풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
네트워크 정리-Chap 5-네트워크 계층-컨트롤 측면
Chapter 5. 네트워크 계층: 컨트롤 측면(Network Layer: Control plane)
- 5.1 소개(Introduction)
- 5.2 라우팅 알고리즘 (Routing Algorithms)
- 5.3 인터넷에서의 AS 내부 라우팅 : OSPF (Intra-AS Routing in the Internet: OSPF)
- 5.4 ISP 간의 라우팅 : BGP (Routing Among the ISPs: BGP)
- 5.5 SDN 컨트롤 측면 (The SDN Control Plane)
- 5.5.1 SDN 컨트롤 측면 : SDN 컨트롤러와 SDN 네트워크 컨트롤 응용 프로그램(The SDN Control Plane: SDN Controller and SDN Network-control Applications)
- 5.5.2.오픈플로우 프로토콜(OpenFlow Protocol)
- 5.5.3.데이터와 컨트롤 측면 상호작용: 예제(Data and Conrol Plane Interaction: An Example)
- 5.5.4 SDN: 과거와 미래(SDN: Past and Future)
- SDN 컨트롤러 예시 (SDN CONTROLLER CASE STUDIES: THE OPENDAYLIGHT AND ONOS CONTROLLERS)
- 5.5.1 SDN 컨트롤 측면 : SDN 컨트롤러와 SDN 네트워크 컨트롤 응용 프로그램(The SDN Control Plane: SDN Controller and SDN Network-control Applications)
- 5.6 ICMP: 인터넷 컨트롤 메세지 프로토콜 (ICMP: The Internet Control Message Protocol)
- 5.7 네트워크 관리와 SNMP, NETCONF/YANG (Network Management and SNMP, NETCONF/YANG)
- 5.7.1. 네트워크 관리 프레임워크(The Network Management Framework)
- 5.7.2.간단 네트워크 관리 프로토콜(SNMP, Simple Network Management Protocol)와 관리 정보 베이스(MIB) (The Simple Network Management Protocol(SNMP) and the Management Information Base (MIB, Management Information Base))
- 5.7.3.네트워크 설정 프로토콜(NETCONF)과 YANG(The Network Configuration Protocol (NETCONF) and YANG)
- 5.7.1. 네트워크 관리 프레임워크(The Network Management Framework)
Computer Networking: A Top-Down Approach(Jim Kurose, Keith Ross)의 강의를 정리한 내용입니다.
( Jim Kurose Homepage )student resources : Companion Website, Computer Networking: a Top-Down Approach, 8/e
컨트록 측면에서는 최소 비용 경로를 구하는 두가지 알고리즘 OSPF, BGP를 배울 것이다.
OSPF는 단일 ISP 네트워크 내부에서, BGP의 경우 모든 인터넷 내의 네트워크를 연결하기 위한 라우팅 알고리즘이다.
보통 컨트롤 측면의 라우팅 알고리즘은 라우터 내에서 데이터 측면의 포워딩 함수와 함께 구현됬지만, 이전 장에서 배운 소프트웨어 정의 네트워크(SDN, software-defined networking) 이후로, 컨트롤 측면의 컨트롤러와 데이터 측면의 포워딩 함수를 물리적으로 구별하게 되었다.
또한 ICMP(Internet Contro노드는l Message Protocol)과 SNMP(Simple Network Management Protocol)에 대해서도 배울 것이다.
5.1 소개(Introduction)
우리는 이전 장의 데이터 측면에서 포워딩 테이블(forwarding table)과 플로우 테이블(flow table)을 이용해 라우터에서의 포워딩을 포함해 다른 패킷의 활동을 실행하는 것에 대해서 배웠다.
이번 장에서는 어떻게 그러한 포워딩 테이블과 플로우 테이블이 계산되고, 유지되고, 설치되는지 배워볼 것이며, 크게 두가지가 있다.
-
라우터별 조정 (Per-router control)
아래의 fig.5.1의 그림은 각 라우터 마다 라우팅 알고리즘이 돌아가고 있음을 표현하였다. 포워딩과 라우팅 기능이 둘다 라우터에서 존재하며, 각 라우터는 다른 라우터의 라우팅 구성품과 통신하여 포워딩 테이블을 만들 수 있는 라우팅 구성품이 들어가 있다. 우리가 배울 OSPF와 BGP 프로토콜의 기반 방법이며, 지난 몇 십년간 사용된 방법이다.
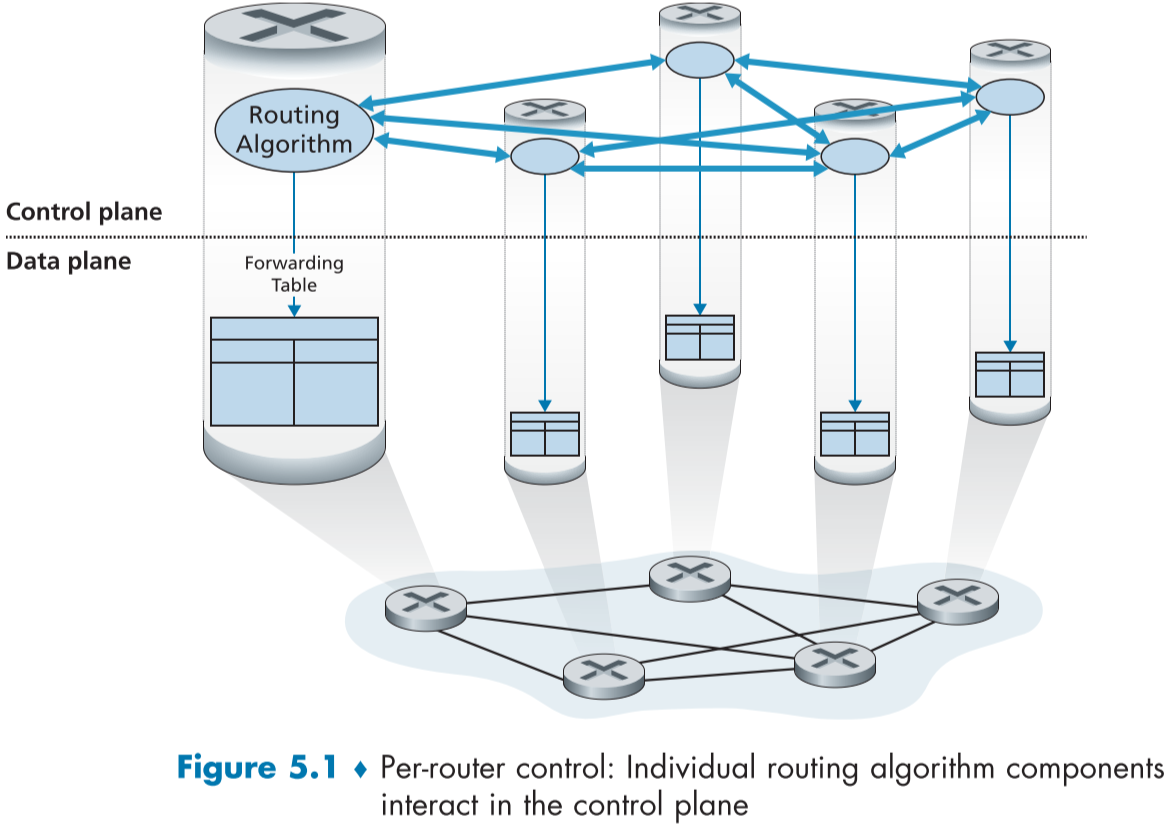
-
논리적 중앙화된 조정 (Logically centralized control)
아래 fig.5.2는 논리적 중앙화된 컨트롤러가 각 라우터가 사용할 포워딩 테이블을 계산하고 분배하는 그림을 표현했다.
이전에 배웠듯이 일반화된(generalized) match-plus-action 추상화는 전통적인 아이피 포워딩 뿐만 아니라 미들박스를 이용해 부하 밸런싱, 방화벽, NAT 같은 다른 기능을 제공할 수 있다고 배웠으며, 이 방법에 속한다.
여기서는 CA(Control agent)가 미리 정의된 프로토콜로 원격의 컨트롤러와 통신하며 라우터 내부의 플로우 테이블을 설정하고 관리한다. 보통 CA는 컨트롤러와 통신하는 정도의 최소한의 기능을 가지며, 다른 라우터와 통신하고 포워딩 테이블을 계산하는 등의 일을 하지 않는다. 이는 위에서 설명한 라우터별 조정과의 가장 큰 차이이다.
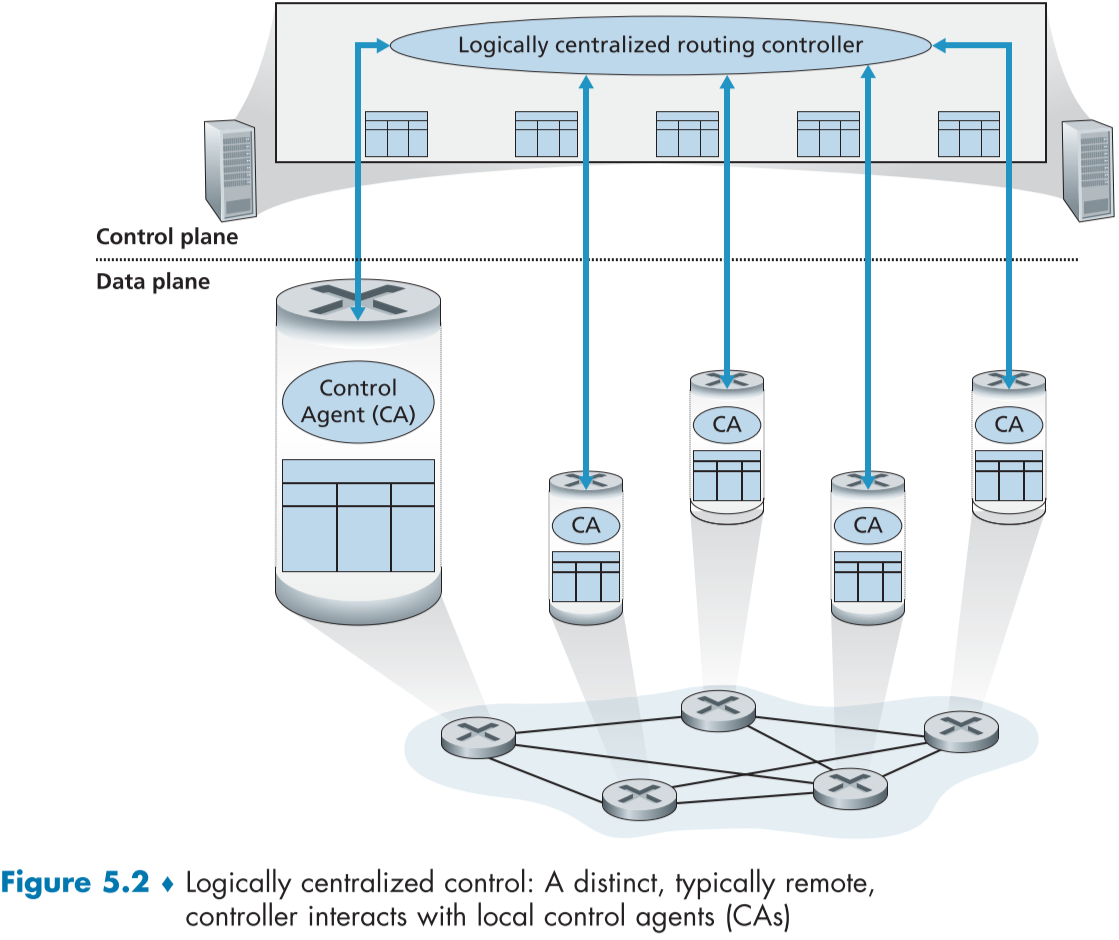
논리적 중앙화된 컨트롤은 라우팅 컨트롤 서비스가 마치 하나의 중앙화된 서비스 지점으로 표현되어 다른 라우터들이 해당 단일 지점에 접근해서 서비스를 이용하여 붙여진 이름이다.
- 실제로 원격 컨트롤러는 단일 지점 실패 방지와 부하 밸런싱, 스케일링의 이유로 여러 서버에 구현될 것이다.
우리가 배울 SDN(software-defined network)이 논리적 중앙화의 개념을 받아들여 구글 사설망, 마이크로소프트 연구용 망, 여러 ISP 등에서 SDN이 널리 퍼지고 있다.
5.2 라우팅 알고리즘 (Routing Algorithms)
라우팅 알고리즘의 목표는 송수신자 사이의 좋은 경로를 찾는 것으로, 네트워크에서 아주 중요한 개념이다. 여기서 좋은 경로는 주로 비용을 의미하지만, 실제 세계에서는 단순히 비용 뿐만아니라, 특정 라우터의 경로 설정 정책(특정 포트에서 온 패킷은 접근 불가, 패킷 우선 순위 등), 라우팅 방식(라우터별 접근 방법인가, 논리적 중앙화된 접근 방법인가?) 등을 살펴보고, 이를 통해 최적의 경로를 찾아야 한다.
이러한 라우팅 문제를 표현하기 위해 그래프(graph)를 이용한다. 그래프 $G=(N,E)$는 N개의 노드와 E 개의 노드 간의 경로, 엣지의 모임으로 된 그래프를 의미한다.
여기서 노드는 라우터를, 엣지는 라우터 간의 물리적 링크를 의미한다.
위에서 설명한 네트워크의 연결에 대한 알고리즘인 BGP의 경우, 조금 다르게 노드는 ISP 등의 네트워크, 엣지는 이 네트워크 간의 연결성(connectivity, 정확히는 피어링(peering))로 표현된다.
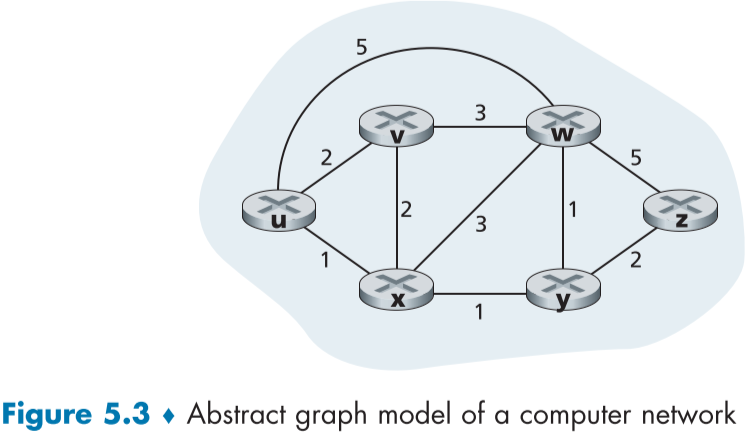
fig.5.3에서의 엣지 위의 숫자는 비용을 의미하며, 보통 물리적 링크의 길이에 의한 성능 저하를 의미하지만, 실제로는 이외에도 링크의 성능, 금전적인 비용 등을 고려해야한다. 하지만 우리는 비용의 의미를 크게 관심 두지 않고, 값을 이용할 것이다.
또한 표현 적으로 노드 x와 노드 y 사이의 엣지(링크)를 (x,y)로 놓고, 이 엣지의 비용을 c(x,y)라고 표현할 것이며, 만약 x와 y 간에 연결이 없다면 c(x,y) = $\infty$이다. 방향성이 없는 그래프로 가정할 것이므로 (x,y) = (y,x)이고, 비용도 동일하다. x와 y를 연결하는 엣지가 존재할 때, x와 y는 서로의 이웃 노드라고 표현한다.
그리고 우리의 목적은 시작 노드부터 끝 노드까지 비용의 합이 최소가 지나갈 엣지의 집합과 노드의 순서를 찾는 것이며, 이를 최소 비용 경로(least-cost path)라고 부르자.
또한, 모든 엣지의 비용이 같을 때는, 이는 지나가는 노드가 가장 적은 최단 경로(shortest path)이기도 할 것이다.
라우팅 알고리즘은 중앙화(centralized)와 분산화(decentralized)된 알고리즘으로 나누며 이 둘을 나누는 방법은 크게 세가지다.
먼저, 첫번째는
-
중앙화된 라우팅 알고리즘(centralized routing algorithm)은 노드간의 최단거리를 구하기 위해서 가능한 모든 경로의 경우의 수를 따져서 그 중 최솟값을 취한다. 즉, 모든 노드의 연결상태와 엣지들의 비용을 알고 있어야하며, 네트워크 상태가 바뀌지 않는 이상 한번만 계산해서 저장하며, 논리적 중앙화된 컨트롤러가 해당 결과를 가지고 있거나, 아니면 복사해서 각 라우터에 뿌려준다.
이러한 전역 상태 정보가 필요한 알고리즘을 연결 상태(link-state, LS) 알고리즘이라고 한다.
-
분산화된 라우팅 알고리즘(decentralized routing algorithm)의 경우, 최소 비용 경로를 구할 시, 라우터들이 서로 반복적이고(iterative) 분산된 방법으로 구한다. 각 노드는 자기 자신과 연결된 엣지 비용 정보만 알고 있고, 이 정보들을 이웃 노드 간에 서로 정보 교환하며 자기 자신과 나머지 노드간의 예상 최소 경로와 비용의 벡터(vector)를 저장해 놓는다. 이러한 전역 정보가 필요없고, 주변 노드와 반복적인 정보 교환을 통해 정답을 만드는 알고리즘을 거리 벡터(distance-vector, DV) 알고리즘이라고 한다. 보통 라우터별(per-router) 조정처럼 노드 간 메시지 교환이 활발한 구조에서 사용한다.
라우팅 알고리즘을 구분하는 두번째 방법은 정적(static)과 동적(dynamic)으로 나뉜다.
정적 라우팅 알고리즘(static routing algorithms)은 경로의 정보가 아주 드물게 바뀌는 경우이며, 동적 라우팅 알고리즘(Dynamic routing algorithm)은 경로의 정보의 트래픽 부하 상태나 배치가 계속 바뀌는 경우를 의미하며, 주기적으로나 변화가 감지될 때마다 재계산한다.
- 동적 라우팅 알고리즘(Dynamic routing algorithm)은 그래서 네트워크의 변화, 라우팅 루프(routing loop), 루트 진동(route oscillation) 등에 취약하다.
마지막 세번째 방법은 부하 민감(load-sensitive)과 부하 둔감(load-insensitive)으로, 부하 민감 알고리즘(load-sensitive algorithm)은 링크의 비용이 현재 네트워크 혼잡 상황을 반영해 자주 바뀌며, 혼잡한 회선을 우회하는 등의 경향이 있다. 과거 ARPAnet 등, 초기의 네트워크에 자주 사용되었지만 여러 문제가 있어 사용하지 않고 최신의 인터넷 라우팅 알고리즘들(RIP, OSPF, BGP 등..)은 부하 둔감 알고리즘(load-insensitive algorithm) 이며, 현재 네트워크 혼잡도에 민감하게 반응하지 않는다.
5.2.1.연결 상태(LS) 알고리즘 (The Link-State (LS) Routing Algorithm)
LS 알고리즘은 전역 네트워크 상태를 알아야 하며, OSPF 라우팅 알고리즘 같은 실무에서는, 연결 상태 전파 알고리즘(link-state broadcast algorithm)을 통해 각 노드가 다른 모든 노드들에게 연결 상태(link-state) 패킷을 전파(broadcast)하여 네트워크 전역 정보를 얻고, 자신과 다른 노드간의 최소 비용 경로를 계산한다. 이때 연결 상태 패킷에는 노드의 식별자와 주변 이웃 노드와 연결된 링크의 비용이 포함되어 있다.
다익스트라 알고리즘(Dijkstra’s algorithm)은 프림 알고리즘(Prim algorithm)와 연관 알고리즘으로, 연결 상태 알고리즘 중 하나이며, 시작지점으로 놓을 시작 노드를 선정하고 다른 노드간의 거리를 무한대로 산정한(초기화(initialization) 과정)한 뒤, 전체 노드의 갯수를 k개로 생각한다면, 반복적으로 k번의 노드간의 최소비용을 갱신(반복(loop) 과정)하여 시작노드와 나머지 모든 노드들 간의 최소 비용 경로를 구할 수 있다.
시작 노드 u에서 출발하는 연결 상태(LS) 알고리즘(Link-State (LS) Algorithm for Source Node u)
시작 노드 u에서 각 노드간의 최소 거리 비용을 구하는 다익스트라 알고리즘의 pseudo code를 살펴보자.
u, v: 각각 시작 지점 노드와 현재 최소 거리 비용을 구하고 싶은 대상 노드
D(v) : 현재까지 계산된 시작 지점 u 부터 v 노드까지의 최소 비용 경로의 비용
p(v) : 최소 비용 경로에서 도착 노드(v)의 이전 노드, 즉 도착 노드의 이웃 노드
N : 모든 노드들의 집합
N`: 현재 u와의 최소 비용 경로가 계산된 노드들의 집합
/* 초기화(Initialization) 구간*/
N` = {u}
for 모든 노드 중에 노드 v
if v 노드가 u 노드의 이웃이라면
then D(v) = c(u, v)
else D(v) = 무한대
/* 반복 구간 */
N == N`일 때까지 반복:
노드 집합 N`에 존재하지 않는 노드들 중 D(w)가 가장 작은 w 선택
w 노드를 N` 집합에 추가
w의 이웃 노드이며 N`에 존재하지 않는 노드들 v들의 D(v)들을 갱신
D(v) = min(D(v), D(w) + c(w, v)) /*이전 최소 비용이거나 갱신된 최소 비용 중 작은 것으로 변경*/
아래 table 5.1은 반복 구간이 한번 반복될 때마다 step을 증가시켰을 때의 변수 값들이다.

- 초기화 단계에서 시작 지점 u와 직접 연결된 노드의 최소 거리 비용을 비용만큼으로 설정하고, 그렇지 않은 노드는 비용을 무한대로 설정한다.
- 첫번째 반복에서 최소 거리 비용이 제일 작고 ${N}’$에 포함되어 있지 않은 노드인 x를 선정해, ${N}’$집합에 포함시킨다.
- 이웃 노드 v들을 노드 x를 거쳐 지나가는 비용과 현재 설정되어있는 비용을 비교하여 작은 것으로 바꿔준다.
- 더이상 ${N}’$에 포함되지 않은 노드가 없어질 때까지 2,3을 반복한다.
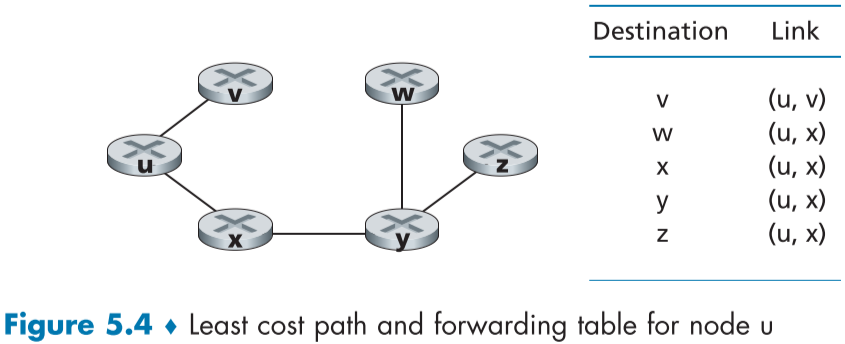
게산의 결과로 시작 노드 u로 부터 각각 노드 v까지의 경로 중 바로 이전 노드인 p(v)를 알 수 있으며, 이전 노드 p(v)를 통해 이전 노드의 이전 노드 p(p(v))도 알 수 있으므로, 이를 시작 노드 u가 나올때 까지 반복하여 최소 비용 경로를 구할 수 있다.
- p(v)는 v의 이웃 노드들 w 중 D(w)가 가장 작은 노드이다.
라우터의 포워딩 테이블의 경우 위 방법을 이용해 경로를 구한뒤, 해당 경로를 기반으로 u의 이웃한 노드의 링크(최소 비용 경로에서 자신의 다음 순서에 있는 노드 방향)로 포워딩 해주면 된다(fig.5.4 참조).
해당 알고리즘의 시간 복잡도는 노드의 갯수를 n으로 놓고 O($n^2$)이며, 만약 힙 자료구조를 이용해서 반복 구조의 최소 비용 노드를 찾는다면 O(nlogn)까지 줄일 수 있다.
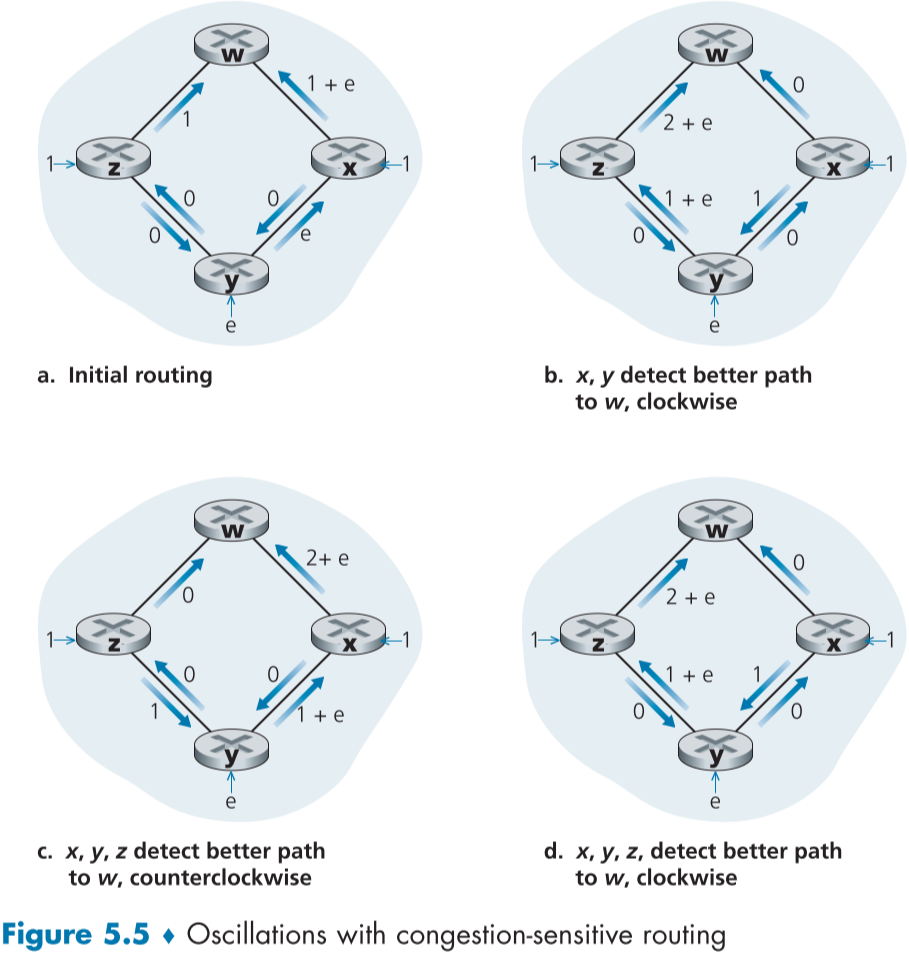
fig 5.5를 참조하기 전에 먼저 이전 가정과 달리, c(u,v)와 c(v,u)는 같지 않은걸로 가정할 것이다.
먼저 각 노드는 패킷을 전송해 링크에 부하와 트래픽을 유발하며, 라우터 z, x는 각각 1만큼, 라우터 y는 e 만큼 유발한다고 가정하자.
라우터 z,x,y 전부 라우터 w와 통신하려고 한다. 그럴 경우 시작 상태는 fig.5.5(a)처럼 될 것이다. 라우터 y가 패킷을 w로 보내며 링크 (y,x)를 택해 c(y,x)는 e, c(x,w)는 라우터 x의 트래픽에 추가로 라우터 y의 트래픽 e를 감당해야 하므로 c(x,w) = 1+e가 된 모습이다.
이후, LS 알고리즘이 실행되면, 이에 따라 fig.5.5(a)의 상황에서 비용을 판단하게 되어, 라우터 y의 시점에서는 시계 방향의 경로를 택하게 되고(1 vs 1+ 2e), 라우터 x 또한 시계 방향의 긴 길을 택하게 된다.(1 vs 1 + e), 라우터 z는 그대로 일것이다.
위의 라우팅 알고리즘에 따른 결과는 fig.5.5(b)처럼 된다. 이번에는 모든 라우터가 비용이 0인 반시계 방향으로 라우팅할 것이다. 그에 따른 비용 변화는 fig.5.5(c)처럼 될 것이다.
fig.5.5(c)에서 새로 LS 알고리즘으로 계산한 비용에 의해, 전부 시계방향으로 다시 바뀌게 되고 fig.5.5(d)처럼 되는데, 자세히 그림을 살피면 앞으로는 fig.5.5(c)와 fig.5.5(d)가 무한히 반복됨을 알 수 있다.
이러한 현상을 경로 진동(route oscillation)이라고 하며, LS 알고리즘 뿐만 아니라 지연이나 혼잡을 측정해 정보로 사용하는 알고리즘은 모두 일어나게 된다.
해결방법으로 첫번째는 트래픽 상황을 알고리즘에서 고려하지 않는 것이지만, 혼잡한 네트워크를 우회하는 것이 최소 비용 경로의 목적이므로 모순되는 방법이다.
두번째는 LS 알고리즘을 모든 라우터에서 동시에 계산하지 않게 하는 것이다. 일정 주기로 LS 알고리즘을 실행하되, 다른 시간에 시작하게 만드는게 이상적이게 보이겠지만, 실제 시뮬레이션 결과, LS 알고리즘을 돌리기 위한 라우터 간의 통신 패킷이 패킷의 지연 등으로 어느 순간부터 주기적으로 변해버려 소용이 없으며, 실제로는 각 라우터에서 랜덤한 시간에 링크 정보를 주고받게 하여 해결한다.
5.2.2. 거리 벡터(DV) 라우팅 알고리즘(The Distance-Vector (DV) Routing Algorithm)
LS 알고리즘과 달리 DV 알고리즘은 반복적(iterative)이고, 비동기적(asynchronous)이며, 분배(distributed)된 알고리즘이다.
분배적 특성은 각 노드가 직접적으로 연결된 이웃 노드와 정보를 주고 받아, 연산 결과를 다시 이웃들에게 분배하기 때문에 붙여졌으며,
반복적 특성은 이웃 간에 더이상 정보교환이 없어져 노드들이 스스로 알고리즘을 멈출 때까지 과정이 반복되기 때문에 붙여졌고,
비동기적 특성은 각자 노드들의 과정이 다른 노드의 과정의 진행에 영향을 받지않기 때문에 붙여졌다.
$d_x(y)$를 노드 x에서 노드 y로 가는 최소 비용이라고 한다면, 이를 구하는 벨만 포드(Bellman-Ford) 방정식은 다음과 같다.
$d_x(y)=\min_v{c(x,v)+d_v(y)}, (5.1)$
이는 직관적으로 최소 거리 비용이 중간 경유지 노드 v를 지나갈 때, 가장 비용이 적게 드는 중간 경유지를 골라야 최소 거리 비용이 나온다는 의미이다.
벨만 포드 방정식을 통해, 라우터의 경로 상에 위치한 중간 경유 노드로의 포워딩 개념과 DV 알고리즘에서의 라우터의 이웃간 통신의 개념이 생겨났다.
DV 알고리즘의 기본적인 골자는 다음과 같다.
각 노드들은 DV 알고리즘에서 다음과 같은 정보를 유지해야 한다.
- 자신으로부터 자신을 제외한 다른 모든 노드들까지의 예상 최소 거리 비용 벡터
- 각 이웃들에 대해서 이웃으로부터 해당 이웃을 제외한 다른 모든 노드들까지의 예상 최소 거리 비용 벡터
- 이웃 노드과 연결된 링크의 비용(최소 거리 비용과 다르다)
한 노드가 자신에 대한 최소 거리 비용 벡터를 새로 갱신하면 이를 주변 이웃 노드들에게 전달하고, 전달 받은 이웃 노드는 아래와 같이 자신에 대한 최소 거리 비용 벡터를 갱신한다.
$D_x(y)=\min_v{c(x,v)+D_v(y)}\ for\ each\ node\ y\ in\ N$
이러한 갱신은 이웃들에게 비동기적으로 반복적으로 일어나게 되고, 그 결과 실제 최소 경로 비용에 가까워지게 된다.
거리 벡터(DV) 라우팅 알고리즘 (Distance-Vector (DV) Algorithm)
DV 알고리즘은 LS 알고리즘과 달리 전체 네트워크의 정보가 필요 없고, 이웃 노드로 가는 링크 비용과 이웃 노드가 주는 정보만 있으면 된다.
DV 알고리즘이 사용되는 라우틴 프로토콜은 RIP, BGP, ISO, IDRP, Novell IPX, 초기의 ARPAnet 등이 있다.
초기화(Initialization):
for 모든 목적지 노드 y in N
D_x(y) = c(x,y)/* 만약 y가 x의 이웃이 아니면 비용은 무한대*/
for 노드 w in x의 이웃 노드
for 노드 y in N
D_w(y)= ? (빈칸)
for 노드 w in x의 이웃 노드
거리 벡터 D_x = [D_x(y): y in N]를 w에게 전송
loop(무한 반복)
if (이웃으로부터 거리 벡터 수신 또는 내 이웃과의 링크 비용이 변함)
for 목적지 노드 y in N
D_x(y) = min_v(c(x,v) + D_v(y)) /* 여기서 최소값을 이룩하는 v가 v*, 즉 최소 거리로 y를 가기위해 라우팅되야 할 이웃 노드이다. */
if D_x = [D_x(y): y in N]가 하나라도 변경됨
for 노드 w in x의 이웃 노드
거리 벡터 D_x = [D_x(y): y in N]를 w에게 전송
라우터가 DV 알고리즘을 돌리는 이유는 포워딩 테이블을 생성하기 위해이므로, 중요한 것은 특정 노드 y까지의 최소 비용이 아니라 특정 노드 y까지 최소 비용으로 가기 위해 첫 발을 내디뎌야 할 x의 이웃 노드(v*)이다.
아래 fig.5.6은 DV 알고리즘에 의한 라우팅 테이블 갱신의 시뮬레이션이다.
원래는 비동기적으로 시행되지만, 편의를 위해 동기적으로 시행한다.
그래프의 행은 각 라우터의 라우팅 테이블이고, 열은 포워드 테이블의 시간별 변화이다.
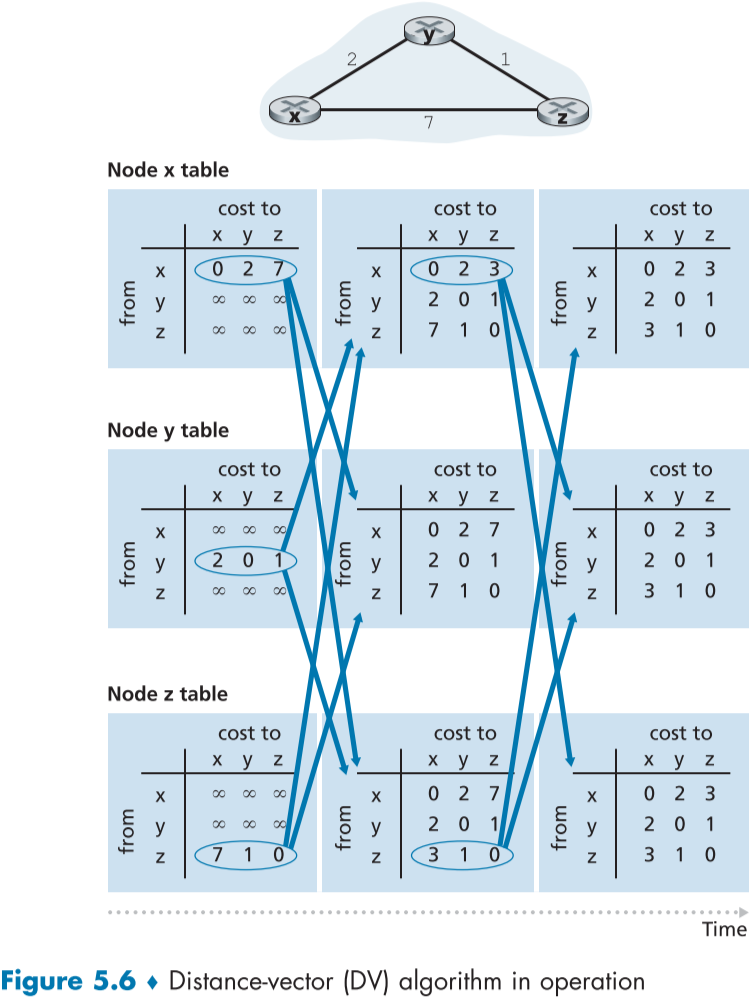
가장 왼쪽 열은 초기상태의 라우팅 테이블로, 이웃 노드의 정보가 아직 없어 무한대로 표시되어있다. 이후 화살표 방향의 라우터에게 자신의 정보를 나눠준다.
중앙 열은 이웃 노드에게 받은 정보를 토대로 자신의 이웃과의 거리 벡터를 재조정한다. 이후 x와 z의 라우팅 테이블은 변화가 생겼으므로, 자신의 정보를 보내주고, y의 라우팅 테이블은 그대로 이므로 정보를 전파하지 않는다.
- 이때, 라우팅 테이블의 변화는 아래와 같이 생긴다.
마지막 열은 모두들 새로운 정보를 받았지만 이로 인해 생기는 라우팅 테이블 변화가 없으므로, 아무런 변화나 정보 전파가 이루어 지지 않는다. 앞으로 링크의 비용이 바뀌는 등의 변화가 생기기 전까지는 DV 알고리즘이 실행되지 않을 것이다.
거리 벡터(DV) 알고리즘 : 연결 비용 변경과 연결 실패 (Distance-Vector Algorithm: Link-Cost Changes and Link Failure)
연결 비용 변경으로 인한 라우팅 테이블 갱신의 두가지 예제를 살펴보겠다. 이번 경우는 중요한 라우터 y의 라우팅 테이블과 라우터 z의 라우팅 테이블만 살펴보겠다.
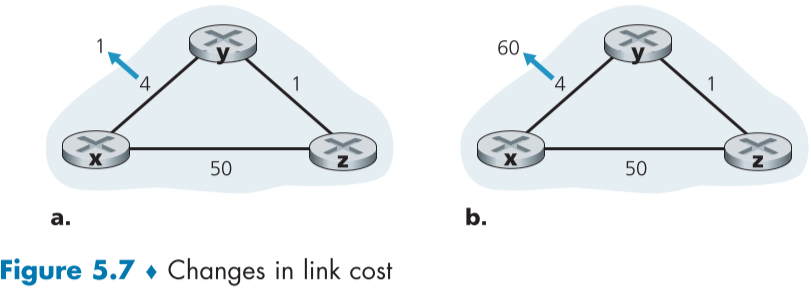
먼저 fig.5.7(a)의 경우 c(x,y)가 4에서 1로 변경되었다.
- y가 링크 비용의 변경을 탐지하고 자신의 라우팅 테이블값(c(x,y)는 4->1)을 바꾸고 주변 라우터에게 전파한다.
- z가 y의 정보를 받고 라우팅 테이블 값을 바꾼다.(c(z,x)는 5->2)또 이를 주변 라우터에게 전파한다.
- y는 z의 정보를 받고 DV 알고리즘을 실행하나 기존과 다를게 없으므로 전파를 멈춘다.
이는 이상적인 상황으로 2번의 전파만으로 최적의 경로를 찾을 수 있게 되었다.
fig.5.7(b)의 경우 c(x,y)가 4에서 60으로 변경되었다.
-
초기 변경 되기 전에 y의 라우팅 테이블에는 $D_y(x)=4,\ D_z(y)=1$로 되있고,
z의 라우팅 테이블에는 $D_z(y)=1,\ D_z(x)=5$로 되있을 것이다.
여기서 y가 c(x,y)가 4에서 60으로 증가한 것을 감지하면, 다음과 같은 식으로 $D_y(x)$를 바꿀 것이다.
\[D_y(x)= \min\{c(y,x)+D_x(x),c(y,z)+D_z(x)\}=\min\{60+0,1+5\}=6\]하지만 알다시피 위의 식의 $D_z(x)$가 5인 것은 이전 네트워크가 변경되기 전의 정보이고, 실제로는 해당 하는 길은 60+1만큼의 비용이 들어야한다. 하지만, 이를 이해하지 못하는 라우터 y는 잘못 갱신한 라우터 테이블 정보를 라우터 z를 포함한 주변 라우터들에게 보낼 것이다.
-
라우터 z는 해당 정보를 받고 다음과 같은 식으로 $D_z(x)$를 바꿀 것이다.
\[D_z(x)= \min\{c(z,x)+D_x(x),c(z,y)+D_y(x)\}=\min\{50+0,1+6\}=7\]이 또한 잘못된 값이며, 위에서 잘못 계산된 $D_y(x)$로 인한 오류이다. 오류가 있는 라우팅 테이블은 이 정보를 다시 주변 노드에게 전파하게 된다.
-
$D_y(x)$는 같은 방법으로, 이번에는 $D_y(x)=8$로 바꾸게 되며, 결국 y와 z 두 라우터는 잘못된 비용과 최소 경로를 가지고, 반복적으로 서로 계속 잘못된 정보를 갱신하고 전파하는 라우팅 루프(routing loop) 현상에 의해 count-to-infinity 문제에 빠지게 된다.
- 이 갱신은 잘못된 최소 경로 비용이 반복마다 1씩 증가하다 60의 값을 넘기면 잘못이 고쳐지고 올바른 비용과 올바른 경로를 선정하게 된다.
b의 시나리오의 경우 이때, 총 44번의 계산과 메시지 교환이 있게 되며, 만약 갱신된 링크 비용이 60이 아니라 9999면 끔찍할 정도로 긴 시간 동안 잘못된 계산을 이어가게 되고 이는 크나큰 성능 저하로 이어진다.
- 같은 증상이 서로 다른 두 라우터가 서로에게 메시지를 동시에 보내서 생기기도 한다.
거리 벡터(DV) 라우팅 알고리즘 : 포이즌드 리버스 추가 (Distance-vector Algorithm: Adding Poisoned Reverse)
위 fig.5.7(b) 시나리오에서 설명한 라우팅 루프 문제는 포이즌드 리버스(Poisoned Reverse)로 해결할 수 있다.
포이즌드 리버스는 특정 노드가 라우팅 정보를 전파할 때, 특정 목적지 노드까지의 경로에 포함된 이웃 노드에게는 해당 목적지 노드까지의 최소 경로 비용을 무한대 바꿔 표기해 전파하는 방법으로, 이를 통해 라우팅 루프 문제를 해결할 수 있다.
쉽게 말해, 라우터 z가 라우터 x로 가기위한 경로에 라우터 y가 존재한다면, 라우터 y에게 정보를 전파해줄 때, 라우터 y 한정으로 $D_z(x)=\infty$로 바꿔 표기해서 보내주는 것이다.
위의 fig.5.7.(b) 시나리오에서 예시를 들어보자.
-
라우터 y가 c(x,y) 비용의 변화를 감지하고 다음과 같은 식으로 라우팅 테이블을 변경하고 주변 노드에게 정보를 전파한다.
\[D_y(x)= \min\{c(y,x)+D_x(x),c(y,z)+D_z(x)\}=\min\{60+0,1+5\}=6\]하지만 이때, 라우터y에서 라우터 x로 가는 경로에 라우터 z가 있는 경우가 최소 비용이므로, 라우터 z에게 $D_y(x)=\infty$로 바꾸어 전파해준다.
-
라우터 z는 해당 정보를 가지고 다음과 같이 라우팅 테이블을 변경한다.
\[D_z(x)= \min\{c(z,x)+D_x(x),c(z,y)+D_y(x)\}=\min\{50+0,1+\infty\}=50\]라우터 z는 무한대인 라우터 y의 경로 대신, 비용 50짜리 라우터 x의 경로를 최소 비용 경로로 택했으며, 이곳에서는 라우터 y가 포함되지 않으므로 정상적으로 전파한다.
-
라우터 y는 해당 정보를 가지고 다음과 같이 라우팅 테이블을 변경한다.
\[D_y(x)= \min\{c(y,x)+D_x(x),c(y,z)+D_z(x)\}=\min\{60+0,1+50\}=51\]이제 양측다 정상적인 경로와 비용을 계산하게 된다!
하지만 포이즌드 리버스로도 여러 노드가 연관되어 있는 라우팅 루프는 풀 수 없다.
포이즌드 리버스 추가로 막기위해
-
Triggered Update : 네트워크에 변경사항이 있으면 지체 없이 바로 상태를 갱신하도록 함.
-
Hold Down : 회선이 먹통이 될 시, 라우팅 테이블을 바로 갱신하지 않고, 전체 네트워크 경로 정보가 올 때까지 기다림
- 1, 3으로도 못막는 루프를 막을 수 있다
-
Split Horizon: 이웃 노드로부터 받은 새로운 라우팅 정보가 자신의 라우팅 정보의 갱신을 초래하여 이를 전파해야할 때, 이전에 새로운 라우팅 정보를 줬던 이웃에게는 전파하지 않는다.
- 보통 포이즌드 리버스를 함께 사용하여 효율을 극대화함
LS와 DV 라우팅 알고리즘 비교(A Comparison of LS and DV Routing Algorithms)
앞서 설명한 두 알고리즘은 서로 상호보완적인 접근 방법을 가지고 있다.
DV는 주로 이웃들과 통신하여 모든 노드에 대한 예상 최소 거리 비용 주고 받고, LS는 전역 네트워크 정보를 활용해 경로를 구하며, 전파(boradcast)를 이용하여 이웃과의 비용을 모든 노드에게 알려준다.
DV와 LS의 주요 차이점을 알아보자, N은 노드들의 집합(routers), E는 엣지들의 집합(link)
- 메시지 복잡도(Message complexity)
-
LS에서는 각 노드가 모든 노드의 비용을 알고 있어야 하므로 $O( N \ E )$만큼의 메시지를 보내야하며, 링크 비용이 바뀌면, 새로운 메시지가 각 노드마다 보내져야 한다. - DV에서는 매 연산마다 이웃 노드간 메시지 교환이 필요하다. 링크 비용이 변경되면 메시지가 전파되기 시작하지만, 링크와 관계가 된 노드로 가는 최소 비용이 바뀔 때만 전파가 되므로 제한된다. 이외에도 여러 요인에 따라 알고리즘의 복잡도가 달라진다.
-
- 수렴 속도(Speed of convergence)
- 네트워크의 변화로 부터 올바른 최소 비용 경로를 계산하는데 걸리는 시간
-
LS는 $O( N ^2)$ 시간복잡도에 $O( N \ E )$ 만큼의 메시지가 필요하며, DV는 수렴 과정이 느리고(약 3분, LS의 3배정도 느림) count-to-infinity 문제가 생길 수 있다.
- 강건성(Robustness)
- 라우터가 실패, 오작동, 공격 당했을 때의 피해
- LS는 잘못된 링크 비용이나 오류인 정보를 주변 이웃 노드 한정으로만 전파한다. LS에서 한 노드의 포워딩 테이블 연산은 다른 노드의 연산과 별개로 진행되므로, 시스템을 오류 등에서 강건하게 만들어 준다.
- 잘못된 최소 비용 경로나 오류가 이웃간 전파의 반복을 통해 모든 노드에게 전염될 수 있다. DV는 노드의 계산 결과를 이웃에게 전달하고, 해당 이웃은 그에 대한 반응으로 마찬가지로 계산결과를 하여 전달하므로 순식간에 오류가 퍼진다.
둘다 일장일단이 있는 알고리즘이며, 인터넷에 다양한 곳에 쓰이는 중이다.
5.3 인터넷에서의 AS 내부 라우팅 : OSPF (Intra-AS Routing in the Internet: OSPF)
우리가 앞서 가정했엇던 네트워크와 라우터의 행동들은 너무 간단하게 생각한 건데, 그 이유는
- 규모(Scale), 최근의 인터넷은 수많은 라우터로 이루어져 있으며, 통신, 계산, 라우팅 정보 저장 등에 필요한 오버헤드가 불가능할 정도로 크다.
- 관리상의 조절(Administrative autonomoy), ISP들은 자신의 거대한 네트워크를 원하는 대로 설정, 조정하고, 외부의 인터넷과 연결됨과 동시에 외부로 부터 정보를 숨기고 싶어한다.
이 둘의 문제를 해결하기위해 라우터들의 자동화 시스템(autonomouse systems, ASs)을 만들게 되는데, 각 자동화 시스템은 같은 관리 하에 놓이게 한다.
ISP는 자신의 네트워크를 거대한 하나의 AS에 놓기도하고, 여러개의 AS로 쪼개어 관리하기도 하며, 이러한 AS에는 마치 아이피 주소처럼 전세계에서 유일한 식별자값인 ASN(autonomouse system number)를 ICANN 지역 레지스트리에게서 부여받는다.
같은 AS 하에서는 같은 라우팅 알고리즘과 라우팅 정보를 공유하며, AS 내부에서 실행되는 라우팅 알고리즘을 AS 내부 라우팅 알고리즘(intra-autonomous system routing protocol)이라고 한다.
열린 최단 경로 우선 (Open Shortest Path First (OSPF))
열린 최단 경로 우선(OSPF, Open Shortest Path First), 그리고 이와 비슷한 IS-IS은 널리 사용되는 AS 내부 라우팅 알고리즘(intra-autonomous system routing protocol)이다.
OSPF의 OPEN은 라우팅 프로토콜이 대중에게 공개되어 있기 때문이며 최신버전인 버전 2는 [RFC 2328]에서 볼 수 있다.
- 반대로 Cisco의 EIGRP 프로토콜은 20년 동안 Cisco 사의 사유 프토콜이었다가 최근에 풀렸다.
OSPF는 LS(link-state) 프로토콜로, 연결 상태(link-state) 정보와 다익스트라 최소 비용 경로 알고리즘을 사용한다.
OSPF 하의 라우터들은 각각 AS 네트워크 전체에 대한 그래프와 자기자신을 루트로 하는 각각 서브넷에 대한 최단 거리 트리를 가지고 있으며, 모든 링크 비용들은 네트워크 관리자(network administrator)에게 의해 관리된다.
네트워크 관리자는 자유롭게 링크 비용을 산정할 수 있는데, 모든 링크를 1로 설정하여 최소합(minimum-hop) 라우팅을 하거나, 각 링크의 대역폭의 역수를 가중치로 두어 트래픽에 따라 라우팅을 할 수 있다.
- 이후, 네트워크 관리자의 의도대로 설정한 비용에 의거해 다익스트라 알고리즘으로 경로를 구한다. 이를 역이용해, 네트워크 링크 사용률 관리 등을 위해 특정 경로로 라우팅을 강제하기 위해 일부러 링크의 비용을 바꾸는 경우도 있다.
OSPF에서는 라우터가 라우팅 정보를 이웃 뿐만 아니라 AS 내의 전체 라우터에게 전파하며, 링크의 상태가 바뀌거나, 바뀌지 않았어도 주기적으로(최소 30분 이상) 링크 상태를 체크하고 전파한다. 이는 연결 상태(link-state) 알고리즘을 강건하게 해준다.
OSPF 전파(broadcast)는 아이피 주소에 따라 상위 계층 프로토콜인 OSPF(헤더 필드 값 89번)에 의해 OSPF 메시지를 주고 받으며 이루어지며 따라서 메시지 신뢰성 보장 전송(reliable message transfer)과 연결 상태 전파(link-state boradcast) 같은 기능이 구현되어있어야 한다.
또한 OSPF 프로토콜은 라우터 간에 HELLO 메시지를 보내게 하여 링크의 사용 가능 상태를 확인하고, 라우터들에게 주변 라우터의 네트워크 전역 연결 상태 정보에 접근할 수 있게 해준다.
다음은 OSPF의 장점이다.
-
보안(Security)
OSPF의 라우터들은 정보를 공유할 때 인증을 이용해 공격자들의 잘못된 라우터 정보 입력을 막을 수 있다. 설정에 따라 보안 설정을 안하거나, 간단, MD5로 설정할 수 있다.
간단 버전은 단순히 각 라우터 간에 비밀번호를 공유하며, OSPF 패킷을 보내면 암호가 plaintext 형태로 적혀있으므로 전혀 안전하지 않다.
MD5 버전은 나중에 8장에서 배울 방법으로, 라우터 전역에 공유된 비밀 키를 이용해 OSPF 패킷의 데이터를 해쉬화하고 해쉬 결과값를 패킷에 포함해 보낸다. 이후 도착한 라우터에서는 이를 공유한 비밀키로 패킷의 데이터를 해쉬화 하고 이 해쉬값을 패킷의 해쉬값과 비교하여 인증한다. 시퀀스 번호(sequence number)를 사용해 리플레이 공격(replay attack)을 방지한다.
-
다중 동일 비용 경로(Multiple same-cost paths)
동일한 비용의 최소 비용 경로가 여럿이 있다면 부하 방지를 위해 여러 경로를 번갈아가며 사용한다.
-
유니캐스트, 멀티 캐스트 라우팅 통합 지원(Integrated support for unicast and multicast routing)
멀티 캐스트 OSPF (Multicast OSPF, MOSPF)는 OSPF의 확장형으로, 멀티캐스트 라우팅을 제공하며, OSPF 연결상태 전파 메커니즘을 이용해 기존의 OSPF 정보 데이터베이스에 새로운 종류의 연결 상태를 추가하고 전파한다.
-
단일 AS 내의 계층 지원(Support for hierarchy within a single AS)
AS 내부를 또 각각의 지역(area)으로 나누어 라우터간의 정보전파나 라우팅 알고리즘을 구별할 수 있다.
지역의 가장자리 바깥 라우터들이 다른 지역의 패킷을 라우팅하는데 이러한 지역 가장자리 라우터들과 가장자리가 아니어도 추가로 포함된 라우터들의 지역을 백본 네트워크로 설정하여 지역 간의 트래픽을 전달하는 역할을 한다.
먼저 지역 내부의 패킷은 외부 지역과 통신하기 위해 지역 가장자리 라우터에게 보내지고(지역 내부 라우팅), 이후 백본을 거쳐 목적지 지역에 도착한다.
OSPF는 복잡한 프로토콜이므로 더욱 많이 알고 싶다면 [Huitema 1998; Moy 1998; RFC 2328] 참조
RIP(Routing Information Protocol)
DV 방식을 이용하는 AS 내부 라우팅 프로토콜(=게이트웨이 내부 프로토콜, IGP, Interior Gateway Protocol <=> EGP), UDP를 이용해서 정보교환
라우터를 얼마나 넘어가느냐 (=홉, HOP)으로 거리를 측정하며, 최대 15개가 넘어가는 홉은 측정하지 못하므로 대규모 네트워크에 부적합하다.
매 주기 마다(기본 30초) RIPv1은 브로드캐스트(broadcast), RIPv2부터는 멀티캐스트(Multicast)로 주변 네트워크에 UDP 패킷을 보내 라우터의 정보를 갱신한다.
하지만 이 주기 안에 갱신되지 않은 정보로 인해 라우팅 루프(routing loop)에 빠질 수 있다.
5.4 ISP 간의 라우팅 : BGP (Routing Among the ISPs: BGP)
다른 AS를 포함하고 있는 여러 ISP가 서로 통신하기 위해서는 AS 간 라우팅 프로토콜(inter-autonomous system routing protocol)이 필요하다.
AS 간 라우팅 프로토콜(inter-autonomous system routing protocol)를 통해 서로 다른 AS가 통신하기 위해서는 같은 프로토콜을 공유해야 하는데 그것이 바로 BGP(Border Gateway Protocol)이며, 전체 인터넷에서 BGP만 사용한다.
BGP는 ISP 간 통신을 위해 아주 중요하며, distance-vector 라우팅과 비슷하게 분산적(decentralized), 비동기적(asynchronous) 프로토콜이다.
5.4.1.BGP의 역할 (The Role of BGP)
AS 내부의 라우터 간의 통신은 AS 내부 라우팅 프로토콜(intra-AS routing protocol)을 통해 이루어지며, AS 외부와의 통신은 BGP를 이용하게 된다.
BGP는 특정 아이피 주소가 아닌 CIDR화된 접두어(CIDRized prefixes)를 이용해 서브넷이나 서브넷의 모임을 주소로 지정한다.
- 예시로 BGP의 목적지 주소가 138.16.68/22이면, 1024개의 아이피 주소가 포함되있는 주소이며, 이에 따라 라우터의 포워딩 테이블의 항목은 (CIDR화 접두어 주소, 라우터의 특정 인터페이스 번호) 형태로 표시된다.
BGP는 다음과 같은 것을 라우터들에게 제공한다.
-
인접한 AS간의 접두어 주소 도달가능성 정보 확보(Obtain prefix reachability information from neighboring ASs)
BGP는 각 서브넷에게 자신의 존재를 인터넷 상에 전파할 수 있도록 하여 접두어 주소를 알려주는 역할을 한다.
-
접두어 주소로의 최선의 경로 결정(Determine the “best” routes to the prefixes)
라우터는 특정 접두어 주소로 접근하는 여러 경로를 알 수 있다. 최선의 루트를 결정하기 위해서, 라우터는 BGP 경로 선택 절차(BGP route-selection procedure)를 실행할 수 있으며, 최선의 경로는 정책과 도달가능성 정보에 따라 결정된다.
5.4.2.BGP 경로 정보 전파(Advertising BGP Route Information)
아래 fig.5.8과 같이 AS1, AS2, AS3로 이루어진 네트워크를 가정하자, AS3는 접두어 주소가 x인 서브넷을 포함하고 있다.
모든 라우터들은 관문 라우터(gateway router) 아니면 내부 라우터(internal router)이다. 관문 라우터는 AS의 가장자리에 위치해 다른 AS와 연결되어 있는 라우터이며, 내부 라우터는 오직 같은 AS의 라우터와만 연결되어 있는 라우터이다. 아래와 같은 경우, 1c, 2c ,3a가 관문 라우터, 나머지는 경계 라우터이다.
이제 접두어 주소 x의 도달가능성 정보를 모든 라우터에게 전파하는 과정을 살펴보자.
먼저, AS3가 AS2에게 BGP 메시지로 x가 AS3 내부에 존재한다고 알리는 메시지 “AS3 x”를 보내면, AS2는 AS1에게 BGP 메시지 “AS2 AS3 x”를 보내 자신, AS2와 연결된 AS3에 x가 존재함을 전파한다.
이렇게 모든 AS 들은 x의 존재 뿐만 아니라 도달하기 위한 AS들의 경로 또한 알게 된다.
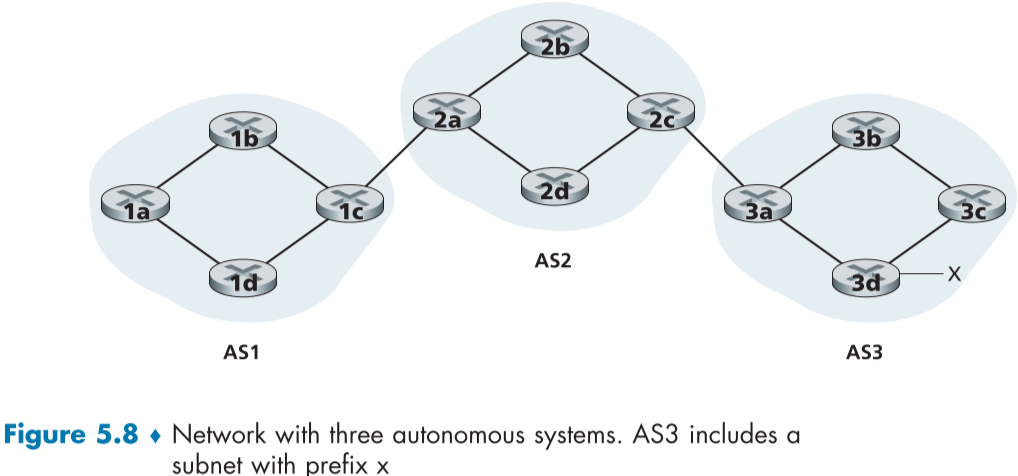
정확히는 AS 간의 통신이 아니라 라우터 간의 BGP 메시지 교환을 통해 이루어지며, 통신을 위해 포트 179번을 이용하는 반영구적 TCP 연결을 이용한다.
이때, TCP 연결로 BGP 메시지가 주고 받아진다면, BGP connection이라고 부르며, 같은 AS 소속 간의 통신은 내부 BGP(Internal BGP, iBGP) 연결, 다른 AS 소속 간의 통신은 외부 BGP(external BGP, eBGP) 연결이라고 한다.
아래 fig.5.9는 그러한 BGP 연결의 예시이며, 보통 AS 간에 직접적으로 연결된 하나의 라우터마다 하나의 eBGP 연결이 수립되어 있으며 예시로는 1c-2a, 2c-3a 연결이다.
iBGP 연결의 경우 같은 AS 소속 라우터간의 연결로 표시되 있지만, iBGP 연결이 오직 직접적으로 물리 도선으로 연결되어야만 수립되는 것은 아니다.
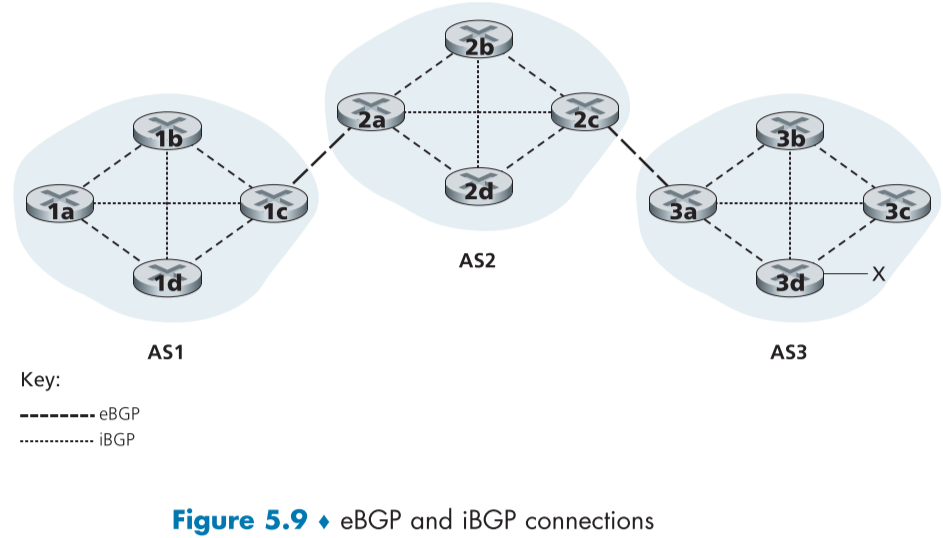
도달가능성 정보를 전파하기 위해서는 이러한 eBGP와 iBGP가 활용된다.
예를 들어, AS3 x 메시지는 3a에 의해 2c에 전파되고, 2c라우터는 2a 라우터를 포함해 2b, 2d 라우터에게도 해당 AS3 x 메세지를 전파해 AS2 전체에게 알리게 된다.
이후 2a는 이 메시지를 AS2 AS3 x로 바꾸어 1c에게 전달하고, 1c는 해당 메시지를 AS1 라우터 전체에게 퍼트려 모든 라우터는 x의 존재와 도달하기 위한 경로를 알게 된다.
물론 실제로는 x로 도달하는 경로가 하나가 아니라 여러 경로가 존재할 수 있으며, 이는 fig.5.10에 예시로 나와있다.
이 경우, 두가지 경로의 전파가 모두 일어나 라우터들은 x로 향하는 경로 정보 또는 도달가능성 정보를 두개 유지하게 된다.
5.4.3.최적 경로 결정 (Determining the Best Routes)
그렇다면 여러 경로 중 하나를 고를 땐 어떻게 고를까?
라우터가 BGP 연결을 통해 접두어 주소를 전파할 때, 접두어 주소 뿐만아니라 BGP 속성(BGTP attributes)를 추가로 포함해서 보낸다.
BGP 속성의 예시로 route는 접두어 주소를 의미하며, AS-PATH는 전파하면서 지나온 AS들을 의미하며, 뒤의 메시지의 예시에서 AS2 AS3 x 에서 “AS2 AS3” 부분이다.
- 이를 통해 단순히 경로 뿐만 아니라 전파의 루프 또한 감지할 수 있다. 만약 해당 AS-PATH에 자신이 속한 AS가 있다면, 라우터는 해당 메시지를 전파하는 것을 거부한다.
NEXT-HOP 속성은 AS 간 프로토콜과 AS 내부 프로토콜의 연결점을 알려주는 속성으로, AS-PATH의 가장 첫번째 AS의 관문 라우터의 인터페이스 아이피 주소를 가지고 있다.
예시를 들자면 아래 fig.5.10에서 AS1에 전파된 메시지의 AS-PATH가 AS2 AS3 x인 경우, NEXT-HOP은 2a 라우터가 1c와 연결되어있는 인터페이스의 아이피 주소이다.
AS2가 제일 처음에 나온 AS이고, AS2와 연결하기 위해 2a 라우터와 연결되어 있기 때문이다.
여기서 주의할 점은 NEXT_HOP은 자신이 속한 AS에 속해있지 않은 라우터의 인터페이스라는 점이다.
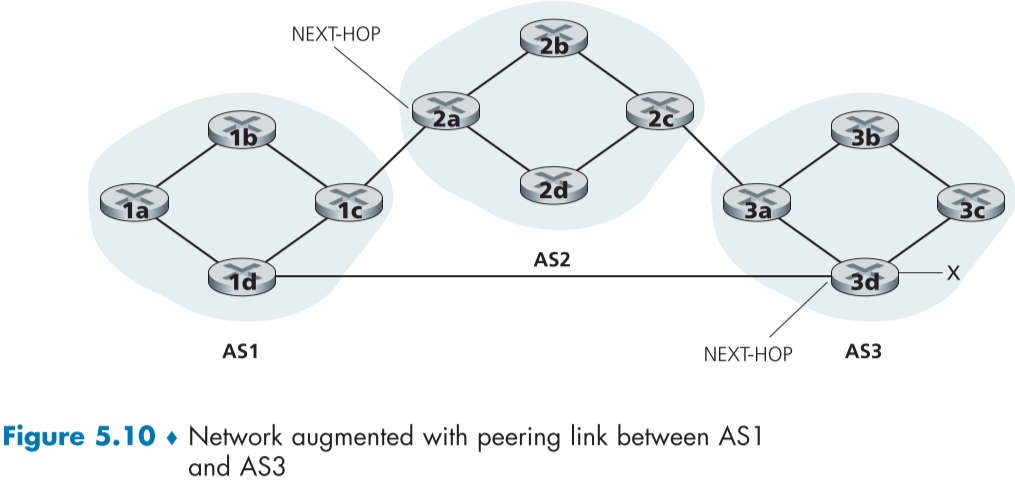
정리하자면 AS1의 각 라우터가 x로 가는 경로 정보는 다음과 같이 두개가 저장되어 있다.
2a 라우터의 AS1가 연결된 인터페이스 아이피 주소; AS2 AS3; x
3d 라우터의 AS1가 연결된 인터페이스 아이피 주소; AS3; x
현재는 NEXT-HOP, AS-PATH, 목적지 접두어 주소 3개로 이루어졌다고 가정했지만, 실제의 BGP 루트 정보는 더 많은 속성을 포함하고 있다.
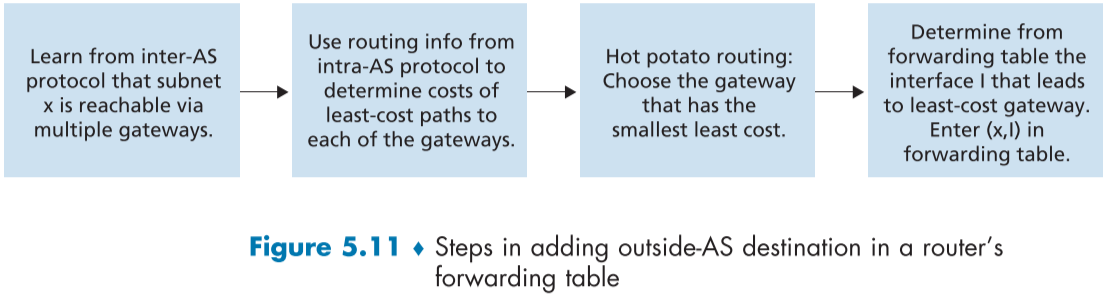
뜨거운 감자 라우팅(Hot Potato Routing)
이제 좀더 자세한 BGP 라우팅 알고리즘에 대해서 알아볼 것이며, 그중 간단한 라우팅 알고리즘으로 뜨거운 감자 라우팅(Hot Potato Routing)이 있다.
뜨거운 감자 라우팅에서는 여러 경로 중에 NEXT-HOP으로 가는 경로의 비용이 가장 적은 경로가 선택된다.
라우터가 AS 외부의 접두어 주소를 포워딩 테이블에 넣기위해, AS 간 프로토콜(BGP)과 AS 내부 프로토콜(OSPF)가 둘다 사용된다.
아래 fig.5.11은 뜨거운 감자 라우팅을 사용한 포워딩 테이블 생성의 요약이다.
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| BGP를 이용해 서브넷 x가 여러 관문 라우터를 통해 도달할 수 있음을 알게됨 | OSPF를 이용해 얻은 라우팅 정보로 각 관문 라우터까지 도달하는 최소 비용 경로의 비용을 계산함. | 뜨거운 감자 라우팅 : 가장 작은 비용이 드는 관문 라우터 선택 | 최소 비용 관문 라우터의 인터페이스 I를 포워딩 테이블에 (x, I) 형태로 집어넣음 |
뜨거운 감자 라우팅의 아이디어는 최대한 패킷을 저비용으로 다른 AS에게 넘기는 것이다.
뜨거운 감자의 명칭도, 손이 뜨거우니 최대한 빨리 뜨거운 감자(패킷)를 다른 사람(AS)에게 넘기자는 것이다.
그리하여 뜨거운 감자 라우팅은 이기적인 알고리즘으로 불리운다.
문제는, 그렇게 넘긴 AS가 x로 향하는 AS 루트 중에 최적의 루트가 아닐 수도 있다는 점이다.
당장에 fig.5.10의 예시를 보자면 1b 입장에서 뜨거운 감자 라우팅 상으로 2a가 3d보다 가까우므로 AS2로 패킷을 보내겠지만, 실제로는 AS 내부 상에서는 조금 멀더라도 3d로 보내는 것이 패킷이 빨리 도착한다.
또한 주의할 점은 뜨거운 감자 라우팅의 결과 값은 같은 AS 라우터여도 서로 다를 수 있다는 점이다.
1b와 달리 1a 라우터는 3d 라우터가 더욱 가까우므로 패킷을 AS3로 보내게 될것이다.
경로 선택 알고리즘 (Route-Selection Algorithm)
실제 BGP는 뜨거운 감자 라우팅보다 더 복잡하지만 이를 일부에서 포함하고 있다.
BGP의 경로 선택 알고리즘(Route-Selection Algorithm)은 각 라우터들이 알고 있는 해당 접두어 주소로 가는 경로 정보들이다.
하나만 있다면 그것을 선택하겠지만 여러 개 있다면 다음과 같은 소거법으로 경로가 하나만 남을 때까지 누락한다.
-
BGP 경로 정보에는 추가로 지역적 선호(local preference) 속성이 있어, 가장 선호하는 경로를 고른다.
라우터가 설정하거나 다른 라우터가 설정한 값으로 같은 AS 소속 라우터들이 공유하는 값이며, AS의 네트워크 관리자가 정한 정책에 따라 정해진다.
-
만약, 가장 높은 지역적 선호 속성값을 가진 경로가 여럿 있다면, AS-PATH 속성이 가장 짧은 것(AS를 가장 적게 지나는 경로)를 고른다.
BGP 이때 DV 알고리즘을 이용해 경로를 계산하며, 라우터 홉보다는 AS 홉을 기준으로 구한다.
-
AS-PATH 속성의 길이가 같은 경로가 여럿 있다면, 뜨거운 감자 라우팅을 이용한다. 위에서 설명한대로 NEXT_HOP까지의 비용이 가장 적은 경로를 구한다.
-
여전히 경로가 둘 이상 남았다면, 라우터는 BGP 식별자를 사용하여 고른다.
3번의 뜨거운 감자 라우팅을 이용하기 전에 2번의 AS-PATH 속성의 길이를 고려하니 이제 더이상 이기적인 알고리즘이 아니다.
BGP 알고리즘은 AS 간 알고리즘의 사실상의 기준이 됬으며, http://www.routeviews.org 에서 tier-1 ISP의 BGP routing table을 볼 수 있다.
5.4.4.아이피-애니케스트 (IP-Anycast)
BGP는 추가로 DNS 등에서 사용되는 아이피 애니케스트를 구현하는데 사용된다[RFC 1546, RFC 7094]
우리는 이전에 CDN의 멀티미디어 컨텐츠, DNS의 레코드 등을 배울때, 지정학적으로 떨어져있는 사용자들에게 양질의 서비스를 제공하기 위해 여러 서버 클러스터를 지정학적으로 퍼뜨리고, 가장 응답이 빠른 서버를 연결해주는 방식을 사용했었다.
이 가장 가까운, 즉 가장 비용이 적게드는 서버를 고를 때 BGP의 경로 선택 알고리즘을 이용할 수 있다.
fig.5.12의 CDN의 예시를 보자면, CDN 측에서 여러 서버의 아이피 주소를 같은 걸로 하여 ISP에 연결하면, 각 라우터들은 BGP 경로 정보 전파를 통해 제각기 같은 아이피 주소를 가진 여러개의 루트 정보가 생기게 되고, BGP 경로 선택 알고리즘에 의해 가장 최적의 서버의 주소를 포워드 테이블에 추가하게 된다.
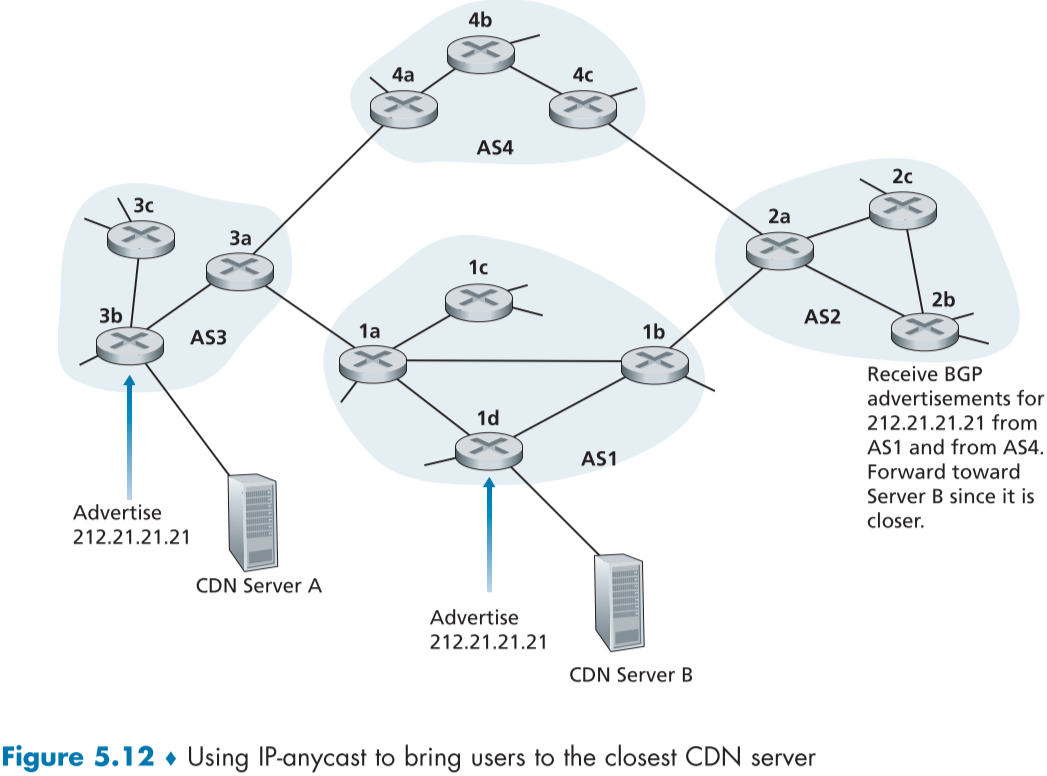
하지만 실제로 CDN들은 아이피 애니캐스트로 구현하지 않는데, BGP 라우팅으로 인해 TCP 연결 중에 패킷들이 여러 서버에 나뉘어 보내질 수 있기 때문이다. 실제로는 2장에서 설명했었던 지정학적 위치 데이터베이스나 주기적인 성능 측정으로 서버를 지정해준다.
하지만 BGP를 이용한 아이피 애니캐스트 방법은 루트 DNS 서버 쿼리에는 자주 사용된다.
루트 DNS 서버가 13개 있다고 알려진 것은 아이피 주소가 13개라는 의미이며, 실제로 돌아가는 루트 DNS 서버는 백여개가 세계에 퍼져있으며, 같은 아이피 주소의 DNS 서버를 BGP 라우팅 알고리즘으로 쿼리해준다.
5.4.5.라우팅 정책 (Routing Policy)
라우팅 정책을 이용해 AS 라우팅 알고리즘을 조정할 수 있다. 예를 들어 BGP 경로 정보의 local-preference 속성을 이용할 수 있다.
fig.5.13의 예를 들자면 A, B, C, X, Y는 각각 한 ISP에 속한 AS들이다. 다만 ABC는 W, X, Y를 연결해주는 백본 제공자 네트워크(backbone provider network)이며, XYZ는 소비자들이 사용하는 고객 접근 ISP(customer access ISP)이다. 특히 X는 여러 백본 제공자 네트워크에게 연결된 멀티홈드 접근 ISP(multi-homed access ISP)이다.
W, X, Y에 들어오는/나가는 패킷은 각각 해당 AS 내부 라우터만 목적지 아이피 주소/ 발신지 아이피 주소야 한다.
즉, 그 어떤 패킷도 W, X, Y 네트워크를 경유를 목적으로 들어갈 수 없다.
이러한 경로를 강제하기 위해 BGP 경로 정보(BGP route)를 조정하게 끔 라우팅 정책(Routing Policy)을 수립할 수 있다.
예를 들어 XCY 경로의 BGP 경로 정보를 가지고 있음에도 B에게 알리지 않게끔 정책을 세우면, B는 Y로 패킷을 보내는데 해당 경로를 사용할 수 없다.
이를 통해 고객/제공자 네트워크를 구현할 수 있다
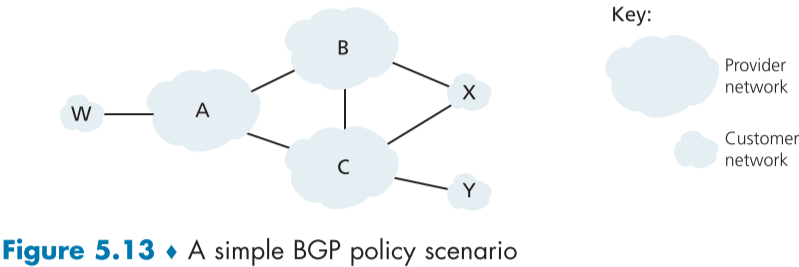
추가적인 예로 BAW 루트 정보를 C에게 알리지 않아 C가 굳이 패킷을 W에게 보낼 때 CAW처럼 직접적인 효율적인 경로를 내버려두고, CBAW처럼 비효율적인 경로를 선택하지 않게 한다.
ABC 같은 백본 네트워크에는 패킷이 경유할 이유만 있지 패킷이 도착할 이유는 많지 않기 때문에, 목적지나 출발지가 ABC인 패킷을 막을 수도 있을 것이다.
실제로 ISP 간의 공개적이거나, 비밀적이거나, 암묵적인 피어링 동의를 통해 저런 비효율을 막는다.
BGP에 대한 추가 자료는 [Stewart 1999; Huston 2019a; Labovitz 1997; Halabi 2000; Huitema 1998; Gao 2001; Feamster 2004; Caesar 2005b; Li 2007]에서 볼 수 있다.
왜 AS 간 프로토콜과 AS 내부 프로토콜이 차이를 보이는가?(WHY ARE THERE DIFFERENT INTER-AS AND INTRA-AS ROUTING PROTOCOLS?)
이유는 두 프로토콜 간의 목적이 차이를 보이기 때문이다.
- 정책(policy) : AS 간 프로토콜은 AS 간의 정책의 차이가 존재하지만, AS 내부 프로토콜은 보통 하나의 관리적 조정 하에 라우팅 된다.
- 규모(scale) : 라우팅 알고리즘과 자료 구조의 대규모 네트워크에서의 라우팅을 다루고 규모를 바꾸는 능력이 AS 간 라우팅에서 중요하다. 하지만 AS 내부 라우팅에서는 규모의 변경은 큰 일이 아니다. 만약 해당 AS가 너무 커져 성능이 저하된다면 AS를 여러 지역(area)로 나누어 관리하거나 AS를 여러개로 쪼갤 수 있다.
- 성능(performance) : 앞서 말했던 정책 덕분에, AS 간 프로토콜은 가끔 성능 보다는 정책을 우선시 해야되는 경우가 있다. 예를 들어 조금 더 많은 hop을 지나가도, 계약되지 않은 ISP는 피해간다던지, 등이다. 하지만 AS 내부 프로토콜은 대부분 그러한 정책에서 자유로우므로, 라우팅의 성능에 좀더 집중할 수 있다.
5.4.6.정리하기 : 인터넷 존재감 확보 (Putting the Pieces Together: Obtaining Internet Presence)
당신이 여러개의 서버로 이루어진 작은 서버와 공개 웹 서버, 사원들이 이용할 메일 서버와 DNS 서버를 가지고 있다고 하자.
가장 먼저 해야할 일은 인터넷과 연결성을 확보하는 것이다. 지역 ISP와 연락하여 계약하면, 당신의 관문 라우터(gateway router)와 ISP의 라우터를 연결하기 위해 DSL 연결로 전화선을 통해 ISP의 라우터와 연결되거나 챕터 1에서 묘사된 다양한 방법으로 연결해 줄 것이다.
물리적 연결이 끝난 이후, ISP는 당신에게 아이피 주소 범위(예를 들어 a/24, 최대 256개 아이피 주소)를 줄 것이며 해당 아이피 주소들을 웹서버, 메일서버, DNS 서버, 관문 라우터, 기타 인터넷 장비등에 할당해야 한다.
이후 추가로 인터넷 레지스타(registar)에게 연락해 당신의 회사의 도메인명을 확보하고, 레지스타에게 DNS 서버의 아이피 주소를 알려줘서 DNS 시스템에서 존재성을 확보해야한다. 당신 회사의 도메인명과 DNS 서버 주소는 레지스타에 의해 top-level-domain(.com 등)에 추가될 것이며, 이후로는 사람들이 해당 도메인명으로 접근할 수 있게 된다.
이제 당신은 웹서버의 호스트명과 아이피 주소를 매핑하여 당신의 DNS 서버의 항목으로 추가할 것이다. 이를 통해 도메인명으로 찾아온 사람들이 DNS 시스템에 도메인명에 매핑된 아이피 주소를 요구할 것이고, DNS 시스템은 당신의 DNS 서버에 물어봐 웹서버의 아이피 주소를 알려할 것이며, 당신은 방금 추가한 DNS 서버에 매핑된 아이피 주소를 돌려줄 수 있다. 그리하여 사람들이 웹서버에 도달해 TCP 연결을 할 수 있게 되고, 메일 서버 같은 기타 공개 서버에 대해서도 같은 일을 해야한다.
하지만, 그렇게 하기 위해서는 인터넷 AS 내부의 라우터들이 당신의 웹서버로 가는 경로를 알고있어야지 데이터그램을 적절한 출력 포트로 포워딩해줄 수 있고, 그러기 위해서는 당신의 a/24 주소와 BGP 알고리즘을 이용해야 한다.
당신이 계약한 지역 ISP회사는 당신의 접두어 주소(아이피 주소 범위)를 BGP를 이용해 전파할 것이다.
이제 전세계의 라우터가 당신의 서비스로 가는 길을 알게 되고, 사람들이 당신의 웹 서비스와 메일 서버에 접근할 수 있게 된다.
5.5 SDN 컨트롤 측면 (The SDN Control Plane)
SDN을 지원하는 장비들과 서비스를 설정하고, 관리하며, 패킷 포워딩을 조정하는 네트워크 전역 논리인 SDN 컨트롤 측면에 대해서 배울 것이다.
또한 SDN의 용어대로 여러 계층 패킷의 헤더를 참고해 포워딩하는 장비를 라우터 대신 패킷 스위치로 바꿔 부를 것이다.
SDN 구조의 특징은 크게 4가지가 있다.
-
흐름 기반 포워딩 (Flow-based forwarding)
SDN 제어 스위치는 전달 계층, 네트워크 계층, 링크 계층의 헤더 필드들을 활용해 포워딩할 수 있다.
우리는 이전에 오픈플로우 1.0 추상화에서 11개의 헤더필드를 이용해 포워딩하는 것을 배웠고, 이는 기존의 각자의 계층 헤더만으로 포워딩하던 방법과의 주요한 차이이며,
이러한 오픈플로우의 포워딩 규칙인 항목을 스위치에서 계산, 관리, 설치하는 하는 것이 SDN의 일이다.
-
데이터 측면과 컨트롤 측면의 분리(Separation of data plane and control plane)
데이터 측면은 match-plus-action을 행하는 스위치들로 이루어져 비교적 간단하고 빠른 장비들이다.
컨트롤 측면은 스위치의 플로우 테이블을 설치 관리하는 서버와 소프트웨어로 이루어졌다.
-
네트워크 제어 기능(Network control functions)
SDN의 컨트롤 측면은 소프트웨어로 정의되며, 기존의 라우터와 달리, 컨트롤러가 네트워크 스위치와 물리적으로 분리되어 있는 원격 컨트롤러이다.
컨트롤 측면은 SDN 컨트롤러(또는 네트워크 운영체제, network operating system)와 네트워크 제어 응용 프로그램(network control application)으로 이루어져있으며,
컨트롤러는 정확한 네트워크 상태 정보를 유지하고, 네트워크 제어 응용 프로그램에게 상태 정보를 주어 네트워크 장비를 모니터, 프로그래밍, 조종하게 해준다.
fig.5.14에 그림에서는 하나의 단일 컨트롤러로 보이지만 실제로는 여러 서버에 분산되어 구현되며 논리적으로만 중앙화되어 있다.
-
프로그래밍 가능 네트워크(A programmable network)
네트워크는 상기한 네트워크 제어 응용 프로그램에 의해 프로그램이 될 수 있다.
이러한 응용 프로그램은 SDN 컨트롤 측면에서 뇌로 작용하며 SDN 컨트롤러의 API를 이용해 네트워크 장비를 모니터링하고 조종한다.
예를 들어 SDN 컨트롤러가 준 노드 상태와 연결 상태 정보를 이용해 다익스트라 알고리즘을 돌린다.
이외에도 패킷의 차단이나 서버의 부하 밸런싱 등을 수행한다.
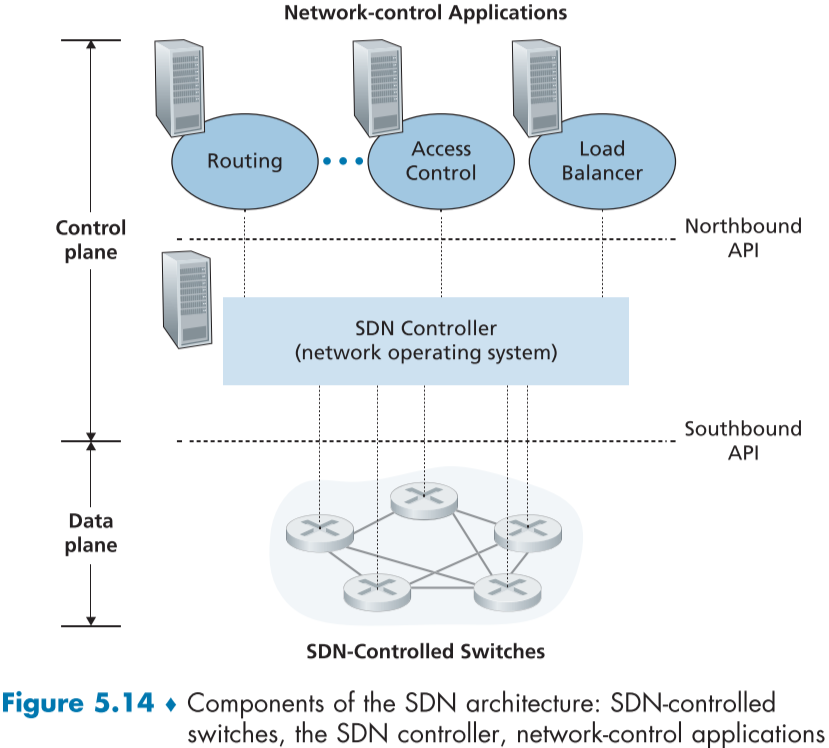
SDN이 여러 네트워크의 기능을 나누는 특성은 오픈소스 시스템 확립과 많은 회사들의 참여를 끌어 모았고 혁신을 가능케 하였다.
5.5.1 SDN 컨트롤 측면 : SDN 컨트롤러와 SDN 네트워크 컨트롤 응용 프로그램(The SDN Control Plane: SDN Controller and SDN Network-control Applications)
컨트롤 측면이 제공해야할 기능들을 알아볾으로써 SDN 컨트롤 측면에 대해 알아보자.
SDN 컨트롤 측면은 크게 SDN 컨트롤러와 SDN 네트워크 제어 응용 프로그램 부분으로 나뉜다.
SDN 컨트롤러는 SDN 초기부터 고안되었으며 fig.5.15는 SDN을 크게 3가지로 나누어 설명하는 그림이다.
-
통신 계층 : SDN 컨트롤러와 제어되는 네트워크 장비 간의 통신(A communication layer: communicatin between the SDN controller and controlled network devices)
SDN 컨트롤러는 SDN 제어 스위치, 호스트 같은 네트워크 장비들의 운용을 원격으로 조종하므로, 컨트롤러와 장비 간의 정보를 교활할 프로토콜이 필요하다.
추가로 네트워크 장비가 탐지하게 되는 링크의 상태나 새로운 장치의 추가 같은 지역적 이벤트 또한 컨트롤러 측에 보고되어 최신 네트워크 상태를 유지해야되며, 이러한 프로토콜은 컨트롤러 구조 상 가장 아래쪽에 위치하기 때문에 장비와 컨트롤러의 통신을 남방 경계 인터페이스(Southbound interface, Southbound API)라고도 부른다.
여러 프로토콜 중 대부분의 SDN 네트워크 장치에서 사용하는 오픈플로우에 대해서 배워볼 것이다.
-
네트워크 전역 상태 관리 계층(A network-wide state-management layer)
SDN 컨트롤 측면에서 하는 플로우 테이블 갱신이나 부하 밸런싱, 방화벽 같은 중요한 일들은 네트워크 장비들이 측정하는 최신 네트워크 정보가 필요하다.
각 스위치의 플로우 테이블에는 네트워크 제어 응용 프로그램들이 유용하게 쓸 수 있는 카운터 값들이 갱신되고 있으며, 이를 그들에게 전달해 줘야한다.
플로우 테이블은 각 스위치에 전달될 뿐만 아니라 컨트롤 측면에서도 저장되어야 하며, 앞에서 설명한 이러한 정보들이 모두 SDN 컨트롤러가 유지해야할 네트워크 전역 정보 중 일부이다.
-
네트워크 제어 응용 프로그램 계층의 인터페이스(The interface to the network-control application layer)
컨트롤러와 장비가 통신 계층의 남쪽 경계 인터페이스를 통해 정보를 주고 받음으로써, 상위의 네트워크 전역 상태 관리 계층이 네트워크 제어 응용 프로그램들이 네트워크의 상태와 플로우 테이블을를 읽고 쓰게 해준다.
응용 프로그램들은 상태 변경 이벤트 알림에 반응하여 대응할 수 있어야 한다. 그러기 위해서는 컨트롤러 장비 간 뿐만 아니라 컨트롤러 응용 프로그램 간의 인터페이스가 필요하고 네트워크 응용 프로그램 계층에 존재하며 북방 경계 인터페이스 (Northbound interface, Northbound API)한다.
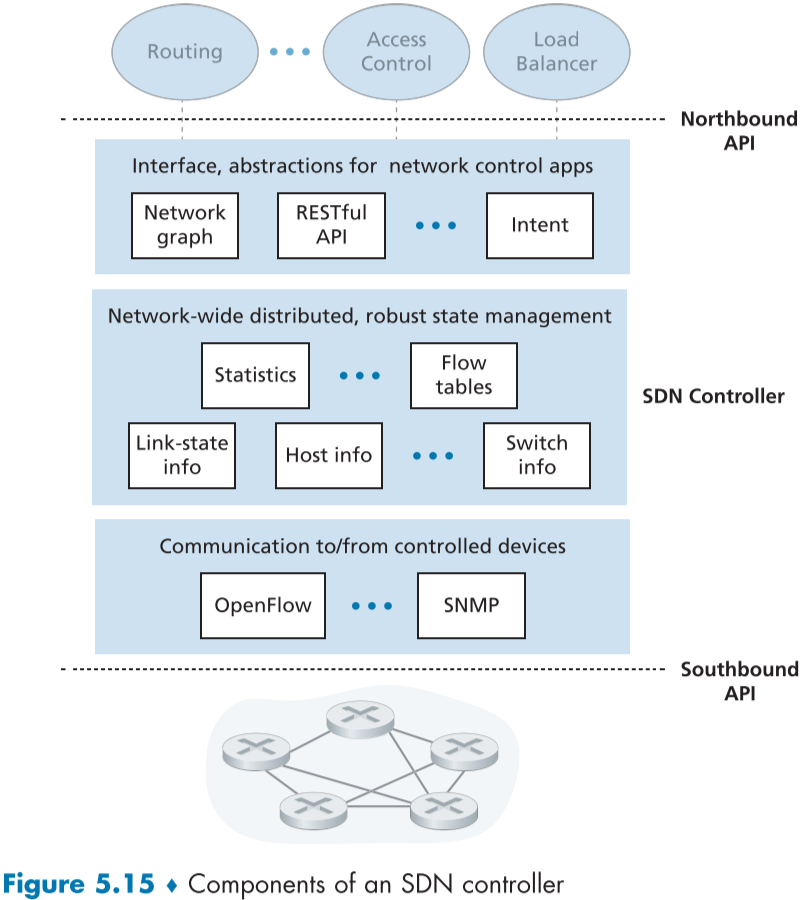
SDN 컨트롤러가 논리적으로 중앙화됬다는 의미는 네트워크 장치나 응용 프로그램 시점에서 SDN 컨트롤러는 하나의 일체화된 서비스로 보이지만 실제로 컨트롤러의 서비스와 데이터들은 서버 장애 방지, 고가용성, 성능상의 이유로 분산된 서버에 구현된다.
이러한 분산 처리 시스템의 경우, 데이터의 일관성, 동시성, 이벤트의 순서 등을 고려해야하며, OpenDaylight나 ONOS 같은 최신형 컨트롤러들은 이러한 분산처리 컨트롤러의 고가용성과 확장 가능성을 염두에 두고 설계되었다.
위의 그림 fig.5.15는 NOX 컨트롤러에서 제안된 구조로 최신의 OpenDaylight와 ONOS 컨트롤러도 차용하고 있다.
5.5.2.오픈플로우 프로토콜(OpenFlow Protocol)
오픈플로우 프로토콜은 SDN 컨트롤러와 오픈플로우 API가 구현되어 있는 SDN 제어 스위치, 기타 장비 등에서 사용하는 프로토콜로, TCP 프로토콜 위에 6653번 포트를 사용한다.
컨트롤러 측에서 제어되고 있는 스위치 측으로 보내는 중요한 메시지들은 다음과 같다.
-
설정(Configuration)
이 메시지는 컨트롤러가 스위치의 설정 파라미터 값을 설정하고 요청할 수 있다.
-
수정 상태(Modify-State)
이 메시지는 컨트롤러가 스위치의 플로우 테이블의 항목을 추가, 삭제, 변경하거나 스위치 포트 속성을 설정한다.
-
읽기 상태(Read-State)
이 메시지는 컨트롤러가 스위치의 플로우 테이블이나 포트로 부터 통계값이나 카운터 값을 가져온다.
-
패킷 전송(Send-Packet)
이 메시지는 컨트롤러가 보내고 싶은 패킷을 보내고 싶은 스위치의 포트로 보내도록 한다.
메시지의 페이로드로 보내고 싶은 패킷이 포함되어 있다.
스위치 측에서 컨트롤러 측으로 보내는 중요한 메시지들은 다음과 같다.
-
흐름 제거(Flow-Removed)
컨트롤러에게 플로우 테이블 항목 하나가 지워졌음을 알리는 메시지, 주로 시간 초과나 수정 상태(Modify-State) 메시지를 받은 뒤에 돌려준다.
-
포트 상태(Port-status)
스위치가 컨트롤러 측에게 포트의 상태가 변경됬음을 알리는 메시지
-
패킷 입력(Packet-in)
스위치의 포트를 통해 도착한 패킷이 플로우 테이블의 어떤 항목에도 맞지 않는다면 컨트롤러 보내 추가적인 처리를 받는다.
설정에 따라 일치된 패킷도 컨트롤러로 보내져 추가적인 처리를 받을 수 있다. 패킷 입력 메시지를 통해 해당 패킷을 페이로드에 넣어 보낼 수 있다.
추가적인 오픈플로우 메시지는 [OpenFlow 2009, ONF 2020]에서 볼 수 있다.
5.5.3.데이터와 컨트롤 측면 상호작용: 예제(Data and Conrol Plane Interaction: An Example)
아래 그림 fig.5.16은 SDN의 다익스트라 연결 상태 라우팅 시나리오이다.
이는 기존의 다익스트라 알고리즘이 모든 라우터에서 실행되고, 연결 상태가 갱신되어 모든 라우터 간에 공유하던 라우터별 조정 시나리오와 두가지가 다르다.
- SDN에서는 다익스트라 알고리즘이 패킷 스위치가 아닌 별도의 응용 프로그램에서 실행된다.
- 패킷 스위치는 연결 상태 갱신 정보를 다른 라우터 간에 공유하지 않고 SDN 컨트롤러에게만 보낸다.
s1과 s2 스위치 사이의 연결이 먹통이 되었고, 이로 인해 s1과 s2, s4에는 포워딩 규칙에 영향이 갔고, s3에는 가지 않았으며, 통신계층 프로토콜로 오픈플로우가 사용되었으며 연결 상태 라우팅을 사용했다고 가정하자.
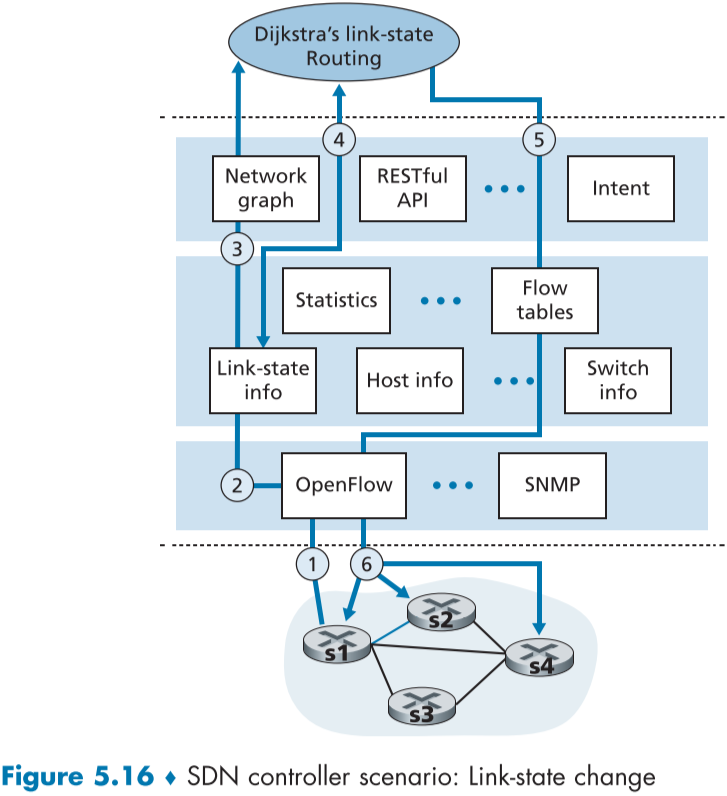
- 스위치 s1이 s2와의 연결이 실패하자, SDN 컨트롤러에게 연결 상태 변경을 오픈 플로우 포트 상태(port-status) 메시지로 통보한다.
- SDN 컨트롤러가 연결 상태 변경에 관한 메시지를 받고 연결 상태 데이터베이스를 갱신한다.
- 다익스트라 연결 상태 라우팅이 구현되어 있는 네트워크 제어 어플리케이션이 사전에 연결 상태가 바뀌면 알림을 받도록 되어 있었고, 연결 상태가 바뀌자 연결 상태 변경의 통지를 받는다.
- 연결 상태 라우팅 응용 프로그램이 연결 상태 매니저와 상호작용하여 최신 연결 상태를 가져오고, 추가로 상태 관리(state-management) 계층의 다른 요소들과 상담한뒤, 새로운 최소 비용 경로를 계산한다.
- 연결 상태 라우팅 응용 프로그램이 다음에 플로우 테이블 매니저와 상호작용하여 새로운 최소 비용 경로에 기반해 플로우 테이블을 갱신하도록 한다.
- 플로우 테이블 매니저가 오픈 플로우 프로토콜을 통해 영향을 받은 스위치들의 플로우테이블을 바꾼다. - s1(s4를 경유해 s2에 패킷 전송), s2(s4를 통해 s1의 패킷 받음), s4(s1의 패킷을 s2에게 전달해줘야 함)
SDN 컨트롤 측면에서 어떻게 네트워크 계층 라우팅을 라우터별 제어 방법을 대신하여 구현할 수 있는지 알아보았다.
SDN 컨트롤의 장점 중 하나로, 어떻게 최소 비용 경로 뿐만 아니라 다른 기준을 쉽게 적용하여 경로를 구할 수 있었다.
기존의 방법으로는 그러한 기준을 바꾸기 위해 라우터의 소프트웨어를 일일이 바꿔줘야 했지만, SDN에서는 중앙에서 해당 비용 경로를 구하는 소프트웨어나 소프트웨어의 설정값을 바꿔주면 손쉽게 변경이 가능하다.
5.5.4 SDN: 과거와 미래(SDN: Past and Future)
SDN은 최근의 개념이지만, SDN의 데이터 측면과 컨트롤 측면을 나누는 아이디어는 [Feamster 2004, Lakshman 2004, RFC 3746] 등 꽤나 예전부터 등장했으며, ATM 네트워크에서의 예시[van der Merwe 1998, Black 1995]등이 있었다.
에단 프로젝트[Casado 2007]은 중앙 라우팅 관리와 포워딩, match-plus-action 플로우 테이블을 이용한 흐름기반 이더넷 스위치의 개념을 만들었으며 이 실험은 오픈플로우에 큰 영향을 주었다.
상당히 많은 연구 노력이 SDN 구조와 가능성 향상을 목표로 하였고, SDN 혁신으로 컨트롤 측면과 데이터 측면, 전부 일체형 서비스로 제공하는 네트워크 스위치들을 간단한 상용 하드웨어와 복잡한 소프트웨어로 바꿔나가고 있다.
SDN의 일반화는 이전에 배웠던 네트워크 기능 가상화(NFV, network functions virtualization)을 통해 복잡한 미들박스들을 간단한 상용 서버와 스위치, 저장소로 대체하려 하는 시도에 영향을 주었고, 최근에는 SDN의 개념을 AS 내부에서 뿐만 아니라 AS 간에서도 사용해보려고 연구 중이다[Gupta 2014]
SDN 컨트롤러 예시 (SDN CONTROLLER CASE STUDIES: THE OPENDAYLIGHT AND ONOS CONTROLLERS)
과거에는 오직 하나의 SDN 프로토콜 (오픈플로우)와 하나의 SDN 컨트롤러(NOX)만 존재하였지만 최근에는 기업의 맞춤형 컨트롤러 부터 오픈소스까지 다양화되었다.
리눅스 그룹과 함께 오픈소스로 제작된 사업가능 컨트롤러로 OpenDaylight와 ONOS에 대해 알아보자.
OpenDaylight 컨트롤러 (THE OpenDaylight Controller)
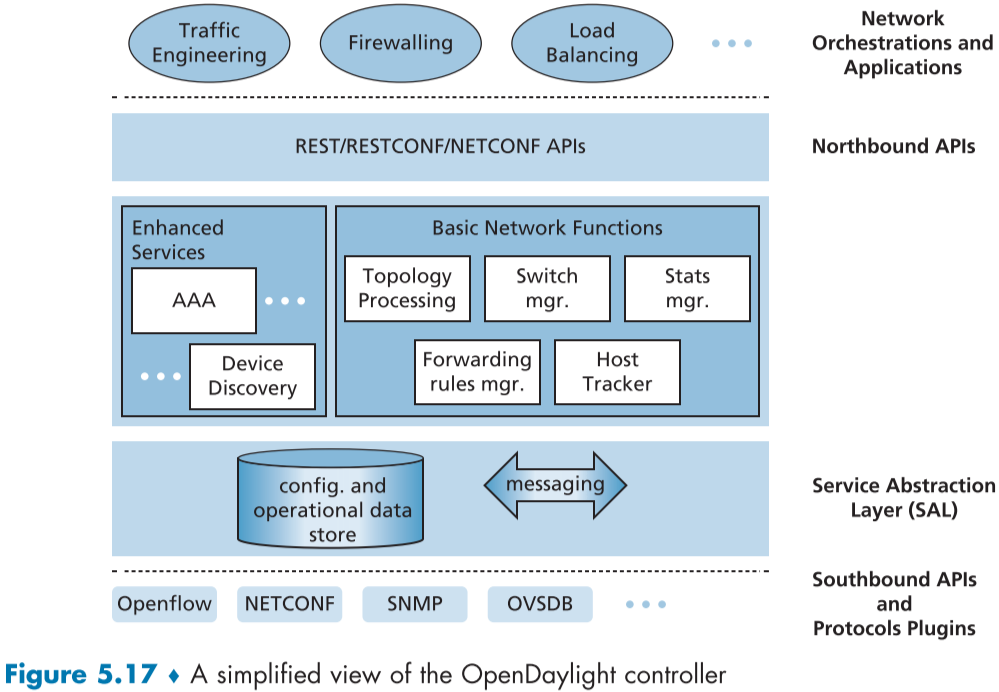
아래 fig.5.17은 OpenDaylight(ODL) 컨트롤러 기반의 간단화된 모습이다.
ODL의 기본 네트워크 기능(Basic Network Functions)은 컨트롤러의 심장부 중간층에 존재하며 네트워크 전역 상태 관리 능력(network-wide state management capability)에 관계있다.
서비스 추상화 계층(SAL, Service Abstraction Layer)는 컨트롤의 중추 심경으로, 남방 경계 쪽에 가깝게 위치해있으며, 컨트롤러 요소와 응용 프로그램이 서로의 서비스를 이용하고 설정과 운영 데이터를 공유하고 서로가 생성하는 이벤트를 구독할 수 있다.
또한 SAL에서는 ODL 컨트롤러와 네트워크 장비들 사이를 연결하는 프로토콜과 통신할 수 있는 정형화된 추상화 인터페이스를 제공한다.
ODL 컨트롤러와 네트워크 장비들 사이를 연결하는 프로토콜의 예시로, 오픈 플로우, NETCONF(Network Configuration), SNMP(Simple Network Management Protocol), OVSDB(vSwitch Database Management Protocol, 데이터센터 스위치에 사용) 등이 존재한다.
네트워크 통합 및 응용 프로그램(Network Orchestrations and Applications)은 데이터 측면 포워딩과 방화벽, 부하 밸런싱 같은 서비스들이 어떻게 네트워크 장치에 동작할 지 결정한다.
응용 프로그램이 컨트롤러 서비스, 컨트롤러 서비스를 통한 네트워크 장치 등과 서로 운영할 수 있게 만드는 두가지 방법이 있는데,
첫번째는 API 기반 방법(AD-SAL)으로, 응용 프로그램이 HTTP 기반의 REST API를 이용해 컨트롤러 모듈과 통신하는 방법이고, ODL 컨트롤러 초기에 사용된 방법이다.
두번째는 ODL이 네트워크 설정 및 관리에 널리 사용되면서 바뀐 방법으로 모델 기반 방식(MDL-SAL)이다.
YANG 데이터 모델링 언어[RFC 6020]이 장치, 프로토콜, 네트워크 설정과 운영 상태 데이터 등의 모델을 정의하고, NETCONF 프로토콜을 통해 이런 데이터들에 조작하여 네트워크 장치들이 설정, 관리되어진다.
ONOS 컨트롤러 (The ONOS Controller)
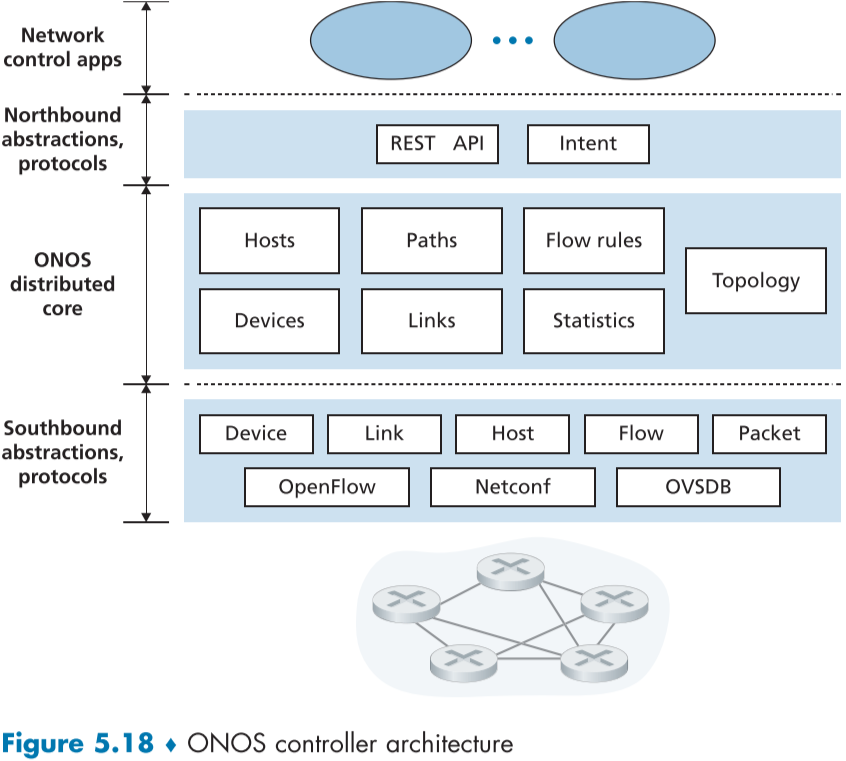
위의 fig.5.18은 ONOS 컨트롤러의 간소화된 그림이다.
표준 컨트롤러 구조와 비슷하게 3가지 층으로 이루어져있다.
-
북방 경계 추상화와 프로토콜(Northbound abstractions and protocols)
ONOS의 프레임워크는 응용 프로그램에게 TCP 연결 설정 또는 금지 같은 고차원 서비스를 작동의 이해없이 요구할 수 있게 해준다.
상태 정보가 북방 경계 API를 통해 네트워크 제어 응용 프로그램에게 동기(쿼리), 또는 비동기적(콜백, 이벤트)으로 제공된다.
-
분산 코어(Distributed core)
네트워크의 상태는 ONOS의 분산 코어에 의해 유지관리되는데, ONOS는 서로 연결된 여러 서버에 ONOS 소프트웨어가 여럿 복사되어 배포되어 서비스를 제공한다.
서비스 인스턴스 간의 복제와 조화를 통해 성능과 서버 장애 문제 없이 위로는 응용 프로그램, 아래로는 네트워크 장치에게 서비스 제공이 가능하다
-
남방 경계 추상화와 프로토콜(Southbound abstractions and protocols)
ONOS의 남방 경계 추상화는 호스트, 네트워크 장치, 프로토콜들의 세세한 원리를 가려 사용자가 구애받지 않게 해주며, 이 때문에 ONOS의 남방 경계 인터페이스는 논리적으로 다른 컨트롤러 구조에 비해 좀더 많은 역할을 수행한다.
5.6 ICMP: 인터넷 컨트롤 메세지 프로토콜 (ICMP: The Internet Control Message Protocol)
인터넷 컨트롤 메세지 프로토콜 (ICMP: The Internet Control Message Protocol)[RFC 792]는 호스트와 라우터가 사용하여 네트워크 계층 정보를 서로 공유하게 해준다.
주로 에러 보고에 사용되며, 예를 들면 HTTP로 요청한 아이피 주소가 존재하지 않다면 에러 메시지로 “Destination network unreachable”이 오는데, 이는 라우터 측에서 해당 아이피로 접근하지 못하니 ICMP 메시지로 에러 메시지를 생성해서 호스트로 되돌려보낸 것이다.
ICMP는 구조적으로 아이피보다 상위 계층인 전달 계층 프로토콜로, TCP와 UDP 세그먼트처럼 아이피 데이터그램의 페이로드에 담겨진다. 아이피 데이터그램 upper-layer 헤더 필드 번호는 1이다.
ICMP 메시지에는 code 필드와 type 필드가 존재하며, 메시지에 오류가 일어난 아이피 데이터그램의 헤더와 첫 8바이트를 포함하고 있어, 수신자에게 어떤 데이터그램이 문제였는지 알 수 있게 한다.
아래 fig.5.19는 ICMP 메시지의 종류이며, ICMP가 에러 메시지로만 쓰이지 않음을 알 수 있다.
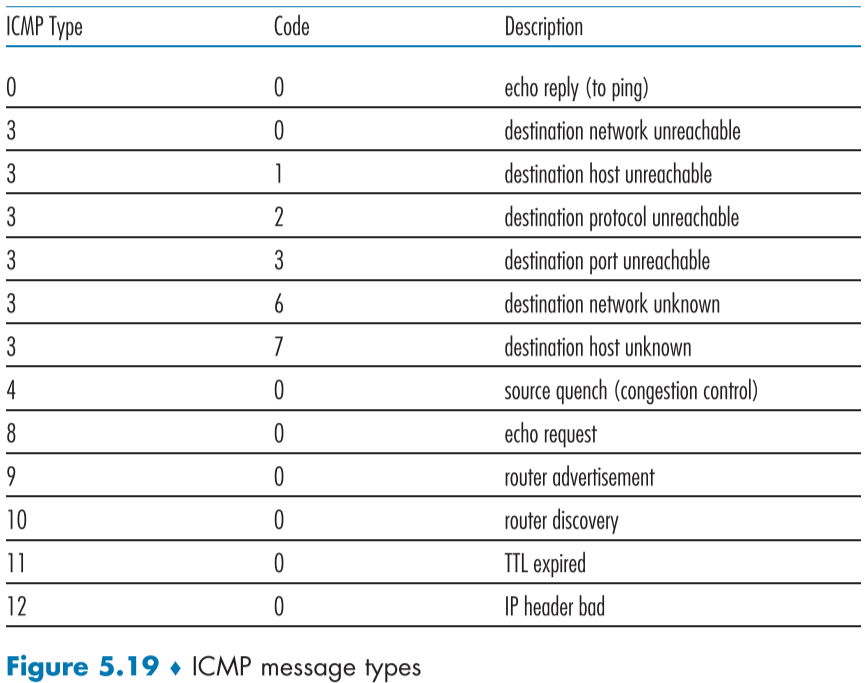
ICMP type 8 code 0를 호스트에게 보내 핑을 구현할 수 있고, 호스트는 핑 메시지를 받고 ICMP type 0 code 0로 응답한다. 대부분은 이러한 ICMP 메시지 생성은 운영체제에서 구현되어 있으며, 클라이언트가 요청하여 만들어준다. 즉, ICMP를 생성하는 것은 프로세서, 응용 프로그램이 아니다. [Stevens 1990]에 핑 클라이언트 프로그램의 코드가 나와있다.
ICMP type 4 code 0는 근원 해소(source quench) 메시지로 TCP 혼잡 제어를 위한 필드인 Explicit Congestion Notification bit 헤더에 밀려 자주 사용되지 않지만 라우터가 해당 메시지를 호스트에게 보내 전송량을 줄이게 만드는 메시지가 원래 의도였다.
Traceroute 프로그램은 ICMP의 type 11 code 0의 TTL expired 메시지를 이용한다. 프로그램은 TTL이 1이고 존재하지 않을법한 UDP 포트 번호가 적힌 UDP 세그먼트를 만들어 목적지를 향해 보낸다. 이때 라우터에서 TTL이 다하면 라우터는 해당 패킷을 버리고 ICMP type 11 code 0 메시지를 돌려보낸다.
- 정확히는, 더 많은 정보를 위해 같은 UDP 세그먼트를 3개씩 보내어 3개의 결과 값을 보게된다.
송신자는 이 ICMP 메시지 내부의 라우터명과 아이피 주소, 라우터의 순서 번호와 측정한 RTT를 보여주고, TTL을 1 증가시킨 UDP 세그먼트를 다시 보내는 과정을 목적지에 도착할 때까지 반복한다.
TTL이 충분히 커져, 목적지에 도착하게 되면 목적지 호스트는 해당 UDP 세그먼트의 포트 번호를 확인하게 되고 존재하지 않는 포트임을 알아 차리고 ICMP type 3 code 3,”port unreachable” 메시지를 돌려주게 되고 , 해당 메시지를 돌려받은 송신자는 목적지에 도착했음 알 수 있다.
traceroute 프로그램을 구현하려면 운영체제에게 ICMP 메시지를 생성시키고, 보내며, 운영체제로 부터 응답 받은 메시지를 받을 수 있어야 한다.
최신버전 ICMP인 ICMPv6는 [RFC 4443]에서 확인할 수 있으며, 기존의 type과 code뿐만 아니라 “Packet Too Big”이나 “unrecognized IPv6 options” 같은 IPv6를 위한 새로운 에러용 type과 code가 추가 되었다.
5.7 네트워크 관리와 SNMP, NETCONF/YANG (Network Management and SNMP, NETCONF/YANG)
네트워크를 관리하는 것은 힘들고 복잡한 일이며, 이를 돕기위한 도구와 기술들이 많이 나와 있으며, 공부해볼 것이다.
네트워크 관리의 정의는 [Saydam 1996]에 다음과 같이 나와있다.
네트워크 관리는 네트워크와 기타 요소를 실시간으로, 운영가능한 성능 하, QOS(Quality of Service) 요구사항에 맞추어, 합리적인 비용으로 모니터링, 테스트, 통계, 설정, 분석, 평가, 조절하기 위한 하드웨어, 소프트웨어, 인적 요소를 배포, 집약, 통합하는 것을 포함한다.
네트워크 관리자의 의사결정 과정, 결함 발견, 이상현상 감지, 서비스 레벨 동의(Service Level Agreements, SLA)에 맞는네트워크 디자인 및 엔지니어링 등의 다른 부분은 배우지 않을 것이다.
자세한 네트워크 관리자에 대한 사항은 [Subramanian 2000; Schonwalder 2010; Claise 2019]와 웹사이트를 참조 바란다.
5.7.1. 네트워크 관리 프레임워크(The Network Management Framework)
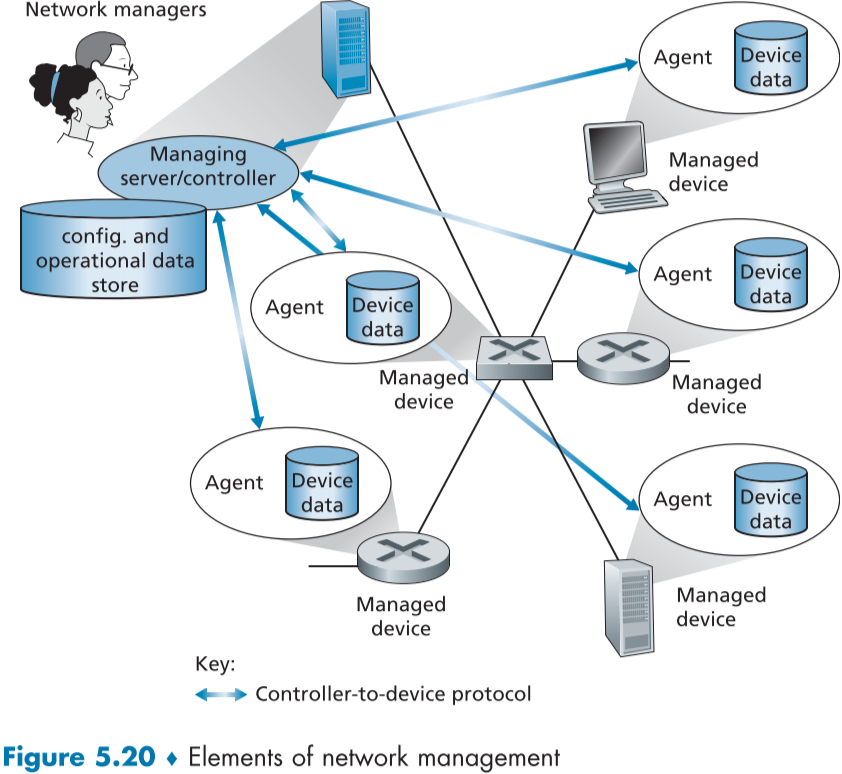
아래 fig.5.20은 네트워크 관리 프레임워크의 주요 요소를 보여주고 있다.
-
관리 서버(Managing server)
관리 서버(managing server)는 네트워크 관리자(network manager)가 네트워크 운영 센터(network operations center, NOC)의 중앙 네트워크 관리 스테이션(cneralized network management station)에서 반복적으로 작동시키고 있는 응용 프로그램이다.
관리 서버는 네트워크 관리 활동의 중심으로, 네트워크 관리 정보와 명령을 수집, 처리, 분석, 발송한다.
네트워크 장비들을 설정, 모니터링, 조종하는 활동이 시작되는 곳이기도 하다.
한 네트워크가 여러 개의 관리서버를 가질 수 있다.
-
관리되는 장치(Managed device)
관리되는 장치는 관리되고 있는 네트워크(managed network)의 소프트웨어를 포함해서 네트워크 장비의 일부이다.
호스트, 라우터, 스위치, 미들박스, 모뎀, 온도계 등 네트워크가 연결되어있는 장비를 의미한다.
장비는 또 추가적으로 관리할 수 있는 요소(호스트나 라우터가 가지고 있는 네트워크 인터페이스 등,)나 그러한 하드웨어와 소프트웨어(OSPF 같은 프로토콜)의 설정 변수를 가질 수 있다.
-
데이터(Data)
각 관리되는 장치는 장치와 관련된 상태(state)라는 데이터를 가지고 있으며, 데이터에는 여러 종류가 있다.
설정 데이터(Configuration data)는 네트워크 관리자가 장치에 설정하는 정보로, 아이피 어드레스, 인터페이스 제한 속도 등이 있다.
운영 데이터(Operational data)는 네트워크를 운영하면서 장치들이 획득하는 정보로, OSPF 등에서의 주변 이웃 라우터 정보 등이 있다.
장치 통계(Device statistics)는 장치가 기록하는 상태 지시자와 횟수 정보로, 차단한 패킷의 수, 장치 쿨링 팬 속도 등이 있다.
장치 관리자는 원격으로 데이터를 읽거나 데이터를 써서 장치를 통제할 수 있으며, 관리 서버에서는 이러한 정보들을 장치와 네트워크 전역에서 가져와 복사본을 저장해 둔다.
-
네트워크 관리 에이전트(Network management agent)
네트워크 관리 에이전트는 관리 서버와 통신하는 관리되는 장치에 돌아가고 있는 소프트웨어로, 관리 서버의 명령에 따라 지역적인 활동을 취한다.
-
네트워크 관리 프로토콜(Network management protocol)
관리 서버와 관리되는 장치 사이에서 작동하며, 관리서버에게 관리 장치의 상태를 읽을 수 있게 하거나 에이전트를 통해 활동하게 한다.
에이전트는 네트워크 관리 프로토콜을 통해 요소 장애나 성능 미달 등의 소식을 관리서버에게 알려줄 수 있다.
중간 매개체 역할을 하지 직접 네트워크를 관리하지 않는다.
현업에서는 네트워크 운영자가 네트워크를 관리할 수 있게 해주는 세개의 요소가 있다.
-
명령어 인터페이스 (Command Line Interface, CLI)
네트워크 관리자는 직접 장치에 포함된 CLI를 이용하거나 Telnet, SSH 프로토콜로 원격에서 명령어나 스크립트를 이용해 장치의 콘솔에 접근할 수 있다.
CLI 명령어는 회사나 장치마다 다를 수 있고, 자동화 및 규모 증강이 힘들며, 오류가 일어날 수 있으므로 소규모 네트워크나 개인 장치 등에만 활용된다.
최근 홈 네트워크 장비의 경우 HTTP를 통해 장치를 제어할 수 있는 환경을 제공한다.
-
SNMP/MIB(Simple Network Management Protocol/Management Information Base)
네트워크 운영자는 관리 정보 베이스(MIB,Management Information Base) 객체가 가지고 있는 데이터를 간단 네트워크 관리 프로토콜(SNMP, Simple Network Management Protocol) 통해 쿼리, 설정 할 수 있다.
일부 MIB는 장비나 회사에 따라 다르지만 많은 MIB(라우터가 차단한 패킷의 수, 호스트가 받은 UDP 패킷 수 등)들이 공통적으로 구현되어있다.
주로 MIB로 정보를 쿼리하거나 장치 상태를 모니터링 하는데 사용되고, CLI를 통해 장치 정보를 설정하거나 제어한다.
두 방법 전부 장치를 하나 하나 접근하는 방법이므로, 규모가 큰 방법에 좋은 방법이 아니다.
-
NETCONF/YANG
정확성 제한 같은 설정 관리 측이 강조되어 세세하면서도 여러 장치를 동시에 관리할 수 있게 해주어 좀더 추상화되고 네트워크 전역의 전체론적인 네트워크를 가능하게 해준다.
YANG[RFC 6020]은 설정과 운용 데이터의 모델을 설정하는 데 사용되는 데이터 모델링 언어이며, NETCONF 프로토콜[RFC 6241]은 원격장치 간/에/로 부터 YANG에 호환되는 활동과 데이터를 주고 받는데 사용된다.
5.7.2.간단 네트워크 관리 프로토콜(SNMP, Simple Network Management Protocol)와 관리 정보 베이스(MIB) (The Simple Network Management Protocol(SNMP) and the Management Information Base (MIB, Management Information Base))
간단 네트워크 관리 프로토콜 버전 3(SNMPv3, Simple Network Management Protocol v3)[RFC 3410]는 관리 서버와 관리 서버의 지시대로 행동하는 에이전트 사이에 네트워크 관리 정보 메시지와 제어 메시지를 전하는 응용 계층 프로토콜이다.
SNMP의 가장 흔한 사용법은 SNMP와 에이전트 간의 요청-응답(request-response) 모드로, 요청을 받으면, 요청 대로 행동한 뒤, 응답 메시지를 돌려 보낸다.
보통은 관리되는 장치 관련 MIB 객체를 쿼리하거나 수정하는 요구가 많다.
두번째 사용법은 에이전트가 링크 인터페이스의 장애 등의 예외적인 상황에서 관리 서버에게 요청하지 않았어도 보고를 위한 메시지를 보낸다. 이를 Trap 메시지라고 한다.
MIB 객체는 SMI(Structure of Management Information, 관리 정보 구조)라는 의미불명의 이름을 가진 데이터 묘사 언어(data description language)로 표현된다.
형식 정의 언어는 주로 네트워크 관리 데이터의 의미와 구문이 애매모호하지 않게 잘정의되었는 지 확인하는데 사용됩니다.
MIB 모듈은 연관된 MIB들의 모임으로, 현재 MIB는 400개 이상의 연관된 RFC 문서를 가지고 회사마다 다른 MIB 모듈을 가지고 있다.
SNMPv3는 PDU(protocol data units라고 불리우는 7종류의 메시지를 정의하였고, 아래 Table.5.2와 Fig.5.21에서 형식과 예시를 볼 수 있다.

-
GetRequest, GetNextRequest, GetBulkRequest PDU
관리서버가 에이전트에게 관리되는 장치로 부터 하나 이상의 MIB 오브젝트 인스턴스를 요청한다. 요구된 MIB 오브젝트는 PDU의 변수 공간의 일부에 자신의 값을 채워넣고 돌려준다.
GetRequest : 임의의 MIB 값들의 집합을 요구
GetNextRequest: 여러 GetNextRequest를 보내서 MIB 객체 표나 리스트로 만들어 받음
GetBulkRequest: 한꺼번에 대량의 데이터를 받을 수 있음
-
SetRequest PDU
관리 서버가 하나 이상의 장치의 MIB 객체의 값을 설정하도록 에이전트에게 요청, 에이전트는 “noError” 에러 상태를 가진 Response PDU를 응답 메시지로 보내 확인시켜준다.
SNMPv1 시절에는 보안상의 이유로 거의 안쓰였다.
-
InformRequest PDU
관리 서버가 다른 관리서버에게 해당 관리서버가 닿을 수 없는 MIB 정보를 보내주는데 사용
-
Response PDU
관리되는 장치가 관리 서버에게 응답 메시지로 보내 요청 받은 정보를 돌려주는데 사용
-
Trap 메시지
관리 서버에게 필요한 알림 이벤트가 발생할 시 관리서버에게 알리기 위해 비동기적으로 생성되는 메시지, RFC 3418에 여러 기본 trap type이 정의되어있다. 예를 들어, 링크의 작동 여부, 인증 실패, 이웃 장치의 손실 등이다.
Trap 메시지를 받은 관리서버는 이에 응답 메시지를 보내지 않아도 된다.
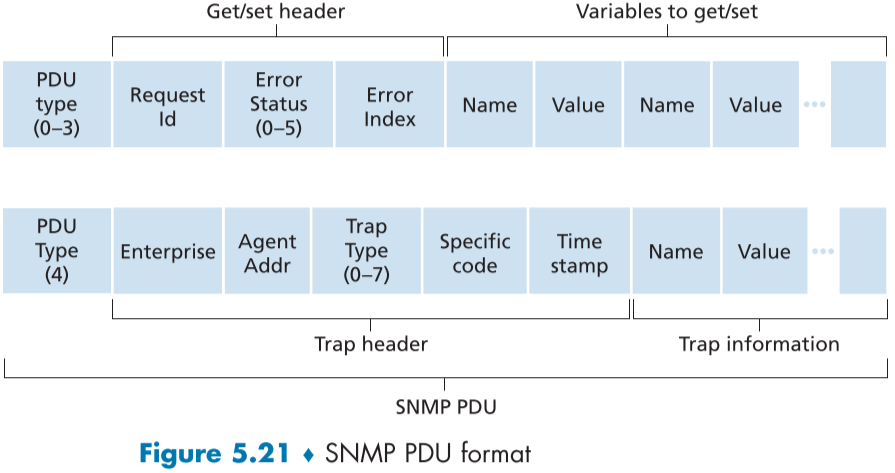
SNMP PDU는 다양한 전달 프로토콜을 통해 전달될 수 있지만, UDP 다이어그램을 권장하며, 가장 많이 사용된다.
하지만 UDP는 reliable data transfer를 지원하지 않으므로, PDU에 Request Id 헤더 필드를 이용한다.
관리 서버는 이 PDU에 해당 필드에 요청 번호를 부여하여, 에이전트가 응답 메시지에 기입하도록 한다.
이를 통해 응답 메시지가 오지 않은 PDU를 알 수 있고, SNMP는 재전송이 의무가 아니므로 일정 시간이 기다린 뒤, 재전송하거나 다른 행동을 취한다.
SNMP는 SNMPv1부터 SNMPv3까지 있으며 최신 버전은 보안과 관리 능력이 좋아졌다.
관리 정보 베이스(MIB) (The Management Information Base (MIB))
우리는 SNMP/MIB에서 관리되는 장치들의 운영 상태, 설정 데이터 등이 MIB의 형태로 장치에 저장된다고 배웠다.
MIB 오브젝트는 라우터에서 폐기된 IP 데이터그램의 숫자, DNS 서버의 버전 묘사 정보 등이 될 수 있다.
관련된 MIB 객체들은 MIB 모듈로 모이게 되고, 용도별, 장비별, 회사별 등으로 400여개의 MIB 모듈이 IETC RFC에 정의되어있다.
아래는 IP와 ICMP를 구현을 관리하기 위한 MIB 객체의 설명 예시이다.

ipSystemStatsinDelivers 객체 타입
구문 Counter32
최대 접근 권한 읽기만 가능
상태 사용 가능
묘사
"ICMP와 IP 사용자 프로토콜에 성공적으로 전달된 전체 데이터그램 숫자.
인터페이스 통계에서는 앞서 말한 데이터그램들이 전달된 인터페이스의 카운터는 증가한다. 이 인터페이스는 일부 데이터그램의 입력 인터페이스와 다를 수 있다.
카운터의 기록의 불연속성은, 관리 시스템의 재시작 또는 ipSystemStatsDiscontinuityTime의 값이 지시한 시간대로 인해 일어날 수 있다.
"
:: = { ipSystemStatsEntry 18 }
5.7.3.네트워크 설정 프로토콜(NETCONF)과 YANG(The Network Configuration Protocol (NETCONF) and YANG)
NETCONF 프로토콜은 관리 서버와 관리 네트워크 장비 사이에서 사용되는 프로토콜로,
- 관리 장치의 설정 데이터를 설정, 수정, 쿼리해주는 메시지
- 관리 서버가 장치의 설정하는 XML 문서 메시지를 통해 능동적으로 관리 장치 조종 가능
- 관리 장치의 운영 데이터와 통계를 쿼리해주는 메시지
- 관리 장치가 생성하는 알림을 구독하는 메시지
를 제공한다.
NETCONF은 원격 프로시저 호출(remote procedure, RPC) 패러다임을 사용하는 데, 이는 프로토콜 메시지가 XML로 인코딩 되고, 관리 서버와 관리되는 장치 간에 TLS (Transport Layer Security) 프로토콜 같은 보안이 보장된 연결 중심 세션을 이용하는 것을 의미한다.
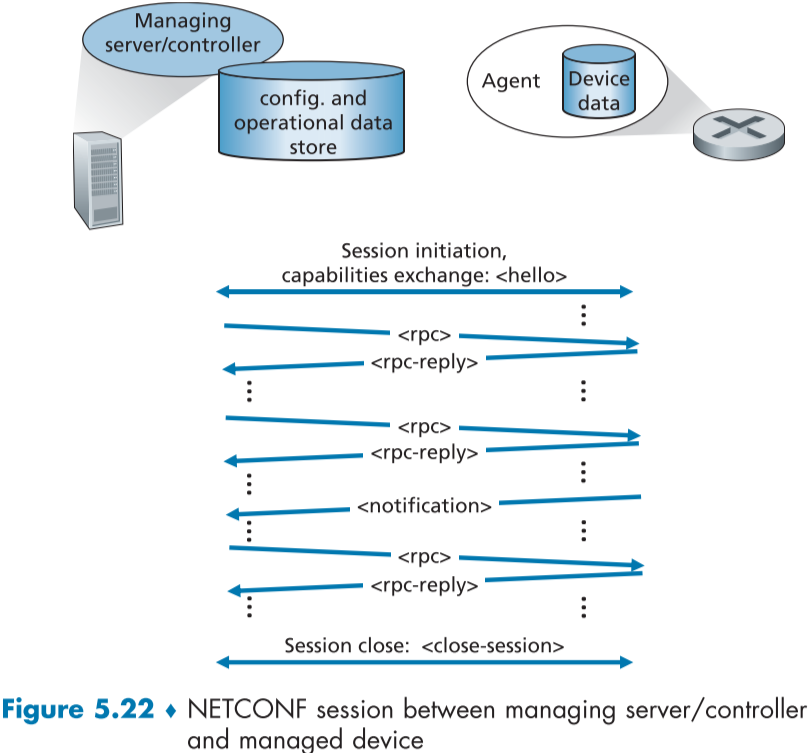
위의 Figure 5.22는 NETCONF의 예시이다.
- 관리 서버가 클라이언트 역할, 관리되는 장치가 서버 역할로 보안 연결을 수립한다.
- 연결이 수립되면 서로
메시지를 주고 받고 자신의 역량(capabilities, NETCONF 기능 중 하나[RFC 6241])을 선언한다. - RPC의 형태로 서버와 장치 간에
와 를 사용해 상호작용한다. - 이러한 메시지들은 설정, 운영, 통계, 데이터 등을 읽고 쓰고, 수정하게 해주며, 장치의 알림을 구독하게 해준다
- 장치는 서버 측에 해당함에도,
메시지를 통해 일어난 이벤트를 서버측에 전달할 수 있다. - 세션은
message를 보냄으로 종료된다.

-
: 장치의 해당 설정을 전부 또는 일부를 가져옴, 장치는 여러 설정을 가지고 있으며 장치가 현재 실행되고 있는가를 의미하는 running/ 설정은 언제나 가지고 있다. -
: 설정 상태와 운용 상태 데이터를 전부 또는 일부 가져옴 -
: 관리되는 장치로부터 주어진 설정 값으로 설정을 전부 또는 일부 바꿈, 예를 들어 running/ 값을 off로 바꾸면 장치가 꺼질 것이다. 받아들일 수 있는 명령이라면 장치는 요소가 포함되어 있는 메시지를 돌려줄 것이며, 아니면 메시지가 응답으로 간다. 에러가 난 상황에서는 명령을 실행하기 이전의 상태로 롤백된다. -
, : 관리 서버가 관리되는 장치들의 전체 설정 데이터 저장소 시스템을 잠그거나 해제할 수 있다. lock은 NETCONF, SNMP, CLI 등으로 상호작용 하는 동안, 다른 곳의 변경으로 인한 충돌을 방지하기 위해 짧게 유지한다. -
, : 대상 장치가 특수한 상황이 발생할 때 서버측에 변화 정보를 보내주는 비동기 이벤트 을 보내주는 이벤트 알림 구독(event notification subscription)을 설정한다. 알림 구독은 해제할 수 있다.
Table 5.3은 NETCONF 동작 중 중요한 몇몇 예시이다. 추가적인 NETCONF는 [RFC 6241, RFC 5277, Claise 2019; Schonwalder 2010] 참조.
_articles/computer_science/network/네트워크 정리-Chap 5-네트워크 계층-컨트롤 측면.md