풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
OS 정리-Chap 7-메모리 관리
7. 메모리 관리
IT COOK BOOK 운영체제 (개정 3판, 구현회 저, 한빛 아카데미) 를 정리한 내용입니다.
01 메모리 관리의 개요
1 메모리 관리의 개념과 정책
메모리란 디스크에 있던 프로그램을 적재하여 실행하는 작업 공간
메모리 관리는 프로세스들을 위해 메모리를 할당, 제거, 보호하는 기술
메모리 관리자는 운영체제의 관리 모듈과 메모리 관리 장치(MMU, Memory Management Unit)이 협업하여 적재 정책, 배치 정책, 대치 정책을 통해 메모리를 관리
메모리 관리 정책
- 적재 정책(fetch policy) : 디스크에서 메모리로 프로세스를 반입할 시기를 결정하는 것
- 요구 적재 : 운영체제, 프로그램 등의 참조 요청에 따라 다음 프로세스를 메모리에 적재
- 예상 적재 : 시스템의 요청을 미리 예측에 메모리에 적재, 보조기억장치의 탐색 시간, 회전 지연 특성 또한 참조.
- 배치 정책(placement policy) : 디스크로 부터 반입한 프로세스의 메모리 상 적재 위치를 결정하는 것
- 최초 적합
- 최적 적합
- 최악 적합
- 교체 정책(replacement policy) : 메모리 부족 시 제거할 메모리 내의 프로세스를 결정하는 것
- 선입선출, 최소사용 알고리즘 등이 존재 (8장 참조)
2 메모리의 구조와 매핑(사상)
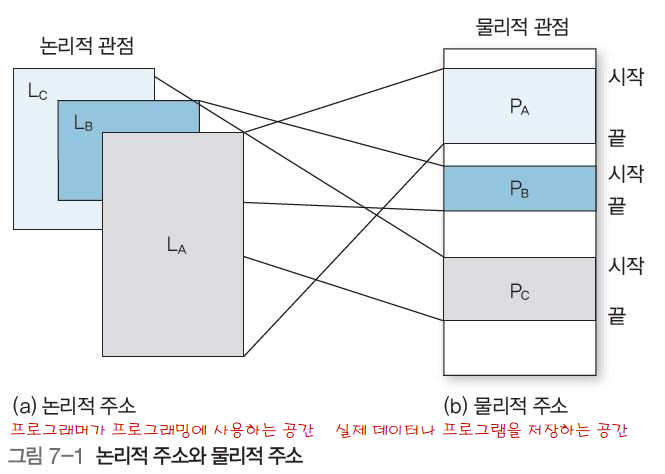
메모리는 주소의 연속으로 이루어져 있으며, 주소는 크게 두가지 관점으로 해석 가능
-
프로그래밍에 사용되는 논리전 관점의 논리적 주소 (그림 7-1 (a)), 가상 주소라고도 함
목적 코드(object code), 자료 구조등이 해당
-
실제 데이터나 프로그램을 저장하는 물리적 관점의 물리적 주소 (그림 7-2(b)), 실제 주소
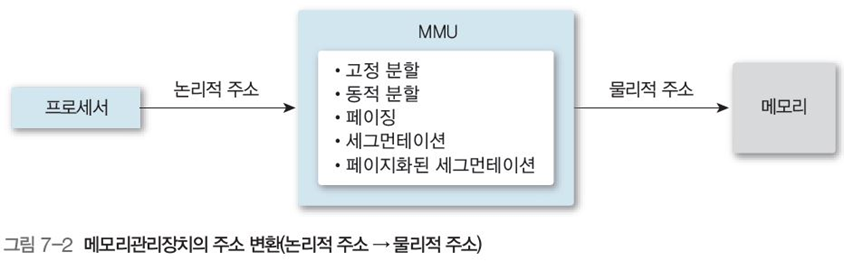
논리적 주소와 물리적 주소는 메모리 관리 장치(MMU)에 의해 변환되며, 그림 7-2와 같이 동여러 번환 방법이 존재한다. 이때, 변환을 위해서는 논리적 주소에 대응 하는 물리적 주소를 알아야 한다.
예를 들어 프로그래밍 언어에서 변수 라는 논리적 주소의 값을 알기 위해서는 메모리 주소라는 물리적 주소를 알아야 한다.
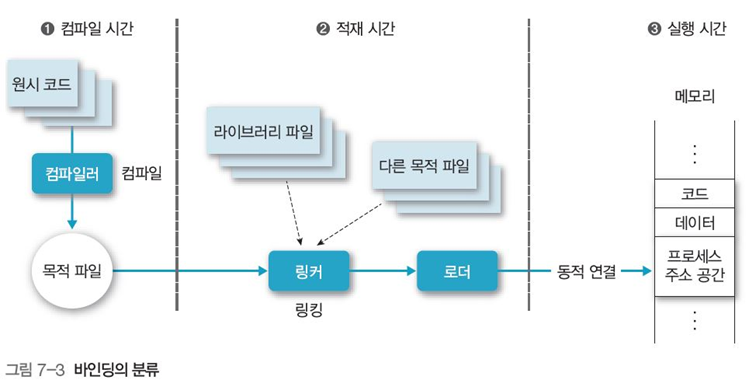
프로세스의 논리적 주소에 대응하는 물리적 주소를 연결, 즉 매핑(mapping)하는 것을 바인딩(binding)이라고 하며, 바인딩은 변환 시점에 따라 3가지로 나눌 수 있다.
-
컴파일 시간
컴파일러가 메모리에서의 프로세스 위치를 파악하고 물리적 주소에 배치한 뒤, 확장시켜 나간다. 만약, 시작 위치가 바뀌어야 한다면, 코드를 다시 컴파일 해야한다.
-
적재 시간
만약, 컴파일러가 적재 위치를 모른다면, 대신 시작 주소가 0인 상대 주소를 생성한 뒤, 바인딩은 적재 시간에 이루어 지게 한다. 시작 주소가 변하면 사용자 코드를 재적재 한다. 이를 정적 대치라고 한다.
-
실행 시간
가장 주요한 바인딩 방법, 기본 및 경계 레지스터 등의 하드웨어를 이용해 수행시간에 바인딩, 이를 이용해 프로세스가 메모리의 세그먼트 간에 이동하면서 실행할 수 있다. (동적 연결)
- 컴파일러(compiler)가 원시 코드를 컴파일해 목적 파일을 생성
- 링커(linker)가 목적 파일에 라이브러리 파일이나 다른 목적 파일을 결합
- 로더(loader)가 지정 위치에서 시작해 메모리에 프로그램을 배치, 배치 방법은 다음이 존재
- 절대 적재 : 프로그램을 메모리의 지정된 위치에 적재
- 교체 적재: 프로그램을 메모리의 여러 위치에 적재
3 메모리 관리 관련 용어
3.1 동적 적재(dynamic loading)
필요한 일부 루틴만 메모리에 적재하고 나머지는 적재 가능 상태로 디스크에 저장하다가 필요 시 메모리의 다른 루틴과 교체하여 주소 테이블을 갱신하는 방법
바인딩을 실행 직전에 실행하는 동적 적재로 효율적인 메모리 관리가 가능케 되었다.
🟢 PROS: 효율적인 메모리 사용
🟠 CONS : 오류 발생 가능성, 구현의 어려움
3.2 중첩(오버레이, overlay)
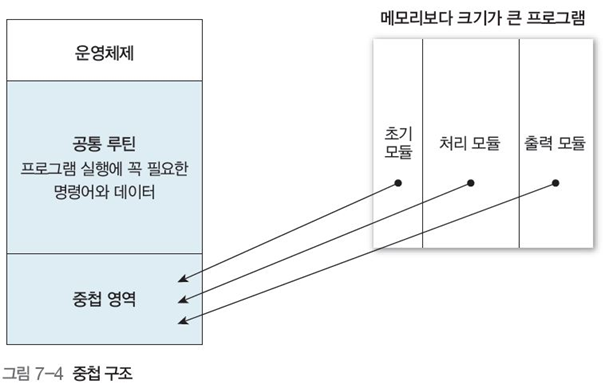
특정 시기에만 사용하는 일부 데이터를 메모리 내의 중첩 영역에 순차적으로 호출하여 그림 7-4 처럼 적재 및 교체 하는 적재 방식
운영체제 영역과 필수적인 공통 루틴은 메모리에 무조건 포함된다.
🟢 PROS
-
운영체제 지원없이 메모리에 따른 분기와 파일구조를 이용해 구현 가능
-
규모가 큰 프로세스를 메모리에 효율적이게 적재 가능
🟠 CONS
- 프로그램 구조, 코드, 자료구조를 완전히 이해해야 구현 가능, 현 시대의 큰 규모의 프로그램에 적용 힘듦, 마이크로 컴퓨터나 메모리 크기가 극히 제한된 임베디드 시스템에서만 사용
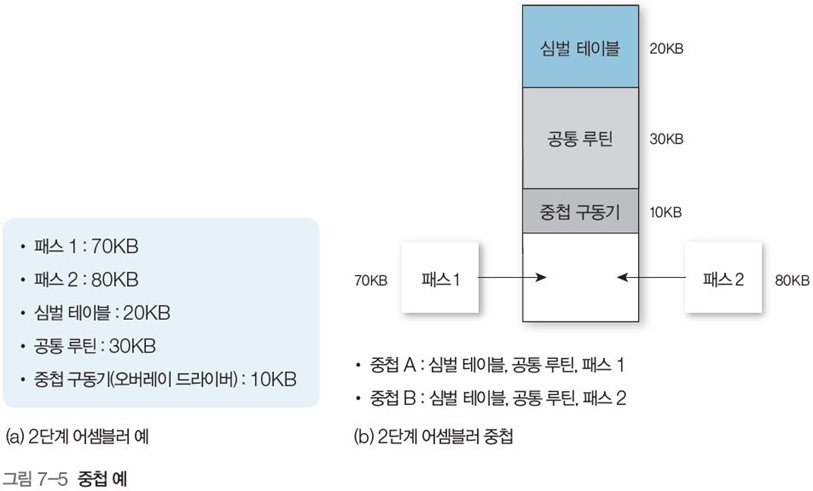
그림 7-5는 패스 1과 2가 존재하는 2패스 어셈블러 예시이다.
어셈블러 프로세스의 총 크기는 210KB, 메모리의 최대 크기는 200KB, 즉, 메모리 초과로 모두 적재가 불가능하다.
패스 1과 패스 2의 기능이 다르므로 중첩 영역으로 설정한 뒤, 교체해가며 실행 가능하다.
3.3 스와핑(프로세스 교체)
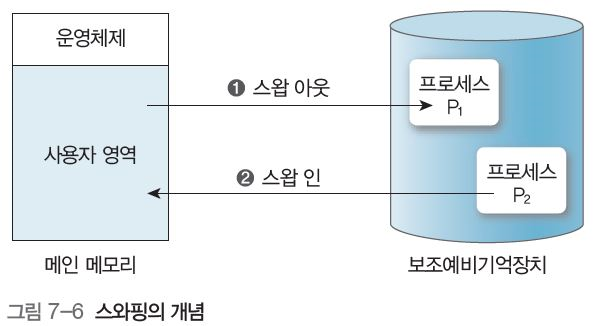
스와핑은 다중 작업과 효율적인 메모리 사용을 위해 수행이 완료된 프로세스는 보조 기억장치로 보내는 스왑 아웃, 새롭게 시작하는 프로세스는 메모리에 적재하는 스왑 인을 반복하는 것이다.(그림 7-6)
프로세스가 빈번하게 교체되는 순환 할당 알고리즘이나 우선순위 알고리즘을 사용하는 다중 프로그래밍 환경에서 사용한다.
스와핑을 통해 우선순위에 따른 프로세스 처리가 가능하며, 시스템에 유연성을 제공한다.
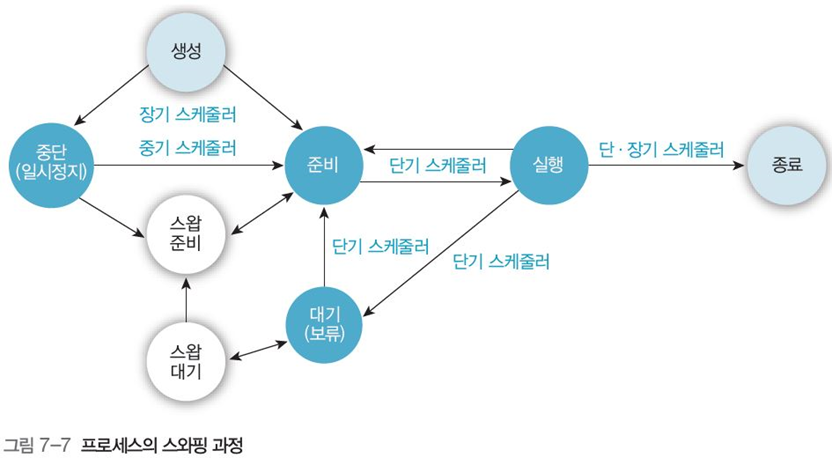
스와핑의 과정
스와핑은 주로 중기 스케줄러가 실행
준비 큐에서 대기 상태 👉 스왑 인에 의해 프로세스가 준비큐 메모리에 적재
실행 중인 프로세스가 할당 시간 종료, 작업 종료, 입출력 등에 의해 대기 상태 👉 스왑 아웃을 통해 교체된다.
이때 스왑을 위해 스왑 준비와 스왑 대기 상태를 거쳐 우선순위, 조건에 따라 스왑되게 된다. (그림 7-7)
스와핑 유의할 점
-
실행 시간 바인딩에서만 사용 가능
-
스와핑 시 생기는 주요 오버헤드로 문맥 교환시간이 존재, 프로세스가 많을 수록 커짐
-
따라서 보조 기억장치의 전송속도가 중요하다.
-
메모리를 요청하는 정보의 변화를 관리하면 효과적으로 제어 가능
-
스와핑은 프로세스가 유휴(일부 대기, 중단) 상태여야 가능
- 입출력 버퍼를 액세스 중이거나 실행 중이면 불가능 하다.
나중에 페이지로 발달하게 된다.
3.4 메모리 적재 방법
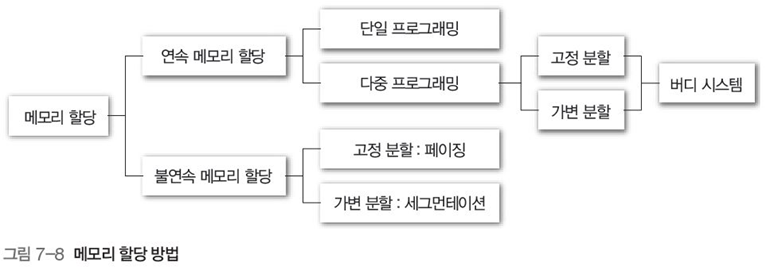
메모리 적재 방법은 그림 7-6과 같이 나뉜다.
-
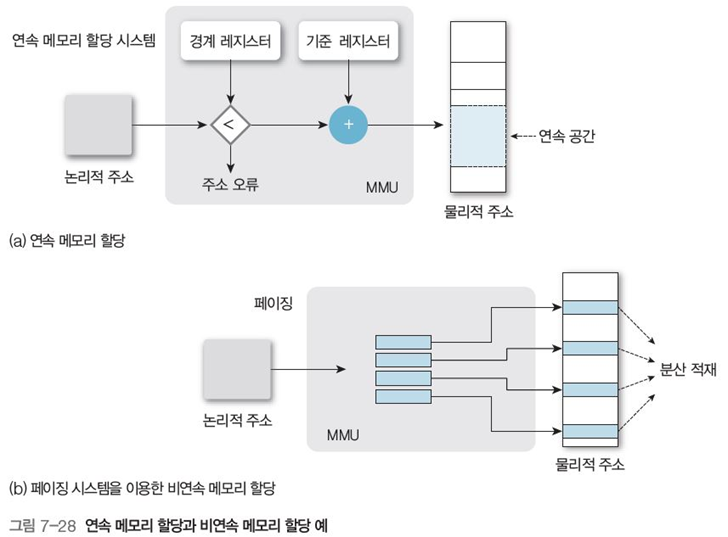
연속 메모리 할당: 프로세스의 데이터가 메모리 주소상 연속적으로 위치함
다만, 내부 단편화, 외부 단편화를 초래하며, 메모리 압축을 통해 이를 해결 시, 대신 실행 시간 낭비가 초래됨
-
고정 분할 : 크기가 각기 다른 프로세스에도 같은 크기의 메모리를 할당해 메모리 낭비 초래
-
가변 분할: 프로세스 별로 각기 다른 메모리 크기 할당
-
이외에도 직접 배치, 중첩, 버디 시스템 등이 존재
-
-
비연속(분산) 메모리 할당 : 프로세스 데이터가 페이지나 세그먼트 단위로 나눠 여러 곳에 적재, 연속 메모리 할당의 단점을 극복
-
고정 분할(페이징) : 프로그램 하나를 분할하는 기준에 따라 동일한 크기의 페이지로 나누어 적재
-
가변 분할(세그먼테이션) : 일정치 않은 크기의 세그먼트로 나누어 적재
-
02 연속 메모리 할당
1 단일 프로그래밍 환경에서 연속 메모리 할당
단일 프로그래밍 환경의 특성
-
초기 프로그래밍 환경 시스템
-
한명의 사용자만 사용 가능
-
컴퓨터 자원을 독점
-
메모리 보다 작은 크기의 프로세스만 사용 가능
-
메모리에 직접 배치 과정을 통해 항상 같은 메모리 위치에 적재
-
메모리 제어 권한을 사용자가 전적으로 가짐
연속 메모리 할당 시스템 구조
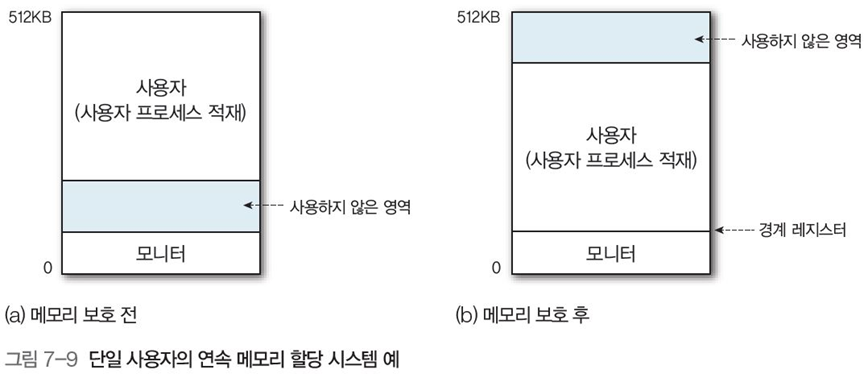
단일 프로그래밍 환경에서는 메모리를 다음과 같이 나누었다. (그림 7-9)
-
메모리 상위나 하위에 위치한 운영체제 상주 영역(모니터 영역)
- 경계 레지스터 : 사용자 영역과 모니터 영역 사이를 표시, 사용자가 임의로 운영체제 영역을 건드려 오류가 나지 않게 방지, 메모리 주소시 마다 이를 검사
-
사용자 영역
-
사용하지 않는 미사용 영역
연속 메모리 할당 시스템의 동적 적재
동적대치의 문제점과 해결 방안
문제점
만약, 운영체제의 동적 크기 변화 등의 원인으로 기준 레지스터의 값을 바꿔야 한다면, 모든 프로그램을 재적재 해야함
해결방안
-
그림 7-9의 (a) 처럼 운영체제 변화에 영향없도록 언제나 상위 부분에 프로그램 적재
- 중간의 사용하지 않는 공간을 통해 운영체제와 사용자 프로그램 확장 가능
-
이후, 기준 레지스터를 이용하여 주소 바인딩을 연기
- 이를 통해, 프로그램이 확장, 축소 되는 경우 기준 레지스터만 바꾸면 메모리 범위를 쉽게 알 수 있다.
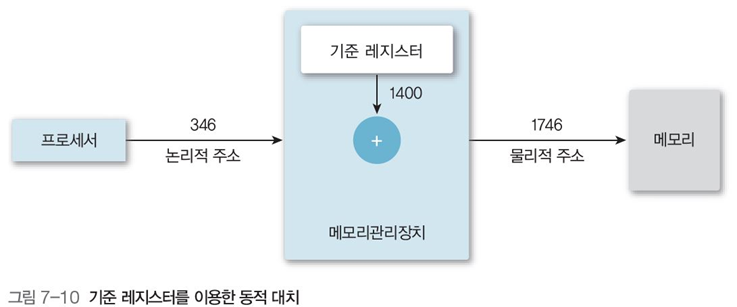
기준 레지스터를 이용한 동적 대치
기준 레지스터 : 메모리 상의 물리적 시작 주소, 프로그램의 시작 주소를 저장
경계 레지스터 : 프로그램 영역이 저장되어 있는 크기, 논리적 주소
예를 들어, 어떤 프로그램의 기준 레지스터값이 300이고, 경계 레지스터 값이 400이면, 메모리 내의 물리적 주소 300~700까지의 범위는 해당 프로그램의 범위이다.(그림 7-10)
연속 메모리 할당 시스템의 장단점
🟢 PROS: 단순하고 이해하기 쉬움
🟠 CONS
-
메모리 효율성이 떨어짐
-
한번에 하나의 프로그램만 이용 가능
-
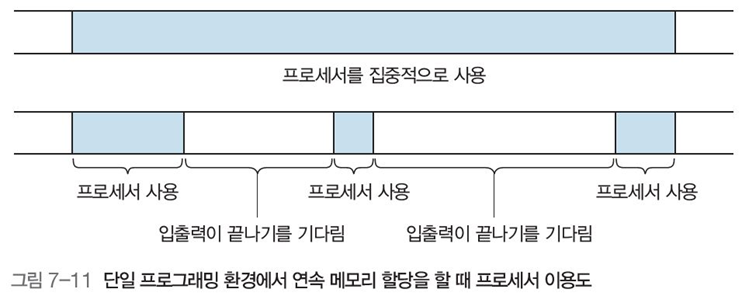
메모리보다 큰 프로그램은 스와핑을 사용해야 함
- 단, 스와핑 사용시 프로세서 중심 작업이 아니라 입출력 작업이 교대로 발생한다면, 프로세서의 유휴 상태가 자주 일어나 자원 낭비가 심하고 문맥 교환 비용이 급증(그림 7-11)
2 다중 프로그래밍 환경에서 연속 메모리 할당
여러 사용자가 여러 프로세스를 사용 가능한 다중 프로그래밍 환경에는 다음과 같이 두 방법이 사용 되었다.
2.1 고정 분할 방법
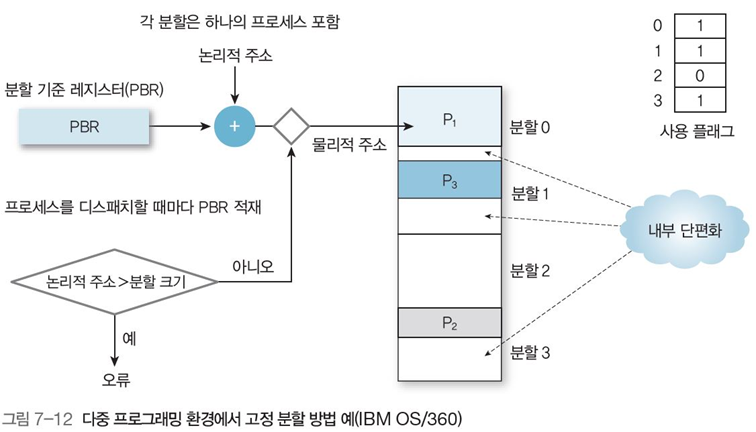
고정 분할 방법은
-
메모리를 고정된 크기의 여러 구역으로 분할
-
이후, 분할된 구역별로 프로세스를 하나씩 배정한다.
고정 분할의 물리적 주소 구하기(그림 7-12)
-
분할 기준 레지스터(PBR)에 프로세스 별로 구분된 값을 기준 레지스터로 사용 불러옴
-
논리적 주소를 더해 프로세스 별 메모리 범위 한정
즉, 프로세스 $P_1$의 메모리 범위는 $PBR_{P_1}$ ~ $PBR_{P_1}+ 경계\ 레지스터(논리적\ 주소)$까지이다.
고정 분할 방법의 문제
-
분할된 메모리의 경계보다 논리적 주소가 크면(=프로세스 크기가 고정 분할 크기보다 크면) 오류 발생
-
분할된 메모리의 경계보다 논리적 주소가 작으면(=프로세스 크기가 고정 분할 크기보다 작으면) 내부 단편화 발생
-
큐의 분할 방법과 분할 영역의 크기에 따라 성능이 크게 바뀜
-
예를 들어 그림 7-16는
Q2 준비큐는 2KB 고정 분할 주소로
Q7 준비큐는 6KB 고정 분할 주소로
Q12 준비큐는 12KB 고정 분할 주소로 할당 시,
Q2 준비큐는 가득차고, 나머지 큐는 대기하는 프로세스가 없어도
6KB와 12KB 고정 분할 주소는 사용되지 않고 낭비되게 됨. -
위 경우를 막기위해 그림 7-17처럼 하나의 큐로 만들 경우, 7KB 작업이 충분히 12KB 공간에 5KB 이하의 작업과 동시에 처리 가능함에도, 낭비가 된다.
-
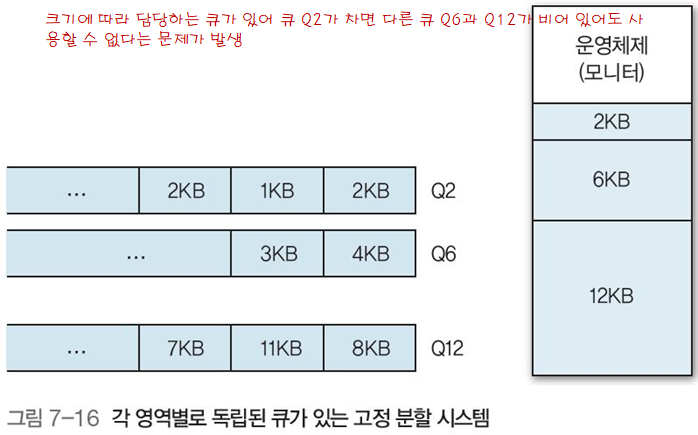

위와 같은 문제를 해결하기 위해 시스템을 분석하여
-
적절한 분할 영역의 개수와 크기를 결정
-
효율적인 작업 스케쥴링이 필요하다.
내부 단편화란?
다른 프로세스가 들어가기 너무 작아 낭비되는 메모리 공간
페이징에서는, 특정 페이지가 모종의 이유로 패이지 내 일부 공간만 활용하고 나머지 공간은 활용하지 못하고 낭비되는 공간
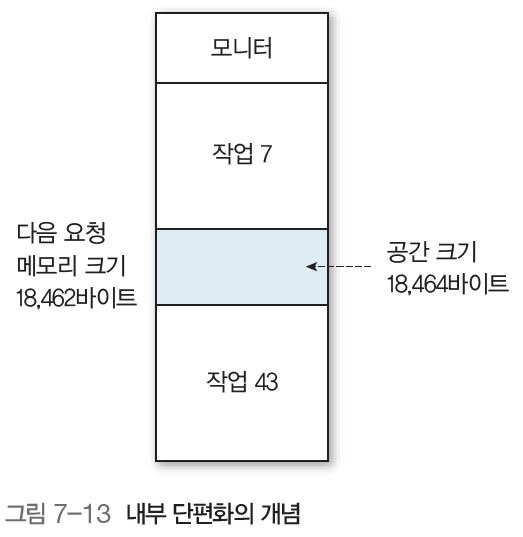
프로세스 고정 분할 크기(18,464 바이트) - 프로세스 크기 (18,462 바이트) = 2바이트 (그림 7-13)
👉 이 크기는 다른 프로세스를 넣거나 기능 확장을 하기에 너무 작은 크기며, 그냥 낭비(=내부 단편화)로 남게 됨
내부 단편화의 예시
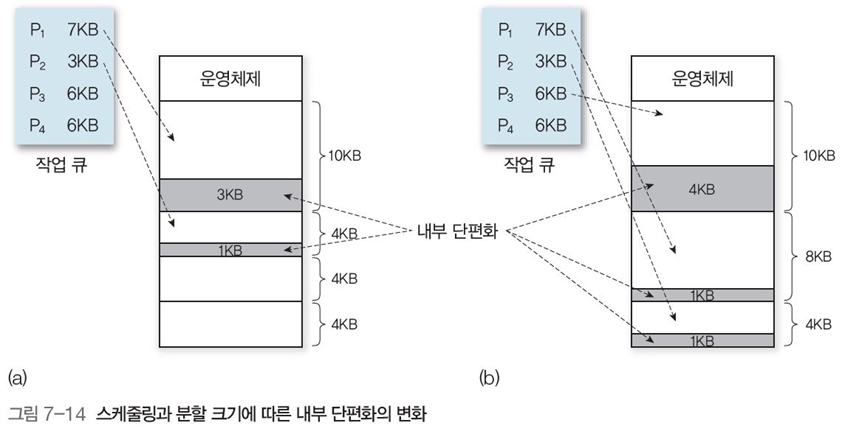
내부 단편화 비효율성에 영향을 주는 요소들
-
각기 다른 크기의 프로세스들의 스케줄링 방법
-
분할 크기
고정 분할에서의 프로세스 메모리 보호
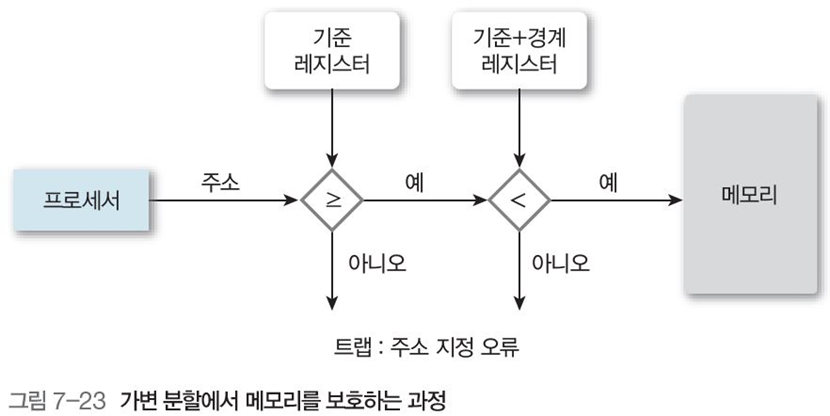
여러 프로세스가 같은 메모리에 상주하면서 다른 메모리를 침범을 막기 위해 기준 레지스터와 경계 레지스터를 사용
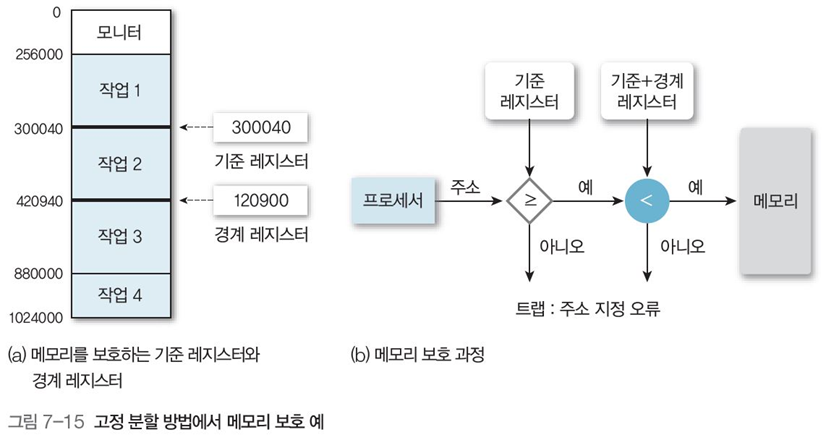
그림 7-15에서 기준 레지스터 값(물리적 시작 위치)은 300040, 경계 레지스터 값(메모리 크기)은 120900이다. (a)
이를 이용해, 그림 7-15(b)처럼 프로세서가 주소에 접근 시, 접근 주소의 크기 $S$를 다음과 같이 설정시 메모리를 보호할 수 있다.
\[기준\ 레지스터\ 값 \leq S < 기준\ 레지스터\ 값+경계\ 레지스터\ 값\]2.2 가변 분할 방법
고정된 경계를 없애고 각 프로세스가 필요한 만큼 메모리를 할당하는 것
기준 레지스터와 경계 레지스터를 이용해 분할 영역 표현
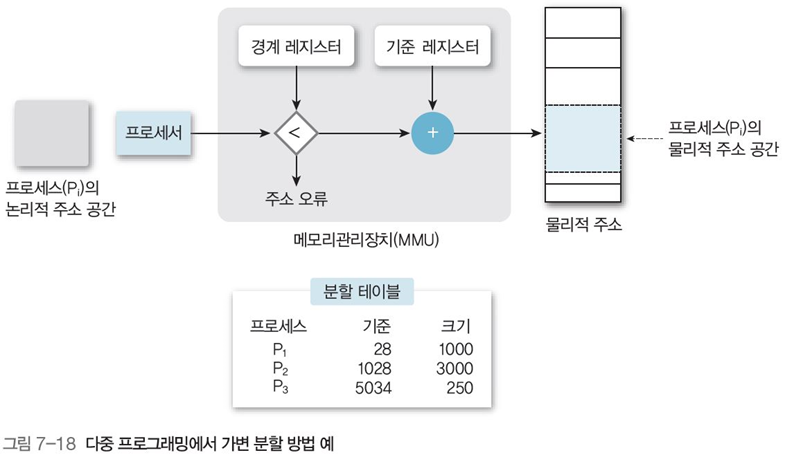
(그림 7-18)의 분할 테이블을 살펴보면, 기준은 기준 레지스터 값, 크기는 경계 레지스터 값을 의미한다.
분할 테이블을 통해 프로세스의 사용 부분을 알 수 있다.
해당 프로세스가 기준 레지스터 값보다 낮은 주소나 기준 레지스터 값 + 경계 레지스터 값 초과의 주소를 참조하려 하면 오류가 발생한다.(=이를 통해서 메모리 보호)
가변 분할의 배치 알고리즘
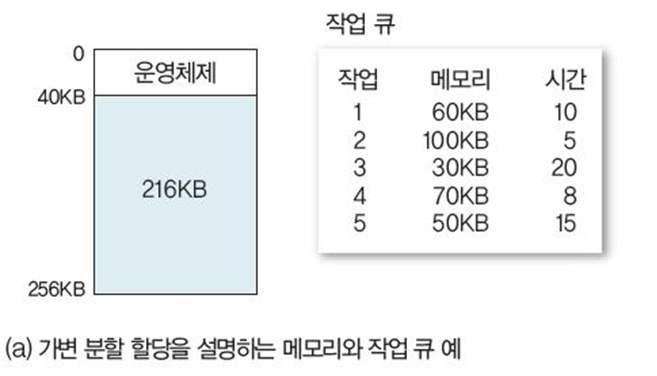

가변 분할은 그림 7-19처럼 효율적인 배치 알고리즘을 이용해 공간활용이 가능하다.
배치 알고리즘 : 비어있는 메모리 공간의 크기와 위치를 파악해 하나 이상의 특정 작업을 나누어 할당하는 알고리즘
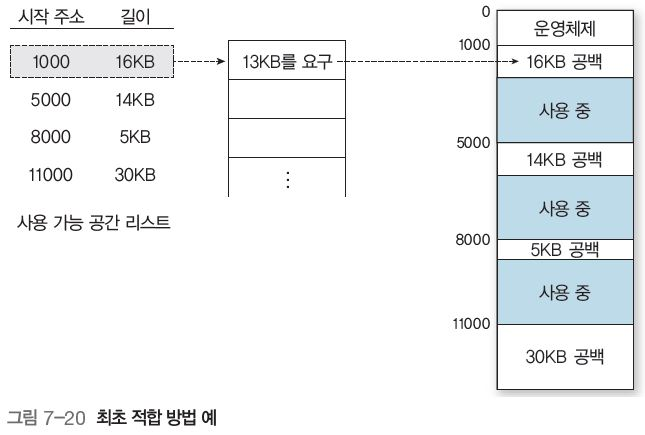
-
최초 적합(first-fit) : 사용 가능 공간 중 충분히 큰 첫번째 공간에 할당 (그림 7-20)
-
🟢 PROS : 사용 가능 공간의 첫 공간, 혹은 이전 검색의 인덱스 활용, 빨리 검색 가능
-
🟠 CONS : 공간 활용도가 크게 떨어짐
-
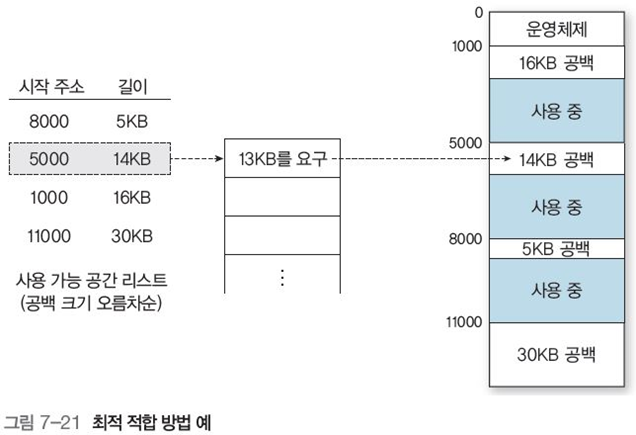
-
최적 적합(best-fit) : 프로세스를 충분히 큰 사용 가능 공간중 들어갈 수 있는 가장 작은 공간에 할당 (그림 7-21)
-
🟢 PROS : 사용 가능 공간 이용률 향상
-
🟠 CONS : 크기 순으로 사용 가능 공간을 정렬 및 관리 필요, 할당 과정에 많은 시간 소요
-
-
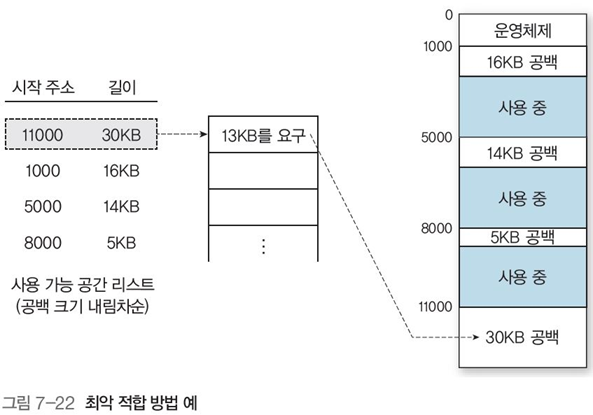
최악 접합(worst-fit) : 프로세스를 가장 큰 사용 가능 공간에 할당 (그림 7-22)
-
🟢 PROS: 새로운 사용 가능 공간이 생기므로 메모리 활용 효율이 최고, 가장 많이 사용됨
-
🟠 CONS: 크기 순으로 사용 가능 공간 정렬 및 관리 필요, 할당 과정에 많은 시간 소요
-
앞서 말했던 것처럼 기준 레지스터와 경계 레지스터를 통해 메모리를 보호하며, 디스패처는 이 값들을 이용해 적재하고, 검사한다.
외부 단편화
전체의 사용 가능 공간의 합은 충분히 다음 작업이 적재될 수 있으나 다른 프로세스 공간들 사이에 여러 작은 공간으로 단편화되어 사용할 수 없는 문제
가변 분할 방법은 내부 단편화 문제는 없으나 외부 단편화 문제가 존재한다.
이를 해결하기 위해 다음 두 가지 해결방안이 있다.
-
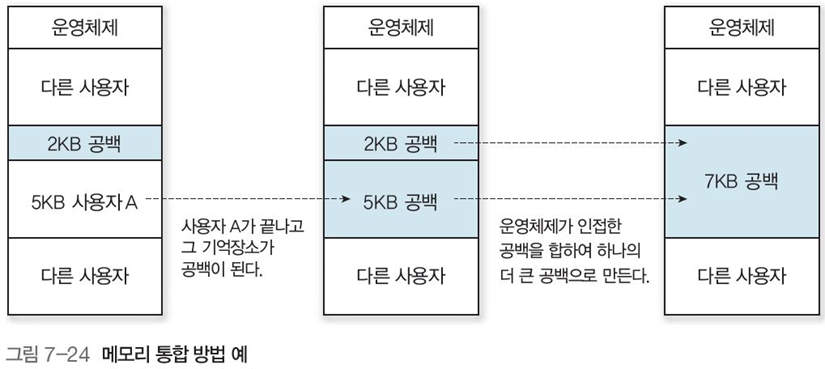
메모리 통합(coalescing) 방법
작업 종료시, 다른 빈 공간과 인접을 확인하고 하나로 합침, 일부 공간을 통합 되지 않기도 함(그림 7-24)
-
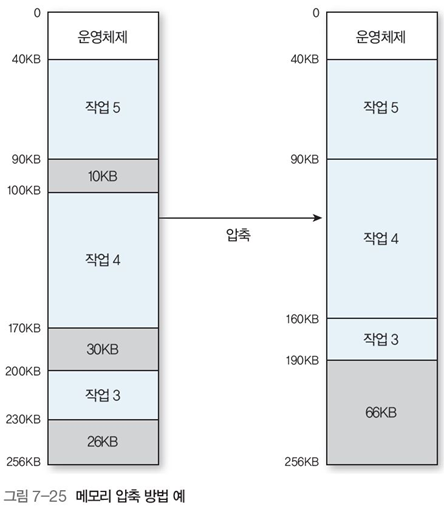
메모리 압축(compaction) 방법
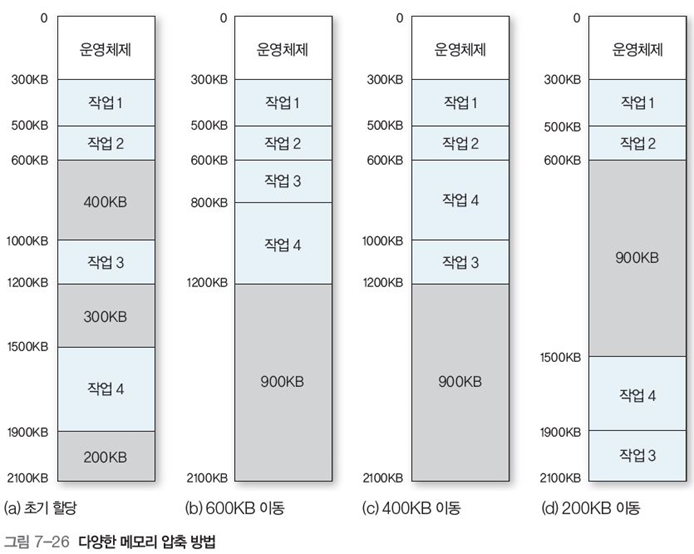
그림 7-25처럼 작업들의 메모리 적재 위치를 변경하여 하나의 커다란 공간으로 만든다.
🟢 PROS: 남김 없이 모든 흩어진 빈공간 통합, 이론상 모든 메모리 사용 가능
🟠 CONS
-
주소 대체가 정적이거나, 컴파일 중이거나 적재 중인 작업은 압축을 수행할 수 없다.
- 즉 동적 대체, 작업이 실행 상태일 때, 중단시켜야일때만 가능하다.
-
추가로, 압축동안 전체 시스템이 모든 일을 중지해야하며, 이때 대화형 사용자는 응답시간이 일정치않고, 실시간 시스템은 멈추게 된다.
-
메모리의 작업들의 정보를 일시적으로 액세스 가능한 형태로 보관 후, 복구 해야함.
-
압축 작업을 자주 요구하며, 시스템 자원의 소모가 큼
-
메모리 테이블을 유지해야 압축이 가능하므로, 오버헤드가 발생하며, 외부 단편화 조각들이 작을 수록 비효율적이다.
- 예를 들어 고작 1byte 크기의 외부 단편화를 해결하기 위해 작업을 옮기는 것은 비효율적이다.
-
그림 7-26 처럼 같은 압축 방법에 따라 효율이 달라진다.
-
3 다중 프로그래밍 환경의 버디 시스템(buddy system)
버디 시스템은 고정, 동적 분할의 단편화 문제를 해결하기 위해 제안되었다.
큰 버퍼들을 반복적으로 이등분하여 작은 버퍼들을 만들며, 가능할 때마다 인접한 빈 버퍼들을 합치는 방식으로 동작한다.
버퍼를 나눌 때 각각 분할을 서로의 버디라고 한다.
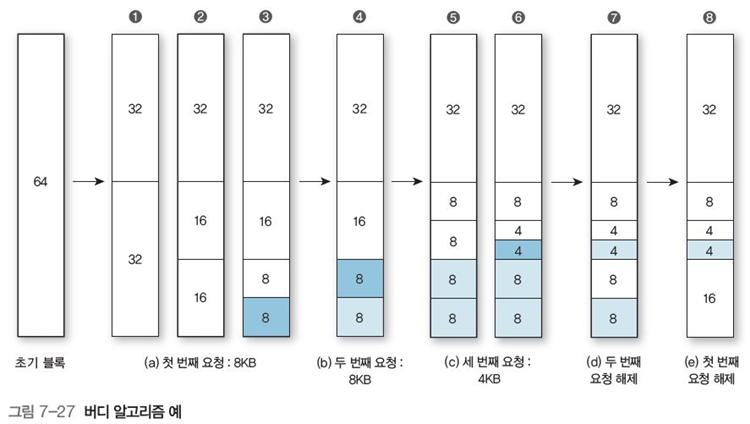
그림 7-27처럼 예시를 들자면 만약 (a) 경우처럼 최소 크기 버디보다 요청한 메모리(8KB)가 더 작다면 들어갈 수 있는 크기내에 최소한 작게 이등분으로 나눈 뒤 할당한다.
이후 (e)처럼 요청이 해제될 때 다시 합치면 된다.
고정 분할이나 가변 분할 방법의 단점을 해결했지만, 최근에는 페이징이나 세그먼테이션 가상 메모리를 이용하며, 유닉스의 커널 메모리 할당이나 병럴 처리 시스템에서 주로 사용한다.
03 분산 메모리 할당 1: 페이징
프로세스를 크기가 동일한 페이지들로 나누고, 메인 메모리도 (페이지) 프레임이라는 고정 크기 블록으로 나눠 프레임에 페이지를 적재하는 방법
동적 대치의 한 형태이며, 논리적 주소를 페이징 시스템을 이용해 물리적 주소로 변환한다.
1 페이징의 개념
페이징에서는 그림 7-28 (a)와 달리 같은 프로세스의 내용이라고 해도 (b) 처럼 여러 위치에 같은 크기의 페이지로 분산 적재된다.
따라서 페이징을 이용하는 프로그램은 다음 작업이 필요하다
-
프로세스에 필요한 페이지를 결정해 페이지 번호 부여
-
메모리의 빈 프레임을 조사해 프로세스를 적재할 위치를 파악
-
프로세스의 페이지를 빈 프레임에 적재하도록 준비
🟢 PROS
-
빈 프레임에는 어떤 페이지든 적재 가능, 메모리 효율적
-
프레임 간 외부 단편화 없음
-
시분할 환경에서 중요한 공통 코드 공유 가능(공유 페이지)
-
압축 기능 제거
🟠 CONS
-
분산 적재된 페이지들의 관리 부담
- 특히 메모리에 페이지들의 정보가 담긴 페이지 테이블을 따로 준비해야한다.
-
언제나 마지막 페이지에 할당된 프레임이 차지않아 내부 단편화가 발생
-
페이지 크기가 100이고, 프로세스 크기가 101이면, 페이지 1개는 99가 낭비됨
-
페이지 크기가 작아지면 작아질수록 내부 단편화 정도가 약해지지만, 대신 페이지 관리 부담 증가
-
-
하드웨어 비용 증가
-
연속 적재에 비해 속도 저하
2 페이징 시스템의 하드웨어 구조와 원리
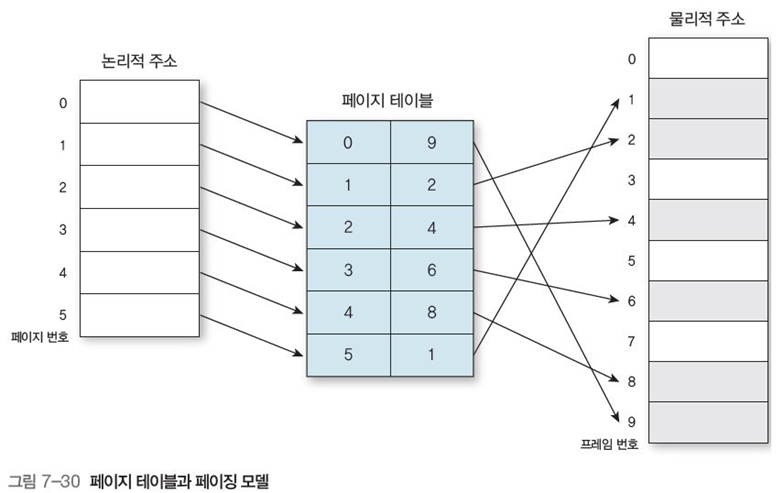
페이징 시스템의 하드웨어 구조는 그림 7-29와 같다.
페이지의 물리적 주소 구하기
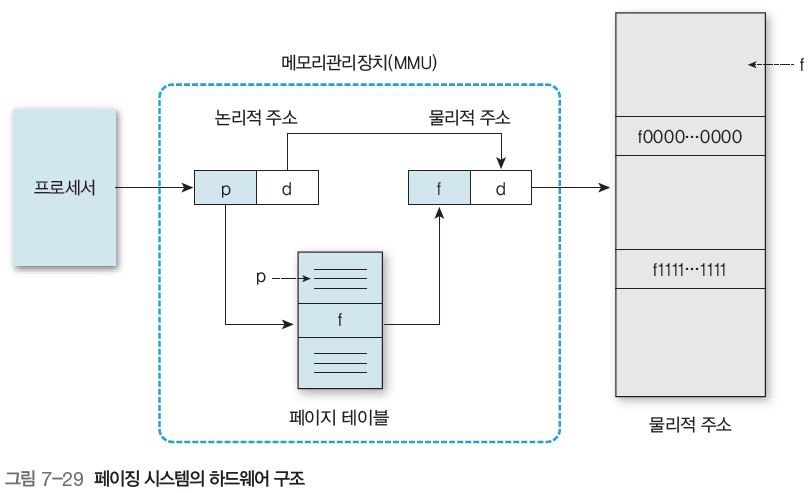
프로세스의 논리적 주소는 페이지 번호 p와 오프셋(변위) d로 구성
-
논리적 주소의 페이지 번호 p를 페이지 테이블에서 찾아본다.
-
페이지 테이블에서 페이지 기준 주소이자 메인 메모리 프레임 번호인 f를 얻는다.
- 페이지 테이블은 별도의 레지스터 혹은 메인 메모리에 배치되며, 프로세스 당 하나씩 관리해야 한다.
-
논리적 주소의 오프셋 d를 기준 주소 f와 더하면(f+d) 메인 메모리의 물리적 주소가 된다.
- 이때 오프셋 d 크기가 페이지 프레임 크기보다 작아야 한다.
페이지와 논리적 주소의 구조
페이지의 크기는 보통 하드웨어에 따라 다르며, 512Byte ~ 1GB 사이이며, 2의 배수만큼의 크기이다.
논리적 주소를 페이지 번호와 오프셋으로 쉽게 변환할 수 있기 때문이다.
아래의 논리적 주소의 설명에 따라서 오프셋의 크기의 최대값은 이진법 표기로 2의 계승 - 1이므로, 임의의 수보다 비교하기 쉽다.
논리적 주소의 구조
논리적 주소의 상위 n 비트는 페이지 번호, 나머지 하위 비트들은 오프셋을 나타낸다.
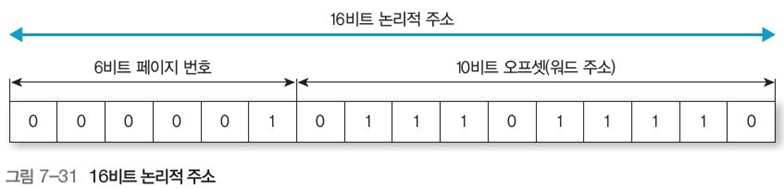
예를 들어 그림 7-31의 16비트 논리적 주소는 6비트의 페이지 번호와 나머지 10비트의 오프셋으로 이루어져있으므로, 페이지는 최대 64개로 이루어져 있고, 페이지 크기는 최대 1024bit(=1KB)이다.
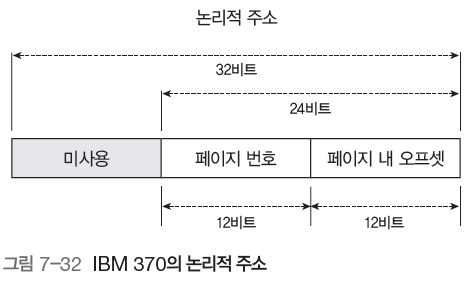
그림 7-32는 IBM 370의 32비트 논리적 주소로, 앞의 8비트는 사용되지 않는다.
2의 계승을 유지하면서, 가능한 페이지 번호나 오프셋이 너무 크면 생기는 문제를 막기 위함
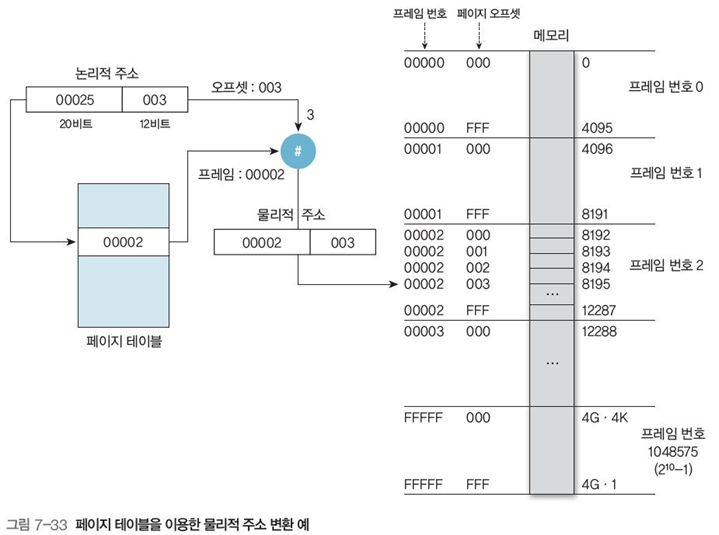
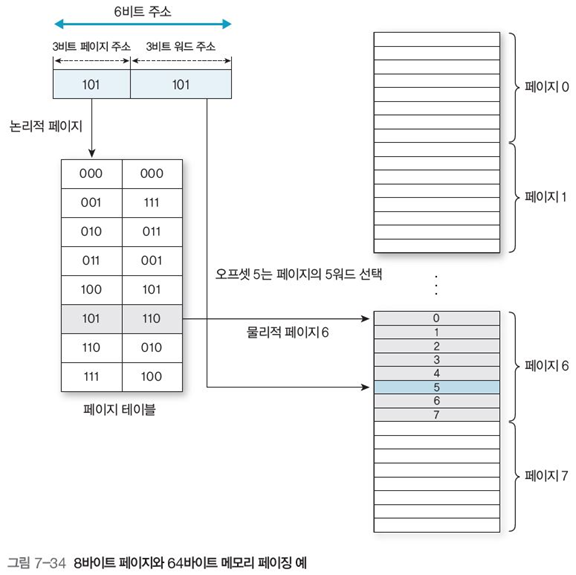
그림 7-33과 7-34는 메모리 페이지의 예시이다.
3 다중 단계 페이징 시스템의 구조와 원리
기존 페이징 시스템의 문제점
논리적 주소가 크면 관리해야할 페이지 테이블 크기가 증가하며, 이는 곧 더 큰 메모리 사용량 오버헤드로 이어진다.
자세하게 예를 들어보자
-
32비트 프로세서의 메모리는 $2^{32}$인 4GB가량까지 지원
-
페이지 크기 : 4KB(=$2^{12}=4096$)로 가정
-
총 페이지의 수는 $4GB/4KB=1,048,576$개
-
페이지 하나당 관리를 위한 페이지 테이블의 항목이 하나 필요
-
페이지 테이블 하나당 4Byte이므로, 페이지 테이블 하나는 4MB이다.
-
프로세스 별로 페이지 테이블이 하나씩 필요
-
프로세스가 100개만 되도 (보통 백그라운드 프로세스가 많다.), 400MB가 낭비, 이는 4GB의 1/10 수준
- 심지어 10KB짜리 작은 프로세스를 위해서 4MB의 페이지 테이블을 유지해야 한다.
다중 단계 페이징 시스템을 이용한 해결
다중 단계 페이징 시스템
- 실제 참조할 페이지가 있는 영역에서만 단계별 페이지 테이블을 설정하는 페이징 시스템
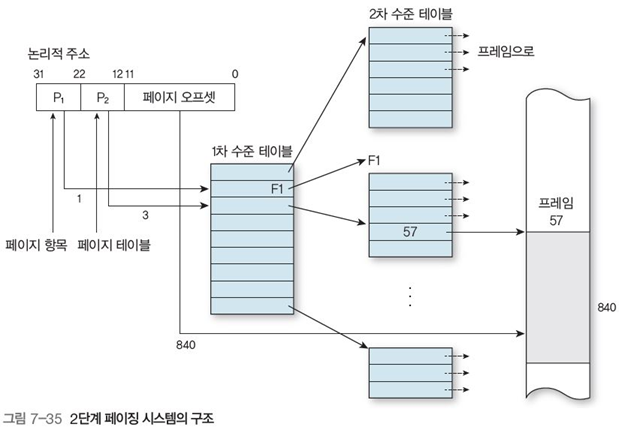
기존의 페이지 주소와 오프셋으로 구성되는 논리적 주소를 페이지 항목, 페이지 테이블, 페이지 오프셋으로 구성되게 함(그림 7-35)
-
페이지 항목은 1차 수준 테이블에서 2차 수준 테이블의 주소를 찾는데 사용
- 1차 수준 테이블은 2차 수준 테이블들의 물리적 주소(디렉토리)들이 적혀있다.
-
페이지 테이블은 2차 수준 테이블에서 페이지의 주소를 찾는데 사용
- 2차 수준 테이블은 페이지들의 주소들이 적혀있으며, 해당 디렉토리에 데이터가 있는 경우에만 생성된다.
-
페이지 오프셋은 기존의 오프셋과 동일
다중 페이징 시스템에서의 페이지 테이블 메모리 계산
-
페이지 항목과 페이지 테이블이 각각 10비트
-
페이지 항목이 10비트이므로 1차 수준 테이블의 전체 항목수는 $2^{10}=1024$
-
1차 수준 테이블 한 항목의 크기는 4Byte, 즉 1차 수준 테이블의 전체 크기는 4KB
-
페이지 테이블이 10 비트, 2차 수준 테이블 또한 마찬가지로 전체 항목 수 $2^{10}=1024$
-
2차 수준 테이블의 한 항목 의 크기는 4Byte, 즉 2차 수준 테이블의 전체 크기 또한 4KB
-
2차 수준 테이블은 해당 1차 수준 테이블에서 지정한 주소(디렉토리)에 데이터가 존재하는 경우에만 생성
-
2차 수준 테이블의 수를 넉넉하게 200개라고 하자. (최대 1024개 가능)
-
페이지 하나 크기가 4KB라고 가정하면,
\[200(2차\ 수준\ 테이블\ 수) \times \\1024(2차\ 수준\ 테이블\ 최대\ 크기)\times4Kbyte=800MB\]800MB 크기의 엄청난 크기의 프로세스(창을 18개 정도 열어놓은 구글 크롬 브라우저 수준?)이다.
-
-
페이징 시스템에 필요한 $4+4 \times 200=804KB$로 기존의 4MB에 비해 1/5 수준으로 유지
- 만약 10mb 수준의 간단한 프로세스(백그라운드 실행중인 메신저 프로그램 수준) = 2차 수준 테이블 수는 3~4개 = 대략 16kb(기존 4mb에 비해 1/20 이하)
추가적으로 다중 단계 페이징에서는 페이지가 연속적으로 배치되어 있지 않아도 된다.
4 페이지 테이블의 구현
페이지 테이블은 아래 그림처럼 구성되어 있다.
프로세스 하나에는 페이지 테이블이 하나씩 존재한다.
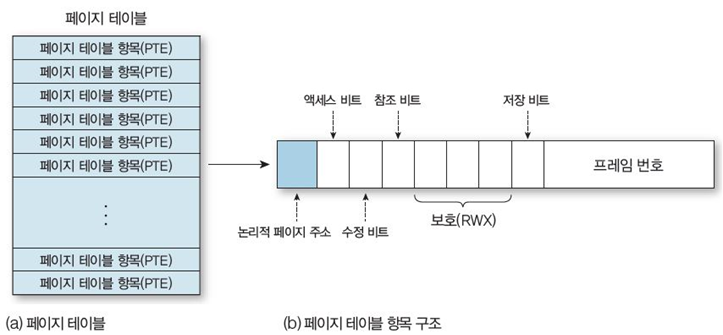
-
액세스 비트 : 메모리 액세스 여부 표시
-
수정 비트 : 메모리에 적재한 이후 수정했는지 여부
-
참조 비트 : 액세스 여부
-
보호(RWX) : 읽기, 쓰기, 실행 권한
-
저장 비트 : 참조 페이지의 메모리 저장 여부
-
프레임 번호 : 메인 메모리에서 페이지 프레임 번호
페이지 테이블 기준 레지스터(PTBR, Page Table Base Register)
-
페이지 테이블는 계산 및 입출력이 빠른 전용 레지스터에 저장하는 것이 이상적
-
하지만 대게 페이지 테이블의 크기가 커서 적합하지 않음. 👉 따라서 페이지 테이블은 메모리에 두고 이를 관리하기 위한 페이지 테이블 기준 레지스터(PTBR, Page Table Base Register)를 이용
-
문맥 교환 시 실제로 메모리 정보를 모두 교환하는 것보다, 레지스터의 값을 서로 바꾸는 편이 경제적
하지만 이 방법에서 특정 주소에 액세스 하려면 메모리 접근이 필요하고, 이는 속도를 느리게 한다.
- 구체적인 예를 들자면, 임의의 주소 i에 접근하려면 i의 페이지 번호와 PTBR 기준 주소 값을 찾아서 이 둘을 결합한 프레임 번호를 제공해야 한다. 이때, 페이지 번호 접근에 메모리 접근이 필요함
👉 이 단점을 해결하기 위해 연관 레지스터나 변호나 우선 참조 버퍼(TLB, Translation Look-aside Buffer, 8장 참조)를 이용한다.
연관 레지스터를 이용하는 방법은 다음 세가지로 나뉜다.
-
직접 매핑(direct mapping) 주소 변환
-
연관 매핑(associative mapping) 주소 변환
-
연관 직접 매핑을 결합한 주소 변환
4.1 직접 매핑(direct mapping)으로 주소 변환
메모리나 캐시에 프로세스 메모리를 구성하는 모든 페이지 항목이 존재하는 페이지 테이블을 유지하며, 이를 PTBR의 값과 페이지 번호를 통해 물리적 주소를 구하는 방식이다.
🟢 레지스터만 변경해도 페이지 테이블을 변경 가능
🟠 사용자 메모리 위치에 액세스하는 데 시간이 걸림
-
주소 p에 액세스 하기 위해 페이지 테이블에서 한번($p’$값 읽기), 해당 주소 p의 값(워드, 원하는 값)를 읽기 위해 한번 총 2번의 메모리 액세스가 필요해서 2배로 시간이 걸림
-
이를 해결하기 위해, 연관 레지스터 또는 보조예비 기억장치라고 하는 하드웨어 메모리 사용
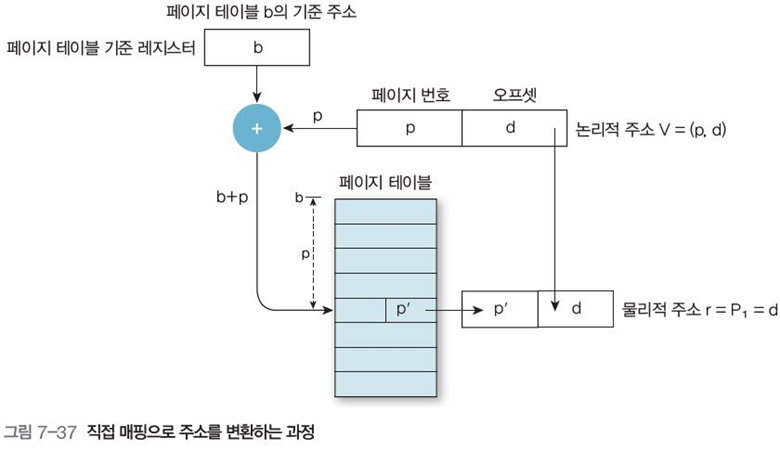
그림 7-37의 예시를 들자면, 논리적 주소 V = (p, d)일 때,
-
페이지 테이블 기준 레지스터에 프로세스 페이지 테이블의 메모리 주소 b를 적재한다.
-
페이지 테이블 시작 주소 b에 참조 페이지 번호 p를 더함
-
b+p 주소를 통해 페이지 번호 p에 존재하는 프레임 $p’$를 얻는다.
-
$p’$에 오프셋 d 값을 더해 물리적 주소 $p’+d$를 얻는다.
4.2 연관 매핑(associative mapping)으로 주소 변환
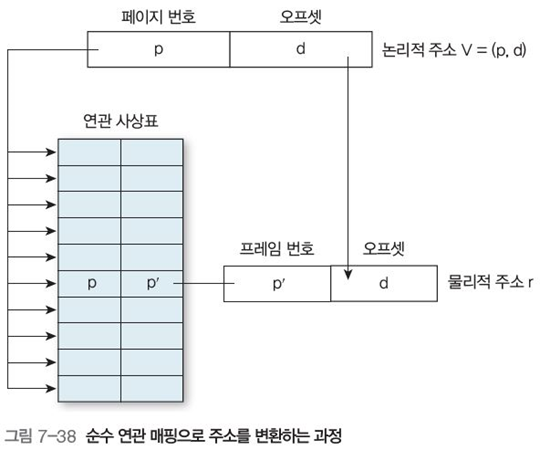
논리적 주소를 프로세스의 페이지 번호와 프로세스에 대응하는 프레임 번호가 있는 연관 레지스터의 집합으로 표현하고, 페이지 번호를 모든 키값과 동시 비교하여 프레임 번호를 얻어내는 방식
각 레지스터는 키와 값으로 구성되며, 연관 레지스터에 항목을 추가할 수 있다.
🟢 매우 빠르게 검색 가능, PTBR 불필요
🟠 모든 항목을 동시 비교하는 하드웨어가 비쌈, 보통 일부 연관 레지스터만 구축함
4.3 연관 직접 매핑을 결합한 주소 변환
앞선 두 방법을 혼용하는 방법, 최근에 사용한 페이지는 연관 레지스터에, 연관 레지스터에 없는 페이지는 직접 매핑 하는 방법이다.
프로세스가 메모리의 정보를 균일하게 액세스하는 것이 아니라,
-
많이 참조하는 정보
-
방금 참조하는 정보(시간 지역성)
-
방금 참조한 정보의 주변 메모리에 존재하는 정보(공간 지역성)
이상을 자주 참조하는 경향이 있으며 이를 지역성(locality)이라고 한다.
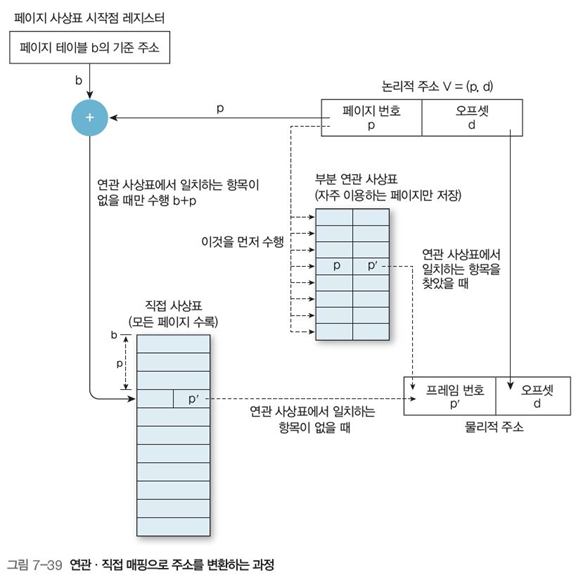
그림 7-39로 구체적인 예를 들자면, 논리적 주소가 V=(p, d)일 때,
-
먼저 페이지 번호 p를 부분 연관 사상표에서 모든 항목을 동시에 조사해 페이지 번호 p를 찾는다.
1-1. 존재한다면, 프레임 번호 p’를 찾아 오프셋 d를 더해 물리적 주소 p’+d를 얻는다.
-
만약 부분연관 사상표에 존재하지 않는다면, PTBR의 페이지 테이블 주소와 페이지 번호 p를 합쳐 페이지 테이블 번호 b+p를 찾는다.
-
직접 사상표(페이지 테이블)에서 프레임 번호 p’를 얻어 물리적 주소 p’+d를 얻는다.
과정 1에서 부분 연관 사상표(연관 레지스터)에서 페이지 번호를 발견하는 비율을 적중률이라고 한다.

연관 레지스터 탐색이 50나노초, 메모리 접근이 750 나노초 걸린다고 할때, 과정 1-1(적중 성공 시), 800나노초가 걸린다.
만약 과정 2(적중 실패 시)에는 페이지 테이블 액세스 (b), 프레임 번호 액세스(p’), 총 2번 액세스 해야하므로 50+ 750+750=1550나노초가 소요된다.
이를 유효 접근 시간을 적중률 80%에 대입해 계산하면 그림 7-40-1처럼, 적중률 90%에 대입해 계산하면 그림 7-40-2처럼 계산된다.
5 공유 페이지
페이징 시스템에서는 프로세스를 메모리에 연속적으로 할당할 필요가 없기 때문에 여러 프로세스가 일부 페이지를 공유할 수 있다.
공유를 위해서 각 프로세스는 메모리의 같은 페이지(지역)을 가리키게 해야하며, 재진입을 허용하므로 재진입 코드(reentrant code) 혹은 순수 코드(pure code)라고도 한다.
동시에 접근이 가능하게 하기 위해 수정이 불가능한 읽기 전용이며, 주로 공유 라이브러리 코드 등에 사용됨
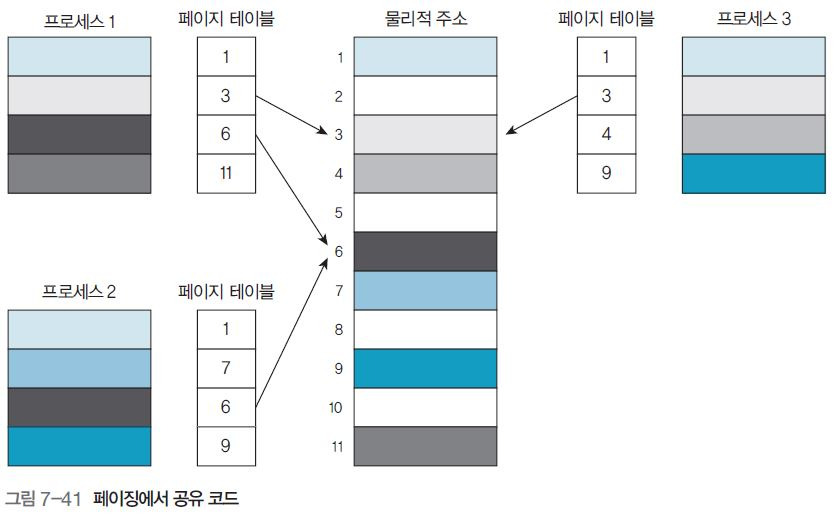
공유 페이지는 스레드가 텍스트와 메모리를 공유하는 방법과 비슷한데, 모든 프로세스에서 논리적 주소 공간의 동일한 위치(논리적 주소)는 동일한 물리적 주소로 매핑된다.
예를 들면, 그림 7-41 에서
-
물리적 주소 3번 위치는 프로세스 1과 프로세스 3이 공유 (공유 페이지 3)
-
물리적 주소 6번 위치는 프로세스 1과 프로세스 2가 공유 (공유 페이지 6)
-
프로세스 1과 프로세스 3에서 공유 페이지 3번은 페이지 테이블 2번 위치에 동일하게 존재해야 한다.
-
프로세스 1와 프로세스 2에서 공유 페이지 6번은 페이지 테이블 3번 위치에 동일하게 존재해야 한다.
이렇게 설계한 이유는 공유페이지를 다른 프로세스가 공유하려면 프로그래밍 시, 공통 코드로 접근하는 코드가 접근하는 위치가 모두 같아야 하기 때문이다.
-
만약, 동일한 공유페이지를 접근하는 코드를 가지고 있는 두 프로세스 A, B가 있다면,
-
A 프로세스의 공유 페이지 접근 코드는
get_share_from_3() -
B 프로세스의 공유 페이지 접근 코드는
get_share_from_2() -
위 두 코드의 결과는 같아야 하므로, 공유 페이지의 내용은 물리적 주소의 2번과 3번에 동일하게 존재해야할 것이다. (=같은 데이터가 메모리 내에 2개, 즉 공유가 아님)
-
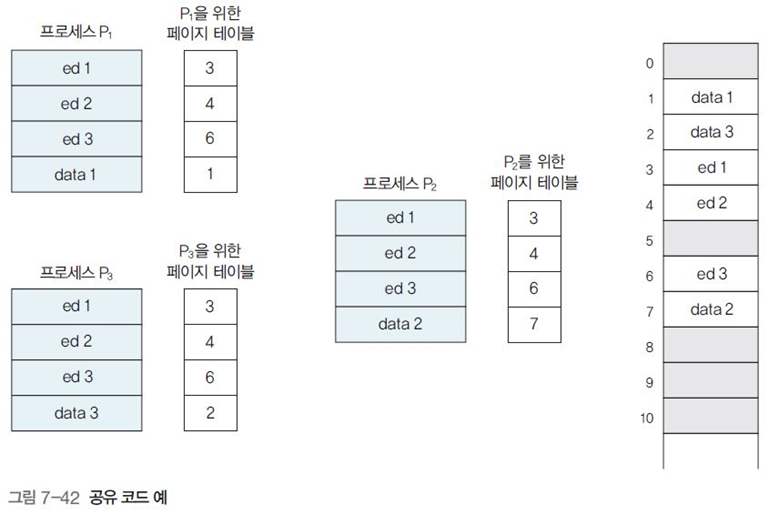
그림 7-42처럼 각 프로세스가 ed1~ed3를 공유한다면 이를 공유 페이지로 만들고 data 1~3만 메모리에 적재하면 되므로, 이용 메모리가 크게 줄어든다.
페이지 공유는 주로 컴파일러, 윈도우 시스템, 데이터베이스 시스템 등에 사용된다.
6 페이징에서 보호
프로세스 하나가 다른 프로세스의 데이터 영역을 무단으로 읽거나 쓰게 하면 안되므로, 페이지 별로 액세스 권한을 다르게 부여할 수 있다.
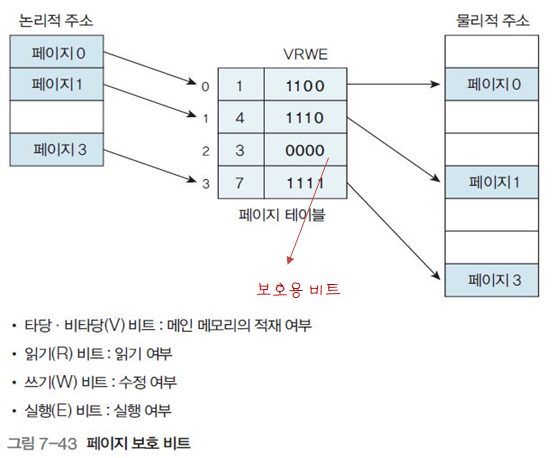
그림 7-43에서 각 페이지 테이블 항목에 보호 비트를 추가해 페이지 보호를 할 수 있다.
보통 1의 경우 접근 가능, 0의 경우 접근 불가능이다.
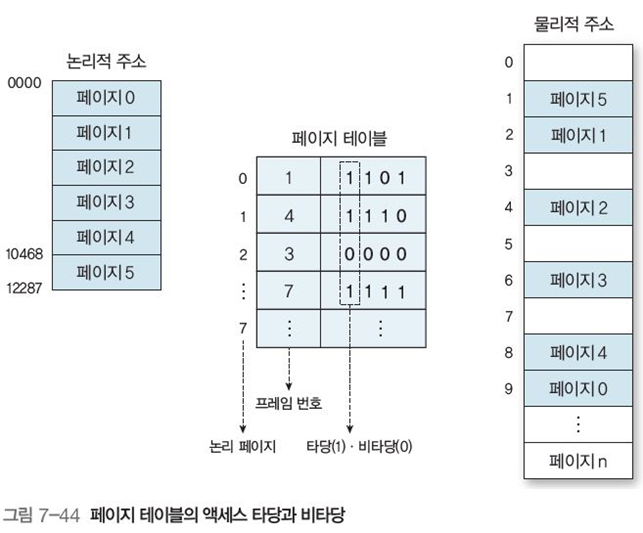
그림 7-44는 불법적인 시도를 막는 과정이다.
04 분산 메모리 할당 2 : 세그먼테이션(segmentation)
1 세그먼테이션의 개념
메모리의 사용자 관점을 지원하는 비연속 메모리 할당 방법으로, 논리적 영역을 세그먼트의 집합으로 인식한다. 즉 세그먼테이션은 그림 7-45 처럼 프로세스 관점에서 페이징과 달리 크기가 다양한 세그먼트로 메모리를 나눈다.
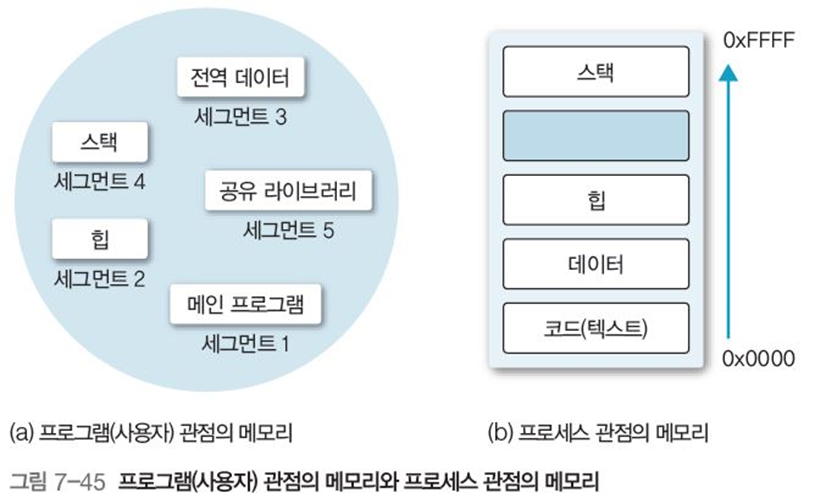
각 세그먼트는 컴파일러가 원시 프로그램을 실행 프로그램으로 변환하면서 프로그램을 구성하는 서브루틴, 프로시저, 함수나 모듈 단위로 구성함.
즉, 세그먼트는 연관된 기능을 수행하는 하나의 모듈 단위가 많으며, 세그먼트는 연속된 위치에 구성하되 서로 인접할 필요는 없다.
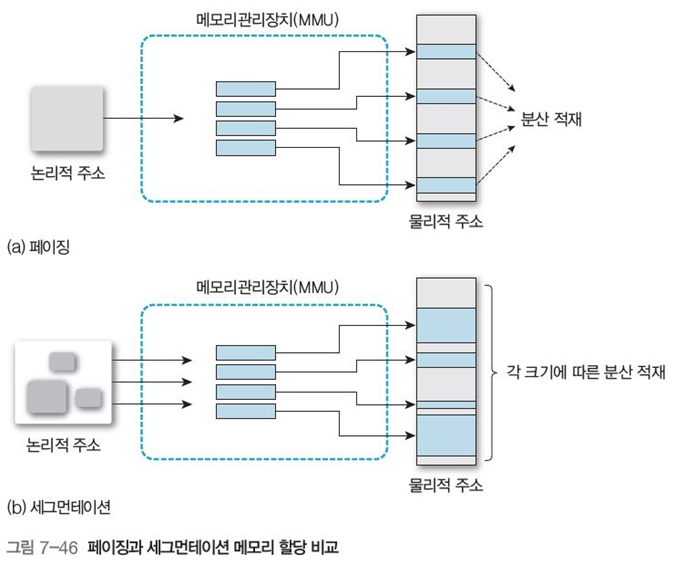
그림 7-46은 일정한 크기의 페이지로 나누는 페이징과 가변 분할이 가능한 세그먼테이션의 비교이다.
하드웨어 보호나 관리 또한 페이징과 비슷하거나 동일
2 세그먼테이션에서 하드웨어 구조와 원리

그림 7-47은 프로세서로 생성한 세그먼트의 논리적 주소로, IBM 370 예처럼 세그먼트 번호 s와 오프셋 d로 구성
세그먼트 번호는 8비트이므로 총 256개가 가능하며, 각 세그먼트는 64KB가 최대 크기이다.
페이징과 마찬가지로 각 프로세스는 고유의 세그먼트 테이블을 메모리에 유지.
세그먼트 테이블의 항목은
-
세그먼트가 적재될 메모리의 시작 주소(세그먼트 기준)
-
잘못된 주소 방지를 위한 세그먼트 길이(세그먼트 경계)이다.
추가로 세그먼트 테이블을 위한 레지스터가 둘이 존재한다.
-
세그먼트 테이블 기준 레지스터(STBR)
-
세그먼트 테이블 길이 레지스터(STLR)
세그먼트 테이블은 각 세그먼트 경계와 기준 항목을 가지고 메모리 주소의 시작과 세그먼트의 끝을 나타내느 기준과 경계 레지스터의 쌍들로 구성된 배열이다.
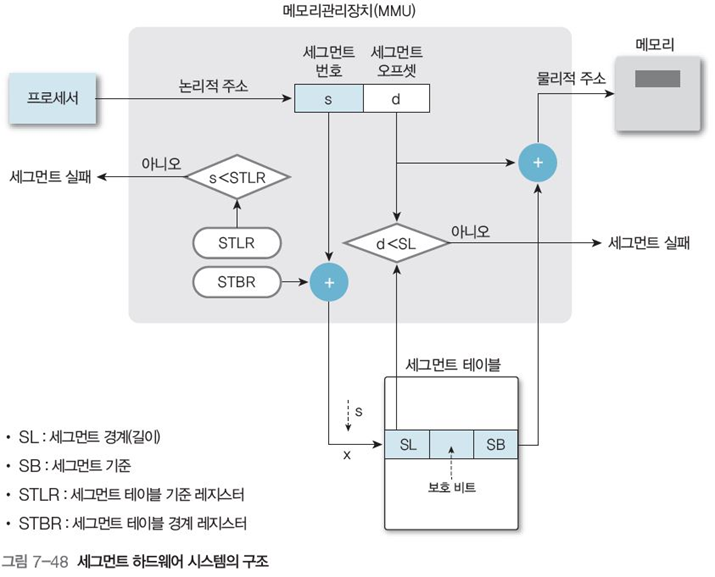
세그먼트 테이블 레지스터는 주로 위의 논리적 시작 주소를 검사하는데 사용한다.
그림 7-48의 예시를 보자면,
-
접근하려는 세그먼트 번호 s를 세그먼트 길이 레지스터(STLR)과 비교
1-1. 만약 실패한 경우 (0 > s || s > STLR), 오류 발생
-
이하일 경우 (0<= s < STLR), s + STLR을 이용해 세그먼트 테이블 주소 산출
-
세그먼트 테이블에서 보호 비트를 확인해 접근 가능한지 확인
-
세그먼트 테이블에서 세그먼트 경계(SL)과 세그먼트 기준(SB) 값을 읽는다.
-
접근하려는 세그먼트 주소 오프셋 d가 세그먼트 경계(SL)과 비교
3-1. 만약 실패한 경우 (0 > d || d > SL), 세그먼트 실패
-
이하일 경우 (0<= d < SL), SB + d를 통해 원하는 워드 주소에 접근
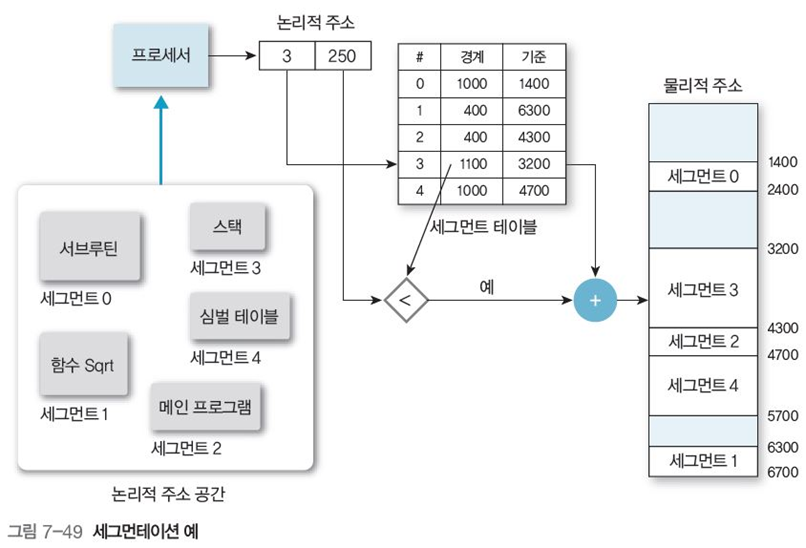
세그먼테이션도 일련의 과정이 페이징과 비슷하며, 메모리 액세스 과정으로 인해 속도가 매우 느리다.
3 세그먼트 공유
세그먼트 공유는 페이징 시스템과 달리 페이지 테이블의 공유 항목을 표시 할 필요 없이 해당 항목을 공유로 선언하면 된다. 즉, 다른 프로세스에서 동일한 메모리 주소를 지정해 접근하면 된다.
추가로 공유를 위한 보호체계와 사용자 승인을 통과하면 액세스 할 수 있다.
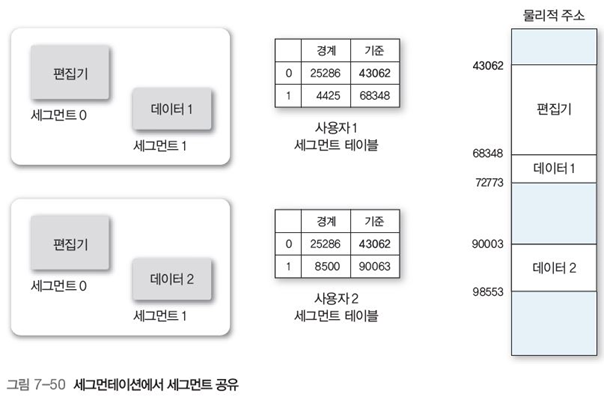
그림 7-50은 세그먼테이션에서 세그먼트를 세그먼트 테이블 주소를 동일하게 표시하여 공유하는 예시이다.
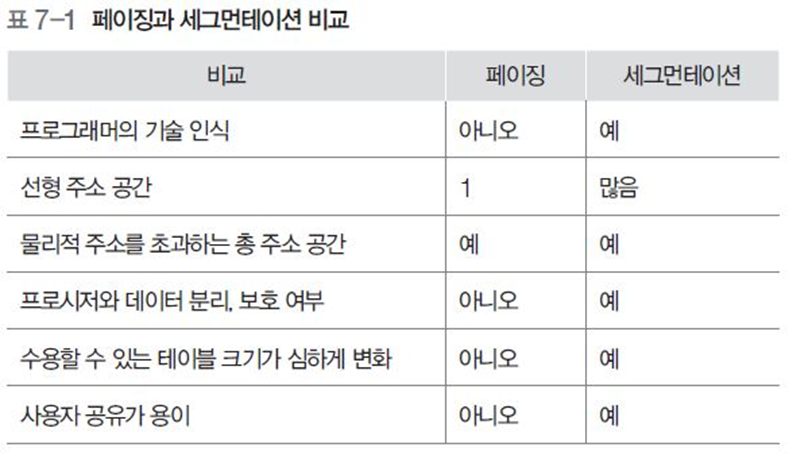
4 페이징과 세그먼테이션 비교
공통점
- 프로그램을 나눈 세그먼트나 페이징에서 메모리의 빈 공간을 찾아 할당
차이점
-
페이징과 달리 프로그램을 나누는 크기가 변함.
-
세그먼테이션은 최적, 최초 적합 알고리즘 같은 동적 메모리 할당 방법을 이용
-
따라서 세그먼테이션은 외부 단편화 발생 가능
- 압축, 대기, 프로세스 큐에서 충분히 작은 프로세스 찾기, 세그먼트 크기 줄이기 등으로 해결
-
페이징은 크기가 일정하므로 물리적 주소 없이도 큰 가상 주소 공간이 가능
-
세그먼트는 프로그램과 데이터를 논리적으로 독립된 주소 공간으로 나누고 쉽게 공유,보호 할 수 있음
5 페이지화된 세그먼테이션
페이지화된 세그먼테이션은
페이지의
-
내부 단편화 발생
-
메모리의 효율적 사용
-
작업 크기 동일에 의한 다양한 알고리즘
세그먼테이션의
-
외부 단편화 발생
-
가변적인 데이터 구조와 모듈 처리
-
공유와 보호의 지원 편리
특성을 합친 시스템이다. 즉, 외부 단편화 문제와 할당 과정의 어려움을 해결했다.
멀틱스 시스템과 인텔 386 계열에서 사용했다.
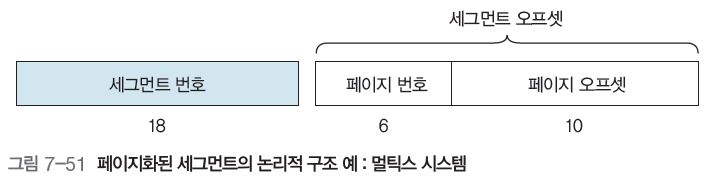
멀틱스 시스템의 논리적 주소는 그림 7-51 처럼 총 32 비트이며,
-
18 비트의 세그먼트 번호
-
16비트의 세그먼트 오프셋 : 페이지 크기보다 작으면, 해당 세그먼트는 페이지가 하나
-
6비트의 페이지 번호 : 프레임 번호 제공을 위한 페이지 테이블 인덱스
-
10비트의 페이지 오프셋 : 페이지 테이블 내의 위 페이지 번호 주소에서 구할 수 있는 프레임 번호와 더해서 페이지 주소 찾음
-
으로 구성되어 있다.
엄밀히 말하면 멀틱스의 18비트의 세그먼트 번호는 너무 커서 추가로 세그먼트테이블을 페이징했다.
8비트 페이지 번호와 10비트 오프셋으로 분할해 세그먼트 페이지의 물리적 주소를 색인해야 한다.
이를 통해, 논리적 주소를 세그먼트들로 나누고, 이 세그먼트를 고정된 페이지들로 나눌 수 있다.
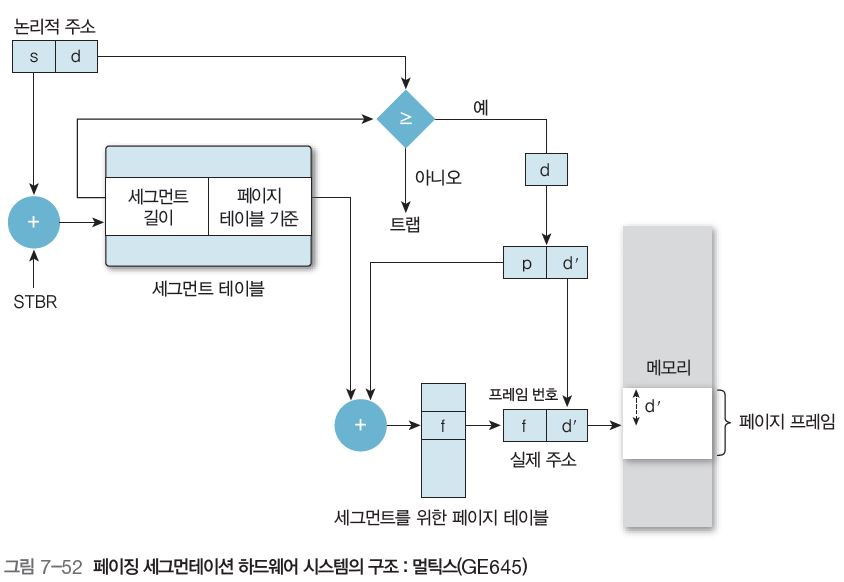
페이지화 세그먼트의 주소 변환 과정
그림 7-52는 페이징 세그먼테이션의 주소 변환 과정이다. 초기의 논리적 구조는 {s, d}로 시작되며, 또 d는 {p, d’}로 나눌 수 있다.
-
프로세서는 논리적 주소의 세그먼트 번호(s)와 세그먼트 테이블 기준 레지스터(STBR)를 이용해(s+STBR) 세그먼트 테이블 확인
-
세그먼트 오프셋을 세그먼트 길이와 비교하여 (d <= 세그먼트 길이) 오류를 확인한다.
-
오프셋(d)을 나누어 세그먼트 페이지 테이블을 찾기 위한 논리적 주소({p, d’})로 만든다.
-
해당 세그먼트 페이지 테이블에서 페이지 번호(페이지 테이블 기준 + p)를 찾아 이에 대응하는 페이지 프레임(f)을 찾기
-
페이지 프레임(f)을 오프셋(d’)과 결합해(f+d’) 메모리 주소 생성
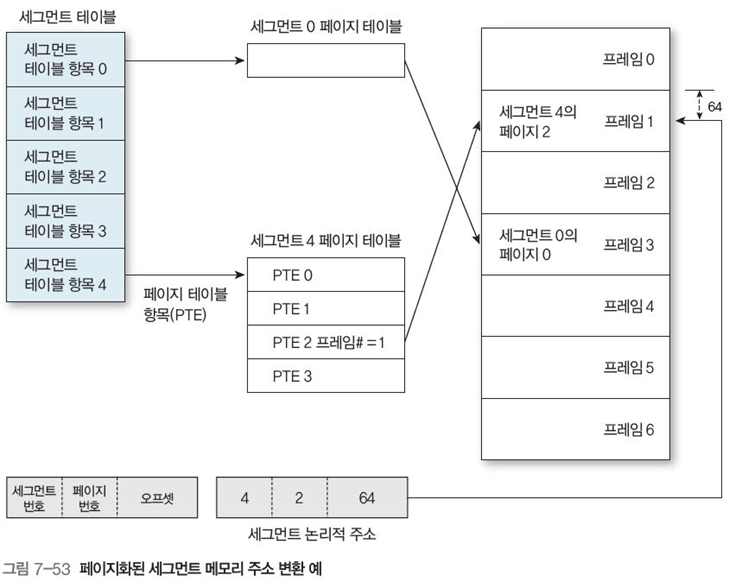
그림 7-53은 위의 주소변환 과정을 논리적 주소 4, 2, 64를 변환하는 과정이다.
세그먼트 4 테이블의 페이지 번호 2에서 프레임 번호 1을 찾은 뒤, 이를 페이지 오프셋 64를 이용해 프레임 1로 매핑한다.

각 프로세스는 세그먼트 테이블과 세그먼트 테이블 시작 주소를 가진 레지스터가 있음
각 세그먼트는 자신의 페이지 테이블이 있다.
각 세그먼트의 마지막 페이지는 내부 단편화 존재, 외부 단편화는 없음.
복잡하지만 할당 과정을 쉽게 해결했다.
그림 7-2는 이를 정리한 장단점 표이다.
_articles/computer_science/OS/IT_COOK_BOOK_OS_정리/OS 정리-Chap 7-메모리 관리.md