풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
네트워크 정리-Chap 4-네트워크 계층-데이터 측면
Chapter 4. 네트워크 계층: 데이터 측면(Network Layer: Data plane)
- 4.1 네트워크 계층 개요(Overview of Network Layer)
- 4.2 라우터의 내부(What’s Inside a Router)
- 4.3 인터넷 프로토콜(IP) : IPv4, 어드레싱, IPv6, 등등 (The Internet Protocol (IP): IPv4, Addressing, IPv6, and More)
- 4.4.일반화된 포워딩과 SDN (Generalized Forwarding and SDN)
- 4.5 미들 박스(Middleboxes)
Computer Networking: A Top-Down Approach(Jim Kurose, Keith Ross)의 강의를 정리한 내용입니다.
( Jim Kurose Homepage )student resources : Companion Website, Computer Networking: a Top-Down Approach, 8/e
우리는 이전 챕터에서 네트워크 계층의 서비스를 몰라도 이전 계층 서비스들의 동작들을 배울 수 있었다.
이제 네트워크 계층가 진행하는 호스트간 통신에 대하여 배워보자.
네트워크 계층은 앞서 배운 계층들과 다르게 네트워크 장비와 호스트에 모두 구현되어 있으며, 그에 따라 복잡하고 흥미로운 주제이기도 하다.
복잡한 네트워크 계층을 데이터 측면과 컨트롤 측면으로 나누어 두 챕터 동안 배울 예정이다.
데이터 측면에서는 라우터에서 하는 일인, 데이터그램이 어떻게 라우터에서 올바른 다른 라우터 링크로 포워딩되는가에 대해서 알아볼 예정이다.
5장에서는 컨트롤 측면에서는 네트워크 계층이 어떻게 데이터그램의 목적 호스트에 도착할 수 있게, 올바른 라우터 경로를 형성하는가에 대해서 알아볼 것이다.
라우팅 알고리즘 뿐만 아니라, OSPF, BGP 등의 라우팅 프로토콜도 알아볼 것이다.
보통 이 두 측면은 라우터 하나에 함께 구현되어 있지만, 소프트웨어 정의 네트워크(SDN, Software-defiend Network)에서는 각자 컨트롤러(controller)에 따로 구현한다.
이렇게 역할에 따라 두 측면으로 나누는 것이 이해에 도움이 될 것 이다.
4.1 네트워크 계층 개요(Overview of Network Layer)
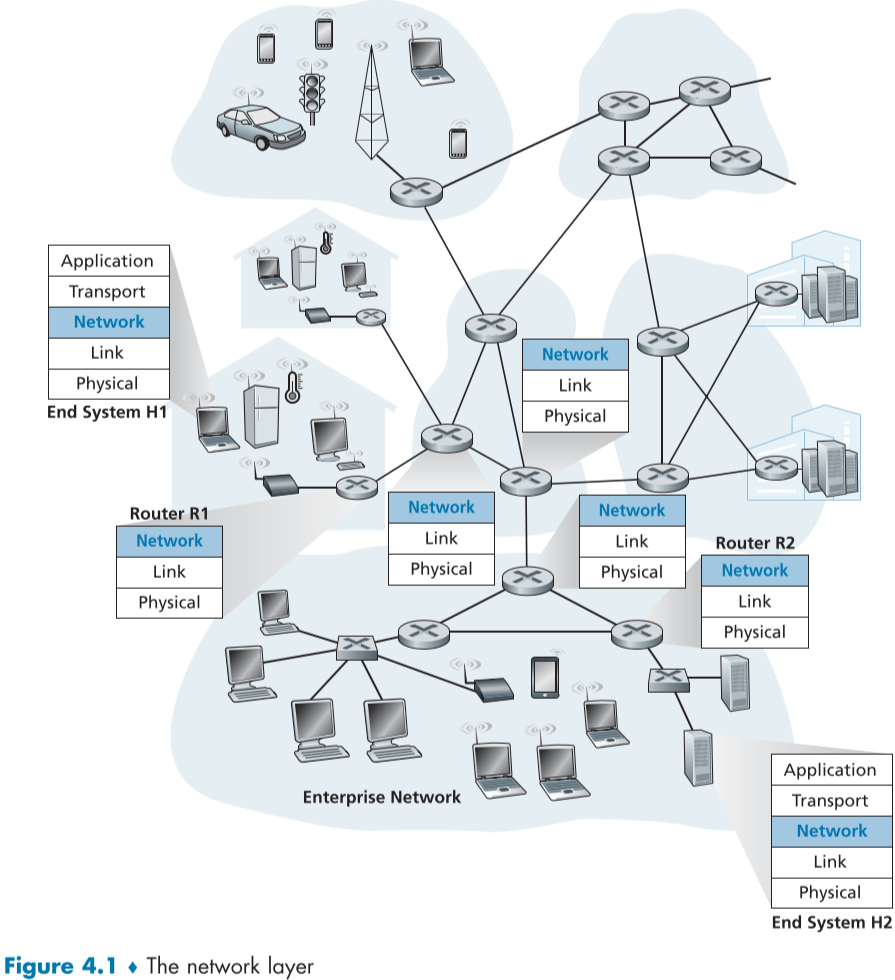
아래 fig4.1과 같이 두 호스트 H1과 호스트 H2가 라우터 R1과 라우터 R2를 포함한 경로를 통해 통신하는 과정을 살펴보자.
H1은 H2에게 데이터를 보내려하면, 트랜스포트 계층의 세그먼트가 네트워크 계층에서 데이터그램으로 캡슐화되면서 가까운 라우터인 R1으로 보내진다.
이윽고 R2를 거쳐 H2에 도달한다.
각 라우터의 네트워크 계층의 데이터 측면의 역할은 데이터그램들을 입력 링크에서 알맞은 출력 링크로 포워드하는 것이다.
네트워크 계층의 컨트롤 측면의 역할은 데이터 측면의 행동 같은 라우터 별 포워딩들을 알맞게 편성하여 궁극적으로 호스트 간의 통신하는 것이다.
그림에서 라우터들이 네트워크 계층 위로 없는 것을 주목하자, 라우터는 어플리케이션을 돌리지 않으며, 전달 계층도 필요하지 않다.
4.1.1 포워딩과 라우팅: 데이터와 컨트롤 측면 (Forwarding and Routing: The Data and Control Planes)
결국, 네트워크 계층의 궁극적인 목적은 송신 호스트에서 수신 호스트로 패킷을 이동시키는 것이다. 이를 위한 두가지 중요한 기능은
-
데이터 측면의 포워딩(Forwarding)
- 패킷이 라우터의 입력 링크에 도착하면 라우터는 해당 패킷을 목적 호스트에 도착하는 길에서 다음 라우터에 해당하는 출력 링크에 보내야 한다.
- 악의적인 호스트에게서 온 패킷이나 접근 불가한 호스트에게 가는 패킷을 block시키거나, 패킷을 복사하여 여러 링크에 동시에 뿌리는 일도 맡는다.
- 주로 하드웨어에서 실행되며, 수 ns(나노세컨드) 정도로 짧게 소요됨.
- 자동차 여행 중에 도로의 분기점에서 올바른 도로로 선택해서 가는 것과 같다.
-
컨트롤 측면의 라우팅(Routing)
- 네트워크 계층에서는 수신 호스트에 도착하기 위해 패킷이 흘러갈 일종의 길이나 경로를 설정해야한다.
- 이러한 경로를 만드는 알고리즘을 라우팅 알고리즘(routing algorithm)이라고 하며, 이는 컨트롤 측면에서 정의된다.
- 주로 소프트웨어에서 실행되며, 1초 정도로 길게 소요됨
- 자동차 여행 출발 전, 플로리다에서 뉴욕까지 가는 전체 경로를 계획하는 것과 같다.
각 라우터에는 포워딩 테이블이 존재하는데, 라우터는 패킷이 들어오면 해당 패킷의 헤더의 한개 이상의 필드를 살펴보고 필드의 값으로 포워딩 테이블을 색인하여 패킷을 알맞은 링크로 나아가게 한다.
포워딩 테이블에 담긴 값은 해당 라우터의 외부 출력 링크(outgoing link)의 인터페이스(일종의 정보 교환 수단)이다.
컨트롤 측면: 전통적인 접근방법 (Control Plane: The Traditional Approach)
그렇다면 처음에 라우터는 어떻게 포워딩 테이블을 얻을 수 있는가?
아래 그림에서 보듯, 전통적인 방법에서는 라우팅 알고리즘이 라우터의 포워딩 테이블을 결정한다.
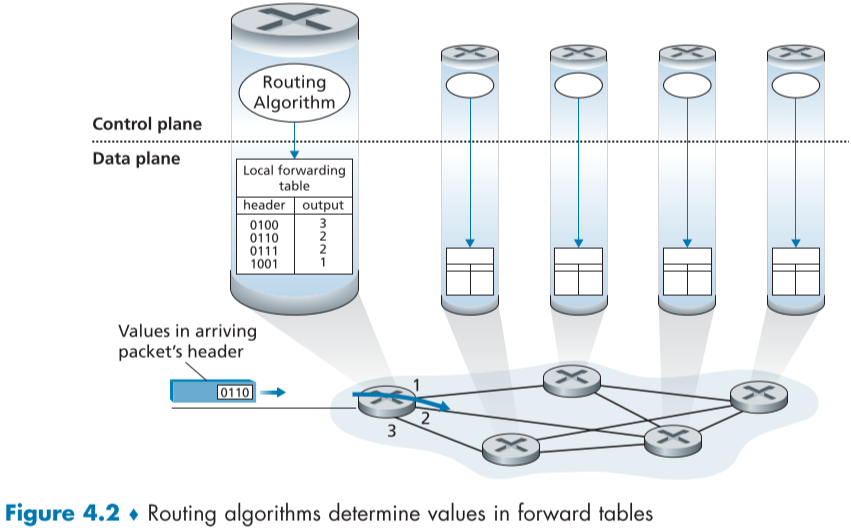
컨트롤 측면에 속한 라우팅 알고리즘이 각 라우터에서 실행되며, 한 라우터의 라우팅 알고리즘이 다른 라우터의 라우팅 알고리즘과 통신하며, 데이터 측면의 포워딩 테이블의 값을 결정한다.
이때의 통신은 라우팅 프로토콜을 지키는 라우팅 메시지를 주고 받음으로써 실시된다.
컨트롤 측면: SDN의 접근방법(Control Plane: The SDN Approach)
위에서 우리는 컨트롤 측면의 기능인 라우팅 알고리즘이 데이터 측면의 기능인 포워딩 테이블을 정해주는 것을 보았고, 이는 오랫동안 라우터 생산자들이 사용했던 방법이다.
데이터 측면의 포워딩 테이블을 결정해주는 컨트롤 측면의 또 다른 기능은 없을까?
아래 그림이 설명하는 그러한 방법은 물리적으로 분리되었는 원격 컨트롤러(Remote Controller)가 각 라우터가 사용할 포워딩 테이블을 계산하고 분배하는 방법이다.
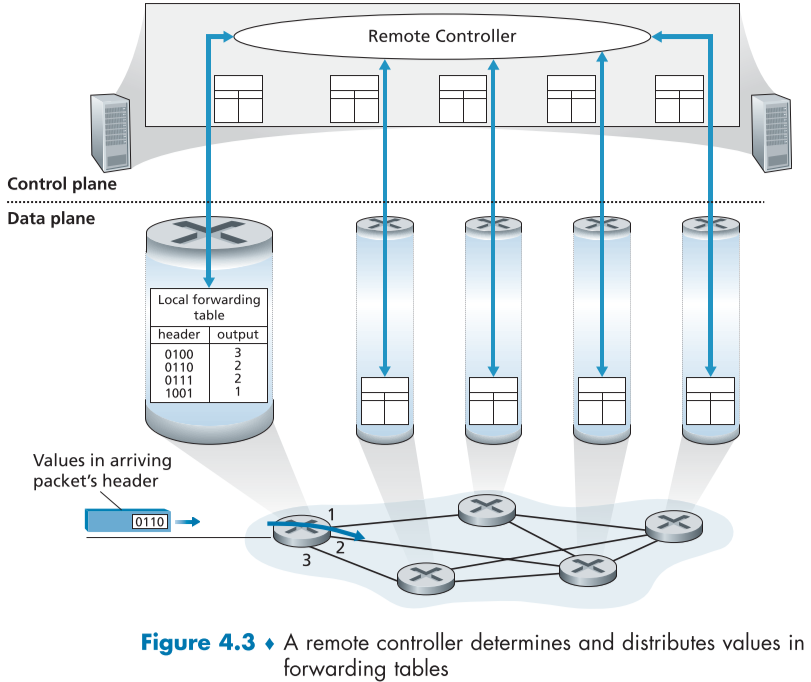
위의 전통적인 방법과 다른 점은, 컨트롤 측면의 기능이 같은 라우터에 존재하는게 아니라 물리적으로 떨어진 다른 시스템이 진행한다는 점이다.
이때 라우터는 오직 데이터 측면의 포워딩만 진행하며, 컨트롤 측면은 다른 시스템이 대신 해준다고 볼 수 있다.
이러한 원격 컨트롤러는 높은 신뢰성과 보안을 자랑하는 원격 데이터 센터 내부에 ISP가 구현하며, 이때 원격 컨트롤러는 각 라우터와 forwarding table이 포함되어 있는 메시지를 교환하여 통신한다.
이 방법은 소프트웨어 정의 네트워킹(SDN, software-defined networking)의 핵심이며, 스프트웨어 정의 네트워크는 해당 원격 컨트롤러를 소프트웨어로 구현하기 때문에 이렇게 불리운다.
오픈소스로 많이 나와있기 때문에 코드를 살필 수 있다.
4.1.2.네트워크 서비스 모델(Network Service Model)
네트워크 측면에 더 알아보기 전에 네트워크 서비스 모델에 대해 알아보자.
전달 계층에서 네트워크 서비스에 데이터를 줄 때, 어떠한 서비스(데이터 신뢰 통신? 혼잡 제어?)를 받을 수 있을까?
전달 계층에 제공해줄 서비스를 결정하는 것이 바로 네트워크 서비스 모델이다.
네트워크 서비스 모델에 따라 패킷의 통신의 성격이 달라지게 된다.
예를 들어 네트워크 계층이 줄 수 있는 서비스의 예시로,
- 보장된 전달(Guaranteed delivery) : 해당 패킷이 확실히 목표 호스트에 도달할 수 있음을 보장하는 서비스
- 제한된 지연 내로 보장된 전달(Guaranteed delivery with bounded delay) : 위의 서비스에 추가로 호스트간 최소 딜레이를 보장한다.
- 순차 패킷 전달 (In-order packet delivery) : 패킷의 순서가 뒤섞이지 않고 원래 순서대로 통신하는 것을 보장한다.
- 최소 대역폭 보장(Guaranteed minimal bandwidth) : 특정 bit rate 이상의 전송 속도 보장
- 보안(Security) : 네트워크 계층에서 모든 데이터그램을 암호화하고 목적 호스트에서 복호화하여 보안성 보장.
등 등..
인터넷 구조의 네트워크 계층이 제공하는 서비스는 최선 서비스(best-effort service) 하나이다.
최선 서비스(best-effort service)에서는 통신은 하되 결과의 모든 걸 보장하지 않는다.
즉, 지연될 수도, 패킷 내용이 바뀔 수도, 없어질 수도, 순서가 바뀔 수도 있다는 것이다.
ATM 네트워크 구조의 네트워크 계층이 최소 딜레이, 순서와 최소 대역폭을 보장하며, 인터넷 구조를 개선하기 위한 Intserv 구조[RFC 1633]에서도 최소 딜레이와 무 혼잡 통신을 보장하지만, 사용되지 않고 있다.
대신, 대역폭 확보(Bandwidth provisioning)과 대역폭 적응형 어플리케이션 프로토콜(bandwidth-adaptive application-level protocol, 예를 들어 DASH 등) 등의 활약으로 고성능 멀티미디어 어플리케이션(유튜브, 넷플릭스, 스카이프…)을 돌릴 수 있게 되었다.
챕터 4의 개요 (An Overview of Chapter 4)
이제 네트워크 계층의 데이터 측면에 대해 알아볼 것이다.
포워딩(forwarding)과 스위칭(switching)은 사람들이 많이 의미를 혼용해서 사용하고 여기서도 그럴 것이지만,
라우터(router)는 네트워크 계층에서의 데이터그램의 헤더 필드를 보고 스위칭하는 스위치 장비로,
링크 계층 스위치(link-layer switch)는 링크 계층에서의 패킷의 헤더 필드를 보고 스위칭하는 스위치 장비로 구별해서 부를 것이다.
4.2 라우터의 내부(What’s Inside a Router)
라우터에 입력 링크에서 입력된 패킷을 알맞은 출력 링크로 전달하는 역할을 하는 포워딩 기능에 대해 알아보자
아래는 일반적인 라우터 구조를 표현한 것이다.
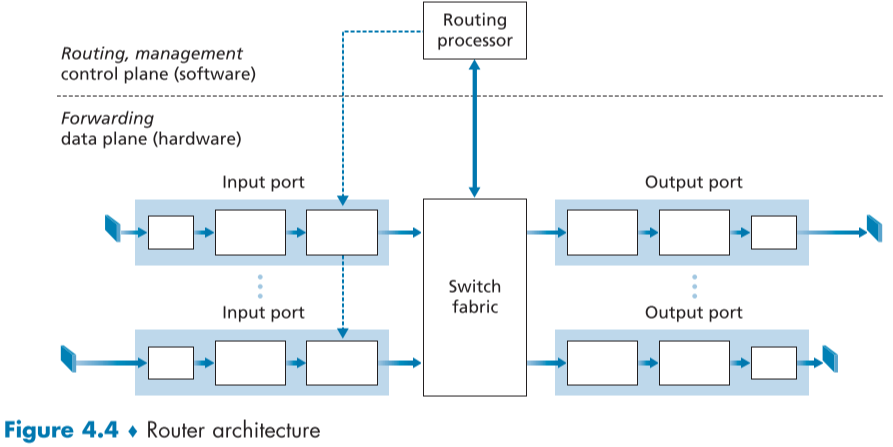
그림에서 총 4개의 부분을 구별할 수 있다.
-
입력 포트들(Input ports)
여기에서의 포트는 앞서 배웠던 소켓과 어플리케이션의 포트를 의미하지 않으며, 포트는 라우터의 물리적인 입출력 인터페이스(꽂는 구멍)를 의미한다.
- 10여개의 10 Gbps 포트를 가진 기업용 라우터에서부터 800개의 100Gbps 이더넷 포트를 가진 엣지 라우터까지 다양하다.
라우터의 물리적 링크(그림에서 왼쪽, 또는 오른쪽 끝에 있는 파란색 박스)를 종료하는 물리 계층 기능 담당
반대쪽에 들어오는(incoming) 링크의 링크 계층(파란 포트 사각형 안에 하얀 박스들)와 상호운용(interop)하는데 필요한 기능 담당
가장 중요한 기능으로, 룩업(look up) 기능 담당(위 입력 포트 박스의 오른쪽 끝, 포워딩 테이블을 참조하여 스위치 패브릭을 통해 적절한 출력 포트에 배정)
라우팅 프로토콜 정보가 담긴 컨트롤 패킷 같은 경우 입력 포트에서 라우팅 프로세서로 보낸다.
-
스위칭 패브릭 또는 스위칭 매트릭스(Switch fabric)
입력 포트와 출력 포트를 연결하는 역할, 일종의 라우터 내부의 네트워크, 입출력 포트들과의 가상의 회선이 마치 직물과도 같다고 해서 이렇게 불리운다.
-
출력 포트들(Output ports)
스위칭 패브릭에게 받은 패킷을 저장해두고 링크 계층, 물리 계층 기능을 통해 나가는(outgoing) 링크로 보낸다., 양방향 링크일 경우 같은 라인 카드의 입력 포트와 쌍을 이룸?
-
라우팅 프로세서(Routing processor)
과거에는 라우팅 테이블과 부착된 링크 상태 정보, 포워딩 테이블을 유지 관리하는 컨트롤 측면 기능을 수행
SDN 라우터에서는 라우팅 프로세서가 원격 컨트롤러와 통신하여 포워딩 테이블 항목을 받아와 라우터 입력 포트에 설치 하는 역할을 함.
나중에 배울 네트워크 관리 기능도 수행
위 4개 부분은 거의 모든 라우터에서 하드웨어로 구현되었으며, 여러 포트의 데이터그램 처리 파이프라인으로 데이터그램을 처리가능해 소프트웨어 구현에 비해 더 빠를 수 있었다.
이러한 데이터 측면 동작이 ns 수준의 빠른 처리가 가능하다면, 라우터의 컨트롤 측면(라우팅 프로토콜 실행, 링크에 대한 응답, 원격 컨트롤러와의 통신, 관리 기능 등)은 ms~s 수준으로, 보통 라우팅 프로세서(CPU) 내에서 소프트웨어로 처리된다.
또한, 자동차가 로터리에서 잠시 고민할 때 처럼, 패킷들도 라우팅될 때 처리가 필요한데, 그때 필요한 정보는 다음과 같다.
-
목적지 기반 포워딩(Destination-based forwarding)
자동차가 출발 하자마자 로터리 한번만 지나면 목적지에 도착하는 상황이라면, 로터리 안내원은 어느 도로 출구가 목적지인지 구별해야 한다.(패킷의 목적지 호스트 주소)
-
일반화된 포워딩(Generalized forwarding)
자동차의 도로 출구는 또한, 자동차의 정보(패킷의 헤더)(번호판, 자동차 모델, 생상년도)에 따라 차별화할 수 있을 것이다.
예를 들어, 일부 특별 회원에게는 속도가 빠른 도로출구로 보내주고, 아닌 회원에게는 느린 회선을 줄 수 있다.
자동차가 출구를 결정하고 떠날 때, 같은 결정을 한 여러 자동차에 의해 밀릴 수도 있다.
이러한 비유를 들자면 진입 도로와 스테이션은 입력 포트이며, 로터리는 스위칭 패브릭, 로터리 출구는 출력 포트라고 생각하면 되며, 자동차 러쉬아워 처럼 병목현상을 겪을 수도 있으며, 안내원이 일처리속도가 느리면 대기열 등이 생기거나, 처음보는 차는 차별화 할 수 없는 등의 문제가 생긴다.
이후에 라우터 기능에 대해 알아볼 때 이해하기 쉽도록, 일단 패킷의 헤더는 보지않고 도착 주소만 보고 판단하다고 가정할 것이다.
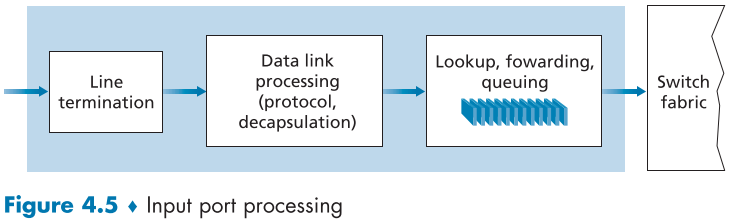
4.2.1.입력 포트 처리와 목적지 기반 포워딩(Input Port Processing and Destination-Based Forwarding)
fig.4.5는 입력 패킷 처리에 대한 그림이다.
입력 포트는 앞서 설명한 기능과 라우터 기능의 핵심인 룩업 기능을 포워딩 테이블을 통해 실행해 패킷을 스위칭 패브릭을 통해 보내며, 포워딩 테이블은 라우팅 테이블에 의해 다른 라우터의 프로세서와 상호작용을 통해 가져오거나, SDN의 경우 원격 컨트롤러에 의해 처리된다.
포워딩 테이블은 라우팅 프로세서에서 복사되어 라인 카드로 버스(일종의 데이터 통로, fig4.4의 점선, PCI bus 등이 존재)를 통해 전달되어, 각 라인 카드마다 입력 포트에 의해 개별 처리되므로 라우팅 프로세서를 이용할 필요없어, 프로세서 병목 현상이 일어나지 않는다.
패킷이 스위칭되어 도착할 출력 포트를 패킷의 목적지 주소를 통해 구해야하는 상황에서 32비트 아이피 주소를 이용해 포워딩 테이블과 대조하려면 브루트 포스를 이용할 경우 도합 $2^{32}$개의 주소를 대입해야하며, 이는 불가능하다.
다음과 같이 라우터에 0부터 3까지 4개의 링크가 있고 링크 인터페이스는 다음과 같다고 생각 하자.
| Destination Address Range | Link Interface |
|---|---|
| 11001000 00010111 00010000 00000000부터 11001000 00010111 00010111 11111111까지 | 0 |
| 11001000 00010111 00011000 00000000부터 11001000 00010111 00011000 11111111까지 | 1 |
| 11001000 00010111 00011001 00000000부터 11001000 00010111 00011111 11111111까지 | 2 |
| 나머지 | 3 |
이 예시에서는 확실히 $2^{32}$를 전부 볼 필요는 없어보인다.
극단적으로 아이피 범위에서 겹치는 접두어(prefix)를 이용하면 4개의 항목으로 줄일 수 있는데,
| Prefix | Link Interface |
|---|---|
| 11001000 00010111 000110 | 0 |
| 11001000 00010111 00011000 | 1 |
| 11001000 00010111 00011 | 2 |
| Otherwise | 3 |
이런 식으로 라우터는 포워딩 테이블의 항목들의 접두어(Prefix)를 패킷의 목적지 주소와 대조하여 일치하는 링크 인터페이스로 보낸다.
만약 11001000 00010111 00011000 110101110 처럼 여러 접두어와 일치하는 경우에는 가장 길게 일치된 링크 인터페이스로 보내며, 위의 경우 1번이다.
이러한 방법을 최장 접두어 일치(Longest prefix matching)이라고 하며, 접두어가 가장 길게 일치하는 테이블의 항목으로 패킷을 보내게 된다.
자세한 사항은 4.3절에서 추가설명할 것이다.
포워드 테이블의 존재 덕분에 룩업 기능은 하드웨어적으로 간단하게 최장 접두어 일치만 찾으면 되며, ns 수준의 빠른 성능을 자랑하게 되었다.
또한 하드웨어뿐만 아니라 선형 탐색보다 빠른 룩업 알고리즘들을 이용해 더욱 빨라졌는데[Gupta 2001, Ruiz-Sanchez 2001], DRAM과 DRAM cache로 SRAM을 칩셋 내부에 포함하여 빠른 메모리 접근 시간을 달성하거나, 이진 내용 주소화 기억장치(TCAM, Ternary Content Addressable Memories)를 이용해 메모리에 IP address를 투영하여 상수 시간 내에 값을 구할 수도 있다.
이렇게 출력포트가 정해진 패킷은 스위칭 패브릭에 들어가기 전에 큐에 들어가고, 스케듈링에 따라 처리된다. 이러한 패킷의 블록킹, 큐잉, 스케듈링은 나중에 볼것이다.
이러한 룩업 이외에도 입력 포트는 물리, 링크 계층 처리, 패킷의 버전 번호, 체크섬(checksum), TTL(Time-to-live) 등이 확인되고 체크섬과 TTL은 덮어쓰기, 네트워크 관리를 위한 카운터(주로 전달받은 아이피 데이터그램 수) 변경 등의 일을한다.
또한, 입력 포트의 룩업과 같은 “일치 후 행동(match plus action)”은 라우터 이외에도 링크 계층 스위치, 방화벽 등, 네트워크 주소 번역기(NAT, network address translator) 같은 여러 네트워크 개념에서 볼 수 있다.
4.2.2 스위칭(Switching)
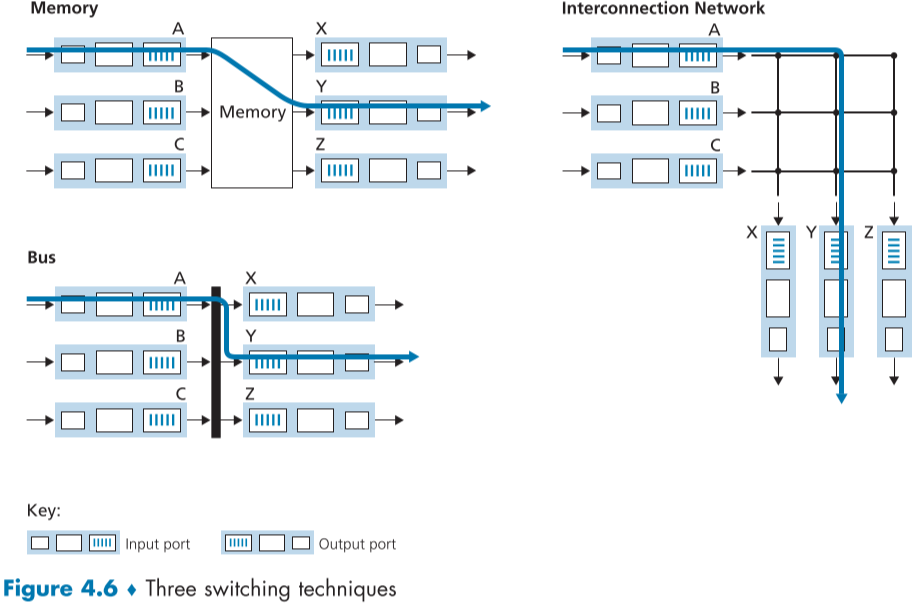
스위칭 패브릭(switching fabric)은 실제로 패킷이 입력 포트에서 출력 포트로 스위칭(= 포워딩)되기 때문에 아주 중요하다, 이러한 동작의 원리는 다음과 같은 방법들이 존재한다.
-
메모리를 통한 스위칭(Switching via memory)
가장 초기의 간단한 방법은 라우팅 프로세서(=CPU)에 의해 통제되는 것이다. 입력과 출력 포트는 기존의 입출력 장치에서 기존의 운영체제에 의해 처리되는데, 라우팅 프로세서에 의해 입력된 패킷이 인터럽트(Interrupt)되어, 프로세서 메모리로 복제된 뒤, 패킷 헤더에서 목적지 주소를 가져와 포워딩 테이블을 참고해 적절한 출력 포트의 버퍼로 패킷을 복사 붙여넣기 한다.
이 시나리오에서는 메모리 대역폭을 B라고 놓으면, 메모리에 패킷을 읽고, 쓰면서 최대 패킷 처리속도(throughput)가 B/2로 줄어들며, 설령 목적지가 다르더라도 공유 시스템 버스 상에서 하나씩 메모리에서 읽고 쓸 수 있으므로 동시에 포워딩 될 수 없다.
최근에도 메모리를 통해 처리하는 라우터와 다른 점은 룩업 기능과 적절한 메모리 지점에 패킷을 적재하는 기능을 입력 라인 카드에서 실행한다는 점이다.
각각의 라인 카드에서 병렬적으로 스위칭되는 모습이 마치 공유 메모리 다중처리장치(multiprocessor)로 처리하는 것과 같다.
-
버스를 이용한 스위칭(Switching via a bus)
이 방법은 라우팅 프로세서를 거치지 않고 공유 버스(share bus)를 이용해 직접적으로 입력 포트에서 출력 포트로 전달된다.
**패킷이 입력포트에 도착하면 버스를 통해서 어느 출력 포트로 가야하는 지에 대한 정보를 스위치 내부 레이블이 헤더에 적히게 된다. **
**버스를 지나간 이후, 모든 출력포트는 각각 모든 패킷의 복사본을 받지만, 그 중 패킷의 레이블을 살펴 출력 포트가 일치하는 것만 취하고 나머지는 버리게 된다. **
이 레이블은 출력 포트에서 제거되며, 오직 버스를 넘어 스위칭되는데만 사용되며, 만약 여러 입력포트에서 여러 패킷이 도착하면 버스 이용을 기다리기 위해 큐잉된다.
모든 패킷이 하나의 버스를 지나야 하므로, 마치 로터리에 차량이 한대씩만 들어갈 수 있는 것과 같으므로, 최대 스위칭 스피드가 버스 처리 속도에 제한되어 있어 한계가 있지만, 소규모 네트워크나 기업 망등에는 사용할 만하다.
-
상호연결 네트워크를 이용한 스위칭(Switching via an interconnection network)
하나의 공유 버스의 대역폭 한계를 극복하는 방법 중 하나로 다중처리장치(multiprocessor) 컴퓨터 구조에서 사용하던 상호연결 프로세서의 정교한 상호연결 네트워크를 이용하는 방법이 있다.
십자 스위치(crossbar switch)는 fig.4.6의 Interconnection network 그림처럼 입력 포트 수의 버스, 출력 포트 수만큼의 버스를 각각 수직 버스, 수평 버스로 놓고 이를 교차시켜 $N^2$개의 교차지점을 만들고, 각 교차지점을 스위치 패브릭 컨트롤러에 의해 여닫을 수 있게 한다. 패킷이 한 입력 포트에서 출발하면 스위치 패브릭 컨트롤러가 버스의 교차지점을 조작해 특정 출력 버스로 향하게 만든다.
이전 두 방법과 다르게 동시에 여러 패킷을 처리가 가능한 비블로킹(non-blocking) 방식이지만, 만약 서로 다른 입력포트에서 온 두 패킷이 같은 방향으로 향한다면 이 역시 처리가 순서대로 처리될 때 까지 기다려야 한다.
이를 극복하기 위해 다중층 스위칭 패브릭(multi-stage switching fabric)을 이용해 층의 갯수 만큼 같은 출력 포트를 향하는 패킷들을 동시 처리할 수 있다.
또한, 입력포트에서 패킷을 k개로 나눈 뒤, 이를 다중 스위칭 패브릭에서 동시에 빠르게 전달하고, 출력 포트에서 k개의 조각을 1개의 패킷으로 재조립하여 빠르게 처리할 수도 있다.
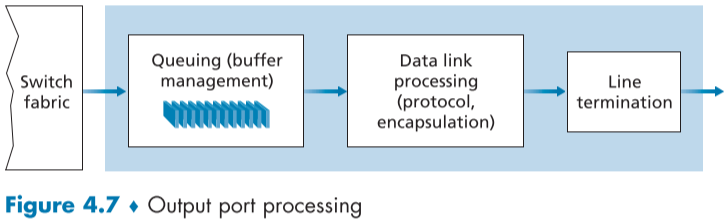
4.2.3.출력 포트 처리(Output Port Processing)
출력 포트 처리에서는 패킷을 받고 메모리에 적재한 뒤, 출력 링크에 전송한다.
출력 포트 처리는 패킷 선택(=스케듈링)과 디큐잉(de-dqueueing), 필요한 링크 계층과 물리 계층의 전송 기능을 포함한다.
4.2.4.큐잉이 일어나는 부분(Where Does Queuing Occur?)
입력 포트와 출력 포트의 기능을 살펴보았다면, 양 측에서 모두 패킷의 큐잉이 일어난다는 것을 알 수 있다.
마치, 로터리의 진입 부분과, 출구 도로에서 자동차가 막히듯이, 스위칭 패브릭의 처리속도, 라인 속도 등에 따라 양측 버퍼에 큐잉이 일어날 수 있으며, 이러한 큐잉이 아주 커지면 결국 메모리의 한계에 도달해 패킷 손실(packet loss)일어난다.
우리가 앞선 챕터들에서 배웠던 패킷의 손실이 일어나는 곳이 바로 이 두 곳이다.
각 라인별 처리 속도를 $R_{line}$, 패브릭 스위치의 속도가 $R_{switch}$, 입출력 포트 쌍이 총 N개가 있으며, 입력 포트마다 동일한 크기의 모두 서로 다른 출력포트가 목적지인 packet이 동시에 하나씩 도착한다고 가정하면, $R_{line}$*N보다 $R_{switch}$가 크거나 같으면 각 패킷이 모두 적시에 처리되어 각 큐잉이 발생하지 않는다.
만약 $R_{switch}$가 충분히 크지 않다면 큐잉이 발생하며, 각 패킷은 자기 차례가 올때까지 기다려야 한다.
입력 큐잉(Input Queuing)
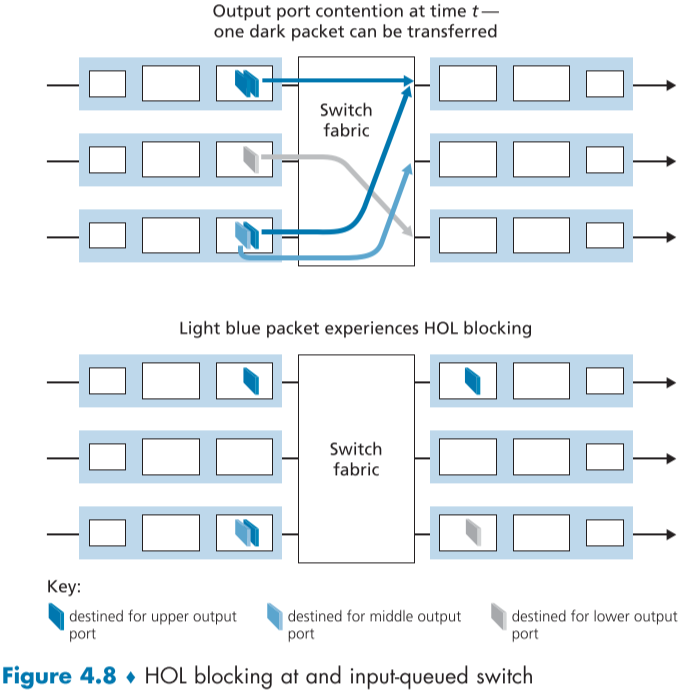
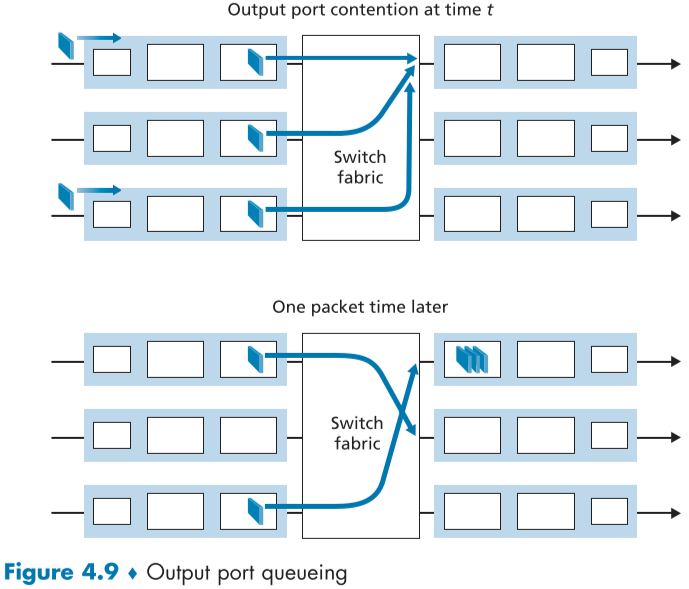
위의 가정을 조금 바꾼다면, $R_{switch}$ 가 충분히 빠르더라도 큐잉이 발생할 수도 있는데, 각 패킷이 갈 출력포트가 겹치는 순간, 패킷은 큐잉이 생겨 해당 출력포트가 처리가 끝날때 까지 기다려야 한다.
이는 큰 문제가 되는데 아래 Fig.4.8과 같이, (위에서 부터)1번 입력 포트와 3번 입력 포트의 첫번째 패킷이 동일한 출력 포트를 목적지로 가지게 되어, 3번째 입력포트에 큐잉이 발생하게 되고, 3번째 입력포트의 2번째 패킷은 목적지인 2번째 출력 포트가 아무도 사용하지 않고 있음에도 불구하고 자신의 앞에 있는 패킷이 처리될때 까지 접근할 수 없고 기다려야 한다.
이러한 경우를 HOL 블록킹(HOL Blocking, head-of-the-line blocking)이라고 부르며, 엄청난 비효율과 이에 의한 패킷 손실을 초래하게 된다[Karol 1987].
HOL 블록킹의 해결방안이 몇 개 제안 되기도 했다[McKeown 1997].
출력 큐잉(Output Queuing)
$R_{switch}$이 무한히 크고 HOL 블록킹이 발생하지 않고, 출력 큐잉이 발생할 수 있다.
출력 포트가 나가는 링크로 보내는 전송 시간이 추가로 필요하기 때문에 전송이 완료될 때까지 출력 포트에 도착한 패킷들이 큐잉되며, 이때도 처리속도가 충분하지 않으면 버퍼 오버플로우로 인한 패킷 손실이 발생할 수 있다.
버퍼 크기가 충분하지 않고, 패킷의 처리속도 보다 도착 속도가 빠르다면 여러가지 방안을 고민해야 하는데, 그중 하나가 버퍼가 가득찬 이후 도착하는 패킷은 버리는 꼬리 버리기(drop-tail) 정책이 있고, 버퍼 내부의 큐잉된 패킷을 몇개 버려 이후 오는 패킷을 받아들이는 정책 또한 있다.
버퍼가 가득차지 않았음에도 미리 패킷을 버리거나 패킷의 헤더의 Explicit congestion Notification bit를 표시하여 수신자 측에 알리는 정책 또한 존재하는데 이러한 정책을 능동 큐 관리 알고리즘(active queue management, AQM)이라 한다.
가장 널리 알려진 AQM 알고리즘은 임의 조기 발견(RED, Random Early Detection)이며, PIE(Proportional Integral controller enhanced)나 CoDel 또한 존재한다.
이러한 패킷의 스위칭, 큐잉, 전송 등은 패킷 스케듈러에 의해 실행되며 나중에 다시 다룰 것이다.
적정 버퍼링 찾기(How Much Buffering Is “Enough”)?
앞서 큐잉은 대량의 패킷이 라우터의 입출력 포트에 도착하거나 패킷의 도착량이 패킷 포워딩 처리량 보다 순간적으로 넘어갔을 때 등장한다고 이야기 했다.
이러한 큐잉이 지속되면 버퍼 크기는 점점 커지다가 가득차게 되고 결국 패킷이 손실된다.
그렇다면 적절한 버퍼링은 얼마나 되야할까? 이 답은 생각보다 복잡하고 네트워크 여러 분야가 관련된다.
오랫동안 버퍼 사이즈의 정답은 $B=RTT\cdot C$로, 버퍼링 사이즈 B는 평균 왕복 시간(RTT)에 링크 전송 허용량(capacity)를 곱한 것이였다.
예를 들어, 10Gbps 링크에 250msec RTT라면 2.5Gbits의 버퍼 사이즈가 적정량이었다.
이는 큐잉과 TCP 연결의 상관관계에 따라 나온 값이었다.
최근에는 여러 실험과 연구 끝에 $B=RTT\cdot C/\sqrt{N}$이며, N은 링크 내부의 독립된 TCP 연결 수이다.
보통 버퍼 사이즈가 크면 클수록, 많은 양의 패킷 도착량을 받아들일 수 있고, 패킷 손실이 줄어들어 좋다고 생각할 수도 있지만.
버퍼 사이즈가 크면 손실되는 패킷이 줄어들면서, 혼잡 제어를 위해 표시된 패킷의 딜레이가 커지고, RTT가 증가한다.
예를 들어, 게임이나 실시간 영상회의 같은 경우, 버퍼가 10배 늘어날 경우 종단 간의 지연 시간은 10배가 늘어난다.
늘어난 RTT에 의해 TCP의 반응성과 혼잡 상황 파악 등이 늦어 지기도 한다.
즉 버퍼 크기는 소금처럼 적절한 양이 좋다.
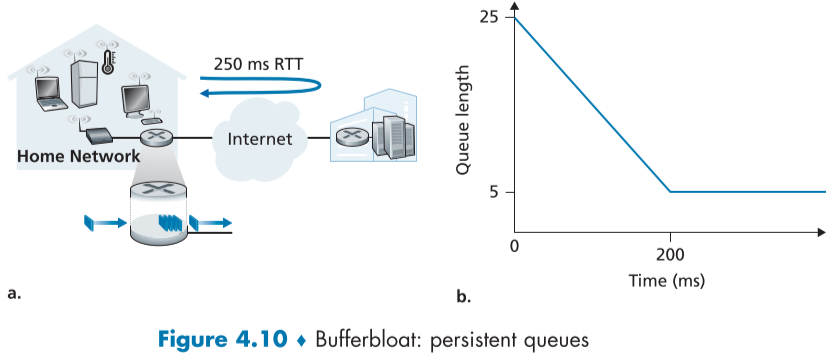
위의 Fig.4.10은 TCP 세그먼트를 게임 서버에 보내는 홈 라우터의 예제이다.
패킷 전송 딜레이(packet transmission delay, 라우터에 나가 링크에 적재되는 딜레이)가 20ms, RTT가 200ms, queueing delay는 무시할 정도로 작고, 0초에 25개의 packet이 한꺼번에 queue에 들어왔다고 가정하자.
그럴 경우 fig.4.10.b 와 같은 그래프가 나타나는데, 매 20ms에 1개씩 패킷이 처리되며, 큐의 길이가 점점 줄어들어 200ms에 5개가 남는다.
200ms 시점에서 RTT가 200ms이므로, 가장 처음에 처리했던 1번째 패킷의 ACK 가 도착함과 동시에 21번째 패킷이 처리되어 나가는 링크로 나가게 된다.
ACK가 도착했으므로 TCP 송신자는 다음 세그먼트 번호에 속한 패킷을 보내려할 것이다 (TCP의 self-clocking 참조).
ACK가 하나 도착할 때 마다 새로운 패킷을 하나 보내게 되므로, 큐의 길이는 5로 유지가 될것이다.
즉, 언제나 새로 보내는 패킷은 큐의 가장 마지막 5번째에 들어가게 될 것이며, 게임, 멀티미디어 응용 프로그램 같이 패킷을 지속적으로 보내는 한, 사용자는 언제나 같은 시간의 딜레이에 시달리게 된다.
버퍼의 크기가 클수록 큐의 길이가 길어지므로 지연시간은 더욱 컷을 것이다.
위 시나리오처럼 일정 길이로 유지되는 버퍼링에 의한 지속적이고 일정한 딜레이를 버퍼블로트(bufferbloat)이라고 하며, 단순히 처리율(throughput) 뿐만 아니라 최소 딜레이(minimal delay) 중요하다는 것을 알 수 있다. (시나리오 상에서 처리율은 일정하고 이상적인 상태를 유지했다.)
케이블 네트워크를 위한 DOCSIS 3.1 기준에서는 처리율 성능을 유지하며 이러한 버퍼 블로트와 싸우기 위해 자세한 AQM 메커니즘을 추가하였다.
4.2.5 패킷 스케듈링 (Packet Scheduling)
라우터가 큐된 패킷들을 어떤 순서로 처리하는지 알아보자.
흔히 알고있는 먼저 온 패킷이 먼저 처리되는 선입선출(FCFS(first-come-first-served), 또는 FIFO(first-in-first-out))부터,
우선등급과 계급을 정하여 차별적으로 처리 서비스를 제공하는 방법,
패킷을 종류별로 나눈 뒤, 종류별로 순차적으로 처리되는 라운드로빈(round-robin) 등이 있다.
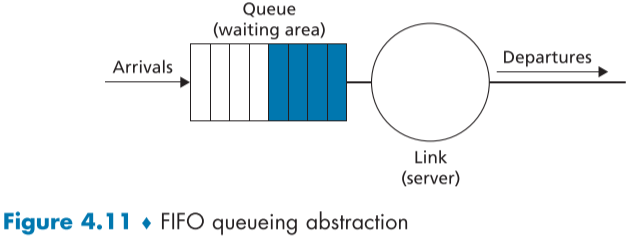
선입선출(FIFO) (First-in-First-Out (FIFO))
아래 fig.4.11은 선입선출 구조를 나타낸 그림이다.
버퍼가 넘치게 되면, 추가로 들어오는 패킷을 버리거나, 또는 큐 내부의 패킷을 버려 공간을 만드는 정책 등도 고려해야하지만, 이번에는 버퍼가 넘치는 경우가 없다고 가정하고, 오직 패킷이 올바르게 처리될 시에만 큐에서 제거된다고 가정하자.
선입 선출(FIFO, First-in-First-out) 구조는 출력 링크 도착시간 순으로 패킷의 링크 전송을 처리하는 것이다.
우리가 일상 생활에서 줄을 서는 방법과 같으며, 익숙한 방법이다.
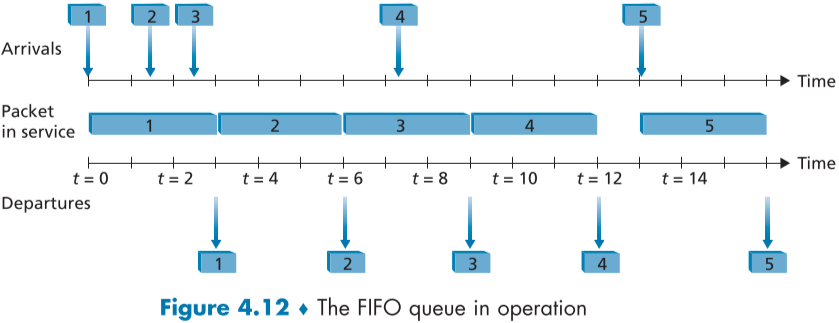
아래 fig.4.12는 FIFO 큐의 동작 예시이다.
파란색 상자로 표시된 패킷들에 적혀있는 번호는 도착 순서이며, Packet in service는 큐에서 패킷들이 보낸 시간이다.
패킷 전송 처리 시간이 3 단위시간 만큼이라고 가정하면, 선입선출 구조에서는 도착한 순서와 같게 패킷이 떠나며, 패킷이 없을 때, 5번 패킷이 도착할 때 까지 대기 상태를 유지하는 것도 볼 수 있다.
우선순위 큐잉(Priority Queuing)
우선순위 큐잉에서는 도착한 패킷들이 특정 기준에 따라 우선순위 등급이 나뉘어지고, 각자 별도로 존재하는 큐에서 처리되게 된다.
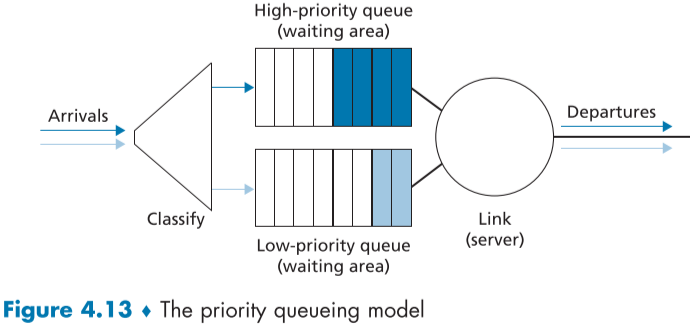
실무에서는 우선순위 큐잉을 통해 네트워크 관리자가 큐를 조작하여 네트워크 정보를 담은 패킷을 우선처리 할 수 있다.
이메일처럼, 실시간 처리가 필요없는 패킷은 우선순위가 낮게, VOIP 같은 실시간 패킷은 우선순위를 높게 잡을 수도 있을 것이다.
보통은 각 우선순위 종류 마다 별도의 큐를 가지고 있으며, 기다리는 패킷이 존재하는 높은 우선순위의 큐 먼저 처리하는 방식이다.
같은 우선순위의 큐 내의 패킷들은 보통 선입선출로 처리된다.
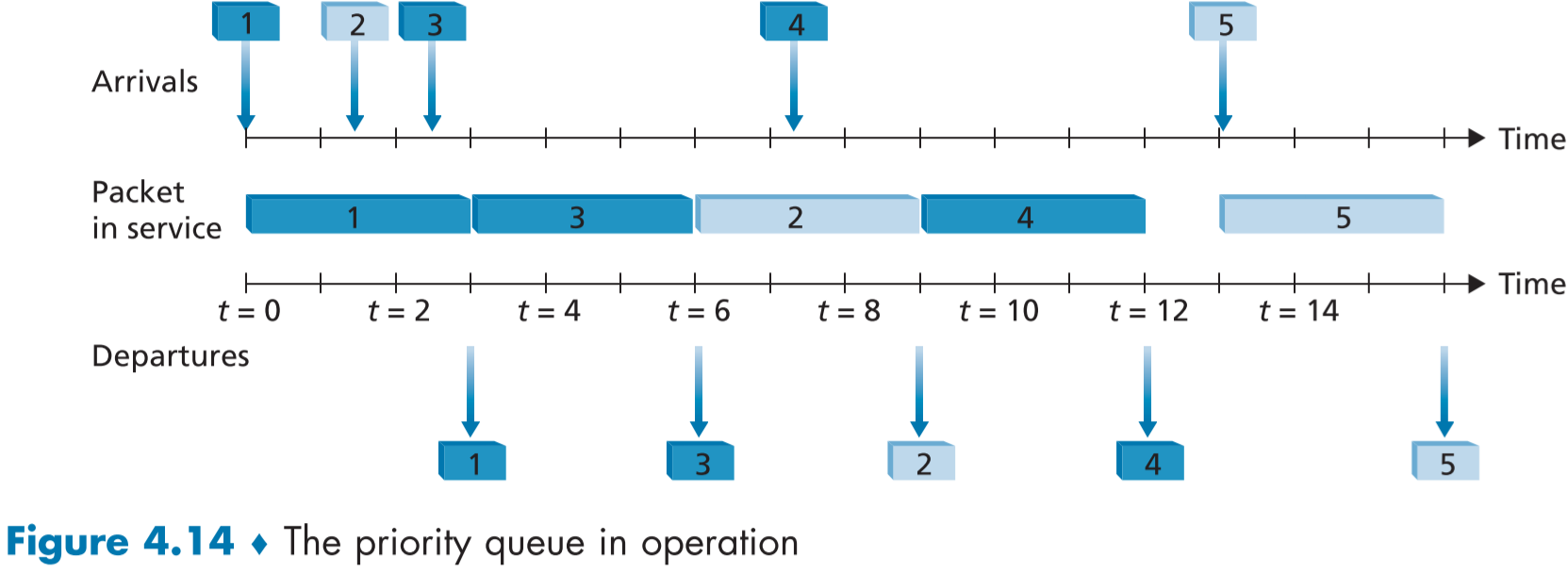
위 fig.4.14는 패킷의 색깔로 우선순위를 구별한다.
도착 순서와 관계없이 우선순위가 높은 파란색 색깔의 패킷들이 우선 처리된 후, 하얀 패킷들이 처리되는 모습이다.
단, 4번과 2번 패킷처럼, 우선순위가 낮은 패킷이 전송되는 중간에 우선순위가 높은 패킷이 도착해도, 중간에 전송을 취소하고 우선순위가 높은 패킷을 먼저 전송해주진 않는데, 이를 비선제 우선순위 큐잉(non-preemptive priority queuing)라고 한다.
라운드 로빈과 가중 공정 큐잉(WFQ) (Round Robin and Weighted Fair Queuing(WFQ))
라운드 로빈 큐잉 정책에서는 패킷들은 우선순위 큐잉때 처럼 여러 분류로 나뉘지만, 우선순위 때와 달리 서비스를 다르게 제공하지 않고 클래스 별로 순차적으로 제공한다.
작업 보존 큐잉 (work-conserving queuing)의 경우 대기하고 있는 패킷이 있을 경우, 링크가 대기상태에 있지 않고 계속 패킷을 전송하게 하는데, 만약 특정 분류에 더이상 전송 대기 중인 패킷이 없다면 라운드 로빈 순서로 다음 분류의 패킷들을 전송한다.
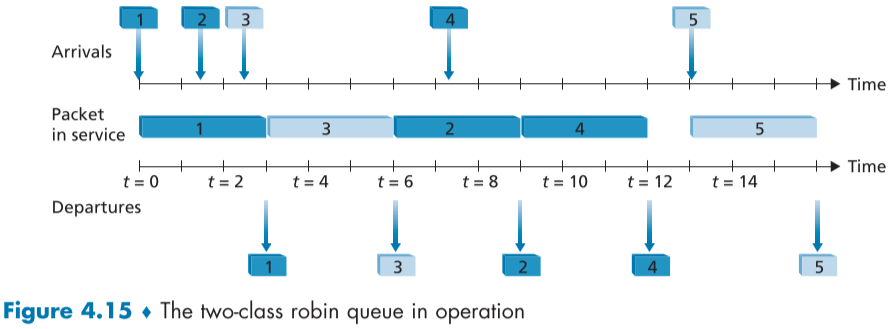
위 fig.4.15는 2개의 분류를 가진 라운드 로빈의 예시이다.
마찬가지로, 작업 보존 큐잉의 성격을 띄고 있어, 2번 패킷을 보낸 뒤, 다음은 라운드로빈에 의해 흰색 패킷의 차례지만, 흰색 패킷의 큐가 비어있어 바로 같은 파란색인 4번 패킷이 전송되었다.
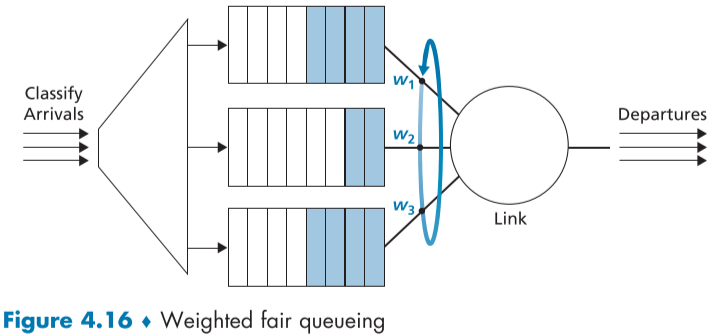
일반화되고 널리 사용되고 있는 라운드 로빈 정책의 일종으로 가중 공정 큐잉(WFQ, weighted fair qureuing)이 있다.
위 4.16은 WFQ를 나타낸 것으로, 기본적으로 라운드 로빈처럼 각자 분류 별로 큐를 생성한 뒤, 각 분류에 맞는 패킷 간에 선입선출로 전송된다.
역시나 작업 보존 큐잉의 성격을 띄고 있어 비어있는 분류의 큐는 대기하지 않고 다음 분류의 큐로 넘어간다.
WFQ가 기존의 라운드 로빈과 다른 점은, 각 분류마다 가중치를 설정하여, 해당 가중치의 비율 만큼 서비스를 배정한다는 점이다.
예를 들어 $w_1$의 차례가 됬다면, $w_1/\sum_{i=1}^{3}{w_i}$ 만큼의 패킷이 처리된 후, $w_2$의 차례가 되는 식이다.
위와 같이 처리하면 가중치 비율 만큼 처리율(throughput), 또는 대역폭이 형성되어, 이를 통해 분류별로 서비스를 차별화할 수 있다.
다만, 실제 패킷은 소수점으로 나누어 전송할 수 있지 않고, 이산적인(discrete) 처리가 필요하며, 패킷 중간에 전송이 취소되지 않고, 끝까지 전송된 후, 다음으로 넘어가며, 이를 packetization 문제라고 한다..
망 중립성 (Net Neutrality)
앞서 설명했던 패킷 스케듈링에 의힌 패킷 차별화를 통해 SNMP 네트워크 관리 데이터그램의 포트 번호(161)에 우선순위를 주어 네트워크 혼잡을 막는 등에 사용할 수 있지만, ISP의 의도에 따라 특정 고객에게 높은 대역폭과 처리율을 주거나, 특정 회사의 영업 방해 등을 이룩할 수도 있다.
이러한 ISP의 행동은 국가 마다 다른 법률에 적법성이 달려있지만, 대표적인 예로 미국의 정책인 망중립성(Net Neutrality)에 대해 알아보자.
망 중립성은 사실 정확한 정의는 없지만, 미국 연방 통신 위원회가 2015년 3월에 열린 열린 인터넷의 보호 및 촉진을 위한 질서[FCC 2015] 에서 다음과 같은 규칙을 제공하였다.
- 차단 금지 (No blocking) : 인터넷 제공업에 종사하는 자는 합리적인 네트워크 관리에 준해 합법적인 컨텐츠, 응용 프로그램, 서비스, 무해한 장비를 차단하면 안된다.
- 조정 금지 (No Throttling) : 인터넷 제공업에 종사하는 자는 합리적인 네트워크 관리에 준해 합법적인 컨텐츠, 응용 프로그램, 서비스, 무해한 장비를 저해하거나 조정하면 안된다.
- 유료 순위 금지 (No Paid Prioritization) : 인터넷 제공업에 종사하는 자는 유료 순위(Paid Prioritization)를 제공하면 안된다. 유료 순위란, 트래픽 형성, 우선순위 지정, 리소스 예약 등의 모든 기술을 포함하여 직간접적으로 인터넷 제공자가 특정 트래픽을 다른 트래픽에 비해 선호되도록 네트워크를 관리하는 것을 의미한다.
실제로 이렇나 규칙을 어겨 발각된 ISP도 존재하고, 망 중립성은 고객의 편의 제공과 인터넷의 혁신에 주제를 맞춰 맹렬히 토의되고 있는 주제이다.
최근에는 미국 연방 통신 위원회는 이러한 인터넷 관리에 대한 강제적인 규칙이 아니라 ISP의 투명성에 초점을 맞춰 규칙이 대체되기도 했다.[FCC 2017]
4.3 인터넷 프로토콜(IP) : IPv4, 어드레싱, IPv6, 등등 (The Internet Protocol (IP): IPv4, Addressing, IPv6, and More)
인터넷 프로토콜 (IP), IPv4, IPv6, 아이피 어드레싱에 대해 알아보자.
4.3.1.IPv4 데이터그램 형식 (IPv4 Datagram Format)
네트워크 계층에서는 패킷을 데이터그램이라고 부른다. 먼저 IPv4 데이터그램의 구조와 의미에 대해 알아보자.
총 옵션 제외 20 byte의 헤더를 가지고 있고, TCP header의 20 bytes와 합치면 총 40 bytes의 헤더가 응용 계층 메시지에 존재한다.
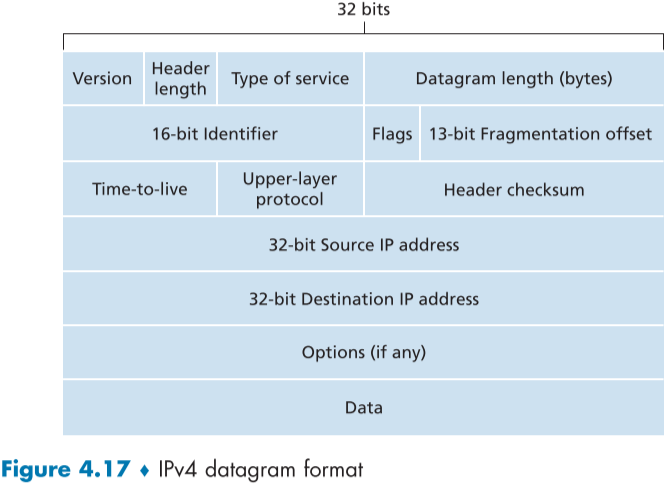
fig.4.17은 IPv4의 데이터그램 형식이다.
| 필드 이름 | 설명 | 크기(bit) |
|---|---|---|
| Version number (버전명) | 데이터그램의 아이피 프로토콜 버전, 버전에 따라 라우터가 데이터그램을 비트들을 해석하는 방법이 달라짐. (IPv4 vs IPv6) | 4 |
| Header length (헤더 길이) | IPv4는 추가적인 옵션을 헤더에 넣을 수 있으므로 패킷 내의 페이로드 부분이 시작하는 위치를 바이트 기준으로 적는다. 옵션이 없는 기준에서는 20byte | 4 |
| Type of service (TOS, 서비스 종류) | 아이피 데이터그램의 종류를 구분하기 위한 부분, 라우터의 정의에 따라 달라지지만, 보통 실시간 데이터그램(게임 등) vs 비실시간 데이터그램(FTP 등)을 구분하거나, ECN(Explicit Congestion Notification)을 위해 네트워크 상황을 알리는 비트로 사용 | 8 |
| Datagram length (데이터그램 길이) | 데이터가 포함된 아이피 데이터 그램의 바이트 기준의 총 길이, 16 비트이므로 이론상 $2^{16}$ 바이트까지 커질 수 있다.(보통은 이더넷 프레임 최대 크기를 통과하기 위해 1500바이트 이하이다.) | 16 |
| Identifier (식별자), flags (부호들), fragmentation offset (조각 오프셋) | IPv4는 데이터그램의 조각화를 지원하므로 여러 조각으로 나뉜 데이터그램을 합치기 위한 헤더 필드, 조각난 데이터그램은 목적 호스트에 도착하면 이를 통해 재조립된다. IPv6는 더이상 지원하지 않는다. | 16, 3,13 |
| Time-to-live (TTL) | 데이터그램이 장기간 라우팅 루프 등의 이유로 영원히 네트워크 상을 떠도는 것을 방지하기 위한 필드, 라우터를 지날 때마다 1씩 줄어들고 0이 되면 라우터가 데이터그램을 버린다. | 8 |
| Protocol (프로토콜) | 데이터그램이 목적지 도착 후, 어떤 전달 계층 프로토콜로 사용된 데이터인지 알려주는 필드, TCP의 경우 6, UDP의 경우 17 이외는 [IANA Protocol Numbers 2016] 참조. 이는 전달 계층 세그먼트의 포트 번호처럼 다른 계층간의 데이터 변환을 위해서다. | 8 |
| Header checksum (헤더 체크섬) | 라우터가 비트 에러를 탐지하기 위한 필드, 페이로드 제외 헤더만 대상이라는 점을 제외하고 전달 계층의 체크섬과 같은 방식이다.(원리, 중복 구현 이유는 챕터 3 체크섬 참조), 에러가 발견되면 보통 데이터그램을 버린다. 라우터를 지날 때마다 TTL이 바뀌므로 라우터가 새로 바꿔넣어야 한다. [RFC 1071]에 빠른 인터넷 체크섬 알고리즘이 있다. | 16 |
| Source and Destination IP addresses (주소) | 데이터 그램 생성시, 출발지 주소와 목적지 주소를 적어넣는다. 목적지 주소는 DNS 룩업을 통해서 구하기도 한다. 자세한 내용은 이후 설명 | 32,32 |
| Options (옵션) | 아이피 헤더에 추가적인 정보를 추가할 수 있다. 데이터그램 크기가 증가할 뿐만 아니라, 라우터에서 해당 옵션을 지원하지 않을 수도 있고, 자원을 잡아먹는 옵션 필드 처리 과정을 추가시키기 때문에 오버헤드를 유발한다는 이유로 거의 사용되지 않는다. 옵션은 IPv6부터 지원하지않는다. | 가변길이 |
| Data(payload) (데이터) | 전달 계층 세그먼트가 캡슐화(encapsulated)되어있는 부분, TCP, UDP, ICMP 등이 존재할 수 있다. |
4.2.3. IPv4 어드레싱 (IPv4 Addressing)
아이피에 대해 알아보기 전에 호스트와 라우터, 인터페이스에 대한 이야기를 해보자.
호스트는 보통 하나의 연결링크를 가지고 있으며, 이를 통해 인터넷과 통신이 가능하다. 이러한 통신 주체(호스트, 라우터 등)와 물리적 연결(케이블, 와이파이) 간의 경계를 인터페이스라고 한다.
라우터 또한, 패킷을 주고 받을 수 있으므로 인터페이스를 가지고 있으며, 심지어 하나만 가지고 있는 호스트와 달리 여러 들어오는 링크에서 온 패킷을 여러 나가는 링크로 보내줘야 하므로 각 입출력 링크 별로 하나씩 여러개의 인터페이스를 가지있다.
누군가가 그러한 라우터나 호스트와 연결을 하고 싶으면, 그들의 인터페이스를 통해서 하는 것이므로, 그들의 인터페이스의 고유한 주소를 알아야하는데, 이를 아이 주소(IP address)라고 한다. 즉, 아이피 주소는 엄밀히 말하면 인터페이스의 주소이지, 호스트, 라우터의 주소가 아니다.
각 아이피 주소는 32 비트(4 바이트) 길이로, 총 $2^{32}$개의 주소를 표현할 수 있으며, 바이트 별로 점으로 구분되는 10진수 정수 표현(dotted-decimal notation)으로 표현한다.
(11000001 00100000 11011000 00001001) == (193.32.216.9)
NAT(4.3.3 참고)내부의 인터페이스를 제외한 모든 인터페이스는 전체 인터넷 망에서 유일한 값을 가지고 있어야 하며, 마음대로 고를 수 없다.
하지만, 아이피 주소의 일부분은 인터페이스가 연결된 서브넷(subnet)에 의해 결정되기도 하는데 예시를 들자면, 아래 fig.4.18은 아이피 어드레스와 인터페이스의 예시로, 3개의 인터페이스를 가진 하나의 라우터가 일곱개의 호스트를 연결하고 있고, 라우터와 연결된 호스트들의 인터페이스의 아이피 주소가 라우터의 인터페이스에 따라 24 비트 자리까지 동일함을 알 수 있다.
하나의 라우터 인터페이스에 여러개의 호스트가 연결될 수 있는 이유는 나중에 설명할 이더넷 LAN(Ethernet LAN)의 이더넷 스위치나 무선 접근 지점(wireless access point)에 의한 것이다.
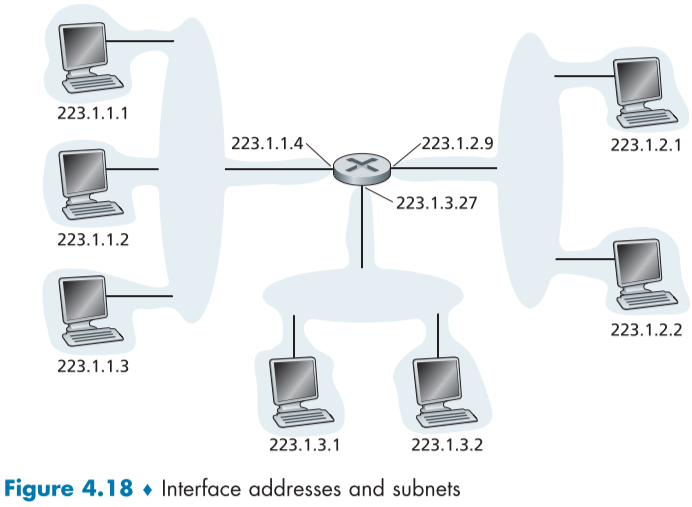
이런식으로 여러 호스트 인터페이스가 하나의 라우터 인터페이스와 연결을 이룬 것을 서브넷(subnet)[RFC 950] 또는 아이피 네트워크라고 한다.
아이피 어드레싱은 이러한 주소를 (223.1.1.0/24) 같은 식으로 표현해 할당하는데 이를 서브넷 마스크(subnet mask)라고 한다.
여기서 모두 동일한 값을 가지는 앞의 24bit는 "x.x.x.x/24" 같은 식으로 표현하고 이를 서브넷 주소(subnet address)라고 하며, 서브넷에 추가로 참가할 인터페이스는 해당 어드레스 형식을 맞춰야 한다.
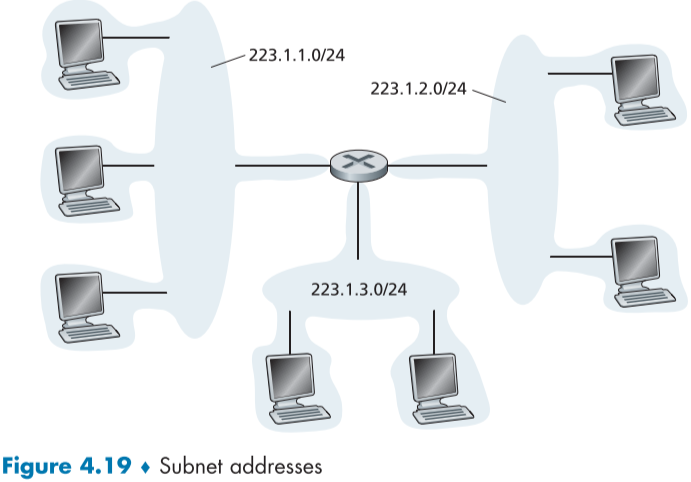
- 현재 위의 그림의 서브넷 예시에서 223.1.1.0/24 서브넷에 속한 아이피는 223.1.1.1~223.1.1.3과 라우터 인터페이스인 223.1.1.4까지 총 4개이다.
- 또한 총 3개의 아이피 서브넷이 존재하며, 각각 223.1.3.0/24, 223.1.2.0/24가 추가로 존재한다.
- 여기서 서브넷 마스크에서의 0은 실제 주소가 0임을 표현한 것이 아닌 소속한 아이피 주소들 별로 구분되는 부분이다.
위에서 설명한 아이피에서의 서브넷 정의는 실제로 이더넷 영역에서는 엄격하게 지켜지지 않는데, 아래와 같은 예시를 볼 수 있다.
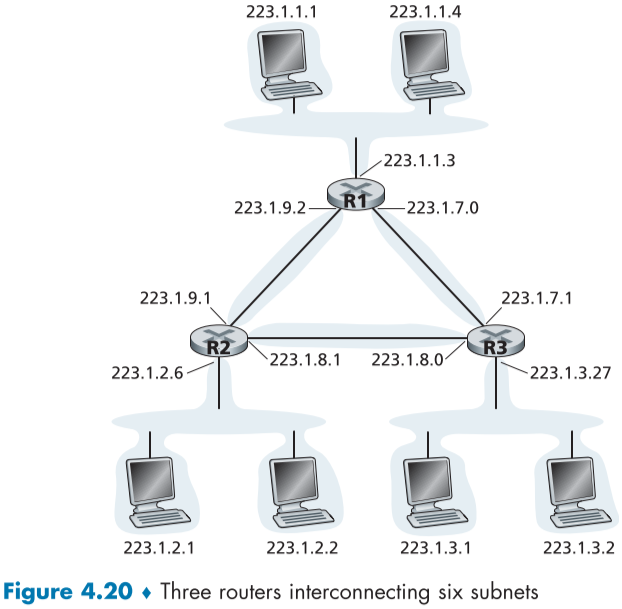
여기서 서브넷은 우리가 생각하는
- 223.1.1.0/24
- 호스트 인터페이스 223.1.1.1
- 호스트 인터페이스 223.1.1.4
- 라우터 인터페이스 223.1.1.3
- 223.1.2.0/24
- 호스트 인터페이스 223.1.2.1
- 호스트 인터페이스 223.1.2.2
- 라우터 인터페이스 223.1.2.6
- 223.1.3.0/24
- 호스트 인터페이스 223.1.3.1
- 호스트 인터페이스 223.1.3.2
- 라우터 인터페이스 223.1.3.27
뿐만 아니라
- 223.1.7.0/24
- 라우터 인터페이스 223.1.7.0
- 라우터 인터페이스 223.1.7.1
- 223.1.8.0/24
- 라우터 인터페이스 223.1.8.0
- 라우터 인터페이스 223.1.8.1
- 223.1.9.0/24
- 라우터 인터페이스 223.1.9.1
- 라우터 인터페이스 223.1.9.2
또한 추가로 존재한다.
그러므로 서브넷은 인터페이스 하나를 통해 분리되어 있는 인터페이스들의 네트워크를 서브넷이라고 부른다.
이더넷 세그먼트와 점간 연결을 구축한 회사나 대학 같은 단체들은 이러한 서브넷을 여럿 가지고 있으며, 보통 같은 단체의 서브넷들 간은 유사한 서브넷 주소를 가진다. 그 이유를 알아보기 전에 먼저 CIDR에 대해서 알아보자면,
인터넷 주소 할당 전략을 Classless Interdomain Routing(클래스 없는 도메인간 라우팅, CIDR, 사이더)이라고 부르며, CIDR은 서브넷 어드레싱의 개념 정립하였는데,
a.b.c.d/x
서브넷 마스크와 똑같이 생겼으므로 잘 구분해야한다.
서브넷 어드레싱에 의해 단체가 할당받는 아이피 주소는 두개의 부분으로 나뉘는데, 뒤의 “/x”는 첫번째 부분과 두번째 부분의 경계 위치를 알려준다.
- /x 같이 표현 하는 방식을 CIDR notation 이라고 한다.
첫번째 비트부터 x번째 비트 부분을 접두어(prefix) 또는 네트워크 접두어(network prefix)라고 부르며, 한 단체는 보통 연속된 하나의 블록 주소를 할당 받으며, 그 부분이 공통 접두어(common prefix)의 범위이다.
단체에 속한 아이피 장비들의 개개의 아이피 주소는 이러한 공통 접두어를 공유하며, 나중에 알아볼 인터넷의 BGP 프로토콜에서는 단체에 속하지 않은 외부의 라우터들이 이러한 x개의 공통 접두어만 인식하여 단체를 구분한다.
- 즉 라우터들이 데이터그램을 보고 해당 주소가 특정 단체에 소속된 장비의 주소라면, 해당 단체의 공통 접두어만 보고 해당 단체로 라우팅한다.
- 전체 아이피 주소 중 일부 접두어만 참고하면 되므로, 이로 인해 포워딩 테이블의 크기가 줄어들게 된다.
나머지 x+1 비트 부터 마지막 32 비트까지는 해당 단체 내부에서 추가로 기기들이 구분될 수 있는 주소로, 단체 내부에 속한 라우터들은 이 부분만 보고 패킷을 포워딩 한다.
이 두번째 부분은 앞서 설명했던 추가적인 서브넷 구조의 서브넷 주소를 가질 수도 있는데 예를 들어, 단체의 공동 접두어인 a.b.c.d/21은 첫 21 비트의 경우 CIDRized(사이더화 됨)이라고 하여 단체 내부의 모든 아이피 주소가 공유하며, 나머지 32-21개의 비트는 단체 내부의 서브넷으로도, 또는 전부 개인으로도 사용될 수 있다.
CIDR이 생기기 전의 아이피 주소는 8, 16, 24 비트의 고정된 길이만큼의 서브넷 주소로 네트워크를 구분했으며 이러한 네트워크 어드레싱 구조를 네트워크 클래스(classful addressing)라고 불럿다.
이 각각의 8, 16, 24 bit의 서브넷 마스크를 가진 서브넷 주소를 클래스 A, B, C로 나누었는데, 이러한 경직된 구조는 단체 네트워크와 소규모 서브넷이 마구 생겨나던 시절에 문제가 되었다.
예를 들어, 클래스 C의 경우 /24 서브넷의 경우 전체에 $2^8$-2=254개의 호스트만 가질 수 있었고 이는 너무 작은 수이고, 그다음 클래스인 클래스 B의 경우 /16 서브넷이 $2^{16}$-2=65634개로 너무 많았다.
- 2를 뺀 이유는 아래 네트워크 클래스 참조
또한, 클래스 B의 경우 전체 가능한 경우의 수 65634개 중 겨우 2000개 정도가 할당될 수 있게 했는데, 이는 너무 적었다.
참고로 255.255.255.255는 브로드캐스트 주소(broadcast address)라고 하며, 브로드캐스트 주소를 목적지 아이피 주소로 데이터그램을 생성해 보내면 라우터는 보통 자신이 속한 서브넷에 한해 모든 연결된 호스트에게 메시지를 복사해서 보내게 된다.
- 아주 가끔 설정에 따라 이웃 서브넷에게도 보내는 경우가 있다.
네트워크 클래스(Network class)
https://en.wikipedia.org/wiki/Classful_network 발췌
네트워크 클래스(Network class), 클래스식 네트워크(classfull network) 또는 IP 주소 클래스는 CIDR 이전에 사용하던 네트워크 어드레싱 구조 중 하나이다.
IPv4 공간을 마스크(위의 서브넷 마스크와 같은 방식)와 범위, 규모에 따라 5개로 나누며,
A,B,C 클래스는 일반 사용자의 양방향 1:1 통신 네트워크를 정의하기 위한 클래스로, 네트워크 크기로 구분되며, 국가, 회사, 개인 들에게 할애 되어 사용되었다.
D 클래스는 다대다 네트워크를 위한 클래스이고, E 클래스는 실험용 및 미래를 위한 예비 클래스이다.
지금은 더이상 사용하지 않지만, 여전히 소프트웨어, 하드웨어 설정 등에 남아있고, 특히 서브넷 마스크의 기본 값으로 많이 사용한다.
| 클래스 | 접두어 비트 | 네트워크 번호 마스크 | 서브넷 마스크 | 범위 | 클래스 당 할당 네트워크 수 | 네트워크당 할당 주소 수 |
|---|---|---|---|---|---|---|
| Class A | 0 | /8 | 255.0.0.0 | 0.0.0.0 ~ 127.255.255.255 | 128($2^7$) | 16777216($2^{24}$) |
| Class B | 10 | /16 | 255.255.0.0 | 128.0.0.0 ~ 191.255.255.255 | 16384($2^{16}$) | 65536($2^{16}$) |
| Class C | 110 | /24 | 255.255.255.0 | 192.0.0.0 ~ 223.255.255.255 | 2097152($2^{21}$) | 256($2^8$) |
| Class D (multicast) | 1110 | 없음 | 없음 | 224.0.0.0 ~ 239.255.255.255 | 없음 | 없음 |
| Class E (reserved) | 1111 | 없음 | 없음 | 240.0.0.0 ~ 255.255.255.255 | 없음 | 없음 |

실제 사용 가능한 네트워크 내의 주소 수는 2개를 빼줘야 하는데, 1개는 브로드캐스트 주소, 나머지 1개는 네트워크의 주소로 사용되기 때문이다.
브로드캐스트(boradcast) 주소는 위의 IPv4 어드레싱 마지막 부분에 설명되어 있다.
네트워크 주소는 해당 서브네트워크를 지칭하는 주소를 의미한다.
몇 몇 주소들은 특별한 용도를 위해 예약되어 있어 사용 불가하다.
| 주소 | 해당 사이더 | 목적 | RFC | 클래스 | 전체 주소 개수 |
|:——————————-:|:————–:|:—————————————————————————————————:|:———————————————–:|:—:|:———–:|
| ` 0.0.0.0 - 0.255.255.255 | 0.0.0.0/8 | Zero 주소 | [RFC 1700](https://tools.ietf.org/html/rfc1700){: .wikilink}{:target=\"_blank\"}{: .externallink} | A | 16,777,216 |
| 10.0.0.0 - 10.255.255.255 | 10.0.0.0/8 | [사설망](https://ko.wikipedia.org/wiki/사설망) | [RFC 1918](https://tools.ietf.org/html/rfc1918){: .wikilink}{:target=\"_blank\"}{: .externallink} | A | 16,777,216 |
| 127.0.0.0 - 127.255.255.255 | 127.0.0.0/8 | 로컬호스트 Loopback 주소 | [RFC 1700](https://tools.ietf.org/html/rfc1700){: .wikilink}{:target=\"_blank\"}{: .externallink} | A | 16,777,216 |
| 169.254.0.0 - 169.254.255.255 | 169.254.0.0/16 | [Zeroconf](https://ko.wikipedia.org/wiki/Zeroconf){: .wikilink}{:target=\"_blank\"}{: .externallink} | [RFC 3330](https://tools.ietf.org/html/rfc3330){: .wikilink}{:target=\"_blank\"}{: .externallink} | B | 65,536 |
| 172.16.0.0 - 172.31.255.255 | 172.16.0.0/12 | [사설망](https://ko.wikipedia.org/wiki/사설망) | [RFC 1918](https://tools.ietf.org/html/rfc1918){: .wikilink}{:target=\"_blank\"}{: .externallink} | B | 1,048,576 |
| 192.0.2.0 - 192.0.2.255 | 192.0.2.0/24 | 문서와 예제 | [RFC 3330](https://tools.ietf.org/html/rfc3330){: .wikilink}{:target=\"_blank\"}{: .externallink} | C | 256 |
| 192.88.99.0 - 192.88.99.255 | 192.88.99.0/24 | [IPv6](https://ko.wikipedia.org/wiki/IPv6){: .wikilink}{:target=\"_blank\"}{: .externallink}에서 [IPv4](https://ko.wikipedia.org/wiki/IPv4){: .wikilink}{:target=\"_blank\"}{: .externallink}로의 애니캐스트 릴레이 | [RFC 3068](https://tools.ietf.org/html/rfc3068){: .wikilink}{:target=\"_blank\"}{: .externallink} | C | 256 |
| 192.168.0.0 - 192.168.255.255 | 192.168.0.0/16 | [사설망](https://ko.wikipedia.org/wiki/사설망) | [RFC 1918](https://tools.ietf.org/html/rfc1918){: .wikilink}{:target=\"_blank\"}{: .externallink} | C | 65,536 |
| 198.18.0.0 - 198.19.255.255 | 198.18.0.0/15 | 네트워크 장치 벤치마크 | [RFC 2544](https://tools.ietf.org/html/rfc2544){: .wikilink}{:target=\"_blank\"}{: .externallink} | C | 131,072 |
| 224.0.0.0 - 239.255.255.255 | 224.0.0.0/4 | [멀티캐스트](https://ko.wikipedia.org/wiki/멀티캐스트) | [RFC 3171](https://tools.ietf.org/html/rfc3171){: .wikilink}{:target=\"_blank\"}{: .externallink} | D | 268,435,456 |
| 240.0.0.0 - 255.255.255.255` | 240.0.0.0/4 | 예약됨 |
RFC 1700
| E | 268,435,456 |
표 출처 https://ko.wikipedia.org/wiki/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC%ED%81%B4%EB%9E%98%EC%8A%A4_
결국 아이피 주소와 네트워크의 고갈과 스케일 가능성 등의 이유로 사장되었고 CIDR로 바뀌게 되었다.
주소 집계(또는 경로 집계, 경로 요약)(address aggregation(or route aggregation, route summarization))
CIDR화(CIDRized) 주소가 라우팅에 미친 긍정적인 영향을 예시로 알아보자
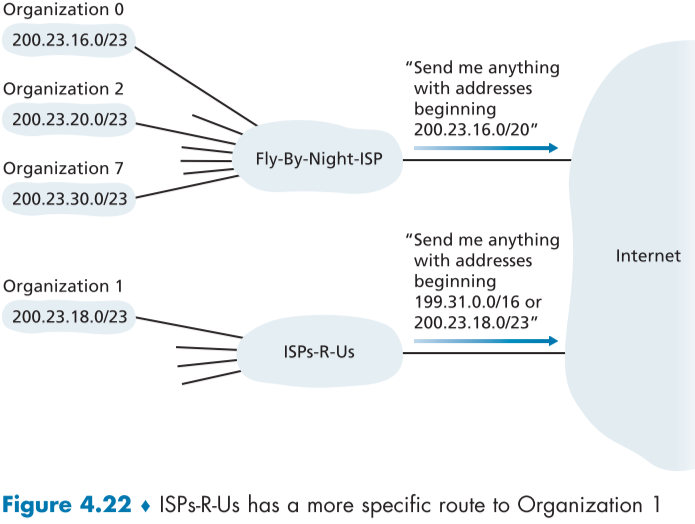
fig.4.21의 경우, Fly-By-Night-ISP에서 도합 8개의 조직(organization) 네트워크를 가지고 있으며, 인터넷 망에 자신의 서브넷 주소(200.23.16.0/20)를 등록하였다.
해당 ISP 외부에 속해있는 라우터들은 이제 Fly-By-Night-ISP의 서브넷 주소만 일치한다면, 어느 단체(organization)의 어떤 호스트인지 관계없이 그 뒤의 비트를 확인하지 않고 ISP 측 네트워크 방향의 링크로 패킷을 넘긴다.
이런식으로 하나의 접두어(prefix) 주소로 여러 네트워크를 통신 가능하도록 등록(advertise)하는 것을 주소 집계(또는 경로 집계, 경로 요약)(address aggregation(or route aggregation, route summarization))이라고 한다.
주소 집계는 블록 째로 ISP에 추가된 조직 네트워크와 잘어울린다.
하지만 만약 서브넷의 주소와 ISP 네트워크의 주소가 비슷하지 않은 경우, 예를 들어 fig.4.22처럼 조직 1(200.23.18.0/23)을 ISPs-R-US ISP측으로 이동시키려면 어떻게 해야하는가?
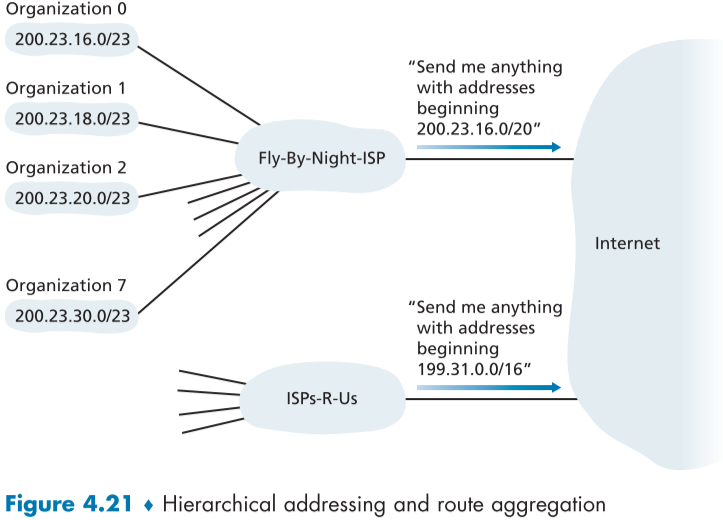
첫번째 방법으로 조직 1의 모든 장치들의 아이피 주소를 ISPs-R-Us ISP의 서브넷 마스크에 맞게 바꾸는 방법이 있다. 하지만 이 방법은 아주 힘들고 번거로운 일이며, 다른 조직의 추가, 삭제가 있을 때마다 할 수 있을 만한 일이 아니다.
두번째 방법은 조직 1의 서브넷 주소를 그대로 둔 채, ISPs-R-Us ISP 측에서 새로 추가된 해당 서브넷 주소도 함께 등록(advertise)하는 것이다.
아래 fig.4.22는 ISPs-R-Us가 새로 추가된 조직 1의 서브넷 마스크 또한 함께 인터넷에 등록하는 모습이다.
외부 라우터들은 언제나 최장 접두어 일치(Longest Prefix Match)를 통해 라우팅하므로, 조직 1의 서브넷 마스크는 23자리까지이므로 서브넷 주소가 비슷한 Fly-By-Night-ISP 측이 아니라 ISPs-R-Us측으로 패킷을 보낼 것이다.
조직을 위한 주소 블록 확보하기 (Obtaining a Block of Addresses)
만약 단체를 위한 서브넷을 조직하기 위해서는 ISP와 연락하여 ISP가 가지고 있는 아이피 주소 범위에서 일부를 할당받을 수 있다.
예를 들어, ISP가 8개의 조직을 연속적으로 할당해준다면 아래와 같이 가능하다.

ISP를 통하지 않고 아이피 주소를 할당 받는 방법은 ICANN(Internet Corporation for Assigned Names and Numbers)의 허락을 받는 방법밖에 없다.
ICANN은 아이피 주소, DNS 루트 서버, 도메인 이름과 분쟁에 대한 일을 처리하는 비영리 단체이다.
ICANN은 지역 인터넷 회사에게 아이피를 할당하고 지역 인터넷 회사들은 해당 할당받은 주소들을 관리한다.
호스트 주소 확보 : 동적 호스트 설정 프로토콜(DHCP)(Obtaining a Host Address: The Dynamic Host Configuration Protocol)
조직을 위한 주소 블록을 확보했다면, 호스트나 라우터 인터페이스에 아이피 주소를 할당할 수 있는데, 이는 네트워크 관리 도구로 직접 할당하는 것도 가능하지만, 보통은 동적 호스트 설정 프로토콜(Dynamic Host Configuration Protocol, DHCP)을 이용한다.
DHCP는 주소를 자동으로 설정해주며, 해당 호스트에게 연결시마다 같은 아이피 주소를 할당해 줄 수도 있고, 아니면 연결시에만 잠시 유지되는 임시 아이피(temporary IP address)를 할당할 수도 있다. 추가로 DHCP는 서브넷 마스크, 첫 홉 라우터(first hop router, 기본 게이트웨이(default gateway)라고 불리운다), 지역 DNS 서버의 주소 등의 추가 정보를 제공해준다.
이러한 자동 아이피 설정 기능 덕에 플러그 앤 플레이(plug-and-play), 제로컨프(zeroconf) 프로토콜이라고도 불리운다.
주로 주거지 인터넷 접근 네트워크나, 기업 네트워크, 무선 네트워크 같이 호스트가 자주 들어왔다 나가는 환경에 사용되며, 동적 아이피를 제한된 기간만큼으로 자주 할당해준다.
DHCP는 클라이언트-서버 구조 프로토콜이며, 클라이언트는 새로 네트워크에 참여하기 위해 네트워크 설정 정보를 요구하는 호스트이고, DHCP 서버가 서버 역할을 한다.
보통은 서브넷 마다 DHCP 서버가 있지만, 서브넷 내부에 DHCP가 없다면, DHCP 서버의 주소를 알고, 알려주는 역할을 하는 DHCP 릴레이 에이전트(DHCP relay agent)를 담당하는 라우터가 필요하다.
아래 fig.4.23 그림에서 DHCP 서버는 223.1.2/24 서브넷에만 DHCP 서버가 있으며, 중앙의 라우터는 다른 DHCP가 없는 서브넷을 위한 릴레이 에이전트 역할을 하고 있다.
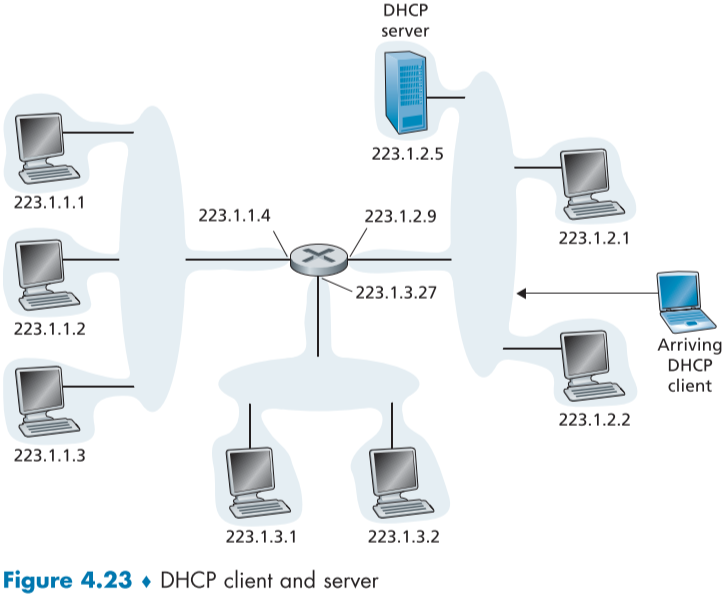
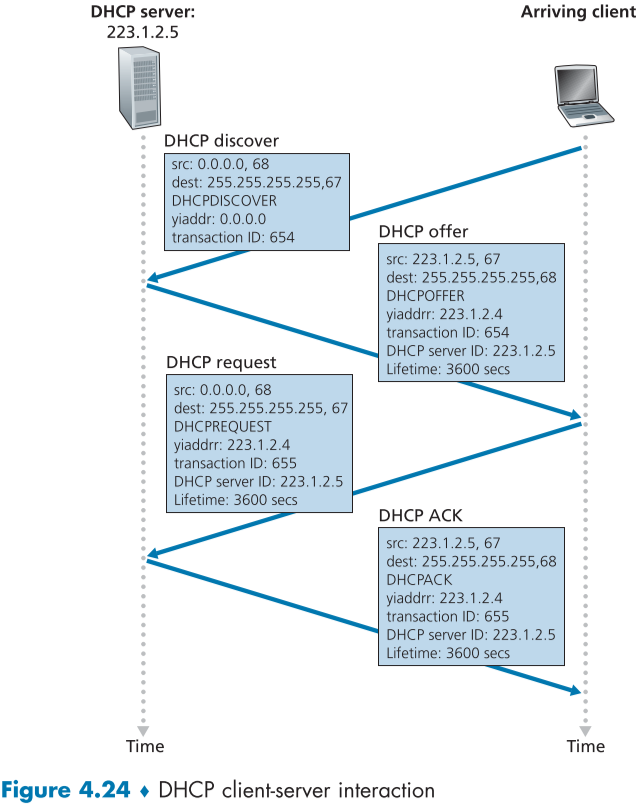
위의 fig.4.23의 구조에서 새로운 호스트가 도착하면 DHCP는 fig.4.24의 4단계 과정을 진행한다. yiaddr은 새로운 호스트에게 할당된 아이피 주소를 의미한다.
-
DHCP 서버 발견 (DHCP discover)
호스트가 통신할 DHCP를 찾는다, 호스트는 DHCP의 주소를 모르기 때문에 DHCP 발견 메시지(DHCP discover message)를 이용한다.
DHCP 발견 메시지는 포트번호 67번을 사용하는 UDP 패킷으로, 헤더의 목적지(destination) 아이피 주소를 255.255.255.255로, 자신을 의미하는 발신지(source) 아이피 주소를 0.0.0.0으로 설정하여 서브넷에 속한 모든 노드(호스트, 라우터, 스위치, 등등)들에게 메시지를 아이피 데이터그램에 캡슐화하여 보낸다.
목적지 주소가 255.255.255.255:67라면 라우터는 해당 패킷을 복사해 모든 노드에게 보내주며, 발신지 주소가 0.0.0.0:68인 이유는 이제 막 들어온 호스트의 경우 해당 서브넷에 아이피 주소가 할당되지 않았기 때문이다.
-
DHCP 서버 제공 (DHCP offers)
DHCP 서버가 DHCP 발견 메시지를 받게되면, DHCP 제공 메시지(DHCP offer message)를 255.255.255.255 번호로 브로드캐스트하여 보내게 된다.
클라이언트는 받은 여러개(DHCP 서버가 하나가 아닐 수도 있다.)의 DHCP 제공 메시지 중에 가장 나은 제안을 받아들인다.
각 DHCP 제공 메시지에는 어떠한 DHCP 발견 메시지의 요청인지 표해주는 트랜잭션 아이디(transaction ID)가 포함되있고, 아이피 주소, 네트워크 마스크, 아이피 대여 시간(보통 몇 시간~ 하루) 등이 제안되어있다.
-
DHCP 서버 요청 (DHCP request)
클라이언트(호스트)가 DHCP 제공 메시지를 받아들이고 싶다면, DHCP 요청 메시지(DHCP request message)로 해당 설정 파라미터들을 포함해 서버에 보내야한다.
아직 제안에 대한 확인이 오지않았으므로, 여전히 브로드캐스하며, 발신자 주소는 여전히 0.0.0.0:68 이다.
이때 트랜잭션 아이디가 새로 갱신되어, 그 뒤로 오는 ACK 메시지가 이전 메시지와 헷갈리지 않도록 한다.
-
DHCP ACK (DHCP ACK)
DHCP 서버가 위의 DHCP 요청 메시지를 받았다면, 같은 파라미터를 집어넣고 DHCP ACK 메시지(DHCP ACK message)를 돌려줘야한다.
사용자가 ACK 메시지를 받은 뒤 부터 아이피 주소를 사용 가능하므로 여전히 브로드캐스트로 보내야한다.
클라이언트가 DHCP ACK 메시지를 받은 뒤, 클라이언트는 할당받은 아이피 주소를 주어진 시간동안 사용 가능하다.
만약 해당 기간을 연장하고 싶으면, 위의 과정과 조금 다른 방법으로 연장 가능하다.(아마 discover과 offer 과정이 필요 없지 않을까?)
다만, 위 과정은 아쉬운 점이 하나 있는데, 사용자가 무선 인터넷 환경 등에서 이동을 하며 기존의 서브넷에서 나가 새로운 서브넷의 범위에 들면, 사용 중이었던 응용프로그램들의 아이피 주소가 바뀌므로 TCP 연결이 유지될 수 없다는 점이다.
이를 극복하는 방법은 챕터 7에서 배운다.
추가적인 DHCP에 대한 내용은 [Droms 2002], [dhc 2020] 등에서 알 수 있고, DHCP의 오픈소스 구현은 Internet Systems Consortium[ISC 2020]에서 볼 수 있다.
4.3.3.네트워크 주소 번역 (Network Address Translation (NAT))
작은 규모의 사무소나 집의(Small office, Home Office, SOHO) 서브넷이 계속 증가하는 추세이나, 이러한 작은 규모에서는 네트워크를 관리하기도 힘들고, ISP 측에서는 LAN으로 설정된 여러 장비(스마트폰, 인쇄기, TV, 프린터 등) 갯수 만큼 연속된 아이피 주소 공간을 무한히 할당해주는 것도 한계가 있다.
이를 해결해주는 방법이 네트워크 주소 번역(Network Address Translation, NAT)이다.
아래 fig.4.25는 NAT가 설정된 라우터의 모습이다. NAT 설정 라우터(NAT-enabled router)는 오른쪽 부분의 홈 네트워크(10.0.0.0/24)의 일부를 구성하고 있다.
아이피 주소 10.0.0.0/8은 사설망(private network)나 개인 주소 영역(realm with private addresses)을 위해 예약된 주소로, 이외의 용도로 해당 네트워크를 사용할 수 없다.(앞서 배웠던 네트워크 클래스 부분 참조)
개인 주소 영역은 소속 장치들의 아이피 주소가 해당 사설망내에서만 의미있음을 의미하는데, 이 세상에는 수많은 10.0.0.0/24 아이피를 사용하는 SOHO 네트워크가 존재할 것이므로, 개인 주소 영역의 아이피로 통신을 하면, 중복되는 같은 아이피가 수없이 많을 것이기 때문이다.
그러므로, 사설망 내의 아이피 주소를 가진 장비가 설정되었다면, 외부 인터넷과 통신하기 위해 NAT를 사용한다.
먼저, 홈 네트워크를 대표하는 NAT 설정 라우터의 아이피 주소를 첫 설정 하기 위해, ISP 측의 DHCP로 부터 가져오고, NAT 설정 라우터는 그 뒤로, DHCP 서버 행세를 하면서 홈 네트워크 내부의 디바이스에게 사설망의 아이피 주소(10.0.0.0/8)를 할당해준다.
NAT 설정 라우터(NAT-enabled router)는 외부 인터넷 입장에서 라우터가 아닌 하나의 아이피 주소를 가진 호스트로 행세하며, 패킷을 주고 받는다.
아래 예시에서는 홈 네트워크로 보내는 모든 패킷의 목적지 주소와 홈 네트워크에서 내보내는 모든 패킷의 발신지 주소가 NAT 설정 라우터의 아이피 주소인 138.76.29.7로 되있음을 알 수 있다.
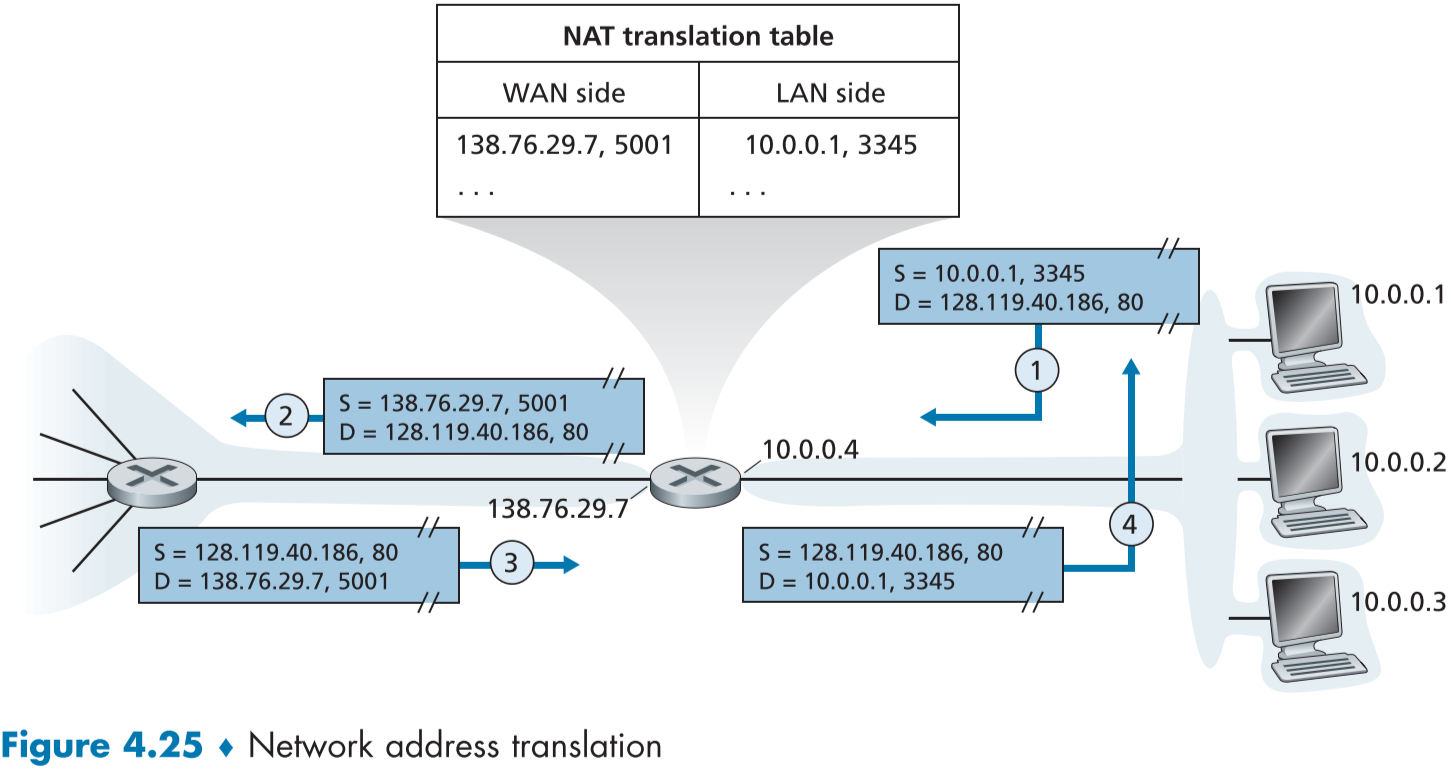
그렇다면 NAT 설정 라우터에게 오는 모든 WAN 측의 패킷은 같은 목적지 주소(NAT 설정 라우터의 아이피 주소)를 가지는데, 이를 어떻게 서로 구별하고, 각기 다른 홈 네트워크 내의 장치에게 돌려줄 수 있을까?
바로, NAT 번역 테이블(NAT translation table)을 이용해서 라우터가 가진 포트 번호를 각기 다른 홈 네트워크 장치에게 할당하여 구분해준다.
위 fig.4.25의 경우, 1번(10.0.0.1)의 경우, 포트번호를 3345의 응용 프로그램으로 외부의 웹서버(128.119.40.186:80)의 패킷을 보내주면, NAT 설정 라우터는 해당 디바이스의 아이피 주소와 포트번호(10.0.0.1:3345)를 NAT 번역 테이블에 자신의 아이피 주소와 새로 지정한 포트번호(138.76.29.7:5001)로 지정하여 이를 발신지 주소로 바꾸어 보낸다.
반대로 해당 장치를 위한 패킷 받을 시에는 자신의 아이피 주소와 지정했던 포트번호(138.76.29.7:5001)를 가진 패킷의 목적지 주소를 NAT 번역 테이블을 참고해 홈 네트워크 내의 주소(10.0.0.1:3345)로 고치고 보내준다.
즉, 홈 네트워크 장치의 응용 프로그램 하나 하나를 NAT 설정 라우터의 응용 프로그램으로 행세하게끔 하는 것이다. 참고로 포트번호 필드는 16비트 길이이므로 60000여개가 한계이다.
NAT로 인해 생기는 문제들을 생각해보자.
먼저, 홈 네트워크 내부의 장치가 well known 포트 번호를 가진 어플리케이션을 돌리려면 어떻게 해야할까?
예를 들어 홈 네트워크 장치에서 웹 서버(포트번호 80)를 돌리면, NAT 설정 라우터에서 임의의 포트번호로 바꾸어 버리면, 외부에서는 웹 서버로 인식되지 않을 것이다. NAT 설정 라우터의 웹서버 포트 번호 80을 할당할 경우, 이외의 다른 홈 네트워크 장치가 똑같이 웹 서버를 돌리면 중복되는 문제가 될것이다.
이를 해결하기 위해 NAT 트래버설(NAT traverasal) 장비를 이용한다[RFC 5390, 5128, Ford 2005].
두번째로 네트워크의 설계 철학에 반하는 이유인데, 라우터는 네트워크 레이어의 장비로써, 오직 데이터그램에만 관여해야 한다.
하지만 NAT 설정 라우터는 중간자 행세를 하며 패킷의 헤더 정보(목적지 주소)를 조작하고, 심지어 다른 계층인 전달 계층 헤더인 포트번호까지 조작한다. 자세한 내용은 4.5절의 미들박스(middlebox)에서 알아보자.
데이터 그램 조사: 방화벽과 침입 감지 시스템(INSPECTING DATAGRAMS: FIREWALLS AND INTRUSION DETECTION SYSTEMS)
우리가 네트워크 관리자가 됬을 경우, 외부의 공격자에게로 부터 다음과 같은 공격을 받을 수 있다.
공격자가 우리 네트워크의 아이피 주소 공간에 대한 정보를 확보한 뒤, 해당 아이피 주소 공간에 데이터그램 패킷을 보내 핑 스윕(ping sweep), 포트 스캔(port scan) 등을 통해 보안상 취약한 호스트, TCP/UDP 포트, 주소 등을 찾아내어, 변형된 패킷으로 취약점을 공격하거나 악성 소프트웨어(malware) 등을 심을 수도 있다.
이를 막기 위해서 두가지 보안 방법이 있다.
첫번째는 방화벽(Firewall)이다.
방화벽은 데이터그램과 세그먼트 헤더 필드를 확인하고, 의심스러운 패킷은 접근을 제어할 수 있다.
예를 들어 ICMP 에코 요청 패킷(ICMP echo request packets)을 막으면 기본적인 방법의 포트 스캔은 막을 수 있다. 의심스러운 발신지 주소의 패킷을 막거나, TCP 연결을 확인해 허락된 연결만 할 수 있도록 만들 수 있다.(Blacklist, Whitelist)
두번째는 침입 감지 시스템, IDS(Intrusion Detection System)이다.
IDS는 네트워크 경계에서 심층 패킷 조사(Deep packet inspection)을 통해, 패킷의 헤더 필드 뿐만 아니라 페이로드와 응용 계층 페이로드를 살펴보고 시그니처(일종의 해쉬)를 생성한다.
해당 시그니처를, 공격자들이 지금까지 시도해온 악성 패킷의 시그니처들을 저장해 놓은 데이터베이스와 대조하여, 만약 일치하는 악성 패킷이 감지되면 시스템에 주의를 표하거나 패킷을 차단한다.
데이터베이스는 새로운 공격자나 공격 패킷이 발생하면 업데이트한다.
IPS(Instrusion Prevention System)은 단순 주의 뿐만 아니라 추가로 패킷을 차단한다는 점이 다르다.
물론 이 두가지 보안만으로 완벽하게 방어해낼 수 없다, 예를 들어 새로운 공격 패킷을 이용하는 등의 방법이 있다.
하지만 네트워크를 공격자를 방어하는데 도움이 될 것이다.
보안에 대한 자세한 내용은 8장에 다룰 예정이다.
4.3.4.IPv6
IPv4의 빠른 고갈에 대처하기 위해 IPv6를 만들었다.
IPv6는 IPv4의 고갈과 기타 다른 문제점을 해결하기위해 만들어 졌고, 중간에 IPv5로 ST-2 프로토콜이 있었으나, 사장되었다.
IPv6 데이터그램 형식(IPv6 Datagram Format)
아래 fig.4.26은 IPv6 데이터그램의 형식이다.
이 가장 크게 변한 부분은
-
주소 수용량 확장(Expanded addressing capabilities)
IPv6에서는 기존의 IPv4의 아이피 주소 크기를 32비트에서 128비트로 늘렸으며, 할당될 수 있는 주소는 지구 상의 모든 모래알 보다 많다.
또한 일대일 통신인 유니캐스트(unicast), 일대다 통신인 멀티캐스트(multicast), 이외에 일대 가장 적합한 일 통신인 애니케스트(anycast)통신이 생겼으며, 이를 통해 예를 들면 사용자와 서버 클러스터들 중 가장 딜레이가 적은 서버와 통신 등을구축 할 수 있다.
-
간결한 40바이트 헤더(Streamlined 40byte header)
많은 양의 IPv4 헤더 필드가 없어지거나 선택할 수 있게 되었고, 언제나 고정적으로 40byte인 헤더 길이로 헤더 길이 탐색을 할 필요가 없어 오버헤드가 줄어들었고, 새로운 옵션 인코딩으로 옵션 처리가 자유로워 졌다.
-
흐름 레이블링(Flow labeling)
IPv6 개발자가 흐름을 애매모호하게 정의했기 때문에 덕분에 흐름 레이블을 여러가지 용도로 사용할 수 있다.
예를 들면, 비디오나 오디오 스트리밍을 흐름으로 레이블하고, 이메일과 FTP 등을 비흐름으로 레이블하여 처리율에 차이를 둘 수 있고, 일부 우선순위가 높은 사용자를 지정해줄 수도 있다.
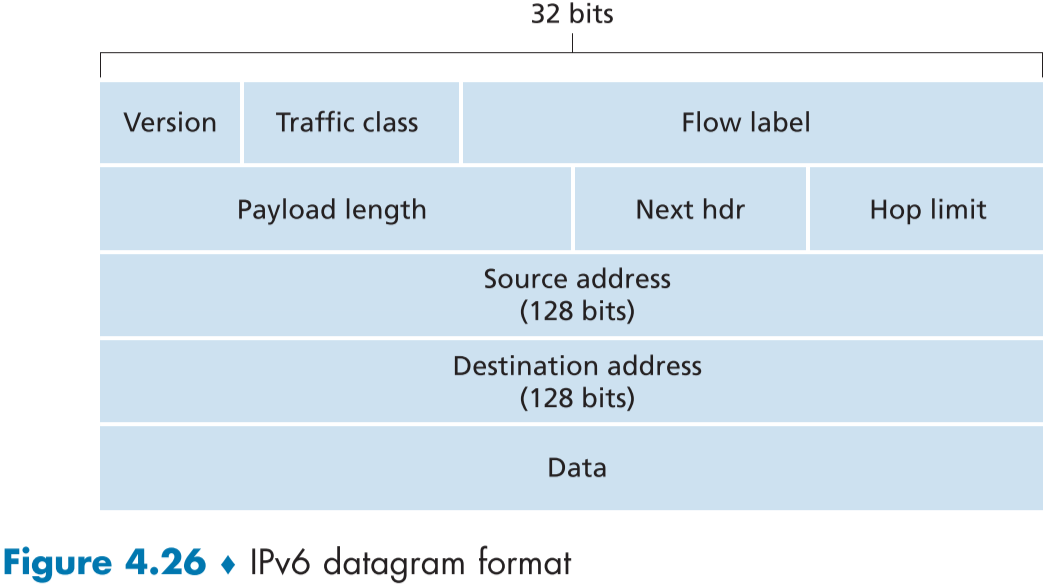
다음은 IPv4에 비해 간결화된 IPv6의 헤더 필드들이다.
| 필드 이름 | 설명 | 크기(bit) |
|---|---|---|
| 버전(Version) | IP 버전 번호, IPv6는 6번이다. | 4 |
| 트래픽 클래스(Traffic class) | IPv4의 TOS 필드, 흐름의 우선순위 등을 적는 곳, 특정 패킷 흐름에 우선순위를 주는 방법 등으로 사용 | 8 |
| 흐름 레이블(Flow label) | 위에서 말한 패킷 흐름에서 흐름을 구분하기 위해 사용함, 즉, 이곳은 흐름의 식별자를 적는 곳 | 20 |
| 페이로드 길이(Payload length) | 비부호(unsigned, 양수만 존재) 정수로 데이터그램의 페이로드 크기를 적는다. | 16 |
| 다음 헤더(Next header) | 현재 데이터그램이 어떤 전달 계층 프로토콜을 이용하는가 적는다. IPv4와 같은 값을 사용함. | 8 |
| 홉 한계(Hop limit) | 현재 데이터그램이 몇번의 라우터를 거칠 수 있는지 적는다. 라우터를 지날때 마다, 이 필드의 값을 1씩 줄이고 0이 되는 순간 라우터가 패킷을 폐기한다. | 8 |
| 발신지, 목적지 주소(Source and Destination addresses) | 각각 128 비트의 주소 정보 | 128, 128 |
| 데이터(data) | 데이터그램의 데이터가 들어가는 부분, 목적지 도착시 이 부분만 다음 계층에 전달된다. 보통 전달 계층의 세그먼트가 담긴다. |
IPv4 데이터그램과 비교해서 다음과 같은 일부 필드가 없어진 것을 확인할 수 있다.
-
조각/조립(Fragmentation/reassembly)
IPv6는 데이터그램을 경로 중간의 라우터가 조각내고 다시 조립하는 것을 허락하지 않으며, 오직 발신지와 목적지에서만 가능하다.
대신, IPv6 데이터그램의 크기가 너무 크면, 라우터는 해당 패킷을 버리고 송신자 측으로 ICMP 에러 메시지 “패킷 사이즈가 너무 큽니다.” 를 보내며, 송신자 측은 이를 받으면 데이터그램을 여러개로 쪼개서 다시 보낸다.
위 과정을 통해 중간에 라우터들이 반복적으로 쪼개고 조립하는 과정을 없애서 성능을 높일 수 있다.
-
헤더 체크섬 (Header checksum)
IPv6 개발자들은 상위계층인 전달 계층에서 오류 확인을 하므로 중복하여 체크할 필요없다고 느꼈을 뿐만 아니라, 매 라우터 마다 TTL, 또는 홉 한계(Hop limit)값이 바뀌므로 해당 체크섬 기능을 위해 매 라우터 마다 바뀐 헤더의 체크섬값을 재계산하는 것이 너무 성능이 나빠진다고 생각했다.
-
옵션(options)
IPv6부터는 옵션을 제공하지 않아 언제나 헤더 크기가 40byte 로 고정되어 있다. 대신 next header 필드의 값으로 확장 헤더를 사용하고 있는지 표시할 수 있어서 이를 통해 확장 헤드의 추가 헤더를 이용할 수 있다.
IPv4에서 IPv6로의 전환 (Transition from IPv4 to IPv6)
IPv4 환경의 인터넷을 IPv6 시스템으로 바꾸려면 어떻게 해야할까? 과거에는 특정 기점으로 이전의 방법은 대체되었음을 알리고 새로운 방법을 쓰게 하였다. 과거 NCP가 TCP 프로토콜로 바뀌었을 때 그러했지만, 네트워크 규모가 작았을 때 가능한 일이였고, 현재로서는 불가능하고 비효율적인 방법이다.
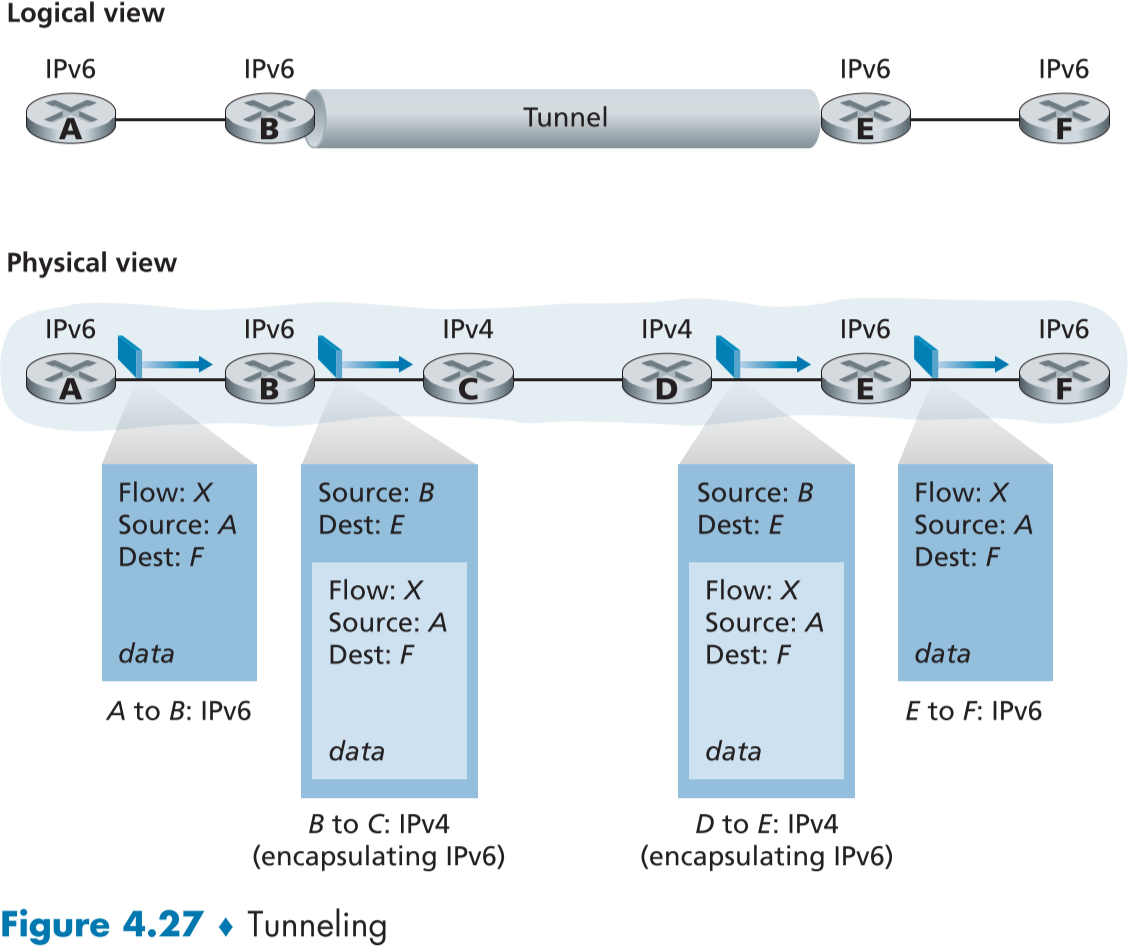
현재 IPv4에서 IPv6 시스템으로 바꾸는 데 가장 많이 사용되고 있는 방법은 터널링(tunneling)[RFC 4213]이다.
fig.4.27에서 처럼 IPv6 라우터 사이의 IPv4만 지원하는 라우터가 존재할 수 있는 중간 경로를 터널(Tunnel)이라고 칭한다.
-
터널의 시작점(즉, 데이터그램의 보내는 서버 방향에 가까운 쪽)의 IPv6 라우터 B는 받은 IPv6 데이터그램을 IPv4 데이터그램의 payload에 집어넣어 새로운 패킷을 생성한다. 이때 IPv4의 헤더는 IPv6에서 값을 가져온다.
-
그렇게 IPv6 데이터그램을 품은 IPv4 데이터그램은 터널을 지나면서 IPv4 라우터나 IPv6 라우터(보통 헤더를 확인해 IPv4도 지원하게 만듦)를 만나도 안전히 다음 라우터로 이동할 수 있다.
-
터널을 통과하면, 앞으로 IPv6 라우터 밖에 존재하지 않으므로, 터널을 끝점(즉, 데이터그램의 받는 서버 방향에 가까운 쪽)에 존재하는 첫번째 IPv6가 해당 IPv4 내부의 페이로드를 확인하고, 만약 IPv6 데이터그램이 통채로 들어있으면 페이로드를 패킷으로 목적지 서버까지 보낸다.
이렇게 IPv6는 IPv4만 지원하는 라우터들을 지나고서도 안전하게 목적지 라우터에 도착할 수 있다.
이러한 방법 덕분에 IPv4에서 IPv6로 천천히 시스템이 바뀌어 나가고 있다.
이러한 낮은 계층의 변화는 마치 건물의 기반부터 바꾸는게 어려운 것처럼, 갑자기 바꾸기 쉽지 않다. 하지만 그에 반해 웹, 게임, 소셜 미디어 같은 응용 계층의 프로토콜. 응용 프로그램은 시대가 바뀌면서 빠르게 바뀌고 추가된다. 위에 영향을 줄 다른 계층이 없기때문이다.
4.4.일반화된 포워딩과 SDN (Generalized Forwarding and SDN)
우리는 라우터에서의 포워딩이 match-plus-action으로, 목적지 주소를 살피고(match), 해당 출력 포트로 스위칭 패브릭이 패킷을 보내는(action) 과정이라고 말했다.
좀더 일반화된 match-plus-action을 살펴보자면, 먼저, match의 경우 여러 종류의, 여러 계층에서의, 여러 프로토콜에서의, 헤더 필드를 읽어야 한다.
또한, action의 경우, 단순히 패킷을 포워딩하는 것 뿐만 아니라, 여러 출력 포트로 포워딩, 부하 밸런싱(load balancing), 패킷 헤더 고쳐쓰기(NAT), 패킷 필터링(방화벽), 패킷을 특정 서버에 보내 추가적인 처리를 거친 후 포워딩 하기(DPI) 등이 존재한다.
일반화된 match-plus-action에서는 링크 계층의 스위치나 네트워크 계층의 라우터를 합쳐서 SDN에서 사용하는 용어인 패킷 스위치로 부르겠다.
아래 fig.4.28을 보면 이전 라우팅에 관한 그림과 달리 일반화된 포워딩에서는 원격 컨트롤러가 포워딩 테이블(정확히는 같은 역할을 하는 플로우 테이블)을 계산, 설치, 갱신 해주며, 포워딩 테이블 대신 지역 플로우 테이블(Local flow table) 이라는 것을 이용한다는 것을 알 수 있다.
일반화된 포워딩에서는 오픈플로우(OpenFlow)[McKeown 2009, ONF 2020, Casado 2014, Tourrilhes 2014]를 이용할 것이다.
오픈플로우는 match-plus-action 포워딩과 컨트롤러, SDN에 혁신적인 영향을 끼친 개념이다.
오픈플로우 1.0을 통해 SDN의 개념과 기능에 대해서 알아볼 것이고, 최신 버전 오픈플로우는 [ONF 2020]에서 볼 수있다.
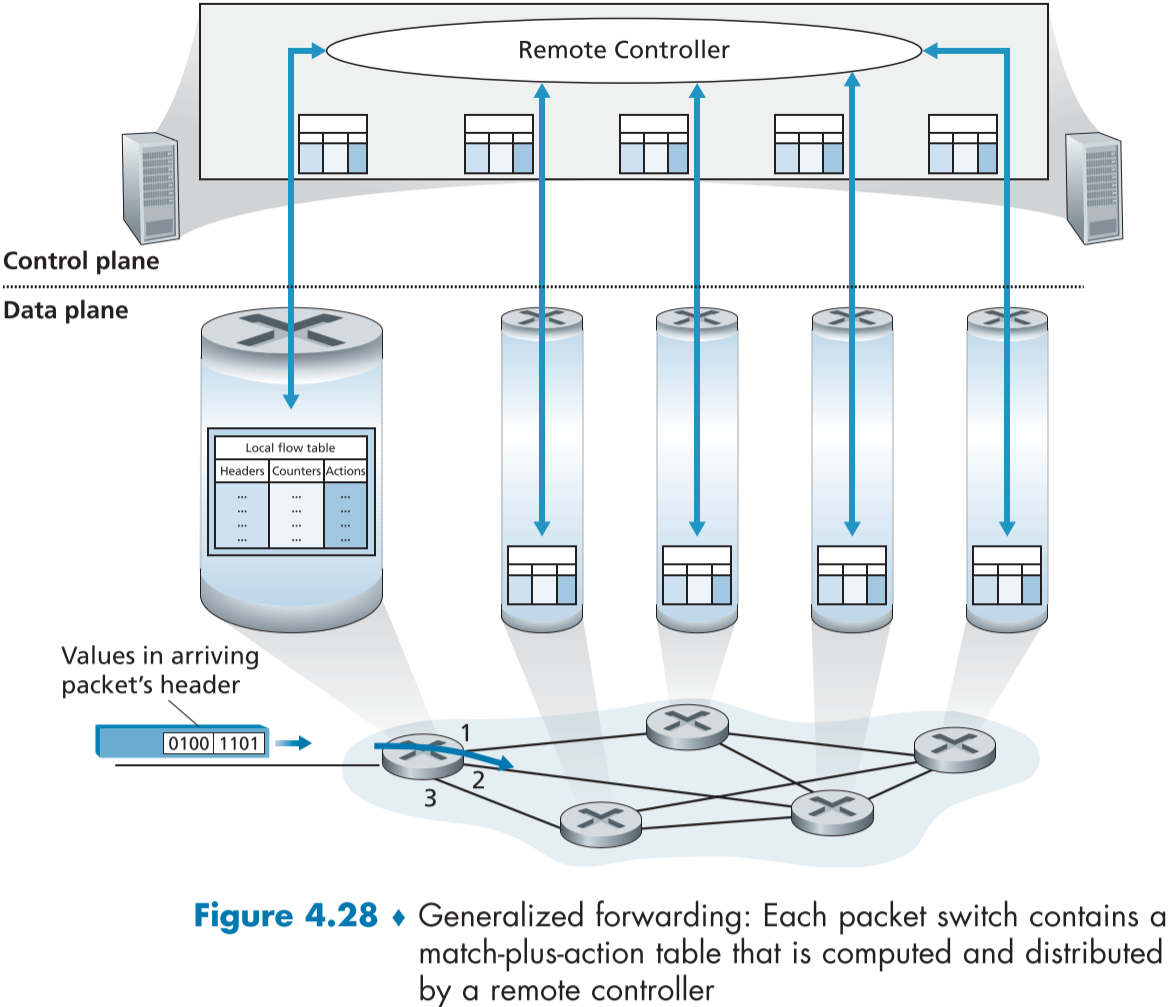
오픈 플로우에서 사용하는 match-plus-action 포워드 테이블 또는 플로우 테이블(flow table)의 항목(entry)들은 다음과 같은 정보를 포함하고 있다.
-
입력 패킷의 헤더와 비교할 헤더 필드 값들의 집합
하드웨어 기반 방법인 TCAM을 이용하면 길이 수십만 수준의 플로우테이블도 검사할 수 있다.
플로우테이블에 일치하는 결과가 없는 패킷의 경우 버려지거나 원격 컨트롤러로 보내져 추가 처리를 받게 된다.
실제로는 성능상의 이유로 여러 플로우테이블을 유지하지만 우리는 일단 하나로 생각하고 학습할것이다.
-
플로우 테이블에 일치한 패킷들로 갱신되는 카운터의 집합
플로우 테이블의 항목에 일치한 패킷의 수와 마지막으로 업데이트한 시점을 갱신하며 기록한다.
-
플로우 테이블에 일치되면 취할 활동들의 집합
패킷을 출력 포트로 포워딩하거나, 버리거나, 복사하여 여러 출력포트로 보내거나 헤더 필드를 기록하는 등의 활동이 있다.
플로우테이블은 엄밀히 말하면 패킷 별로 할 행동이 적혀있는 API로, 여러 패킷 스위치에 존재하는 테이블들을 수정하여 행동들을 행하게할 수 있다.
4.4.1.일치(Match)
아래 그림 fig.4.29는 오픈플로우 1.0에서 match-plus-action 규칙에 의해 일치할 수 있는 11개의 패킷 헤더 필드와 들어온 포트 아이디 정보를 표현한 것이다.
- 총, 12개지만 최근 버전 오픈플로우에는 41개까지 늘어난다.
우리 모두 패킷은 여러 계층의 패킷이 상위 계층의 패킷을 페이로드에 캡슐화하여 만들어진 것임을 알고 있으며, 아래 그림을 보면 3개의 계층 패킷의 헤더 요소를 참조하여 비교한다는 것을 알 수 있다.
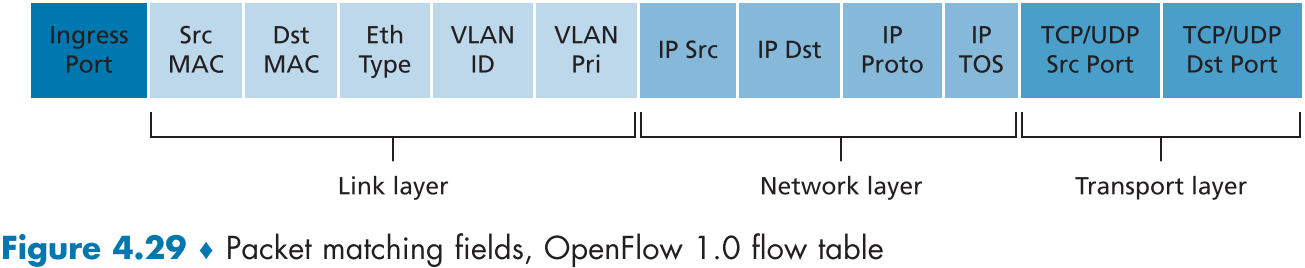
아직 링크 계층에 대해서 자세히 배우지 못했지만, 대략적으로 각 요소를 설명해보겠다.
-
Src/Dst MAC
링크 계층의 송수신 이더넷 주소, 오픈플로우는 네트워크 계층 장비인 라우터이외에 링크 계층 장비인 스위치에서도 프레임을 포워딩하는데 쓸 수 있다.
-
Eth Type
이더넷 종류 필드는 어떤 종류의 상위계층 패킷으로 역다중화(demultiplexed)될 것인가? 보통은 아이피 프로토콜
-
VLAN
가상 로컬 지역 네트워크(virtual local area network)에 대한 필드, 챕터 6 참조
-
Ingress Port
입장(Ingress) 포트는 패킷 스위치의 패킷이 들어온 입력 포트를 의미한다.
-
IP Src, IP Dst, IP Proto, IP TOS
아이피 데이터그램 형식에서 배웠던 헤더 필드 그대로이다.
-
TCP/UDP Src/Dst Port
전달 계층 패킷 헤더의 필드
오픈플로우의 플로우테이블의 각 항목(entry)에는 와일드카드(wildcard)가 존재할 수 있는데, 예를 들어 아이피 주소 정보가 128.119.*.* 로 되어있다면, 이는 앞의 128.119 부분이 일치하는 모든 아이피 주소를 일치시키라는 의미이다. 또한 여러 항목과 일치할 때를 대비하여 관련 우선순위에 대한 정보도 있다.
굳이 패킷 헤더의 모든 필드를 비교하지 않고 일부만 하는 이유는 기능성과 복잡도를 저울질 하여 최소한의 비교가 가능하게 끔 만든 것이다. (추상화에 필요한 요소 최소화)
4.4.2.활동(Action)
각 플로우 테이블의 항목은 일치했을 때 취해야할 행동(Actioin)이 0개 이상 존재하며, 여러개가 존재할 시, 주어진 순서대로 처리한다.
활동의 예시로는
-
포워딩 (Forwarding)
들어온 패킷을 입력 포트를 제외한 특정 물리적 출력 포트나, 여러 포트, 또는 모든 포트에게 보낼 수 있다. 추가로 패킷은 캡슐화되거나 원격 컨트롤러에게 보내져 추가 처리를 받고 돌아오거나, 플로우 테이블가 업데이트 되는 등의 활동을 할 수 있다.
-
버림 (Dropping)
플로우 테이블 항목에 아무런 활동이 적혀있지 않으면 패킷은 버려진다.
-
필드 수정 (Modify-field)
아이피 프로토콜 필드(IP Protocol field)를 제외한 10개의 패킷 헤더 필드의 값을 수정한 뒤 포워딩 될 수 있다.
- 입장 포트(Ingress Port)는 패킷 헤더 필드 값이 아니다.
4.4.3.매치-플러스-액션 활동의 오픈플로우 예제(OpenFlow Examples of Match-plus-action in Action)
아래 fig.4.30과 같은 네트워크 예시에서 구현할 네트워크 전역 행동(network-wide behaviors)과 이러한 행동을 구현할 플로우 테이블 항목 s1, s2, s3에 대해 고려해보자.
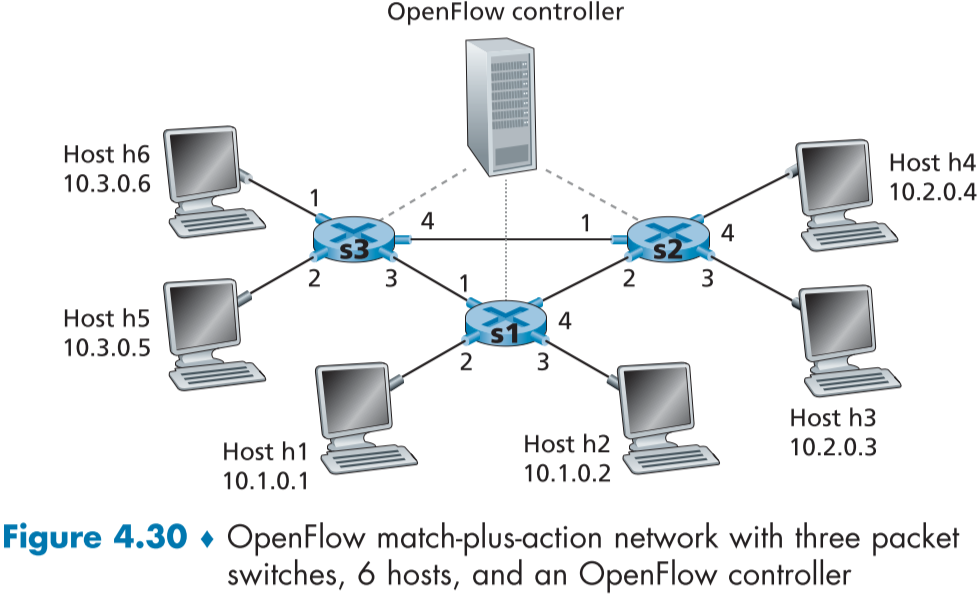
첫 예제: 단순 포워딩(A First Example: Simple Forwarding)
먼저 호스트 h5, h6가 라우터 s3, s1, s2 순서로 거쳐 호스트 h4나 h3에 패킷을 전송하는 행동을 구현해보자.
아래는 위 행동을 하기 위한 라우터별 플로우 테이블 예시이다.

s1 라우터의 경우 호스트 h5 또는 h6의 패킷이 1번 포트를 통해 들어올 것이므로, 활동(Action)에 4번 포트로 보내 s2 라우터로 보낸다.
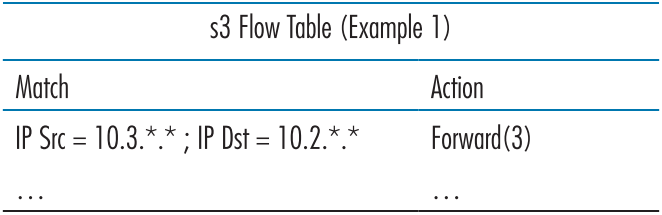
s3 라우터의 경우, 입장 포트가 1번 또는 2번이 될 수 있으므로, 입장 포트(Ingress Port)는 일치(Match) 항목에 적지 않고, 주소로 판별하여 3번 포트를 통해 s1 라우터로 보낸다.

s2 라우터의 경우, 입장한 패킷의 주소를 보고 해당 호스트가 존재하는 출력포트로 보낸다.
두번째 예제: 부하 밸런싱(A Second Example: Load Balancing)
이번에는 호스트 3이 10.1.*.*로 보낸 데이터그램은 라우터 s2와 s1 사이의 링크를 이용해 이동하고, 호스트 4가 10.1.*.*로 보낸 데이터그램은 라우터 s2와 s3 사이의 링크와, 라우터 s3와 s1 사이의 링크를 지나 이동하는 시나리오를 생각해보자.
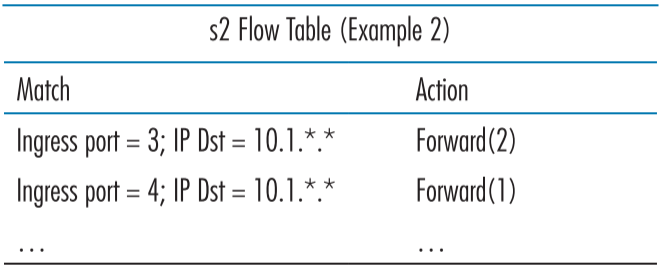
같은 목적지 주소를 가지되, 입장 포트에 따라 다른 라우터로 보내게 만들면 된다.
세번째 예제: 방화벽 차단(A Third Example: Firewalling)
s2 라우터가 s3 라우터와 연결되어 있는 호스트의 패킷만 받아들이게 하고 싶다면,

아이피 발신자 주소가 10.3.*.*인 패킷만 3번 포트, 4번 포트로 나가게 될 것이며, s2의 플로우테이블에 위 두 항목 이외의 항목이 없다면 이외의 패킷은 행동이 적혀있지 않으므로, 버려지게 된다.
우리가 살펴본 시나리오는 상당히 제한되고 기본적인 부분이며, 좀더 복잡하고 논리적으로 분리된 가상 네트워크 등 또한 만들 수 있다.
플로우 테이블 내의 활동과 일치보다 더욱 복잡한 프로그래밍을 P4(Programming Protocol-independent Pacekt Processors)[P4 2020] 프로그램 언어를 통해 가능하다.
4.5 미들 박스(Middleboxes)
RFC3234에 적혀있는 미들박스의 정의는 다음과 같다.
발신지와 목적지 사이 데이터 경로에서 아이피 라우터가 실행하는 기본적인 기능 이외의 추가적인 기능을 실행하는 중간 박스
우리는 앞서 웹캐쉬, TCP 연결 분배기, NAT, 방화벽과 IDS, 부하 밸런싱과 match-plus-action을 실행하는 최신 라우터들 같은 미들박스들을 많이 만나보았다.
무선 환경, 유선환경 따지지 않고 미들박스가 실행하는 서비스의 종류는 크게 세가지로 나뉜다.
-
NAT 번역(NAT Translation)
4.3.4에서 배웠던 것처럼, 주로 사설망 주소 생성, 데이터그램 헤더 주소와 포트 번호 수정 등을 함.
-
보안 서비스(Security Services)
방화벽은 트래픽을 헤더 필드 기준으로 막거나 DPI(deep packet inspection) 같은 추가적인 처리 이후 리다이렉트한다. IDS는 이전에 방화벽과 IDS 절 참조.
-
성능 향상(Performance Enhancement)
패킷 압축, 컨텐츠 캐싱, 부하 밸런싱 등을 통해 서버의 부하를 줄이고 요청에 빠르게 대답할 수 있음.
이러한 미들박스의 확산은 성능 상의 이점을 주지만 별도로 관리자에게 장비를 장비, 관리 및 업그레이드 하는데 시간과 비용을 쏟게 만든다.
이런 서비스를 쉽게 제공하기 위해 개별 라우터가 아닌 중앙 서버 등에서 미들박스를 대체할 소프트웨어 스택으로 이루어진 전용 소프트웨어가 포함되어 있는 상용 하드웨어(SDN의 접근 방법과 유사) 등을 연구 중인데 이러한 방법을 네트워크 기능 가상화(NFV, Network function virtualization)라고 한다.
또 다른 방법은 이런 미들박스의 기능들을 클라우드를 이용해 처리하는 것이다.
사실 이전까지의 인터넷 구조에서는 네트워크 엣지에서 실행되는 호스트 측에서 주로 활동하며 전달/응용 계층과 네트워크 코어에서 실행되는 라우터, 스위치 측에서 주로 활동하는 나머지 계층이 확연히 구분되어왔지만, 이러한 미들박스들은 이러한 원리를 어기고 있다.
예를 들어, 방화벽이 계층과 관계없이 헤더들을 확인하고, NAT가 라우터와 호스트 사이에서 멋대로 패킷을 수정하거나, 이메일 보안 게이트웨이(e-mail security gateway)가 이메일 송수신자 사이를 가로막는 등의 일이다.
하지만 미들박스는 어떻게든 필요성에 의해 존재하고 점점 늘어나고 있다.
인터넷의 구조적 기반(ARCHITECTURAL PRINCIPLES OF THE INTERNET)
[RFC 1958]에 의하면 인터넷의 구조적 기반은 다음과 같다.
“많은 인터넷 커뮤니티 구성원들이 주장하길, 적어도 25년 역사동안 인터넷은 구조는 없고 오직 관습만 존재했다고 한다. 하지만 커뮤니티들은 목적은 연결성이고, 도구는 인터넷 프로토콜이며, 지식은 네트워크에 숨겨져 있기보단 종단간 연결이라고 믿는다”
즉 연결을 하기위해 아이피 프로토콜을 이용하였고, 지식(또는 복잡성)은 네트워크 코어보다는 네트워크 엣지에 있어야 한다는 것이다.
아이피 모래 시계 (The IP HOURGLASS)
다른 계층은 다양한 프로토콜이 사용되고 있음과 달리 네트워크 계층은 아이피 프로토콜이 거의 주가 되어 사용되고 있다.
이러한 인터넷 구조를 아이피 모래 시계 (The IP HOURGLASS) 또는 얇은 허리(narrow waist)라고 한다.
아이피 프토토콜의 간단함과 통일성 덕분에 인터넷이 성황될 수 있었고 미들박스가 등장했다.
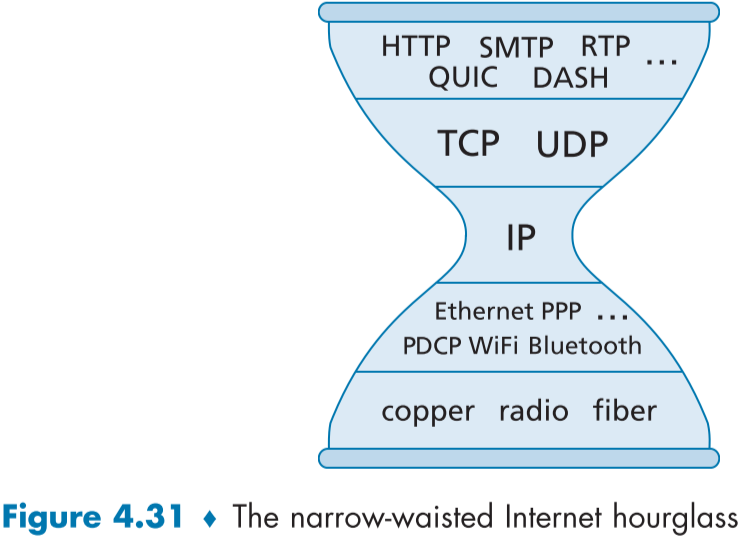
종단 인자 (THE END-TO-END ARGUMENT)
앞서 언급했던 End-to-End는 네트워크에서의 기능들의 위치를 의미한다. 최근 대부분의 기능들은 네트워크 엣지에 위치한다.
_articles/computer_science/network/네트워크 정리-Chap 4-네트워크 계층-데이터 측면.md