풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
네트워크 정리-Chap 6-연결 계층과 LAN
Chapter 6. 연결 계층과 LAN(Link Layer and LAN)
- 6.1 연결 계층 소개 (Introduction to the Link Layer)
- 6.2 에러 감지와 수정 기술(Error-Detection and Correction Techniques)
- 6.3 다중 접근 링크와 프로토콜 (Multiple Access Links and Protocols)
- 6.4 스위치 근거리 네트워크 (Switched Local Area Networks)
- 6.5 연결 가상화: 연결 계층으로서의 네트워크 (Link Virtualization: A Network as a Link Layer)
- 6.6 데이터 센터 네트워킹 (Data Center Networking)
- 6.7 회고 : 웹 페이지 요청의 하루(Retrospective: A Day in the Life of a Web Page Request)
Computer Networking: A Top-Down Approach(Jim Kurose, Keith Ross)의 강의를 정리한 내용입니다.
( Jim Kurose Homepage )student resources : Companion Website, Computer Networking: a Top-Down Approach, 8/e
이전 챕터에서는 두 호스트 간의 연결에 대해서 배웠다. 이번에는 각 링크에서의 통신에 대해서 배워보자.
연결 계층에는 근본적으로 다른 두가지 연결 계층 채널이 있다.
-
브로드캐스트 채널(broadcast channel)
여러 호스트를 무선 LAN, 인공위성, HFC(hybrid fiber-coaxial cable, 복합 동축 섬유 회선) 등을 이용해 연결한 네트워크.
동일한 브로드캐스트 통신 채널에서 연결되려면, 매체 연결 프로토콜(medium acess protocol)로 프레임 전송을 조정 해야한다.
주로 중앙 컨트롤러나, 개개의 호스트들이 조정한다.
-
지점간 통신 연결(point-to-point communication link)
보통 두 라우터나 장치 같이 두 객체간을 연결하는 방법.
전화선부터 광섬유까지 다양한 곳에서 프레임을 전송하는데 사용하는 프로토콜인 PPP(Point-to-Point Protocol)가 있다.
이외에도 에러 감지와 수정, 이더넷, LAN, virtual LAN, 데이터 센터 네트워크 등에 대해 알아보자.
6.1 연결 계층 소개 (Introduction to the Link Layer)
앞으로 링크 계층 프로토콜로 돌아가는 장치들을 노드(node)라고 칭할 것이며, 호스트, 라우터, 스위치, 와이파이 접근 지점 등이 그 예이다.
링크는 멀리 떨어진 호스트간의 연결(connection)과도 구분하기위해 통신 경로를 통해 인접 노드를 연결하는 통신 채널을 링크(link)라고 칭할 것이다.
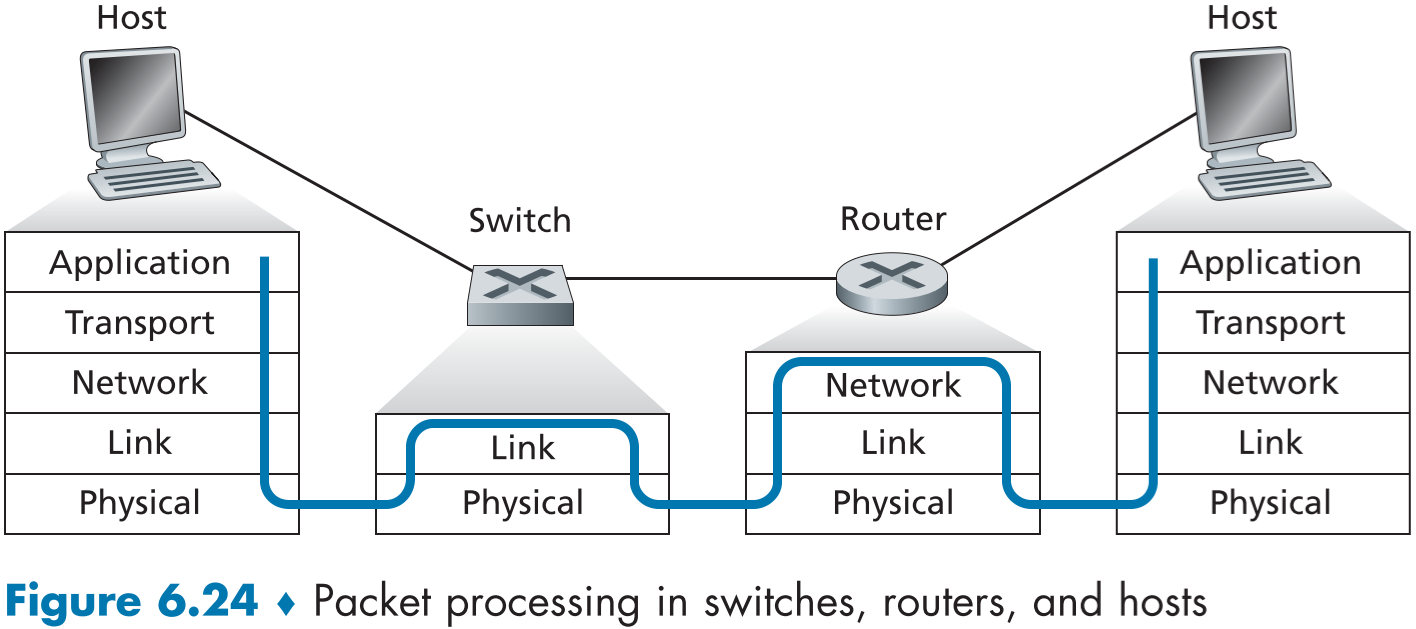
아래 fig 6.1의 화살표를 보면 무선 통신 호스트와 서버 호스트의 통신(호스트, WIFI 접근 지점, 이더넷 링크, 스위치 링크, 라우터 링크를 통함)을 볼 수 있다. 전송 노드는 데이터그램을 캡슐화하여 보내는데, 이를 연결 계층 프레임(link-layer frame)이라고 한다.
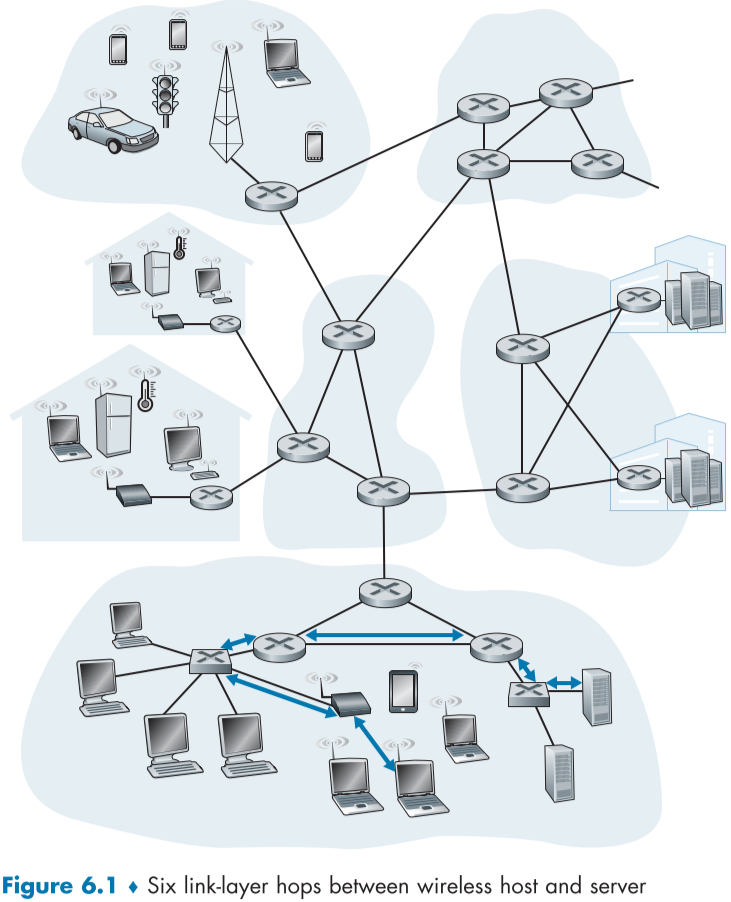
연결 계층과 네트워크 계층을 비유해보자면, 여행객은 데이터그램, 여행객이 타는 교통 수단의 종류(기차, 배, 비행기)은 링크의 연결 계층 프로토콜, 각 교통수단의 출발지에서 도착지까지 연결은 링크, 이러한 여행객의 경로를 짠 여행 가이드는 라우팅 프로토콜이라 볼 수 있다.
6.1.1 연결 계층에 의해 제공되는 서비스들 (The Services Provided by the Link Layer)
연결 계층 프로토콜들의 공통의 기본 서비스는 데이터그램을 단일 통신 링크를 통해 한 노드에서 인접 노드로 보내는 것이며, 상세한 추가 서비스는 프로토콜마다 다르며 다음과 같은 것이 있다..
- 프레임화(Framing) : 모든 연결 계층 프로토콜은 링크로 보내기 전에 각 네트워크 계층 데이터그램을 연결 계층 프레임으로 캡슐화한다. 여느 패킷들과 마찬가지로 헤더 필드와 페이로드 필드로 되어 있으며, 프로토콜 마다 프레임의 구조가 다르다.
- 링크 접근(Link access) : 매체 접근 제어(medium access control, MAC) 프로토콜은 프레임이 링크를 통해 전송되는 규칙을 명시하는데, 간단하게 링크가 사용 가능할 때, 송신자가 전송할 수 있게 해준다. 여러 노드가 동시에 하나의 전파(broadcast) 링크를 공유하려 하면 다중 접근 문제(multiple access problem)이라는 문제가 생기며, MAC 프로토콜은 이러한 많은 노드의 전송을 관리한다.
- 신뢰성 전달(Reliable devlivery): 노드 간의 전송에 오류가 없음을 보장한다. 전달 계층과 유사하게 재전송과 ACK를 통해 구현되며, 오류가 잦은 무선 연결은 이를 중시하며, 오류가 적은 유선 연결의 경우 일부 프로토콜은 데이터 신뢰성 전달 서비스를 제공하지 않기도 한다.
- 에러 감지 및 수정(Error detection and correction) : 수신자측의 연결 계층 하드웨어는 데이터의 비트 값이 반전되면 이를 감지할 수 있다. 이러한 비트 에러는 물리적으로, 신호 감쇠나 전자기적 노이즈로 인해 발생할 수 있으며, 이를 감지하고 수정하기 위해 에러 감지 비트가 프레임에 포함되어 있고 수신자 노드 측에서 에러를 확인한다. 전달 계층, 연결 계층의 오류 감지인 인터넷 체크섬(checksum)보다 더욱 복잡하고 하드웨어로 구현되어 있으며, 감지 뿐만 아니라 오류를 수정할 수도 있다.
6.1.2 연결 계층은 어디에 구현되는가? (Where Is the Link Layer Implemented?)
연결 계층의 경우 주로 네트워크 어답터(network adapter) 또는 네트워크 인터페이스 컨트롤러(NIC, network interface controller)라는 하드웨어 칩에 주로 구현되며, 예시로 이더넷의 경우 주로 메인보드 칩셋이나 저가형 이더넷 칩에 구현된다.
구동의 경우, 송신자 측은 컨트롤러가 상위 계층 프로토콜로 인해 호스트 메모리에 적재된 데이터그램을 가져와 연결 계층 프레임으로 만들고 통신 링크로 전송한다. 수신자 측은 전체 프레임을 받은 뒤 네트워크 계층 데이터그램을 추출하고, 에러 감지를 한다면, 헤더의 error-detection 비트를 확인하여 확인한다.
아래 fig 6.2는 전형적인 호스트 구조에서 보여준다.
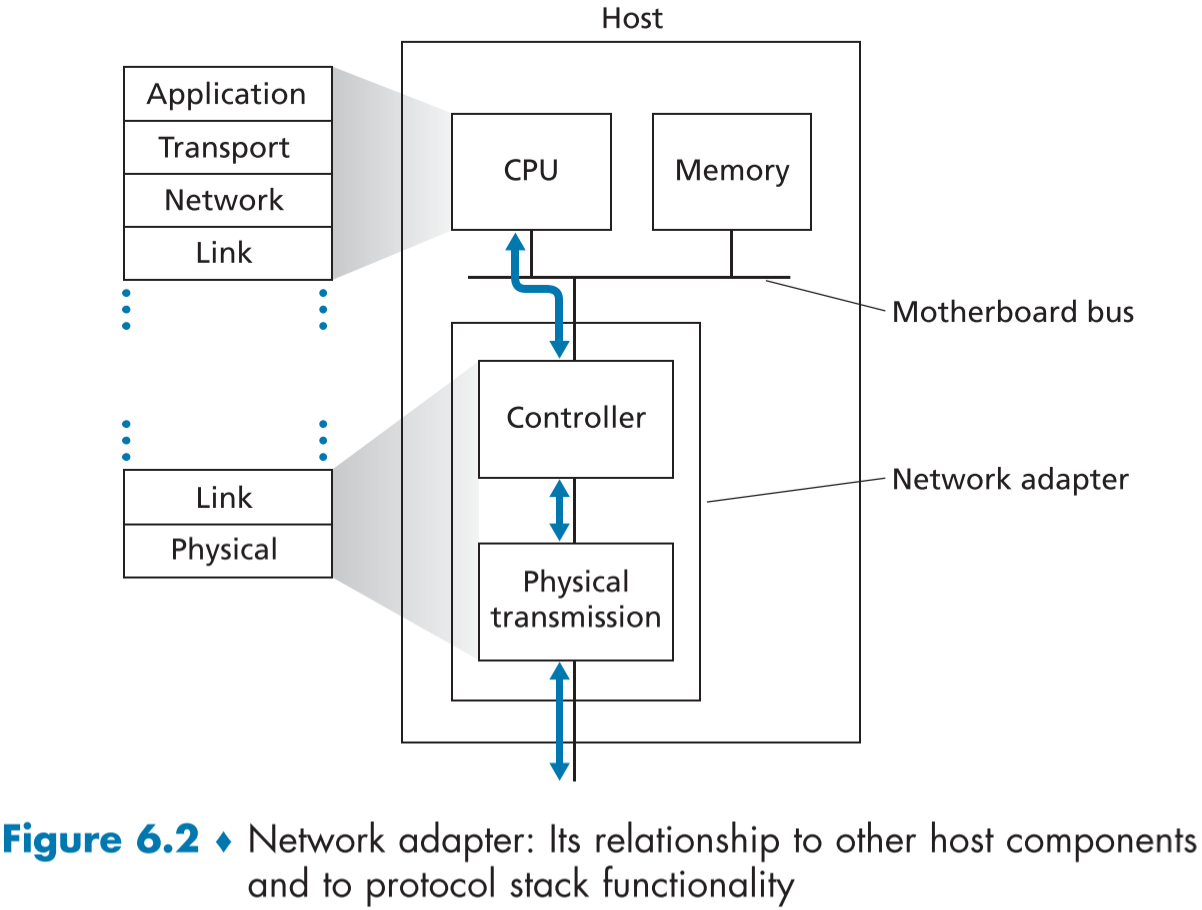
대부분의 연결 계층 부분은 칩셋 속의 하드웨어로, 일부분은 호스트의 CPU 안의 소프트웨어로 구현되는데, 소프트웨어 부분은 컨트롤러 가동, 연결 계층 주소 정보 취합 같은 좀더 상위 단계의 기능을 구현한다.
수신자 측의 연결 계층 소프트웨어은 프레임이 도착하면 하드웨어 컨트롤러의 방해에 반응하여, 에러 상태 확인 및 네트워크 계층으로의 전달 등을 진행한다.
이처럼 하드웨어와 소프트웨어가 섞여있는 구조는 연결 계층이 프로토콜 스택에서 하드웨어와 소프트웨어가 만나는 부분임을 의미한다.
6.2 에러 감지와 수정 기술(Error-Detection and Correction Techniques)
비트 단계 에러 감지 및 수정(bit-level error detection and correction)은 연결 계층 프레임의 비트들의 오류를 감지, 수정하는 서비스이며, 여기서 간단한 원리를 살펴보자.
아래 fig 6.3은 에러 감지 및 수정 시나리오를 나타낸 그림이다.
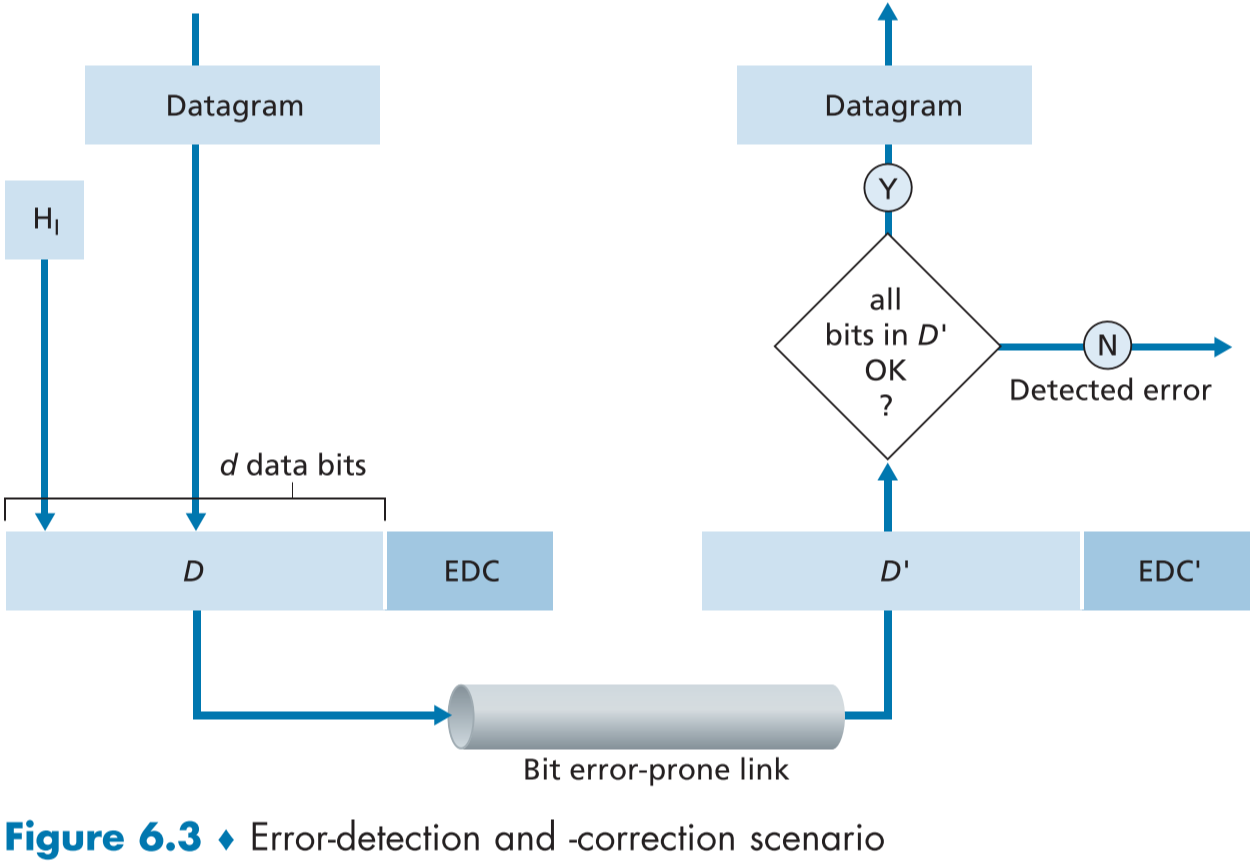
송신자측 노드는 헤더가 포함된 데이터그램 D를 에러로 부터 보호하기위해 에러 감지 및 수정 비트들(EDC, Error-detection and correction bits)를 데이터그램에 추가하고 이를 전송한다.
도착한 데이터 D와 EDC는 수신자측 노드에 의해 에러를 감지하게 되는데, 간단한 방법으로는 일부 탐지되지 않은 비트 에러(undetected bit errors)가 존재할 수 있다.
탐지되지 않은 비트 에러를 최소화하는 방법일 수록 더욱 많은 계산과 복잡함, 오버헤드가 요구된다.
에러를 줄이기 위한 방법들을 살펴보자.
6.2.1 동등성 검사 (Parity Checks)
가장 간단한 에러 감지 형태는 단일 Parity 비트(Parity bit)이며, 짝수 동등성과 홀수 동등성이 있다.
짝수 동등성 비트는 d개의 데이터 비트와 Parity 비트 자신의 1의 갯수의 합이 짝수개가 되도록 표기하며,
홀수 동등성 비트는 d개의 데이터 비트와 Parity 비트 자신의 1의 갯수의 합이 홀수개가 되도록 표기한다.
즉, d개의 데이터 비트의 1의 갯수가 홀수개라면 짝수 동등성 비트는 1, 홀수 동등성 비트는 0으로 표기되며, 반대로 짝수개라면 값이 반전된다.

수신 측에서도 간단하게, Parity 비트를 포함, 1의 갯수를 센 뒤, Parity 비트 설정에 따라 아래와 같은 표의 원리로 에러를 감지한다. (직접 예시를 생각하며 이해해 보자.)
| 짝수 동등성에서의 1의 갯수 | 짝수 Parity 비트가 1인 경우 | 짝수 Parity 비트가 0인 경우 |
|---|---|---|
| 짝수 | 에러 없음 혹은 짝수 개의 에러 존재 | 홀수 개의 에러 존재 |
| 홀수 | 홀수 개의 에러 존재 | 에러 없음 혹은 짝수 개의 에러 존재 |
| 홀수 동등성에서의 1의 갯수 | 홀수 Parity 비트가 1인 경우 | 홀수 Parity 비트가 0인 경우 |
|---|---|---|
| 짝수 | 홀수 개의 에러 존재 | 에러 없음 혹은 짝수 개의 에러 존재 |
| 홀수 | 에러 없음 혹은 짝수 개의 에러 존재 | 홀수 개의 에러 존재 |
어느 설정이던지, 홀수 개의 에러는 감지 가능하고 짝수 개의 에러는 감지할 수 없다. 즉, 전체 에러의 절반은 감지할 수 없다.
비트 에러는 여러 비트에서 에러가 일어나는 버스트 에러(burst error)가 자주 일어나므로, 1 비트 에러만 감지하는 이 경우는 실용성이 없다.
- 에러 비트가 연속 해야만 버스트 에러 인것이 아님을 주의!
- 예를 들어 111111 비트가 001101 비트로 오류가 났을 시, 0번~1번 비트만 버스트에러인 것이 아니라, 0~4번까지가 버스트 에러 지점이다.
- 즉 에러 비트 사이의 올바른 비트도 포함해서, 비트가 처음 에러난 구간부터 마지막 비트 에러 구간까지가 버스트 에러이다.
fig 6.5는 1비트 동등성 에러 체크의 이차원 일반화 모습이다.
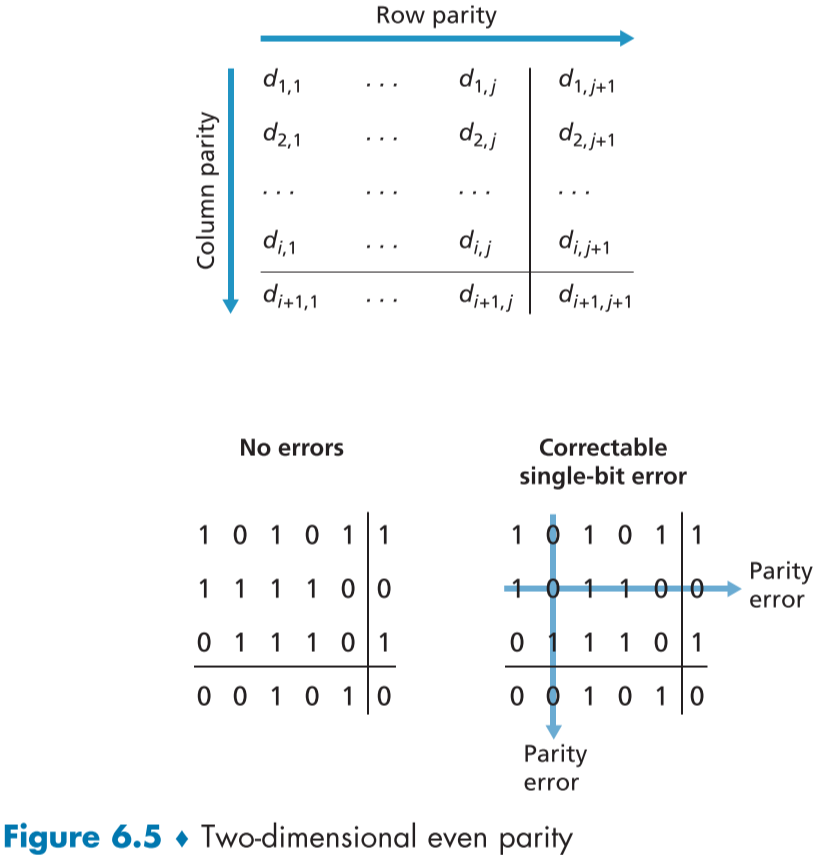
위처럼 데이터를 (i,j)의 2차원 배열로 바꾼 뒤, 각 열과 행에 해당하는 총 i + j + 1((i,j), 최우측아래 줄에도 있어야 함)개의 Parity 비트를 이용해 단일 비트 에러에 대해 탐지 및 수정이 가능하며, 어떠한 조합에서의 2개의 비트 에러는 탐지만 가능하다.
- 3개 이상 부터는 모든 에러의 탐지를 보장하지 않는다.
수신자 측에서 에러를 탐지 및 수정할 수 있는 능력을 포워드 에러 수정(FEC, Forward Error Correction)이라고 하며, 오디오 관련해서 사용된다.
주로 FEC 단일로, 또는 ARQ(Automatic Repeat reQuest, 재전송 기반 프로토콜, 3장 참조)와 함께 사용하여 에러 수정으로 ARQ의 재전송 횟수를 줄여주는 역할을 하며, 이는 대역폭이 좁거나 아주 먼 거리 통신에 의해 전파(propagation) 속도가 늦어진 통신이나, 실시간 통신에 효과적이다.
FEC 에러 제어에 대한 내용은 [Biersack 1992; Nonnenmacher 1998; Byers 1998; Shacham 1990]
6.2.2 체크섬 방법들 (Checksumming methods)
인터넷 체크섬(Internet checksum)은 이전에 우리가 배웠던 방법으로, 데이터 바이트들을 16 비트 정수로 생각하고 모두 더해서 구한다. 이렇게 구한 값의 1의 보수를 헤더에 추가하면, 수신자 측에서 모든 바이트들의 합이 16비트 자리 전부 1인 값이 나오지 않으면 오류로 생각한다. 자세한 구현은 [RFC 1071]에 나와있고, TCP와 UDP 처럼, 전체 모든 바이트를 대상으로 하는 체크섬, IP 처럼 헤더만 대상으로 하는 체크섬, XPS 처럼 헤더와 전체 패킷에 대한 체크섬이 따로 나와 있는 경우도 있다.
체크섬은 오버헤드가 비교적 적지만 에러 방지 효과가 순환 중복 검사 (CRC, cyclic redundancy check)에 비해 약하다. 하지만 하드웨어를 사용할 수 있는 연결 계층에 비해 소프트웨어에서 구현되는 전달 계층의 특성상, 오버헤드가 큰 검사를 사용하면 너무 느려지기 때문에 간단하고 빠른 체크섬을 사용하는 것이다.
가중 체크섬, CRC 등의 최적화되고 빠른 소프트웨어적 구현 기술은 [Feldmeier 1995]에서 확인 가능하다.
6.2.3 순환 중복 검사 (Cyclic Redundancy Check (CRC))
CRC 코드는 널리 사용되고 있는 에러 검사 방법으로, CRC codes는 비트를 0 또는 1의 계수를 가진 다항식으로 보면, 마치 다항식처럼 보이므로 다항식 코드(polynomial codes)라고도 알려져있다.
CRC 코드의 원리는 Figure 6.6과 같다.
d 비트 길이의 데이터 D와 송수신자 양 측이 사전에 합의한 임의로 정한 r값에 대해 r+1 길이의 비트들인 생성자(generator) G가 있다.
G의 가장 중요한 비트는 G의 제일 좌측으로, 무조건 1이다.
- G의 길이가 CRC 표준으로 정해져있기 때문에, 지켜져야한다.
- 가장 왼쪽 첫번째 비트가 1이 아니면 길이가 달라진다. 예를 들어 1014는 4자리 수지만 0121는 3자리 수이다.
송신자는 기존 데이터 D에 추가로 r 만큼의 데이터 R을 더해 총 d+r 길이의 새로운 비트 패턴을 만드는 데, 이때의 r 비트는 d+r 비트 패턴이 G의 모듈로-2(modulo-2) 연산상, 나머지 없이 나누어 떨어지는 비트 패턴이 되도록 설정한다.
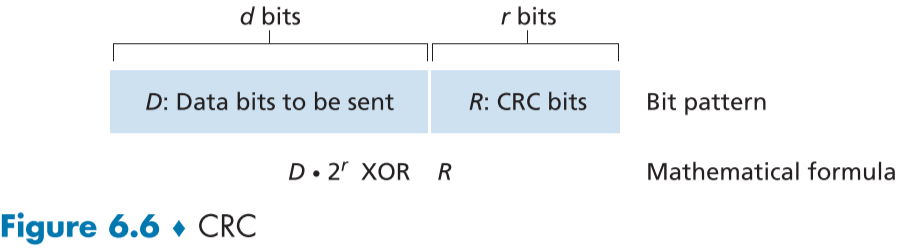
이후 수신자 측에서 받은 d+r 데이터를 G로 나누어 나누어 떨어진다면, 오류가 없고, 나머지가 생긴다면 오류가 생긴 것이다.
이때 모든 CRC 계산은 모듈로-2 연산에 덧셈과 뺄셈에 의한 받아올림(carry)과 받아내림(borrow)이 발생하지 않는다.
즉, 1+1이 된다면 10이 아니라 받아올림이 사라져 0이며, 10-1은 1이 아니라 받아내림이 사라져 11이다.
이는 덧셈과 뺄샘이 둘다 결과가 같고, 마치 비트 간의 XOR 연산을 한 것과 같은 결과를 낸다.
1011 XOR 0101 = 1110
1001 XOR 1101 = 0100
1011 - 0101 = 1110
1001 - 1101 = 0100
곱셈과 나눗셈의 경우, 받아올림(carry)과 받아내림(borrow)이 없는 베이스-2 연산(base-2 arithmetic)과 같으며, 마찬가지로 XOR 연산과 결과가 같다.
- 참고한 전공서적에서는 Base와 modulo를 동일하게 적어놓은것 같다…
베이스-n 연산(base-n arithmetic): 0부터 n-1까지를 밑수로 하는 밑(base)이 10인 산술 연산, base-10은 우리가 흔히 쓰는 10진수
- 밑(base)은 수학 연산에 기초가 되는 수를 의미하며, 베이스-10은 우리가 사용하는 0~9를 밑수로 사용하는 밑(base)이 10인 10진수를 의미
- 덧셈의 경우, n진수 덧셈을 하면 된다. (base-7, 5 + 4 = 12)
- 곱셈의 경우, n진수 곱셈을 하면 된다. (base-7, 3 * 5 = 21)
모듈로-n 연산(modulo-n arithmetic): 0부터 n-1까지, n개의 수를 이용한 산술 연산, 모듈로-2의 경우, 0과 1만으로 산술한다.
-
즉, 베이스 연산과 달리 모듈로 연산은 언제나 한 자릿 수의 결과가 나온다.
-
덧셈의 경우, 덧셈의 결과를 n으로 나눈 나머지가 결과값이 된다. (mod-7, 5 + 4 = 2)
-
곱셈의 경우, 곱셈의 결과를 n으로 나눈 나머지가 결과값이 된다. (mod-7, 3 * 5 = 1)
이진 연산에서는 수에 $2^k$를 곱하는 것은 k 만큼 왼쪽으로 쉬프트(shift)하는 것과 같다.
즉 fig 6.6에서 만들었던 에러 감지를 위한 새로운 데이터 d+r은 기존 데이터 D에 대하여 $D\cdot 2^r\ XOR\ R$와 결과값이 같다.
d+r = R을 구하는 방법을 알아보자
먼저 수신자가 뒤에 덧붙이는 데이터 R을 구하는 방법을 알아보려며,
이전에 새로운 데이터가 G에 나누어 떨어져야 한다고 했으므로,
$D \cdot 2^r\ XOR\ R= nG$
앞서 XOR의 결과물은 덧셈, 뺄샘과 같다고 했으므로 XOR 연산자를 양 식에 XOR 해주면, 위 식은 아래와 같이 다시 표현할 수 있다.
$D \cdot 2^r\ XOR\ R\ XOR\ R=D \cdot 2^r+R - R = D \cdot 2^r = nG\ XOR\ R$
양 식에 G로 나누면 다음과 같이 된다.
$R=remainder\ \frac{D\cdot 2^r}{G}$
아래 Figure 6.7은 D=101110, d= 6, G = 1001, r =3인 경우의 R의 계산법이다. 결과적으로 R은 011이 생성된다.
$D \cdot 2^r=101011\cdot G\ XOR\ R$ (101011은 결국 n이 된다)

이러한 R에 대해서 길이 값 r은 국제 표준으로 8, 12, 16, 32가 나와있으며, 각각 CRC-8, CRC-12, CRC-16, CRC-32라고 부른다.
$G_{CRC-32}=100000100110000010001110110110111$
위는 연결 계층 IEEE 프로토콜에서 사용하는 33자리 생성자이다.
각 CRC의 r 값 이하의 길이를 가진 연속된 비트 에러를 100% 탐지할 수 있으며, 그 이상의 길이(>=r+1)의 비트 에러를 탐지할 비율은 $1-0.5^r$이다.
추가로 CRC는 모든 숫자의 홀수 갯수의 비트 에러를 감지할 수 있다.
- 즉, CRC-32의 경우 에러를 탐지하지 못할 비율은 $0.5^{32}=2.33\times10^{-10}$이다.
- 에러를 탐지못할 확률 $0.5^r=\frac{1}{2^r}$은 R이 나눠질 때 생길수 있는 나머지의 범위가 $0 \sim 2^r-1$까지 총 $2^r$개이므로 무작위 수가 0(=나누어 떨어져서 에러로 탐지 안될 확률)이 $\frac{1}{2^r}=0.5^r$이 된다.
더욱 자세한 내용은 [Williams 1993, Schwartz 1980]을 참조
6.3 다중 접근 링크와 프로토콜 (Multiple Access Links and Protocols)
네트워크 링크에는 두가지가 있다.
지점간 링크(point-to-point)
링크 끝 단의 송수신자가 1:1로 연결하는 링크, PPP(point-to-point protocol, 지점간 프로토콜), HDLC(high-level data link control, 고레벨 데이터 링크 컨트롤) 같은 프로토콜이 존재.
브로드캐스트 링크(boradcast link)
송신자 여러명, 혹은 수신자 여러명이 하나의 브로드캐스트 채널(broadcast channel)을 공유하여 서로 연결되어 있는 링크,
브로드캐스트(broadcast)란, 한 노드가 프레임을 보내면 채널 측에서 프레임을 여러개로 복사해서 여러 노드로 보내는 것
이더넷(ethernet), 무선 LAN(wireless LAN)이 속한다.
어떻게 다수의 송수신자가 공유된 하나의 브로드캐스트 채널을 공유할 수 있는가? - 다중 접근 문제(multiple access problem)에 대해서 알아보자.
먼저 **지정학적으로 한 지역에 집중되어 다중 접근 채널을 활용하는 LAN 또한 **알아보자.
흔히 브로드캐스트(broadcast, 방송, 송출) 채널은 학교의 한 반에서 선생님과 학생들이 동시에 이야기하는 것을 비유로 들 수 있다.
당연히 모든 사람들이 동시에 이야기하면 시끄러워 말이 서로 전달이 안되니,
“손 들고 질문할 것”, “다른 사람이 이야기 할 때 떠들지말 것”, “말하는 도중에 잠자지 말것”, “제한된 시간까지만 말할 것”
등의 규칙을 정하여 이야기하면 되는데 이는, 다중 접근 프로토콜(multiple access protocols)에 해당한다.
위의 figure 6.8 은 여러가지 네트워크 설정에 따른 다중 접근 프로토콜의 필요를 보이고 있다. 사실, 각 노드는 브로드캐스트 채널을 어답터를 이용해 접근하지만 일단 우리는 각 노드를 장치로 가정하고, 브로드캐스트 채널에 접근하는 것으로 하자.
만약 여러 노드가 동시에 프레임을 보내게 된다면, 프레임들은 서로 간에 충돌된 채로 여러 노드에게 보내지고, 보내진 충돌난 프레임은 그대로 버려지게 된다.
많은 충돌이 일어나 재전송이 일어나면, 더욱더 브로드캐스트 채널의 한정된 대역폭 내에서 많이 충돌이 일어나게 되고, 결국 대역폭은 낭비되고 만다.
이러한 활성된 노드들의 전송들을 조정하는 것이 다중 접근 포로토콜의 일이며, 다음과 같이 크게 세가지로 분류된다.
- 채널 나눔 프로토콜(channel partitioning protocols)
- 무작위 접근 프로토콜(random access protocols)
- 순번 프로토콜(taking turns protocols)
전송속도가 R bps인 브로드캐스트 채널에 대하여 다음과 같은 특성이 있어야 한다.
- 하나의 노드만 데이터를 보낼 때 처리율이 R bps 여야 한다.
- M 개의 노드가 데이터를 보낼 때 처리율이 일정 시간동안 평균적으로 R/M bps여야 한다.
- 단일지점 장애를 예방하기 위해 하나의 마스터 노드가 관리하는 것이 아니라 프로토콜은 분산적이어야 한다.
- 프로토콜은 간단하고 비용이 적게 들어야 한다.
6.3.1 채널 나눔 프로토콜 (Channel Patitioning Protocols)
섹션 1.3에서 설명했던 시간 분배 멀티플렉싱(TDM, time-division multiplexing)과 주파수 분배 멀티플렉싱(FDM, frequency-division multiplexing)은 브로드캐스트 채널의 대역폭을 여러 노드에게 나눠줄 수 있는 방법이다.
브로드캐스트 채널을 공유할 N개의 노드가 있다고 가정하면,
TDM은 시간을 여러 개의 시간 프레임(time frames)로 나누어 추가로 각 시간 프레임을 N 개의 시간 슬롯(time slot)으로 나누어 각 슬롯에 N개의 노드들을 배정한 뒤, 라운드 로빈 방식으로 각 노드가 각 시간 프레임에 한번씩 시간 슬롯 동안 보내도록 하는 방식이며, 이때 슬롯 사이즈와 시간 프레임 사이즈는 보낼 단일 패킷의 크기에 따라 정해진다.
비유하자면, 한 반에 학생들이 번호 순서대로 일정한 발언 시간을 가지는 것과 같으며, 패킷 간의 충돌을 막을 수 있다.
아래 figure 6.9는 간단한 4개의 노드 TDM과 나중에 설명할 FDM의 예시이다.
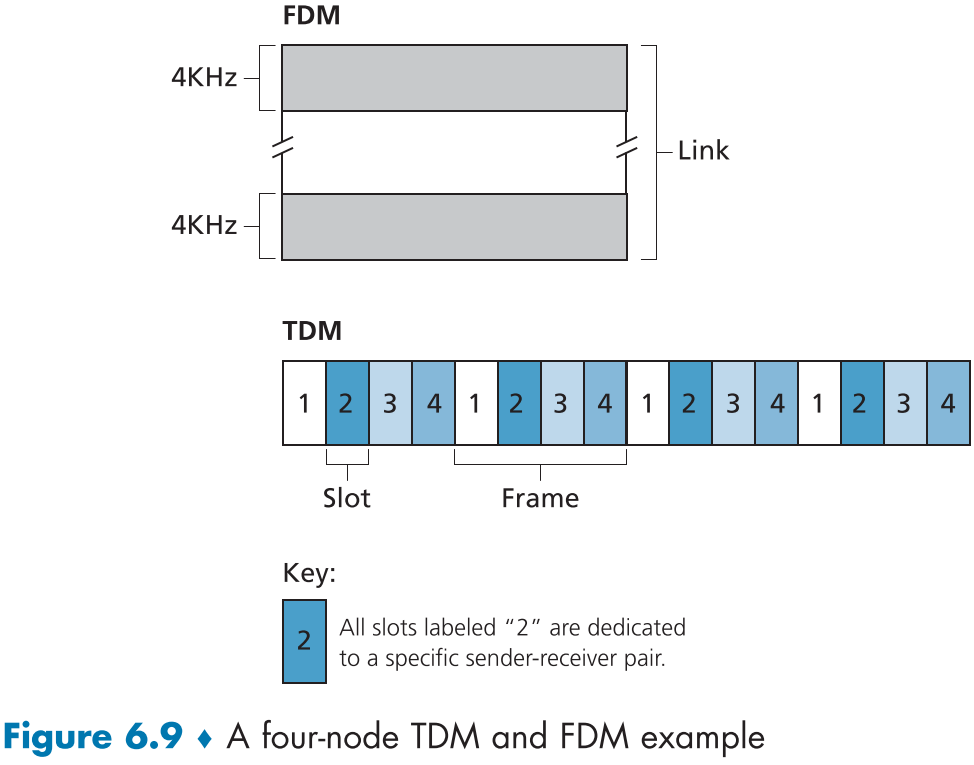
하지만 TDM은 2가지 큰 단점이 있는데, 바로 첫번째는 노드들 중 패킷을 보내고 싶은 노드가 하나여도 R/N bps로 대역폭이 제한된다는 점, 두번째는 마찬가지 상황에서 추가로 보내고 싶을때 바로가 아니라 언제나 자신의 순번을 기다리고 있어야한다는 점이다.
비유로 치자면, 반에서 1명을 제외하곤 할말이 없는데 다들 똑같은 시간을 공유하고, 발언자는 원하는 시간에 말하지 못한다는 점이다.
FDM은 이러한 TDM 대신 다른 주파수의 영역을 N개로 나누어 각각 R/N 만큼의 대역폭을 사용하는 방법으로 TDM과 같은 장점을 공유하지만, 마찬가지로 TDM의 첫번째 단점을 그대로 공유하고 있다.
이외의 새로운 채널 나눔 프로토콜인 CDMA(코드 나눔 다중 접근, code division multiple access)은 노드 별로 다른 코드를 통해 데이터를 인코딩하여 보내며, 이미 해당 코드를 알고 있는 수신자측에서 디코딩하는 방식이며, 모든 노드가 동시에 전송할 수 있다.
추가로 반 재밍(anti-jamming) 특성이 있어 군에서 사용하다가 민간 무선 통신에 사용되는 중이며, 자세한 설명은 7장에서 다룰 예정이다.
6.3.2 무작위 접근 프로토콜 (Random Access Protocols)
무작위 접근 프로토콜은 채널을 공유하는 각 노드가 전체 처리율인 R bps로 보내다가, 다른 노드의 전송에 의해 충돌이 감지되면, 무작위 지연 시간(random delay) 동안 전송을 멈췄다가, 재전송을 시작한다.
이때 각 노드 별로 무작위로 지연 시간을 고르므로, 몇번 더 충돌이 일어나더라도, 결국에는 각기 다른 시간에 전체 처리율 R로 프레임을 보낼 수 있게 된다.
우리는 무작위 접근 프로토콜인 ALOHA 프로토콜과 CSMA(반송파 감지 다중 접속 프로토콜,carrier sense multiple access)을 배울 것이며, CSMA 중 가장 유명한 이더넷에 대해 배울 것이다.
일자형 ALOHA (Slotted ALOHA)
간단한 일자형 ALOHA에 대해서 배우기 전에 가정을 하자면
- 모든 프레임의 크기는 정확히 L 비트이다.
- 시간은 L/R 초(=정확히 한 프레임을 보낼 수 있는 시간)의 슬롯으로 나눈다.
- 슬롯의 시작 지점에 바로 전송을 시작
- 각 노드들은 동기화되어 있어서 슬롯들의 시작과 끝의 타이밍을 잘 안다.
- 2개 이상의 프레임이 슬롯에서 충돌이 나면, 슬롯이 끝나기 전에 이미 충돌 이벤트를 노드들이 인지한다.
각 노드에서의 일자형 ALOHA의 동작은 간단하다.
- 노드가 보낼 프레임이 있으면, 다음 슬롯에 시작할 때까지 기다렸다가 슬롯을 통해 전체 프레임을 보낸다.
- 만약 충돌이 없었다면, 새로 보낼 프레임을 준비하고 위의 행동을 반복한다.
- 만약 슬롯이 끝나기 전에 충돌이 있었다면, 충돌이 일어나지 않을때까지 노드는 연속된 슬롯에 p의 확률로 재전송한다.
- 만약 재전송하지 않는 확률(1-p)에 걸렸다면, 다음 슬롯까지 기다렸다가 다시 p의 확률로 재전송한다.
일자형 ALOHA는 활성화된 노드의 경우 전체 처리율인 R로 전송이 가능하고, 충돌 감지와 재전송 확률 계산 등이 노드 별로 분산화되었으며, 간단한 프로토콜이다.
비록, 노드들이 슬롯에 동기화되어야 한다는 점이 완전한 분산화의 발목을 잡지만, 다음에 배울 ALOHA 프로토콜과 다른 CSMA 프로토콜들은 이를 해결하였다.
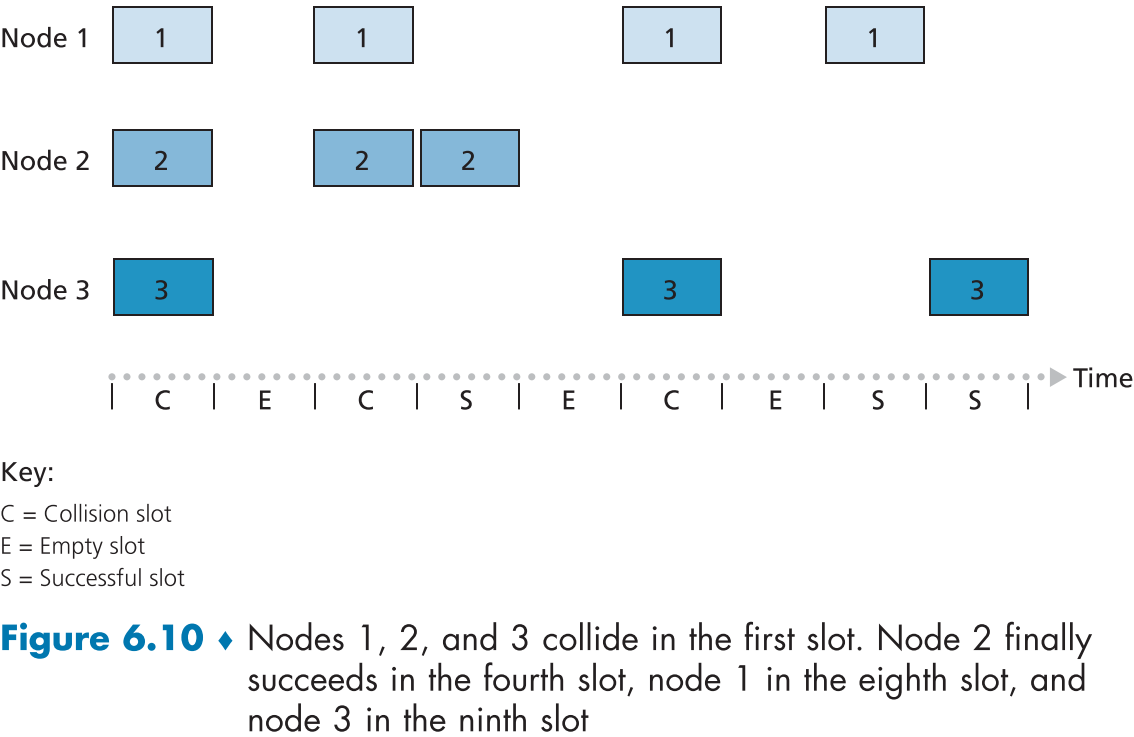
위 그림 figure 6.10을 보면, 일자형 ALOHA의 다른 문제점이 보인다.
바로 슬롯이 두 가지 방법으로 낭비된다는 점인데 첫번째는 아무도 전송하지 않기로 결정한 시간대의 슬롯이 낭비되고, 두번째로 충돌이 일어난 슬롯도 결국 아무 패킷도 보내지 못하고 낭비되는 셈이다.
전체 슬롯 중에 성공적으로 패킷을 보낸 슬롯의 비율을 효율성으로 보자면, 일자형 ALOHA의 최대 효율은 0.37 정도로 전체 R bps의 0.37정도로 효율이 낮다.
아래는 ALOHA의 효율성을 구하는 공식이다.
성공적인 슬롯은 노드 하나만 패킷을 보내고, 나머지는 패킷을 보내지 않을 확률이므로, $p(1-p)^{N-1}$이며, 이러한 노드가 N개 있으므로 N을 곱해 $Np(1-p)^{N-1}$이다.
\(Np^*(1-p^*)^{N-1}\)
N은 노드의 갯수, $p^*$는 가장 효율성이 최적의 재전송 확률 p이다.
$p^* = $
N의 값을 무한대로 발산시키면 $1/e$로 수렴하는데, 이 값이 0.37이다.
ALOHA
위에 설명했듯이 일자형 ALOHA 프로토콜은 각 슬롯의 시작지점에 동기화되야한다는 단점이 있다. 최초의 ALOHA 프로토콜은 슬롯을 사용하지 않는 분산화된 프로토콜이었다.
순수 ALOHA에서는 보낼 프레임은 지체없이 바로 브로드캐스트 채널 보내었고, 만약 충돌을 겪었다면, 노드는 바로 p의 확률로 재전송 하거나, 1-p의 확률로 보내야 될 프레임에 걸리는 전송 시간 만큼 기다렸다가 다시 p의 확률을 계산했다.
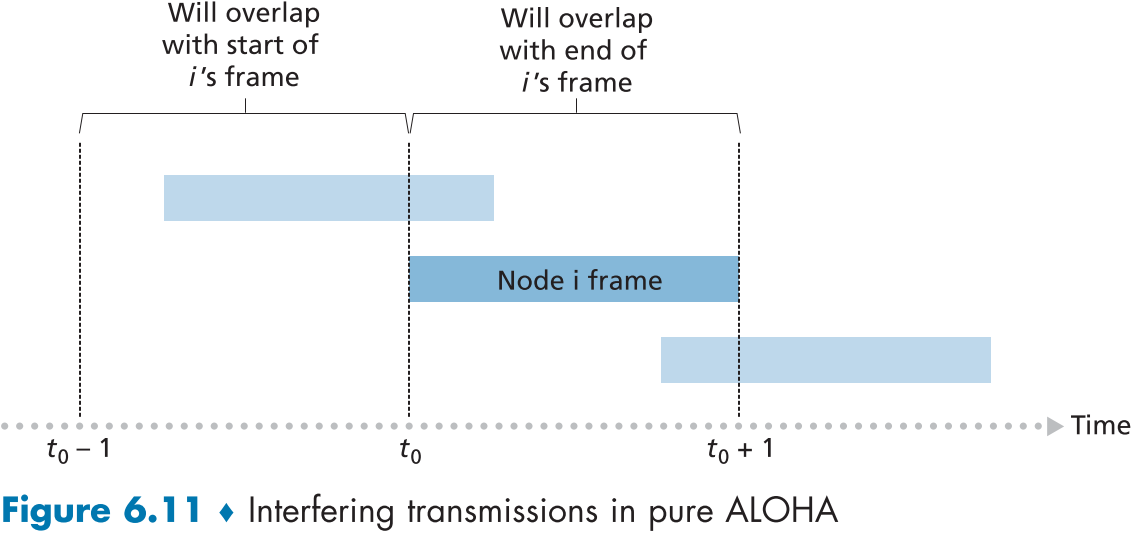
순수 ALOHA의 효율성은 $1/2e$=0.18 정도로 일자형 ALOHA의 정확히 절반이다.
figure 6.11 을 살펴본면 순수 ALOHA는 단순히 특정 슬롯 시간($[t_0 \sim t_0+1]$ 구간)에 둘 이상의 노드가 전송하면 안될 뿐만 아니라,(확률 :$(1-p)^{N-1}$)
같은 단위시간 이전의 시간($[t_0-1 \sim t_0]$ 구간)에도 노드가 전송될 경우 충돌이 일어나므로,(확률 :$(1-p)^{N-1}$), 충돌할 확률이 두배로 커지기 때문에(확률 :$(1-p)^{2(N-1)}$) 효율이 절반으로 줄어든다.
완전히 분배된 프로토콜인 대신, 안그래도 비효율적이었던 ALOHA가 더욱 비효율적으로 변했다.
반송파 감지 다중 접속 (Carrier Sense Multiple Access, CSMA)
ALOHA 계열 프로토콜들은 전송을 시작할 때, 다른 노드의 전송상태를 살피지 않고, 전송 중일 때, 다른 노드의 전송 요청 여부도 확인하지 않는다.
비유하자면, 반에서 누가 말하든, 누가 말하고 싶어하든 상관하지 않는 거만한 학생과도 같다.
현실에서 이러한 행동을 막기위해 규칙이 예절이 있는 것처럼, 프로토콜에도 다음과 같은 규칙이 있다.
-
반송파 감지(carrier sensing), 말하기 전에 먼저 들어보기
전송하기 전에 채널의 상태를 감시하며, 아무도 패킷을 보내지 않게되면 전송한다.
-
충돌 감지(collision detection), 누군가와 동시에 이야기하기 시작하면, 발언을 멈추기
전송하고 있어도 채널의 상태를 계속 감지하다가 누군가 갑자기 전송을 시작하면, 무작위 시간만큼 기다렸다가 반송파 감지를 실시한다.
위 두 규칙은 carrier sense multiple access(CSMA, 반송파 감지 다중 접속)와 CSMA with collision detection(CSMA/CD, 충돌 감지 CSMA)의 기능이다.
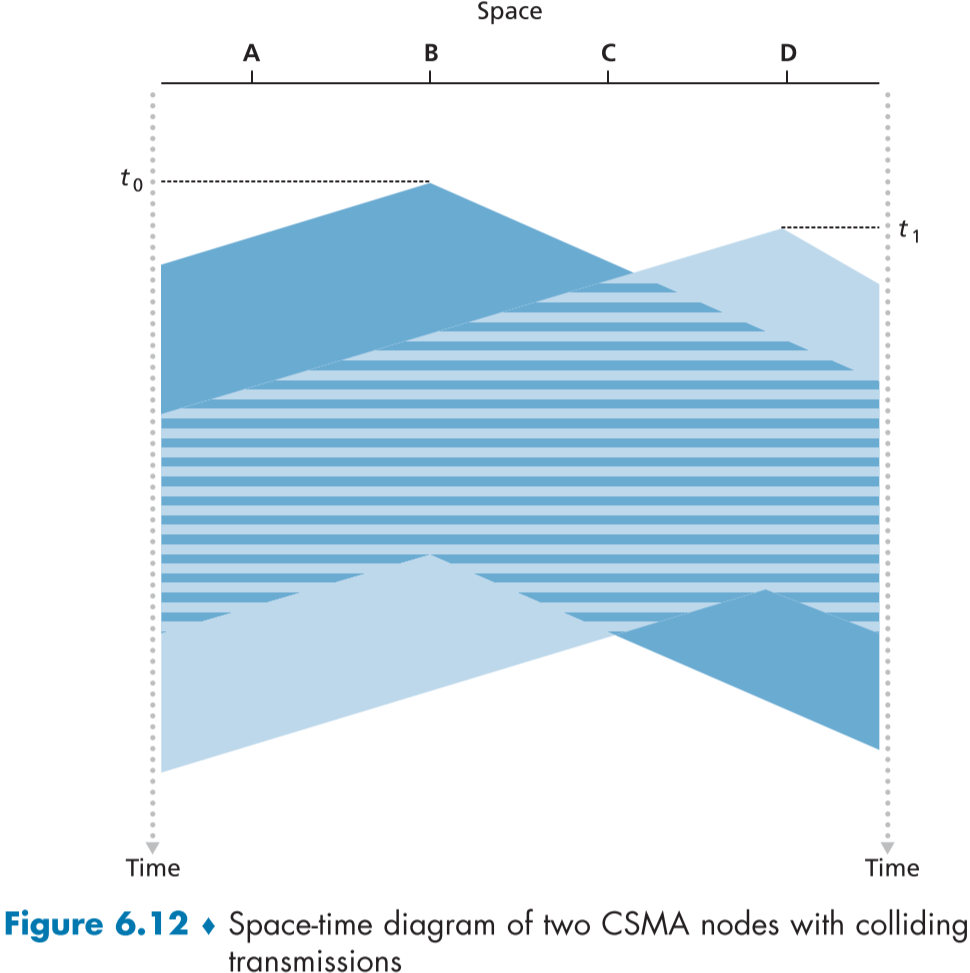
CSMA와 CSMA/CD의 기본적이고 중요한 질문 중 하나로, CSMA의 프로토콜의 특성 대로 모든 노드들이 다른 노드의 전송을 감지 중(반송파 감지)이라면, 충돌은 절대 일어나지 않을텐데, 어째서 우리는 충돌을 방지해야하는가? 이다.
일단, 반송파 감지가 있어도 충돌은 일어난다.
그 이유는, 패킷을 전파할 때 다른 노드에게 전송되는데 시간(end-to-end channel propagation delay, 지점간 채널 전파 지연)이 걸리기 때문에, 먼 거리의 노드는 반송파를 감지하기 전에 이미 비어있는 채널로 착각하고 전송하여 충돌이 일어난다.
figure 6.12로 알아보자면, 아무도 채널에 전송하지 않는 것을 깨닫고, B는 A, C, D를 향해 시간 $t_0$에 전파를 시작했지만, $t_0$보다 조금 늦은 $t_1$ 시점에 D 입장에는 아직 B의 전송 데이터가 도착하지 않아, 아무도 채널에 전송하지 않는다고 착각하여 $t_1$에 전파를 시작하고, 충돌이 일어난다.
이를 통해 CSMA 계열 프로토콜에게 지점간 채널 전파 지연이 성능에 중요함을 알 수 있다.
충돌 감지 반송파 감지 다중 접근(CSMA/CD, Carrier Sense Multiple Access with Collision Detection)
CSMA/CD는 CSMA에 추가로 충돌 방지를 추가한 것이다.
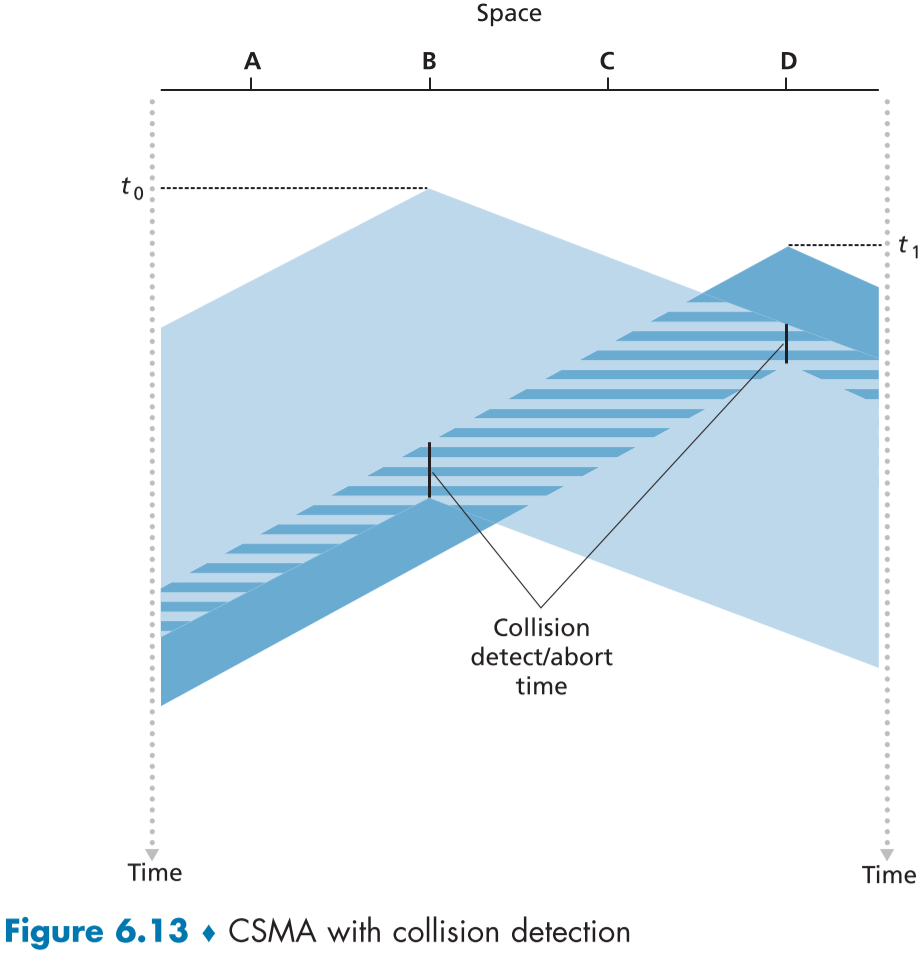
아래의 figure 6.13은 충돌 방지가 추가된 그래프이다.
B와 D가 서로의 전파를 처음 맞닥뜨리는 시간으로 부터 충돌 감지 및 중단 시간(Collision detect/abort time)의 지연이 발생한 뒤 전송이 중단된다.
이를 통해 의미없이 충돌이 생긴 프레임이 전송되는 것을 최대한 빨리 막아 성능 향상을 이룰 수 있다.
CSMA/CD 프로토콜의 활동을 브로드캐스트 채널을 이용하는 노드의 어답터 기준으로 알아보자면,
-
어답터가 네트워크 계층으로 부터 데이터그램을 가져오고 연결 계층 프레임으로 바꾼 뒤, 프레임 어답터 버퍼(frame adapter buffer)에 집어넣는다.
-
만약 어답터가 채널로부터 들어오는 신호 에너지가 없으면 채널이 사용가능한 상태라고 판단하고 전송을 시작한다.
만약 반대로 채널이 붐비다고 판단되면, 더이상 채널로부터 신호 에너지가 들어오지 않을 때까지 기다리다가 전송을 시작한다.
-
전송 중에 어답터는 다른 어답터가 보내는 신호 에너지의 존재를 모니터링한다.
-
만약 어답터가 아무런 다른 어답터의 신호 에너지를 감지 하지 못한 채 전체 프레임의 전송을 완료하면, 전송을 끝마친다.
만약, 도중에 다른 신호 에너지를 감지하면, 전송을 멈춰버린다.
-
전송이 멈춰졌다면, 무작위 시간 만큼 기다린 뒤, 다시 2번 과정부터 시작한다.
- 다들 동일한 일정 시간을 기다리게 하면, 모두 같은 시간만큼 기다렸다가 동시에 신호를 측정하므로 영원히 충돌을 반복하게 되어, 무작위 시간을 기다리게 한다.
무작위 시간의 정할 때의 시간 범위는 너무나 넓으면, 어답터들이 비효율적으로 오래 기다려야 하여 비효율적이고, 너무나 좁으면 충돌이 자주 일어나 비효율적이다.
이상적인 무작위 시간 범위는 충돌 경험의 수가 적으면 좁게, 충돌 경험의 수가 많으면 채널이 상당히 붐빈다는 의미이므로 넓게 가지는 것이 좋을 것이다.
이진 지수적 백오프(binary exponential backoff)는 이더넷과 DOCSIS 유선 네트워크 다중 접근 프로토콜에 사용되는 방법으로, 위의 이상적인 시간범위 설정을 해결해 준다.
원리는 노드가 특정 프레임에 대하여 n번째 충돌을 겪는다면, 무작위 백오프 시간 K는 시간 범위는 ${0,1,2…,2^n-1 }$에서 고른다.
즉 매 충돌마다 무작위 백오프 시간 범위는 2배씩 늘어나는 것이며, 이더넷의 경우, 무작위 백오프 시간 K * 512 bit times(해당 채널에서 512bit 데이터를 전송하는데 걸리는 시간) 만큼 기다리며 최대 충돌 제한은 10으로 놓는다.
또한, 전송이 끝난 뒤, 다음 프레임을 준비할 때, CSMA/CD의 변수들은 초기화되고 다시 시작한다.
예를 들어 저번에 6번의 충돌이 일어났고, K의 시간이라는 백오프를 기다렸었다면, 해당 프레임이 전송된 뒤로, 충돌 횟수는 1로, 백오프는 0으로 초기화한다.
이를 통해 노드가 빠르게 전송 시간을 차지할 수 있다.
CSMA/CD 효율 (CSMA/CD Efficiency)
CSMA/CD의 효율성은 $d_{prop}$은 최대 크기의 프레임을 보내는데 걸리는 시간일 때 아래 처럼 유도한다.([LAM 1980, Bertsekas 1991])
\[Efficiency =\frac{1}{1+5d_{prop}/d_{trans}}\]$d_{prop}$이 0에 가까워지거나 반대로 무한대에 발산할수록, 효율은 1에 가까워진다.
이는
- 전파 지연시간(propagation delay)가 0에 가까울 수록, 채널을 낭비하지않고 바로 전송을 그만둘 수 있기 때문에
- 프레임 전송하는 시간이 늘면서 단일 노드가 채널의 전송속도를 가지고 있는 시간이 늘어서 효율적으로 자원을 쓰기 때문에
이다.
6.3.3 순번 프로토콜 (Taking-Turns Protocols)
다중 접근 프로토콜(multiple access protocol)의 필요한 특성으로 첫번째, 한 노드만 채널 사용시 R bps의 처리율, 두번째, 여러 노드가 채널 사용시 R/N bps를 기억하자면, ALOHA와 CSMA의 랜덤 접근 방법은 첫번째 특성은 만족하지만 두번째 특성은 만족하지 않는다는 것을 알 수 있다.
두 가지 특성을 모두 성립하기 위해 연구된 것이 순번 프로토콜(Taking-Turns Protocols)이며 다음과 같은 종류가 있다.
-
폴링 프로토콜 (polling protocol)
하나의 마스터 노드가 각 노드에게 라운드 로빈 순으로 다른 노드들을 폴링(하나의 장치가 다른 장치들을 주기적으로 검사 후, 조건에 만족하면 송수신 등의 자료처리하는 것)하는 방식이다.
예를 들어, 마스터 노드가 노드 하나에게 메시지를 보내 제한된 프레임의 전송을 허락한 뒤, 채널의 신호가 사라짐을 감지하면, 다른 노드에게 메시지를 보내어 전송을 허락하는 방식의 반복이다.
블루투스(Bluetooth) 프로토콜이 해당한다.
충돌과 사용하지 않는 시간대 또는 슬롯을 없앨 수 있어서 높은 효율을 보이지만, 다음과 같은 단점이 있다.
- 폴링 지연(polling delay) : 마스터 노드가 노드에게 권한을 부여하기 위해 생기는 시간의 지연, 폴링 프로토콜에서는 한 노드만 전송할 시, 미묘하게 효율이 100%가 못되는데, 마스터 노드가 비활성 노드를 포함해서 채널의 노드들에게 폴링하는 데 시간이 걸리기 때문이다.
- 중앙집중식 프로토콜(centralized protocol) : 만약 마스터 노드에 장애가 발생시, 전체 채널이 가동할 수 없게 된다.
-
토큰 전달 프로토콜 (token-passing protocol)
마스터 노드가 존재하지 않으며, 대신 토큰(token)이라 불리우는 특수 목적 프레임이 노드들 사이에 일정한 순서로 건네지면서 채널 자원을 활용할 수 있다.
보통 제한된 프레임의 전송을 끝내면 각 노드가 라운드 로빈식으로 다음 노드에게 토큰을 넘겨주며, 보낼 프레임이 없으면 즉시 다음 노드로 넘겨주는 방식으로 진행된다.
높은 효율과 분산화된 알고리즘의 장점이 있지만, 한 노드가 먹통이되거나 악의적으로 토큰을 독점하면, 반환 절차 등을 시행하면서 오버헤드가 생긴다.
FDDI(fiber distributed data interface, 광섬유 분산 데이터 인터페이스) 프로토콜, IEEE 802.5(WiFi) token ring 프로토콜 등이 존재한다.
6.3.4 DOCSIS: 유선 인터넷 접근을 위한 연결 계층 프로토콜 (DOCSIS: The Link-Layer Protocol for Cable Internet Access)
앞서 배웠던 채널 나눔 프로토콜, 무작위 접근 프로토콜, 순번 프로토콜을 유선 접근 네트워크를 이용해 살펴보자.
이전 섹션 1.2.1에 배웠던 유선 접근 네트워크는 보통 수많은 주거지 유선 모뎀을 유선망 종점의 유선 모뎀 종결 체계(CMTS, cable modem termination system)와 연결하여 생성된다. DOCSIS(유선상 데이터 전달 서비스 인터페이스 설명서, Data-Over-Cable Service Interface Specificationis)는 유선 데이터 네트워크 구조와 프로토콜에 대해 설명한다.
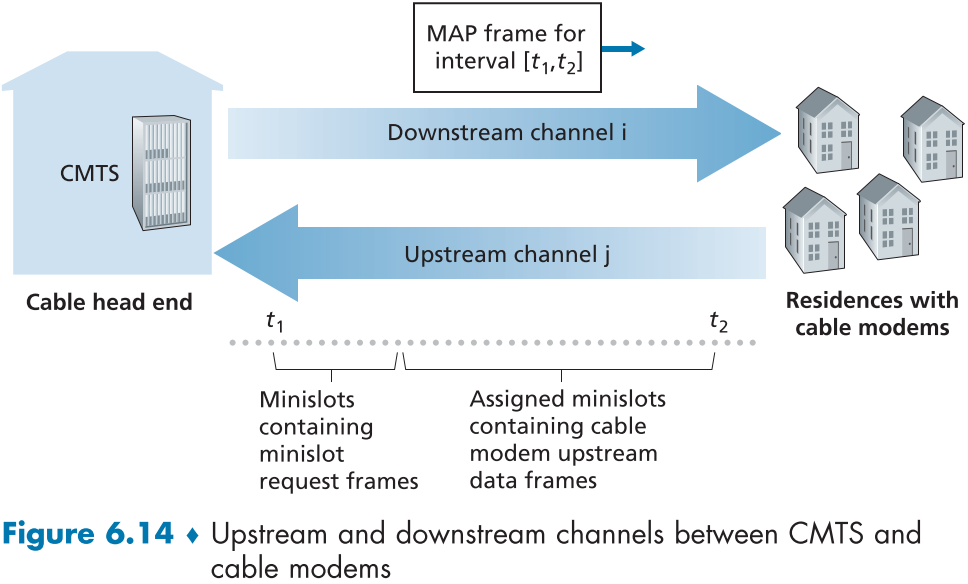
DOCSIS는 브로드캐스트 채널을 FDM을 통해 두 채널로 나누는데,
각각 다운 스트림(CMTS->모뎀, 24MHz ~ 192MHz, 1.6 Gbps/채널)과 업 스트림(모뎀->CMTS, 6.4MHz ~ 96MHz, 1Gbps/채널)로 나눈다.
다운 스트림 채널은 CTMS 단일 노드가 사용하므로 다중 접근 문제가 없지만, 업 스트림 채널은 수많은 모뎀이 사용하므로 그렇지 않다.
figure 6.14를 보면, 업스트림 채널을 TDM 형식으로 여러 미니 슬롯으로 나눈 뒤, CMTS 측에서 컨트롤 메시지인 MAP 메시지를 다운스트림 채널을 통해 특정 유선 모뎀에게 특정 미니 슬롯을 부여하여 전송하는 방식을 사용하여, 충돌을 없앴다.
이때, 미니슬롯을 배정받으려면 미니슬롯 요청 프레임(mini-slot-request frame)을 랜덤 접근 프로토콜 방식으로 보내어 CMTS에게 보낼 데이터가 있음을 어필해야 하며, 이때의 방식에는 충돌이 존재할 수 있다.
모뎀 측에서는 반송파 감지나 충돌 감지가 불가능한 대신, 보낸 요청 프레임에 대한 응답으로 MAP 메시지가 돌아오지 않으면, 충돌로 생각하고, 앞서 배웠던 이진 지수적 백오프(binary exponential backoff)를 실시한다.
만약 업스트림 채널의 트래픽이 여유있다면, 유선 모뎀은 명시적인 미니슬롯 할당을 받기 전까지 원하는 대로 데이터를 보내어 폴링 지연을 막는다.
DOCSIS는 이런식으로 FDM, TDM, 무작위 접근, 중앙 할당이 모두 포함된 좋은 네트워크 예시이다
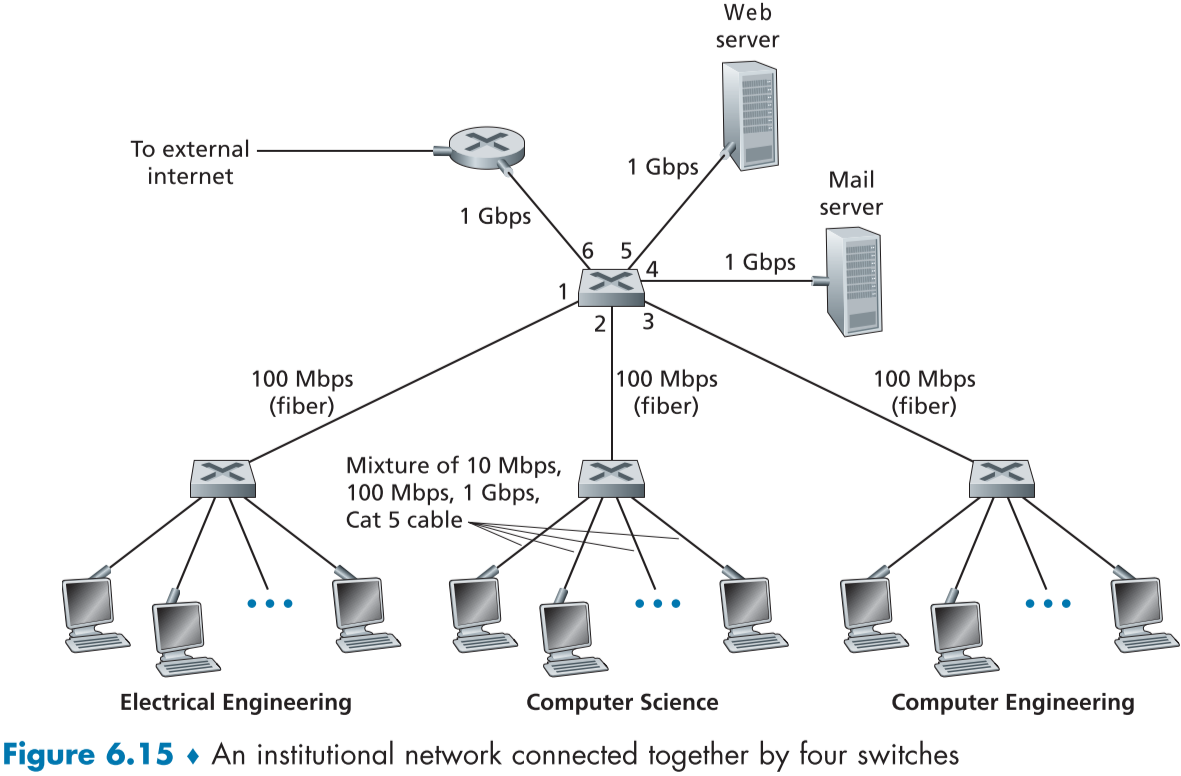
6.4 스위치 근거리 네트워크 (Switched Local Area Networks)
figure 6.15는 세 부서, 두 서버, 4개의 스위치와 한개의 라우터에 연결된 스위치드 LAN의 예시이다.
스위치들은 연결 계층 장비이므로, 연결 계층 프레임을 주고 받으며, 네트워크 계층의 OSPF 등을 이용해 라우팅하지 않고, IP 주소를 통해 구분하지도 않으며, 대신 연결 계층 주소를 이용해 통신한다.
우리는 연결 계층 주소와 이더넷 프로토콜, 연결 계층 스위치의 동작 등에 대해서 배울 것이다.
6.4.1 연결 계층 주소와 ARP(Link-Layer Addressing and ARP)
호스트와 라우터들은 연결 계층 주소와 네트워크 계층 주소를 둘다 가지고 있어야 하는 이유와 연결 계층 주소의 기능과 문법, IP 주소와 연결 계층 주소를 서로 번역해주는 ARP(주소 확인 프로토콜, Address Resolution Protocol)에 대해 알아볼 것이다.
MAC 주소(MAC Addresses)
연결 계층 주소는 주로 MAC 주소라고 불리우며 이외에 LAN 주소, 물리적 주소 등으로도 불린다.
한 라우터와 호스트에 인터페이스별로 여러 IP 주소를 가질 수 있듯이, MAC 주소 또한, 장치들(정확히는 장치들의 연결 계층 어답터)이 여러 개의 연결 계층 주소를 가질 수 있다.
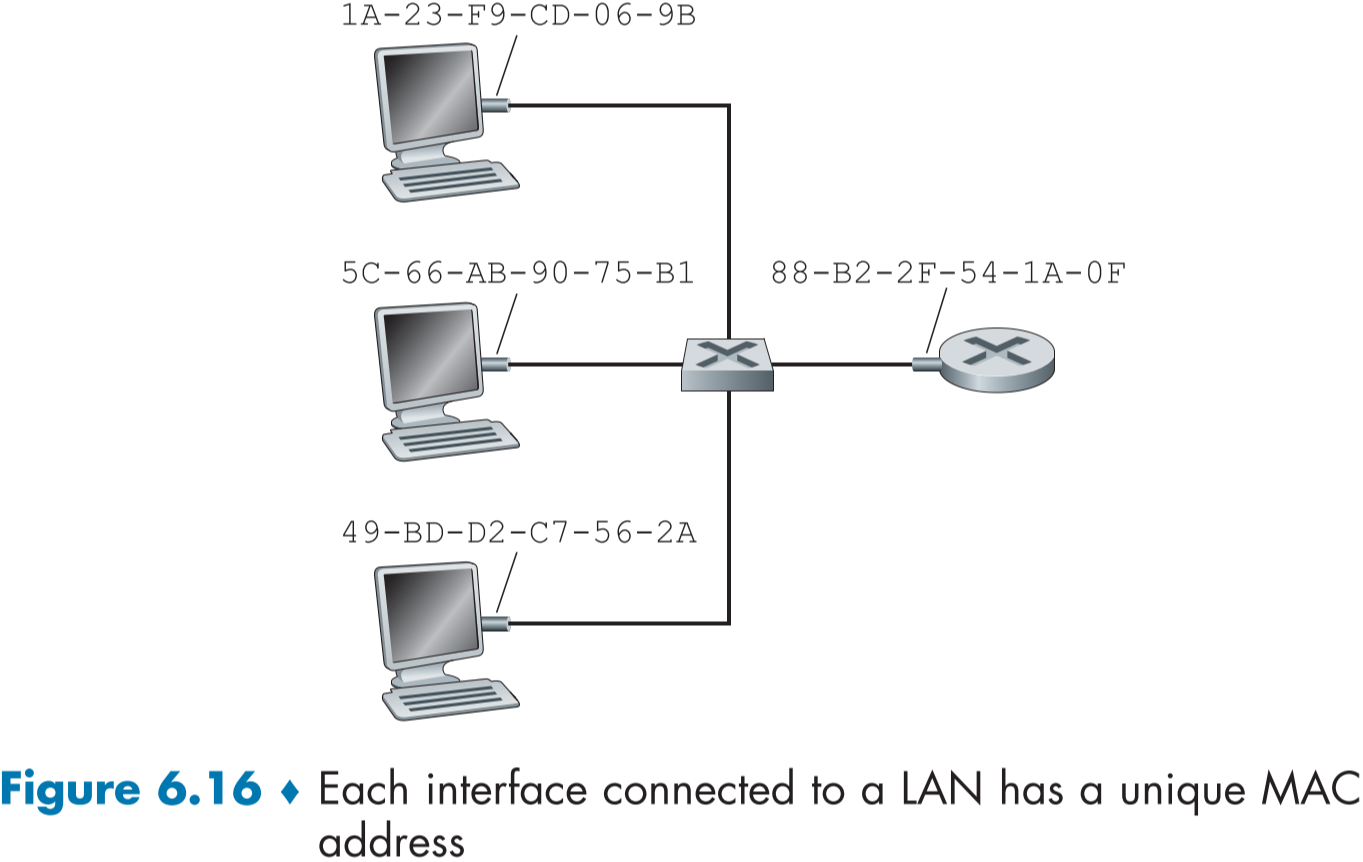
다만 아래 figure 6.16 처럼 연결 계층 스위치의 경우 MAC 주소를 가지지 않는데, 이는 스위치에는 패킷이 도착하지 않고 경유만할 뿐이기 때문이다.
MAC 주소는 아래처럼 6 바이트(=48 비트)의 길이로 주로 16진수(hexadecimal notation)로 표현되며, 과거와 달리 최근 어답터에서 소프트웨어로 MAC 주소가 정의되면서 바꿀 수 있게 되었지만, 보통 고정하여 바꾸지 않고 사용하며, IEEE에서 MAC 주소 공간을 관리하여 여러 장치의 MAC 주소는 장치마다 유일한 값이다.
IEEE에서 $2^{24}$개의 주소 공간중에 하나를 구매하여 사용하고, 나머지 $2^{24}$개의 주소를 기기 별로 유일한 MAC 주소로 이용한다.
MAC 주소는 평등 구조(flat structure)로, IP 주소의 계층 구조(hierarchical structure)와 대비되는데,
이는 IP 주소의 경우, 호스트가 네트워크를 변경할 때마다 바뀌지만, 기기의 MAC 주소는 네트워크가 바뀌어도 동일하게 유지하기 때문이다.
비유하자면, IP 주소는 이사갈때 마다 바뀌는 집 주소, MAC 주소는 언제나 일정한 주민등록번호로 생각할 수 있고 둘다 따로 있어야 편하다는 것을 알 수 있다.
어뎁터가 프레임을 특정 어뎁터에 보내고 싶다면, 해당 어뎁터의 MAC 주소를 프레임에 넣은 뒤, LAN으로 보내면, 연결 계층 스위치가 해당 프레임을 LAN 내부의 모든 인터페이스에 브로드캐스트한다.
LAN 내의 모든 어뎁터들은 받은 프레임의 주소 정보를 확인하여 자신에게 온 것이면 네트워크 계층으로 전달하고, 아니면 프레임을 버린다.
만약, LAN 내의 모든 어뎁터들에게 전파되어야할 브로드캐스트 메시지라면, MAC 브로드캐스트 주소(FF-FF-FF-FF-FF-FF)로 목적지 주소를 설정하여 프레임을 만들고 스위치로 넘기면 모든 어뎁터들이 대상이 된다.
IP 주소가 MAC 주소를, 또는 MAC 주소가 IP 주소를 대체하지 못하는 이유는
-
IP 프로토콜이 대다수의 인터넷 프로토콜을 차지하지만 유일한 네트워크 계층 프로토콜이 아니다.
즉, IP 주소가 존재하지 않는 프로토콜을 사용한다면? 그렇다면 또 다른 식별자와 네트워크 라우팅 방법이 있을 수 있겠지만, 연결 계층에서 모든 프로토콜에 대응해 새로운 ARP 프로토콜 역할을 하는 프로토콜을 짜는것 보다는 그냥 고유의 주소를 가지고 있는 편이 낫다.
즉, 연결 계층이 IP 프로토콜 이외의 프로토콜 아래에서 일할 수 있게 유연성을 제공해준다. 실제로 SPX/IPX 주소 체계의 경우 IP 프로토콜을 MAC이 대체해, 네트워크 주소와 MAC 주소를 이용해 라우팅하고, ARP 프로토콜이 없어 상대적으로 성능상 이득을 봄에도 불구하고, IP 프로토콜의 서브넷 개념이 주는 유연성에 밀려 많이 사용하지 않는다.
-
MAC 주소는 IP 주소와 달리 네트워크 내의 위치를 추정할 수 없다.
MAC 주소는 IP 주소와 달리 서브넷 마스크로 자신의 소속을 나타내지않으며, 그렇게 되게끔 MAC 주소를 고안했다고 해도, 고정된 값이기 때문에 서브넷을 바꾸면 엉망이 된다. 마치 집주소 대신 주민등록번호로 편지 배달을 하는 것과 비슷하다.
-
IP 주소는 MAC 주소와 달리 수시로 변한다.
MAC 주소는 단순히 라우팅 뿐만 아니라 일종의 기기의 식별자로도 사용되곤 한다. 만약 IP 주소를 식별자로 사용한다면, 내가 사용하던 IP 주소를 내 노트북이 네트워크에서 나간 뒤에 DHCP가 다른 기기에 부여하게 된다면, 그 기기는 내 노트북으로 구별될 것이다.
그러니 유연성을 위해 네트워크를 찾는데는 IP 주소, 불변성으로 네트워크 내에서 특정 기기를 찾아내는 데는 MAC 주소를 사용한다.
주소 분석 프로토콜 (Address Resolution Protocol(ARP))
주소 분석 프로토콜(Address Resolution Protocol(ARP))은 네트워크 계층 주소와 연결 계층 주소를 서로 번역하는 역할을 한다.
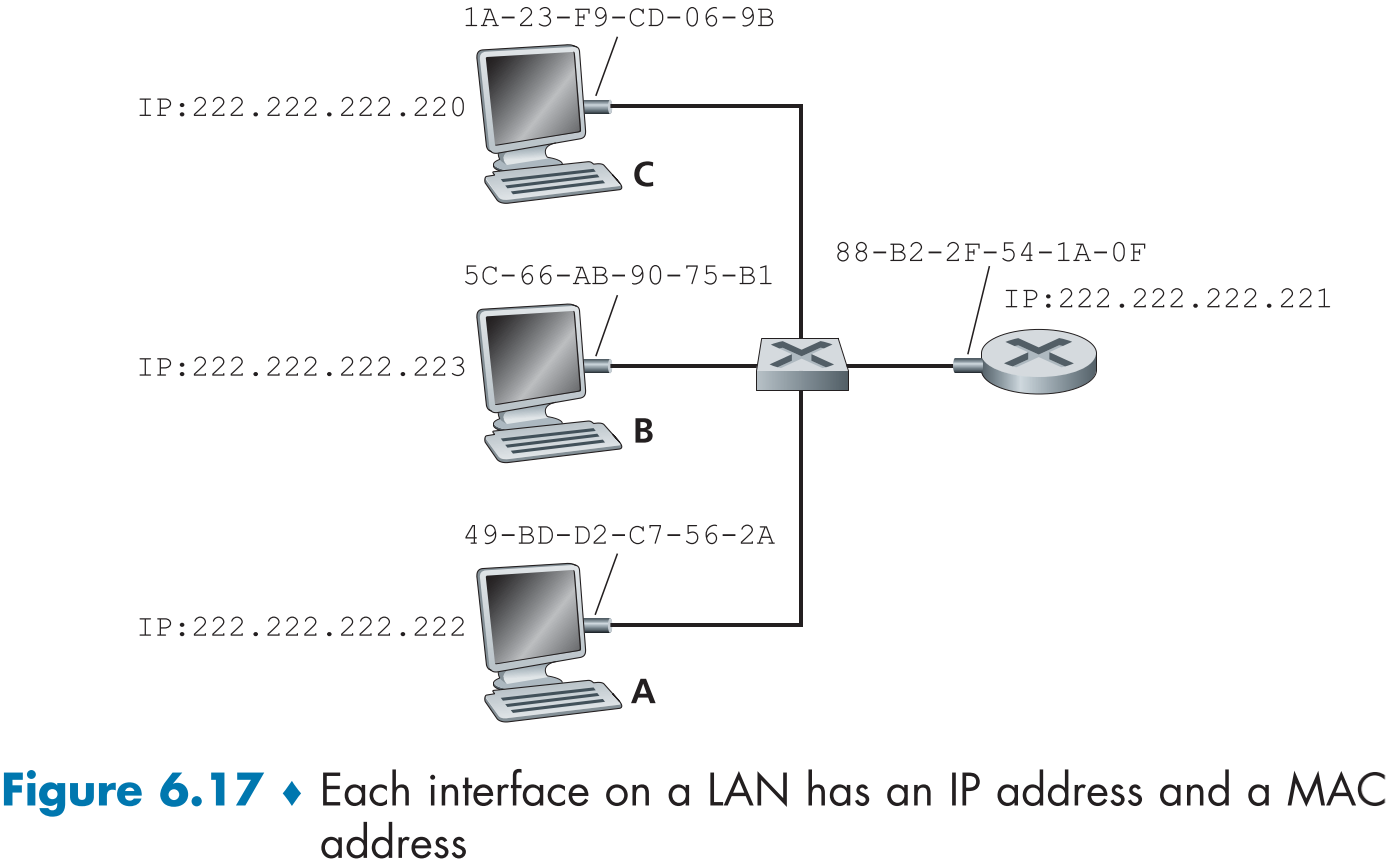
figure 6.17은 네트워크 계층 주소와 연결 계층 주소가 하나씩 할당된 네트워크의 예시이다.
만약 222.222.222.220이 222.222.222.222에게 패킷을 보내려면, 목적지의 IP 주소 뿐만 아니라 MAC 주소를 프레임의 목적지 MAC 주소 헤더에 적어 LAN으로 보내야한다.
이때 송신자 측은 목적지의 MAC 주소를 얻기 위해 호스트에 포함된 ARP 모듈을 이용해 IP 주소(222.222.222.222)에서 MAC 주소(49-BD-D2-C7-56-2A)를 알아낸다.
ARP의 IP 주소를 이용해 MAC 주소를 얻어낸 다는 점이 도메인을 이용해 IP주소를 얻어내는 DNS와 유사한데, 한가지 차이점은
DNS는 전체 인터넷에서 IP 주소를 얻어내지만, ARP는 같은 서브넷에 한해서만 호스트와 라우터 인터페이스의 MAC 주소를 얻어낸다는 점이다.
각각 호스트와 라우터는 figure 6.18과 같은 ARP 테이블을 메모리에 가지고 있으며, IP 주소와 MAC 주소의 맵 형식으로 되어 있다.
TTL(Time-to-live)는 해당 항목이 유효한 시간이며, 해당 항목은 시간을 넘으면 지워지게 되며, 보통 생성부터 20분 뒤 이다.
ARP 테이블은 서브넷 내부의 모든 IP 주소와 MAC 주소에 대한 정보를 가지고 있지 않고, 추가로 TTL에 의해 지워지므로, 존재하지 않은 항목은 ARP 프로토콜을 이용해서 생성해야한다.
-
먼저 ARP 쿼리 패킷(ARP query packet)이라는 ARP 형식을 가진 패킷을 생성한다.
-
해당 패킷의 목적지 IP 주소를 설정하고, 목적지 MAC 주소를 MAC 브로드캐스트 주소(FF-FF-FF-FF-FF-FF)로 설정한 뒤, 프레임으로 캡슐화해 서브넷에 보낸다.
-
스위치는 ARP 쿼리 프레임을 브로드캐스트하여 서브넷 내의 모든 호스트에게 보낸다.
-
각 호스트의 어답터는 ARP 패킷을 ARP 모듈로 보내고, 목적지 IP 주소를 자신의 IP 주소와 비교해본다.
-
다르다면 무시하고, 같다면 ARP 응답 패킷(ARP response packet)을 생성한다. ARP 응답 패킷은 ARP 쿼리 패킷과 같은 형식 구조를 가지고 있다.
-
ARP 응답 패킷은 ARP 쿼리 패킷을 참조해 목적지 주소를 설정하고, 출발지 주소는 자신의 IP 주소와 MAC 주소로 설정해서 스위치로 보낸다.
-
스위치에 의해 원래 브로드캐스트했던 호스트에게 돌아가고, 해당 호스트의 어답터의 ARP 모듈은 응답 패킷의 정보를 토대로 ARP 테이블을 갱신한다.
| IP 주소 | MAC 주소 | TTL |
|---|---|---|
| 222.222.222.221 | 88-B2-2F-54-1A-0F | 13:45:00 |
| 222.222.222.223 | 5C-66-AB-90-75-B1 | 13:52:00 |
[Figure 6.18 222.222.222.220에서 가능한 ARP 테이블 (A possible ARP table in 222.222.222.220)]
ARP의 추가적인 특징은 다음과 같다.
-
ARP 쿼리 패킷은 브로드캐스트 프레임, ARP 응답 패킷은 기존 프레임에 담겨진다.
-
ARP는 plug and play로, 운영체제나 시스템 관리자와 관계 없이 ARP 테이블이 자동으로 생성되며, 스스로 운영된다.
-
만약 해당 호스트가 서브넷에서 지워지면 서브넷 내의 다른 호스트의 ARP 테이블에서 관련 항목이 즉시 지워진다.
ARP는 ARP 패킷이 프레임에 캡슐화된다는 점과 IP 주소를 다룬다는 점에서 네트워크 계층 프로토콜 특성이 있고, MAC 주소를 다룬다는 점에서 연결 계층 프로토콜 특성이 있으므로, 양 계층의 경계에 해당하는 프로토콜로 보면 된다.
서브넷 바깥에 데이터그램 보내기 (Sending a Datagram off the Subnet)
그렇다면 다른 서브넷에 속한 호스트와 통신하려면 어떻게 할까? figure 6.19는 두 서브넷으로 이루어진 라우터의 네트워크 그림이다.
각 호스트, 라우터의 인터페이스에는 IP 주소와 MAC 주소, ARP 모듈과 어답터가 존재하며, 라우터의 경우는 인터페이스가 2개이므로 2개씩 존재하는 셈이다.
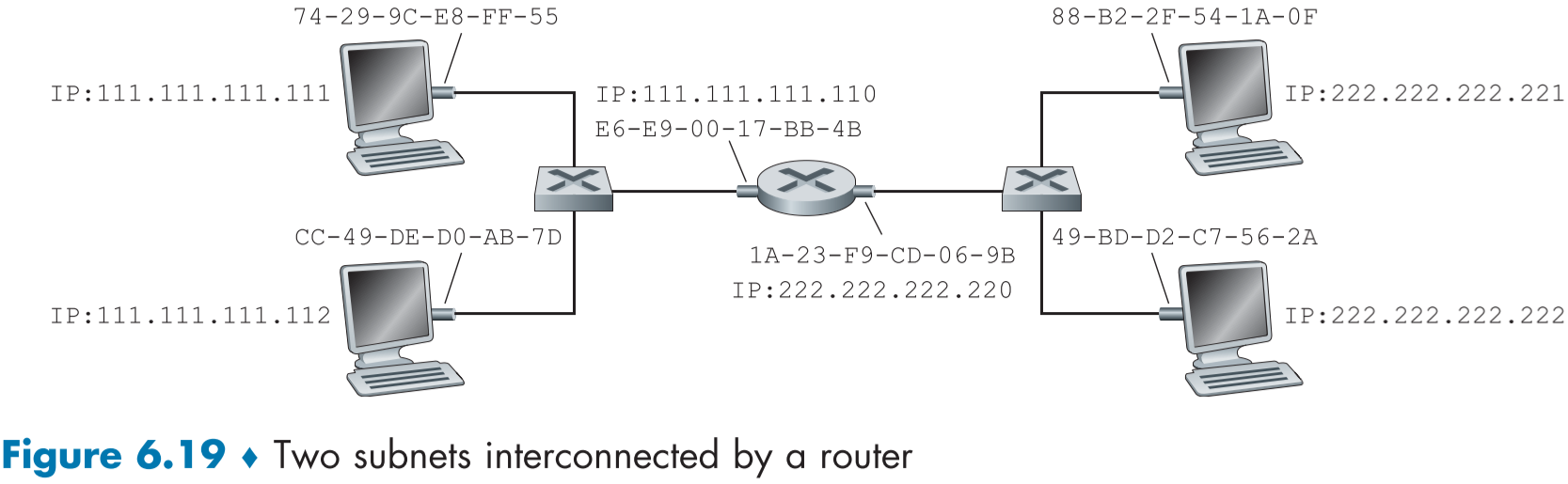
위 네트워크에서 좌측 서브넷의 111.111.111.111이 우측 서브넷의 222.222.222.222에게 데이터그램을 보내는 과정을 알아보자.
먼저 111.111.111.111 측에서 데이터그램을 만들때, 목적지 IP 주소는 알지만, 목적지 MAC 주소는 모르므로, 목적지 MAC 주소에 적을 정보를 알아내야 한다.
물론, 무슨 이유로 222.222.222.222의 MAC 주소 49-BD-D2-C7-56-2A를 안다고 하여도 해당 MAC 주소를 집어 넣으면, 스위치 측에서 해당 MAC 주소가 좌측 서브넷 에 존재하지 않으므로, 데이터그램을 파기해버린다. MAC 주소는 같은 서브넷에서만 유효하다는 것을 상기하자.
- 먼저, 111.111.111.111은 데이터그램의 목적지 IP 주소가 원래 목적지인 222.222.222.222로 설정하고, 이를 프레임으로 캡슐화한 뒤, 프레임의 목적지 MAC 주소는 좌측 서브넷에 연결된 라우터의 인터페이스 MAC 주소인 E6-E9-00-17-BB-4B로 보낸다.
- 라우터의 인터페이스 MAC 주소는 ARP 프로토콜을 통해서 가져올 수 있다.
- 라우터 인터페이스 111.111.111.110은 해당 프레임을 받고, 네트워크 계층으로 옮기면서 디캡슐화하여 데이터그램으로 바꾼다.
- 네트워크 계층에서 데이터그램과 포워드 테이블을 대조하여 목적지 IP 주소가 우측 서브넷 소속임을 알고, 라우터 인터페이스 222.222.222.220로 포워딩한다.
- 라우터 인터페이스 222.222.222.220은 받은 데이터그램의 우측 서브넷 소속인 것을 알고, 222.222.222.222의 MAC 주소를 ARP 테이블에서 가져와 프레임으로 만들고 스위치에 보내 서브넷 내부에 전파한다.
- 이때 ARP 테이블에 없으면 역시나 ARP 프로토콜을 통해서 가져온다.
이더넷에서의 ARP의 행동은 RFC 826에 적혀있으며, ARP TCP/IP 튜토리얼은 RFC 1180에 존재한다.
6.4.2 이더넷(Ethernet)
유선 LAN 기술은 token ring, FDDI, ATM 등이 있었지만 단연 최고의 인기는 이더넷(Ethernet)이다.
인기의 원인은 다음과 같다.
- 오래전에 소개된 고속 LAN, 선점 효과
- 토큰 링, FDDI, ATM은 상대적으로 더 복잡하고 비용이 높은 프로토콜
- 최신 LAN 기술을 따라잡을 수 있도록 업데이트 되어 왔음
- 이더넷이 인기가 많자, 이더넷 하드웨어들 또한 가격이 싸지고, 제품이 다양함.
원본 이더넷 LAN은 동축 버스(coaxial bus)를 통해서 서로 연결하였고, 브로드캐스트 LAN이라서 전송하는 모든 프레임은 버스에 연결된 모든 어뎁터들에게 전송되었다. (섹션 6.3.2 그래프 참조)
그후, 허브(hub)라고 불리우는 비트 정보를 증폭시켜주는 역할만 하는 물리 계층 장비를 이용한 허브 기반 LAN이 유행하였고, 이때도 여전히 브로드캐스트 LAN으로, 충돌이 발생하고, 이를 재전송해줘야 했다.
2000년대 초에는 허브 중심을 링크 계층 장치인 스위치로 바꾼 스위치드 이더넷(switched ethernet)이 유행하게 되었고, 충돌이 존재하지 않으며, 패킷을 저장 및 포워드(store-and-forward)하였다.
이더넷 프레임 구조 (Ethernet Frame Structure)
이더넷 프레임 구조에 대해 알아보기 위해 네트워크를 가정해보자.
두 호스트 A, B는 같은 이더넷 LAN(figure 6.17 같은)에 존재하며, 어뎁터 A의 MAC 주소는 AA-AA-AA-AA-AA-AA이고, 어뎁터 B의 MAC 주소는 BB-BB-BB-BB-BB-BB이며, 이더넷 프레임은 페이로드로 IP 데이터그램을 집어 넣어 통신한다. 어뎁터 A가 B에게로 통신하려 한다고 가정하자.
이제 figure 6.20을 참조하며 이더넷 프레임 구조를 알아보자.

-
Data field (데이터 필드, 46 바이트 ~ 1500 바이트)
IP 데이터그램이 담기는 곳, 이더넷의 최대 전송 단위(maximum transmission unit, MTU)는 1500 바이트이며, 이 이상일 경우 호스트가 데이터그램을 여러개로 나누어야 하며, 최소 전송 크기는 46 바이트로, 이 이하일 경우 추가로 의미없는 데이터 집어넣어야 한다. IP 데이터그램의 length 필드를 통해 의미없는 데이터와 데이터 그램을 구분한다.
-
Destination address (목적지 주소, 6 바이트)
목적지 어뎁터의 MAC 주소가 담기는 곳, 시나리오 같은 경우 BB-BB-BB-BB-BB-BB이며, MAC 브로드캐스트 주소(FF-FF-FF-FF-FF-FF)일 경우 이더넷 LAN 내부의 모든 어뎁터에게 프레임이 복사되어 전달된다. 자신의 MAC 주소와 일치하지 않거나 MAC 브로드 캐스트 주소가 아니면 프레임을 버린다.
-
Source address (출발지 주소, 6 바이트)
전송을 시작한 출발지 어뎁터의 MAC 주소가 담기는 곳, 이번 경우에는 AA-AA-AA-AA-AA-AA
-
Type field (종류 필드, 2 바이트)
이더넷이 멀티플렉스할 네트워크 레이어 프로토콜의 고유 코드가 담기는 곳, 보통은 IP이지만 ARP(0806)나 AppleTalk 같은 다른 네트워크 계층 프로토콜이 들어올 수 있다. 이를 보고, 어뎁터는 어느 네트워크 계층 프로토콜로 데이터그램을 보낼지(디멀테플렉스) 결정한다.
이 부분은 네트워크 계층의 데이터그램이나 전달 계층의 포트번호 필드와 비슷한 역할을 한다; 상위 계층 어느 프로토콜로 데이터를 보내야하는가?
-
Cyclic redundancy check(CRC, 4 바이트)
이전에 배웠던 CRC 필드, 프레임의 비트에러를 탐지한다.
-
Preamble (서문, 8 바이트)
프레임의 비트들의 처음 시작으로 등장하는 필드로, 총 8 바이트중 7바이트는 10101010이고, 마지막 바이트는 10101011이다. 첫 7바이트는 수신측 어뎁터를 깨우는 역할을 하며, 내장 시계를 송신측 클럭과 동기화한다.
클럭의 동기화는 이더넷 LAN은 특정 수치(10 Mbps, 100 Mbps, 1 Gbps)의 처리율을 노리지만, 언제나 조금씩 처리율의 차이가 나므로, 송신자측에서 1과 0의 반복 신호의 도착 속도를 측정하여 비트 속도를 계산해 송신자 측에서 수신자 측의 클럭과 맞추는 것이다. 비트 동기화라고도 한다.
마지막 바이트는 SFD(프레임의 시작 구분자, Start of Frame delimiter)라고 따로 분류되어 불리우기도 하며, 마지막 두 비트(11)은 이제 Preamble이 끝나고 본문이 시작됨을 알린다. 이를 프레임 동기화라고 한다.
이더넷은 IP와 UDP처럼 비연결성 서비스이며, 데이터 비신뢰성(unreliable service) 서비스이며, 즉 아무런 예고없이 프레임이 도착하고, 해당 프레임이 CRC 에러 감지를 통과하든 못통과하든 ACK나 negative ACK 메시지를 돌려주지 않는다.
덕분에 이더넷의 구현이 간단하고 저렴하지만 대신 데이터 흐름에 빈 공간이 생길 수 있다. 이러한 갭은 보통 전달 계층의 TCP가 재전송시켜 해결하거나 UDP처럼 그냥 내버려둔다.
이더넷 기술(Ethernet Technologies)
사실 이더넷은 IEEE 802.3 CSMA/CD (Ethernet) working group에서 지정한 10BASE-T, 10BASE-2, 100BASE-T, 1000BASE-LX,10GBASE-T, 40GBASE-T 등 많은 접두어(acronyms) 버전이 있으며,
각각 앞 부분은 10, 100, 1000, 10G, 40G은 10 Mbit/s, 100 Mbit/s, 1 Gbit/s, 10 Gbit/s, 40 Gbit/s 의 이더넷을 의미하며, BASE는 물리적 매질이 오직 이더넷 트래픽만 사용하는 것을 의미하며, 802.3 기준의 대부분을 차지한다. 마지막 부분은 동축케이블, 광섬유, 구리선 등의 물리적 매질을 의미하며, T의 경우 구리 연선(twisted-pair copper wire)를 의미한다.
역사적으로 이더넷은 동축 케이블의 한 부분으로 개발되었으며, 10BASE-2와 10BASE-5 기준은 10Mbps 이더넷에 2가지 종류의 500m 내의 동축 케이블로, 이뤄진다. 이보다 길면 리피터라는 물리 계층 장비를 이용해 입력 신호를 증폭하여 출력해 먼 곳까지 도달하게 했다.
동축케이블은 브로드캐스트 매질로, 자원을 공유하며 여러 충돌이 일어났고, 이를 CDMA/CD 프로토콜로 해결하여 LAN을 만들 수 있게 되었다..
지금의 이더넷은 과거의 bus기반과 달리 스위치를 이용해 노드들은 연결하며, 사용하며, 속도도 월등히 빨라졌다.
- 이때는 100m 내에서는 구리 연선, 수킬로 미터 단위는 광섬유를 사용해 연결한다.
figure 6.21은 이러한 다른 기준들과 MAC 프로토콜, 프레임 포맷을 보여준다.

최신의 기가비트 이더넷은 40000Mbps 급의 처리율을 보이며, 거대한 규모에도 높은 호환성을 보인다.
다음은 IEEE 802.3z에서 설명한 기가비트 이더넷의 기준이다.
-
표준 이더넷 프레임 포맷(fig 6.20)을 사용하고, 10BASE-T, 100BASE-T와 호환이 되어야 한다. 이를 통해 기존의 이더넷 장치 기반에 기가비트 이더넷을 구현하기 쉬워진다.
-
스위치를 사용하는 지점간(point-to-point) 연결과 허브를 사용하는 공유 브로드캐스트 채널을 사용함. hub는 이더넷에서 버퍼드 분배자(buffered distributor)라고 부른다.
-
브로드캐스트 채널에는 CSMA/CD 프로토콜 사용하며, 성능 향상을 위해 노드 간의 최대 거리가 엄격히 지켜져야 한다.
-
지점간 통신에서 40Gbps의 완전 양방향 통신이 가능해야한다.
기가비트 이더넷과 광섬유로 인해 카테고리 5 UTP 케이블을 사용하여 이더넷을 구축할 수 있게 되었다.
사실 store-and-forward 패킷 스위칭을 사용하는 최신 스위치 기반 성형 이더넷의 경우, 스위치가 자동으로 전송을 조정해주고, 완전 양방향 통신과, 포워딩 버퍼를 지원하는 등의 이유로, 더이상 MAC(매체 접근 제어, medium access control) 프로토콜을 이용해 충돌을 관리하지 않아도, 스위치가 해준다.
하지만 이더넷 프레임 포맷은 전혀 변하지 않았으므로, 여전히 이더넷의 정의에 부합한다.
6.4.3 연결 계층 스위치 (Link-Layer Switches)
스위치는 연결 계층 프레임을 입력받아 나가는 링크로 포워딩하는 장치이며, 서브넷 내의 호스트나 라우터들에게 투명(transparent)하다.
이 뜻은 호스트나 라우터가 프레임을 보낼 때, 스위치의 존재와 포워딩 기능 등을 전혀 신경쓰지 않는다는 의미이다.
스위치 또한 갑작스런 통신 증가에 따른 부하를 방지하기 위해 버퍼(buffer)를 가지고 있다.
포워딩과 필터링 (Forwarding and Filtering)
필터링(filtering)은 스위치의 기능으로, 프레임을 포워딩 또는 버림을 결정하는 것이고, 포워딩(forwarding)은 또한 스위치의 기능으로 프레임이 어떤 인터페이스로 전달되어야 하는지 스위치 테이블을 통해서 결정한다.
스위치 테이블은 항목들을 가지고 있지만 LAN 내부의 모든 필요한 호스트와 라우터 정보를 가지고 있지 않다.
스위치 내부의 항목은 각각 (1) MAC 주소, (2)해당 MAC 주소가 포워딩 되야하는 스위치 인터페이스, (3) 항목 생성 시간
아래 figure 6.22는 figure 6.15(책의 오류인듯, 해당하는 주소를 가진 figure가 이 장에 없음) 네트워크의 스위치 테이블 예시이다.
| 주소 | 인터페이스 | 시간 |
|---|---|---|
| 62-FE-F7-11-89-A3 | 1 | 9:32 |
| 7C-BA-B2-B4-91-10 | 3 | 9:36 |
| … | … | … |
[Figure 6.22 상단 스위치 테이블 일부 (Portion of a switch table for the uppermost switch in Figure 6.15)]
이는 네트워크 계층 라우터의 라우팅 테이블과 비슷하게 생겼는데, 실제 현재의 SDN 스위치들은 설정을 통해 네트워크 계층 데이터그램 스위치로 쓸 것인지, 연결 계층 프레임 스위치로 쓸지 설정할 수 있다. 하지만 우리는 여기서는 SDN을 사용하지 않는 전통적인 스위치 테이블을 이용할 것이다.
먼저 스위치 인터페이스 x에 도착한 데이터그램의 목적지 MAC 주소가 DD-DD-DD-DD-DD-DD라고 가정하고 세가지 시나리오를 알아보자.
- DD-DD-DD-DD-DD-DD 주소에 관한 항목이 x의 스위치 테이블에 없는 경우, 스위치는 프레임의 복사본을 인터페이스 x(왔던 길)을 제외한 모든 인터페이스에 보낸다.(=프레임을 브로드캐스트 한다.)
- DD-DD-DD-DD-DD-DD 주소에 관한 항목이 x의 스위치 테이블에 있고, 해당 주소가 가야하는 인터페이스가 x 자신일 경우, 스위치가 필터링 기능을 수행하여 프레임을 버린다.
- DD-DD-DD-DD-DD-DD 주소에 관한 항목이 x의 스위치 테이블에 있고, 해당 주소가 가야하는 인터페이스가 x 자신이 아닌 경우, 프레임이 목적지가 있는 LAN 부분의 인터페이스로 포워딩되고, 프레임은 해당 인터페이스의 출력 버퍼에 들어간다.
스위치는 허브보다 위와 같은 기능을 추가로 수행한다.
자가 학습(Self-Learning)
스위치의 스위치 테이블을 처음 부터 가지고 있지않으며, 라우터와 같이 라우팅 프로토콜도 실행하지 않는다.
대신 스위치 테이블은 자동, 동적, 자체적으로 테이블을 생성하며, 이를 자가 학습(Self-Learning)이라고 한다.
- 스위치 테이블은 시작시 비어있다.
- 인터페이스에 프레임이 도착할 때마다, (1) source address 필드의 MAC 주소와, (2) 프레임이 입력된 인터페이스, (3) 현재 시간을 이용해 테이블에 기록한다. 만약 LAN 내부의 모든 호스트가 프레임을 보냈다면, 모든 호스트에 대한 항목을 가진 테이블이 완성된다.
- 일정 시간마다(이를 에이징 시간(aging time)이라고 한다.), 특정 주소로 부터 프레임이 오지 않으면, 해당 주소가 출발지 주소인 항목을 지워버린다. 이를 통해 호스트가 추가, 제거, 변경되는 상황에 대비할 수 있다.
| 주소 | 인터페이스 | 시간 |
|---|---|---|
| 01-12-23-34-45-56 | 2 | 9:39 |
| 62-FE-F7-11-89-A3 | 1 | 9:32 |
| 7C-BA-B2-B4-91-10 | 3 | 9:36 |
| … | …. | … |
[Figure 6.23 스위치가 01-12-23-34-45-56의 주소를 가진 어답터의 위치를 학습(Switch learns about the location of an adapter with address 01-12-23-34-45-56)]
스위치는 plug-and-play 장치로, 네트워크 관리자나 사용자의 관심이 필요 없으며, LAN 세그먼트(랜의 연결선?)에 스위치를 아무 설정없이 설치하기만 하면 된다.
스위치는 완전 양방향 통신(full-duplex)로, 스위치 인터페이스는 동시에 프레임을 보내거나 받을 수 있다.
연결 계층의 스위칭 속성(Properties of Link-Layer Switching)
버스나 허브 기반 성형 구조 같은 브로드캐스트 링크보다, 연결 계층 스위치를 사용하는 것의 장점은 다음과 같다.
-
충돌 없음(Elimination of collisions)
스위치 기반 LAN은 충돌에 의한 대역폭 손실이 없다.
스위치가 프레임을 버퍼에 집어넣어 순서대로 LAN 세그먼트에 보내주므로 효율적이다.
-
다차원적 링크(Heterogeneous links)
스위치로 인해 링크들이 분리되어 있으므로, 다른 매체나 속도로 링크를 고를 수 있다. 와이파이와 광섬유, 구리 연선이 섞여있는 스위치가 존재할 수 있다. 이를 통해 레거시 시스템으로 인한 다른 장치의 시스템에 새로운 장치를 추가할 수 있다.
-
관리(Management)
추가적인 보안성과 쉬운 네트워크 관리체계를 제공한다.
만약 어뎁터가 이상해서 끊임없이 프레임을 보낸다면(jabeering 어뎁터라고 함), 스위치가 그걸 감지하고 해당 어뎁터를 무시할 수 있다.
스위치가 트래픽, 충돌율, 링크 상태 등의 통계 데이터를 모아 관리에 도움을 줄 수 있다.
SNIFFING A SWITCHED LAN: SWITCH POISONING
스위치는 프레임을 모든 호스트에게 브로드캐스트하지 않으므로 패킷 스니핑에 강하다.
공격자가 목적지 주소가 브로드캐스트 주소(FF-FF-FF-FF-FF-FF)로 되어있고, 출발지 주소는 무작위 가짜 주소로 되어있는 프레임을 스위치에 마구 보내면, 스위치는 그 내용을 토대로 의미없는 항목을 스위치 테이블에 계속 넣게 되고, 이에 따라 결국 정상적인 호스트들의 주소는 추가되지 않게 되며, 이를 스위치 포이즈닝(switch poisoning)이라고 한다.
또한, 이러한 프레임은 브로드캐스트 되기 때문에 공격자에게 알림이 간다.
복잡한 공격에도 대비할 수 있는 스위치가 상대적으로 허브나 무선 랜보다 보안상 낫다.
스위치 VS 라우터(Switches Versus Routers)
스위치와 라우터는 일부 공통점과 차이점을 아래처럼 공유한다.
| 스위치 | 라우터(비 SDN 계열) | |
|---|---|---|
| 계층 | 연결 계층 | 네트워크 계층 |
| 대상 | 프레임 | 데이터그램 |
| 사용 주소 | MAC 주소 | IP 주소 |
| 하는 역할 | 패킷을 올바른 링크로 보냄 | 패킷을 올바른 링크로 보냄 |
| 스위칭 방식 | 버퍼를 이용한 store-and-forward | 버퍼를 이용한 store-and-forward |
하지만 오픈플로우를 사용하는 라우터는 IP 주소뿐만 아니라 프레임, 데이터그램, 세그먼트의 필드를 활용한다.
그러므로, 네트워크를 만들 때 스위치와 라우터 중에 사용할 장치를 잘고려해서 설치해야 한다.
장단점은 다음과 같다.
| 스위치 | 라우터 | |
|---|---|---|
| 장점 | plug-and-play 방식, 따로 설정해줄 필요 없음, 필터링과 포워딩 속도가 빠름 (네트워크 계층이 구현되지 않아 오버헤드가 적음) |
IP 주소는 계층적 구조+ IP 데이터그램 TTL 헤더덕분에 설정을 잘못하지 않는 이상, 패킷의 무한 순환이나 중복 경로가 없음, 네트워크 구조가 스패닝 트리(spanning tree: 노드간에 군더더기없는 엣지 없이 최소한의 링크로 연결)로 제한되지 않고 다양한 구조가 가능(방화벽, bypass 링크) |
| 단점 | 프레임 브로드캐스트 순환(cycling of broadcast frames: 프레임이 도착하지 못하고 끊임없이 네트워크 내부를 돌아 성능을 잡아먹음)을 막기 위해 스위치드 네트워크의 형상이 스패닝 트리로 제한되어있음, 네트워크 규모가 커지면 큰 ARP 표가 호스트와 라우터에 필요하고, ARP 트래픽과 프로세싱이 성능을 잡아먹음, 브로드캐스트 폭풍(broadcast strom: 호스트 하나가 오작동으로 끊임없이 브로드캐스트 프레임을 보내고 스위치가 이를 브로드캐스하여 네트워크가 마비되는 현상)에 취약 |
plug-and-play 방식이 아님, 설치시 설정 필요, 패킷 처리 시간이 비교적 오래 걸림, 발음을 라우터로 부를지 루터로 부를지 논란이 있음 |
주로 LAN 세그먼트(링크, 스위치 같은 장비를 의미하는 듯?)가 적은 소규모 네트워크의 경우, 스위치가 만들어내는 브로드캐스트 트래픽을 감당할만 하므로, IP 설정이 필요없고 성능이 더 빠른 스위치 덕분에 스위치를 도입하는게 더욱 좋다.
하지만 규모가 커지면 라우터의 트래픽 고립 기능, 브로드캐스트 폭풍 방지, 좀 더 지능적인 라우팅을 위해 스위치에 추가적으로 라우터를 섞어 사용한다.
| 허브 | 라우터 | 스위치 | |
|---|---|---|---|
| 트래픽 고립(Traffic isolation) | X | O | O |
| 플러그 앤 플레이(Plug and play) | O | X | O |
| 최적 라우팅(Optimal routing) | X | O | X |
[Table 6.1 흔한 상호 연결 장치의 전형적인 특징 비교 (Comparison of the typical features of popular interconnection devices)]
추가적인 장단점과 스위치드 LAN을 이용한 이더넷의 성능향상은 [Meyers 2004; Kim 2008]에서 볼 수 있다.
6.4.4 가상 근거리 네트워크(VLANs) (Virtual Local Area Networks(VLANs))
최신 기업 LAN들은 마치 figure 6.15 처럼 각 부서별로 계별 스위치드 LAN을 만든 뒤, 서로 계층적으로 연결 시켜 계층적 구조를 이루기도 한다.
계층적 구조는 이상과 달리 세가지 단점이 있는데.
-
트래픽 고립의 부족(Lack of traffic isolation)
계층 구조가 그룹의 트래픽을 각자 스위치에 고립하더라도, ARP나 DHCP, 자가 학습되지 않은 프레임의 브로드캐스트 트래픽에 의해 LAN의 성능이 떨어질 수 있으므로, 세심한 트래픽 고립이 필요하다.
트래픽 고립은 추가로, 인사과의 메시지는 다른 부서에 절대로 가지못하게 하는 등의 보안이나 프라이버시 등에 사용될 수 있다.
이러한 트래픽 고립을 수행하려면 보통 라우터를 이용해야하지만, 나중에 스위치를 이용한 방법을 배워볼 것이다.
-
스위치들의 비효율적인 사용(Inefficient use of switches)
계층적 구조에서는 각 그룹마다 트래픽 고립을 위해 스위치가 하나씩 필요한데, 규모가 작은 그룹이 많으면, 할당된 스위치의 성능과 포트가 남아돌 수 있다.
-
사용자 관리(Managing users)
만약 사용자가 다른 그룹으로 이동한다면 물리적인 연결선을 바꿔줘야 하며, 두 그룹에 속해야하는 사용자는 더 큰 문제다.
이와 같은 문제들은 VLAN(가상 근거리 네트워크,virtual local area networks)을 지원하는 스위치를 통해 해결할 수 있다.
VLAN은 물리적으로 하나에 속하는 LAN을 가상으로 여러개로 나누며, 호스트들은 같은 VLAN에 속해야만 서로 통신할 수 있다.
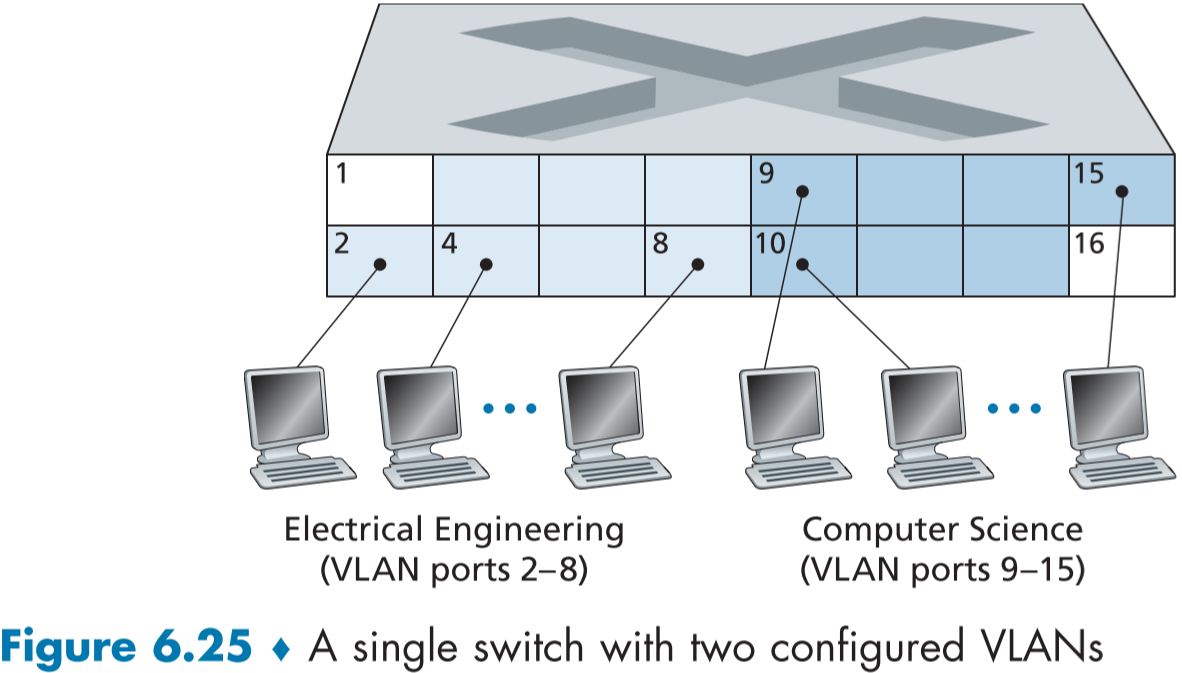
아 figure 6.25같은 경우, 포트 기반 VLAN으로, 일정 포트 번호들을 네트워크 관리자가 VLAN으로 지정하며, 각 VLAN들은 브로드캐스트 도메인을 형성하여 같은 도메인끼리만 연결가능하다.
예를 들어 아래에는 2~8 포트는 전기공학 부서, 9~15는 컴퓨터공학 부서에 할당하여 VLAN을 형성하였고, 할당되지 않은 1, 16번은 기본 VLAN 그룹이 된다.
만약 8번 포트 전기공학 사용자가 컴퓨터 공학으로 옮기게 되면, 물리적으로 바꿔낄 필요없이 단순히 8번 포트의 소속을 컴퓨터 공학 VLAN으로 옮기면된다.
이렇게 스위치 관리 소프트웨어로 port-to-VLAN 매핑이 된 표를 유지 관리하여, 스위치의 성능 및 포트 낭비 없이 여러 VLAN을 형성할 수 있다.
만약 각기 다른 VLAN의 호스타가 통신할 수 있게 설정하고 싶다면,
첫번째 방법은 설정하지 않은 1, 16번 같은 포트에 추가적인 라우터를 연결하고, 연결된 포트를 양쪽 VLAN에 모두 속하게 한 뒤, 라우터를 통해 통신하게 끔 하면 된다.
두번째 방법은 스위치와 라우터 기능을 둘다할 수 있는 장치의 경우, 위와 같은 기능을 가상으로 할 수 있게 제공하는 경우가 많다.
이번에는 물리적으로 다른 곳에 있는 호스트드과의 VLAN 설정에 대해 알아보자.
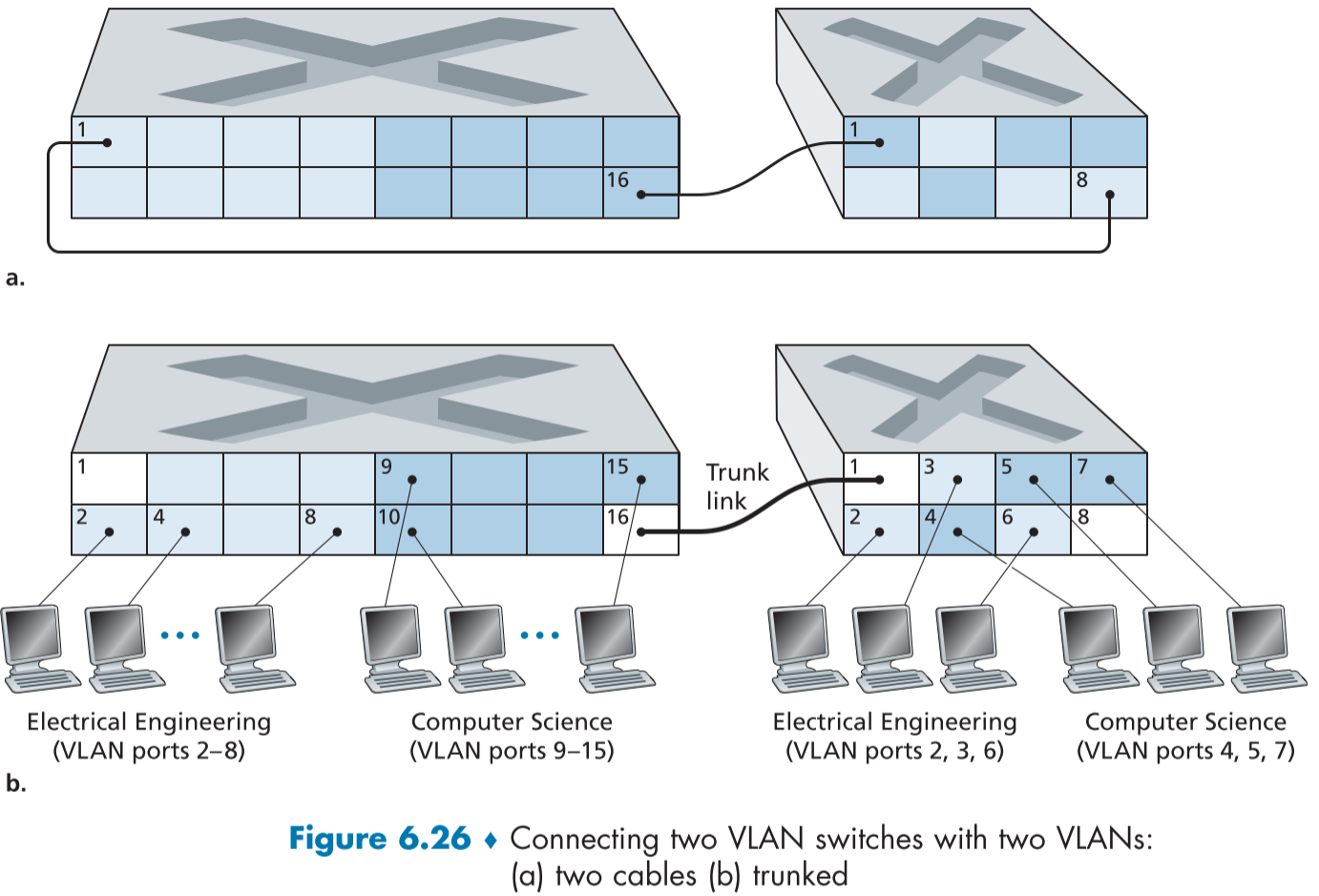
figure 6.26은 두 부서에 속한 호스트들 중 일부는 포트 8개의 스위치에 속한 상황에서 VLAN 설정을 하는 그림이다.
첫번째 방법은 figure 6.26(a)처럼 각 스위치에 부서마다 하나씩 대표 포트를 설정한 뒤, 이를 서로 연결하는 방법이다. 이 방법은 간단하지만 부서 N개에 총 N개의 포트가 필요하고, 스케일링이 힘들다는 단점이 있다.
두번째 방법은 figure 6.26(b)처럼 VLAN 트렁킹(VLAN trunking)을 이용하는 것이다.
각 스위치에 하나씩 모든 부서에 속하는 트렁크 포트를 설정하고, 이를 스위치 간에 연결하면, VLAN 내부의 브로드캐스트 되는 프레임은 트렁크 포트를 통해 다른 스위치로 전달된다.
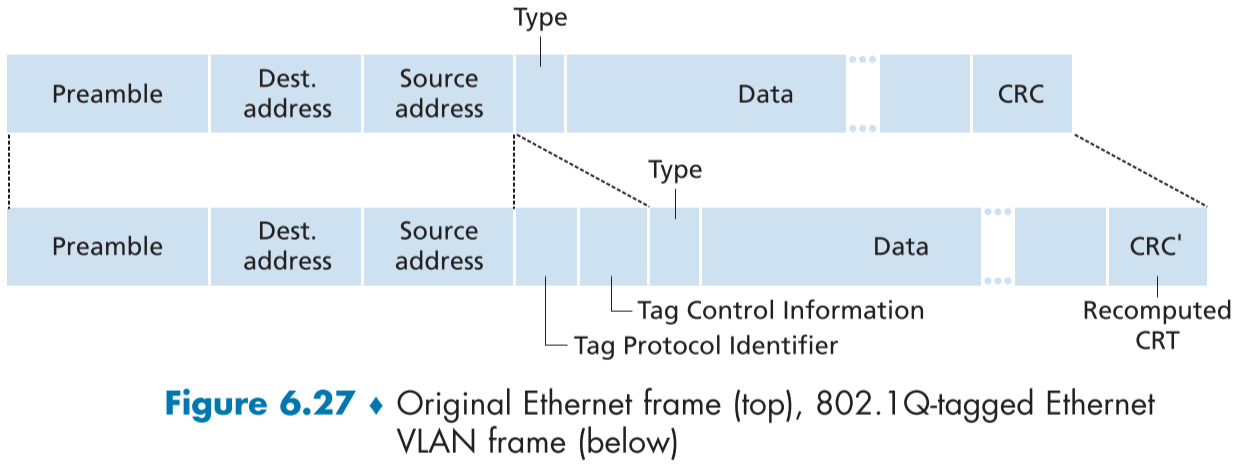
하지만 스위치는 트렁크를 통해서 들어온 프레임을 알맞은 부서에 브로드캐스트해줘야 하는데, 이를 위해 확장된 이더넷 프레임 형식인 802.1Q에는 4바이트의 VLAN tag 필드를 추가하여 VLAN을 구분하게 만들었다.
figure 6.27에 보이는 것 처럼 프레임이 VLAN 트렁크를 통과하려 할때, 송신자 측 스위치에서 VLAN tag를 추가하고, 수신자 측 스위치에서 VLAN tag를 확인하고 없앤다.
2바이트의 TPID(태그 프로토콜 식별자, Tag Protocol Identifier) 필드(보통, 16진수로 표현 xx-xx)와 2바이트의 Tag Control Information(태그 제어 정보)필드로 이루어져 있고, Tag Control Information은 12비트의 VLAN identifier 필드와 IP의 TOS 필드와 비슷한 3비트의 priority(우선순위) 필드로 이루어져 있다.
- 나머지 1비트는 CFI(canonical format identifier) 필드로, 이터넷의 경우 0, 토큰 링의 경우 1
포트 기반 VLAN 이외의 방법은 다음이 있다.
MAC 기반 VLAN은 특정 MAC 주소를 VLAN 그룹으로 묶는 방식이며, 포트에 장치가 연결될 때마다 해당 장치의 MAC 주소를 읽고 해당 포트를 VLAN 그룹에 추가하는 방식이다.
네트워크 계층 주소 기반 VLAN과 IP 라우터를 이용한 LAN들을 묶은 VLAN이 존재한다.
6.5 연결 가상화: 연결 계층으로서의 네트워크 (Link Virtualization: A Network as a Link Layer)
지금까지 학습을 통해 링크를 단순한 물리적 도선에서 부터 복잡한 스위치 구조까지 인식을 올리게 되었다.
하지만 호스트 입장에서 연결 계층의 일은 신경 쓰지 않아도 되므로, 어떠한 매질의 연결인지, 공유되는 브로드 캐스트 채널인지, LAN 세그먼트로 연결 되었느닞, 아니면 스위치드 LAN이나 VLAN인지 신경쓸 필요가 없다.
MPLS (다중 프로토콜 레이블 스위칭 Multiprotocol Label Switching) 네트워크는 패킷 스위칭을 이용한 가상의 서킷 스위치 네트워크로 고유한 패킷 포맷과 포워딩 행동을 가지고 있다.
MPLS는 IP 장비들을 연결해주는 연결 계층 기술처럼 볼 수 있으며, Frame-relay와 ATM이 비슷한 역할을 하지만 이번엔 다루지 않는다.
6.5.1 다중 프로토콜 레이블 스위칭(MPLS) (Multiprotocol Label Switching (MPLS))
다중 프로토콜 레이블 스위칭(MPLS)은 가상 서킷 네트워크의 키인 고정 길이 레이블(fixed-length-label)을 이용해 IP 라우터의 포워딩 속도를 높이기위해 등장하였다.
목적은 IP의 목적지 기반 포워딩을 대체하는 것이 아니라, 라우터에게 포워딩의 새로운 선택권을 주도록 하는 것이었으며, IP 주소와 라우팅에 많은 영향을 받았고, 이러한 VC(가상 서킷, Virtual Circuit) 기술과 데이터그램 라우팅의 결실이 MPLS 프로토콜로 나타났다.
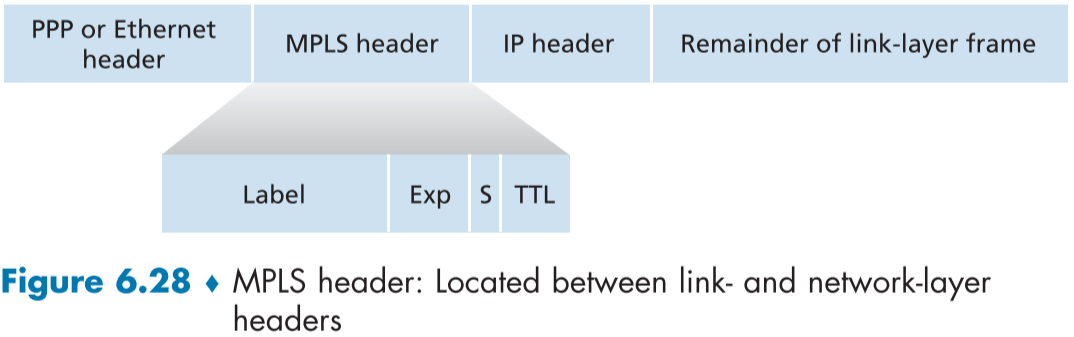
위 figure 6.28은 MPLS 헤더의 위치와 구조에 대해 잘알 수 있다.
MPLS 헤더는 MPLS 지원 라우터에 의해 연결 계층과 네트워크 계층 헤더 사이에 추가되며, 레이블 필드, 실험용으로 남긴 3 비트, 쌓여진 MPLS 헤더의 연속의 끝을 알리는 1 비트의 S 필드, TTL 필드로 이루어져 있다.
MPLS 헤더는 MPLS 지원 라우터 간의 연결일때만, 라우터에 의해 추가된다.
- 즉, 송신 라우터와 수신 라우터가 둘다 MPLS 지원 라우터일 때만 추가되며, 지원하지 않는 라우터 입장에서는 IP 헤더가 있어야할 자리에 오류가 난 비트가 있는거롤 보일 것이다.
MPLS 헤더는 IP 주소 대신 Label 필드를 보고 빠르게 라우팅하므로 레이블 스위치드 라우터(Label switched router)라고도 부른다.
즉, MPLS 지원 라우터는 굳이 목적지 IP 주소를 보고 포워드 테이블을 보고 최장 접두어 매치를 할 필요가 없다.
어떻게 Label 필드로 빠르게 라우팅하는 지, 상대가 MPLS 지원 라우터인지는 어떻게 아는 지 등을 알아보기 위해 figure 6.29 같은 시나리오를 알아보자.
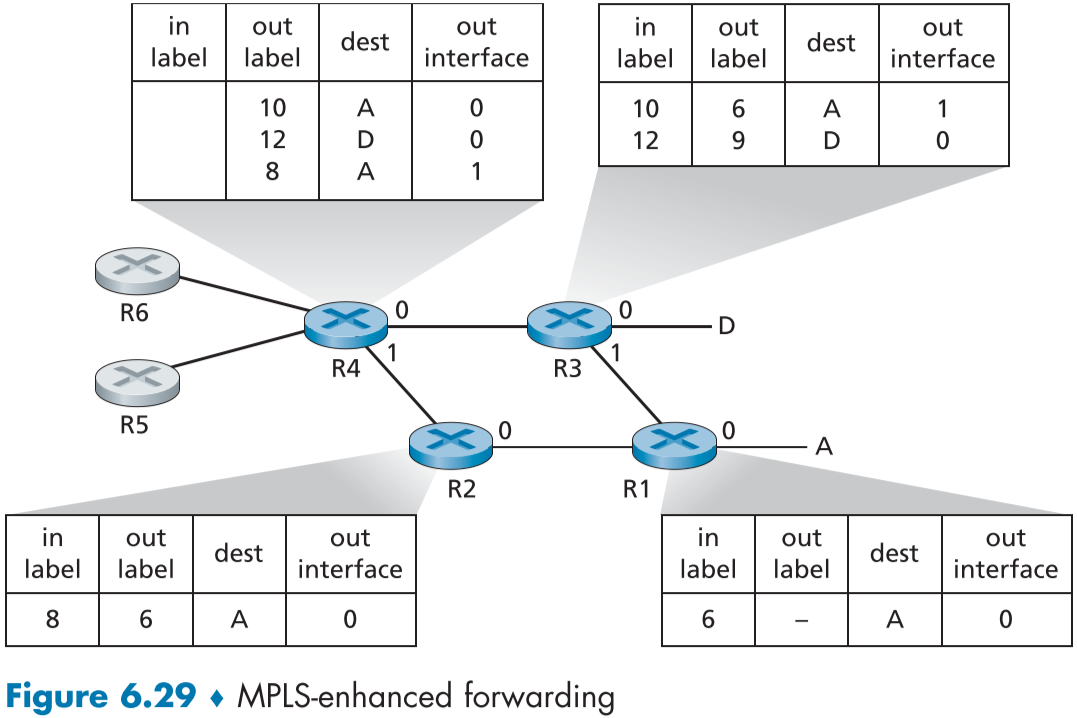
그림의 파란색 라우터(R1~R4)는 MPLS 지원 라우터이다.
먼저 연결된 MPLS 지원 라우터들은 자신이 갈 수 있는 MPLS 라우터가 아닌 링크와 필요한 레이블에 대한 정보를 주변 이웃의 다른 MPLS 지원 라우터 한정으로 전파한다.
예를 들어 R1은 레이블 6을 포함한 패킷은 A로 갈수 있게 할 것임을 R2와 R3에 알려주고, 이 정보를 받은 R2와 R3는 자신에게 각각 레이블 8번과 레이블 12번으로 온 패킷을 레이블 6으로 바꾸어 A에게 넘겨주는 형식으로 A로 갈 수 있음을 R4에게 알려준다.
이제 R4는 A로 갈 수 있는 레이블 변경 경로를 2개나 알고 있게 된다.
MPLS 구조는 ATM과 스위치드 LAN 처럼 패킷의 IP 헤더를 이용하지 않고, A, D 그리고 R5, R6 사이를 이어주고 있다.
자신의 레이블 정보를 다른 라우터에게 보내는 RSVP-TE[RFC 3209] 프로토콜(시그널링(signaling)이라고도 함),
MPLS 라우터들의 구조 안에서 최적의 경로를 계산하는 프로토콜,
- 실제로 공시적인 프로토콜은 없고, 네트워크 장치 회사마다 알아서 구현한다.
경로 계산을 위해 연결 상태 정보를 수집하는 프로토콜
- 보통 기존의 OSPF 같은 연결 상태 라우팅 알고리즘이 MPLS 지원 라우터에게 정보를 넘겨 주도록(flooding: 자신에게 패킷을 준 경로 이외의 경로들에게 패킷을 복사해서 뿌리는 알고리즘) 확장되있다.
등의 자세한 내용은 다루지 않겠다.
MPLS의 포워딩 속도 상승 이외의 또 다른 강력한 점은 트래픽 관리 능력(traffic management capability)의 향상이다. IP 라우팅 프로토콜은 언제나 최소 비용의 경로 하나만을 선택하지만, MPLS는 여러 경로를 선정하고 패킷의 순서, 정책, 성능, 트래픽 상황 등에 따라 다른 경로 또한 가능하게 만들어져있다. 이를 MPLS를 이용한 트래픽 공학(traffic engineering)이라고 한다.[RFC 3346; RFC 3272; RFC 2702; Xiao 2000]
MPLS를 이용해서 링크 연결이 실패할 시에 대비해 미리 계산한 예비 경로로 트래픽을 보낼 수도 있고, VPN(가상 사유 네트워크, virtual private network)를 구현하는데 사용할 수 있다.
- VPN 서비스를 제공 ISP는 각 사용자들의 VPN을 MPLS 네트워크를 통해, 이를 통해 각 네트워크의 자원과 주소, 링크 상태를 격리시키면서 동시에 서로 연결시켜줄 수 있다.
MPLS는 현재 나중에 개발된 SDN, 일반화된 포워딩 패러다임과 여러 기능이 겹치며 경쟁중이다.
6.6 데이터 센터 네트워킹 (Data Center Networking)
구글, 아마존, 같은 거대 기업들은 수 천의 호스트로 이루어진 데이터 센터들을 외부 뿐만 아니라 내부적으로 서로 연결하여 데이터 센터 네트워크(Data Center Networking)를 형성했다.
클라우드 어플리케이션을 위한 데이터 센터 네트워킹에 대해서 배워보자.
데이터 센터는 보통 세가지 이유로 만든다.
- 웹 페이지, 검색 결과, 이메일, 비디오 등의 컨텐츠를 유저들에게 보내기 위해
- 분산 검색 엔진 색인 계산 같은 빅데이터 처리를 위한 거대 병력 컴퓨팅 자원 확보
- 다른 회사에게 클라우드 컴퓨팅 서비스 제공
6.6.1 데이터 센터 구조 (Data Center Architectures)
데이터 센터 설계는 보통 회사의 이득을 위해 극비에 부쳐져있다. 10만 호스트 데이터 센터의 경우 월 12억원 정도의 비용이 들어가며,
전체 비용의 45%는 3~4년 주기로 교체하는 호스트 서버 교체 비용, 25%는 변압기, UPS(무중단 전력 공급, uninterruptable power supplies) 시스템, 예비 발전기, 냉각 시스템 같은 기반 시설, 15%는 전기 사용을 위한 유틸리티, 15%는 스위치, 라우터, 부하 밸런서, 연결선, 트래픽 이동용 네트워크 장비 등에 쓰인다.
네트워크 비용은 가장 큰 비용은 아니지만, 성능을 늘리면서 비용은 줄일 수 있다.
호스트들은 일벌과 같은 존재로, 블레이드(blades)라고 불리우는 피자박스처럼 생긴 CPU, 메모리, 디스크 등을 포함하고 있는 상용 호스트를 이용한다.
블레이드는 랙(rack)이라고 불리우는 곳에 20~40개가 적층되며, 랙의 꼭대기는 TOR(랙의 꼭대기, Top of Rack) 스위치라고 불리우는 스위치가 위치하여, 자신이 속한 랙을 다른 랙, 데이터센터 내의 다른 스위치들과 연결하는 역할을 한다.
블레이드 호스트들은 자신의 렉에 위치한 TOR 스위치와 40 ~ 100 Gbps 수준의 이터넷 연결이 되고, 각자 데이터 센터 내의 유일한 IP 주소를 가지고 있다.
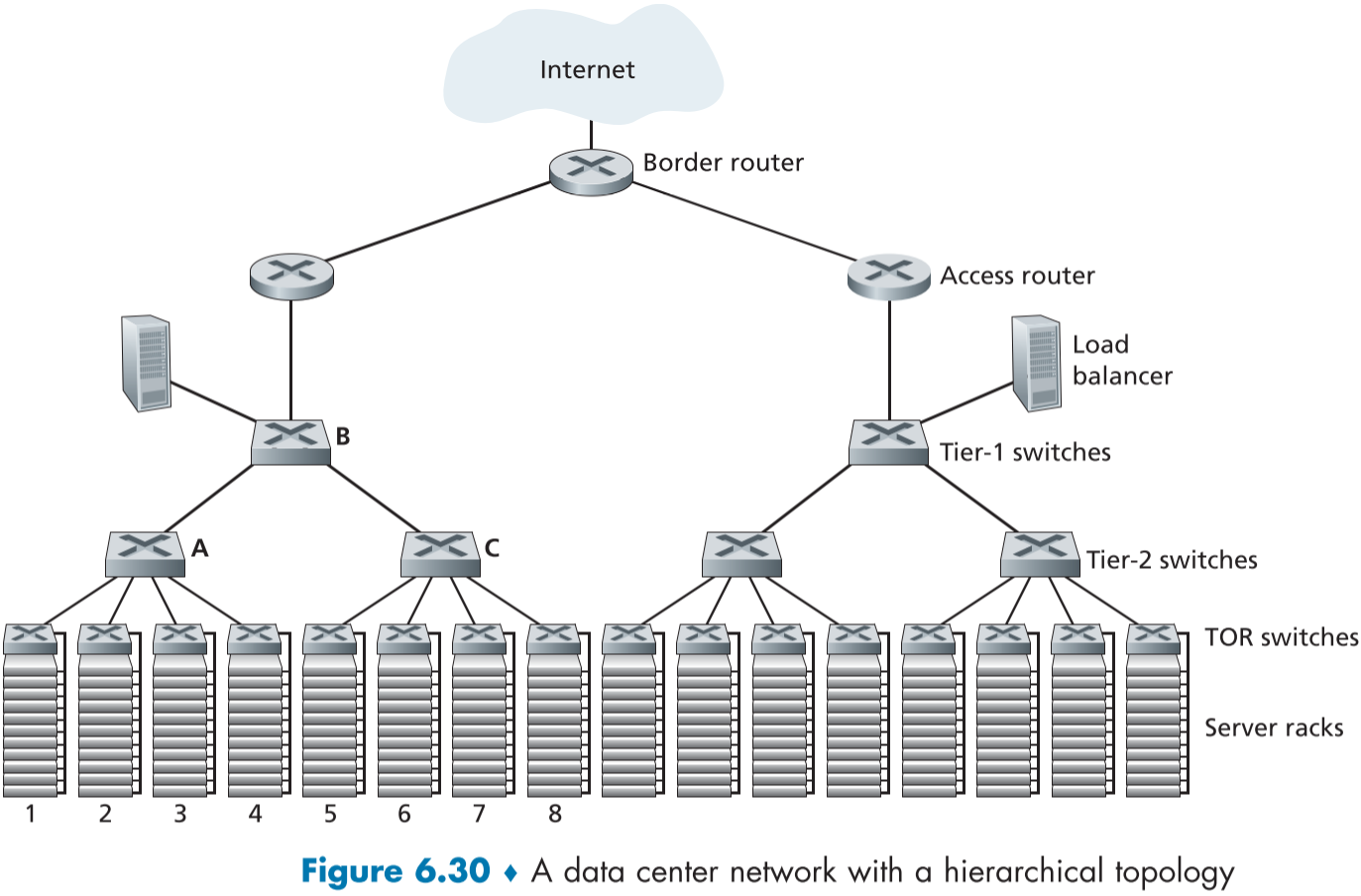
데이터 센터 네트워크의 트래픽은 크게 호스트와 외부 클라이언트와의 트래픽, 내부 호스트 간의 트래픽으로 트래픽을 나누며,
데이터 센터 네트워크는 한 개 이상의 경계 라우터(border router)를 이용해 외부 인터넷과 연결된다.
이러한 데이터센터 네트워크와 프로토콜, 랙과 경계 라우터들의 연경 방법을 데이터 센터 네트워크 설계는 최근 아주 중요하게 연구되고 있다.
부하 밸런싱 (Load Balancing)
클라우드 데이터 센터는 이메일, 검색, 비디오 같은 여러 응용 프로그램 서비스를 동시에 제공하기 위해 존재하며, 공개 IP 주소를 통해 외부 클라이언트들로부터 요청을 받고, 이를 처리한다.
외부 클라이언트의 요청들은 제일 먼저 부하 밸런서(Load Balancer)에게 보내지고 호스트들에게 호스트 부하를 고려하여 분산되어 전해진다.
거대한 데이터 센터에는 여러개의 부하 밸런서가 특정 클라우드 서비스에 소속되어 존재하며, 부하 밸런서는 목적지 포트 번호와 IP 주소를 이용해 특정 호스트에게 포워딩하므로 “4 계층(전달 계층) 스위치(layer-4 switch)”라고도 불리운다.
단순 성능 뿐만 아니라 NAT와 비슷하게 외부 IP 주소에 따라 특정 호스트로 연결해주거나 아니면 그 반대의 역할을 수행할 수 있으며, 이를 통해 높은 보안과 클라이언트가 직접 호스트와 연결되거나 내부 구조를 파악하는 행동 방지 등이 가능하다.
계층적 구조 (Hierarchical Architecture)
작은 규모의 데이터센터와 달리 큰 규모의 데이터 센터는 쉬운 확장과 효율적인 연결을 위해 계층적 구조(Hierarchical Architecture)로 만들 수 있다.
경계 라우터(Border router)가 각각 접근 라우터(access rotuer)들과 연결되고, 각 접근 라우터들은 Top-tier 스위치와, Tier-1 스위치는 그아래 Tier 2 스위치와 연결되는 식으로 반복하여 계층 구조를 만든다.
- 이때 부하 밸런서(load balancer)는 TOR 스위치와 함께 Tier-2 스위치에 붙는다.
모든 연결들은 보통 이터넷과 물리 계층 프로토콜로 만들어졌으며, 라우터에 원하는 규모의 특정 티어 스위치를 추가하는 것으로 쉽게 스케일링할 수 있다.
가동율을 높이기 위해 계층적 구조 이외의 추가적인 연결을 다른 라우터와 만들기도 하고, ARP 브로드캐스트 트래픽을 고립시키기 위해 각 서브넷은 추가로 여러 수백 호스트 규모의 VLAN 서브넷으로 나뉜다.
하지만 이런 구조는 하위의 호스트들이 동시에 통신을 시작하면 호스트간 전송 능력이 제한되는 문제가 발생하는데, 예를 들면 figure 6.30 Tier-2 스위치 A 하의 호스트들과 Tier-2 스위치 C 하의 호스트들이 동시에 수많은 패킷을 서로 교환하면 링크 AB와 링크 AC가 붐비게 된다.
이러한 문제를 막기 위해 다음과 같은 방법이 있는데
-
고성능 스위치와 라우터, 링크로 교체하기 X
이는 비용이 비싸지고 관리가 어려우며, 교체에 힘이 든다는 단점이 있다.
-
호스트간 패킷 교환이 많은 관련 서비스별 호스트들이나 데이터별 호스트들을 지리상, 라우터 홉상 가까운 위치에 모아놓기 X
이는 데이터 센터 서비스의 유연성을 저해할 수 있다. 예를 들어 사용자들의 가상 머신 서비스를 돌리는 호스트들을 같은 서비스로 구분해 모아놓으면, 해당 데이터센터와 지정학적으로 먼 사용자들에게는 성능 저하가 일어날 것이다.
-
스위치 간의 연결성을 증가시킨다. O
figure 6.31처럼 자신의 바로 직속 스위치들과의 연결 뿐만 아니라 다른 스위치들과의 연결을 추가시켜 네트워크의 역량과 신뢰성을 모두 올릴 수 있다.
페이스북의 경우 각 TOR 스위치는 다른 4개의 tier-2 스위치와 연결하도록 되어있고, 각 tier-2 스위치는 다른 tier-1 스위치와 연결되도록 하고 있다.
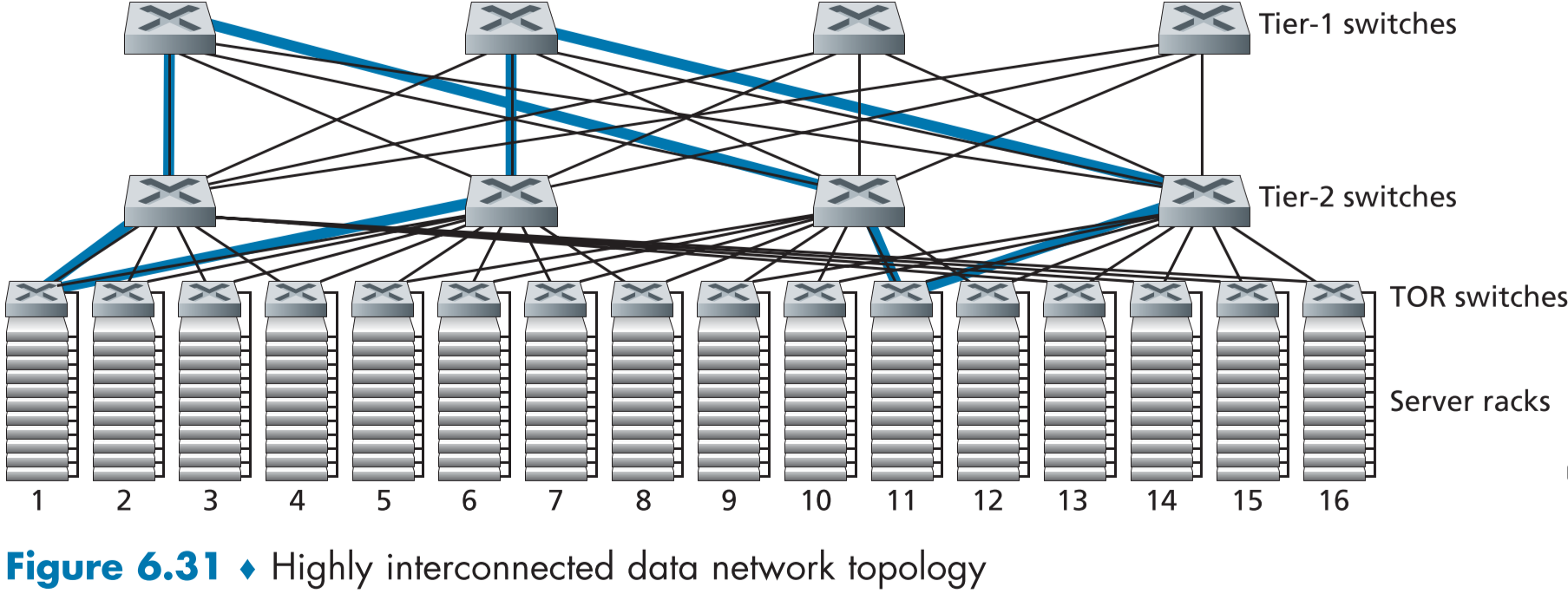
스위치간 연결성을 증대시킬 시, 다중 경로 라우팅(multi-path routing)이 정말 중요한 프로토콜이 된다.
보통 다중 경로 라우팅 프로콜들은 플로우(흐름, flow) 별로 여러 경로를 설정할 수 있게 하며,예시를 들자면
ECMP(동비용 다중 경로, Equal Cost Multi Path) [RFC 2992]는 무작위로 다음 홉의 스위치를 골라서 다중 경로를 생성한다.
세분화된 부하 밸런싱을 이용해 다중 경로 생성이 가능하다.[Alizadeh 2014; Noormohammadpour 2018]
플로우 수준이 아니라 같은 플로우 내의 다른 패킷들을 각각 다른 경로로 보내는 방법도 연구 중이다.[He 2015; Raiciu 2010]
6.6.2 데이터 센터 네트워크의 트렌드 (Trends in Data Center Networking)
데이터 센터 네트워크는 비용 절감, 가상화, 물리적 제한, 모듈성, 커스터마이제이션을 위해 빠르게 진화하고 있다.
비용 절감 (Cost Reductioin)
비용과 지연 시간 절감과 처리율, 확장성, 배포의 향상을 위해 회사 개인, 또는 오픈소스로 많은 데이터 센터 네트워크 설계가 연구되고 있다.
앞서 figure 6.31에서 배웠던 계층 구조내 스위치 간 고연결성을 이룩한 데이터 센터 네트워크는 크로스바, 또는 망형 구조의 라우터와 비슷한 원리로 구현되며, 다중 경로 라우팅으로 인한 성능과 신뢰성 증대가 장점이다.
이러한 구조는 많은 량의 작은 스위치들의 상호연결로 이루어지며, 거대기업들이 자주 사용하며 구조 전체가 세트로 하나의 장치로써 팔리기도한다.
다중 스위치 계층 상호연결 구조는 과거 전화 연결 스위칭을 연구하던 Charles Clos의 이름을 따 Clos 네트워크라고도 불리우며, 데이터 센터 네트워크와 다중프로세서 상호 연결 네트워크에서 계속 연구되고, 사용되고 있다.
중앙화된 SDN 제어와 관리 (Centralized SDN Control and Management)
데이터 센터 네트워크는 주로 거대 기업에서 중앙집중식으로 관리되기 때문에 SDN 형태의 논리적 중앙화된 제어가 연구되고 있다.
앞서 우리가 SDN에서 배웠던 것처럼, 소프트웨어 기반 중앙 통제와 경로 계산을 하는 컨트롤 측면과, 개개의 상용 스위치의 라우팅을 의미하는 데이터 측면으로 나누는 구조를 가지고 있으며, 데이터 센터들의 거대한 스케일로 인해 자동화된 설정과 운영 상태 관리도 중요하다.
가상화 (Virtualization)
가상화는 가상 머신(VM, Virtual Machine)을 이용해 소프트웨어를 물리적인 한계에서 벗어나 좀더 유연하고 관리가 편한 네트워크를 생성할 수 있다.
물리적으로 떨어져 위치한 서버 사이에 VM을 이동시키거나, 전체 네트워크를 하나의 레이어로 보는 등의 일이 가능하다.
물리적 제한 (Physical Constraints)
데이터 센터 네트워크는 인터넷과 달리 강력한 성능과 낮은 지연을 가지고 있으므로, 버퍼 크기 같은 기존의 하드웨어 설정과 TCP 혼잡 제어 같은 기존의 프로토콜이 잘 맞지 않을 수 있다.
데이터 센터에서는 혼잡 제어 반응 속도가 빠르고, 낮은 손실하에 진행되어야 하며, 타임 아웃이나 fast-recovert 같은 상태는 비효율적일 이다.
이를 위해 TCP 프로토콜에서 파생된 전용 프로토콜이나 RDMA(원격 직접 메모리 접근, Remote Direct Memory Access) 기술 등이 연구되고 있다.
스케쥴링 또한 적용되어 흐름 스케듈링과 전송율 제어가 분리되어 간단하게 흐름 제어를 함과 동시에 높은 가동율을 달성할 수 있다.
하드웨어 모듈성과 커스터마이제이션 (Hardware Modularity and Customization)
운송용 컨테이너 기반 모듈형 데이터 센터(MDC, modular data center)는 12 미터 길이의 운송용 컨테이너에 십여개의 랙, 수천개의 호스트가 들어가 있는 공장 생산 소형 데이터센터이다.
여러 MDC를 연결에 추가 및 제거하는 것으로 스케일링 할 수 있으며, MDC는 기기 이상으로 네트워크 성능이 저하됬을 때를 감지하여 연산량을 줄이거나, 제거되는 기능을 갖추었다.
수많은 컨테이너를 중심 네트워크에 연결하는 것 이외에도 컨테이너 내의 수천 호스트를 서로 연결하는 것은 힘들일이고 많은 연구가 진행되고 있다.
또한 각 데이터 센터마다, 스위치, 어뎁터, TOR, 프로토콜, 소프트웨어를 실정에 맞게 커스터마이징하는 것 또한 트랜드이다.
예를 들어 아마존은 신뢰성을 늘리기 위해 사용 가능 지역이라는 수 키로 떨어져있는 빌딩에 데이터센터를 복제한 듯한 데이터센터를 이용해 시스템 장애와 성능 이슈에 대항하고 있다.
6.7 회고 : 웹 페이지 요청의 하루(Retrospective: A Day in the Life of a Web Page Request)
이제 이 책의 프로토콜 스택에 대한 이야기는 끝났으며, 전체적이고 집약된 프로토콜의 정리를 보기 위해 예시 시나리오를 만들어서 설명해보자.
Figure 6.32는 학생이 학교의 이터넷에 노트북으로 접속한 뒤, 웹페이지를 요청하는 시나리오이다.
6.7.1 시작하기 : DHCP, UDP, IP, 이터넷(Getting Started: DHCP, UDP, IP, and Ethernet)
학생은 이터넷 케이블을 통해 학교의 이터넷 스위치에 접속하고, 이 스위치는 DHCP 서버를 겸하고 있는 학교 라우터를 거쳐 ISP comcast와 연결되어 있으며, comcast.net은 자신의 네트워크로 학교에 DNS 서버와 DNS 서비스를 제공한다고 가정하자.
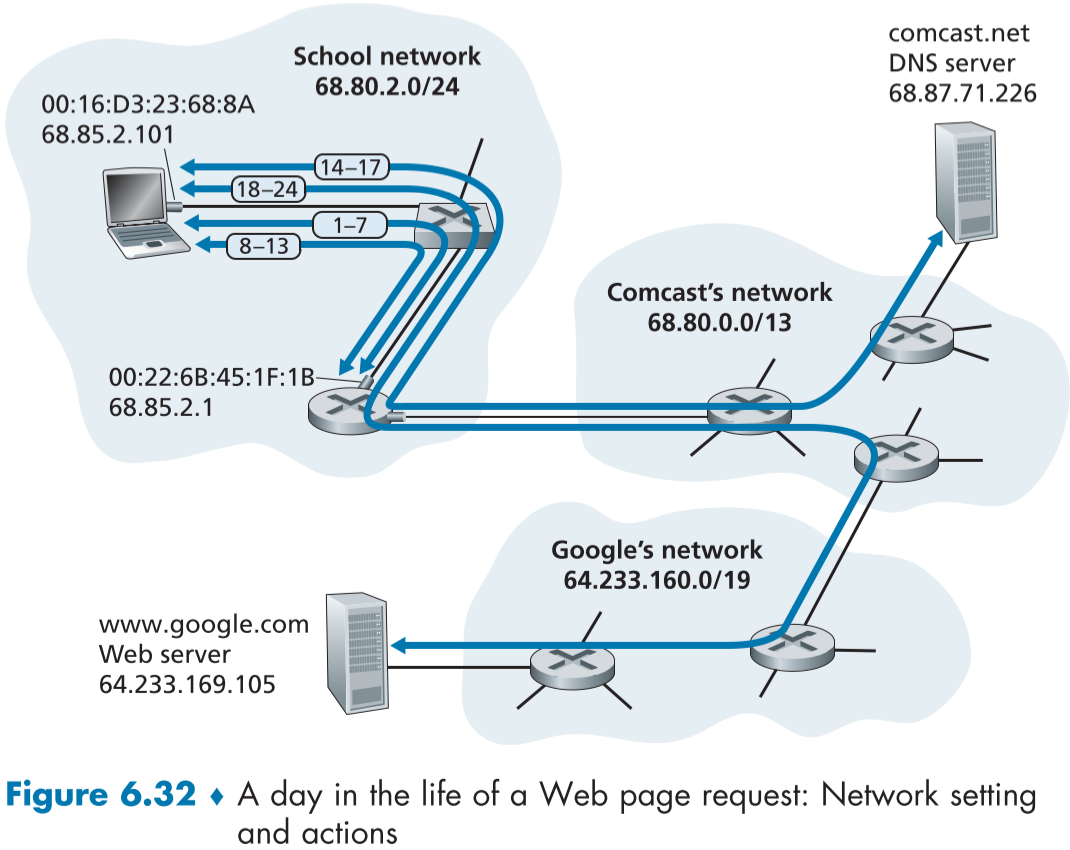
먼저 학생은 IP 주소를 얻기위해 DHCP 프로토콜을 돌리게 된다.
-
이터넷 케이블을 꽂은 뒤, 학생의 노트북의 운영체제가 DHCP 요청 메시지를 생성하고, UDP 세그먼트에 집어넣은 후, IP 데이터그램으로 캡슐화한다.
IP 데이터그램의 address 필드는 출발지의 경우 IP 주소 0.0.0.0, 포트 번호 68, 목적지의 경우 IP 주소 255.255.255.255,포트 번호 67 이다.
-
DHCP 요청 메시지가 담긴 IP 데이터그램이 이더넷 프레임에 캡슐화된 후, 목적지 MAC 주소를 FF:FF:FF:FF:FF:FF로 놓아 스위치에 연결된 기기들 모두에게 브로드캐스트되도록 한다. 출발지 주소는 학생의 노트북 MAC 주소이며, 여기서는 00:16:D3:23:68:8A로 가정한다.
-
브로드캐스트 된 이터넷 DHCP 요청 프레임이 스위치에 도착하면 스위치는 해당 프레임을 복사하여 학교 라우터가 연결된 포트를 포함해 모든 나가는 포트에 뿌린다.
-
라우터는 DHCP 요청 메시지가 들어있는 이더넷 프레임을 라우터 인터페이스(MAC 주소 00:22:6B:45:1F:1B)로 받고, IP 주소를 추출한다.
브로드캐스트 IP이므로 라우터는 해당 데이터그램을 디멀티플렉스하여 세그먼트로 만든 뒤,
UDP 프로토콜에 보내고, DHCP 서버는 세그먼트 내의 요청 메시지를 확인한다.
-
DHCP 서버가 Comcast ISP 측에게 할당 받은 IP 주소 범위의 CIDR 표현은 68.85.2.0/24이며, 68.85.2.101을 학생의 노트북에 할당하기로 했다.
DHCP 서버는 할당할 IP 주소(68.85.2.101), DNS 서버 주소(68.87.71.226), 기본 게이트웨이 라우터(68.85.2.1, 현재 DHCP 서버가 존재하는 라우터이기도 하다.), 서브넷 범위(68.85.2.0/24, 또는 네트워크 마스크) 정보들이 들어가 있는 DHCP ACK 메시지를 생성 뒤,
UDP 세그먼트와 IP 데이터그램, 이터넷 프레임으로 차례차례 캡슐화 하고, 출발지 MAC 주소는 라우터의 주소(00:22:6B:45:1F:1B), 목적지 MAC 주소는 학생의 노트북 주소 (00:16:D3:23:68:8A)로 지정한다.
-
DHCP ACK 메시지를 포함한 이터넷 프레임은 유니캐스트(unicast, 1:1 통신)를 통해 라우터에서 스위치로 전달되고,
스위치는 이전 학생이 보낸 DHCP 요청 메시지로 이미 노트북의 주소를 자가학습(self-learning)하였으므로, DHCP ACK 이터넷 프레임을 00:16:D3:23:68:8A로 향하는 나가는 포트로 보낸다.
-
학생은 DHCP ACK 이터넷 프레임을 받고 페이로드 추출을 반복하여 DHCP 메시지 내의 정보(할당 받은 IP 주소, DNS 서버 주소 등)을 기록하고, IP 포워드 테이블에 기본 게이트웨이 주소를 등록한다.
이제 노트북이 보낼 서브넷(68.85.2.0/24) 바깥이 목적지인 데이터그램은 모두 기본 게이트웨이 라우터로 향할 것이다.
(DHCP 4 단계 중 마지막 2단계는 생략됨.)
6.7.2 계속 시작하기 : DNS와 ARP (Still Getting Started: DNS and ARP)
이제 학생이 www.google.com 을 웹 브라우저에 입력하면, 브라우저에 화면이 나타날 때까지 많은 일이 생기게 된다.
먼저 브라우저는 TCP 소켓을 형성해서 HTTP 요청 메시지를 www.google.com으로 보내야 하며, TCP 소켓을 생성하기 위해서는 도메인명 www.google.com에 대응하는 IP 주소가 필요하며, 이는 DNS 프로토콜을 통해 변환 가능하다.
-
학생의 노트북의 운영체제가 DNS 쿼리 메시지를 생성하고, DNS 메시지의 question 부문에 www.google.com이 입력된다.
DNS 메시지는 이후 목적지 포트 번호를 53번(DNS 서버 포트번호)으로 설정한 UDP 세그먼트에 캡슐화되고
목적지 IP 주소를 68.87.71.226(DNS 서버 주소), 출발지 IP 주소를 68.85.2.101(할당 받은 IP 주소)로 설정한 IP 데이터그램에 캡슐화 된다.
-
DNS 쿼리 메시지가 담긴 데이터그램을 이터넷 프레임에 캡슐화하고, 서브넷의 게이트웨이 라우터로 보내야 하는데, 게이트웨이 라우터의 IP 주소(68.85.2.1)만 알고 MAC 주소는 모르므로, ARP 프로토콜을 통해 IP 주소로 MAC 주소를 가져와야 한다.
-
노트북의 어뎁터 내부의 ARP 모듈이 target IP 주소가 기본 게이트웨이 IP 주소(68.85.2.1)인 ARP 쿼리 메시지를 생성한다.
ARP 쿼리 메시지는 브로드 캐스트 주소(FF:FF:FF:FF:FF:FF)로 설정된 이터넷 프레임으로 캡슐화 된 뒤 스위치로 보내지면,
게이트웨이 라우터를 포함한 서브넷 내부의 모든 호스트에게 프레임이 전달된다.
-
게이트웨이 라우터가 ARP 쿼리 메시지가 담긴 프레임을 받고, ARP 메시지의 target IP 주소가 자신의 IP 주소(68.85.2.1)와 일치함을 확인한 게이트웨이 라우터의 ARP 모듈은 ARP reply 메시지를 준비한다.
ARP reply 메세지에는 target IP 주소(68.85.2.1)의 MAC 주소가 00:22:6B:45:1F:1B 임이 적혀있다.
ARP reply는 프레임에 캡슐화되서 노트북의 MAC 주소(00:16:D3:23:68:8A)로 보내진다.
-
노트북은 받은 프레임에서 ARP reply 메시지를 추출하고, 게이트웨이의 MAC 주소를 알아낸다.
-
이제 학생의 노트북은 DNS 쿼리 메시지가 담긴 데이터그램을 게이트웨이 MAC 주소가 담긴 프레임으로 캡슐화하고, 스위치를 지나 게이트웨이 라우터로 보낸다.
이때, 데이터그램의 IP 주소는 위 8번에 적었음을 상기하자.
6.7.3 계속 시작하기 : DNS 서버를 향한 도메인 내부 라우팅 (Still Getting Started: Intra-Domain Routing to the DNS Server)
-
게이트웨이 라우터는 DNS 쿼리 메시지가 담긴 IP 데이터그램을 받은 프레임으로 부터 추출한다.
추출한 IP 데이터그램의 목적지 주소(DNS 서버 주소)를 살펴보고 포워딩 테이블과 대조하여 Comcast 네트워크의 말단(leftmost)의 라우터에 보내기 위해 해당 라우터와 연결 경로에 연결되어 있는 나가는 링크에 라우팅 해준다.
-
Comcast 네트워크의 말단 라우터는 프레임을 받고 거기서 IP 데이터그램을 추출한 뒤, 목적지 주소인 DNS 서버 주소를 확인하고, 포워딩 테이블과 대조하여 Comcast 내부의 DNS 서버 쪽으로 라우팅 해준다.
이때, 포워딩 테이블은 Comcast의 도메인 내부(intra-domain) 프로토콜(IP, OSPF, ISIS 등)과 도메인간(inter-domain) 프로토콜(BGP)을 이용해 채워넣었다.
-
DNS 서버에 DNS query 메시지가 담긴 패킷이 도착하면, DNS 서버는 역시 패킷에서 DNS 쿼리 메시지를 꺼내 www.google.com을 DNS 데이터베이스에서 찾아보기 위해 DNS 자원 기록(DNS RR, DNS resource record)을 찾아본다.
이 정보는, 이미 Comcast의 DNS 서버에 캐싱되어 있었고, 캐싱 되지 않았으면 구글의 authoritative DNS 서버에서 RR을 얻어야 했다.
캐싱된 결과에서 www.google.com의 IP 주소(64.223.169.105)를 알아내고, DNS 서버는 DNS reply 메시지에 호스트명과 IP 주소 맵핑 정보를 넣고 UDP 세그먼트, IP 데이터그램에 캡슐화하고, 노트북의 주소를 목적지 주소로 설정하고 라우터를 통해 보낸다.
-
DNS 서버가 보낸 DNS reply 메시지가 담긴 패킷이 학생의 노트북에 도착하면, 노트북은 해당 DNS reply 메시지를 추출하고, reply 메시지에 적힌 정보로부터 www.google.com의 IP 주소를 얻어올 수 있다.
6.7.4 웹 클라이언트-서버 상호작용: TCP와 HTTP (Web Client-Server Interaction: TCP and HTTP)
-
학생의 노트북은 이제 구글 IP 주소를 통해 TCP 소켓을 형성할 수 있다. TCP 소켓을 생성하려 하면 노트북 내의 TCP 프로토콜이 three-way handshake를 www.google.com 측과 진행한다.
먼저 TCP SYN 세그먼트를 웹서버 포트인 80번 포트를 목적지 포트로 설정하고 생성한 뒤, 목적지 IP 주소가 64.233.169.105 (www.google.com)인 IP 데이터그램 내부에 캡슐화한다. 이후 목적지 MAC 주소가 00:22:6B:45:1F:1B (게이트웨이 라우터)인 프레임으로 캡슐화해서 스위치로 보낸다.
-
TCP SYN 데이터그램이 학교 네트워크, Comcast의 네트워크, 구글의 네트워크를 거쳐 www.google.com에 도착한다.
이때, 네트워크 간의 경로 정보를 담은 포워딩 테이블은 BGP 프로토콜에 의해 생성되었다.
NAT 부분은 생략되었으나, 정확히는 패킷의 출발지 주소가 학교의 라우터로 바뀌었고, 대신 포트번호를 따로 할당받았을 것이다
-
결국 TCP SYN이 담긴 데이터그램은 www.google.com에 도착한 후, TCP SYN 메시지가 패킷으로부터 추출된 후, 구글 서버의 80번 포트에 존재하는 환영 서버로 디멀티플렉스된다.
이후, 구글 HTTP 서버와 학생의 노트북 사이에 TCP 연결을 위한 연결 소켓이 생성된 후, 응답을 위한 TCP SYNACK 세그먼트가 생성되어 IP 데이터그램, 연결 계층 프레임(이때의 MAC 주소는 학생 노트북이 아니라 해당 네트워크의 말단 라우터의 MAC 주소이다.)으로 캡슐화 된다.
-
TCP SYNACK 세그먼트가 구글, Comcast, 학교 네트워크 들을 거쳐 학생 노트북의 이더넷 컨트롤러에 도착하면, 운영체제에 의해 디멀티플렉싱 되어 생성해놨던 TCP 소켓으로 들어가 연결 상태를 만든다.
-
이제 학생의 노트북의 브라우저는 패치(fetch)할 www.google.com에 대한 HTTP GET 요청 메시지를 만들어 소켓으로 보내지고, TCP 세그먼트로 캡슐화된다. 이후 18번의 데이터그램 캡슐화 부터 20번의 구글 웹 서버 도착까지의 과정을 답습한다.
-
구글의 HTTP 서버가 HTTP GET 메시지를 TCP 소켓으로 부터 읽고 난 뒤, HTTP 응답 메시지를 만들고 응답 메시지의 body에 요구한 웹 페이지의 컨텐츠를 넣어준 뒤 TCP 소켓의 연결을 통해 보낸다.
-
노트북의 TCP 소켓으로 다시 되돌아온 HTTP 응답 메시지 패킷에서 HTTP 응답 메시지를 추출한 뒤, html과 컨텐츠를 메시지 body로부터 가져와 브라우저가 화면상에 표시해준다.
학교 라우터의 NAT, 학교 네트워크로의 무선 접근, 보안 프로토콜, 네트워크 관리 프로토콜 등은 생략되었고, 웹 캐싱이나 DNS 계층 같은 미들박스들도 생략되었다.
_articles/computer_science/network/네트워크 정리-Chap 6-연결 계층과 LAN.md