풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
네트워크 정리-Chap 8-컴퓨터 네트워크 보안
Chapter 8. 컴퓨터 네트워크에서의 보안(Security in Computer Networks)
- 8.1 네트워크 보안이란? (What Is Network Security?)
- 8.2 암호학의 원리 (Principles of Cryptography)
- 8.3 메시지 무결성과 디지털 서명(Message Integrity and Digital Signatures)
- 8.4 엔드포인트 인증(End-Point Authentication)
- 8.5 이메일 보안 (Securing E-Mail)
- 8.6 TCP 연결 보안화 : TLS (Securing TCP Connections: TLS)
- 8.7 네트워크 계층 보안 : IPsec과 가상 사설망 (Network-Layer Security: IPsec and Virtual Private Networks)
- 8.8 무선 랜과 4G/5G 무선 망에서의 보안(Securing Wireless LANs and 4G/5G Cellular Networks)
- 8.9 운영 보안: 방화벽과 침입 감지 체계(Operational Security: Firewalls and Intrusion Detection Systems)
Computer Networking: A Top-Down Approach(Jim Kurose, Keith Ross)의 강의를 정리한 내용입니다.
( Jim Kurose Homepage )
student resources : [Companion Website Computer Networking: a Top-Down Approach, 8/e](https://media.pearsoncmg.com/ph/esm/ecs_kurose_compnetwork_8/cw/)
1.6절에서 간단하게 인터넷 공격에 대해서 배웠지만, 대처법들에 대해선 전혀 배우지 않았으며, 이번 장에서는 인터넷 보안에 대해 자세히 배울 것이다.
앞으로 계속 사용될 앨리스와 밥 예시는 보안에서 자주 사용되는 두 사람으로 A, B를 재미있게 표현한 것이다.
초장에서는 메시지 무결성과 인증, 통신 암호와에 사용될 기본적인 암호화 기술에 대해서 배우겠다.
두번째 부분부터 그러한 기본적인 암호화 기술로 어떻게 상위 4개 계층의 네트워크 보안 프로토콜을 만드는지 알아보겠다.
세번째 부분부터 방벽, IDS 같은 운영 보안에 대해 배우겠다.
8.1 네트워크 보안이란? (What Is Network Security?)
보안있는 통신이 하고 싶다는 것은, 통신하는 와중에, 의도했던 송수신자간의 통신 내용을 어떠한 매체에 관계없이 감청당하지 않고, 변경당하지 않고, 방해받지 않도록 하지 않는 것이다.
이에 따른 보안 통신의 속성은 다음과 같다.
-
기밀성 (Confidentiality)
오직 송신자가 의도한 수신자만 전송된 내용을 이해할 수 있는 것, 메시지의 탈취자가 이해하지 못하게 암호화될 필요가 있다.
흔히 이해되는 보안 통신의 의미이기도 하다. 암호화, 복호화 기술은 8.2절부터 배운다.
-
메시지 무결성 (Message integrity)
송수신자가 주고받은 메시지가 악의적으로든, 사고로든 변경되지 않아야 한다.
이전에 배웠던 데이터 신뢰성 전송을 위한 체크섬 기술이 사용될 수 있다. 8.3절부터 배운다
-
엔드포인트 인증(End-point authentication)
송수신자는 자신의 상대방의 실제 신분을 확신할 수 있어야 한다. 눈으로 확인하면 되는 현실과 달리 인터넷 패킷 통신에서는 쉬운 일이 아니다.
엔드포인트 인증은 8.4절에 배운다.
-
운영 보안 (Operational security)
거의 모든 조직에서 인터넷과 연결된 조직망을 운영하는데, 이는 쉽게 표적이 될 수 있다.
조직망 내의 중요한 기업 비밀, 내부 인터넷 설정, DoS 공격용 좀비 피시 설정, 호스트에 웜 설치 등의 보안적 위험이 있다.
8.9절에서는 이를 막기위한 방화벽이나 침입 감지 체계에 대해서 배운다.
방화벽은 조직망과 인터넷 사이에 자리잡아 패킷의 접근과 유출을 제어하고, 침입 감지 체계는 심층 패킷 조사를 통해 의심스러운 활동이나 위험을 관리자에게 알리거나 조치를 취할 수 있다.
figure 8.1은 공격자가 취할 수 있는 행동에 대한 시나리오이다.
앨리는 밥에게 메시지를 위에서 설명한 보안 통신의 속성대로 안전하게 보내고 싶으므로,메시지는 암호화되었고, 공격자는 다음과 같은 행동을 취할 수 있다.
- 도청, 채널의 제어와 데이터 메시지를 엿듣고, 기록한다.
- 메시지나 메시지 내용의 변경, 삽입, 삭제
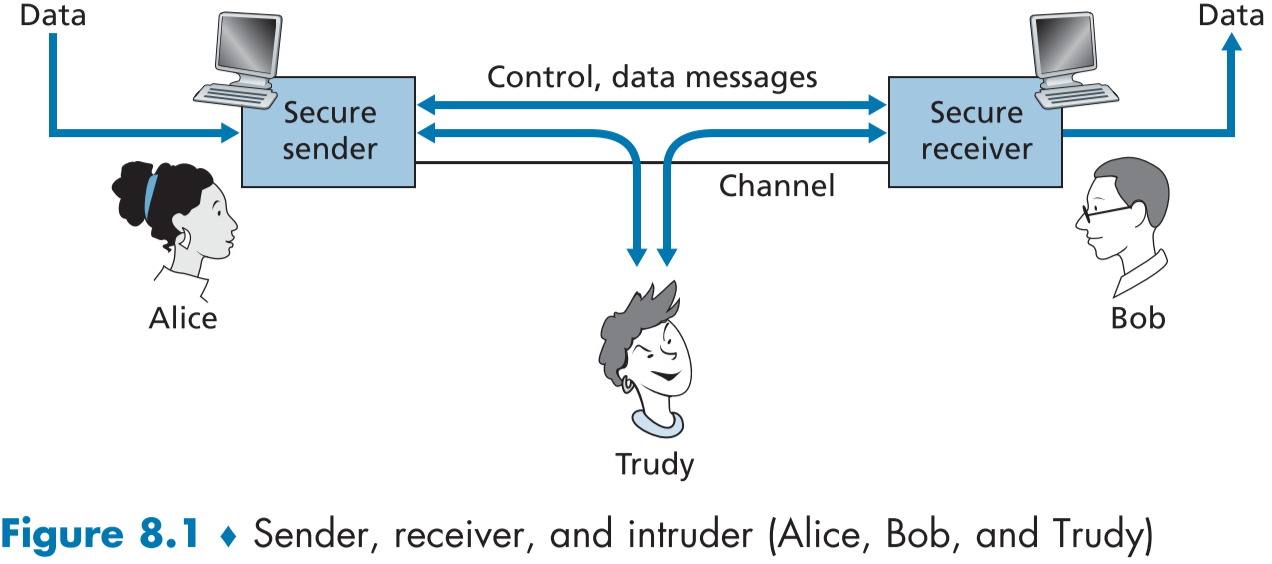
몇 가지 보안 대책을 세우지 않으면, 도청을 통한 데이터(암호, 기업기밀 등) 탈취, 다른 활동의 모방, 세션 탈취, 시스템 자원 과부화를 통한 서비스 무력화 등 다양한 보안 공격이 행해질 수 있다. 이러한 보안 공격의 종류는 CERT 조정 센터(CERT Coordination Center [CERT 2020])에서 알 수 있다.
송수신자의 안전한 통신은 단순 메시지 뿐만 아니라 네트워크 기반 기능들에도 필요하다. 예를 들어 라우팅 정보를 포함하고 있는 DNS나 라우팅 데몬들은 공격자가 DNS 룩업 표, 라우팅 테이블, 네트워크 관리 기능들을 수정, 조작하여 인터넷에 크나큰 타격을 줄 수 있다.
네트워크 보안의 중요성과 의미에 대해 알았으니, 암호화에 대해 알아보자.
암호화는 단순 기밀성 유지 뿐만 아니라 메시지의 무결성과 종단간 인증에도 사용된다는 것을 배울 수 있다.
8.2 암호학의 원리 (Principles of Cryptography)
암호의 역사는 방대하고 오래됬으므로 여기서는 일부만 다룬다.
암호는 네트워크 보안에서 기밀성 유지, 인증, 메시지 무결성, 부인 방지등에도 사용된다.
암호화된 메시지는 침입자가 탈취한 메시지로부터 아무 정보도 얻을 수 없게 변형되어있어야 하며, 송수신자는 변형된 메시지로 부터 원본 데이터를 얻을 수 있어야 한다. figure 8.2는 암호의 중요한 요소에 대해 묘사되어 있다.
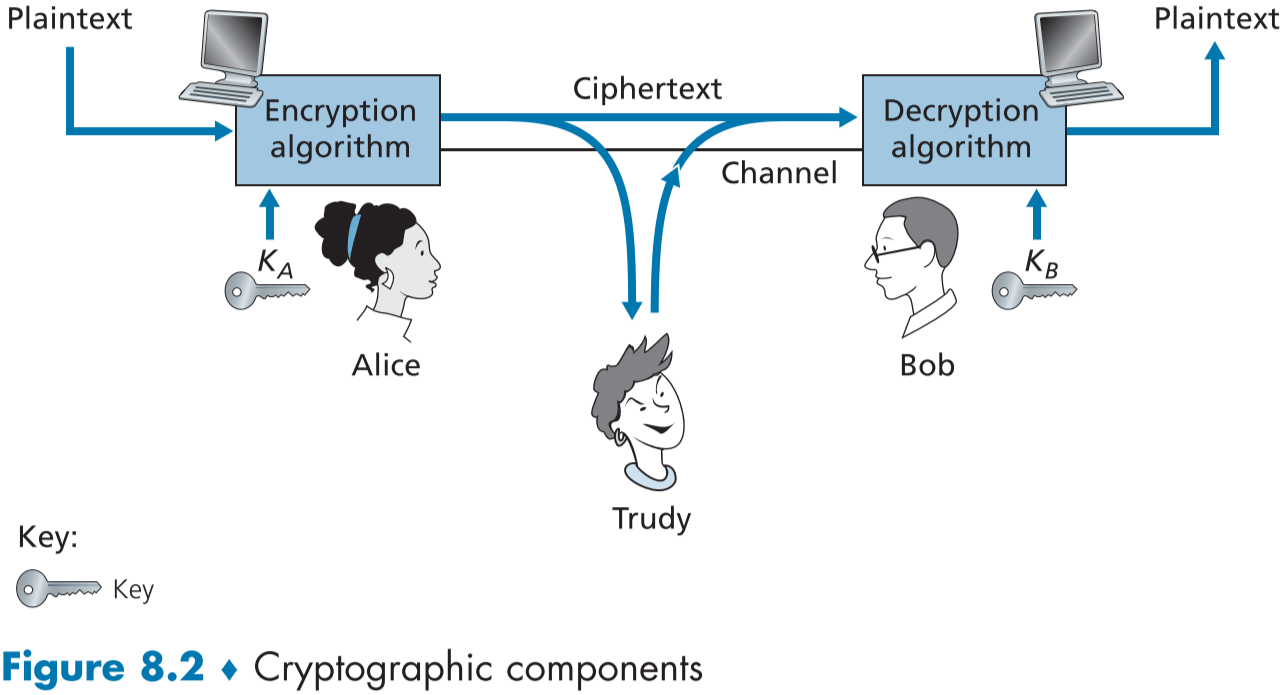
앨리스가 밥에게 보내고 싶은 원본 데이터 메시지(“I love you Bob”)은 plaintext(원문) 또는 cleartext라고 부르며, 이는 암호화 알고리즘(encryption algorithm)에 의해 암호화된 메시지, ciphertext(암호문)가 되며, 이는 침입자에겐 의미없는 문자의 나열처럼 보인다. 이러한 암호화 방법은 오픈소스로 원리까지 완벽하게 알려져있는 경우가 많으며,[RFC 1321; RFC 3447; RFC 2420; NIST 2001], 이때, 침입자가 복호화 할 수 없게, 암호화하는 데 필요한 비밀 정보를 key(키)라고 한다.
figure 8.2에서 앨리스가 숫자와 문자로 이루어진 키 $K_A$와 원문(plaintext) m를 암호화 알고리즘을 통해 암호문(ciphertext) $K_A(m)$를 내보내게 된다.
밥 또한 키 $K_B$와 암호문 $K_A(m)$을 이용해 원문 $K_B(K_A(m))=m$을 얻게 된다.
이때, $K_A$와 $K_B$에 대해서 대칭 키 체계(symmetric key systems)에서는 두 키는 동일하며 공개되지 않고, 공개 키 체계(public key systems)에서는 두 키는 서로 다르고, 키 하나는 세상에 널리 공개되어 있고, 하나는 앨리스와 밥만 알고 있다.
이 두 키에 대해 자세히 알아 보자.
8.2.1 대칭키 암호화 (Symmetric Key Cryptography)
모든 암호화 알고리즘은 무언가를 다른 것으로 대체하는 과정이 들어가 있다. 예를 들어 원문을 암호화를 통해 암호문으로 바꾸는 과정이다.
현대 암호화에 들어가기 앞서 과거의 암호화 방법인 카이사르 암호(cipher, 암호와의 한 방법)에 대해 알아보자.
알파벳의 카이사르 암호는 알파벳 순번을 k번 만큼 밀어내기하는 방법이다.. 예를 들어 k = 3이면, a 는 d, b는 e가 되는 형식이다. plaintext로 “bob, i love you”가 들어가면 암호문으로 “ere, l oryh brx”가 나오게 된다. 이는 쉽고 간편하지만 26가지의 변형만 존재하고, 누구나 금방 해독이 가능하다.
카이사르 암호에 대한 개선으로 단일 알파벳 암호(monoalphabetic cipher)가 가능하다. 각 알파벳 별로 대체 알파벳을 정한 뒤,(정확히는 각각 유일한 알파뱃으로 변환되도록 k 값을 다르게 두어) 암호화하는 방식으로, 도합 $10^{26}$가지의 암호가 가능하다. figure 8.3의 예시를 들자면, 원문 “bob, i love you”가 암호문 “nkn, s gktc wky”가 될 것이다.
브루트포스로 유추하는게 불가능할 정도로 힘들긴 하지만, 통계학적인 방법으로 쉽게 유추할 수 있는데 예를 들어, 영어 문장 중 e와 t는 가장 많이 나오는 문자이므로, 암호문 문자 중 가장 많이 나온 문자를 e와 t로 설정한 뒤, “in, ion, it, the, ing” 같은 자주 나오는 단어들을 이용해 다른 문자들 또한 쉽게 유추가능하다. 추가로 침입자가 메시지의 내용을 예상하고 있다면, 더욱 쉬워지는데, 예를 들어, 위의 문장의 “bob, i love you”에서 침입자가 해당 메시지가 밥과 앨리스의 통신이라고 알게되면, bob이나 alice라는 문자가 하나 이상 나올 것이라 예상하게 되고, 이를 이용해 nkn이 bob을 의미할 수 있다고 예측할 수 있다.
침입자가 얼마나 쉽게 암호를 해독하는 정도는 침입자가 얼마나 미리 정보를 가지고 있느냐에 따라 정해진다.
-
암호문 전용 공격 (Ciphertext-only attack)
침입자가 가로챈 암호문 이외의 정보를 가지고 있지 않은 상태이지만 통계학적 방법 등으로 암호를 해독할 수 있다.
-
알려진 원문 공격 (Known-plaintext attack)
위의 bob과 alice의 대화임을 아는 침입자처럼 만약 침입자가 일부의 (원문, 암호문) 쌍 예시를 아는 경우에는 알려진 원문 공격이라고 한다.
-
선택된 원문 공격 (Chosen-plaintext attack)
침입자가 원하는 원문 메시지에 대한 암호문 형태를 알 수 있는 경우를 의미한다. 예를 들어 침입자가 송신자에게 “abcdefghijklmnopqrstuvwxyz”를 보내게하여 이를 암호화한 문자 “mncvcxzasdfghjklpoiuytrewq”를 얻을 수 있게 한다면, 암호는 완전히 의미없게 된다. 하지만 이러한 치명적인 공격이 뚫리지 않게하는 방법이 복잡한 암호화 방법으로 존재한다.
단일알파뱃 암호화의 개선 버전으로 다중 알파벳 암호화(polyalphabetic encryption) 또한 존재한다. 기본적인 아이디어는 문자의 위치별로 다른 단일 문자 암호화를 적용하는 방식이다. 즉, 같은 문자라도 본문 내 위치에 따라 다른 문자를 가질 수 있다.
figure 8.4은 다중 알파벳 암호화의 예시로 k=5, k=19인 2개의 카이사르 암호화 $C_1, C_2$를 선정하고, 각 두 개의 암호화의 순번을 결정한다. 예를 들어 $C_1,C_2,C_2,C_1,C_2$ 로 결정한다면, 원문의 첫번째와 네번째는 $C_1$을, 나머지는 $C_2$로 암호화될 것이고, 그 이상부터는 반복될 것이다. 원문 “bob, i love you”는 암호문 “ghu, n etox dhz”로 암호화 된다.

블록 암호 (Block Ciphers)
블록 암호는 PGP(보안 이메일), TLS(보안 TCP), IPsec(보안 네트워크 계층) 같은 여러 인터넷 프로토콜이 활용하는 암호화로, 메시지는 k 비트의 블록으로 나뉘어 처리된다.
예를 들어 k = 3인 경우, 각 3비트의 원문은 3비트의 암호문으로 바꾼다는 의미이며, 이때의 암호화는 Table 8.1과 같이 입력값과 출력값의 1:1 매핑으로 되어있다.
원문 010 110 001 111 의 경우 암호문 101 000 111 001로 변한다.

또한 Table 8.1 같은 표는 도합 8! = 40320의 경우의 수를 가질 수 있으며, 이러한 매핑 표 하나를 일종의 키로 보고 송수신자가 암호화와 복호화 하는데 사용할 수 있다.
물론 위의 예시 3 비트의 경우 브루트포스로 쉽게 무력화되므로 더욱 기다란 64 비트 정도의 블록을 이용해 매핑한다. 이 경우 $2^{64}!$개의 키가 나오므로 브루트포스로 유추는 불가능하며, 아주 강력한 암호화를 제공한다.
하지만 위와 같이 전체 매핑 표를 이용한 암호화는 키를 보관하는데 필요한 공간만 $2^{64}$가 필요하므로, 이를 보관하기도, 이용해 매핑하기도, 새로 바꾸어 키를 재발급받는데도 불가능에 가까우므로, 실무에서 사용이 불가능하다.
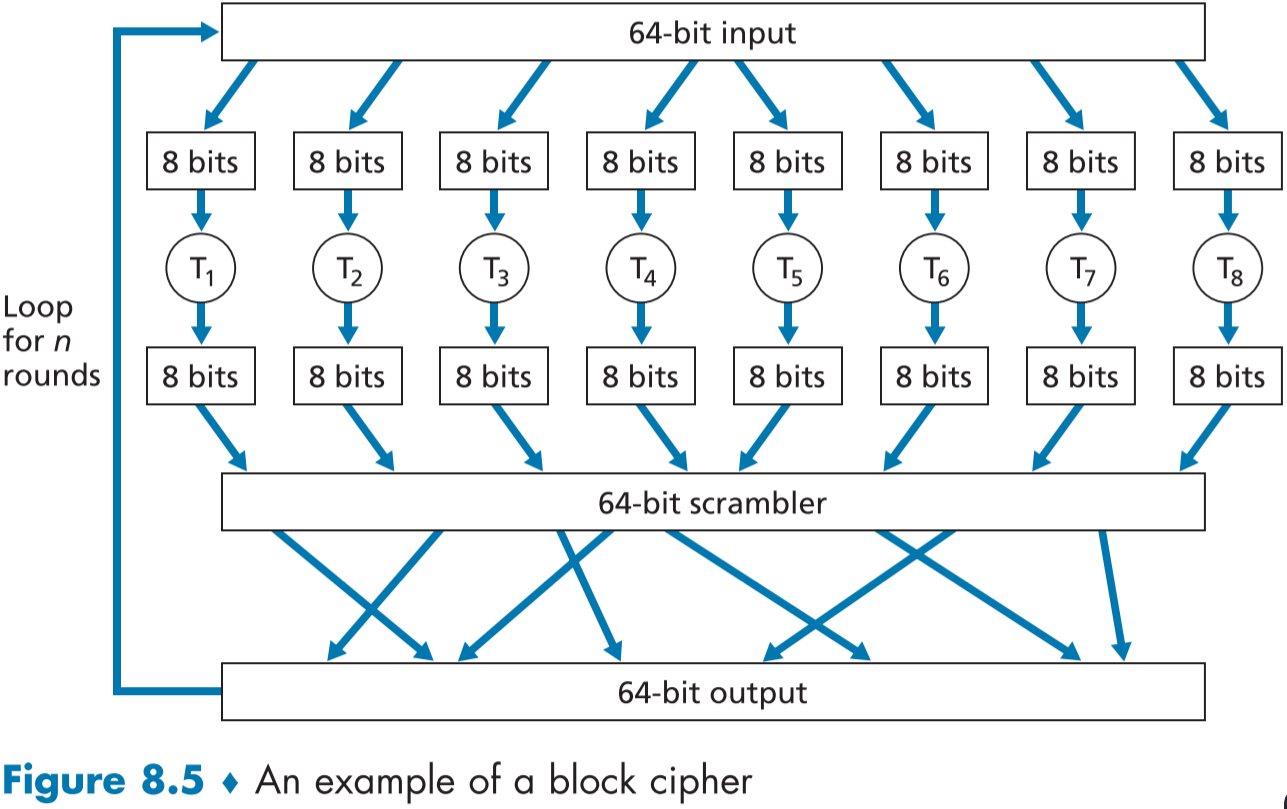
대신, 블록 암호화에서는 무작위 생성된 표를 모사(simulated)해서 사용한다.[Kaufman 2002] 예를 들어 figure 8.5에서는 64 비트를 8비트 블록 8개로 나누고, 각 블록을 8 비트 짜리 맵핑 표로 암호화한 뒤, 다시 합쳐서 64 비트 문자열로 바꾼다. 이후 공개적으로 알려진 스크램블 함수를 이용해 변형된 64 비트 결과를 만들고, 이 결과물을 다시 64비트 입력물로 되돌려 앞선 과정을 총 n번 반복한다.
이를 통해서 비교적 가벼운 8비트 맵핑 표로도 복잡한 암호화를 만들 수 있다.
이외에도 인기있는 블록 암호화로 DES(Data Encryption Standard), 3DES, AES(Advanced Encryption Standard)가 있으며, 이들은 미리 계산된 표 대신 figure 8.5 같지만 더욱 복잡한 함수를 사용하며 키로 비트들의 문자열을 이용한다.
예를 들어 DES는 64 비트 블록 암호화로 56 비트 키를 사용하며, AES는 128 비트 블록에 설정에 따라 128, 192, 256 비트 길이의 키를 사용한다. 이러한 키들은 알고림즘을 통해 각각 특정한 미니 표 맵핑과 순열을 생성할 수 있다.
이러한 키에 대한 브루트포스 공격은 사실상 불가능할 정도로 오래 걸리므로 안전하다.
암호 블록 체이닝 (Cipher-Block Chaning)
위와 같이 블록 암호화하는 경우를 ECB(electronic codebook, 전자 코드북) 방법이라고 부르는데, 이는 치명적인 단점이 있다.
바로 같은 입력의 비트 값을 암호화하면 같은 출력의 비트값이 나온다는 점이다. 이 방법이 치명적인 이유는 우리가 단일 알파벳 암호화 당시, 통계학적 방법으로 해독해낸 방법을 기억해내면 된다. 공격자는 동일하게 반복되는 비트를 통해 원본 비트를 유추해낼 수 있으며, 더 나아가 전체 블록을 해독할 수 도 있다.
이를 막기위해 각 블록마다 무작위 블록을 $\otimes$(XOR)하여 같은 값이더라도 다른 값이 나오도록 조치할 수 있다. 예를 들어 10101010 $\otimes$ 11110000 = 01011010이다.
예를 들어 $c(i)$를 i번째 암호화 블록, $m(i)$를 i번째 원본 블록, $r(i)$를 i번째 무작위 비트블록, $K_s$를 송수신자가 공유한 블록 암호화 대칭 키라고 가정하면,
송신자는 $c(i)=K_s(m(i)\otimes r(i))$로 암호화 블록을 계산한 뒤, $c(i),r(i)$를 같이 함께 수신자 측에 보낸다.
이에 수신자는 $m(i)=K_s(c(i))\otimes r(i)$를 통해 복호화할 수 있고, 탈취자는 대칭키 $K_s$가 존재하지 않으므로, 중간에 데이터를 가로채더라도 복호화하지 못한다.
또한 $m(i)=m(j)$이라고 하더라도 $r(i)!=r(j)$이므로 결과값인 $c(i)!=c(j)$가 되므로 상기한 ECB 블록 암호화의 단점은 없어진다.
하지만 이때 문제가 하나 있는데, 각기 다른 무작위 블록 $r(i)$를 매 블록마다 보내면 전송해야하는 전체 데이터양이 2배로 많아진다.
이를 해결하기 위한 방법이 암호 블록 체이닝 (Cipher-Block Chaning)이며 CBC라고 부른다.
CBC 방법에서는 데이터의 맨 처음 비트 블록 $m(1)$에 $\otimes$(XOR)할 $c(0)$ 딱 하나만 보내고, 나머지 블록들($c(n)$)은 자신의 이전 블록에서 나온 무작위 블록($c(n-1)$)을 이용한다.
자세한 방법은 다음과 같다.
- 송신자가 데이터 암호화 시작시, 무작위한 k 비트 문자열을 만들어낸다. 이를 IV(초기치 벡터, Initialization Vector)라고 하며 $c(0)$라고 표현하겠다. 이 값은 수신자에게 원문으로 보내진다.
- 이후 첫번째 블록 $m(1)$에서 $c(1)=K_s(m(1)\otimes c(0))$을 통해 암호화된 블록을 얻어낸다. 이를 수신자에게 보낸다.
- 이후 부터 i 번째 블록의 암호화 블록 $c(i)$는 $c(i)=K_s(m(i)\otimes c(i-1))$로 생성해 보낸다. 즉, 여기서 $r(i)=c(i-1)$이다.
CBC로 인한 효과로
- 수신자가 대칭키를 이용해 복호화 하는 방법은 $m(i)=K_s(c(i))\otimes c(i-1)$이며 대칭키 $K_s$, 현재 암호화 블록 $c(i)$, 이전 암호화 블록 $c(i-1)$을 전부 알고 있으므로 원본 메시지를 복호화할 수 있다.
- 두 원문 블록이 같은 값이라고 하더라도 결과는 언제나 다르게 나오게 된다.
- 침입자는 IV와 암호화된 블록들을 모두 감청해도, 대칭키 $K_s$를 모르므로 원문을 얻어낼 수 없다.
- 송신자는 암호화를 위해 IV 단 한 블록만 보내면 되므로, 오버헤드나 대역폭 추가 사용은 무시할만 하다.
CBC는 안전한 네트워크 프로토콜을 설계하는데 아주 중요하며, 이를 이용하는 프로토콜은 나중에 배우겠다.
8.2.2 공개 키 암호화 (Public Key Encryption)
공개 키 방법의 맹점은, 서로 암호화와 복호화가 가능한 공개 키를 안전한 통신을 통해 건네줘야 한다는 점이다. 보안 통신을 위해서 공개 키가 필요한데, 공개키를 주고 받으려면 중간 탈취를 막기위해 보안 통신이 필요하므로, 서로 모순적인 상황이 되버린다.
유일한 방법은 통신을 이용하지 않고, 두 송수신자가 직접 만나 공개 키를 합의하는 방법 뿐이 없을까?
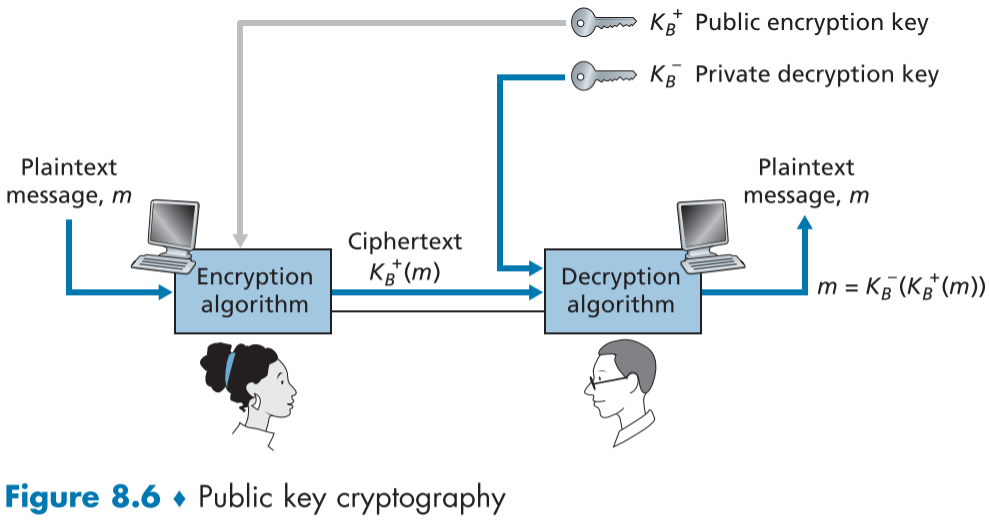
바로 공개 키 암호화(public key cryptography)로 가능하다.[Diffie 1976], [RSA 1978], [Ellis 1987] 공개키 암호는 이외에도 인증과 디지털 서명등에도 쓰인다.
공개키 암호화의 알고리즘은 아래에 배울 RSA가 대표적이며 Diffie-hellman 키 교환 방식, DSA 등이 존재한다.
Figure 8.6은 공개키 암호화의 예시이다.
밥과 앨리스는 대칭키 대신 공개키 암호화를 사용하고 있다.
공개 키는 두개의 키로 이루어져 있는데, 침입자를 포함해 모든 대중이 알고 있는 공개 키 $K_B^+$와 밥 만이 알고 있는 비공개 키 $K_B^-$가 있으며,
놀랍게도 이 둘은 서로의 암호를 상대로만 복호화 할 수 있다 즉, 원문 메시지 $m$에 대하여 $m=K_B^+(K_B^-(m))=K_B^-(K_B^+(m))$이다,
만약 엘리스가 밥에게 메시지를 보내고 싶다면, 공개 암호화 키 대중에 널린 $K_B^+$를 이용해 원문 메시지 m을 암호화하고, $K^+_B(m)$ 밥에게 보내면,
밥은 자신의 비공개 복호화키 $K_B^-$를 이용해 원문 메시지 m로 복호화한다. $m=K_B^-(K_B^+(m))$
중간의 탈취자는 공개된 키 $K_B^+$만 가지고 있으며 이것으로는 $K_B^+$로 암호화된 메시지를 복호화할 수 없다.
하지만 이때, 하나의 맹점이 있다. 만약 다른 누군가가 공개된 공개 키 $K_B^+$를 이용해 엘리스인척하고 메시지를 주고 받을 수 있다. 어떻게 엘리스가 보낸 메시지라고 확인할 수 있을까?
이것을 가능하게 하는 방법이 바로 디지털 서명(digital signature)이며, 8.3절에 배운다.
RSA
알고리즘을 고안한 Ron Rivest, Adi Shamir, Leonard Adleman 세사람의 이름의 글자를 따 명명한 RSA 알고리즘은 위의 문제를 해결한 방법 중 하나로, 현재에는 공개키 알고리즘과 거의 동시에 같이 쓰이는 중요한 알고리즘이다.
RSA는 모듈로-n 산술 연산을 이용한 방식으로, 모듈로 연산은 CRC 오류 검사 때 배웠던 것 처럼, x mod n은 x를 n으로 나눈 뒤의 나머지란 의미이다.
또한, 사칙연산과 지수연산도 가능한데 이 결과와 성질을 간단히 나타내자면 다음과 같다.
\([(a \mod n) + (b \mod n)] \mod n = (a + b) \mod n \\
[(a \mod n) - (b \mod n)] \mod n = (a - b) \mod n\\
[(a \mod n) \cdot (b \mod n)] \mod n = (a \cdot b) \mod n\\
(a \mod n)^d \mod n = a^d \mod n\)
figure 8.6 때와 같은 상황에서 RSA 암호화를 이용해 통신한다고 가정하고, 모든 비트의 나열은 숫자로 표현될 수 있음을 명심하자. 예를 들어 101은 5, 1001은 9이다. 즉, RSA 알고리즘으로 비트로 이루어진 메시지를 암호화한다는 것은 특정 숫자를 암호화한다는 것과 같다.
또한, 아래 둘은 RSA에서 서로 연관된 요소들이다.
- 공개키와 비공개키의 선택
- 암호화와 복호화 알고리즘
다음은 공개 RSA 키와 비공개 RSA 키를 생성하기 위한 밥의 행동이다.
- 아주 커다란 서로 다른 소수 p와 q를 고른다. 이때 p와 q의 값은 클 수록 보안에 좋으면 1024 비트가 권장 사항이다. 커다란 소수값을 구하는 방법은 [Caldwell 2020] 참조
- p와 q의 곱 n과 $z=(p-1)(q-1)$을 준비한다.
- 암호화에 사용될 n보다 작고 z와 1을 제외한 공약수가 없는(상대적 소수) 숫자 e를 고른다.
- 복호화에 사용될 $ed-1$이 z에 나누어떨어지는 수, d를 고른다. 이제 다음 식이 성립할 것이다. $ed \mod z = 1$
- 이제 공개키 $K_B^+$은 (n, e)이며, 비공개키 $K_B^-$은 (n,d)이다.
이제 암호화와 복호화 과정을 살펴보자면,
만약 비트 값의 정수표현이 m (m<n)인 메시지를 암호화하고 싶다면, 공개키 $K_B^+$인 (n,e)를 이용해서 $c=m^e \mod n$값을 구한다. 이 값 c는 메시지 m의 암호문이다.
수신자는 c를 받고 이를 복호화 하고 싶으면, 비공개키 $K^-_B$인 (n,d)를 이용해 $m=c^d \mod n$을 통해서 원문 메시지를 구한다.
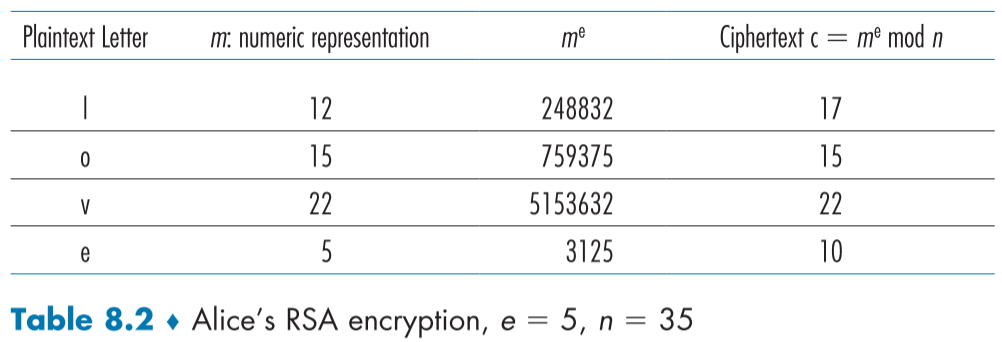

만약 p = 5, q= 7, e =5, n = 35, d = 29로 가정하고, love라는 메시지가 각 알파벳 순번으로(8비트 ASCII 표현이 좀더 현실적이겠지만) 표현할 수 있다고 가정하면 Table 8.2와 Table 8.3과 같은 암호화와 복호화를 실행할 수 있다.
커다란 소수 구하는 법, e와 d를 도출하는 법, 어마어마하게 커다란 값들을 이용해 지수연산을 하는 하는 법 등은 [Kaufman 2002]에서 알아보자.
세션 키들 (Session Keys)
상기한 거대한 값들의 지수연산이 소요되는 RSA 계산은 자원이 많이 드는 방법이므로, 실무에서는 DES, AES 같은 대칭 키 암호화와 함께 사용한다.
-
송신자가 대량의 암호화된 데이터를 보내고 싶을때, 데이터를 암호할 대칭 키 암호화에 사용할 대칭 키이자, 세션 키(session key) $K_S$를 고른다.
-
수신자의 공개 RSA 키를 이용해 세션키 $K_S$를 RSA 암호화한다. $c=(K_S)^e \mod n$
-
수신자가 송신자로 부터 RSA 암호화된 세션키 c를 받으면, 이를 자신이 가지고 있는 비공개 RSA 키로 복호화하여 세션키 $K_S$를 얻는다.
-
이때부터 송수신자간의 통신 암호화는 좀더 자원이 적게드는 세션키 $K_S$를 이용한 대칭키 알고리즘으로 진행된다
RSA이 가능한 이유는? (Why Does RSA Work?)
RSA 암호화에서 메시지를 정수 m으로 표현하고, 이를 모듈로-n 연산으로 e로 지수연산하였다.
\[c=m^e\mod n\]복호화는 이 값을 모듈로-n 연산으로 d로 지수연산을 하였으며, 해당 값은 모듈러 연산의 성질이던 $(a \mod n)^d \mod n = a^d \mod n$에 의하여, 다음과 같이 된다.
\[c^d\mod n=(m^e \mod n)^d \mod n=m^{ed}\mod n\]이번에는 소수 p와 q에 대하여 , $n=pq$이고, $z=(p-1)(q-1)$일 때, 정수론적 증명에 의해 $x^y \mod n = x(y \mod z) \mod n$이라고 한다.
\(m^{ed} \mod n = m^{ed\mod z} \mod n\)
하지만 알다시피 우리는 $ed \mod z = 1$이 나오도록(정확히는 $ed-1$이 z에 나누어 떨어지게) e와 d값을 설정했기 때문에 다음과 같이 된다.
\(m^{ed} \mod n = m^1 \mod n = m\)
이렇게 원문 메시지 값이었던 m으로 다시 되돌렸다.
우리는 e 모듈로-n 지수연산을 먼저하고 d 모듈로-n 지수연산을 실시했는데, 이를 반대 순서로, 즉 복호화를 먼저하고, 암호화를 진행해도 결과는 똑같게 나온다.
\((m^d\mod n)^e \mod n = m^{de} \mod n = m^{ed} \mod n = (m^e \mod n)^d \mod n\)
RSA 암호화 알고리즘은 두 소수의 곱으로 만든 값 n을 소인수 분해하여 두 소수 p와 q를 알아내는 방법이 없다는 가정하에 진행된다.
만약 소수 p와 q를 손쉽게 알아낼 수 있는 알고리즘이 있다면, p와 q, 그리고 공개키의 e를 이용해 비밀 키 d를 쉽게 알아낼 수 있으므로, RSA 알고리즘은 엄밀히 말해서 완벽히 보장된 보안은 아니다.
예를 들어, 양자 컴퓨터가 등장하여 빠르게 소인수분해가 가능하다면, RSA 보안은 무용지물이 될 것이다.
RSA 이외에도 Diffie-Hellman 알고리즘이라는 공개키 암호화 알고리즘이 있으며, 임의의 원하는 메시지의 길이를 정할 수 없지만, 대칭 세션 키를 수립할 때, 메시지를 암호화 하는데 사용한다.
8.3 메시지 무결성과 디지털 서명(Message Integrity and Digital Signatures)
이번 장에는 메시지 무결성(message integrity) 또는 메시지 인증(message authentication)에 대해서 알아보자
수신자가 송신자에게서 메시지를 받았을 때, 이게 보안적으로 괜찮은 메시지인지 알려면 두 가지를 증명해야 한다.
- 내가 특정한 송신자에게서 부터 온 메시지가 맞는가?
- 통신 중간에 메시지가 다른 침입자에 의해 수정되거나 바꿔쳐지지 않았나?
이는 개인간 뿐만 아니라 네트워크 전역에서 중요하게 생각하는 일이다.
예를 포워드 테이블을 생성하기 위한 라우터 간의 메시지 전파에서 가짜 라우터 메시지를 만들어, 네트워크에 혼선을 주거나 자신에게 패킷이 향하게 만들 수 있다.
그러므로, 정확히 메시지를 누가 보냈는지 구별하는 일은 정말 중요하며, 이를 알아보기 위해 가장 먼저 암호화 해쉬 함수에 대해 배워보자
8.3.1 암호화 해쉬 함수 (Cryptographic Hash Functions)
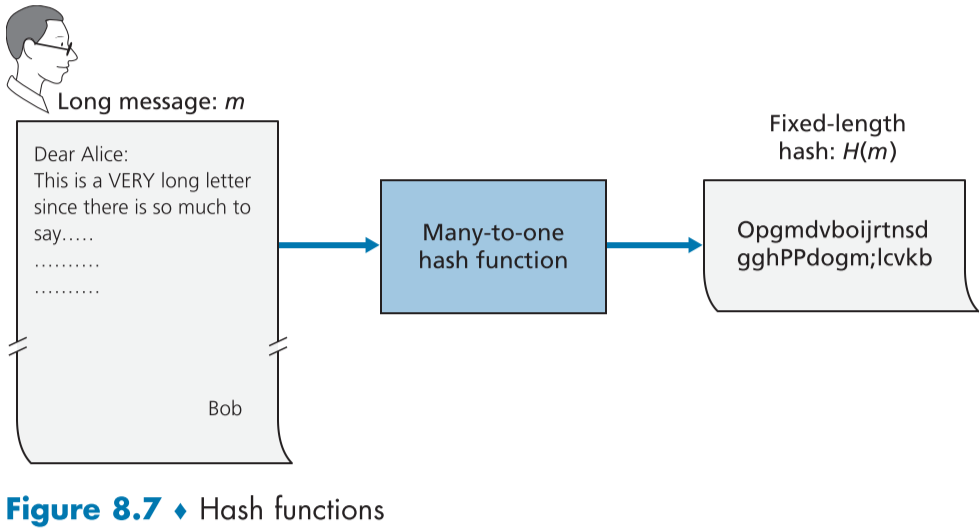
figure 8.7은 입력값 m을 받아 고정된 길이의 문자열 H(m)을 내놓은 해쉬 함수에 대한 묘사이다.
인터넷 체크섬과 CRC가 그 예시이며, 암호화 해쉬 함수는 다른 해쉬함수와 달리 다음과 같은 추가적인 특성을 충족해야한다.
- 다른 입력값 x와 y에 대하여 해쉬 결과물 H(x)와 H(y)는 언제나 달라야 한다.
이는 침입자가 메시지를 다른 메시지로 바꾸는 게 불가능하게 만든다. 만약, 결과물 H(x)가, x로도, y로도 만들 수 있다면, 칩입자는 원문 메시지를 y로 만들 수 있다.
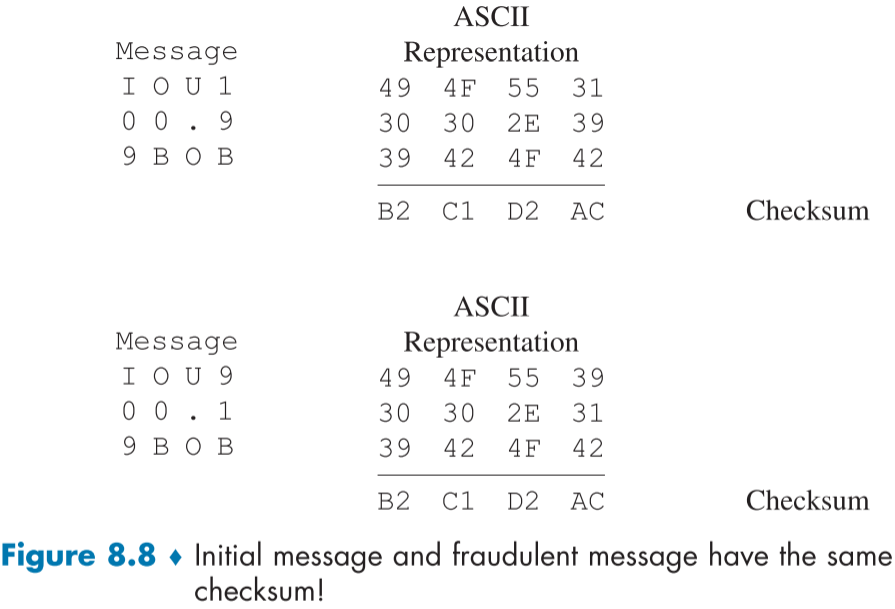
figure 8.8은 위의 특성을 지키지않는 예시로, 1의 보수를 취하지 않는 4비트 인터넷 체크섬의 예시이다.
메시지의 내용은 “IOU100.99BOB”이며, 아스키 표현으로 49,4F,55,31,30,30,2E,39,39,42,4F,42이 된다.
이를 체크섬으로 해쉬 결과물을 내놓으면 B2, C1, D2, AC가 된다.(figure 8.8 위)
또 한, “IOU900.19BOB”라는 다른 결과물을 이용해도 B2, C1, D2, AC가 되므로, 다른 내용의 메시지지만 같은 결과물이 나오게 된다.
이를 수신자가 착각하면 9배나 많은 빚을 지게 된걸로 이해할 것이며, 이러한 일을 막기 위해 강력하면서도 중복 결과값이 나오지 않는 해쉬함수가 필요하다.
MD5 해쉬 알고리즘은 4개의 단계를 통해 128 비트 해쉬를 생성하는 인기있는 해쉬 알고리즘이다.
- 패딩 단계 : 맨 앞에 1, 이후 충분한 갯수의 0이 붙어있는 패딩을 메시지 길이 조건에 맞게 붙여줌
- 삽입(append) 단계: 패딩 이전 위치에 메시지 길이의 64비트 표현을 집어넣음
- 축적 시작(initialization of an accumulator) 단계 : 16 단어 블록으로 처리
- 반복(looping) 단계 : 3번을 4회 반복
자세한 사항은 [RFC 1321]에서 참고바람.
SHA-1(안전한 해쉬 알고리즘 Secure Hash Algorithm) 또한 MD4(MD5 이전 버전)와 비슷하면서 인기가 많은 160 비트 길이 미 연방 표준 알고리즘이다.
8.3.2 메시지 인증 코드 (Message Authentication Code)
먼저, 흠이 있는 메시지 무결성을 보장하는 단계에 대해 설명해보자면,
- 송신자가 메시지 m을 만든 뒤 해쉬 결과값 H(m)을 가져온다.(ex. SHA-1)
- H(m)을 메시지 m에 붙여 더욱 기다란 메시지 (m, H(m))을 만든 뒤, 수신자에게 보낸다.
- 수신자는 받은 메시지 (m, H(m))을 통해 H(m) = h임을 확인해보고, 맞다면 확인 처리 한다.
이 방법은 3번에서 칩입자가 m 대신 악의적인 메시지 m`을 이용해서 (m`,H(m`))으로 바꿔 보내도 수신자는 눈치 채지 못하므로 안전하지 않다.

이를 막기위해 송수신자간에 공유하는 새로운 비밀 키 s가 필요하며 이를 인증키(authentication key)라고 부른다. 이를 이용한 새로운 방법은 아래와 같으며, 묘사는 figure 8.9에 나와있다.
- 송신자는 메시지 m과 인증키 s를 합쳐 m+s를 만들고, 이를 해쉬 함수를 통해 H(m+s)로 만든다. 이때 H(m+s)를 MAC(message authentication code, 메시지 인증 코드)라고 한다.
- 연결 계층의 MAC(media access cotnrol) 주소나, 공유 채널 접근 프로토콜인 MAC(medium access control)과 헷갈리지 말자.
- MAC와 m을 합쳐 늘어난 메시지 (m, H(m+s))를 만들어서 수신자에게 보낸다.
- 수신자는 (m, H(m+s)) 메시지를 통해 m에 자신이 가지고 있는 인증키 s를 합친 뒤, H(m+s)를 계산해 보아 일치하면 확인 처리 한다.
MAC 방법의 장점은 MAC을 위한 별도의 암호화가 필요 없어서 복잡하거나 자원이 많이드는 처리가 필요없다는 점이다.
가장 인기있는 MAC은 HMAC이며, MD5, SHA-1같은 해쉬 알고리즘과 함께 사용할 수 있으며, 심지어 해쉬 과정을 두번 거치게 할 수 있다.
상기했던 라우터 간의 네트워크 정보 교환에도 라우터 간에 같은 인증키를 공유해서 MAC 절차를 이용해서 통신한다.
이때, 라우터를 설치하는 네트워크 관리자가 일일이 인증키를 설정해주거나, 아니면 앞서 배웠던 공개키 암호화 알고리즘을 이용해서 인증키를 주고 받는다.
8.3.3 디지털 서명 (Digital Signatures)
디지털 서명(digital signature)는 수기 사인처럼 검증 가능하고 위조 불가능한 디지털 암호적인 방법으로 자기 자신을 증명하는 방법이다.
디지털 서명은 개인에게 유일하여야 하니, 두 사람이 같은 인증키를 공유해야하는 인증키 방식은 옳지 않다. 공개키 방식에서는 공개되어있는 공개키와 개인만 알고 있는 개인키로 나눠져 있고, 이 비공개키는 디지털 서명의 좋은 후보가 될 수 있을 것 같다.

아래 figure 8.10에서 공개키 방식의 개인키를 이용한 디지털서명의 예시이다.
-
이때 송신자는 전송 전에 개인키를 이용해 원문 m을 암호화 하여 사인된 메시지 $K_B^-(m)$을 원문 메시지와 짝인 (m, $K_B^-(m)$)로 만들어 전송한다.
- 비공개키로 암호화는 것이 미심쩍다면, 공개키 방식에서 공개키와 비공개키는 서로 암호화하고 복호화할 수 있는 관계였음을 떠올리자.
-
수신자는 $K_B^-(m)$를 송신자의 공개키$K_B^+$로 이용해 복호화해보고, 원문 메시지 m으로 복호화된다면 송신자가 보낸 것이라는 증명이 된 것이다.
추가로, 침입자가 탈취하여 m 대신 m`라는 메시지로 바꾸어 보내려고 해도, 개인키 $K_B^-$가 없다면 $K_B^-({m}’)$를 만들 수 없고, 메시지 무결성 또한 증명된다.
하지만 이 방법의 단점은 암호화와 복호화 과정은 자원이 너무 많이 드는 방법이라는 점이다. 이를 위해 위에서 사용했던 해쉬 함수 기능을 이용할 수 있다.
메시지 전체(m)을 암호화($K^-_B(m)$)하는 대신 생성된 해쉬값($H(m)$)을 암호화($K_B^-(H(m))$)하면, 원문에 비해 상대적으로 길이가 짧으므로 드는 비용이 크게 줄어든다.
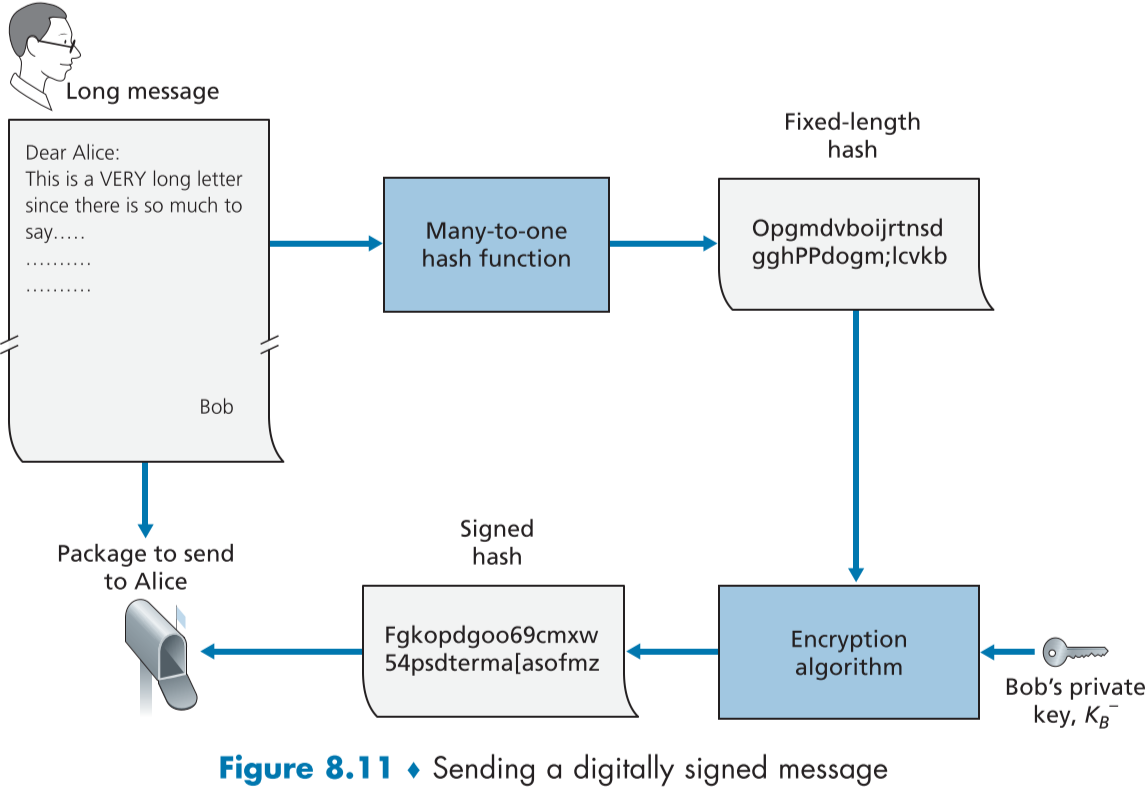
figure 8.11은 디지털 서명 생성의 절차를 묘사한 것이다.
밥은 원문 메시지를 해쉬함수로 처리한 결과물에 자신의 개인키를 이용해 디지털 사인을 한다.
디지털 사인을 한 결과물과 원문 메시지를 함께 붙여 앨리스에게 보낸다.
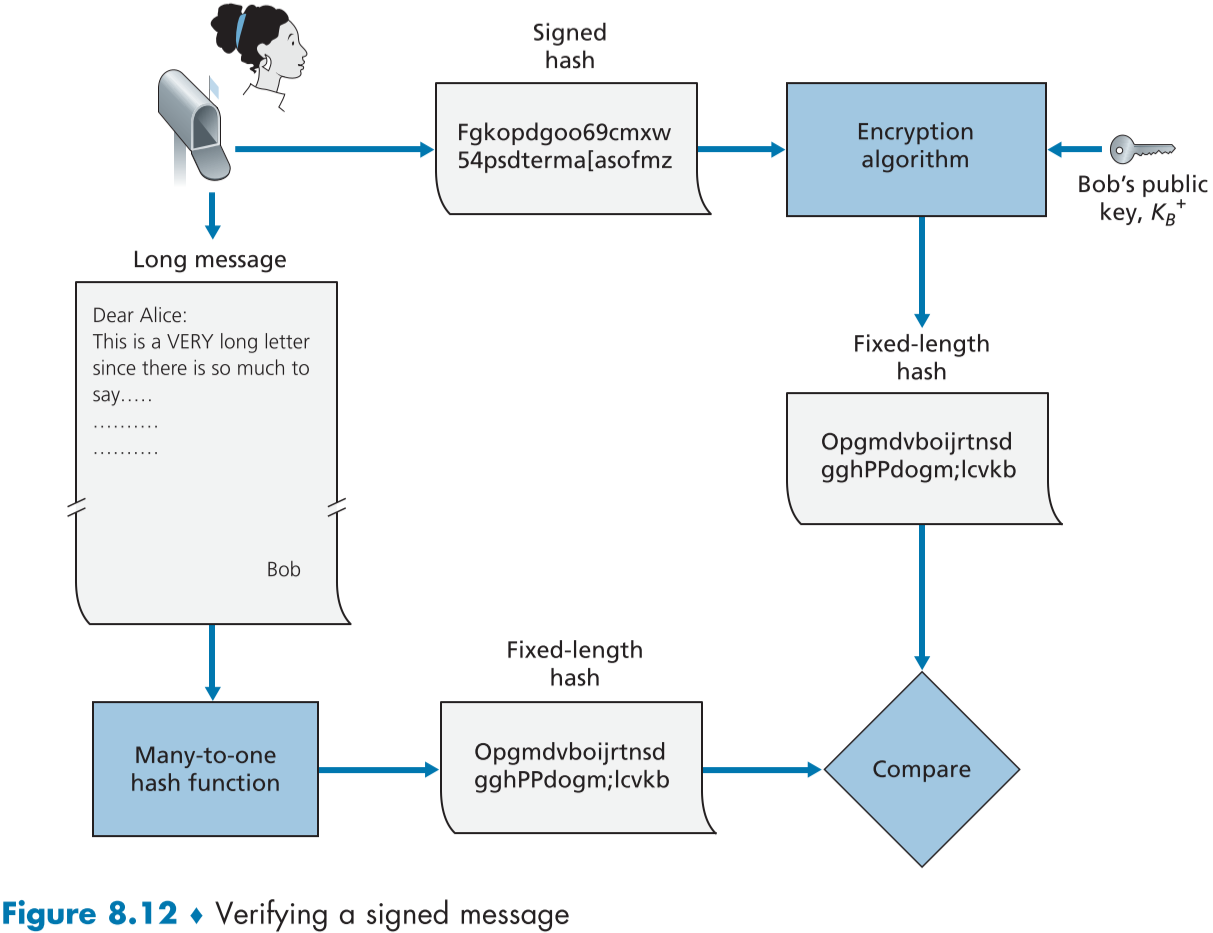
figure 8.12는 디지털 서명의 증명 절차를 묘사한 것이다.
앨리스는 받은 메시지의 원문 m 부분에 해쉬함수를 적용해 $H(m)$을 얻어낸 뒤, 밥이 보낸 메시지의 암호화된 부분을 밥의 공개키로 복호화 해본다,
이렇게 얻어낸 결과과 $H(m)$과 같다면 메시지 무결성이 확인된다.
넘어가기 전에, MAC 방법과 디지털 서명법을 비교해보자면,
MAC을 메시지로 부터 만들어내기 위해, 인증키를 메시지에 붙이고, 해쉬 결과 값을 취한다. 이때 대칭키도, 공개키도 사용하지 않는다.
디지털 서명에서는 메시지의 해쉬값을 개인키로 대칭키 암호화를 적용한다. 디지털 서명법은 좀더 오버헤드가 큰 작업으로, 추가적인 인증된 기관의 PKI(Public Key Infrastructure, 공개 키 기반)이 필요하다.
나중에 알아볼 PGP(보안 이메일)은 디지털 서명을 사용하고, OSPF(라우팅 알고리즘)는 MAC을 이용한다.
이외에도 MAC은 여러 인기있는 프로토콜에 사용된다.(8.5, 8.6절 참조)
공개 키 증명 (Public Key Certification)
디지털 서명의 중요한 응용 프로그램으로 특정 개체의 공개키를 보증해주는 공개 키 증명 (Public Key Certification)이 있으며, TLS나 IPsec 같은 여러 프로토콜이 활용한다.
공개키 증명이 필요한 이유는 아래 figure 8.13을 통해서 증명한다.
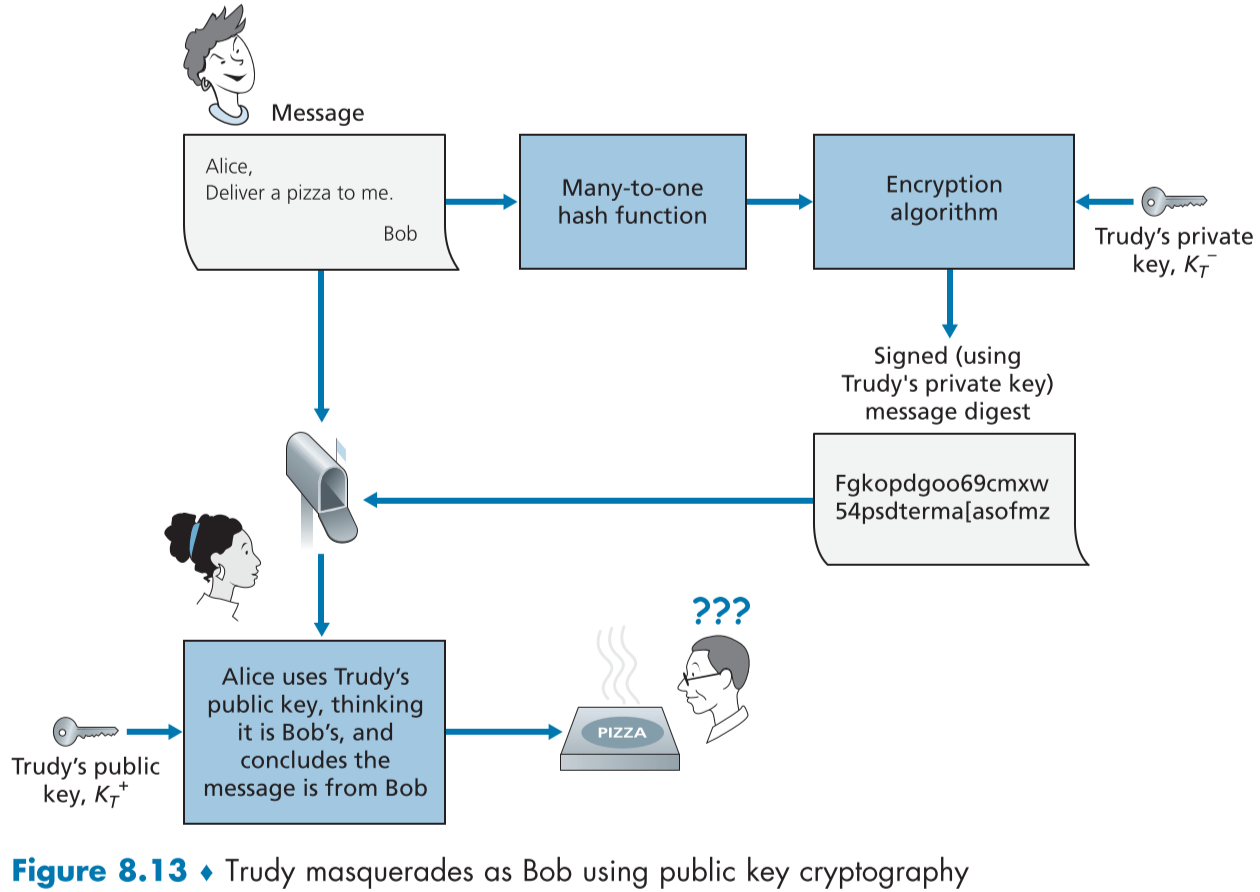
인터넷 피자 가게를 운영하는 앨리스에게 트루디가 장난 전화를 거는 상황이다.
트루디가 앨리스에게 자신이 밥이라는 사람이고, 피자를 주문하고 싶다고 메시지를 디지털 서명을 이용해 보낸다.
그리고 이를 증명하기 위해 트루디는 자신의 개인키와 쌍을 이루는 공개키를 밥의 공개키라고 속이고 첨부한다.
앨리스는 해당 디지털 서명이 첨부된 공개키를 이용해 풀리니 밥이라고 확인하고 밥에게 피자를 배달했지만, 밥은 모르는 일이다.
위를 통해, 해당 공개키가 실제로 송신자의 공개키인지 증명할 필요가 있다는 것을 깨달았을 것이다.
이렇게, 특정 개체의 공개키를 증명해주는 기관이 CA(Certification Authority, 인증기관)이며, 공개키의 유효성을 검사하고 인증서를 발급해주며, 정확한 역할을 다음과 같다.
-
CA는 각 객체(사람, 라우터, 기관 등)가 자신이 주장하는 그 객체가 맞는지 증명한다. 이러한 증명 방법에는 의무적인 절차가 없으므로, 만약 어떤 CA가 단순히, 그 객체가 “나는 OO이야, 니가 증명해줘”라고 주장했다는 이유로 적절한 절차없이 증명서를 발급해준다면, 그러한 CA는 믿으면 안된다. 즉 CA의 인증서를 믿는 다는 것은 CA, 더나아가 CA의 증명 절차를 믿는다는 의미이다. 보통 CA는 엄격한 보안 기준과 일정 이상의 규모를 인증해야 CA로 인정된다.
-
CA가 객체의 정체성을 증명했다면, CA는 해당 객체와 공개키를 짝지어주는 인증서(certificate)를 만든다. 인증서에는 공개키와 객체에 대한 전세계적으로 유일한 정보(이름, IP 주소 등), 인증 기관명 등이 적혀있다. 이러한 인증서는 CA가 디지털적으로 사인하였다.
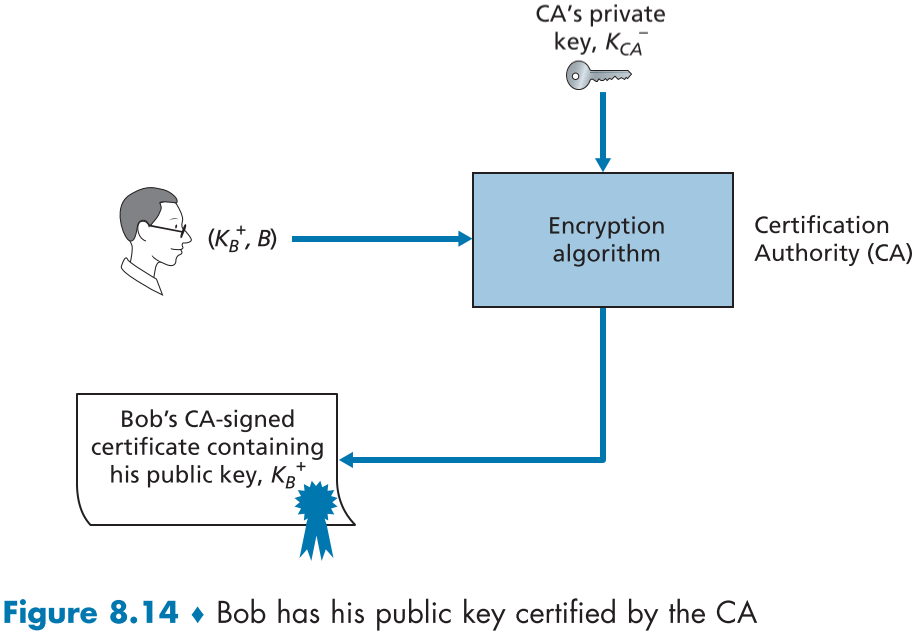
이제 CA에 인증된 밥이 피자를 배달하는 과정을 알아보자.
밥이 디지털 서명으로 암호화된 메시지를 보낼때, CA 인증서를 첨부해서 보낸다.
앨리스는 해당 CA 인증서에 첨부된 증명서를 보고 CA 내부의 공개키로 디지털 서명을 해독해보고, 원문 메시지와 같음을 보고 밥임을 확신한다.
만약, 트루디가 역시 장난을 치려하고 있고
-
트루디가 밥이라고 주장하며 아무런 인증서 없이 자신의 공개키를 보냈다면, 앨리스는 인증서가 없으니 믿지 않을 것이고,
-
밥의 CA 인증서를 가져와 메시지를 보낸다면, 앨리스가 CA 인증서 공개키를 사용해서는 트루디의 개인키로 디지털 서명된 암호화를 해독할 수 없으니 역시 믿지못한다.
-
밥의 개인키를 해킹으로 탈취해서 디지털 서명한 뒤, 밥의 CA 인증서를 보냈다면, 그것은 개인키 관리를 못한 밥의 잘못이다.
-
트루디가 CA의 데이터베이스를 해킹해서 밥의 인증서에 자신의 공개키를 넣도록 하였더라면, 트루디는 디지털 포렌식을 통해 추적되어 미 연방 1급 교도소에 갈 것이다.
ITU(International Telecommunication Union)와 IETF는 CA를 위한 엄격한 기준을 가지고 있으며, 키 관리 구조의 절차 및 의례에 대해 적인 ITU X.509 [ITU 2005a]은 인증을 위한 서비스와 정확한 구문을 정의하며, [RFC 1422]에는 보안 이메일을 이용한 CA 기반 키 관리에 대해 적혀있다.
Table 8.4는 인증서의 필드에 대해 설명한다.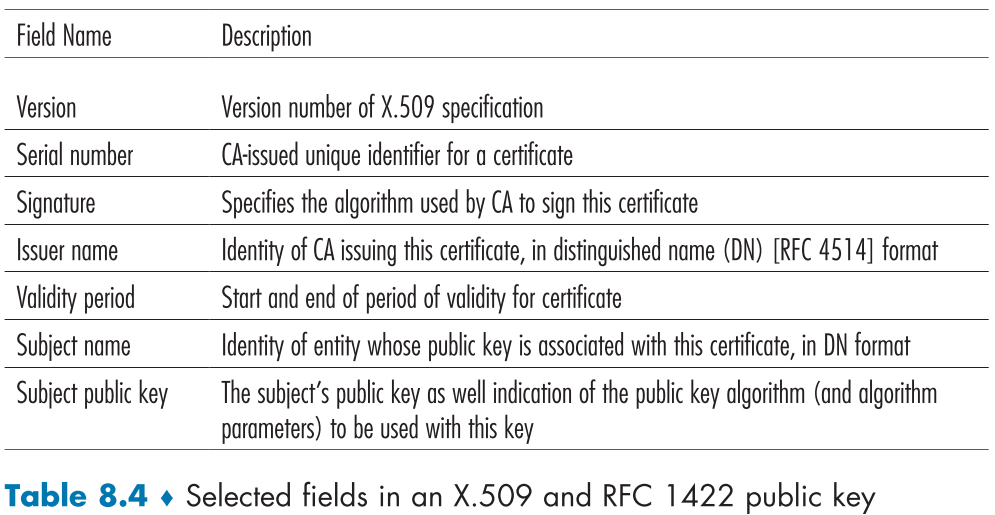
8.4 엔드포인트 인증(End-Point Authentication)
엔드포인트 인증(End-Point Authentication)은 한 객체가 다른 객체에게 자신의 정체를 증명하는 절차이다.
인간은 서로를 목소리, 얼굴, 증명사진 등을 통해 증명한다.
우리는 여기서, 이러한 네트워크 상에서의 실제로 통신하는 객체가 서로를 인증하는 법에 대해서 살펴본다.
예를 들어 이메일 서버에서 사용자의 인증이다.
이러한 인증은 라우터 간이나 클라이언트-서버 간에서도 필요하며, 인증(authentication) 프로토콜의 절차 내의 메시지와 데이터의 교환을 통해 이루어진다.
보통 이런 인증 프로토콜은 다른 프로토콜들(이메일 프로토콜, 데이터 신뢰성 전송 프로토콜)을 이용하기 전에 먼저 서로의 정체를 수립하기 위해 이루어진다,
전에 RDT 프로토콜에 배웠던 것 처럼 절차적으로 진화하는 프로토콜을 설명하는 방식으로 설명하겠다.
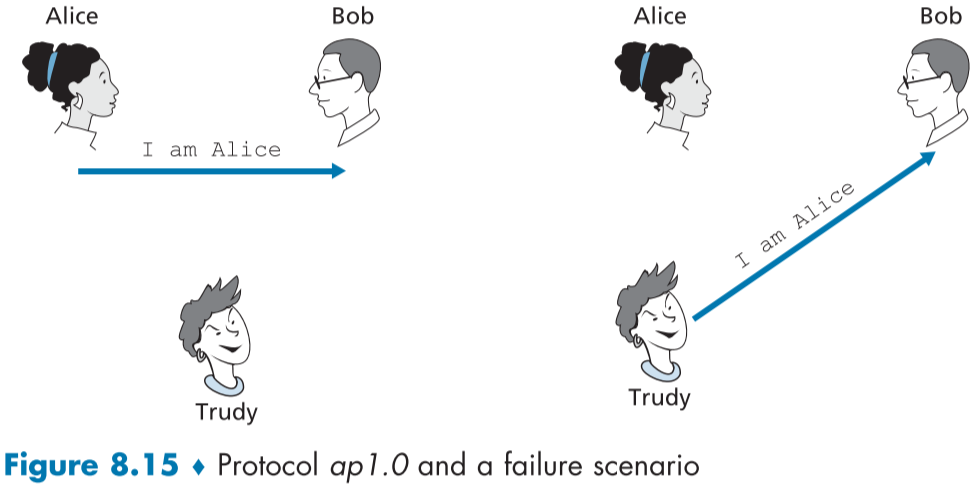
figure 8.15 묘사에서 엘리스는 밥에게 자신을 증명해야하며, 가장 간단한 방법은 자신이 앨리스임을 메시지로 보내는 것이다.
이 방법의 단점은 트루디(침입자)가 자신이 앨리스라고 주장할 수도 있다는 점이다.
분명, 다른 방법이 필요하다.
인증 프로토콜 ap2.0 (Authentication Protocol ap 2.0)
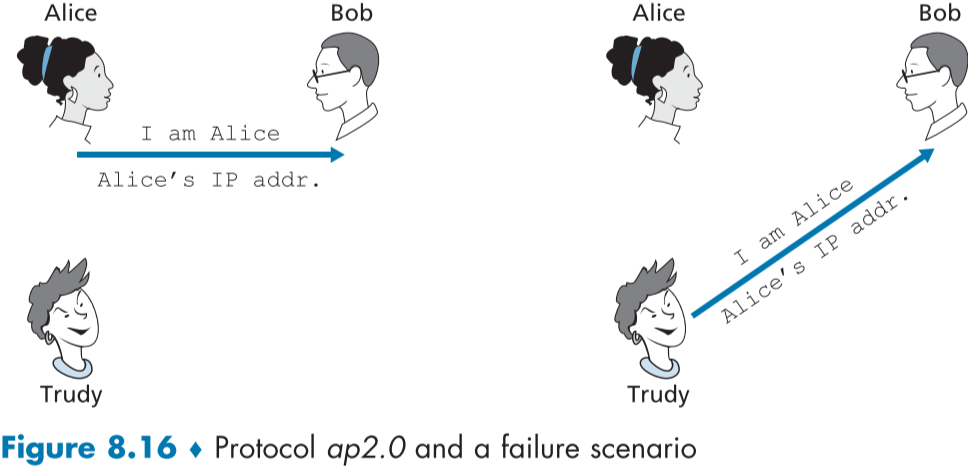
만약 figure 8.16처럼 앨리스가 잘 알려진 자신만의 IP 주소를 발신지 IP 주소로 첨부해서 보낸다면 어떨까?
아쉽게도, IP 데이터그램을 생성하고 조작하는 일은 그렇게 어려운 일이 아니다. 그저 오픈소스 리눅스 운영체제의 코드를 고치고, 자신만의 운영체제 커널을 만든 뒤 원하는 헤더 필드를 가진 데이터그램을 만들어 보내면 된다.
이렇게 IP 데이터그램을 조작해 보내는 공격을 IP 스푸핑(IP Spoofing)이라고 한다.
트루디는 자신의 IP 데이터그램에 잘알려진 앨리스의 IP 주소로 발신지 IP 주소를 수정해서 보내면 된다.
몇 몇 최신 라우터는 이러한 IP 스푸핑 조작을 막게 하기 위해, 보내온 IP 데이터그램 발신지 IP 주소가 실제와 다르면 막게 하는 경우도 있지만, 모든 라우터가 최신 버전이 아닐 수도 있으며, 공격자 본인이 라우터의 설정을 건들 수 있다면 무력화할 수 있다.
분명, 다른 방법이 필요하다.
인증 프로토콜 ap3.0 (Authentication Protocol ap 3.0)
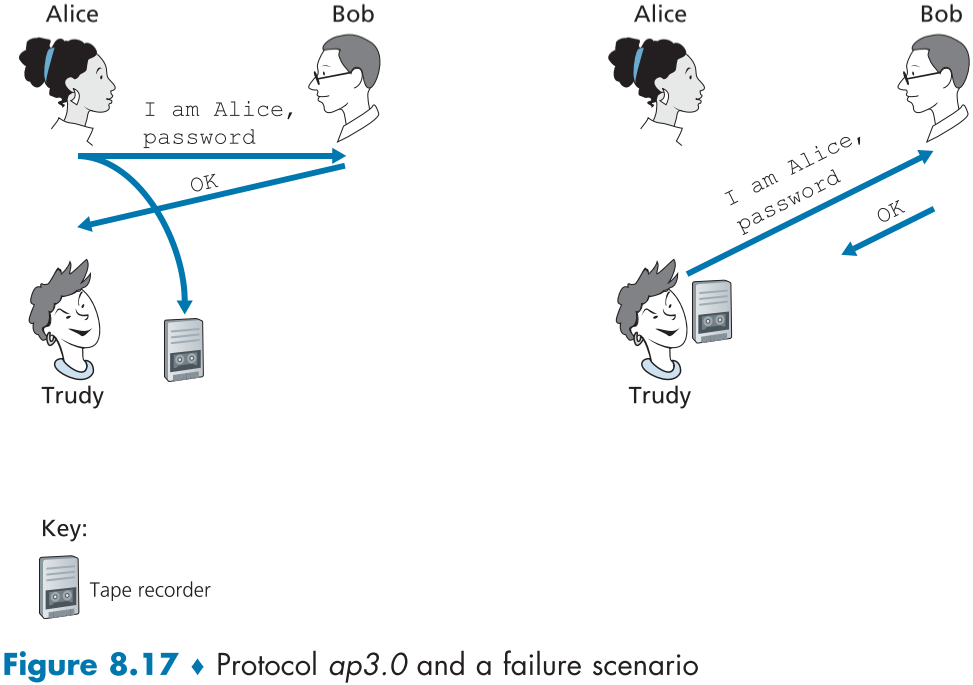
비밀 번호를 활용하는 방법이 존재한다. 비밀번호는 객체와 인증 객체 사이만 공유하는 인증을 위한 번호이며, Gmail, Facebook, telnet, FTP 등 여러 서비스에서 이용 중이다.
우리가 만든 인증 프로토콜 3.0 버전은 앨리스는 밥과 자신만이 공유하는 비밀번호를 메시지에 첨부해서 보내고, 밥은 이 비밀번호를 공유 받은 앨리스의 비밀번호와 비교해 앨리스임을 확신한다.
하지만 이번엔 트루디가 중간에 메시지를 도청해서 가로채어 비밀번호를 알아버렸다. 이제 트루디는 해당 비밀번호를 첨부해 밥에게 메시지를 보내면, 앨리스로 변장할 수 있다.
실제로 운영체제 원격 제어를 위한 Telnet 프로토콜은 이런식으로 비밀번호를 암호화하지 않고 보내기 때문에 서버나 클라이언트 LAN에 연결된 다른 침입자가 패킷을 sniff하고 변장하여 로그인할 수 있다. 이로 인해 오래되고 위험하고 구식이었던 Telnet은 더이상 사용하지 않고 SSH 프로토콜로 대체되었다.
분명, 다른 방법이 필요하다.
인증 프로토콜 ap3.1 (Authentication Protocol ap 3.1)
이번에는 비밀번호를 대칭키로 암호화하여 전달하면 트루디가 메시지를 도청해도 이해할 수 없을 것이다.
앨리스와 밥이 대칭키$K_{A-B}$를 공유한다고 가정하고, 비밀번호를 암호화하고 보내면 된다. 이를 인증 프로토콜 3.1이라고 하자!
이제 트루디가 도청했지만, 대칭키를 가지고 있지 않은 트루디는 비밀번호 부분을 해독할 수 없고, 이해할 수 없다.
하지만 상관없다. 트루디는 원하는 메시지를 적고 암호화된 비밀번호를 그대로 첨부해서 보내면 된다.
밥은 암호화된 비밀번호를 해독하고 비교해보고, 같다는 것을 깨닫고 앨리스로 착각한다.
이런 식으로 암호화된 정보를 해독하지 않고 재이용하는 방식을 플레이백(playback) 공격이라고 한다.
우리의 ap 3.1 프로토콜은 공격자가 암호화된 정보를 해독하지 않고 재이용하는 플레이백 공격에 의해 무력화되었다.
분명, 다른 방법이 필요하다.
인증 프로토콜 ap 4.0 (Authentication Protocol ap 4.0)
상기한 실패들은 잘 생각해보면 송신자가 현 시점에서 서로 인증한 뒤 실시간으로 통신을 진행 중인지, 아니면 이전에 진행했던 인증을 (공격자가) 재사용한 메시지인지, 알 수 있으면, 해결할 수 있다.
TCP 연결을 예시로 들면, TCP 핸드셰이크 당시, 이전 TCP 연결이 사용하던 오래된 SYN 값은 더이상 사용하지 않으며, 만약 예전 SYN 값을 가진 세그먼트가 온다면 무시하게 된다. TCP 서버는 연결 시, SYN 값을 이전 연결에서 한번도 사용한적 없거나, 아주 오래전에 사용했던 SYN 값을 지정해 클라이언트에 보내고, 클라이언트는 해당 SYN 값을 ACK 세그먼트에 넣어 보낸다.
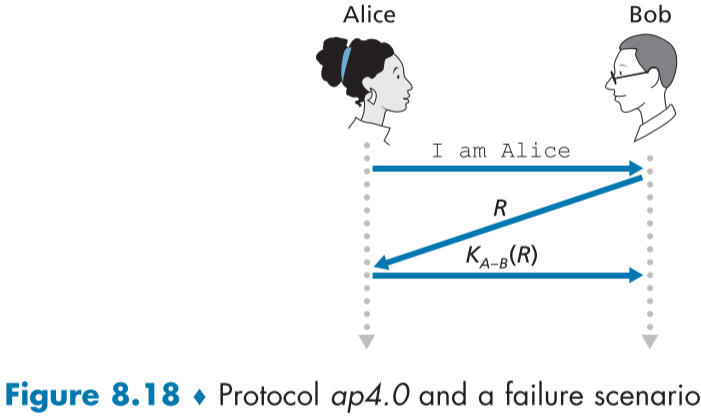
이를 우리의 인증 프로토콜에 사용하기 위해 nonce(넌스)를 사용해보자,
넌스(nonce)는 프로토콜에서 재활용이 불가능한 일생동안 단 한번만 사용가능한 값으로, 매 통신 시작시마다 주어진다.
figure 8.18의 과정을 설명해 보자면,
- 앨리스는 자신이 앨리스라고 밥에게 알린다.
- 밥은 넌스 값 R을 생성하고 암호화하지 않고 앨리스에게 보내준다.
- 암호화하지 않는 이유는 암호화할 필요 없기 때문이다.
- 앨리스는 넌스 값 R을 미리 고유했던 대칭키 $K_{A-B}$로 암호화하고, 다시 밥에게 보낸다.
- 밥은 이를 복호화하고, 넌스 값 R과 일치하면, 현재 엘리스가 실시간으로 통신 중이라고 알 게 된다.
- 이 암호화 복호화 과정을 통해 2번에서 보냈던 넌스 값 R을 탈취해서 보낸 공격자를 구분할 수 있다.
- 넌스 값이 방금 보낸 것이라는 것을 통해, 현재 실시간 통신 중이라고 생각할 수 있다.
통신이 종료된 후, 밥이 복호화시 과거에 사용했던 R 값이면 이전 암호화된 R값을 탈취해서 모방하고 있는 공격자이다.
대칭키 대신 공개키 암호화를 사용하면 어떨까? 그 해답은 이번 장의 끝부분에 나온다.
8.5 이메일 보안 (Securing E-Mail)
앞으로 PGP, TLS, IPsec이 속하는 응용 계층, 전달 계층, 네트워크 계층 순으로 보안 프로토콜에 대해 알아볼 것이다.
기본적으로, 아래 계층이 제공한 기능은 위 계층들이 모두 누리게 된다. 예를 들어 응용 계층의 보안 프로토콜은 해당 프로토콜을 적용한 응용 프로그램만 보안을 누리지만, 연결 계층에서 적용된 보안 프로토콜은 해당 프로토콜을 기반으로 하는 그 위의 네트워크 계층, 전달 계층, 응용 계층의 모든 프로토콜과 응용 프로그램이 보안을 누리게 된다.
하지만 그럼에도 불구하고 응용 계층, 전달 계층, 네트워크 계층 같은 상위 계층에 따로 보안 프로토콜이 필요한 이유는
첫번째, 좀더 세세한 사용자 수준의 보안을 제공하기 위해 상위 계층 프로토콜이 필요하다.
예를 들어 특정 IP가 보낸 것을 보장 하는 네트워크 계층 프로토콜이 있다고 해도, 해당 호스트를 이용한 다른 사람이 똑같이 쇼핑몰 계정을 공유하면 큰일 날 것이다. 쇼핑몰 계정을 나누기 위한 응용 계층 보안 프로토콜이 필요하다.
둘째, 낮은 계층의 보안 프로토콜의 개발과 기능 갱신을 기다리는 것보다 자신의 응용 프로그램에 맞고, 빠르게 개발되는 상위 계층의 프로토콜이 필요할 수 있다.
PGP (Pretty Good Privacy, 꽤 좋은 프라이버시)는 처음으로 널리 퍼진 보안 이메일 기능을 제공하는 보안 프로토콜이며, 이번 절에서 배워볼 것이다.
8.5.1 안전한 이메일 (Secure E-Mail)
안전한 이메일을 설계하기 위해 지금까지 배워왔던 보안의 기초와 밥과 앨리스, 트루디를 사용하자.
우리는 기밀성(아무도 내용을 알수 없게), 송수신자 인증(내가 대화하는 사람이 그 사람이 맞는가), 메시지 무결성(메시지 내용을 누군가가 바꾸지 않았는가)을 가지고 있는 안전한 이메일을 만들 것이다.
먼저 기밀성을 위해 DES와 AES 같은 대칭키 암호화 방식을 채택할 수 있겠지만, 대칭키를 공격자를 피해 보내줄 방법이 어려우므로, RSA 같은 공개키 방식을 이용할 수 있다. 하지만 공개키 방식은 메시지가 길어질 수록 비효율적이다.
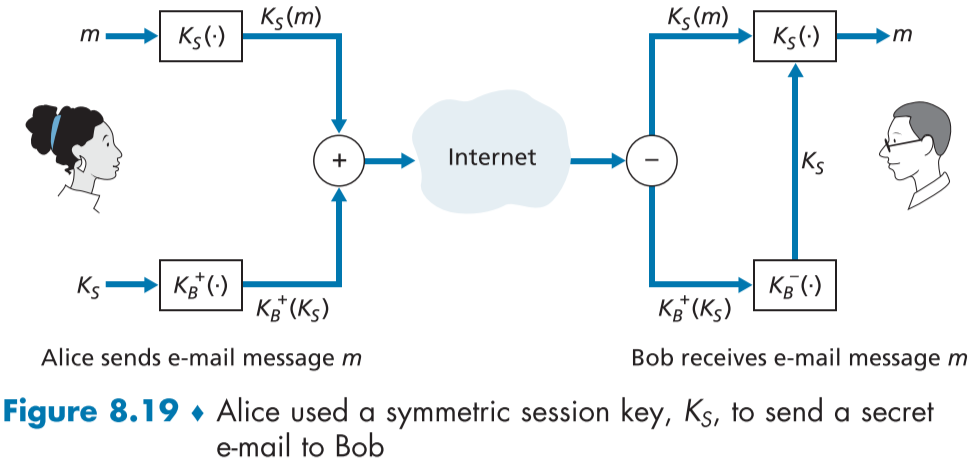
비효율성을 극복하기 위해, figure 8.19에 묘사된 세션키(8.2.2절) 방식을 이용할 수 있다.
- Figure 8.19의 +는 메시지의 합체, -는 분리를 의미한다.
- 엘리스는 무작위 대칭 세션키 $K_S$를 생성한다.
- 그녀의 메시지 m을 세션키로 암호화한다. $K_S(m)$
- 세션키 $K_S$를 밥의 공개키 $K_B^+$로 암호화 한다.
- 암호화된 메시지와 세션키를 묶어 새로운 메시지(($K_S(m)$,$K_B^+(K_S)$))를 만든다.
- 이 메시지를 밥의 이메일 주소로 보내고 밥은 이 메시지를 둘로 분리한다. ($K_S(m)$ 따로 $K_B^+(K_S)$ 따로)
- 밥의 개인키 $K_B^-$를 이용해 대칭 세션키 $K_S$를 얻어낸다.($K_B^-(K_B^+(K_S))$)
- 대칭 세션키 $K_S$를 이용해 원문 메시지 m을 얻어낸다.
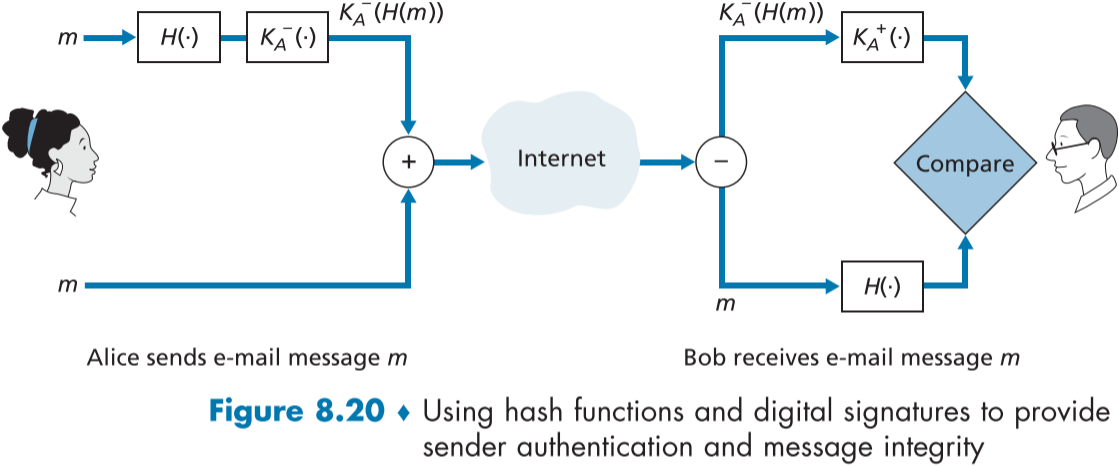
이제 기밀성과 비효율성을 모두 해결한 이메일을 만들었다. 이제 송신자 인증과 메시지 무결성을 제공해 보자.
복잡함을 제거하기 위해, 위의 기밀성 부분은 생략하겠다. 나중에 이를 합칠 것이다.
이번 일을 이뤄내기 위해, 디지털 서명(digital signatures)과 메시지 요약(message digests)을 활용하자, 과정은 Figure 8.20에 묘사되어 있다.
- 앨리스는 원문 메시지 m에 MD5 같은 해쉬 함수를 적용해 메시지 요약($H(m)$)을 얻어낸다.
- 앨리스의 개인키 $K_A^-$를 이용해 디지털 서명 $K^-_A(H(m))$을 생성한다.
- 원문 메시지 m과 디지털 서명을 합쳐 새로운 메시지를 만든다. $(m, K^-_A(H(m))$
- 밥의 이메일 주소에 넣어 보내면, 밥이 메시지를 원문과 디지털 서명으로 나눈다.
- 밥이 앨리스의 공개 키 $K_A^+$를 이용해 디지털 서명을 해독한다. $K^+_A(K^-_A(H(m)))=H(m)$
- 원문 메시지 m에 해쉬 함수를 비교해 5번의 결과물과 비교한다.
만약 5번 결과물과 m의 해쉬 함수 결과물이 같다면, 이는 앨리스가 보낸 것이고, 메시지 또한 변경이 없었다는 것을 증명할 수 있다.
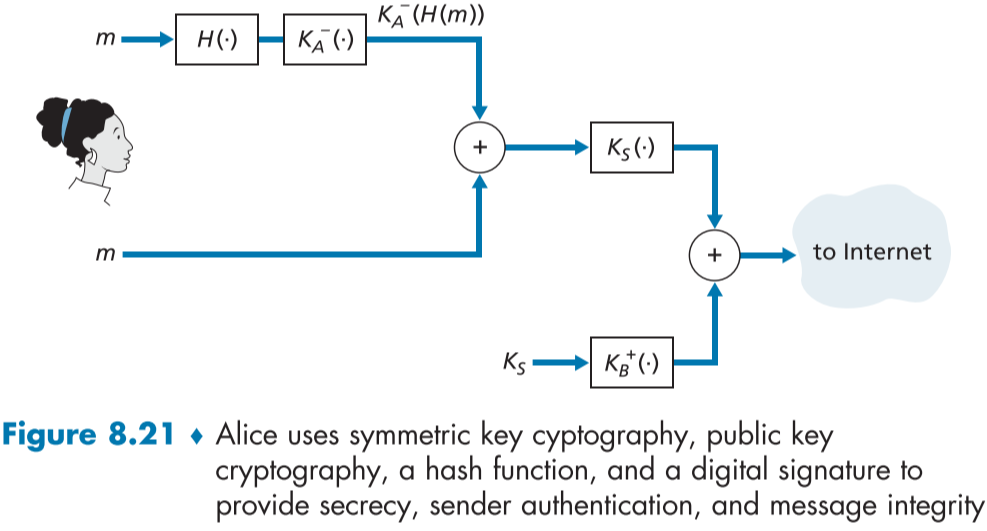
이제 우리는 송신자 증명, 데이터 무결성, 기밀성이 확보된 이메일 서버를 만들어 볼것이다.
앞서 배웠던 Figure 8.19와 Figure 8.20을 결합해보면,
- 앨리스는 먼저 디지털 서명과 원문 메시지가 합쳐진 메시지를 먼저 만든다. 이를 선두 메시지라 하겠다.
- figure 8.19의 4번 과정처럼 선두 메시지를 세션키로 암호화하고, 이 세션키를 밥의 공개키로 암호화한 뒤, 이 둘을 이용해 새로운 메시지를 만든다.
- 이 메시지를 밥이 받으면 Figure 8.19와 Figure 8.20에서 했던 과정을 거친다.
이를 통해 모두 합쳐진 이메일 서버를 만들 수 있었다.
보다시피, 앨리스의 개인키(디지털 서명 생성시), 밥의 개인키(대칭 세션키 얻어낼 때) 공개키 방식을 두번 사용하였다.
그리고 추가로, 서로의 공개키를 사용할 때, 별언급 없었지만 실제로는 CA의 인증서를 가져오는 과정이 있어야 한다.
8.5.2 PGP
Pretty Good Privacy (PGP)는 위에서 우리가 만든 안전한 이메일 서버와 비슷하며, 버전에 따라 MD5나 SHA를 해쉬함수로, CAST, triple-DES, IDEA를 대칭키 암호화 알고리즘으로, RSA를 공개키 암호화로 사용하는 것이 다르다.
PGP는 설치후, 공개키 암호화의 공개키와 개인키를 생성해주며, 공개키는 알아서 CA나 개인 홈페이지를 통해서 공개해야하고, 개인키는 비밀번호로 보호되어 접근할 때마다 비밀번호 입력을 필요로 한다.
PGP는 설정에 따라 전체 메시지를 암호화하거나 디지털 서명화하거나 양쪽 다 선택할 수 있다.

Figure 8.22는 디지털 서명이 설정된 PGP 메시지 예시이다. 이러한 메시지는 MIME 헤더 이후 나타난다.
무작위 문자열로 보이는 인코딩된 데이터는 $K^-_A(H(m))$이며, 메시지 요약(digest)을 의미한다.
메시지 요약은 송신자의 공개키를 이용해 복호화하여 메시지 무결성과 송신자 인증을 위해 사용한다.

figure 8.23은 비밀 PGP 메시지로, 이 또한 MIME 헤더 앞에 나타난다. 기밀성있게 PGP를 설정하면 figure 8.23 처럼 생성된다.
또한 PGP는 공개키 인증을 제공하며, 기존의 CA 방법과 조금 다른데, 신뢰의 웹(web of trust)라는 특별한 방법을 사용한다.
한 사용자는 다른 사용자의 공개키/유저명 짝을 신뢰한다고 선언하면, 자신의 공개키/유저명 짝을 신뢰받을 수 있다. 만약 더 많은 인증서가 필요하다면, 더 많은 다른 사람의 인증서를 신뢰하면 된다. 이러한 키를 신뢰한다고 선언(=인증서를 생성하는) 하는 방법은, 개인키를 이용해 디지털 사인을 만들어 주는 것이다.
몇몇 PGP 사용자는 키 인증 파티를 열어 많은 사람이 서로 신뢰성을 주고 받곤 한다.
8.6 TCP 연결 보안화 : TLS (Securing TCP Connections: TLS)
이번에는 어떻게 암호화가 TCP의 보안성을 증대키시는지 알아보자.
TLS(Transport Layer Security, 전달 계층 보안)은 IETF에서 표준화한 TCP의 향상 버전으로 비슷한 프로토콜로 SSL 버전 3가 있다.
SSL 프로토콜은 넷스케이프에서 고안했지만 비슷한 아이디어는 이전에도 있었고, SSL과 TLS는 모든 웹 브라우저와 웹 서버가 지원하고 여러 기업에서 전자 상거래 등에서도 활용하는 인기있는 프로토콜이 되었다.
만약 http가 아닌 https를 주소창에 한번이라도 본적 있다면 당신은 TLS를 경험한 것이다.
TLS가 없이 전자 상거래를 한다면 다음과 같은 문제가 생길 수 있다.
- 암호화 같은 기밀성이 없으므로, 침입자는 주문자의 주문 정보와 신용 카드 정보 등을 탈취하여 금전적인 피해를 입힐 수 있다.
- 데이터 무결성이 없다면, 침입자가 주문자의 주문 정보를 바꾸어 100배 더 많은 주문을 시도할 수 있다.
- 서버 인증이 없다면, 침입지가 가짜 전자 상거래 페이지를 띄워 고객의 정보를 가져가고, 돈을 갈취할 수 있다.
TLS는 이와 같은 피해를 막을 수 있게 해준다.
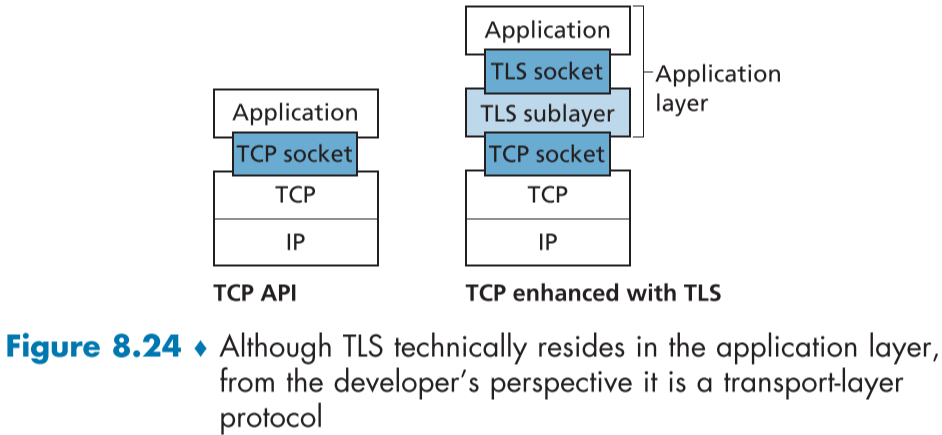
TLS는 주로 HTTP를 이용하는 전자상거래에 보안을 위해 사용되지만, TCP를 이용하는 서비스라면 어디든 사용 할 수 있으며, TCP와 유사한 소켓을 이용한 API를 제공한다.
TLS은 SSL의 연장선으로 시작했기 때문에 TLS를 사용하는 응용 프로그램은 SSL 클래스와 라이브러리가 포함된다.
Figure 8.24에서 보다시피 TLS는 엄밀히 말해서 응용 계층이지만, 개발자 입장에서는 TCP의 연장선이라는 느낌이라 전달 계층으로 분류된다.
8.6.1 큰 그림 (The Big Picture)
처음에는 쉬운 설명을 위해 간소화된 TLS로 시작하겠다.
TLS에는 세가지 단계가 있다. 핸드셰이크(Handshake), 키 도출(key derivation), 데이터 전송(data transfer)
예제는 클라이언트인 밥과 공개키 암호화와 인증서를 사용하는 엘리스로 보이겠다.
핸드셰이크(Handshake)
핸드셰이크에는 “(a) TCP 연결 수립”, “(b) 서버 인증”, “(c) TLS 세션간에 필요한 대칭키들을 생성하는데 사용할 마스터 비밀 키를 서버로 전송” 등의 활동을 할것이다.
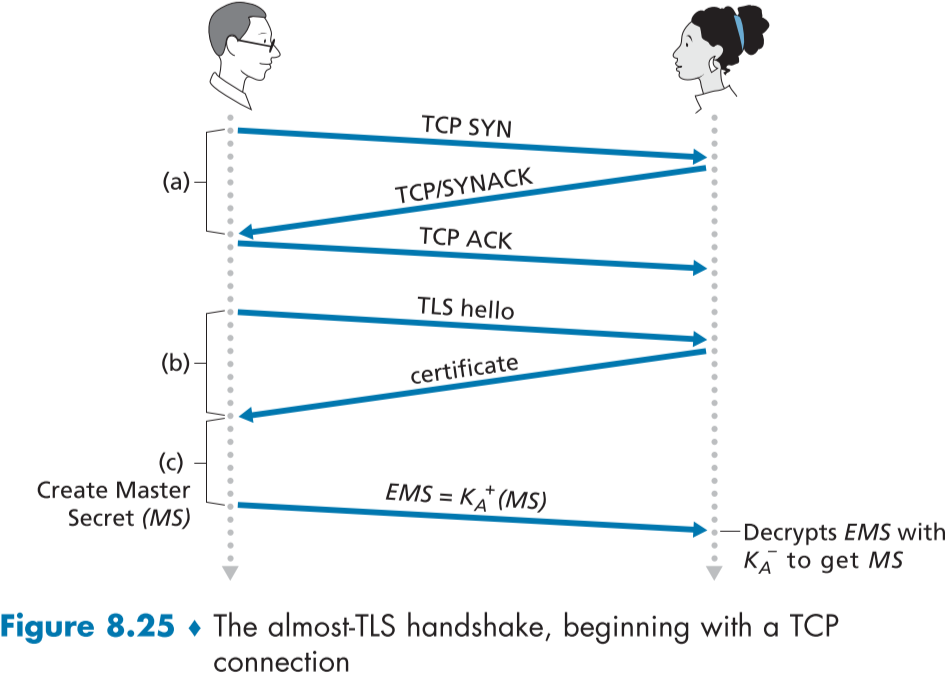
이 세가지 단계는 Figure 8.25에 묘사되어 있다.
(a) TCP 연결이 수립된 이후 밥은 TSL Hello 메시지를 앨리스에게 보내면 공개키가 포함된 CA인증서를 응답 메시지로 받는다.
(b) 이후 밥은 이번 세션에만 사용할 MS(Master Secret, 마스터 비밀)를 생성하고, 엘리스의 공개키로 암호화한다.이를 EMS(Encrypted Master Secret, EMS)라고 한다.
(c) 이 EMS를 서버인 앨리스 측에 보내면, EMS를 앨리스의 개인키로 복호화해 MS를 확보한다.
키 도출 (Key Derivation)
이제 클라이언트와 서버 양측이 가지고 있는 MS를 이용해 모든 암호화와 데이터 무결성 체크에 사용할 대칭 세션 키들을 만드는데 사용한다.
이를 이용해 4개의 키를 생성한다. 1개의 키로 모두 할 수 있음에도 4개의 키로 나누는 이유는 혹시 유출됬을 때의 피해를 최소화하기 위해서다.
- $E_B$ = 클라이언트가 서버로 보낼 때의 데이터를 암호화하는 세션 암호화 키
- $M_B$ = 클라이언트가 서버로 보낼 때의 데이터를 위한 세션 HMAC 키, HMAC(standardized hashed mesage authentication code)은 8.3.2에서 설명한 MAC의 일종
- $E_A$ = 서버에서 클라이언트로 보낼 때의 데이터를 암호화하는 세션 암호화 키
- $M_A$ = 서버에서 클라이언트로 보낼 때의 데이터를 위한 세션 HMAC 키
4개의 다른 키를 생성하기 위해서 MS를 4개의 키로 쪼갠다.(정확히는 좀더 복잡한 방법이다.)
키 생성이 끝나면 대칭키 4개가 생기며, 둘은 데이터를 암호화 하는데, 두 HMAC 키는 데이터 무결성을 확인하는데 사용한다.
데이터 전달 (Data Transfer)
이제 앨리스와 밥은 같은 4개의 세션 키 ($E_B$, $M_B$, $E_A$, $M_A$)를 가지게 되고 이제 데이터를 전송할 수 있다.
하지만 TCP는 응용 계층과 바이트 흐름(byte-stream)으로 데이터를 전송하므로, 전송계층과 응용계층 사이에 있는 TLS의 데이터 또한 바이트 흐름 형태이다.(figure 8.24)
- 바이트 흐름(byte-stream)이란, 패킷 처럼 데이터들이 일정 형태로 나누어 지는 것이 아니라, 거대한 하나의 데이터 흐름으로 전달되는 것을 의미한다. 마치 드럼통 단위로 이동하는 석유가 패킷이라면, 송유관을 타고 흐르는 석유는 바이트흐름과 같다.
- TCP는 IP 계층과 통신할 때는 세그먼트라는 패킷으로 보내지만, 응용 계층과는 사이에 버퍼를 두고 바이트 흐름으로 보낸다.
- 따라서, TCP와 응용 계층 사이에 존재하는 TLS는 바이트 흐름으로 이야기해야한다.
하지만 바이트흐름 형태의 데이터는 일정한 단위가 없으므로, HMAC을 집어 넣어 무결성 검사를 할 위치가 애매하다.
따라서 TLS에서는 바이트흐름 데이터를 레코드(rocord)로 나누어 레코드 별로 HMAC을 이어 붙여 암호화 한다.
이 HMAC은 레코드 데이터 + $M_B$ 키를 이어 붙인 뒤, 해쉬 함수를 이용해 만들며 (8.3절 메시지 인증 코드 참조)
이렇게 이어붙인 레코드 데이터 + HMAC를 $E_B$ 세션 암호 키를 이용해 암호화되고 TCP로 전해져 상대방에게 전달된다.
하지만 여전히 칩입자가 TCP 헤더의 내용을 바꾸거나 세그먼트의 순서를 바꾸기, 삭제, 반복 등의 공격을 할 수 있으며, 이를 중간자(man-in-the-middle) 공격이라고 한다.
이를 막기 위해 시퀀스 번호(sequence number)를 다음과 같이 활용한다.
밥은 시퀀스 번호 카운터를 0부터 시작해 TLS 레코드를 보낼때 마다 증가시킨다.
이때, 시퀀스 번호는 레코드에 포함시키지 않고 HMAC을 만들때 사용하는데,
(데이터 m + HMAC 키 $M_B$ + 현재 시퀀스 번호)를 해쉬 함수를 이용해 HMAC을 만든다.
이후 앨리스는 시퀀스 번호를 기록하면서, 데이터 무결성을 위해 HMAC을 비교할때, (데이터 m + HMAC 키 $M_B$ + 현재 도착했어야할 올바른 시퀀스 번호)를 이용해 HMAC을 만들고, 이 HMAC이 도착한 메시지의 HMAC과 같으면 해당 레코드를 취한다.
이 방법을 이용해 중복되거나, 중간 지점의 여성(woman-in-the-middle) 공격을 방지할 수 있는데, 잘못된 세그먼트들은 그냥 버려지고, 오지 않은 시퀀스 번호는 재전송 요청을 하기 때문이다.
TLS 레코드 (TLS Record)
TLS 레코드의 구조는 figure 8.26에 묘사되어 있다.

레코드는 Type 필드, Version 필드, Length 필드, Data 필드, HMAC 필드로 이루어져 있으며, 첫 세 필드는 암호화 되지 않는다
Type 필드는 핸드셰이크 메시지, 데이터 메시지, TLS 연결 종료에 사용하는 메시지 등을 구분하는데 사용되며,
Version 필드는 TLS의 버전을 의미한다.
Length 필드는 수신자가 TCP 바이트 흐름에서 TLS 레코드를 추출하는데 사용한다.
8.6.2 더욱 완벽한 그림 (A More Complete Picture)
이때까지의 간단한 TLS가 아닌 실제의 좀더 복잡한 TLS 프로토콜에 대해 알아보자.
TLS 핸드셰이크 (TLS Handshake)
SSL에서는 사용자들이 사용할 대칭키나 공개키 알고리즘을 설정하지 않는다. 대신 TLS에서는 양측이 TLS 세션을 시작할 때 핸드셰이크를 통해 합의하도록 되어있다.
추가로 핸드셰이크 중에는 양 측은 넌스(nonces)를 서로에게 보내 세션키($E_B$, $M_B$, $E_A$, $M_A$)를 만드는데 사용된다. 실제 TLS 핸드셰이크 과정은 다음과 같다.
- 클라이언트는 호환가능한 암호화 알고리즘들의 리스트와 클라이언트 넌스를 서버측에 보낸다. (클라이언트 Hello)
- 서버측은 클라이언트 측이 보내준 알고리즘 리스트 중에서 사용할 대칭키 알고리즘(AES 등)과 공개키 알고리즘(RSA 등), HMAC 알고리즘(MD5, SHA-1 등)를 고른 뒤, 이들의 리스트와 CA 인증서(서버 인증(Server Certificate)), 서버측 넌스를 함께 클라이언트측으로 보낸다. (서버 Hello, 서버 Hello 끝(Server Hello Done))
- 이때 클라이언트 측의 인증서를 요구하는 인증 요구 (Certificate Request)도 가능하다.
- 만약, CA 인증서를 이용해 공개키를 주는 방식이 아니라면 Diffie-Hellman 알고리즘을 통한 서버 키 교환(server key exchange) 이 필요하다.
- 클라이언트 측은 인증서를 확인한 뒤, 서버의 공개키를 추출하고 PMS(Pre-Master Secret, 선마스터 시크릿)을 생성한 뒤, 서버의 공개키로 암호화한 뒤 서버에게 보낸다. (클라이언트 키 교환(client key exchange))
- TLS 표준에 명시되어 있는 같은 키 도출 함수로 클라이언트와 서버가 각각 PMS와 넌스를 활용해 MS(Master Secret, 마스터 시크릿)을 생성한다. MS를 나누어 두개의 암호화 키와 두개의 HMAC 키를 생성한다. 추가로 만약 대칭키 암호화 알고리즘(3DES, AES)이 CBC(Cipher block chaining, 암호화 블록 연쇄)를 이용한다면 MS를 이용해 서버와 클라이언트가 각각 한개, 총 두개의 IV(Initialization Vectors, 초기 벡터)를 생성한다. 이후로 모든 통신의 메시지는 이들로 암화회되고, HMAC를 이용해 인증된다.
- 클라이언트가 서버로 모든 핸드셰이크 메시지의 HMAC를 보낸다. 서버측은 자신이 클라이언트로부터 받은 HMAC와 자신이 가지고 있는 핸드셰이크의 HMAC가 전부 같은지 비교한다. 암호화 사양 변경 프로토콜-1(Change Cipher Spec Protocol-1)
- 서버가 클라이언트로 모든 핸드셰이크 메시지의 HMAC를 보낸다 클라이언트 측은 자신이 서버로부터 받은 HMAC와 자신이 가지고 있는 핸드셰이크의 HMAC가 전부 같은지 비교한다. 암호화 사양 변경 프로토콜-2(Change Cipher Spec Protocol-2)
- 이후 모든 과정이 끝났다면 서버측에서 Finished 메시지를 보내 TLS 핸드셰이크를 종료한다.종료 (Finished)
암호화 사양 변경 프로토콜 (Change Cipher Spec Protocol)
마지막 5번, 6번 두 과정은 암호화 사양 변경 프로토콜(Change Cipher Spec Protocol)라고 하며 핸드셰이크 과정 중 중간자의 템퍼링 공격(tempering, 위변조 공격)을 막기 위함이다. 이를 자세히 살펴보자
1번 과정, 클라이언트 hello에서 클라이언트가 보낸 알고리즘의 리스트 정보는 아직 어떠한 알고리즘 선택이나 키 생성이 되지 않은 상태이기 때문에 아무런 보안 처리가 되지않은 원문 메시지로 보내게 되고, 이로 인해 공격자에게 노출되어 있다.
중간자는 해당 메시지를 위변조하여 리스트에서 정상적이고 강력한 알고리즘들은 지워버리고 약하고 공격가능한 알고리즘만 남겨서 서버에 다시 보낸다.
이러한 공격을 막기 위해 5번에서 클라이언트는 모든 핸드셰이크 과정 중 메시지의 HMAC들의 합체를 보낸다. 서버측은 자신의 HMAC들과 받은 HMAC들을 비교하여, 일치하지 않는게 있다면 연결을 종료해버린다. 이후 반대쪽의 클라이언트도 서버가 보내온 HMAC를 비교하여 같은 행동을 한다.
즉, 1번 과정, 클라이언트 hello를 포함해서, 어떠한 핸드셰이크 메시지라도 자기가 보낸 메시지와 다르다면, 연결이 될 수 없다.
예를 들어, 중간자가 리스트에서 정상적이고 강력한 알고리즘들은 지워버리고 약하고 공격가능한 알고리즘만 남겨서 서버에 다시 보냈다면, 이는 클라이언트 측에서는 자신이 보낸 알고리즘의 리스트와 다르게 되므로 서버측의 HMAC가 다르게되고 곧바로 종료시켜 버린다.
유일한 방법은, 1번 과정의 알고리즘 리스트를 전부 가장 약한 알고리즘으로 만든 뒤, 마지막 5번 6번(Change Cipher Spec Protocol) 과정에 개입하여, 암호화가 걸려있는 메시지들을 복호화해 위변조하는 방법 밖에 없지만, SSL 측에서 (TLS와 library를 공유함) 사용가능한 알고리즘 리스트를 가장 약한 알고리즘이어도, 모든 복호화가 즉시 가능하지 못하도록 보안 수준을 유지하게 라이브러리를 유지하므로 사실상 불가능하다.
서버와 클라이언트의 Hello 과정
서버와 클라이언트 측의 Hello (1, 2번) 과정 중에 시퀀스 번호가 있음에도 넌스를 사용하는 이유는 뭘까?
넌스는 연결 리플레이 공격을 방지하기 위해, 시퀀스 번호는 메시지 리플레이 공격을 방지하기 위해 존재한다.
리플레이 공격이란, 중간자가 메시지를 도청한 뒤, 같은 메시지를 또 보내게 하여 보안으로 부터 회피하면서, 같은 명령을 다시 수행하게 만든 것이다.
예를 들어, 이커머스 이용자의 구매 메시지를 도청한 뒤, 이를 다시 한번 보내는 것으로 이용자는 두 번의 구매를 한것으로 나타날 것이다.
TLS 연결 중, 시퀀스 번호가 이미 사용했던 메시지가 다시 나타났다면, 상대 측에서 재전송했거나, 중간자가 리플레이 공격을 시도한 것이므로 무시하면 된다.
넌스는 알다시피, 매 연결마다 설정되는 번호이므로, 같은 주체들의 연결이라고 해도, 넌스는 다르게 생성된다.
즉, 연결 리플레이 공격을 시도하면, 이전에 사용했던 넌스를 재사용하게 되며, 또한 이 넌스는 상기 과정에서 PMS를 MS로 만들 때 사용되므로, 암호화 알고리즘에 사용할 키들 또한 이전에 사용했던 키를 가지게 된다.
서로 다른 키에 의해 메시지들은 무결성 체크에 실패 하게 되고, 공격자의 리플레이 공격 메시지들은 무시되게 된다.
연결 종료 (Connection Closure)
만약 어느 순간에 더이상 주고 받을 통신이 없고 TLS 세션을 종료하고 싶을 때는 TCP FIN 세그먼트를 이용해 TCP 연결을 종료하는 방법이 있다.
하지만 이 방법은 침입자가 진행중인 연결에 연결 종료 의사를 담은 메시지를 보내는 단절 공격(truncation attack)에 취약하다.
트루디가 앨리스에게 TCP FIN을 보내면, 밥은 원하지 않았어도 앨리스가 연결이 끝난 줄 알고 종료를 할 수 있다.
이를 막기 위해, TCP FIN 세그먼트를 보내기전에 TLS의 type 필드가 종료 레코드(closure TLS record)로 되어있는 레코드를 보내야 종료가 되게 만들면 된다.
TLS 레코드는 이미 HMAC으로 송신자가 인증 되기 때문에 침입자가 단절 공격을 위한 위조 종료 레코드는 인증되지 못해 무시된다.
우리의 TLS에 대한 공부는 여기서 끝났고, 더욱 자세한 내용은 [Rescorla 2001]에서 참고바란다.
8.7 네트워크 계층 보안 : IPsec과 가상 사설망 (Network-Layer Security: IPsec and Virtual Private Networks)
IP 보안 프로토콜(IP security Protocol, IPsec)은 네트워크 계층의 보안 프로토콜로, VPN(virtual private networks, 가상 사설망)을 만드는데 사용된다.
네트워크 계층 보안은 기밀성 이외에도 인증, 변조 방지, 리플레이 공격 방지, 데이터 무결성 보장 등이 가능하며, 위가 배울 IPsec 또한 그러하다.
8.7.1 IPsec과 가상 사설망 (VPNs) (IPsec and Virtual Private Networks (VPNs))
일부 규모가 큰 조직들은 보안과 기밀을 이유로 외부에 연결되지 않은 네트워크를 가지고 싶어하고 이를 사설망(private network)라고 한다. 실제로 직접 라우터, 스위치 같은 물리적인 네트워크 장비를 구매해 설치하는 경우도 있지만, 이럴 경우 구매비용, 운영비용, 관리 비용이 엄청나진다.
물리적인 사설망 대신, 많은 조직들은 공개 인터넷 내부에 VPN으로 사설망을 형성하다. VPN 간의 트래픽은 기밀을 위해 암호화된 후 물리적인 네트워크 대신 인터넷을 통해 전해진다.
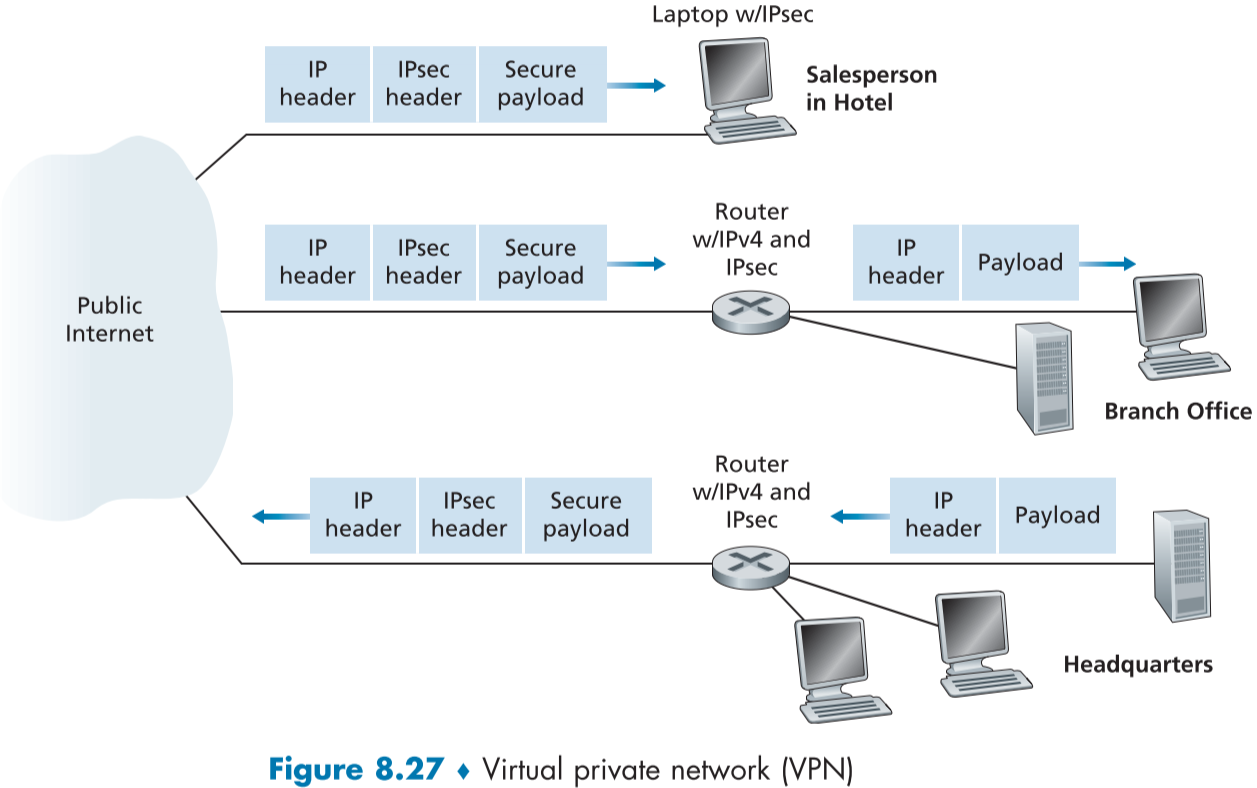
figure 8.27은 간단한 VPN의 예시이다. 본부(headquarter), 지부(branch office), 전근중인 영업사원(traveling Salesperson)으로 이루어져있고 영업사원은 호텔의 인터넷을 통해 연결되어 있다.
VPN에서는 본부의 두 호스트 간이나 지부의 두 호스트 간, 즉 같은 장소에 있는 두 호스트는 서로와 통신할 때는 IPsec을 사용하지 않은 순수 IPv4를 사용하며, 만약 조직의 두 호스트의 통신 경로가 공용 인터넷을 지나간다면, 트래픽은 인터넷에 들어가기전에 IPsec을 통해 암호화되어야 한다.
- 단, 호스트가 같은 VPN 내의 호스트가 아닌 외부 인터넷의 호스트와 통신할 때는 IPsec이 아닌 순수 IPv4로 통신한다.
- 예를 들어 본부의 호스트가 구글의 메일서버를 이용할 때는 IPsec을 이용하지 않는다.
예를 들어 본부의 호스트가 IP 데이터그램을 호텔의 영업사원에게 보내게 되었다면, 본부의 게이트웨이 라우터는 순수 IPv4 데이터그램을 IPsec 데이터그램으로 바꾼뒤 인터넷으로 포워딩 한다. IPsec 데이터그램은 IPv4의 헤더 또한 포함하므로, 평범한 IPv4 데이터그램처럼 경로를 찾아 간다.
하지만 IPsec 데이터그램의 페이로드에는 IPsec 처리에 사용될 IPsec 헤더를 포함하고 있으며, 암호화되어있다.
IPsec 데이터그램이 영업사원의 노트북에 도착하면, 노트북의 운영체제가 페이로드를 복호화하고, 데이터 무결성 등 다른 보안 사항을 체크한 뒤, 데이터를 UDP, TCP 같은 상위 계층에 보내준다.
대략적으로 알아보았으니 좀더 자세하게 알아보자.
8.7.2 AH와 ESP 프로토콜 (The AH and ESP Protocols)
IPsec은 아주 복잡한 개념이며, 여러가지 RFC로 정의되어 있다. 대표적으로 RFC 4301(전체적인 IP 보안 구조), RFC 6071(IPsec 프로토콜들의 개요). 우리는 이를 간단하지만 실전적인 방법으로 알아보자.
IPsec 프로토콜 집단에는 두가지 원리 프로토콜이 존재한다. AH(Authentication Header, 인증 헤더) 프로토콜, ESP(Encapsulation Security Payload, 캡슐화 보안 페이로드) 프로토콜, 둘다 IPsec 객체(호스트나 라우터)가 서로 보안 데이터그램을 주고 받을 때 사용하는 기본 프로토콜로,
AH 프로토콜은 인증과 데이터 무결성을 보장하지만, 기밀성은 보장하지 않고, ESP 프로토콜은 인증, 데이터 무결성, 기밀성을 전부 보장한다.
때문에 현실에서는 ESP 프로토콜이 더욱 널리 사용되고 있으며, 이에 대해 중점적으로 알아볼 것이다.
8.7.3 보안 연관 (Security Associations)
IPsec 개체 둘이 통신하기 전에 네트워크 계층의 단방향성 논리적 연결을 두개(오고 가고) 생성하는데 이것이 바로 SA(Security Association, 보안연관)이다.
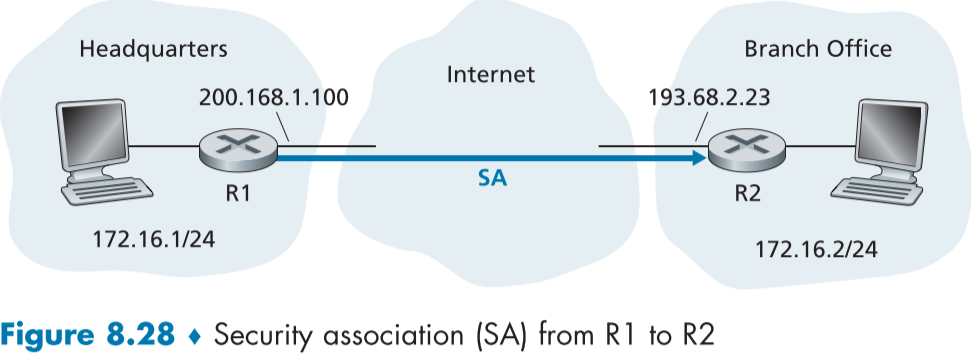
figure 8.28은 본부에서 지부 방향의 통신을 연결하는 SA를 가지고 있는 게이트웨이 라우터 R1과 게이트웨이 라우터 R2의 예시이다.
라우터 R1과 라우터 R2는 SA의 상태 정보를 공유하고 있는데, 예를 들자면,
- SA의 32비트 식별자, SPI(Security Parameter Index, 보안 매개변수 색인)
- SA의 출발지 인터페이스(묘사상 200.168.1.100), SA의 도착지 인터페이스(묘사상 193.68.2.23)
- 암호화 알고리즘 종류 (예를 들어 CBC를 이용한 3DES)
- 암호화 키(The encryption key)
- 무결성 체크 알고리즘 종류 (예를 들어 MD5 HMAC)
- 인증 키(The authentication key)
R1은 IPsec 데이터그램을 생성하고 암호화, 인증한 뒤, 포워딩 하기 위해 위의 상태 정보를 이용하고, R2는 수신받은 IPsec 데이터그램을 복호화하고, 인증하는데 위의 상태 정보를 이용한다.
이러한 SA 정보는 VPN 내에서 연결이 많아질수록 통신 객체에 저장해야 할 정보가 많아지며, 보통 객체 운영체제 커널에 존재하는 SAD(Security Association Database, 보안 연관 데이터베이스)에 저장한다.
8.7.4 IPsec 데이터그램 (The IPsec Datagram)
IPsec 데이터그램은 터널 모드(tunnel mode)와 전달 모드(transport mode) 두가지가 존재하며, 터널모드가 좀더 VPN과 어울려 널리 사용되고 있다.
우리는 여기서 터널 모드 IPsec 데이터그램만 미리 알아보겠다.
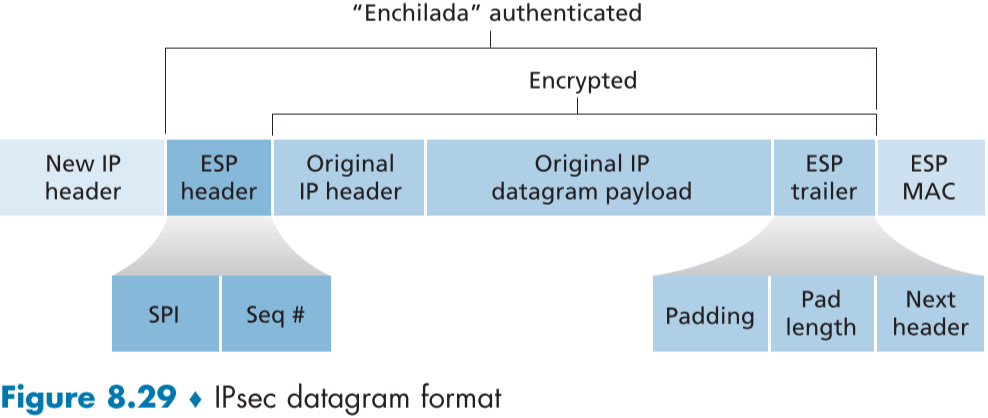
Figure 8.29는 IPsec 데이터그램의 구조이다.
Figure 8.28의 시나리오를 이용해서 순수 IPv4 데이터그램을 IPsec 데이터그램으로 바꾸는 과정을 알아보겠다.
-
IPv4 데이터그램의 뒷편에 ESP trailer(ESP 예고) 필드를 더한다.
- ESP trailer 필드는 padding, pad length, next header 필드로 구성되어있으며, 원본 데이터그램과 함께 암호화 대상이다.
- padding 필드는 블록 암호화를 사용하기 위해 메시지를 정수배로 만드는데 사용 (예를 들어 8 비트 블록 암호화면 메시지는 8의 배수 길이여야 함.)
- pad length 필드는 위의 padding 필드가 얼마나 포함됬는가?(나중에 제거하기 위해서)
- next header 필드는 원본 IP 데이터그램 페이로드의 type(UDP, TCP 등) 정보
- ESP trailer 필드는 padding, pad length, next header 필드로 구성되어있으며, 원본 데이터그램과 함께 암호화 대상이다.
-
SA 상태정보를 참고해 암호화 키를 이용해 암호화한다.
-
**암호화된 데이터그램의 앞에 ESP header(ESP 헤더) 필드를 더한다. **
-
여기까지 패킷을 Enchilada(엔칠라다, 멕시코 음식) 라고 부르자.(실제로는 그렇게 부르지 않고, 이 책에서만의 비유인듯 하다.)
-
ESP header 필드는 SPI 필드와 sequence number 필드로 이루어져 있다.
-
SPI 필드는 소속 SA의 SPI(Security Parameter Index)값, 통신 객체는 이를 통해 SAD에서 SPI를 색인하여 적절한 알고리즘과 키를 가져옴
-
sequence number 필드를 통해 리플레이 공격을 방지한다.
-
-
-
SA 상태정보를 참고해 엔칠라다에 인증 키를 더한 뒤 고정길이 해쉬 함수를 적용하여 엔칠라다 전체에 대한 인증 MAC를 생성한다.
-
생성된 MAC을 엔칠라다 뒤편에 더하여 여태까지의 결과물을 페이로드로 만든다.
-
마지막으로 이전 원본 20 바이트 길이 IPv4 헤더를 참조해 새로운 IP 헤더를 만든 뒤, 맨 앞에 더한다.
-
이때의 새로운 IP 헤더의 출발지와 목적지 주소는 각각 SA의 출발지 인터페이스 주소와 도착지 인터페이스 주소이다.
-
또한 protocol number 필드는 기존의 TCP, UDP 등이 아니라 50(ESP 프로토콜)이다.
-
이렇게 생성된 IPsec 데이터그램은 마치 페이로드로 ESP header, 암호화된 원본 IPv4 데이터그램, 암호화된 ESP trailer, ESP MAC을 가진 평범한 IPv4 데이터그램처럼 보이며, 공용 인터넷에서 평범한 IPv4 처럼 라우팅된다.
도착지 인터페이스에 도착하면 도착지 통신 객체(보통 라우터)가 확인하고 ESP 처리 절차를 밟는다.
- 엔칠라다에서 SPI를 통해 SA 소속을 확인하고 사용해야할 알고리즘과 키를 가져온다.
- ESP MAC값을 통해 데이터 무결성 확인
- sequence number 필드를 확인하여 리플레이 공격 방지
- 원본 데이터그램과 ESP trailer 부분을 복호화
- 패딩을 제거하고 원본 IP 데이터그램을 가져온다.
- 원본 IP 데이터그램을 목적지 호스트에게 전달한다.
통신 객체에는 SAD 이외에 추가로 SPD(Security Policy Database, 보안 정책 데이터베이스)라는 자료 구조를 가지고 있으며, SPD는 들어온 데이트그램의 프로토콜 종류, IP 주소를 이용해 IPsec으로 처리되어야 할 데이터그램과 순수 IPv4 데이터그램으로 보내져야할 데이터그램을 분류하고, 목적지로 가기 위한 올바른 SA를 배정해준다.
즉, SPD는 데이터그램에 무엇을 해야하는가, SAD는 데이터그램을 어떻게 해야하는 가를 담는다.
IPsec 서비스 요약 (Summary of IPsec Services)
IPsec이 제공하는 서비스는 다음과 같다.
-
중간자(man-in-the-middle)이 데이터그램의 protocol number, IP 관련 주소를 알 수 없다.
- 오직 알 수 있는 것은 데이터그램의 출발지 라우터 인터페이스와 도착지 라우터 인터페이스 뿐이다.
- 이는 SSL/TLS에 비해 더욱 기밀성이 강화된 것이다.
-
중간자가 데이터그램을 변조하려고 시도하면, 도착 인터페이스에서 무결성 체크에 실패하게 된다.
-
만약 중간자가 라우터 인터페이스로 변장하여, 거짓 데이터그램을 보낼 경우, 동일한 인증키를 확보하지 못했으므로 무결성 체크에 실패하게 된다.
-
sequence number가 다르기 때문에 리플레이 공격도 불가능하다.
이러한 방법으로 IPsec은 두 통신 객체 간의 기밀성, 발신지 인증, 데이터 무결성, 리플레이 공격을 방지할 수 있다.
8.7.5 IKE: IPsec에서의 키 관리(IKE: Key Management in IPsec)
IKE(Internet Key Exchange, 인터넷 키 교환) 프로토콜은 거대해진 VPN에서 네트워크 관리자가 일일이 SA 정보와 키를 입력해주지 못하므로 이를 자동화하는 프로토콜이다.[RFC 5996]
IKE는 SSL과 유사한 핸드셰이크를 가지고 있으며, 각 IPsec 객체는 인증서와 공개키를 가지고, SSL을 통해 인증서를 공유하고, 보안 알고리즘을 상의한 뒤, 안전하게 IPsec SA 세션 키를 생성하기 위한 정보를 공유한다.
SSL과 달리 IKE는 두 단계의 핸드셰이크로 되어있으며, 이를 figure 8.28의 시나리오로 알아보자.
먼저 첫번째 단계는 두 라우터 인터페이스 간에 두 메시지 쌍을 교환하는 것으로 시작한다.
-
첫번째 메시지쌍 교환 때는 Diffie-Hellman 알고리즘으로 양방향의 암호화되고 인증된 IKE SA를 생성한다.(이는 IPsec SA와 다르다. 주의!)
이때, IKE SA의 암호화와 인증을 위한 키와 두번째 단계 때 IPSec SA키를 생성하기 위한 MS(master secret)가 수립된다.
-
두번째 메시지 쌍 교환 때는 양쪽에서 자신의 메시지를 디지털 사인하여 정체를 밝힌다. (공개키 암호화 처음 사용) 이때 패킷 스니핑으로 보안 IKE SA 채널의 통신을 알지 못하며, 이때 IPsec SA에 사용할 암호화, 인증 알고리즘을 정한다.
두번째 단계는 양측에서 각각 서로의 방향으로 향하는 SA를 총 2개 만든다. 끝날때 쯤에는 양측에 두개의 SA를 위한 암호화, 인증 키들이 생성되고, SA를 이용해 데이터그램을 주고 받을 수 있게 된다.
두 번째 과정중에는 공개키 암호화가 사용되지 않으므로, IKE는 성능상 괜찮고, 많은 양의 SA를 적은 비용으로 생성할 수 있다.
8.8 무선 랜과 4G/5G 무선 망에서의 보안(Securing Wireless LANs and 4G/5G Cellular Networks)
무선 통신에서는 공격자가 전송 범위에 있는 것만으로도 패킷을 받아볼 수 있기 때문에 무선 랜과 4G/5G를 막론하고 중요하다.
우리는 무선망에서의 보안이 우리가 지금까지 배워온 인증을 위한 넌스의 사용, 메시지 무결성을 위한 해싱, 데이터 암호화를 위한 대칭키 도출, AES 암호화 표준 등 의 개념을 연장해서 사용한다는 것을 배울 것이다.
더욱 자세한 내용은 802.11 보안 책 [Edney 2003; Wright 2015], 3G/4G/5G 보안 [Sauter 2014]과 최신 연구 [Zou 2016; Kohlios 2018]를 참고 바란다.
8.8.1 802.11 무선 LAN에서의 인증과 키 합의(Authentication and Key Agreement in 802.11 Wireless LANs)
802.11에서의 중요한 보안 사항에 대해 알아보자.
-
상호 인증(Mutual authentication) 네트워크는 무선 기기를, 무선 기기는 네트워크를 신뢰할 수 있는지 인증하는 것을 상호인증이라고 한다.
-
암호화(Encrpytion) 802.11 프레임이 도청되고 조작당할 가능성이 있으므로, AP와 장치간의 암호화가 중요하다. 이때, 암호화와 복호화의 속도가 빨라야 하므로, 대칭키 암호화방식이 사용된다.
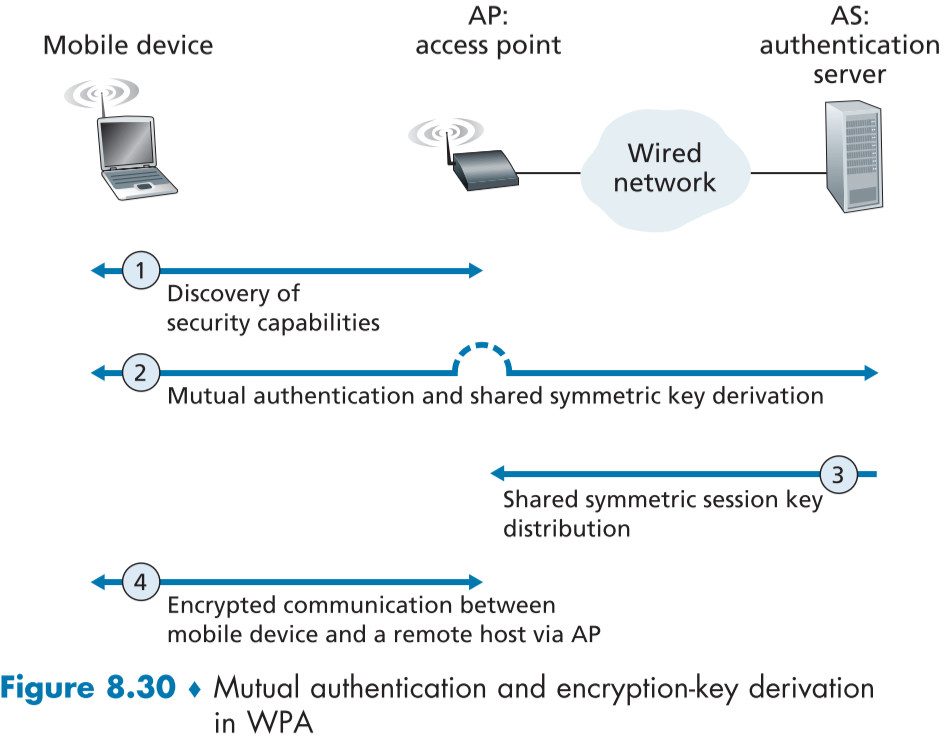
figure 8.30 은 모바일 장치가 AP(Access Point)를 통해 802.11 네트워크에 참여하려하고 있다.
AS(Authentication server, 인증 서버)는 모바일 장치의 인증을 책임지는 서버로, AP 내부에 존재하는 경우도 있지만 네트워크마다 하나의 서버가 같은 네트워크의 여러 AP의 인증 요청을 처리하기 위해 따로 존재한다.
AP 서버는 AS와 모바일 기기 사이의 인증 절차 과정 중의 인증 및 키 도출 메시지를 실어나른다.
위와 같은 시나리오에서 상호인증과 암호화 키 도출 과정은 크게 4 단계로 나눌 수 있다.
-
발견(Discovery)
이 단계에서는 AP가 자신의 존재와 제공할 수 있는 인증, 암호화 형식을 모바일 기기에게 전파한다. 모바일 기기는 이중에 원하는 보안 형태를 요청하고, 다음 절차를 시작한다.
-
상호 인증과 공유된 대칭 키 도출(Mutual authentication and shared symmetric key derivation)
802.11 채널 보안에서 가장 중요한 부분으로, 모바일 기기와 인증 서버(AS)가 이미 공유된 공통 비밀(shared common secret)을 가지고 있다고 가정하고 시작한다. (실무에서 비밀번호 등을 입력하므로 실제로 그러하다). 장치와 AS는 이 공통 비밀과 리플레이 공격을 막을 넌스, 무결성을 위한 암호화 해싱을 이용해 인증한다. 또한 추가로 모바일 장치와 AP가 암호화에 사용할 공유된 세션 키도 도출한다.
-
공유된 대칭 세션 키 분배(Shared symmetric session key distribution)
대칭 암호화 키가 도출된 후, 인증 서버가 AP들에게 대칭 세션 키를 전해줄 프로토콜을 사용한다.
-
모바일 장치와 원격 호스트간의 AP를 통한 암호화된 통신(Encrypted communication between mobile device and a remote host via the AP)
대칭키를 공유받은 AP와 이미 가지고 있던 모바일 장치간의 암호화된 통신이 가능하다. 암호화에는 실무에서 AES 대칭키 암호화가 사용된다.
상호 인증 및 공유된 대칭 세션 키 도출 (Mutual Authentication and Shared Symmetric Session Key Derivation)
WEP(Wired Equivalent Privacy)라고 불리우는 802.11의 보안 사양에 몇 개의 보안 결점이 있었고, WLAN은 공격에 취약하게 되었다.
따라서 WiFi Alliance(와이파이 연합)측에서 무결성 체크, 암호화된 메시지의 흐름을 관찰해 암호화 키를 예측하는 공격을 해결한 WPA1(WiFi Protected Access)과 AES 대칭 키 암호화를 강요한 WPA2를 내놓아 해결하려 했다.
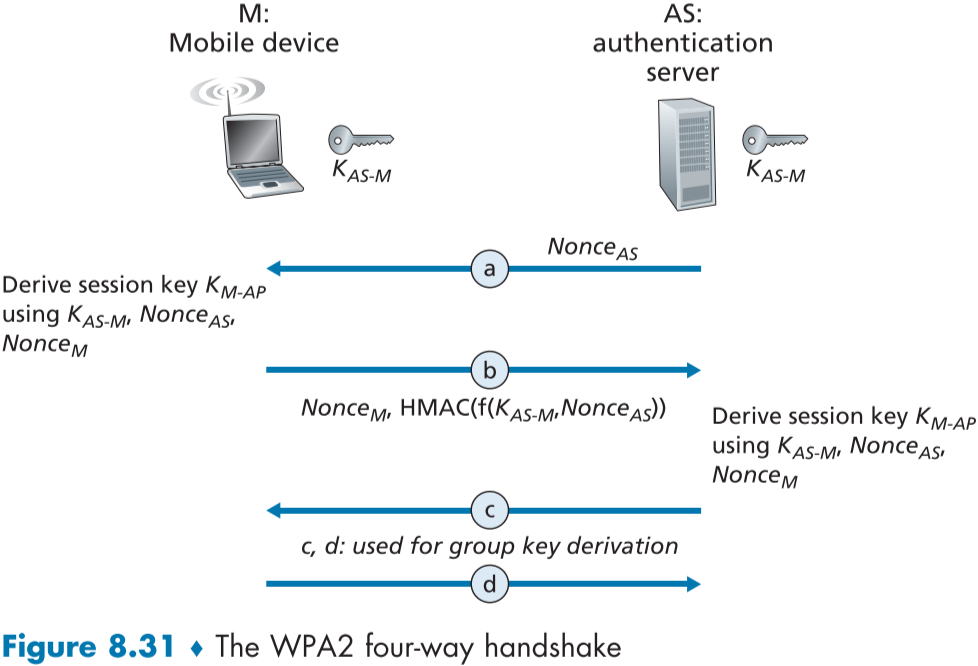
WPA는 4단계의 핸드셰이크 프로토콜을 통해 상호 인증과 공유 대칭키 도출을 실시하며, figure 8.31은 핸드셰이크의 간소화된 버전이다.
처음에 비밀 키 $K_{AS-M}$(패스워드 등)를 모바일 장치(M)과 인증서버(AS)가 공유한 뒤, M과 AP 사이에서 프레임을 암호화/복호화할 공유된 대칭 세션키 $K_{M-AP}$를 도출해야한다.
상호 인증과 공유된 대칭 세션 키 도출은 첫 두 단계 a와 b로 이루어지며, 단계 c와 d는 단체 통신을 위한 두번째 키 도출을 하는 단계이다.
a. 첫 시작시, 인증서버(AS)는 넌스 $Nounce_{AS}$를 만들어 모바일 기기에게 보낸다. 이를 통해 리플레이 공격을 방지하고, 실시간 통신임을 증명한다.
b. 모바일 장치 M은 $Nounce_{AS}$를 받은 후 새로운 넌스 $Nounce_M$을 만든다. 이후 시작시 공유되는 비밀키 $K_{AS-M}$, 장치 M의 MAC 주소, AS의 MAC 주소,$Nounce_{AS}$와 $Nounce_M$를 이용해 공유 대칭 세션 키 $K_{M-AP}$를 생성하고, $Nounce_M$와 $Nounce_{AS}$ 와 $K_{AS-M}$을 이용한 HMAC값을 보낸다.
AS는 이 값을 받고 HMAC에서 $Nounce_{AS}$와 첫 시작시 공유한 $K_{AS-M}$를 알아보고 모바일 장치는 인증된다.
이에 AS 또한 b의 모바일 장치 M과 똑같은 과정과 베이스로 같은 값을 가지는 $K_{M-AP}$를 생성하고, 이를 AP들에게 전달해 통신을 암호화할 수 있게 된다.
WPA3는 WPA2의 갱신 버전으로, 핸드셰이크에서 같은 넌스를 이용하는 방법을 방지한다.
802.11 보안 메시지 프로토콜 (802.11 Security Messaging Protocols)
figure 8.32는 802.11 보안 프로토콜을 구현하는데 사용된 프로토콜의 스택이다.
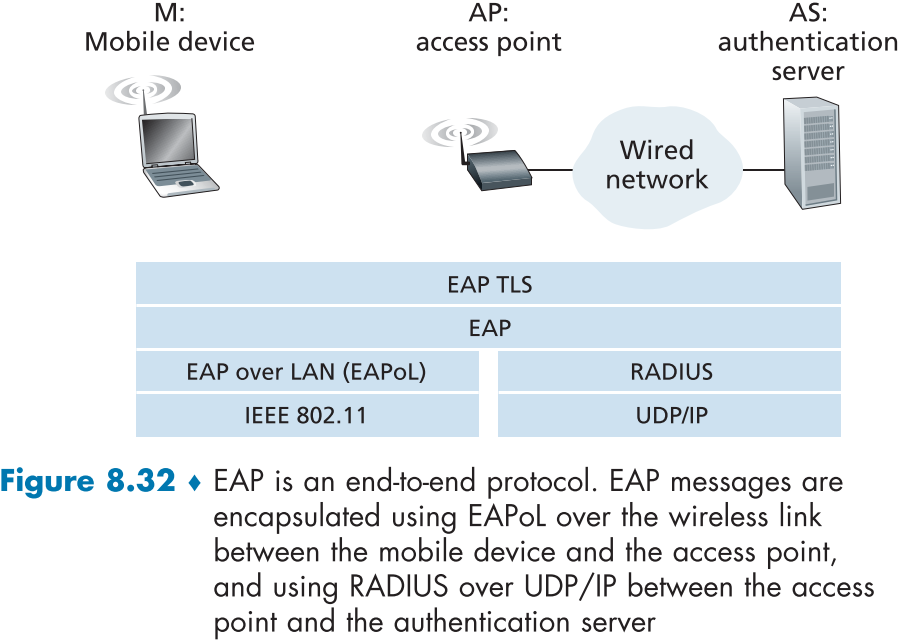
EAP(Extensible Authentication Protocol, 확장가능 인증 프로토콜)은 AS와 모바일 기기간의 간단한 요청/요구 메시지의 엔드투엔드 구조를 정의하며, WPA2로 인증된다.
이러한 EAP 메시지는 무선 연결을 타고 EAPoL(EAP over LAN, LAN 상의 EAP)로 캡슐화되고, AP에서 디캡슐화 된 뒤, EAP 메시지를 UDP/IP로 AS측에 보내기 RADIUS 프로토콜로 재캡슐화한다.
RADIUS 프로토콜과 서버는 필수가 아니며, 가까운 날 DIAMETER 프로토콜로 대체될 것으로 보인다.
8.8.2 4G/5G 무선망에서의 인증 및 키 합의 (Authentication and Key Agreement in 4G/5G Cellular Networks)
4G/5G 에서의 보안은 802.11에서와 달리 홈 네트워크와 방문 네트워크, 이동성의 개념이 존재한다는 점이다. 방문 네트워크와 홈 네트워크는 모바일 기기의 인증과 암호화 키를 생성하기 위해 서로 통신해야만 한다.
4G/5G에서도 AP와 마찬가지로 기지국 또한 모바일 기기와 서로를 인증하고 공통의 대칭키를 생성해야 한다.
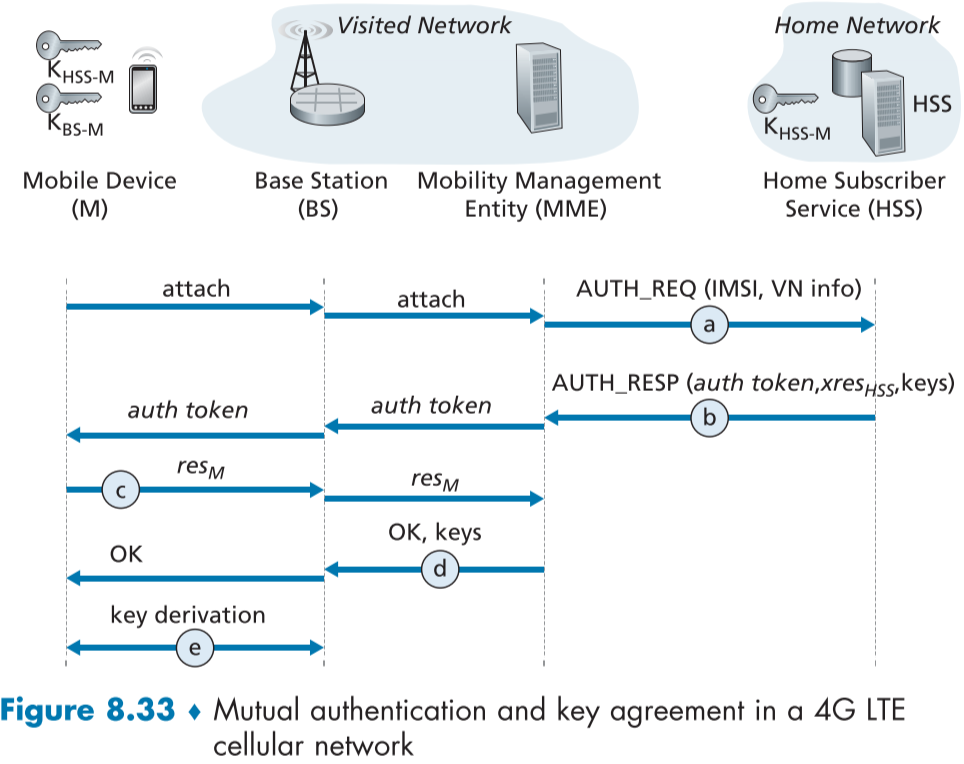
Figure 8.33은 모바일 장치가 4G 무선망에 접속하려는 시나리오이다.
익숙한 모바일 기기(M), 방문 네트워크의 기지국(BS), 이동성 관리 객체(MME), 홈 네트워크의 홈 구독자 서비스(HSS) 등이 보이며, 이를 figure 8.30과 비교하여 802.11과 4G 보안의 비슷한 점과 다른 점을 볼 수 있다.
여기서는 4G MME와 HSS가 인증서버(AS)와 비슷한 역할을 하며, 모바일 기기가 생성된 $K_{BS-M}$이 프레임을 암호화/복호화 하는데 사용된다.
또한 802.11 때와 마찬가지로 공유된 공통 비밀(Shared Common Secret) $K_{HSS-M}$을 가지고 서로의 인증을 시작하는데, 이는 모바일 기기의 SIM 카드와 HSS의 데이터베이스에 적혀있다.
AKA(4G Authentication and Key Agreement) 프로토콜은 다음과 같은 과정을 거친다.
a. HSS로 인증 요청 (Authentication request to HSS)
모바일 기기가 기지국에 최초 네트워크 연결 요청 메시지를 IMSI(international mobile subscriber identity, 국제 모바일 구독자 식별)를 담아서 보내고, 기지국은 연결 메시지를 중계 목적으로 방문 네트워크의 MME(Mobility Management Entity, 이동성 관리 객체)에 보낸다. MME는 IMSI와 VN 정보를 홈 네트워크의 HSS에게 보낸다. MME와 HSS의 통신은 7.4절 참조
b. HSS의 인증 응답 (Authentication response from HSS)
HSS는 미리 정의되고 모바일 기기와 공유하고 있던 비밀키 $K_{HSS-M}$를 이용해 IMSI 등을 암호화해 인증 토큰 $auth_token$, 예상 인증 응답 토큰 $xres_{HSS}$ 토큰을 생성하고 이 둘과 나중에 기지국에 나눠줄 키를 MME로 보낸다.
$auth_token$은 HSS가 $K_{HSS-M}$으로 IMSI를 암호화해서 생성한 암호화된 정보인데,
아직 인증받지 않은 HSS가 $auth_token$를 보냈고, 이 $auth_token$을 모바일기기가 $K_{HSS-M}$을 이용해 풀었을 때 원본 IMSI로 해독이 된다면,
모바일 기기와 HSS만 알고있는 비밀키 $K_{HSS-M}$을 이용했다는 의미이므로, 모바일 입장에서 HSS는 안전하다고 인증된다.
반대로 MME에게(더나아가 HSS 입장에서도) 모바일 장치를 인증하는 방법으로, $xres_{HSS}$를 이용하는데,
모바일 장치는 $K_{HSS-M}$을 이용해 암호화해 $res_M$을 만들고 MME에게 보내줘야하고,
MME는 이 값을 $xres_{HSS}$과 비교해 맞다면 모바일 장치가 $K_{HSS-M}$을 가지고 있다는 의미이므로, 모바일 장치도 인증이 되는 구조이다.
MME는 오직 경유지 역할을 하며, 인증 응답 메시지를 받고 $xres_{HSS}$는 가지고 있다 나중에 모바일 장치가 보낸 것과 비교하고,
auth_token을 모바일 장치에게 주어 HSS를 믿게 하는 등의 역할을 하며, $K_{HSS-M}$은 받지도, 보내지도, 존재를 알지도 않는다.
c. 모바일 기기의 인증 응답 (Authentication response from mobile device)
모바일 기기는 $auth_token$을 건네받고, 이를 가지고 있던 $K_{HSS-M}$로 해독해보아 자신의 IMSI가 나온다면, HSS가 같은 $K_{HSS-M}$를 가지고 있다는 의미이므로 HSS를 믿을 수 있게 된다.
그리고 모바일 기기는 $K_{HSS-M}$를 이용해 HSS와 같은 과정을 거쳐 $res_M$을 만들어 MME에게 보낸다.
d. 모바일 기기 인증 (Mobile device authentication)
MME는 $res_M$과 보내지 않고 간직하고 있던 $xres_{HSS}$를 비교하여 같다면,
모바일 장치가 $K_{HSS-M}$를 보유하고 있다는 의미이므로 모바일 기기인증이 되며,
이 사실을 기지국과 장치에게 알려 상호인증이 끝났음을 알리고, 다음 단계에 기지국이 사용할 키를 보내준다.
e. 데이터 측면과 제어 측면 키 도출 (Data plane and control plane key derivation)
모바일 장치와 기지국은 데이터 측면과 제어 측면 무선 전송 프레임의 암호화/복호화에 사용할 키를 도출한다. 이때 AES 암호화 알고리즘이 사용된다.
이상은 4G에서의 인증과 키 생성 과정이었고, 5G에서는 조금 다르다.
- 먼저 4G에서는 방문 네트워크의 MME가 인증의 결과를 결정했지만, 5G에서는 홈 네트워크 측에서 결정하되, 방문 네트워크 측에서 거절할 수 있다.
- 5G 네트워크는 위와 같은 AKA 프로토콜을 포함해, 추가로 두개의 인증과 키 합의 프로토콜을 지원한다.
- 하나는 $AKA’$라고 불리우며, AKA와 비슷하지만, EAP 프로토콜을 이용하며 메시지가 조금 다르다.
- 나머지 하나는 IOT 환경에서 사용되며 미리 공유된 비밀키 $K_{HSS-M}$가 사용되지 않는다.
- 5G에서는 공용 키로 IMSI를 암호화해서 보내므로 전송간에 IMSI의 원문이 탈취될 수 없다.
더욱 자세한 4G/5G 보안은 [3GPP SAE 2019; Cable Labs 2019; Cichonski 2017]에서 확인바란다.
AES(Advanced Encryption Standard) 대칭키 암호화
DES를 대체하는 대칭키 알고리즘 정확히는 Rijindael 알고리즘 중 블록 크기가 128 비트인 알고리즘.
DES에 비해 가변 길이의 블록과 가변 길이의 키 사용이 가능하며, 속도와 코드 효율성이 뛰어남,
페이스텔 구조가 아닌 SPN(Substitution - Permutation Network) 구조를 이용
대칭키 암호화에서 가장 널리 쓰이고 있음
8.9 운영 보안: 방화벽과 침입 감지 체계(Operational Security: Firewalls and Intrusion Detection Systems)
현대에서는 네트워크 관리자가 네트워크의 패킷을 감시, 허용, 차단하고, 보안을 체크하고, 포워드하기 위해 방화벽(firewalls), IDS(intrusion detection systems), IPS(intrusion prevention systems)를 사용한다.
8.9.1 방화벽 (Firewalls)
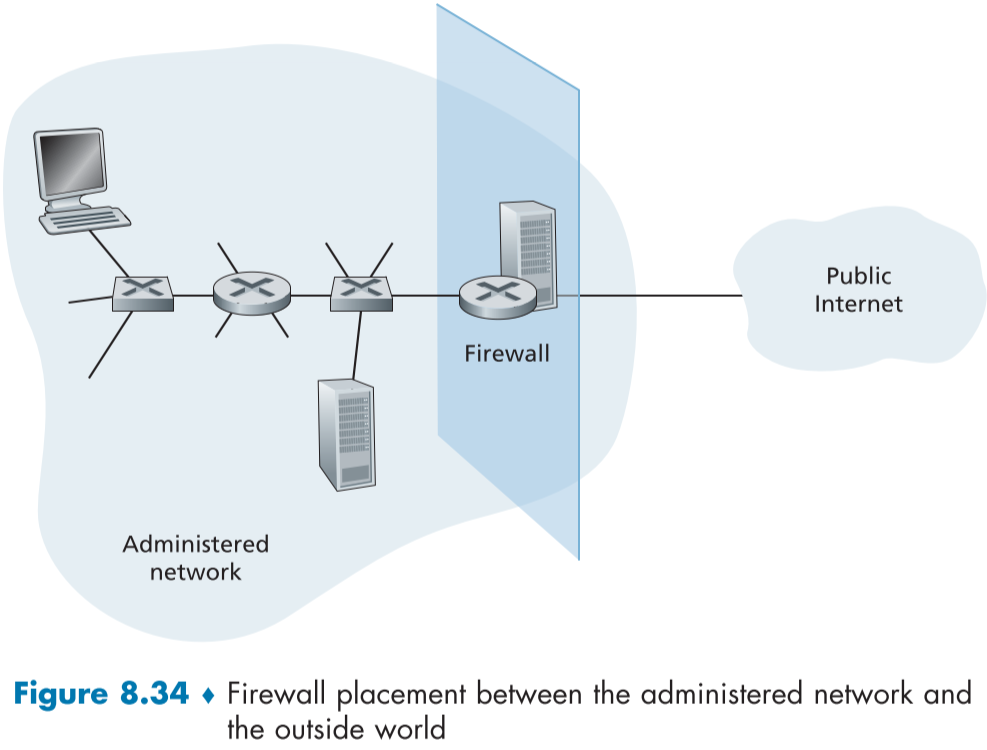
방화벽(Firewalls)은 조직 내부망을 인터넷으로 부터 격리하고 일부 패킷의 출입을 차단하는 하드웨어와 소프트웨어의 조합이다.
방화벽은 네트워크 관리자로 하여금 트래픽 조절을 통해 외부 세계와 자원의 상호 접근을 조정하게 해준다. 다음은 방화벽의 목적이다.
-
모든 트래픽은 방화벽을 통해서만 출입(All traffic from outside to inside, and vice versa, passes through the firewall)
figure 8.34는 관리 네트워크와 인터넷 사이에 위치한 방화벽에 대한 묘사이다. 거대 조직은 묘사와 달리 다단계 방화벽이나 분산 방화벽을 이용하며, 이럴 경우 묘사보다 더욱 관리가 힘들고, 보안 접근 정책 준수가 힘들어진다.
-
로컬 보안 정책에 따라 허용된 트래픽만 출입(Only authorized traffic, as defined by the local security policy, will be allowed to pass)
모든 트래픽 출입은 방화벽이 허용한 경우에만 가능하다.
-
방화벽은 침입에 면역이어야 함(The firewall itself is immune to penetration)
만약 방화벽이 공격 당해 공격자의 입맛대로 트래픽이 조절된다면, 방화벽은 없으니만 못하게 되므로, 보안에 각별한 주의가 필요하다.
Cisco, Check Point 같은 상용 방화벽도 있지만, 오픈소스 Linux 계열 소프트웨어 Linux box의 iptable을 손보는 것도 가능하고, 또는 최신 라우터들에 포함되어있는 기능이나 SDN을 통해 원격으로 트래픽을 조종하는 것도 가능하다.
방화벽은 크게 전통 패킷 필터(Traditional Packet Filters), 상태 분석형 필터(Stateful Packet Filters), 응용 계층 게이트웨이(Application Gateway)로 나뉜다.
전통적인 패킷 필터 (Traditional Packet Filters)
라우터로 ISP, 더나아가 인터넷과 조직 내부망이 연결되어 있는 형태라면, 해당 라우터에 패킷 필터링을 이용해 방화벽을 만들 수 있다.
패킷 필터는 각 데이터그램을 조사하여 관리자가 정한 규칙에 따라 통과와 차단을 결정한다.
보통 필터링의 결정 요소로는 다음이 존재한다.
- 출발지, 도착지 IP 주소
- 데이터그램의 Protocol type 필드(TCP, UDP, ICMP, OSPF 등)
- TCP, UDP 출발지, 도착지 포트번호
- TCP flag bit 필드: SYN, ACK 등
- ICMP 메시지 type
- 출입 라우터 인터페이스, 출입 네트워크
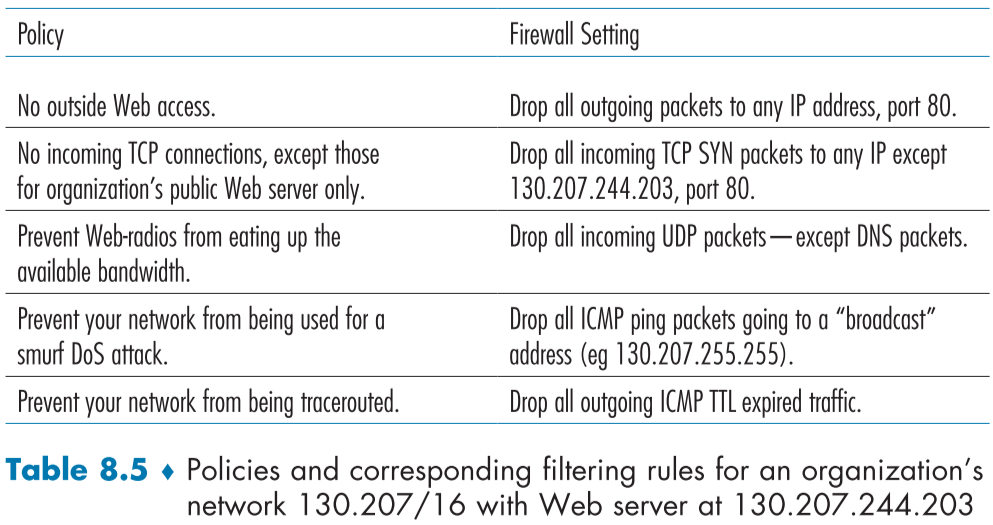
| 정책 | 방화벽 설정 |
|---|---|
| 외부 웹 접근 금지 | 포트번호 80번인 외부로 나가는 패킷 막기 |
| 조직의 웹서버를 제외한 TCP 연결 금지 | 특정 IP 주소, 포트 80번인 IP를 제외하고 모든 TCP SYN 패킷 막기 |
| 대역폭을 잡아먹는 웹 라디오 금지 | DNS를 제외한 모든 UDP 패킷 막기 |
| DoS 공격 방지 | 브로드캐스트 주소의 ICMP 핑 패킷 막기 |
| traceroute의 핑 금지 | 나가는 ICMP TTL expired 패킷 막기 |
Table 8.5는 조직내 정책과 그에 따른 방화벽 설정의 예이다.
예를 들어 외부 인원이 우리 측에 TCP 연결을 걸어오는 것은 막고, 우리가 외부에 TCP 연결을 거는 것은 허용하고 싶다면, TCP의 첫 연결 요청의 경우는 TCP ㅁ차 bit가 0이고, 이후로의 모든 TCP 세그먼트는 TCP ACK가 1이므로, TCP ACK bit가 0인 세그먼트가 들어오는 것을 막으면 된다.
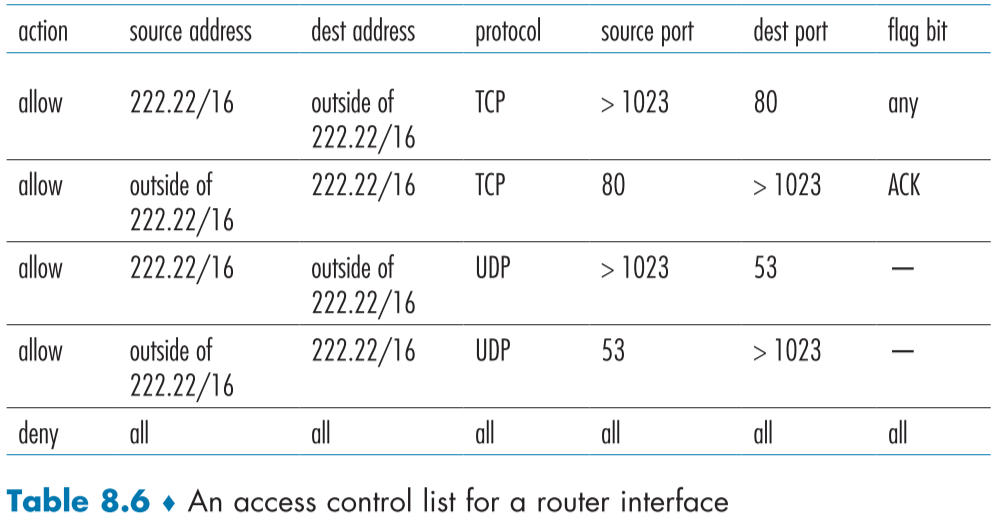
Table 8.6은 조직을 위한 라우터의 접근 조정 리스트 예시이다.
기본적으로 맨 아래에 deny 항목에 all이 적혀있으므로, 일반적인 상황에서는 접근을 막고, 예외 사항을 두어 푸는 방식으로 되어있다.
위의 두 규칙을 통해 외부에서 들어오는 TCP 연결은 막돼, 우리가 외부로 보내는 TCP 연결은 가능해지며, 3번째 4번째 규칙을 통해 DNS 패킷은 통과할 수 있게 되었다.
위와 같은 방호벽 설정 규칙은 라우터의 접근 조정 리스트로 구현되며, 각 라우터 인터페이스는 각기 다른 리스트를 가지고 있다.
이러한 접근 제어 리스트는 외부 ISP와 연결되어있는 라우터 인터페이스를 위한 것이며, 지나가는 모든 데이터그램 마다 적용된다.
[CERT Filtering 2012]에서는 알려진 보안 취약점을 대비하는 추천하는 포트, 프로토콜 패킷 필터링 규칙을 알려주고 있다.
이러한 접근 조정 리스트는 일반화된 포워딩(generalized forwarding) 규칙과 비슷하다.
상태 분석형 패킷 필터(Stateful Packet Filters)
상태 분석형 패킷 필터는 패킷 별로 규칙을 적용하는 것이 아니라, TCP 연결을 추적하여 필터링한다.
예를 들어 ACK 비트가 1인 TCP 패킷을 허용하게 된다면, Dos 공격, 내부 네트워크 맵핑 시도, 기형 패킷으로 인한 내부 시스템 공격 등을 받을 수 있으며, 그렇다고해서 이를 막아버리면, 내부 사용자가 외부에 인터넷 웹 서핑하는 것을 막지못한다.
방화벽은 TCP의 three-way 핸드셰이크(SYN, SYNACK, ACK)를 감지하여 연결의 시작에 추적을 시작하고, FIN 패킷이나 오랜 시간 동안 패킷의 주고받음이 없으면 연결 종료로 감지하여 추적을 멈출 수 있다.
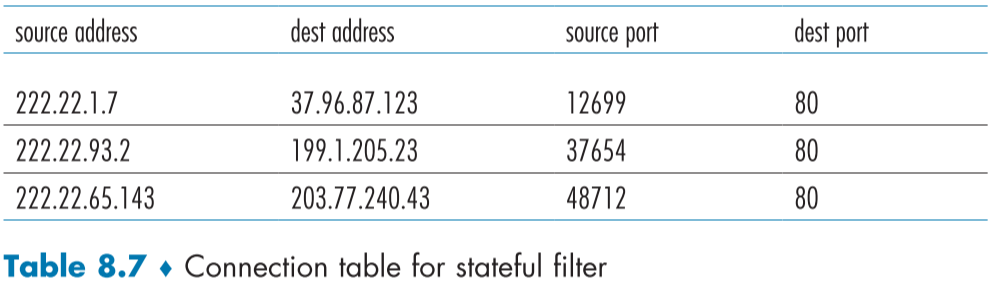
Table 8.7은 방화벽의 연결 테이블의 예시이다. 세션 테이블(session table)이라고도 불리운다.
연결 테이블은 내부에서 외부로 TCP 연결을 진행하기 위해 SYN 세그먼트를 보내면 감지되어 추가된다.
위의 연결 테이블을 보아, 현재 3개의 TCP 연결이 진행중이며, 내부에서 외부로 연결된 TCP 연결임을 알 수 있다.
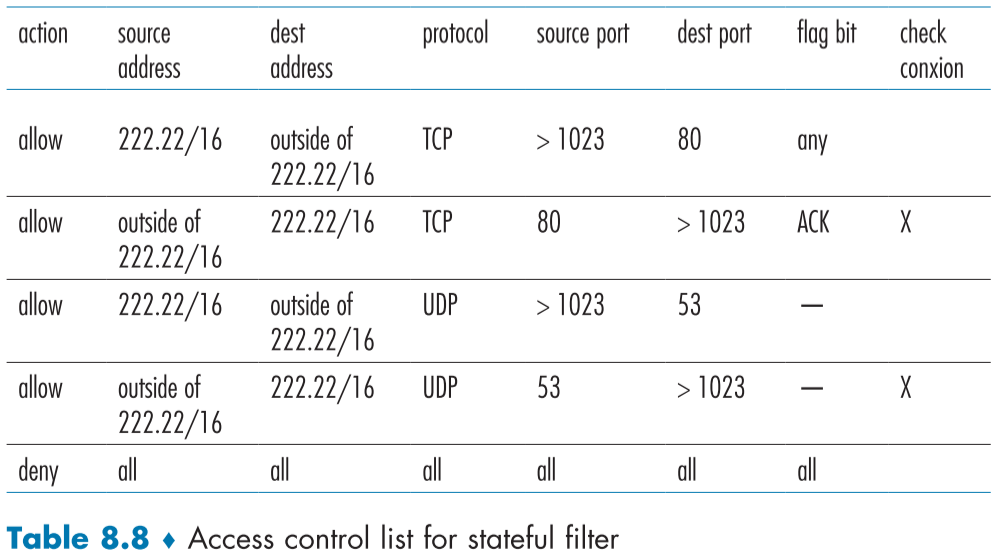
Table 8.8은 상태 분석형 패킷 필터의 접근 조정 리스트로, “check connection” 필드가 추가되어 이를 통해 해당 규칙을 적용하기 전에 먼저 연결 테이블을 확인해야 하는지 표시할 수 있다.
만약 표시가 되어있다면, 연결 테이블을 확인해 연결이 존재한다면 해당 규칙을 적용해준다.
예를 들어 Table 8.8의 경우 두번째 규칙이 표시되어 있기 때문에, 외부에서 뜬금없이 보내오는(보통 악의를 담은) ACK 세그먼트는 allow에 포함되더라도 연결이 없으므로 막히며, 내부 인원이 외부 인터넷으로 웹서핑하다가 답신으로 오는 ACK 세그먼트는 연결 테이블에 추가되어있을 것이므로 허용될 것이다.
응용 계층 게이트웨이 (Application Gateway)
만약 IP 주소나 포트 번호, 기타 패킷의 정보가 아닌, 보낸 인력의 직책, 권한, 또는 비밀번호 등으로 트래픽을 제한하고 싶다면 어떻게 할까?
이럴때는 방화벽이 패킷 필터와 응용 프로그램 게이트웨이 기능을 둘다 제공되는 응용 계층 게이트웨이를 사용해야 한다.
응용 계층 게이트웨이는 응용 프로그램 사양 서버로, 모든 출입 응용 계층 데이터가 출입한다.
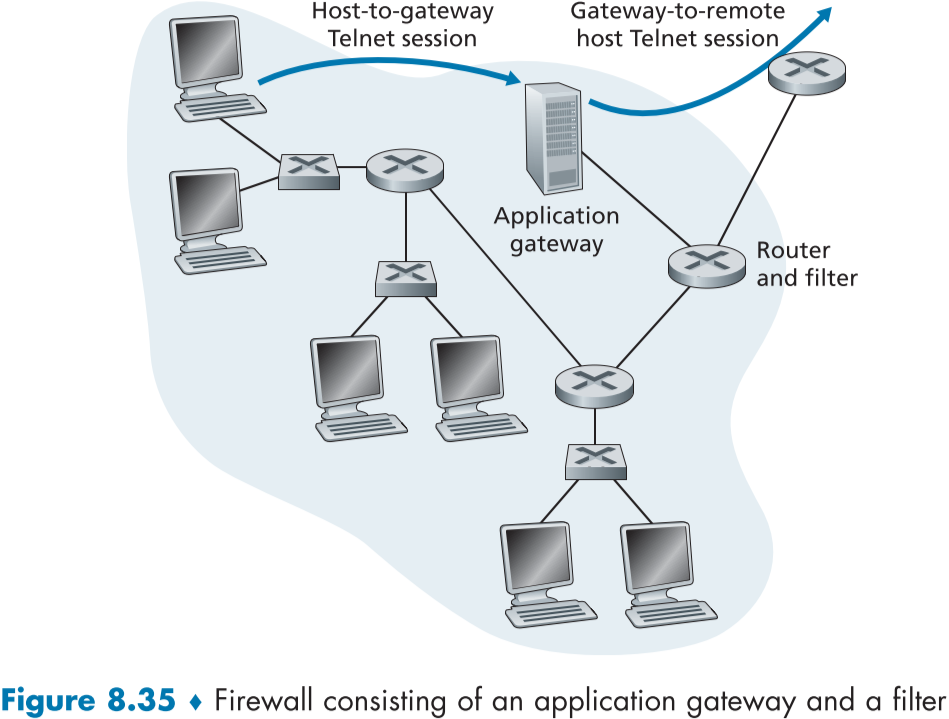
예를 들어, 내부에서 일부 인원은 외부로 텔넷 요청을 보낼 수 있고, 반대로 외부의 모든 인원들은 내부에 텔넷 요청을 보낼수 없게 하고 싶다면 figure 8.35처럼 라우터의 패킷 필터와 텔넷 응용 계층 게이트웨이를 함께 사용하여 구현할 수 있다.
응용 계층 게이트웨이를 통하지 않는 모든 텔넷 연결은 라우터 필터 측에서 막도록 설정하면, 모든 외부로 향하는 텔넷 연결은 응용 계층 게이트웨이를 지나가야만 한다.
이때 응용 계층 게이트웨이에서는 그렇게 들어오는 텔넷 연결들에게 유저 ID와 비밀번호를 요구할 수 있고, 이에 통과하는 경우에 연결할 호스트명을 받아 대신 telnet 연결을 생성해 입력값과 응답 값을 중계할 수 있다. 이때 라우터는 연결에 성공한 텔넷 연결에 대해 추가적인 필터링을 한다.
사내망은 또한, HTTP, FTP, email, Web cache 등 여러 응용 계층 게이트웨이를 두는 것이 일반적이며, 각기 다른 응용 프로그램마다 게이트웨이를 둬야 된다는 점과 응용 프로그램 기능들이 게이트웨이를 중계하여 지나가야하기 때문에 성능상의 이슈가 있을 수 있으며, 사내망 외부와 내부 사용자들은 응용 프로그램 사용을 위해 응용 계층 게이트웨이와 통신하는 방법을 숙지해야 한다는 단점들이 존재한다.
익명성과 프라이버시
만약 사용자가 내가 방문하는 웹사이트에게 나의 IP를 알리고 싶지 않고, 나의 ISP에게 내가 방문한 웹사이트와 데이터 교환 내용을 알리고 싶지않으면, 즉 익명성과 프라이버시를 지키고 싶으면 어떻게 해야할까? SSL 같은 강력한 기밀성을 제공하는 프로토콜을 쓴다고 해도, 출발지 IP 주소와 도착지 IP 주소는 남게 되어 ISP 측에서 확인할 수 있다.
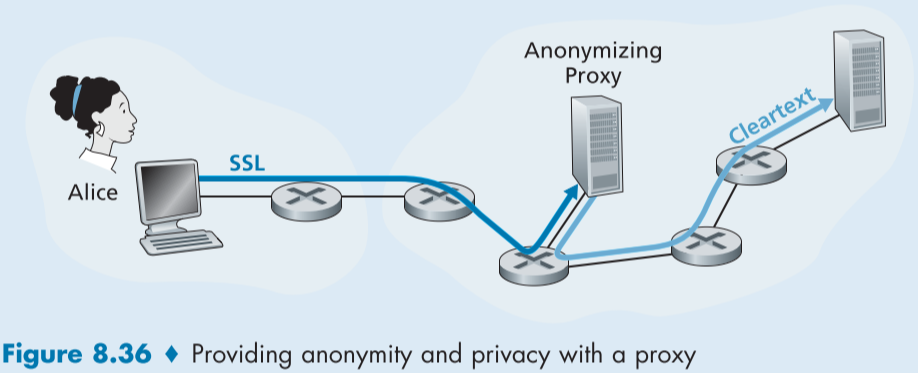
익명성과 프라이버시를 해결하기 위해, 믿음직한 프록시 서버 서비스와 SSL을 이용하면 된다.
figure 8.36은 프록시 서버의 사용 예시이다.
먼저 프록시 서버와 SSL 연결을 맺고, 통신하고 싶은 URL의 HTTP 요청 메시지를 암호화해 프록시 서버로 보내면, 프록시 서버는 SSL 패킷에서 HTTP 요청 메시지를 복호화해 추출하고, 원문의 HTTP 요청을 웹사이트로 보내준다.
웹사이트의 응답은 프록시 서버로 가게되고, 이후 프록시 서버는 해당 메시지를 SSL을 통해 다시 나에게 되돌려 준다.
ISP나 웹사이트 입장에서는 웹사이트는 프록시 서버와 통신하였고, 당신은 프록시 서버와 통신한 것이므로, 프록시를 이용한 사람이 혼자가 아닌 이상, 누가 어느 웹사이트에 들려 어떤 메시지를 주고 받았는지 알 수 없다. 또한, 프록시와 웹사이트가 SSL 같은 보안 통신을 지원한다면, 대화내용 조차 아무도 알 수 없다. 이렇나 프록시 서버 서비스는 상용으로도 많이 나와있다.
단, 내가 고른 프록시 서버 측에서는 출발지와 도착지 IP 주소, 주고 받은 패킷이 모두 알 수 있으므로, 만약 믿음직하지 못한 프록시 서버라면 정반대의 결과가 나올 수 있다.
이를 해결하기 위해서는 TOR 서비스를 이용할 수 있다.
TOR는 비공모식 프록시 서버를 이용해 트래픽을 숨기는데, 자세한 방법은 다음과 같다.
TOR는 각각 독립적인 개인이 프록시 서버를 프록시 풀에 제공할 수 있게 되어있는데, 유저가 TOR을 사용하면, TOR은 프록시 풀에서 무작위의 3개 서버를 가져와 연쇄적으로 3개의 서버를 경유해서 다른 서버에 접근하게 된다.
이로 인해, 각각의 무작위로 골라진 프록시 서버들은 앞, 뒤, 또는 양쪽에 다른 프록시 서버가 위치하므로 패킷을 주고받은 사용자, 패킷을 주고받은 서버, 이 둘 중에 최소 한가지는 모르게 된다.
무작위로 골라졌으므로, 특정 사용자를 노려 데이터를 도청하는 것은 불가능하고, 도청한 데이터는 누가 보냈는지, 또는 누구에게 보냈는지 모르는 불완전한 데이터가 된다.
8.9.2 침입자 감지 체계(Intrusion Detection Systems)
방화벽만으로는 공격을 완벽히 막기 힘들고, 추가적으로 헤더 필드와 패킷의 페이로드까지 검사하는 심층 패킷 분석(deep packet inspection)이 필요하다.
일부 응용 계층 게이트웨이가 심층 패킷 분석을 실시하나, 일부 응용 프로그램에 한해서이며, 패킷의 헤더, 심층 패킷 분석을 하고, 이상 징후가 발견되면 패킷들의 사설망 진입을 차단하거나 네트워크 관리자에게 경고를 줄 수 있는 장치인 IDS(intrusion detection system, 칩입 감지 체계)를 사용하면 좋다.
만약 아예 의심스러운 패킷을 필터링해버리면 IPS(intrusion prevention system, 침입 방지 체계)라고 부르기도 한다.
IDS는 네트워크 매핑, 포트 탐지, TCP 스택 탐지, DoS 대역폭 범람 공격, 웜과 바이러스, 운영체제 취약점 공격, 응용 프로그램 취약점 공격 등 수많은 범위의 공격을 막을 수 있으며, 오늘날에는 수많은 조직들이 IDS 체계를 갖추고 있다.
몇몇은 Cisco, Check Point 같은 상용 IDS를, 몇몇은 Snort 같은 오픈소스 IDS를 이용하기도 한다.
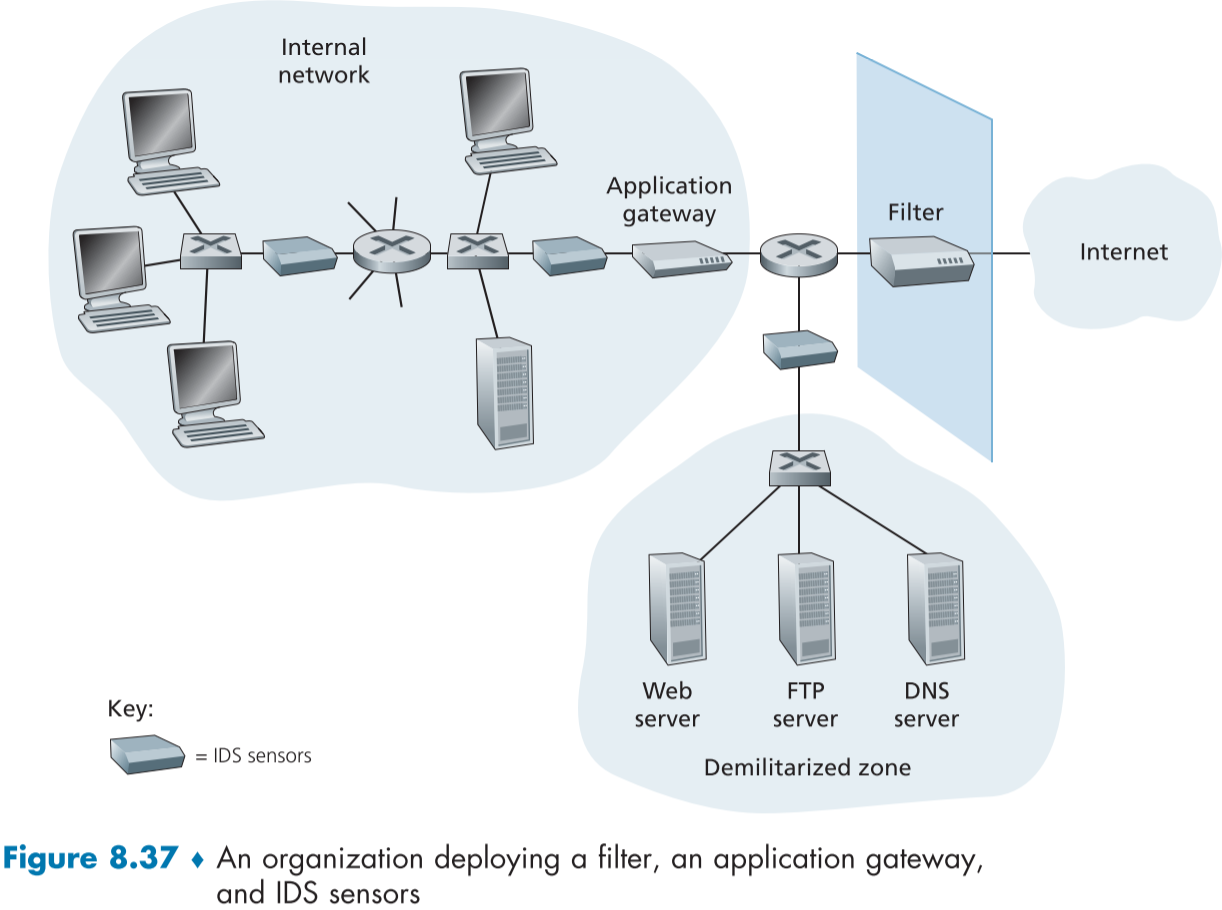
조직은 Figure 8.37처럼 조직망에 하나 이상의 IDS 센서를 놓기도 한다. 다수의 IDS 센서들은 의심스러운 트래픽 활동에 대한 정보를 모아 중앙 IDS 처리장치에 보내고, 중앙 IDS 처리장치는 이들을 취합하여 네트워크 관리자에게 경고하고 조치를 취하게 만든다.
IDS를 방화벽 뒤나, 방화벽의 기능으로 놓고 하나만 사용하지 않는 이유는, IDS가 심층 패킷 분석 이외에도 패킷의 시그너처를 비교하는데, 이 과정이 아주 오래 걸리는 과정이므로, 각 IDS는 지나가는 패킷의 일부분만 검색하고 다른 부분은 다른 IDS가 처리한다. 최근의 고성능 IDS들은 입구에 하나만 놓기도 한다.
Figure 8.37에서 조직은 네트워크 내부를 패킷 필터 라우터, 응용 계층 게이트웨이, IDS 센서 등으로 무장한 높은 보안 지역과 외부 인터넷과의 통신이 잦은 DNS, 웹서버 등이 존재하는 낮은 보안 지역인 DMZ(demilitarized zone)으로 나누곤 한다. DMZ의 보안은 보통 패킷 필터(방화벽)과 IDS 센서의 감시 정도이다.
IDS는 크게 시그너쳐 기반 체계(signature-based systems)와 이상현상 기반 체계(anomaly based systems)로 나뉜다.
시그너처 기반 IDS는 공격 패킷들의 시그너쳐를 데이터베이스에 저장해 놓고, 이를 지나가는 패킷들과 비교해 관리자 측에 경고하거나 기록한다. 각 시그너처는 일종의 공격 활동과 관련된 패킷의 패턴들이며, 이는 한 패킷의 특성(헤더 필드 값, 페이로드의 패턴 등)이거나 여러 패킷들의 연속일 수도 있다. 이러한 시그너처는 관리자에 의해 수정되거나 추가될 수도 있다.
다만, 시그너처 기반 IDS에게 단점들이 있는데, 과거에 경험했던 공격만 막을 수 있고, 새로 생긴 공격이나 처음 보는 공격은 막지 못한다는 점, 시그너쳐가 일치하여도 공격과 관련이 없는 정상적인 패킷은 경우에는 거짓 알람이 된다는 점, 시그너처를 비교하는 과정이 너무 느리기 때문에 가끔 IDS가 일을 전부 처리하지 못하고 공격 패킷을 허용하거나 먹통이 될수 있다는 점이다.
이상현상 기반 IDS는 평상시에는 트래픽에 대한 프로필을 작성하다가 비정상적인 패킷 흐름 통계를 감지하는 방식이다. 예를 들어 비정상적으로 ICMP 패킷이 많아지거나 포트 스캔, 핑 메시지가 많이 들어오게 된다면, 이상 현상 기반 IDS가 이를 경고하게 된다. 이러한 방식이므로, 처음보는 공격, 새로운 공격에도 대처할 수 있다는 장점이 있다. 단점으로는 이러한 이상 현상과 정상 상태를 구분하기 힘들다는 점이다.
최근의 대부분의 IDS는 시그너처 기반이며, 일부는 이상 현상 탐지 기능도 포함하는 경우도 있다.
스노트 (Snort)
스노트는 널리 사용되고 있는 Linux, UNIX, Window에서 사용가능한 오픈소스 IDS로, 패킷 스니핑 인터페이스인 libpcap을 이용해 100Mbps 정도의 패킷을 탐지하며, 이 이상은 여러 스노트 센서를 사용해서 늘려야 한다.
다음은 스노트 시그너처의 예시이다.
alert icmp $EXTERNAL_NET any -&#62; $HOME_NET any
(msg:"ICMP PING NMAP"; dsize: 0; itype: 8;)
이는 외부($EXTERNAL_NET)에서 조직망($HOME_NET)에 들어오는 type(itype) 필드가 8(ICMP), 페이로드 크기(dsize)가 0인 모든 ICMP가 감지되면 “ICMP PING NMAP”이라는 메시지로 경고하게끔 설정한 구문이다. 이를 통해 nmap이 보내는 nmap 핑 스윕 공격에 대해 경고를 받을 수 있을 것이다.
스노트의 장점은 거대한 커뮤니티로 수많은 보안 전문가들이 시그너처 데이터베이스를 유지, 갱신하고 있다. 또한 추가로 스노트 시그너처 구문을 이용해 네트워크 관리자가 조직의 시그너처 데이터베이스에 커스텀 시그너처를 추가하거나 기존의 것을 수정하여 알맞게 활용할 수 있다.
_articles/computer_science/network/네트워크 정리-Chap 8-컴퓨터 네트워크 보안.md