP보다 오래된 Protocol로 초창기 네트워크의 제한된 성능자원 때문에 message의 header 뿐만 아니라 body 부분 또한, 7-bit ASCII로 인코딩되어있어야 한다는 제한을 가지고 있다.
하지만 현대의 e-mail의 경우 image, video 등의 multimedia를 포함할 수 있으므로, binary multimedia encoding -> 7-bit ASCII -> binary decoding로 변환하는 과정이 필요하다.
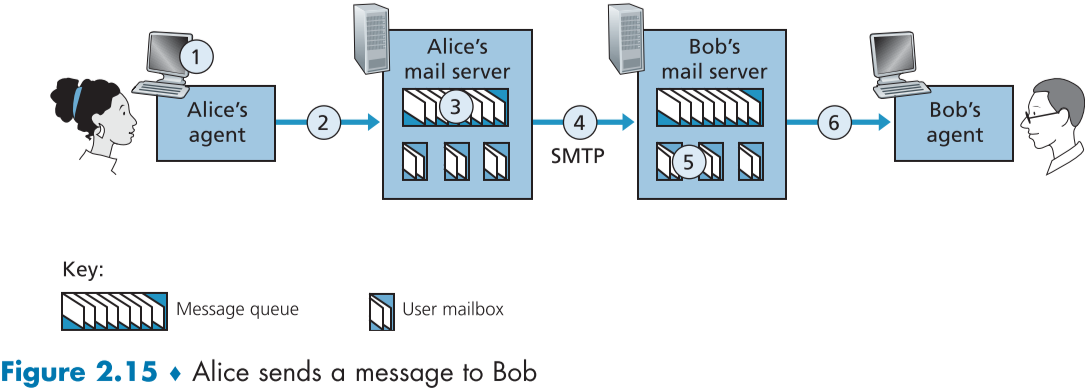
fig 2.15의 시나리오를 설명해보자면
- Alice가 Bob의 email 주소(bob@someschool.edu)로 메시지를 작성하고 user agent에게 메시지 전송을 지시함.
- Alice의 user aget가 메시지를 Alice mail server로 보내고, message queue에 저장됨
- SMTP의 client 측인, Alice의 메일서버가 queue 내부의 message를 확인하고, SMTP Server측인 Bob의 메일버서에 TCP connection을 요청함.
- SMTP Handshaking 이후, SMTP client가 Alice의 메시지를 TCP connection을 통해 보냄.
- Bob의 메일서버가 해당 메시지를 받은 뒤, Bob의 개인 mailbox에 집어넣음.
- Bob이 user agent를 통해 해당 메시지를 원하는 시간에 읽음.
SMTP는 양 측의 서버의 거리가 얼마나 멀든, 상대 서버에 문제가 있든 상관없이, 중간 경유 mail server를 사용하지 않으며, 언제나 송수신 대상간 직접적인 TCP connection을 사용한다.
S: 220 hamburger.edu
C: HELO crepes.fr
S: 250 Hello crepes.fr, pleased to meet you
C: MAIL FROM: &#60;alice@crepes.fr&#62;
S: 250 alice@crepes.fr ... Sender ok
C: RCPT TO: &#60;bob@hamburger.edu&#62;
S: 250 bob@hamburger.edu ... Recipient ok
C: DATA
S: 354 Enter mail, end with &#60;CRLF&#62;.&#60;CRLF&#62; on a line by itself
C: Do you like ketchup?
C: How about pickles?
C: .
S: 250 Message accepted for delivery
C: QUIT
S: 221 hamburger.edu closing connection
“Do your like ktchup? how about pickles?” 라는 메시지를 보내는 SMTP handshaking protocol의 예시이다.
client가 HELO, MAIL, RCPT, DATA, QUIT 등의 Command를 보내면, server 측에서 적절한 응답 코드와 설명을 보내준다.
client의 각 메시지는 CRLF .CRLF로 끝나며 이는 carriage return과 Line feed를 의미한다.
메시지 별로 handshaking을 하지 않고, 해당 메일 서버로 향하는 메시지 큐에 있는 모든 메일 보낸 뒤 TCP connection이 종료된다.(persistent connection)
각각 보내는 메시지의 시작에 MAIL FROM: 을 통해 메일주소를 알려주며, 모두 보냈을 경우 QUIT를 통해 연결을 종료한다.
“telnet {serverName} 25” 를 이용해서 localhost와 SMTP server와 연결이 가능하며, 위와 같은 명령어를 사용해 통신이 가능하다.
앞으로 주어질 Assignment 3번을 통해 구현해 볼 것이다.
2.3.2.Mail Message Formats
마치 현실 우편에서 보낸이, 받는이, 날짜, 우편번호 등을 적는 것처럼, 이메일의 Message에도 header를 줘야한다.(RFC 5322),
header line과 body line은 빈 줄로 구분되어있으며(정확히는 CRLF), Header에는 다음과 같은 format을 가지고 있다.
DATA
From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Searching for the meaning of life.
I love computer networks!
.
QUIT
From과 To는 보낸이와 받는이로 필수이며, Subject와 그 외의 추가적인 header line을 추가할 수 있다.
telnet으로 확인해 볼 수 있다.
extra : MIME Message Format
https://docs.microsoft.com/ko-kr/previous-versions/office/developer/exchange-server-2010/aa494197(v=exchg.140)에서 발췌
Multipurpose Internet Mail Extensions(MIME) Message Format은 문서의 컨텐츠의 내용을 표시하여 기존의 메시지 체계보다 더욱 복잡한 컨텐츠를 포함할 수 있게 해준다.
이러한 문서 타입 정보를 실어나는 방법은 윈도우즈 시스템의 접미사 방법이나, 구조상 보여지는 매직 넘버를 통해 가능하나, 통용되지않거나 예외가 있는 경우가 많다.
단순 메일 뿐만 아니라 HTTP Message 등에서도 많이 사용한다.
MIME header를 추가하여 body 부분을 각기 다른 타입의 여러 body로 나누어 생성하여 사용하며, 다음과 같은 추가적인 정보를 제공한다.
- 해당 body의 content type (image, video, application etc…)
- 각 body content 들의 class 구분, class는 content와 달리, 목적, 용도를 의미한다. (보통 subtype을 의미, application/msword의 msword 부분)
- 각 body content 들의 encoding 방식, 그리고 해독한 결과의 character encoding 구분, 예를 들어 binary, ASCII 등.
- 각 body content 들의 배치 방식, inline or attachment.
- HTML content 들의 base Uniform Resource Identifier (URI) 표기.
이를 통해, header나 message를 US-ASCII 이외로 작성하거나 , text가 아닌 데이터, 여러 part로 나뉜 데이터 등을 메일에 집어넣을 수 있게 된다.
MIME Message Body parts
또한, 이러한 body 부분들은 계층 구조를 형성하고 관계를 형성할 수 있는데 예를 들면, 같은 메시지의 여러가지 표현들(text로, html로, audio로), 사용자가 보기엔 하나로 보이는 여러 타입으로 이루어진 자료들(예를 들면, HTML page 내부에 사진, CSS, javascript 등이 뭉쳐진 경우), 대안 자료, 첨부 자료 등, 여러 목적을 위한 그룹 생성 등이 가능하다.
정확한 mail의 MIME type 결과물을 보고 싶으면 대부분의 이메일 서비스에서 original view를 지원하니, Image, 영상 등을 보내본 뒤, 확인해보자!
다른 body part 자식들을 가지고 있지 않은 body part를 content body part라고 하고, 다른 자식들을 포함하는 body part들을 multipart body part라고 칭한다.
이때, multipart body part는 content body part와 달리 message, text, video 같은 content를 가질 수 없으며, 오직 관계를 정의하는데 사용된다.
- html에 포함되어 있는 그림의 경우, “html content body part가 Image content body part를 자식으로 가지고 있으므로, content body part 속성도 가지고 multipart body part 속성도 가지지 않나?” 라고 생각할지도 모르겠지만, html이나 dom tree와 달리, MIME에서는 부모자식 관계로 표현하지 않고, related multipart body part로 묶어서 표현한다, (아래 예시 참조)
multipart body part의 경우, 여러 body part의 상위 body part인 경우, Content-Type 헤더가 multipart/mixed로 표시되며 ,그 자식 body part는 image/xxx, text/xxx 등의 Content-Type 헤더를 가진다.
또는 메시지의 대체 표현들을 위한 multipart body part도 존재하는데, 이 자신의 Content-Type 헤더는 multipart/alernative이며, 이 경우, 해당 메시지를 표현할 수 있는 여러 표현들의 값들을 자식 body part들이 Content-Type으로 가지고 있다.(같은 정보를 ASCII text, HTML, audio로 표현한 데이터들) 등,
body part type은 body part가 가지고 있는 content data의 종류를 의미하는데, 이는 MIME header의 Content-Type header에 표시되어 있다.
Content-Type은 {primary type}/{secondary type} 형식으로 표기하는데, 예시를 들자면, image/gif, multipart/related 같은 형식이다.
최상단에는 하나의 root body part가 존재한다.
Multipart/mixed header
┠━━━Multipart/related header
┃ ┠━━━Multipart/alternative header
┃ ┃ ┠━━━Text/plain header(content)
┃ ┃ ┗━━━Text/html header(content)
┃ ┗━━━Image/gif header(content)
┗━━━Application/msword header(content)
예를 들어 위의 예시의 경우, msword attachment와, html 또는 plain text로 표현될 수 있는 content를 가지고 있는데, 해당 content를 render하는 데 필요한 gif 파일도 포함하고 있다고 이야기할 수 있다.
Content Body Parts
content body part는 binary 값이나 html 등일 수 있는 bytes들로 이루어진 content와 content 정보를 가지고 있는 header field로 이루어져 있다.
예시의 Content-Transfer-Encoding header는 body의 encoding type을 알려주며, Content-Disposition header는 content가 메시지의 첨부 파일인지, 아니면 다른 body part content와 함께 inline에 표시되는 지 등을 의미해준다.
message 타입이 email 간에 ascii 코드로 변환되기에 이러한 정보들이 decoding 하고 화면에 보여주는데 필요하다.
Content-Type: image/gif;
name="picture_e2k7.gif"
Content-Transfer-Encoding: base64
Content-Disposition: attachment;
filename="picture_e2k7.gif"
[encoded content here]
위의 예시는
- content type은 GIF format의 이미지이다.
- content의 binary data는 base64 알고리즘으로 encoding 되어있다.
- 이 body part는 message의 첨부물이다.
- fiile명은 Picture_e2k7.gif 이다.
를 의미한다.
sample MIME Message
From: Some One &#60;someone@example.com&#62;
MIME-Version: 1.0
Content-Type: multipart/mixed;
boundary="XXXXboundary text"
This is a multipart message in MIME format.
--XXXXboundary text
Content-Type: text/plain
this is the body text
--XXXXboundary text
Content-Type: text/plain;
Content-Disposition: attachment;
filename="test.txt"
this is the attachment text
--XXXXboundary text--
MIME-Version header는 해당 메시지가 MIME Message임을 의미한다.
Content-Type: header가 multipart/mixed임을 통해, user agent에게 여러 body part로 나뉘어져 있음을 말해주며, 각 body는 boundary=”XXXXboundary text”로 나뉜다.(정확히는 boundary로 설정해준 값앞에 “–“가 추가되어야 한다.)
“This is a multipart message in MIME format” 이라는 글자는 boundary 외부에 있기 때문에 MIME를 지원하는 UA에게는 보이지 않는다.
boundary로 나눠진 각 content는, 각각 header가 존재하며, 만약 boundary로 나눠져 있되, header가 존재하지 않다면, 빈줄로 보인다?
첫번째 body part는 plain text를 가지고 있으며, US-ASCII로 이뤄져 있으며, 볼 수 있다. Plain text는 기본 헤더값이다.
두번째 body part는 첨부 파일로 표시되며, file 이름은 test.txt일 것이다.
MIME Headers
각 MIME header는 각 body part의 시작점에 적히며, 일부 헤더들은 message header에도 사용될 수 있다.
주로 “Content-“로 시작하는 헤더들은보통 body part header로만 쓰이며, sub-header나 field, parameter들을 받는다.
-
MIME-Version : MIME message임을 의미하며, top-level header로, 존재하는 body part가 완전한 새로운 message 형식이 아닌 이상, 한 메시지에 하나만 존재하며, 현재 1.0 만 지원하고 있다.
-
Content-Type : media type, subtype 등을 표시, private content-type 또한 기술 가능하며, 이때는 X-{새로운 타입명} 형식으로 기술한다.
-
Content-Transfer-Encoding : 2가지 다른 의미를 가지고 있다. 기본값은 7bit, 마찬가지로 x-로 시작하는 custom 값이 존재함.
- 만약, base64, quoted-printable 같은 값을 가지면, encoding 형식을 의미하는 것이다.
- 만약, 7bit, 8bit, binary 등의 값을 가지고 있으면, encoding 값이 없으며, content의 type을 말해주는 것이다.
-
Content-ID headers: body part를 구분하게 해주는 세계 유일 값, body part 간의 참조를 위해 필요함.
-
Content-Description : 보통 비문자 정보의 추가적인 정보를 제공하기 위한 optional header
-
Content-Disposition : message와 body part를 어떻게 표현할 지 정보를 알려준다. 첨부 파일로 놓고 싶으면, file name parameter를 활용하면 된다.
- Content-Type : MIME에서 가장 핵심적인 부분으로, 해당 content를 알맞은 form으로 보여주게 만든다.
-
크게 “복합형”과 “연속형”으로 나뉜다.
-
복합형
-
Multipart : sub type과 추가 element를 header에 넣어 multipart message로 만들어줌
- multipart/alternative : 같은 정보가 다른 형태로 다른 body에 있을 때 사용한다.
- multipart/byteranges : HTTP protocol의 일부로 정의되었다. 고유의 Content-type과 Content-range로 이루어진 2개 이상의 파트로 이루어져 있고, MIME boundary parameter를 이용해 나뉘어져 있다. binary로, 7bit로, 8bit 로도 파일을 길이가 적혀진 채로 각 파트에 나누어 보낼 수 있다.
- multipart/digest : 여러개의 plain-text message들을 보내게 하기 위해, 만들어졌으며, multipart/mixed와 다른 점은, 각 body가 message/RFC 822 여야한다.
- multipart/form-data : 파일 업로드 표현을 균일하게, MIME에 호환 되게끔 만듦
- multipart/mixed : 각 독립적인 body parts들이 특별한 순서로 묶이게 하기 위해 사용, subtype이 호환되지 않은 경우 UA들은 기본적으로 이 subtype으로 생각한다.
- multipart/parallel : 각 multipart content들이 동시에 출력되게 하기 위해 사용, 예를 들어, 사진이 load되면 동시에 소리도 나게끔 하기 위해 사용.
- multipart/related : 보통 여러 형태의 데이터가 포함된 복합 문서를 표현하거나, 메시지에 포함되지 않는 컨텐츠의 링크를 제공하는데 사용한다. “start” parameter가 주어지지 않으면 첫번째 body part를 root body part를 root로 삼는다.
```
Content-Type: Multipart/related; boundary="boundary-content_example";
type=Text/HTML; start=example@somplace.com
;Content-Base header not allowed here
;since this is a multipart MIME object
–boundary-content_example
Part 1:
Content-Type: Text/HTML; charset=US-ASCII
Content-ID: <example@somplace.com>
Content-Location: http://www.webpage/images/the.one
; This Content-Location must contain an absolute URL,
; since no base; is valid here.
–boundary-content_example
Part 2:
Content-Type: Text/HTML; charset=US-ASCII
Content-ID: <example2@somplace.com>
Content-Location: the.one ; The Content-Base below applies to
; this relative URL
Content-Base: http://www.webpage/images/
–boundary-content_example–
-
- multipart/report : 메시지 처리결과를 알리기 위해 사용하는 type, 주로 기계간 보고를 위해 사용한다.
- multipart/signed, encrypted : MIME part의 보안을 위해 사용된다.
- Message : 다른 메시지, 다른 메시지의 포인터를 포함 가능, 7bit 인코딩만 허용
- message/partial : 커다란 메시지를 쪼갠 여러 부분 메시지의 일부, id(조각들의 매치시킬 수 있는 id), number (메시지의 몇번째 조각인가?), total(전체 메시지는 몇조각인가?, 마지막 조각에만 적혀있음) 3개의 parameter를 받아 생성한다.
- message/external-body : 외부 참조 message, access-type parameter를 통해 FTP, LOCAL-ACCESS 등의 접근 방법을 설명하고, Content-ID header field에 외부 참조를 위한 ID를 제시해야 한다.
- 연속형
- Text
- text/enriched : 여러 글꼴을 지원하는 간단한 type, <commandname> </commandname>사이의 text를 formating 할 수 있다.
- text/html, text/plain
- 그외 Audio, Video, Application(application data들, marc, octet-stream, postscript 등) ....
### 2.3.3.Mail Access Protocols
사용자의 host에도 mail server 역할을 할 수 있게 만들 수 있지만, 그렇게 하기 위해서는 24시간 이메일을 받을 수 있게끔 켜놔야 하므로 개인용 PC로는 어렵다.
그러므로 대다수의 사용자들은 user agent를 local host에 놓고, 공용으로 사용하는 mail server를 공유하여 사용한다.
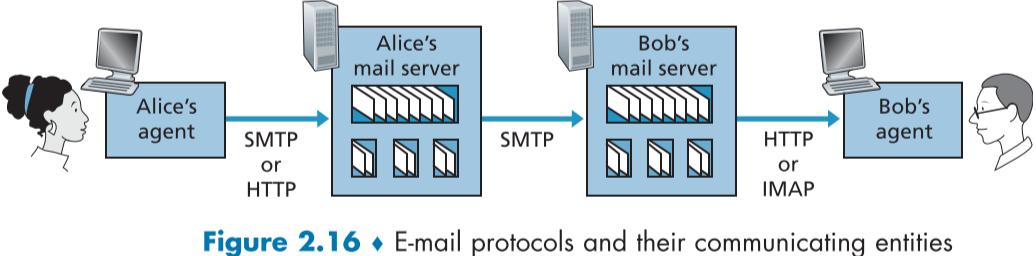
**대부분은 user agent들은 해당 메일을 직접 SMTP protocol로 상대방의 메일 서버로 보내는 것이 아니라 굳이 메일 서버를 거쳐서 보낸다.**
그 이유는, 만약 상대방의 메일 서버가 응답하지 않은 경우, 중간에 꺼지지 않고 지속적으로 새로운 요청을 보내기 위한 능력이 필요하기 때문에, 그러한 능력을 가진 메일 서버를 이용한다.
이때, 해당 서버에 HTTP 요청이나 SMTP protocol을 둘다 이용할 수 있다.
그렇다면 bob은 어떻게 mail server에서 mail을 가져올 수 있을까?
**SMTP는 요청을 통해 데이터를 가져오는 Pull protocol이 아니라 요청을 통해 데이터를 보내주는 Push protocol이니, SMTP protocol로는 불가능**하다.
이때 **웹기반일 경우에는 HTTP Protocol을 이용해서 가져오거나, POP3 protocol, microsoft outlook같은 Internet Mail Access Protocol(IMAP) 기반 어플리케이션**을 이용할 수 있다.
## 2.4.DNS-The Internet's Directory Service
현실에서 사람을 구별할 때 기계는 주민등록번호를 쓰지만 친구는 이름을 쓴다.
네트워크에서도 마찬가지로, 기계에서는 IP address를 사용하지만, 사람들이 웹사이트의 기억을 쉽게 하기 위해 hostname을 쓰곤 한다.
### 2.4.1.Services Provided by DNS
위에 설명한 대로, router는 고정된 길이의, 계층 구조 주소인 IP address로 host를 구별하지만, 인간이 기억하기 쉽도록 hostname을 써야한다.
**이 둘 사이를 변환해주는 역할은 domain name system(DNS)가 맡는다.**
**DNS는 DNS 서버 계층에 존재하는 분산 데이터 베이스나 host가 DB에 검색할 수 있게 해주는 application layer protocol을 의미하기도 한다.**
보통 UNIX 서버 머신에 Berkelty Internet Name Domain(BIND) software를 많이 사용하며, UDP 기반에 port 53을 쓴다.
HTTP와 SMTP(e-mail)에서도 hostname에서 IP Address를 구하는데 사용하며, 과정은 다음과 같다.
1. **유저가 브라우저에 URL을 입력하면, 브라우저가 hostname(www.someschool.edu)를 추출한다.**
2. **DNS의 client side application을 실행하고 DNS Client application에게 hostname을 보낸다.**
3. **DNS client가 DNS server에 해당 hostname을 query한다.**
4. **hostname의 IP address를 탐색하면, DNS client로 해당 IP address를 다시 reply 한다.**
5. **브라우저는 받은 IP address로 TCP 연결을 한다.**
결론적으로 DNS는 TCP와 UDP 전부 사용한다.
DNS로 인해 추가적인 delay가 발생할 수 있으며, 이를 막기 위해 결과값이 cache 되어있는 좀더 network 상 가까운 dns server를 만들기도 한다.
이 뿐만 아니라 아래와 같은 새로운 기능을 제공하기도 한다.
1. Host aliasing : 정식 hostname(canonical hostname)을 대신할 수 있는 보조 hostname을 가질 수 있게 해줍니다. 보통 헷갈리기 쉬운 이름이나, 더욱 간단한 이름을 사용하기위해 쓰며, DNS 서버에서 alias hostname을 받아 정식 이름이나 IP address를 query 해주기도 한다.
2. Mail server aliasing: 위와 비슷하게 메일 서버의 hostname을 새로운 hostname으로 바꿔주거나, 또는 원래 회사 hostname을 메일 서버 aliasing으로 사용할 수 있게 해준다.
3. Load distribution : 트래픽이 많은 서비스의 경우, 사용자들을 분배하기 위해 Load distribution을 사용한다. 트래픽을 분산시키기 위해, 많은 web server를 복사하게 되고 이렇게 복사된 server들은 각기 다른 IP를 가지게 되는데, hostname으로 query하면 DNS 서버는 이러한 IP address 들의 모임을 보내주되, 요청이 있을때 마다, 순서를 하나씩 rotation 하면서 돌려주며, 사용자는 이중 사용가능한 가장 앞선 IP address로 request를 보내게 되어, 사용자가 분배되는 방식이다. 웹 메일 서버에서도 DNS가 같은 방식이 쓰이기도 하며, Akamai 같은 회사에서는 CDN에도 사용한다.
DNS는 복잡한 시스템이며(복잡한 시스템은 network edge에 위치하도록 되어있는 디자인 철학상), 여러 RFC에 제정되고, 개선되어 있다.
### 2.4.2.Overview of How DNS Works
DNS는 사용자 입장에서는 간편하고 편리하지만 실제로는 아주 복잡하고 커다란 규모의 시스템이며, 분산 데이터베이스 구현의 좋은 예이다.
만약 DNS server가 고성능으로 네트워크 상에 단 하나만 운용한다면 다음과 같은 문제점들을 가지게 된다.
1. single point of faiure : 해당 DNS server가 다운되면 서비스 이용 불가
2. Traffic volumn : 너무나 많은 query가 한 서버에 집중됨
3. Distant centralized database: 지구상 모든 포인트 지점 정중앙에 위치할 수 없으므로, (지구 내핵 한가운데?) 어떠한 지역에서는 빠르게 response를 받지만, 어떤 지역에서는 아주 긴 delay를 겪을 것이다.
4. Maintenance: 새로운 hostname이 추가되거나, 변경될 때마다, 전 세계의 모든 서비스를 끊임없이 업데이트, 추가, 삭제해야 한다.
#### A Distributed, Hierachical Database
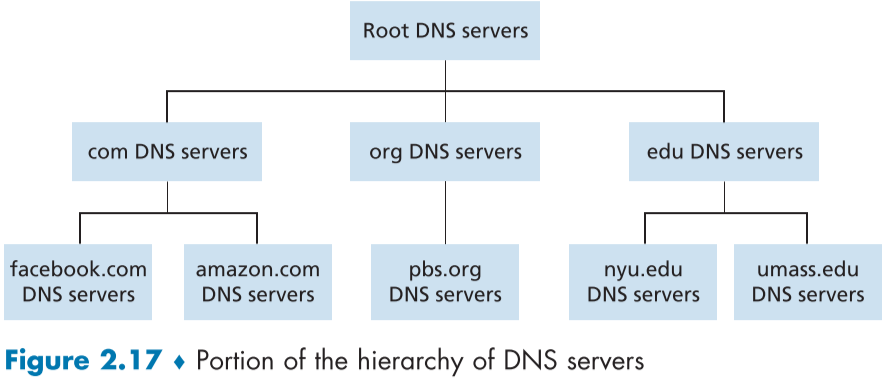
distributed 된 DNS server들은 다음과 같은 3가지 계층으로 이루어져 있으며, 모든 mapping 기록을 전부 가지고 있는 DNS server는 없다.
1. **Root DNS servers : TLD server의 IP addresse를 제공한다.** IANA(Internet Assigned Numbers Authority)에 의해 편성된 12개의 단체에서 관리하는 서로 다른 13개의 root server들의 복사본들이며, 아래 지도 분포대로, 전세계에 1000개 정도 존재한다.
2. **Top-level domain (TLD) servers : authoritative DNS server의 IP address를 제공한다,** top-level domain(com, org, net, edu, or country top-level(uk,kr,jp,fr...))들을 위한 서버들로, 회사나 특정 단체가 관리 중이며, 예를 들어 .com을 관리하는 Verisign network의 [Osterweil 2012]를 통해 서버 구성을 알 수 있다..
3. **Authoritative DNS servers : 공개 접근이 가능한 hostname들 가지고 있는 단체는 hostname : IP address map을 제공해야하며, 이를 제공해주는 서버를 Authoritative DNS server라고 한다**. 규모가 있는 회사의 경우 자기 자신의 DNS server를 운용하고 그렇지 않은 경우에는 관련 회사에 맡기기도 한다.
유저의 이러한 계층 접근 방법은 다음과 같다.
1. 유저가 DNS 서버에 원하는 hostname을 query하면, 먼저 Root server에 query한 뒤, root server는 TLD(.com, .kr, .co 등)를 보고 TLD 서버 IP를 돌려준다.
2. TLD 서버 주소를 알게된 유저는 TLD 서버에 해당하는 IP address(ex) naver.com, amazon.com)를 가진 authoriative server 주소를 물어보게 되고, TLD 서버는 해당 authoriative server 주소를 response로 돌려준다.
3. 유저는 다시 해당 authoriative server 주소에 full hostname(www.naver.com, www.amazon.com)를 물어보게 되고 authoriative server는 해당 웹 사이트의 IP address를 돌려준다.
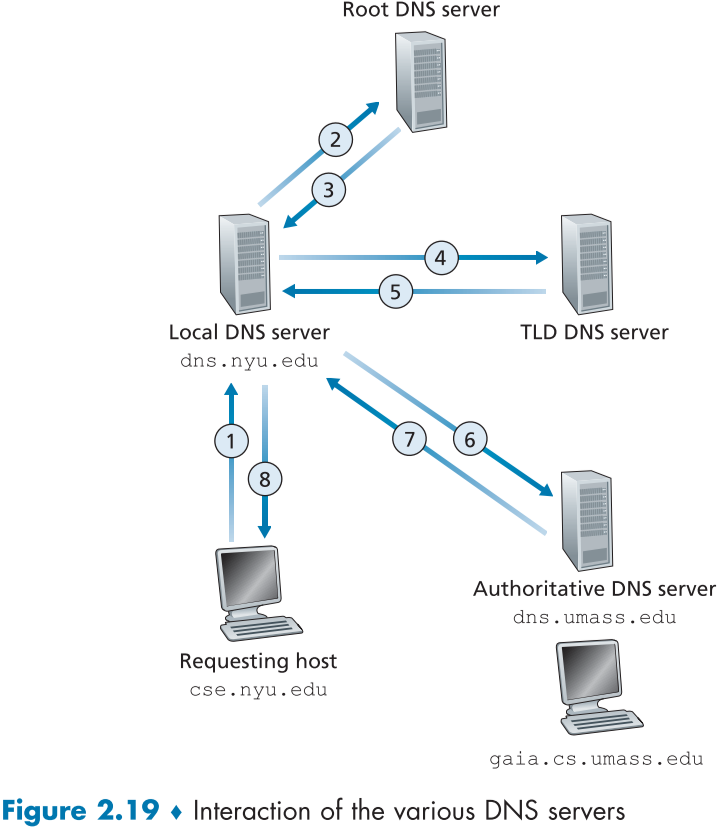
**추가적으로 Local DNS server가 있는데, 보통 ISP의 DHCP나 LAN을 생성한 단체에서 host에 router 상 가깝게 설치한 뒤, query 결과를 캐쉬해서 보내준다.**
아래 그림은 Local DNS server가 다른 DNS Server와 gaia.cs.umass.edu의 IP address를 가져오는 중에서의 동작이다.
그림과 달리 실제로는 TLD DNS server와 Authoritative DNS server 사이에 Intermediate DNS server가 존재하는 경우가 많아 실제로는 총 10개의 DNS message가 보내진다.
**그리고 1<->8번 같이 해당 쿼리가 다른 서버의 쿼리를 유발한 경우는 recursive query라고 하고,**
**나머지 2~7까지 처럼 한 서버가 다른 서버와 순차적으로 쿼리하는 경우는 iterative query라고 한다.**
#### DNS Caching
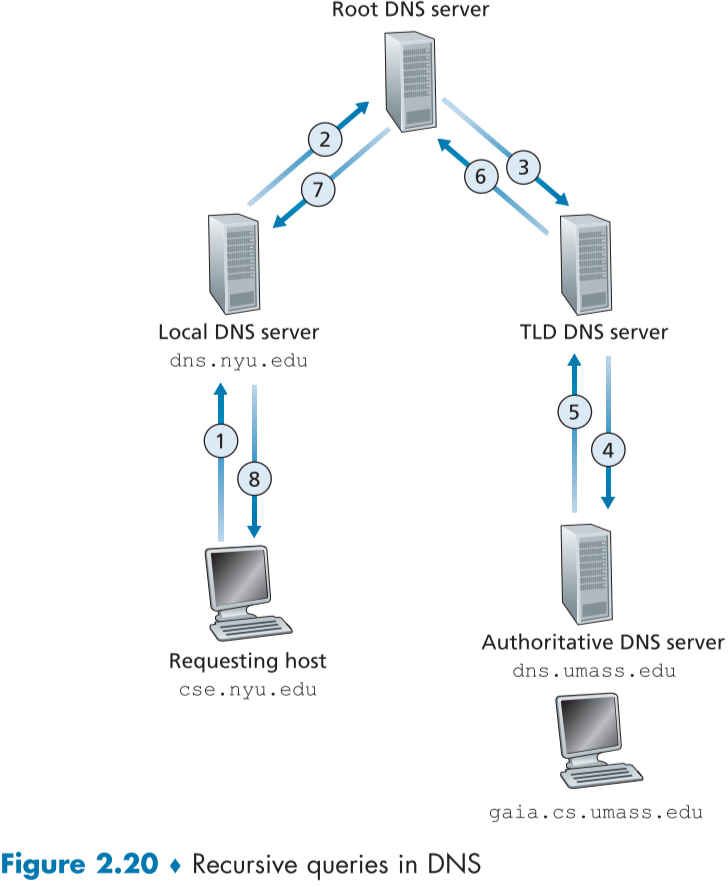
DNS caching 은 DNS 전체 시스템에 있어서 아주 중요한 부분으로, 실제 전세계 1000개조차 되지 않는 root DNS server가 모든 요청의 첫번째에 있음에도 트래픽을 감당할 수 있는 이유이기도 하다.
**Local DNS server에서 한번 query한 IP address map은 Local DNS server에 저장되어 동일한 또는 다른 Host가 해당 Hostname을 query 했을 시, 되돌려주는 역할을 한다.**
또한, full hostname 뿐만아니라, TLD 서버 주소도 cahcing 하므로, 처음 보는 Hostname이여도 TLD 도메인 부터 query할 수 있다.
보통 최장 2일 정도 보관하며, 2일마다 새로 caching한다.
### 2.4.3. DNS Records and Messages
DNS server는 Resource Record(RR)을 저장하고, 이를 message에 집어넣어 작동한다.
Authoriative server의 경우, DB에 저장하고, Hostname에 대한 IP address 값을 돌려주는 역할이지만,
Authoriative server가 아닌 경우도, cache 서버 등에 저장하기도 한다.
**Resource Record(RR)은 (Name, Value, Type, TTL), 4개 field의 tuple로 이루어져있다.**
**TTL의 경우, 서버에 해당 RR을 유지하는 시간**이므로 타입이 달라져도 모두 동일하므로 이번에 설명에서 생략한다.
이때 **Type에 따라 Name과 Value에 들어갈 내용이 달라**지며 Type은 다음이 있다.
1. Type=A : Name은 hostname, Value는 IP Address가 들어간다. 가장 기본적인 Hostname:IP address mapping.
예시 : (relay1.bar.foo.com, 145.37.93.126, A)
2. Type=NS : Name은 domain, Value는 해당 도메인의 IP address를 담고 있을 Authoritative DNS server의 host Name, 해당 서버에 정보가 없고 다른 서버에 쿼리할 필요가 있을 때 (=authoritative server가 아니고) 알려주기 위한 RR.
예시 : (foo.com, dns.foo.com, NS)
3. Type=CNAME : Name은 alias name, Value는 canonical hostname, 더욱 간단한 hostname으로 표기하는 alias 값을 위한 RR.
예시 : (foo.com, relay1.bar.foo.com, CNAME)
4. Type=MX : CNAME과 비슷하나, Mail Server를 위한 aliasing이며, 웹 서버와 같은 이름을 쓸 수 있게 해준다.
예시 : (foo.com, mail.bar.foo.com, MX)
#### DNS Messages
DNS의 message 종류에는 query와 reply message가 존재하며, 둘다 아래와 같은 형식을 가지고 있다.
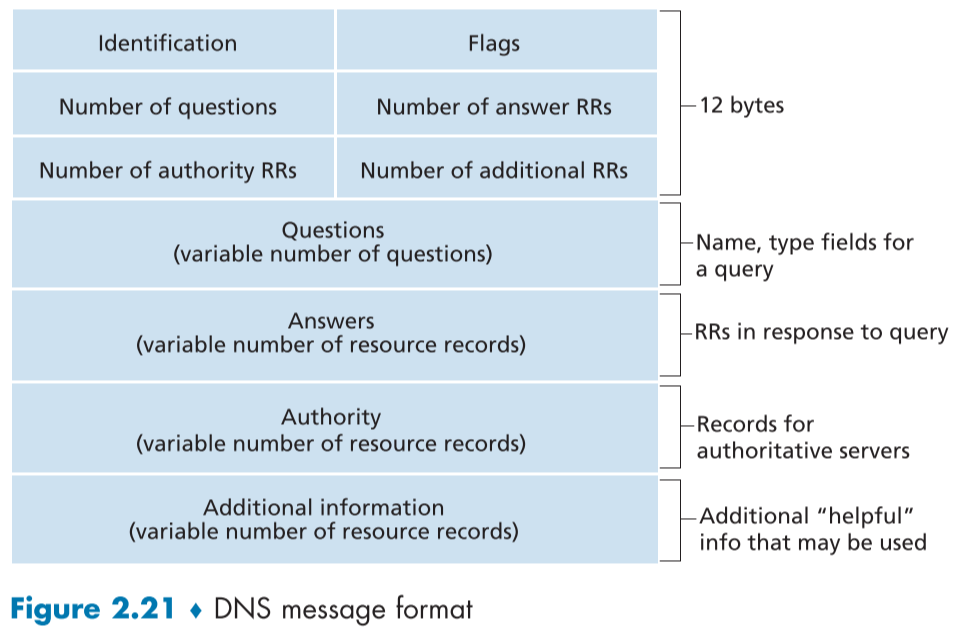
**첫 12 bytes는 header section으로, 숫자들로 이루어져있다.**
16bit의 Identification은 Query에서 제공되어, respond로 오는 reply message가 어느 query의 답변인지 알려준다.
flags filed는 여러 종류의 flag로 이루어져 있으며
- query/reply flag는 1bit로, query(0) or reply(1)를 구분하기 위해 존재한다.
- authoritative flag는 1bit로 reply message에 존재하며, 해당 query name에 대한 authoritative server 측에서 온 메시지인지 구분한다.
- recursion-desired flag는 query에 존재하며, 1bit로 1로 설정시, 해당하는 record가 없으면 recursion qurey를 하게 하여, 다른 서버에서 찾게 한다.
- recursion-available flag는 reply에 존재하며, reply한 DNS 서버가 recursion이 가능한지 여부를 알려준다.
- 추가로 4개의 additional flags는 아래에 설명할 data section 4개에 포함된 RR의 갯수가 적혀있다., 즉 한 메시지에 여러개의 RR query와 reply를 담을 수 있다
**question section은 현재 query에 대한 정보가 담겨져있다.**
- name field : query되는 hostname
- type field : 위의 name이 속한 타입 (ex) Type A, Type MX, 위의 RR 참조)
**answer section은 query된 hostname에 대한 RR을 포함하고 있다.**
- 위의 name field에 대한 Type, Value, TTL을 포함하고 있다.
- 여러개를 포함할 수 있는데, 트래픽이 많은 웹서버가 replicated 된 경우에는 여러 IP address를 가질 수 있기 때문이다.(proxy server)
**authority section은 다른 authoritative sever들의 record(rcursion query log?)를 포함하고 있다.**
**addtional section은 추가적으로 도움이 되는 record를 가지고 있다.**
- 예를 들어, mali server aliasing을 위한 (foo.com, mail.foo.com, mx)의 경우, additional section에 mail.foo.com의 IP address를 포함할 수 있다.
이러한 DNS query message를 DNS sever에 직접 보내보고 싶으면 **nslookup program, Wireshark, nslookup.io**을 이용하자.
#### Inserting Records into the DNS Database
만약, 이제 막 새로 시작한 회사가 hostname을 등록하려면, DNS database에 records를 넣어야 한다.
**이를 도와주는 상업 회사들을 registar이라고 부르며, 보통 유료로 여러 TLD를 사용할 수 있는 선택지를 준다.**
**먼저 호스트 네임과 IP address, 그리고 primary, secondary authoritative DNS server name과 해당 서버들의 IP address를 제공해야 한다.**
그 뒤에는 registar 측에서 type NS, type A record를 TLD server(com이면 TLD com server 측에) 삽입하면 된다.
아래는 primary authoritative server에 대한 TLD com server에 제출할 RR 예시이다.
(yournewcompany.com, dns1.yournewcompany.com, NS)
(dns1.yournewcompany.com, 212.212.212.1, A)
추가로 해당 authoritative server 들에 자신의 hostname(웹서버, 메일서버)가 추가 되어있는지 확인하고, hostname으로 HTTP request를 보내봐서 확인하면 된다.
최근에는 DNS protocol에 UPDATE option이 추가되어, database에 추가하는 것을 DNS Message로 가능하게 되었다.
## 2.5.Peer-to-Peer File Distribution
P2P 파일 분배 구조는 기존의 client-server 구조와 달리 여러 사용자에게 파일을 제공할 때의 서버의 부하를 없앨 수 있다.
가장 유명한 P2P file distribution protocol은 BitTorrent이며, P2P에 대해 알아보자.
#### Scalability of P2P Architectures
P2P 구조를 다음과 같이 생각해보자.
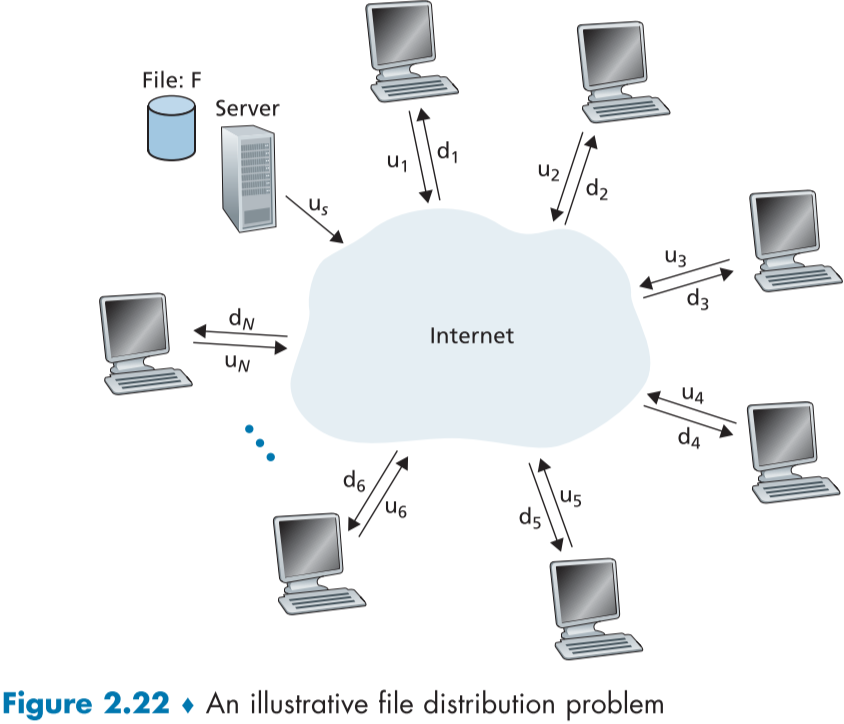
서버와 peer들은 internet을 통해 연결되어 있으며, 모든 피어들이 완벽하게 파일을 받게 되는 시간을 구하려 한다.
1. client-sever 구조의 경우
- 서버는 파일의 복사본을 N 명의 peer에게 보내야 하며, 총 NF bits를 보내야한다. 이때, 서버의 업로드 속도를 $u_s$라고 하면, 총 $NF/u_s$만큼 걸린다.
- 모든 피어들의 다운로드 속드를 $d_1,d_p,\dots,d_N$이라고 하면, 모든 피어가 파일을 받게되는 시간은 다운로드 속도가 가장 느린 피어의 속도인 $d_{min}$에 맞추어 $F/d_{min}$만큼의 시간이 걸리게 된다.
- 즉, 위 두 속도 중 더 느린쪽에 맞춰지므로
$$
D_{cs}\geq\max\begin{Bmatrix}\frac{NF}{u_s},\frac{F}{d_{min}}\end{Bmatrix}
$$
- 이는 client-server 구조에서의 최소 배포 시간을 의미한다.
$$
D_{cs}=\max\begin{Bmatrix}\frac{NF}{u_s},\frac{F}{d_{min}}\end{Bmatrix}
$$
- 또한, 서버는 전송을 예정해놓을 수 있으므로, 최소 배포시간을 실제 배포시간으로 봐도 된다?
[$수정 필요$]
- 해당 식에서 배포시간은 Peer 수인 N에 비례하므로 피어가 1000배 증가하면 시간 또한 100배 증가한다.
2. Peer to Peer 구조의 경우
- client-server 구조에 비해 속도를 구하는게 어렵다.
- 먼저, 서버가 해당 파일을 peer들의 community에 올려놔야 한다. 이때 드는 시간이 $F/u_s$, 한번만 올리면, 다시 올릴 필요 없다.
- client-sever 구조 때와 마찬가지로 가장 느린 peer의 파일 다운로드 속도는 $F/d_{min}$이다.
- 마지막으로, 파일 업로드 속도는 각 peer들의 upload 속도와 server의 업로드 속도와 동일하며, 이는 $u_{total}=u_s+u_1+\dots+u_N$ 로 구하며, 전체 전송되어야할 bit는 NF bits 이므로, 이때 최소 배포 시간은 $NF/(u_s+u_1+\dots+u_N)$이다.
$$
D_{P2P}\geq\max\begin{Bmatrix}\frac{F}{u_s},\frac{F}{d_{min}},\frac{NF}{u_s+\sum_{i=1}^{N}u_i}\end{Bmatrix}
$$
- 실제로 P2P 구조에서는 각 비트별로 구분해 배포되지 않고, file의 조각 별로 배포되며, 위의 최소 속도는 실제 최소 속도와 아주 근접하므로,
$$
D_{P2P}=\max\begin{Bmatrix}\frac{F}{u_s},\frac{F}{d_{min}},\frac{NF}{u_s+\sum_{i=1}^{N}u_i}\end{Bmatrix}
$$
- 실제 배포는 위와 같다고 봐도 된다.
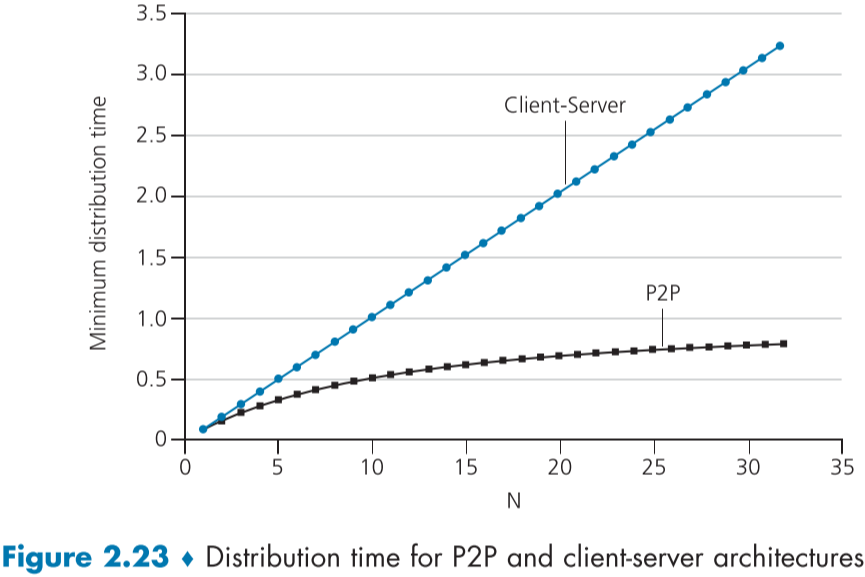
- **client-Server 구조는 peer 수에 따라 선형으로 필요시간이 증가하는 것과 달리 P2P 구조에서는 self-scaling 덕분에 훨씬 적게 증가하며, 1.0 에 수렴하는 것을 알 수 있다.**
#### BitTorrent
BitTorrent는 인기있는 파일 배포 P2P Protocol이다. 여기에서는 **특정 파일의 배포에 참여하는 모든 peer들의 모임을 torrent**라고 표현한다. 각 피어들은 다른 피어로 부터 **256KByte 크기의 파일 조각인 chunk를 다운**받는다.
첫 참여시 chunk가 존재하지 않지만, 첫번째 chunk를 다른 사용자로부터 받은 뒤, 다운받음과 동시에 다른 peer에게 배포를 시작한다. 다운로드가 끝나면 이기적이게 해당 torrent에서 나가거나, 여전히 남아 배포를 지원할 수 있다. 또한, 중도에 나갔다가 다시 들어오는 것 또한 가능하다.
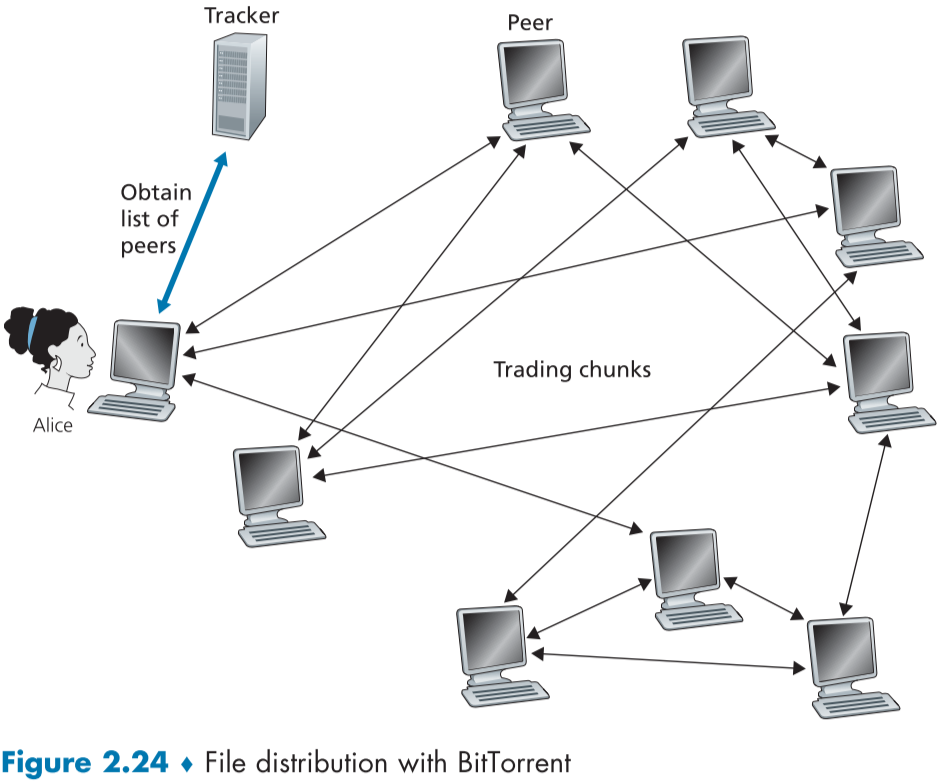
**BitTorrent의 각각 torrent에는 Tracker라는 노드가 존재하는데, 이는 peer들이 주기적으로 tracker에게 상태를 알려, 적게는 수 명, 많게는 수천명의 peer들의 참여 상태를 알 수 있다.**
위 fig의 예시를 들자면, alice가 처음으로 torrent에 peer로 참여하게 되면, tracker node는 alice에게 랜덤으로 50명 정도의 peer들의 IP 명단을 보낸다.
Alice는 해당 peer들과 TCP Connection을 수립을 시도하면, 일부 성공한 peer들을 "이웃 peer"라고 표현하며, 위의 그림의 경우 3명이다.(보통, 실제의 경우 더 많다.)
시간이 지나면서 일부 peer들은 torrent나 alice와의 연결에서 떠날것이며, 일부는 초기 50명의 peer 명단 내외적으로 더욱 참여할 것이다.
각 피어들은 파일 chunk의 일부분을 가지고 있으며, 이 일부분은 서로 모두 다를 것이다. 주기적으로 Alice는 이웃한 피어들에게 TCP Connection을 통해 가지고 있는 chunk의 목록을 요구할 것이고, 응답 받은 목록을 토대로 Alice가 가지고 있지 않은 chunk를 요구한다.
이때, 2가지 중요한 결정이 있는데.
1. **어떤 chunk를 먼저 요구해서 가져와야 하나?**
2. **어떤 peer의 chunk 요청을 먼저 들어줘야 하나?**
이다.
1번째 결정은 **rarest first**, 라는 기준을 사용하는데, 이웃들 중에 가지고 있지않은 가장 희귀한 chunk를 먼저 요구하는 것이다.
이를 통해, torrent 내부의 chunk들의 보유 빈도수를 최대한 고르게 만들 수 있다
2번째로, 어느 peer의 chunk 요청을 들어줘야하는 문제는, 특별한 알고리즘을 사용한다.
**Alice는 주기적으로 이웃들별로 자기에게 chunk를 보내는 속도를 측정한다, 그리고 매 10초마다 최고로 높은 속도의 4명을 선정해서 해당 4명이 요구하는 chunk를 보내준다.**
이러한 top 4 이웃 peer를 **unchoked**라고 한다.
**또한 위의 4명과 별개로, 매 30초마다 랜덤하게 이웃 peer 하나를 골라 해당 peer에게도 chunk를 보내준다.**
이를 **optimistically unchoked**라고 부른다.
만약, 이 랜덤하게 chunk를 받은 peer가 측정한 top4 peer에 alice가 들게된다면, 해당 peer 또한 alice의 chunk 요구에 보탬이 되줄 것이다.
만약, 두 peer가 서로 chunk를 보내주기로 결정되었다면, 한쪽의 peer가 더욱 나은 파트너를 찾을때까지 서로 chunk를 보내주게 된다.
**이러한 알고리즘에 의해, 비슷한 속도로 배포하는 사람들끼리 매칭되는 경향이 생기게 된다.**
**optimaistically unchoked peer에 의해, 배포해줄 chunk가 없는 새로운 참여 peer 또한, chunk를 받을 기회가 생기게 된다.**
위의 chunk를 받는 5명의 peer 이외를 chocked 라고 한다.
이외에도 chunk를 쪼개는 pieces 알고리즘 pipelining, random first selection, endgame mode, anti-snubbing 등의 특이한 알고리즘이 Bittorrent에 적용되어 있다.
이러한 인센티브 메커니즘은 tit-for-tat이라는 전략과 비슷하며, 사실 이러한 방법은 이기적인 방법으로 피해갈 수 있다.
하지만 이러한 전략 때문에 BitTorrent는 크게 성공하였고, 수 많은 파일들이 공유되고 있다.
Bittorrent 이외에도 **DHT(Distributed Hast Table)이라는 피어간에 db record가 분배되어있는 간단한 데이터베이스**도 존재한다.
## 2.6 Video Streaming and Content Distrbution Networks
동영상 스트리밍은 전체 인터넷 traffic의 80%를 차지한다. 이러한 content 중심 웹사이트에게 중요한 CDN에 대해 알아보자
### 2.6.1. Intertnet Video
**video는 초당 특정 프레임 수(보통 24~60 사이) 만큼의 image가 시간 순서대로의 열거된 매체**이며,
image는 2차원 배열로 표현된 pixel의 모임이며,
pixel은 명도와 채도가 숫자로 표기된 한 점에서의 색상을 의미한다.
streaming video란, 사용자가 video 정보를 필요로 할 때, 시간대 별로 연속적으로 미리 인코딩된 비디오를 보내어 비디오 데이터를 전부 받지 않아도 볼 수 있게끔 하는 서비스이다.
**보통, 비디오를 여러 화질로 미리 encoding 하여 서버에 저장한 뒤, 네트워크 상황에도 버퍼링 시간 없는 streaming과 안정적인 throughput을 위해, 화질과 초당 프레임 수를 조절해가며 streaming 한다.**
최근 encoding 기술이 발달해 원하는 화질에 얼마든지 압축, encoding 할 수 있으며, video의 경우 보통 100kbps ~ 10 Mbps(4k)까지 지원한다.
1시간, 2Mbps 정도의 비디오가 1GB 정도를 차지한다.
### 2.6.2.HTTP Streaming and DASH
**HTTP server에서 URL을 통한 GET 요청을 보내면 TCP connection이 열리고, client application의 buffer에 message를 쌓아놓게 된다.**
**이렇게 쌓아놓은 buffer의 bytes가 설정한 수준(predetermined threshold)를 넘기게 되면, play 가능하게 되며, application은 계속 도착하는 message를 buffer에 쌓고, frame을 decompress한 뒤, 유저의 뒷 부분 영상을 보여주게 된다.**
HTTP를 이용한 streaming은 Youtube에서도 사용하고 있지만, 모든 client가 네트워크 상황에 관계없이 언제나 같은 encoding으로 받아야 한다는 단점이 있다.
**Dynamic Adaptive Streaming over HTTP(DASH)는 이를 보완하기 위해 만든 HTTP-based streaming으로, video를 여러가지 버전의 bit rate로 저장해놓고, client는 매 GET 요청마다 video segment의 화질을 스트리밍 중에 동적으로 바꾸어 요청할 수 있다.**
DASH Protocol은 bandwidth 상태가 좋지 않은 경우가 많고 변화무쌍한 모바일 환경 등에서 유리하다.
각 버전의 video 들은 HTTP 서버에 저장되며, 이때, **manifest file을 함께 저장하는데, client가 video를 요청할 때, 가장 먼저 manifest file을 받아보게 되고, 그곳에 적혀있는 각 화질 별 URL과 byte range header에 따라 chunk별 HTTP GET request를 작성하게 된다.**
그렇게 chunk를 받아본 후, bandwidth, buffer 등의 상황을 고려한 알고리즘 또는 사용자의 선택을 통해 다음 request에 요구할 bit-rate를 결정하게 된다.
### 2.6.3.Content Distribution Networks
용량이 큰 Video, sound, image 등을 사용자에게 보내는 일은, 사업이 글로벌화되고, 커다란 수요를 마지하게 되면서 해결하기 힘든 일이 되었다.
만약 성능 좋고 거대한 용량을 가진 data center에 모든 contents를 수용하고, 사용자에게 제공한다면 세가지 문제가 생긴다.
**첫번째는 사용자가 해당 data center에서 멀다면 여러 ISP를 거치면서, delay와 throughput이 엄청나게 악화된다.**
**단 하나의 병목 link만 존재해도, 비디오 스트림은 기나긴 버퍼링 시간과 low bit-rate에 시달려야 한다.**
**두번째는 요청이 많은 content의 경우 같은 내용의 content byte가 전세계 network에 중복으로 엄청나게 보내지게 되고, 이는 곧 커다란 비용과 network 혼잡을 일으키게 된다.**
**세번째는 만약 해당 data center에 문제가 생기면(single-point-failure), 모든 서비스가 중단된다는 점이다.**
Youtube, Netflix 같은 커다란 회사들은 이 문제를 해결하기 위해 **Content Distribution Network(CDN)**을 만들었다.
**CDN은 network상, 그리고 지정학 상으로 전세계로 분배된 content sever를 둔 뒤, content의 복사본들을 위치시켜 사용자에게 하여금 가까운 데이터센터에 content를 요청하게 하는 것이다.**
규모가 큰 회사는 자신의 서비스만을 위한 **private CDN**을 운용하며, 아니면 다른 회사에서 운영하는 **third-party CDN**을 이용할 수 있다.
보통 2가지 서버 배치 전략을 이용한다.
1. **Enter Deep** : 전세계 수많은 Access ISP에 총 수천의 server cluster를 배포하여, end user에 가깝게 위치시킨다. (Akamai의 방법)
- 이를 통해 짧은 delay, 높은 throughput, 지나치는 link와 router수를 줄일 수 있지만, 대신 유지보수와 cluster 관리가 힘들다.
2. **Bring Home** : 10개 정도의 커다란 서버 cluster를 IXP(Internet Exchange point)에 배치하여 content 제공(Limelight, Level-3 의 방법)
- 유지보수와 관리가 비교적 쉽지만, delay와 throughput에서 비교적 손해를 본다.
모든 server cluster들은 완벽하게 content를 복제해서 저장하지 않는다. **content의 지역성을 고려해서 마치 web cache 방법처럼, 요청 받은 content가 해당 지점에 존재하지 않으면 중앙으로 부터 받아와 caching하고, 오랫동안 사용하지 않은 Content는 삭제하는 식**으로 운용한다.
##### CDN Operation
사용자가 DNS를 통해 content를 요청할 시, CDN은 해당 request를 가로채서, 가장 가깝고 적법한 CDN 서버는 어디인지 판별하고, 그리고 해당 CDN 서버에 redirect 해준다.
이때 request를 가로채기 위해 DNS를 활용하곤 한다.
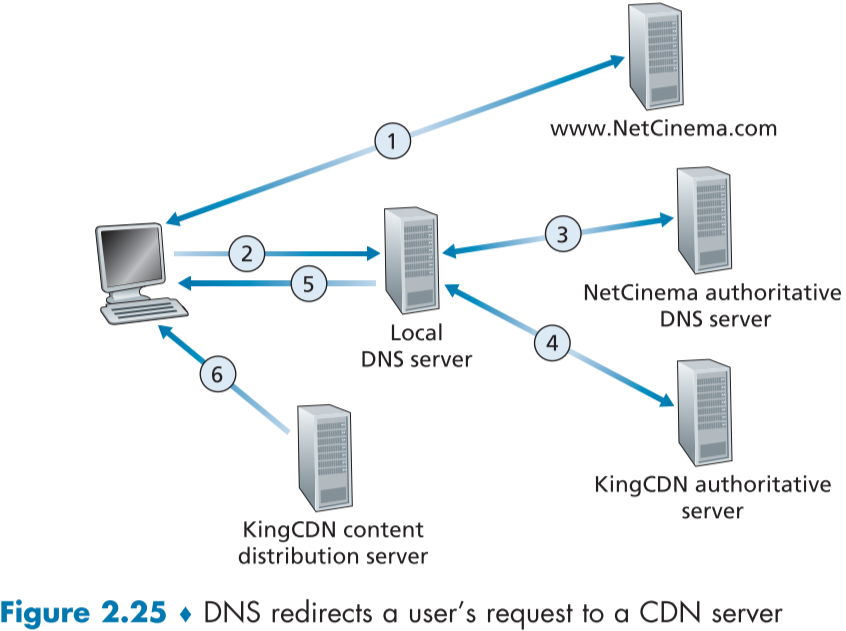
DNS와 CDN을 이용한 content 전달의 과정을 살펴보자면,
1. 사용자가 비디오 웹페이지 접속
2. 사용자가 웹페이지에서 특정 video link를 클릭하여 DNS에 요청을 보냄(ex)http://video.netcinema.com/6Y7B23V)
3. local DNS 서버는 해당 비디오 웹페이지의 hostname의 "video" 문자를 확인하고 authoritative DNS server에 query 요청을 함, (이때 local DNS가 사용자에게 주는 reply는 아직 없음), 그럴 경우 DNS 측 authoritative sever에서 새로운 hostname을 넘겨줌 (ex)a1105.kingcdn.com)
4. local DNS는 새로 받은 hostname을 이번엔 CDN 측의 authoritative server에 query하고 reply로 CDN의 content server IP address를 받음.
- 이때, Cluster selection 전략에 따라 알맞은 content server를 할당받게 된다.
5. 해당 content server IP address를 Local DNS server 측에서 사용자에게 전달.
6. 사용자는 content server IP를 받으면, 해당 server와 TCP connection이 생성되며, video에 대한 HTTP GET request이 가게 된다.
- DASH protocol이라면 manifest file과 URL을 받게 되고, 유저는 그 중에서 알맞은 URL을 선택하게 된다.
#### Cluster Selection Strategies
사용자(정확히는 사용자가 query한 LDNS 서버)에게 건네줄 적정한 content server cluster를 고르는 전략은 크게 2가지로
1. **지정학적으로 가까운 지점 추천**(geographically closest) : Quova, MaxMind와 같은 상용 지정위치 데이터베이스에 LDNS 서버의 위치를 물어봐 가장 가까운 cluster를 알려주는 방법
- 다만, 실제로 network 상의 hop 거리가 실제 거리와 비례하지 않을 수도 있어, 성능이 나쁘게 나올 수 있다.
- 또한, 네트워크 상 최적의 cluster였다고 하더라도, network traffic 상황에 따라 더욱 먼 cluster를 추천하는게 좋은 상황에도 언제나 같은 cluster를 추천하게 된다.
2. **real-time mesurements** : 각 content server와 LDNS 사이의 delay와 throughput을 ping이나 DNS quey를 통해 규칙적 시기마다 조사하여, 최적의 cluster를 결정한다.
- 위의 결점을 보완할 수 있지만, 일부 LDNS는 성능과 traffic, 보안을 이유로 이러한 조사를 위한 message, query를 받아 들이지 않도록 설정하면, 결정이 불가능해진다.
### 2.6.4.Case Studies: Netflix and youtube
CDN의 실제 예시를 알아보자.
#### Netflix
Netflix는 Amazon cloud와 사내 private CDN 인프라를 활용하고 있으며, **서비스 웹사이트와 backend DB의 경우 amazon**을 사용하고 있다.
또한, Amazon cloud는 추가로 다음과 같은 업무 또한 진행하고 있는데,
1. **Content injection(content 삽입?) : 스튜디오로 부터 영화를 받고, amazon cloud에 업로드**
2. **Content processing(content 처리) : 영화를 PC, smartphone, TV에 적합한 여러 버전으로 바꾸고, 추가로 DASH protocol을 위한 여러 bit rate를 설정한다.**
3. **Uploading versions to its CDN : 모든 버전의 영화가 생성되면, 해당 버전들을 CDN server로 옮긴다.**
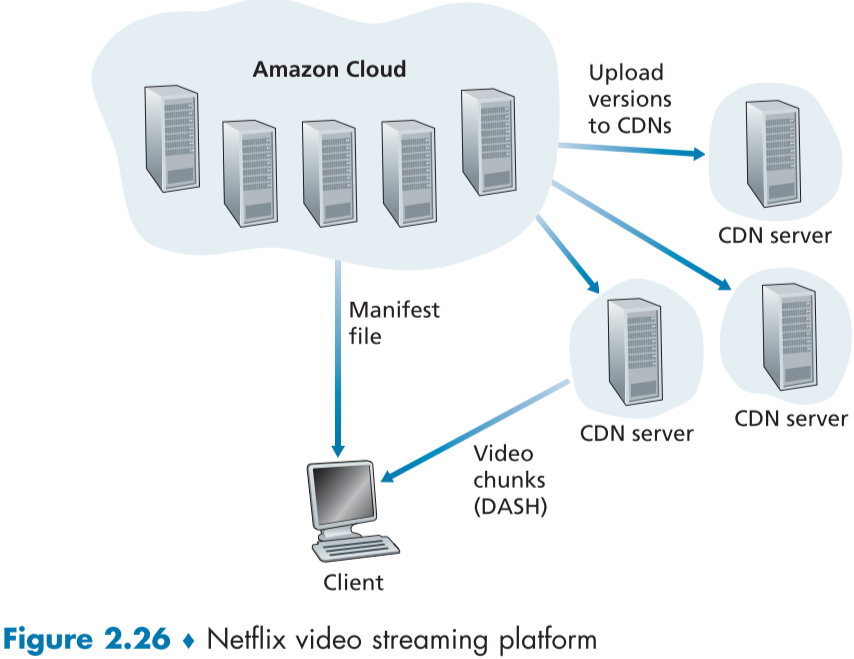
Netflix는 초기에는 third-part CDN을 이용했지만, **개인 CDN 인프라를 200 군데의 IXP와 100여 군데의 직접 만든 residential ISP에 server rack을 갖춘 뒤, 옮겼다.**
이때, 파트너 ISP와 상호간에 10 Gbps Ethernet prot와 100 terabyte의 저장성을 가진 sever rack을 상호 무료 설치하기도 했다.
각 서버렉에는 NETFLIX의 전체 영화들의 여러 화질 버전을 저장하고 있으며, CDN 서버들은 **pull caching(캐쉬에 저장하지 않고 있다가 요청이 들어오면 저장하는 방법)을 사용하지 않고**, 대신 시간대별로 인기많은 영화를 예상해서 각 ISP와 IXP CDN 서버에 집어넣는다(**push caching** 이라고 함).
netflix DASH의 byte-range header에 따른 chunk의 크기는 대략 4초정도이다.
Netflix 측은 DNS redirect 방식 (2.6.3의 CDN operation) 방법을 사용하지 않고 자체 개발한 software를 Amazon cloud에서 돌려, 특정 CDN 서버를 이용하게 한다.
#### Youtube
구글은 세계에서 가장 큰 video 공유 사이트를 운용하고 있으며, Netflix와 비슷하게 자사의 private CDN과 수많은 IXP, ISP에 server cluster를 생성하여 운용한다.
**하지만 Netflix와 달리 위에 설명한 Pull chaching 방법을 사용하고 있으며, cluster selection 방법으로 RTT를 측정하여 사용하되, load balancing 측면을 위해 DNS 측에서 더 먼거리의 cluster를 고르게 하기도 한다.**
DASH 대신 HTTP를 이용해 streaming 하고 있으며, 대신 유저가 알아서 화질은 선택하게 한다.
repostioning과 early termination에 의한 bandwidth와 서버 자원낭비를 피하기 위한 방법으로, HTTP byte range request를 이용하는데,
video가 특정 데이터 목표량에 도달하면, 데이터 송신을 제한하고 있다.
video upload에도 HTTP를 활용하고 있으며, google data center를 이용해 여러 화질 버전으로 변환한다.
## 2.7.Socket Programming: Creating Network Applications
network application에는 RFC 같은 정규 문서를 따른 것과, 그러지 않은 것으로 나눌 수 있으며, RFC 등을 따른다면, TCP를 기반으로 할것이냐, UDP를 기반으로 할것이냐 또한 정해야한다.
예시들은 python으로 작성된다.
### 2.7.1.Socket Programming with UDP
먼저 UDP를 이용한 client-server program을 만들어 보자.
UDP 통신에서 packet은, 목적지 host에 도착하기 위한 destination IP address와 도착 뒤, 올바른 application에 할당되기 위한 port number, 그리고 이 둘의 source address 가 header에 추가 되어야 한다.
packet에 주소를 헤더에 집어넣는 것은 코드가 아닌, operating system이 하는 역할이므로, 등장하지 않을 것이다.
우리의 프로그램의 동작은
1. Client가 글자를 입력받아 서버에게 넘겨줌
2. 서버가 받은 글자들을 대문자로 바꿈
3. 서버가 해당 문자들을 다시 클라이언트로 보냄
4. 클라이언트가 해당 데이터를 받아 디스플레이에 출력
아래에는 UDP와 socket을 이용한 활동을 보여준다.
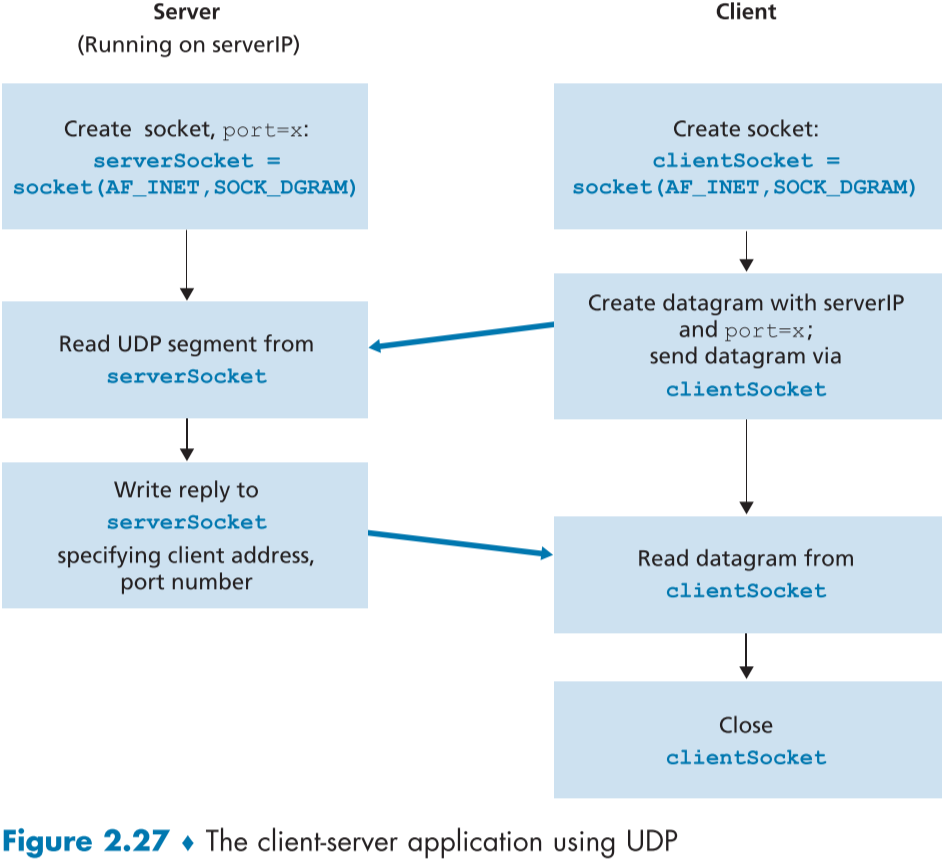
UDPClient.py, UDPServer.py를 구현하며 코드를 설명할 것이며 포트는 12000을 사용할 것이다.
#### UDPClient.py
```python
from socket import socket, AF_INET, SOCK_DGRAM # 프로그램을 위한 소켓 생성
serverName = '127.0.0.1' # 연결할 서버의 hostname 이나 IP address, 일단은 현재 이 컴퓨터로 생성
serverPort = 12000 # 연결할 서버의 포트 넘버 설정
clientSocket = socket(AF_INET, SOCK_DGRAM) # client socket 생성
# AF_INET : IPv4 사용, SOCK_DGRAM : UDP socket 사용
# clientSocket의 port 번호는 OS에서 알아서 설정해줌.
message = input('Input lowercase sentence:') # 메시지 입력값을 변수에 대입
clientSocket.sendto(message.encode(),(serverName, serverPort)) # message.encode() : string을 byte code로
# sendto() :해당 데이터를 body로 해당 서버에 보냄, 이때 source address는 자동으로 생성되므로 표기해줄 필요 없음.
modifiedMessage, serverAddress = clientSocket.recvfrom(2048) # buffer size 2048
# server로부터 응답을 기다리다가, 받은 메시지와 해당 서버의 주소 받기
print(modifiedMessage.decode()) # message byte에서 string으로 decode
clientSocket.close() # socket 닫기, client 종료
UDPServer.py
from socket import socket, AF_INET, SOCK_DGRAM
serverPort = 12000 # 생성할 서버의 포트 설정
serverSocket = socket(AF_INET, SOCK_DGRAM) # 서버 포트 생성
serverSocket.bind(('', serverPort)) # 해당 포트로 서버 생성, 앞의 ''는 hostname을 적는다.
# ''는 현재 host의 요청 중 port번호가 12000이면 모두 가져옴
print('The server is ready to receive')
while True: # 무한 루프로 계속 응답을 기다림.
message, clientAddress = serverSocket.recvfrom(2048) # serverSocket에서 응답 기다리기
print("message incoming")
modifiedMessage = message.decode().upper() # 응답 메시지의 내용 processing
serverSocket.sendto(modifiedMessage.encode(), clientAddress) # Client 측으로 되돌리기
두 파일을 실행해본 뒤 확인해보자!
2.7.2.Socket Programming with TCP
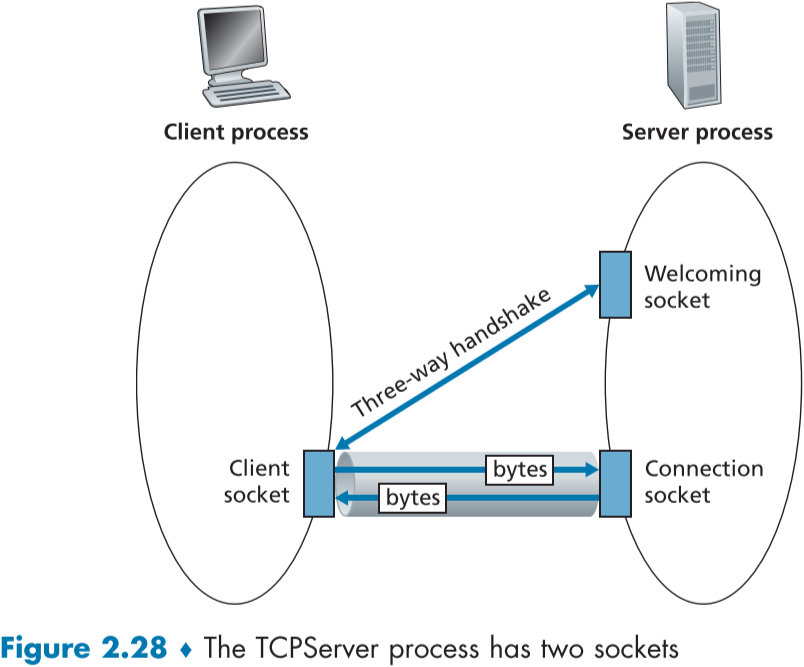
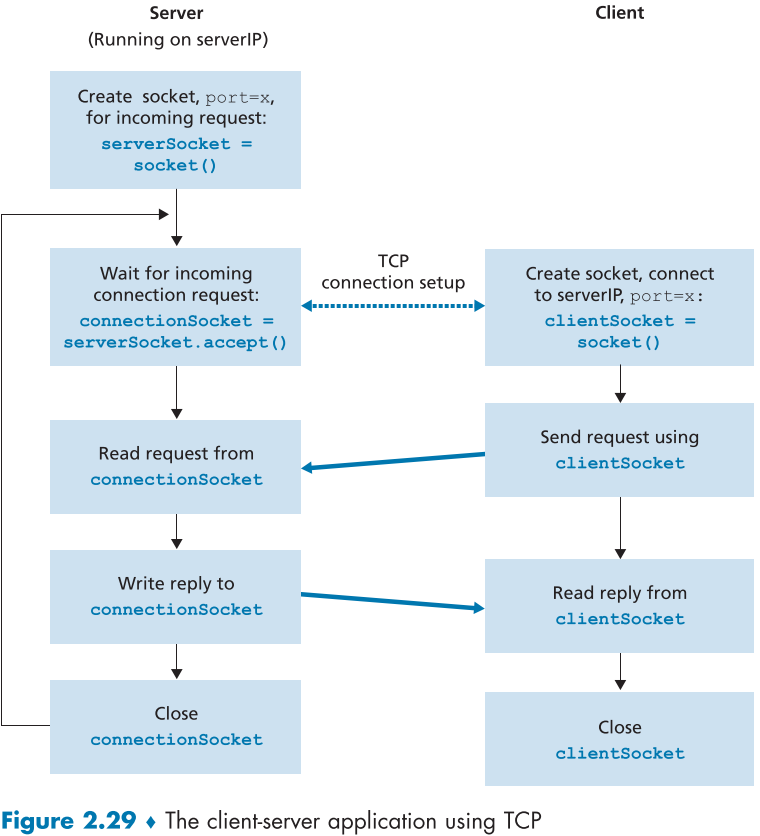
UDP와 달리 TCP는 연결 중심 protocol로, 데이터를 주고 받기전에 handshaking을 통해 소켓 간의 TCP 연결을 생성한다.
이후에는 UDP와 달리 message에 IP address를 적어주지 않고(port는 여전히 적어줌), TCP 연결이 된 host 간에 의사소통한다.
Server가 돌고 있는 중이라면, Client가 해당 sever 주소로 TCP Socket을 열고, 3-way handshaking을 실시한다.
이때의 활동은 transport layer에서 진행되며, Application 단에서는 보이지 않는다.
Client의 TCP 연결 요청이 server의 welcoming socket에 도착하면, server는 해당 client만을 위한 특별한 socket을 열어주며, 이를 connectionSocket이라 한다.
Sever가 Client와 연결을 기다리기 위해 상시 열어놓는 Welcoming socket과 Client에게 할당된 특별한 socket인 Connection Socket이 다름에 유의하여야 한다.
그렇게 생성된 TCP 연결을 통해 데이터 신뢰 전송 뿐만 아니라 상호간에 데이터를 주고 받을 수 있게 된다.
TCPClient.py
from socket import socket, AF_INET, SOCK_STREAM
serverName = 'localhost'
serverPort = 12000
clientSocket = socket(AF_INET, SOCK_STREAM) # SOCK_STREAM: TCP socket 사용 설정, 마찬가지로 source port는 os가 자동 설정
clientSocket.connect((serverName,serverPort)) # TCP connection 생성. three-way handshaking 생성
sentence = ''
while sentence != "exit": # exit input을 받을때까지 TCP 연결 유지
sentence = input('Input lowercase sentence:') # input 받기
clientSocket.send(sentence.encode()) # UDP 때와 달리 address를 붙여주지 않고, TCP connection으로 연결
modifiedSentence = clientSocket.recv(1024)# carriage return을 받을때까지 받은 input을 server측에 보냄
print('From Server:', modifiedSentence.decode())# 결과값 출력
clientSocket.close()# TCP 연결 종료
TCPSever.py
from socket import socket, AF_INET, SOCK_STREAM
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_STREAM) # TCP welcome socket 생성
serverSocket.bind(('', serverPort)) # socket address 설정
serverSocket.listen(1) # TCP connection 기다리기, 최대 1개의 connection만 가능하게 설정
print('The server is ready to receive')
while True:
print('waiting for connection')
connectionSocket, addr = serverSocket.accept() # client가 요청시 Connection socket 생성
print(f'{addr} approachs your server!')
while True:
sentence = connectionSocket.recv(1024).decode()
if sentence != "exit": # exit data가 들어올 때까지 실행하기
capitalizedSentence = sentence.upper()
connectionSocket.send(capitalizedSentence.encode())
print("send data back to client")
else:
connectionSocket.close()# connectionSocket 종료, serverSocket은 여전히 열려있으므로, 다른 Client의 접근 가능.
print(f"close connection between {addr}")
break
2.8 Summary
aplication layer의 protocol 들인 HTTP, SMTP, DNS, CDN 등에 대해서 배웠고, P2P architecutre와 client-server architecture을 구분해보았다.
또한 python socket API를 통해 가벼운 TCP, UDP 서버를 만들어 보았다.
_articles/computer_science/network/네트워크 정리-Chap 2-응용 계층.md