풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
OS 정리-Chap 10-파일 관리
10. 파일 관리
IT COOK BOOK 운영체제 (개정 3판, 구현회 저, 한빛 아카데미) 를 정리한 내용입니다.
01 파일 시스템과 파일
1 파일 시스템의 개념
정보를 저장하는 논리적인 관점과 저장장치의 물리적인 특성을 고려해 논리적 저장 단위인 파일을 정의하고 메모리에 매핑시키는 운영체제 기능
- 데이터를 실제로 저장하는 파일
- 이를 계층적으로 연결하고 파일의 위치와 속성을 기술하는 디렉터리
로 이루어짐.
2 파일 시스템의 기능
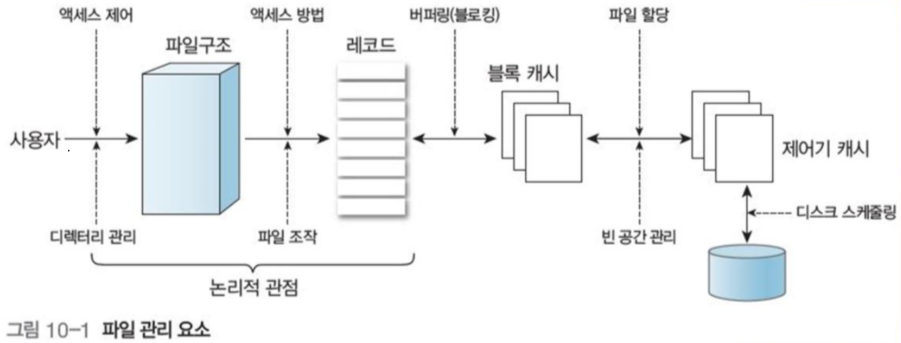
- 파일 구성 : 사용자가 각 응용 업무에 적합하게 파일 구성
- 파일 관리 : 파일 생성, 수정, 저장, 참조, 제거, 보호, 파일 공유 및 다양한 액세스 제어 방법 제공
- 보조 메모리 관리 : 다양한 형태의 저장 장치 지원
- 파일 무결성 보장 : 파일에 저장된 정보 손상 방지
- 파일 액세스 방법 제공 : 기본 연산(파일 생성, 기록, 판독, 삭제) 기능을 활용한 구조(순차, 인덱스)에 따른 다양한 액세스 방법(순차, 직접, 인덱스 등) 제공
- 장치 독립성 유지 : 물리적 장치 별 기호화된 이름으로 장치와 독립성 유지
- 파일 백업과 복구 : 정보 손실 및 고의 손상에 대비해 데이터 사본 생성 및 복구 기능 제공
- 파일 보호 : 정보 암호화 및 해독 기능 제공
- 정보 전송 : 파일 간 정보 전송 명령
- 편리한 인터페이스 제공
종합적으로 다양한 형태의 저장장치에 입출력을 지원하는 것, 데이터 보호 및 처리율 향상과 성능 향상이 목적이다
3 파일 시스템의 구조
파일 시스템은 크게 두가지로 구분할 수 있다.
- 논리적 파일 : 파일의 개념, 속성, 디렉토리 구조, 파일에 허용하는 연산 등을 정의하는 논리적 파일
- 디스크에 이런 논리 파일 시스템을 매핑하는 부분
계층으로 나누자면 아래와 같으며, 각 계층은 낮은 계층의 서비스를 사용한다.
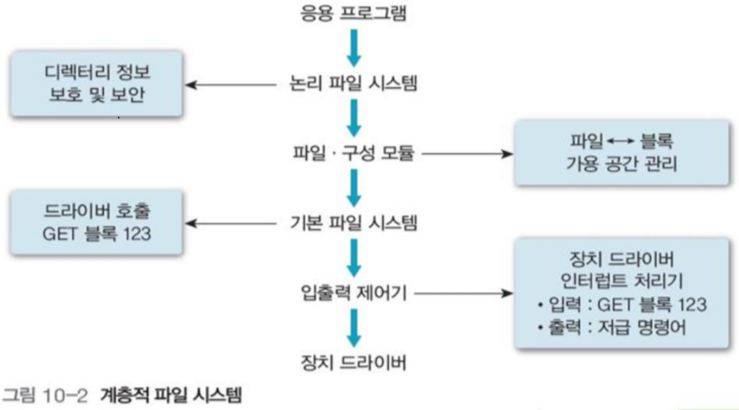
-
장치 드라이버 : 운영 체제의 일부 기능으로, 장치와 통신하여 입출력 연산 및 요구 등을 수행, 논리적 블록을 물리적 블록 주소로 변환
-
입출력 제어기 : 장치 드라이버 루틴과 인터럽트 처리기로 구성, 명령어를 해석해 메모리와 디스크 시스템 간에 정보 전송
-
기본 파일 시스템 : 물리적 블록을 읽거나 쓰려고 장치 드라이버를 호출, 데이터 블록 처리
-
파일 구성 모듈 : 디스크 빈 공간 파악, 파일의 논리 블록 주소를 물리 블록 주소로 변환
-
논리 파일 시스템 : 보호 및 보안 관련 기능, 파일 이름과 디렉터리 등 정보를 이용한 레코드 처리 기능 제공
4 파일 시스템의 관리
4.1 블록
메모리와 디스크 간의 전송 단위이며, 파일은 블록 하나 이상으로 이루어져 있고, 블록은 섹터 하나 이상으로 구성된다.
논리 블록 번호는 입출력 제어기의 명령으로 장치 드라이버에서 물리적 디스크 주소로 변환된다.
물리적 디스크 주소는 트랙, 실린더, 표면, 섹터 등으로 구성되어 있다.
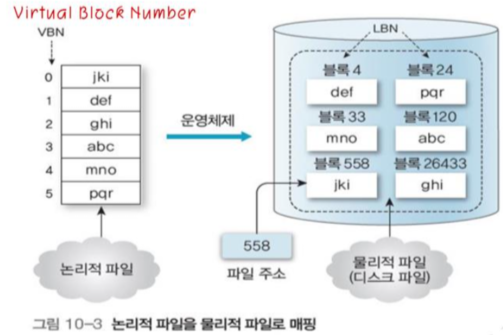
그림 10-3은 논리적 파일인 가상 블록 번호(VPN, Virtual Block Number)가 물리적 파일인 논리 블록 번호(LBN, Logical Block Number)로 매핑시키는 과정이다.
4.2 메타 데이터(Metadata)
파일 시스템은 메타 데이터를 저장한다.
메타 데이터의 예시는 다음과 같다.
- 파일 시스템 크기
- 저장 장치의 빈 공간 정보(비트맵, 가용 블록, 불량 섹터 등)
- 루트 데이터 위치와 파일 소유자
- 파일 크기, 마지막 수정 시간
유닉스 시스템은 메타 데이터를 디렉토리에 데이터 파일로 저장하며, 기본 저장 장치인 i 노드를 이용한다.
보통 사용자가 직접 수정하지 않고 파일 시스템의 무결성을 유지한다.
4.3 마운팅(mount)
새로운 장치의 파일 시스템에 접근하기 위해 기존의 파일 시스템의 디렉토리에 설치하는 과정
운영체제에 마운트하려는 파일 시스템의 저장위치에게 새로운 파일 시스템의 설치 지점인 마운트 포인트를 제공하여 이루어진다.
이후, 마운트 테이블을 통해 마운트된 디렉토리들을 관리한다.
마운트되면, 기존의 디렉토리 처럼 자유롭게 액세스가 가능하다.
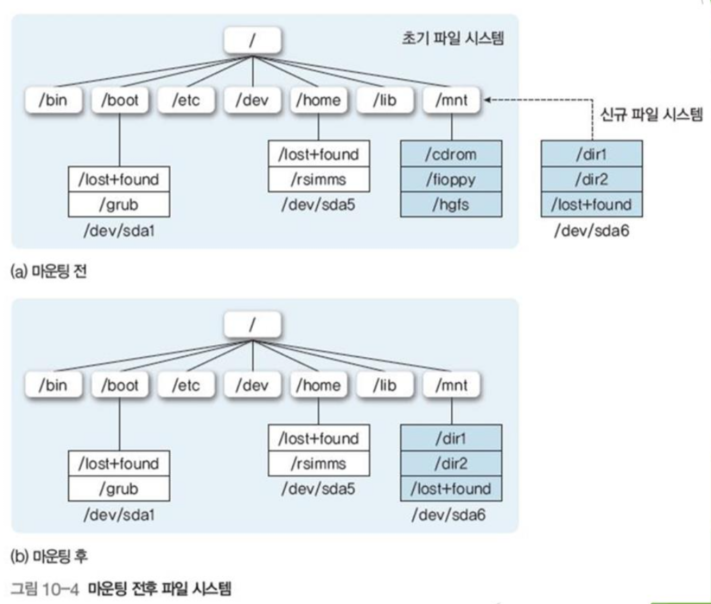
그림 10-4의 경우, \dev\sda6가 \mnt에 마운트 되는 과정이다.
다만, 마운트포인트에 존재하던 \cdrom 등의 기존 디렉토리는 언마운트 될때까지 사용 불가능하다.
윈도우의 경우, C 드라이브와 D 드라이브가 예시이다.
5 파일의 개념과 구성
- 보조 저장 장치에 기록된 프로그램과 데이터 등 정보의 모음
- 파일 제작자와 사용자가 정의한 비트, 바이트, 레코드의 집합
- 사용 목적과 기능에 따라 구조와 형식이 다양하다.
운영체제에 의해서 필드, 레코드, 블록 등으로 매핑된다.
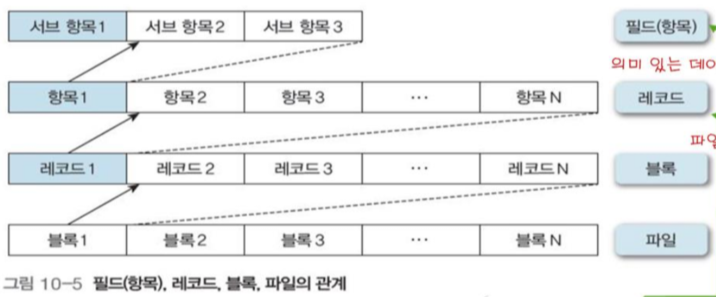
-
필드(항목)
레코드를 구성하는 바이트의 모임, 의미있는 데이터의 가장 작은 단위.
고정 길이나 가변 길이로 정해진다. -
레코드
파일을 구성하는 요소, 레코드가 모여 블록을 형성하기도 한다.
마찬가지로 고정 길이와 가변 길이가 존재하며, 고정 길이 레코드는 크기에 따라 문자열이 잘리거나 저장 공간이 낭비되는 단점이 있고, 가변 길이 레코드는 레코드의 액세스가 힘들다는 단점이 있다.
6 파일의 이름 명명
파일명은 같은 디렉토리 내에선 유일해야 한다.
루트 디렉토리에서 해당 파일까지의 경로를 절대경로라고 한다.
만약 절대경로가 너무 길면, 현재 폴더 위치에서의 상대경로를 이용할 수 있다.
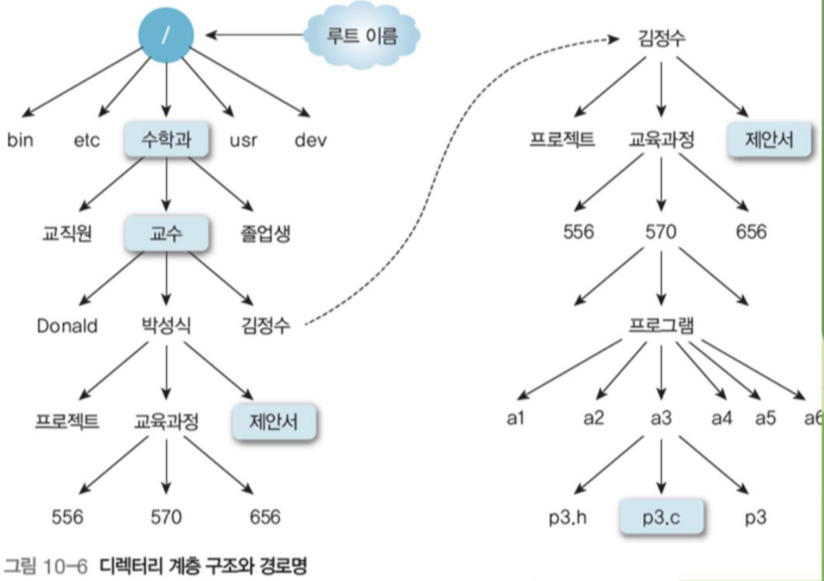
예를 들어 그림 10-6의 p3.c의 절대 경로는 \수학과\교수\김정수\교육과정\570\프로그램\a3\p3.c이며, 현재 위치가 수학과일 때 상대 경로는 \교수\김정수\교육과정\570\프로그램\a3\p3.c이다.
7 파일의 속성
파일 속성이란 시스템이 파일을 관리하는데 필요한 정보를 의미한다.
파일 속성은 운영체제가 파일 관리에 사용하며, 메인 메모리에 유지하여 파일을 열 때 탐색 시간을 줄인다.
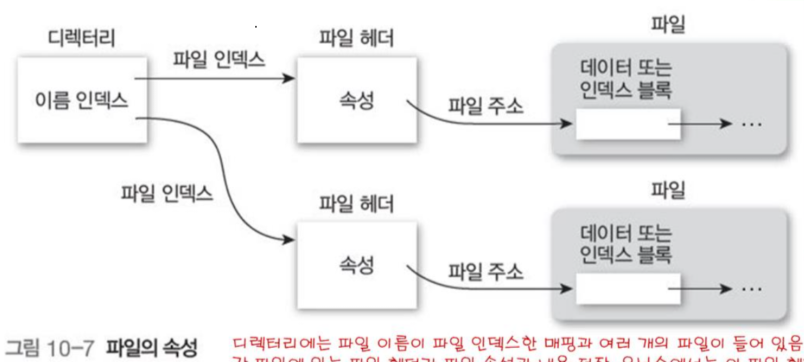
- 파일 이름: 사용자들이 이해할 수 있는 형태
- 파일 식별자: 각 파일에 할당한 고유 번호, 사용자가 보통 판독 불가
- 파일 유형: 다양한 파일 형식을 지원
- 저장 위치: 장치와 장치 내의 위치를 표시하는 포인터
- 파일 크기: 파일의 현재 크기, 허용 가능한 최대 크기 포함
- 액세스 제어 데이터 : 파일 읽기, 쓰기, 실행 등 권한 정보
- 소유자 : 파일을 최초로 생성한 사용자
- 레코드 크기 : 고정된 크기나 최대 크기 등 레코드 종류에 따라 다름
- 시간, 날짜, 사용자 식별 정보 : 생성 시간, 수정 변경 시간, 최근 사용 시간 등으로 파일을 보호, 보안, 감시
디렉토리 내의 각 파일은 파일 속성과 내용이 담긴 파일헤더를 가진다. 유닉스에서는 이를 i 노드라고 부른다.
8 파일의 유형
파일 시스템은 지원 가능한 파일 구조와 해당 구조에서만의 특별한 연산을 제공한다.
예를 들어 텍스트 파일은 프린트 가능하지만, 실행 파일은 불가능 한 대신 실행 가능하다.
다음은 파일의 유형들이다.
-
일반(정규) 파일
텍스트나 이진 형태의 파일, 텍스트는 아스키 형식으로 사용자가 읽거나 인쇄할 수 있는 정보이며, 이진 파일은 컴퓨터로 읽을 수 있는 정규파일로, 작업을 수행하려는 시스템에 지시하는 실행 파일이다. -
디렉터리 파일
모든 유형의 파일에 액세스할 수 있는 정보를 포함하며, 실제 본인의 데이터는 포함하지 않음. 파일이나 하위 디렉터리를 가지고 있다. -
특수 파일
시스템 장치를 정의하거나 프로세스로 생성한 임시 파일로 파이프라고도 하며, 일시적으로 다른 프로세스와 통신하기 위해 생성된다.
운영체제는 파일의 구조를 엄격히 따지지 않고 응용 프로그램이나 사용자가 적절히 해석하고 운용해야 한다.
보통은 파일 이름 뒤에 마침표 (ex) .txt)를 이용해 파일명과 확장자를 구분한다.
| 파일 유형 | 확장자 | 기능 |
|---|---|---|
| 실행 가능 | exe, com, bin 등 | 이진 수행 기능 프로그램 |
| 소스 코드 | c,p,pas,f77,asm,a | 다양한 언어로 된 소스코드 |
| 배치 | bat, sh | 명령어 해석기에서 명령 |
| 문서 | txt, doc | 텍스트 데이터, 서류 |
| 워드 프로세서 | wod,doc,hwp | 다양한 워드 프로세서 형식 |
| 라이브러리 | lib,a,DLL | 프로그래머들이 사용하는 라이브러리 루틴 |
| 백업, 보관 | arc, zip, tar | 관련된 파일을 하나로 묶거나 압축해서 보관 |
9 파일의 연산
-
파일 생성 : 파일 시스템에 있는 공간을 찾는다. => 새로 생성한 파일 항목을 디렉터리에 만들어 파일 이름과 파일 시스템 내의 위치를 기록
-
파일 열기 : 먼저 프로세스를 열고, 메인 메모리에 디스크 주소 속성과 리스트를 가져와 시스템 호출을 빠르게 한다.
-
파일 쓰기 : 파일을 기록하려고 파일 이름과 파일에 기록할 정보를 표시하는 시스템 호출을 수행.
-
파일 위치 재설정: 현재의 파일 위치 포인터 조정.
-
파일 삭제 : 디스크 공간을 확보
-
파일 크기 조절
-
속성 설정하기 : 보호 모드 같은 일부 속성은 사용자가 설정할 수 있고, 파일을 생성한 후 변경할 수 있다.
-
파일 이름 바꾸기 : 사용자가 기존 파일의 이름을 변경 시, 새 이름으로 파일 복사 후 삭제
-
파일 닫기 : 모든 액세스를 완료하면 속성과 디스크 주소는 이제 필요하지 않아 메모리에서 내보낸다.
위 연산들을 응용해서 파일을 편집, 수정, 복사할 수 있고, 파일이 목적 코드 형태이면 실행도 할 수 있다.
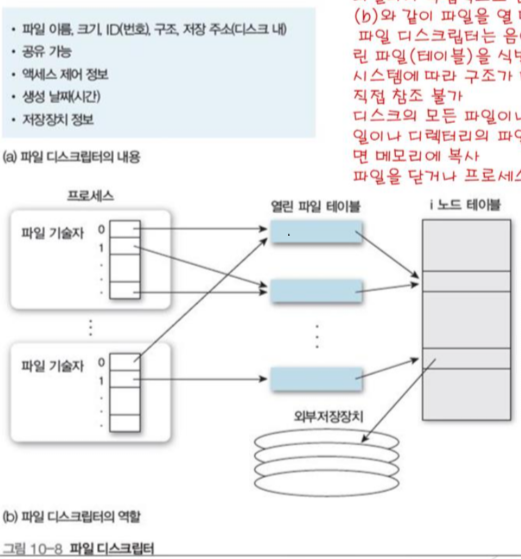
10 파일 디스크립터(descriptor)
- 파일을 액세스하는 동안 운영체제에 필요한 정보를 모아놓은 자료구조
- 각 파일마다 독립적으로 존재하며, 파일을 열 시 프로세스가 생성
- 정확히는 디스크에 파일과 함께 저장되어 있다가 열면 메인 메모리로 적재, 닫으면 메인 메모리에서 폐기
- 음이 아닌 고유의 정수인 ID로 파일을 액세스 하고 열린 파일 테이블을 식별하는데 사용한다.
열린 파일 테이블 : 프로세스나 프로세스 그룹이 현재 열린 파일에 액세스 하는 방법이 기록되어 있음.
파일 디스크립터의 자세한 내용은 그림 1-8(a)와 같다.
11 파일에 액세스하는 방법
파일의 데이터를 순회하는 방법을 의미하며, 다음이 존재한다.
11.1 순차 액세스
레코드 단위의 순서로 파일을 일을 읽는 방식
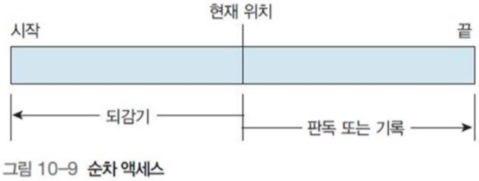
읽기 동작 : 파일의 다음 부분을 읽은 후 자동으로 파일 포인터 증가
쓰기 동작 : 파일의 끝에 내용을 추가하고, 포인터를 쓴 내용(파일의 새로운 끝)으로 이동
주로 프로 그램이 생성하는 임시 작업 파일에 사용
11.2 직접 액세스
모든 블록을 순서없이 직접 읽거나 쓰는 방식
|순차 액세스 방식| 직접 액세스 방식|
|—|—|
|reset(초기화)|cp = 0;|
|read next(다음 것 읽기)|read cp; cp = cp + 1;|
|write next(다음 것 기록)|write cp; cp = cp + 1;|
직접 액세스는 대규모 데이터베이스 등에 유용하다.
11.3 인덱스 순차 액세스(ISAM, Indexed Sequential Access Method)
디스크의 물리적 특성에 따라 인덱스를 구성하여 인덱스를 탐색하고, 포인터를 사용해 파일에 직접 액세스 하는 방식
규모가 클 경우 2차 이상의 인덱스 파일을 구성해 처리할 수 있다.
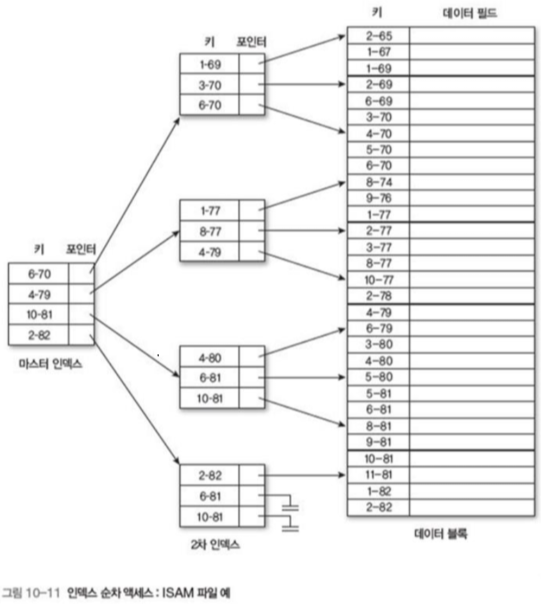
- 먼저 마스터 인덱스에서 이진 탐색을 실행해 2차 인덱스 블록 번호 탐색(첫번째 직접 액세스)
- 2차 인덱스 블록을 이진탐색 하여 원하는 레코드를 포함하는 블록 탐색(두번째 직접 액세스)
- 해당 블록을 순차 액세스
위 처럼 최대 2번의 직접 액세스와 1번의 순차 액세스로 탐색이 가능하다.
+ 적은 입출력으로 탐색이 가능
02 파일을 관리하는 디렉터리 시스템
1 디렉터리의 개념
디렉토리는 파일 시스템에서 다른 파일들의 이름과 위치 정보(파일 인덱스)를 담은 파일로 다른 파일들과 달리 사용자 데이터를 저장하지 않음.
디렉토리의 정보는 주로 시스템이 사용해 간접적으로 사용자에게 도움을 줌
디렉터리는 다음과 같이 두 부류가 있다.
-
장치 디렉터리: 각 실제 장치에 저장, 장치에 있는 파일의 물리적 속성(파일의 위치, 파일의 크기와 할당 과정)
-
파일 디렉터리: 모든 파일의 논리적 구성으로 이름, 파일 유형, 소유한 사용자, 계정 정보, 보호 액세스 코드 등을 기술
운영체제는 심벌 테이블(symbol table)로 디렉토리 내의 파일 이름을 찾는다.
디렉토리 구조를 이용하면 수많은 파일들을 디렉토리 별로 분류하여 빠르게 찾을 수 있다.
디렉터리 내의 정보는 공통적으로 다음과 같다.
- 파일 이름 : 기호로 된 각 파일의 이름은 사람이 읽을 수 있는 형태이어야 하고, 특정 디렉터리 내에서는 유일
- 파일 형태 : 이진 파일, 텍스트, 적재 모듈 등
- 위치 : 파일이 위치한 장치와 위치 포인터, 주로 경로명
- 크기 : 바이트, 워드, 블록 등으로 표현, 파일의 현재 크기와 최대 가능 크기가 포함
- 현재 위치 : 파일에서 현재 읽기나 쓰기를 행하는 위치의 포인터
- 보호 : 액세스 제어 정보는 사용자에 따라 읽기, 쓰기, 실행하기 등을 할 수 있는지 여부를 제어
- 사용 수 : 현재 열린 파일을 사용하는 프로세스 수
- 시간, 날짜, 처리 식별 : 생성 시간, 수정 시간, 마지막 액세스 시간 등을 유지하며 보호와 사용, 감시에 이용
2 디렉터리의 구현
2.1 디렉터리의 구조
디렉터리는 계층적으로 구성되어 있다.
그림 10-13은 디렉터리와 속성(파일 헤더)로 구현한 예이다.
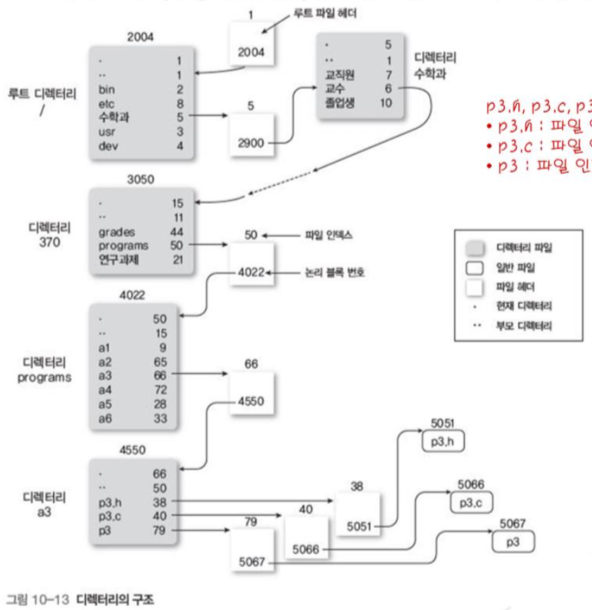
수학과\교수\programs\a3\p3.c 경로의 계층 구조 예시
파일 헤더 액세스와 디스크 블록 액세스(논리 블록 번호를 통한 변환으로 디스크 블록을 알 수 있음) => 각각 디스크 입출력 6번 씩 진행
만약 파일 헤더를 메모리에 유지했다면 파일 헤더 액세스 6번은 메모리 액세스 6번, 디스크 전송 1번(마지막 파일 내용 전송)으로 대체돼 더욱 빠를 것이다.
즉, 파일 헤더를 메모리에 유지, 최근에 사용한 디스크 블록 메모리에 유지하면 빨라진다.
디렉터리 구현은 아래와 같이 두 방법이 있다.
2.2 선형 리스트를 이용한 디렉터리 구현
디렉터리에 파일 이름, 포인터들의 선형적 리스트를 구성하여 파일의 생성과 삭제 등을 실행하는 방법
- 선형 탐색을 통한 오버헤드 증가
+ 소프트웨어 캐시, 이진 연결 트리의 이진 탐색을 통한 이진 탐색으로 오버헤드 줄일 수 있음
2.3 해시 테이블을 이용한 디렉터리 구현
파일 이름을 해쉬에서 값을 얻어 리스트를 직접 액세스하도록 디렉토리를 구현
+ 디렉토리 탐색 시간 감소 + 성능 향상
+ 연결리스트 체이닝을 이용한 해쉬 충돌 방지
- 해시 테이블 크기 고정에 의한 해시 기능 제한
- 예를 들어 해시 테이블 크기가 64 였는데 65번째 파일을 생성하려면 기존의 해시 테이블 크기를 128로 바꾸고 기존의 디렉터리 값들 또한 새로운 해시테이블에 맞게 값을 재구성해야함.
적절한 해시 테이블의 크기는 장치의 파일 수 평균값을 이용해 산정한다.
3 디렉터리의 연산
다음은 디렉토리의 가능한 연산들이다.
- 탐색하기 : 파일의 심볼릭 네임(symbolic name)을 통해 파일 간의 연관성을 나타내 특정 파일을 찾으려고 디렉토리 탐색
- 파일 생성하기
- 파일 삭제하기
- 파일 열람하기 : 파일과 파일의 디렉터리 항목값 열람
- 파일 이름 변경하기
- 파일 시스템 순회하기 : 다른 디렉터리를 순회하며 파일 열람
- 백업하기 : 신뢰성을 위해 내용 복사해 백업
4 디렉터리의 구조
논리적 파일의 디렉터리 구조
4.1 1단계 디렉터리(single level)
모든 파일이 동일한 디렉토리에 존재한다.
장치 디렉토리가 사용하는 구조
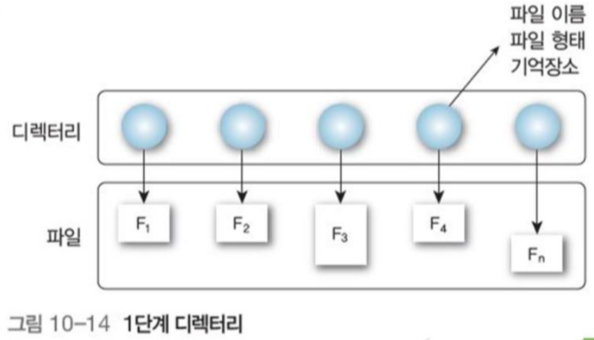
+ 가장 간단하고 쉽다.
- 파일 수가 증가하거나 다수의 사용자가 있을 시 고유한 파일명 짓기 힘듦, 시스템이 정하는 파일명 길이 제한
4.2 2단계 디렉터리
사용자 별로 자신의 서브디렉터리(subdirectory)를 생성해 그곳에 자신의 파일을 구성
사용자는 자신만의 파일 디렉터리(UFD, User File Directory)를 가진다.
유닉스나 도스가 대표
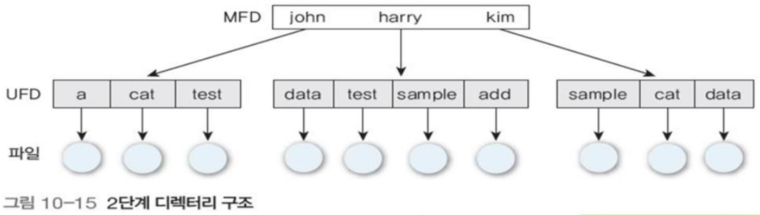
그림 10-5의 트리의 리프가 파일들이며, 사용자 이름을 경로로 사용한다.
+ 파일 이름이 겹쳐도 사용자가 다르면 상관없다.
- 파일 탐색 시, 각 항목의 포인터가 있는 사용자 고유의 마스터 파일 디렉토리(MFD, Master File Directory)를 먼저 탐색
- 삭제, 생성에도 마찬가지
+ 허용하지 않으면 다른 사용자가 함부로 파일 액세스 불가
- 액세스 하려면 상대방의 허용 + 정확한 파일명을 알아야 가능
- 사용자 디렉터리는 새로 추가될 수 있다.
-
파일을 지명하는 문법이 특이하다.
```
u:[sst.jdeck]login.com;1
u: 파티션 명
sst: 디렉터리명
jdeck: 서브디렉터리 명
맨뒤 1: 버전
```
VMS에서의 지명 문법
- 파일 탐색 시, 사용자 파일 디렉토리가 최우선 탐색되며, 없을시 이후로 여러 특수 시스템 디렉토리를 탐색하는데, 이 순서를 탐색 경로라고 하며, 마음대로 바꿀 수 있다.(유닉스, 도스 사용)
#### 4.3 트리 구조 디렉터리
루트 디렉토리를 루트로 삼고, 이후 서브 디렉토리와 파일을 노드로 삼는 구조
앞선 2단계 디렉터리는 높이가 2인 트리구조 디렉터리이다.
모든 디렉터리와 파일은 형식상 동일하고, 한 비트를 활용해 파일(0), 서브디렉토리(1)로 나눈다.
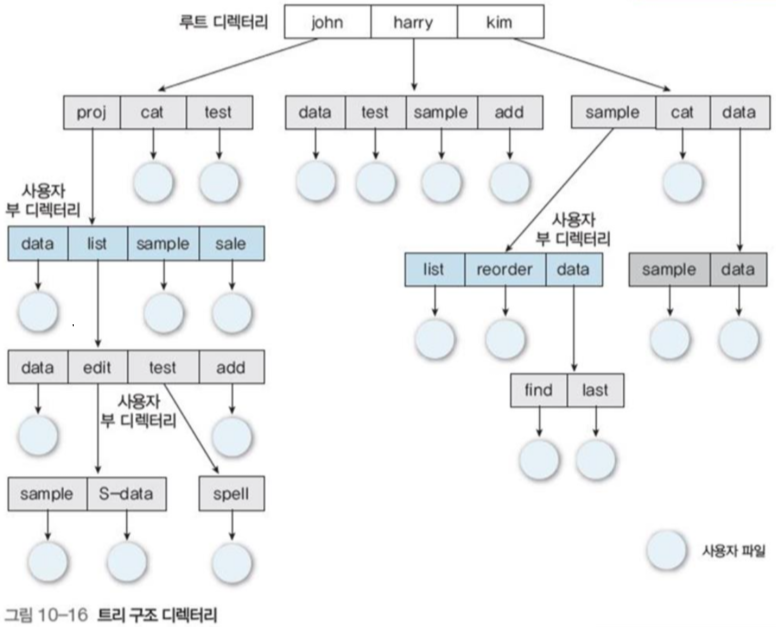
- 사용자 디렉터리 포인터가 계정 파일에 존재해 개인 디렉토리 사용 가능
- 현재 디렉토리라는 개념 존재
- 탐색 등이 현재 디렉토리를 기준으로 시작됨
- 앞서 말한 절대경로와 상대경로 개념
- 파일 삭제시 디렉토리를 비우거나(=모든 자식노드 옮기거나), 그냥 함께 삭제되도록 구현
4.4 비순환 그래프 디렉터리(acyclic graph)
트리 구조 디렉터리에 추가로 서브디렉터리와 파일을 공유할 수 있게 허용
공유는
- 링크라는 파일이나 디렉토리를 가르키는 포인터로 구현, 포인터에는 경로명으로 적혀있다.
- 바로가기와 비슷한가?
- 공유 파일의 정보와 속성을 그대로 복사하는 방법
- 단, 복사본과 원본의 무결성을 유지하기 힘듦
공유된 파일은 복사되는 것이 아니라 참조되는 것이므로, 누군가가 내용을 바꾸면 전부 바꾼 모습으로 보인다.
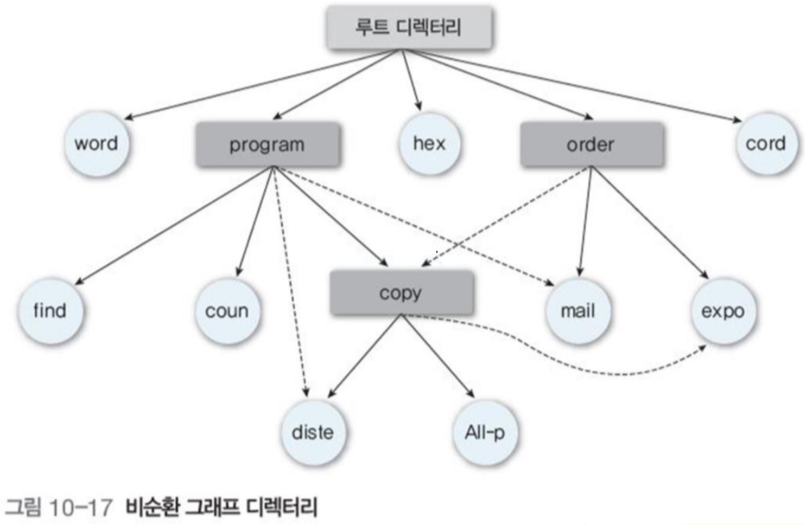
+ 트리 구조 보다 융통성 있음
- 트리 구조 보다 복잡함
- 공유 파일 삭제 시 고아 포인터(dangling pointer) 문제: 한쪽에서 삭제하면 공유된 쪽에 빈 포인터가 남음
- 해결방법 : 해당 파일의 참조 리스트를 추가해 복사나 공유되면 항목 추가, 삭제되면 리스트에서 삭제하여 리스트가 비면 완전 삭제
- 유닉스에서는 i 노드에 참조 카운터를 두어 파일 참조 작업을 수행하면 참조 카운터 증가, 끝나면 참조 카운터 감소, 0이 되면 파일 아예 삭제
- 해결방법 : 해당 파일의 참조 리스트를 추가해 복사나 공유되면 항목 추가, 삭제되면 리스트에서 삭제하여 리스트가 비면 완전 삭제
- 파일 탐색 시 공유된 파일이나 폴더가 같이 검색됨
4.5 일반 그래프 디렉터리
추가로 상위 디렉토리로의 링크를 가지게 하여 순환을 허용한 그래프 구조
기존의 구조보다 더욱 유연성 있다.
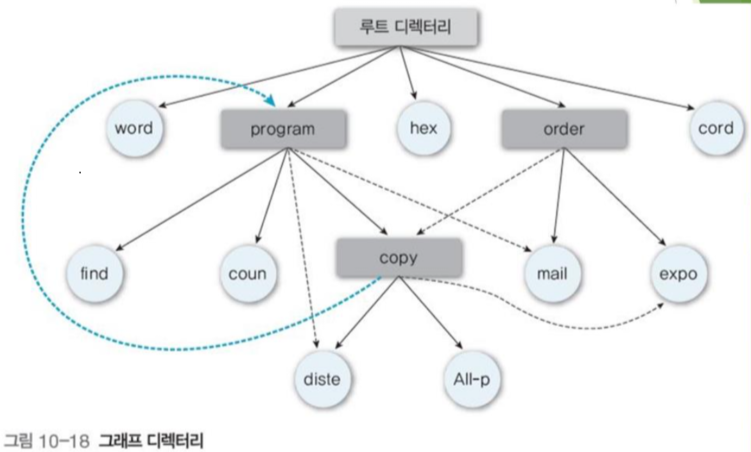
- 전역 탐색 시 순환에 의해 반복적으로 탐색되지 않도록 유의
- 삭제 시, 본인을 참조하는 경우 유의(참조 카운터 혹은 참조 리스트가 0이 되지 않을 수 있다.)
- 이를 방지하기 위해 가비지 컬렉션(garbage collection)이 필요하다.
가비지 컬렉션
- 첫번째 탐색 : 전 파일 시스템을 탐색, 액세스 가능 파일 표시
- 두번째 탐색 : 표시하지 않은 메모리(=사용 가능한 메모리)를 사용 가능 메모리 리스트에 추가
+ 참조하지 않는 파일은 지우고, 사용가능한 메모리를 알 수 있음
- 모든 파일 탐색에 따른 성능 저하, 디스크 시스템에서는 너무 느려서 사용 불가
- 순환이 존재하면 안됨
-
또는 순환 발생을 찾는 알고리즘을 이용하면 되지만 비용이 많이 듦
03 파일의 디스크 할당
1 파일의 디스크 할당 방법
파일 디스크 할당에 따라 액세스 속도와 공간 효율이 달라지며, 일반적으로 세가지 방법 중 하나를 이용
1.1 연속 할당
디스크의 연속적인 주소에 할당하는 방법.
디스크 헤드 이동이 효율적임
블록 단위로 연속 할당하며, 각 파일의 항목은 시작 블록의 번지와 영역의 길이를 가지고 있다.
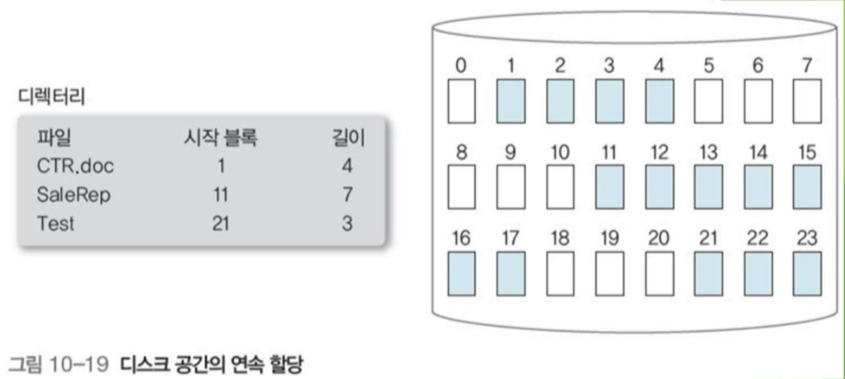
+ 블록의 위치를 예측하기 쉬우므로 직접 액세스 가능
+ 다음 블록의 위치를 찾기 쉬우므로 순차 액세스 가능
+ 좋은 성능 기대할 수 있음, 특히 작은 파일에 특화
- 연속적인 빈공간 찾기 힘듦(메모리의 적합 정책 이용)
- 외부 단편화 발생
- 세그먼테이션의 메모리 압축과 비슷한 재포장 루틴(routine)을 이용해 커다란 연속 가능 공간을 생성하여 해결 가능
- 파일 공간 크기 결정 힘듦
- 만약 파일의 크기가 계속 커져 다른 파일의 영역을 만나게 된다면?
- 해결 방법 1: 오류 메시지를 출력하고 종료한 뒤, 사용자가 재포장 루틴이나 저장공간을 확보하도록 함
- 사용자의 저장 공간의 과도한 추정으로 공간 낭비 단점
- 해결 방법 2: 새로운 충분히 큰 공간을 찾아 복사한 뒤, 이전의 공간 해제
-
추가적인 성능을 요구한다는 단점
1.2 연결 할당
각 파일을 디스크 블록들의 리스트에 연결하고, 디스크 블록들은 디스크 내에 흩어져있는 방법
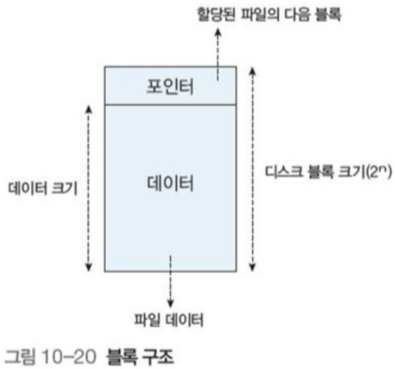
각 블록은 다음 블록의 디스크 주소를 포함하기 위한 공간이 필요하다.
디렉터리는 파일의 첫 번째 블록 포인터를 가지고 있다.
그리고 각 포인터는 다음 블록으로 연결되는 포인터를 가지고 있어, 이를 읽으면서 순차 액세스가 가능하다.
마지막 포인터는 리스트의 마지막 포인터를 의미하는nil값을 가지게 된다.
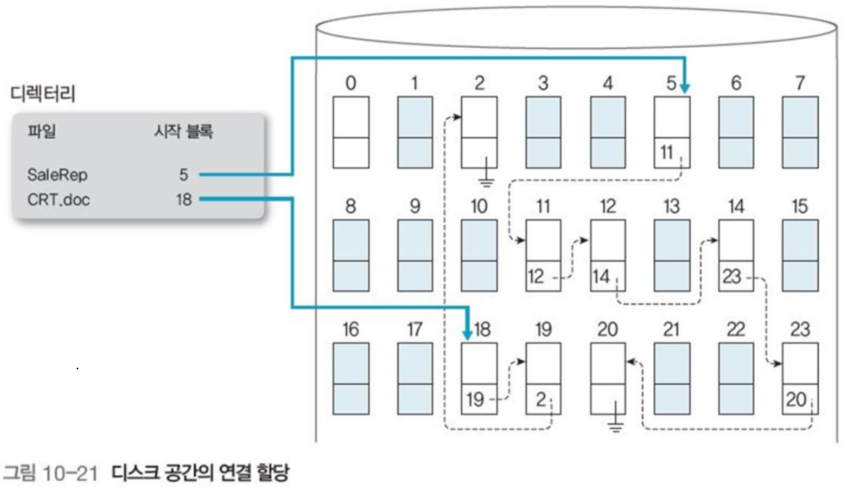
그림 10-21은 연결 할당의 예시이다.
-
- 해결 방법 1: 오류 메시지를 출력하고 종료한 뒤, 사용자가 재포장 루틴이나 저장공간을 확보하도록 함
+ 파일 생성이 쉬움, 장치 디렉터리에 새로운 항목을 생성하고, nil 값을 가진 첫번째 디스크 블록을 만들고, 용량을 키워나갈 수 있음
+ 외부 단편화가 존재하지 않음
- 순차 액세스 파일에만 가능, n번째 블록으로 직접 접근은 바로 되지 않고 순서대로 포인터를 따라가야함.
- 내부 단편화 발생 가능
- 블록이 크면 내부 단편화 심화, 대신 입출력 연산의 횟수 감소 및 연속 배치로 인한 읽기 성능 증가, 블록이 작으면 반대
- 블록 포인터 공간 필요, 대략 512 워드의 블록이라면 2워드 정도가 필요
- 신뢰성 유지가 어려움 한 워드가 블록 포인터 내용을 잃으면 그 뒤부터 모든 내용 손상
- 탐색 시간 증가 파일들이 여러 위치로 흩어져 디스크 헤드의 탐색 시간 증가, 임의 주소 계산 힘듦
신뢰성과 순차 액세스, 탐색 시간 증가의 경우 이중 연결 리스트나 관련 블록 캐싱으로 어느 정도 해결 가능하나, 여전히 많은 부담을 준다.
파일 할당표(FAT, File Allocation Table)
파일 할당표는 사용자가 해당 블록의 포인트를 실수로 지우지 않게 백업 기능과 빠르게 접근하기 위한 포인터를 모아 놓은 곳이다.
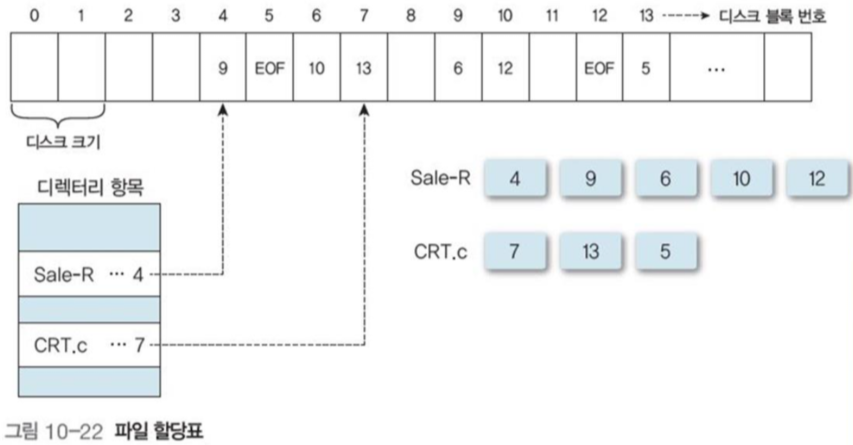
각 디스크 블록 내에 항목이 하나 있고, 블록 번호로 참조해, 연결 리스트로 많이 사용한다.
마지막 블록은 EOF(End of File)값을 가지고 있으며, 사용하지 않는 블록들은 제로 테이블 값으로 표시한다.
주로 도스와 OS/2 운영체제에서 사용한다.
1.3 인덱스 할당
모든 포인터를 인덱스 블록에서 관리하여 해당 인덱스 블록으로 직접 액세스를 지원
인덱스 블록은 각 파일마다 가지고 있는 디스크 블록 주소의 배열이다.
디렉토리에는 각 파일의 인덱스 블록 주소가 존재한다.
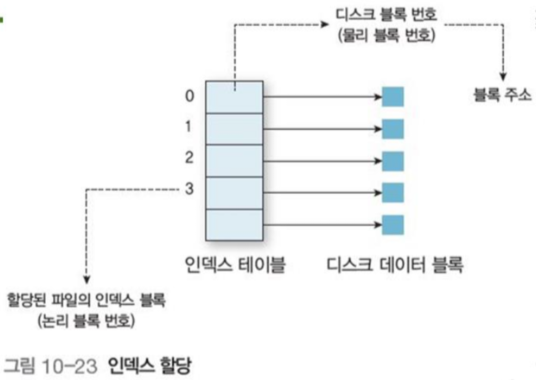
그림 10-23은 인덱스 할당의 예시로, 각 배열마다 디스크 데이터 블록을 가리키고 있다.
- 처음 인덱스를 만들면 모든 인덱스 블록 포인터가
null값이다 - i번째 블록 처음 사용시, 그 블록을 빈 공간 리스트에서 제거하고, i번째 인덱스 블록 항목에 주소를 기록
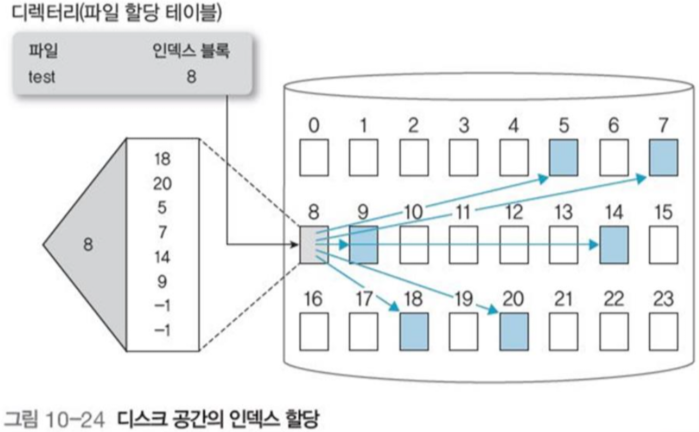
+ 직접 액세스 속도 빠름(인덱스 탐색 + 블록 탐색)
+ 구현하기 쉬움
+ 외부 단편화 없음
+ 인덱스 블록의 최대 크기만큼 확장 쉬움
- 순차 액세스 효율성 떨어짐
- 인덱스 블록 크기 이상으로 확장 어려움
- 인덱스 블록 크기 정하기 힘듬(너무 크면 수많은 파일당 부담, 너무 작으면 파일 크기 제한)
- 사용된 인덱스 블록의 포인터 크기가 연결 할당 포인터보다 메모리 부담이 큼
- 사용되지 않은 인덱스 블록은 nil 값을 가지며 공간 부담이 큼
단점을 극복하기 위해 크기가 작은 파일은 연속 할당을, 크기가 크면 인덱스 할당을 이용하게 하는 방법도 사용한다.
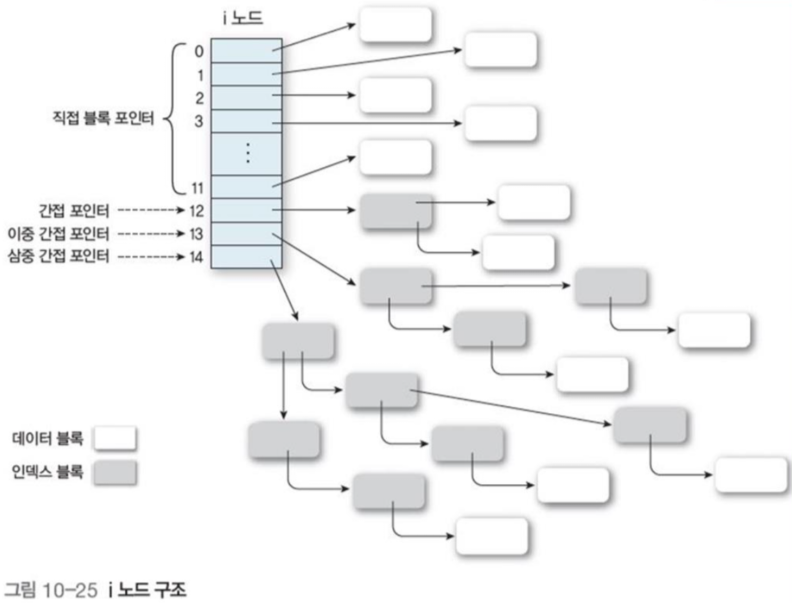
- 유닉스에서는 여러 항목에 파일 주소를 사용하는 다중 인덱스 파일 할당(Multilevel Indexed Allocation), i 노드를 이용함
- 다중 인덱스 파일 할당은 처음 항목 12개의 데이터 블록 주소(LBN)를 담는다
- 나머지 배열 항목은 각각 한 단계, 두 단계 그리고 세 단계 간접 포인터를 통해 또 다른 간접 블록을 참조한다.
- 모든 간접 블록은 마지막에 데이터 블록을 가르킨다.
3 디스크의 빈 공간 관리 방법
디스크는 빈 공간을 표시해놓은 빈 공간 리스트가 있다.
- 파일 생성 시 리스트에서 빈 공간을 빼어 할당
- 파일 삭제 시 비어진 공간을 리스트에 추가
빈 공간을 관리하는 방법은 크게 세가지로 구분된다.
3.1 비트맵
빈 공간 리스트는 비트맵(bitmap) 또는 비트 벡터(bit vector)로 구현할 수 있다.
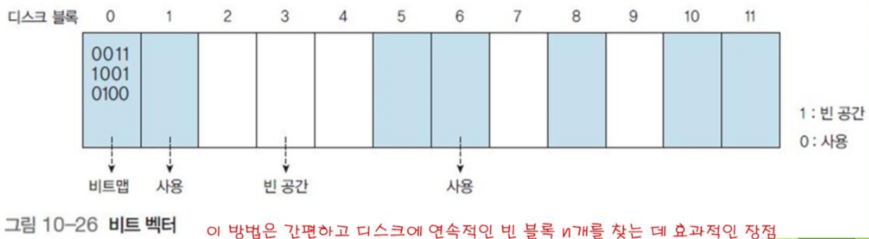
디스크의 블록 중 빈 공간은 1, 사용된 공간은 0으로 표시한다.
블록 크기가 2KB, 디스크 크기가 1GB이면 $2^{30}/2^{12}=2^{18}$개의 비트맵이 필요하며 이는 총 $2^{15}$바이트 =32KB를 의미한다.
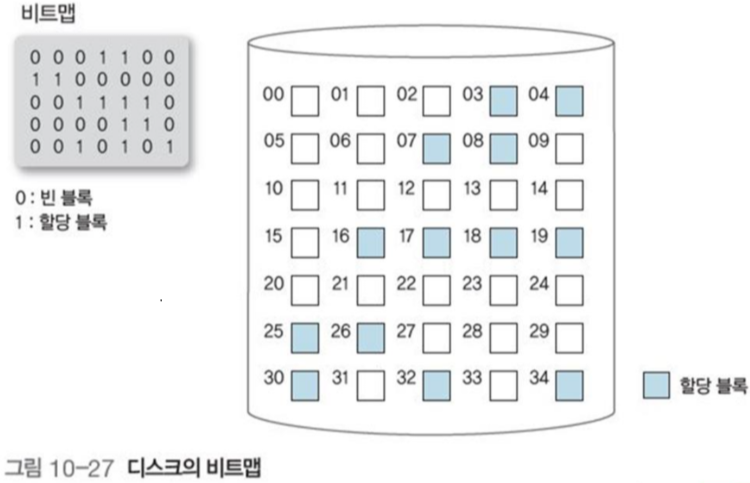
+ 구현이 간편함
+ 연속적인 빈 블록 n개를 찾기 편함
- 비효율적인 메모리 사용량
따라서 보통 대형 컴퓨터 보다는 마이크로 컴퓨터 환경에 많이 사용된다.
3.2 연결 리스트
디스크의 빈 디스크 블록을 첫 번째 빈 블록 내에서 다음 빈 디스크 블록의 포인터를 갖도록 연결 리스트로 구현
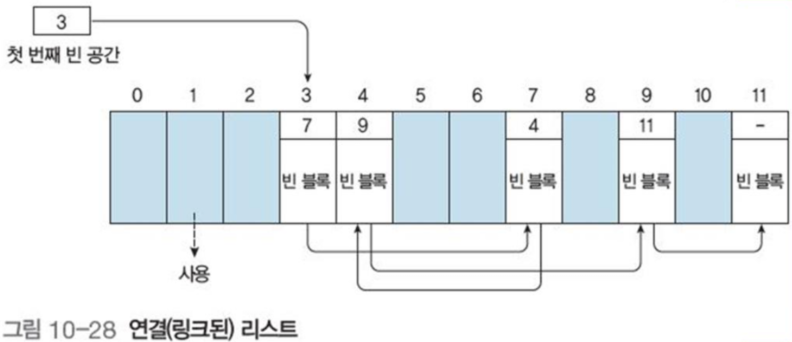
빈 공간 리스트 탐색 시 각 블록을 모두 읽어야 하므로 비효율적
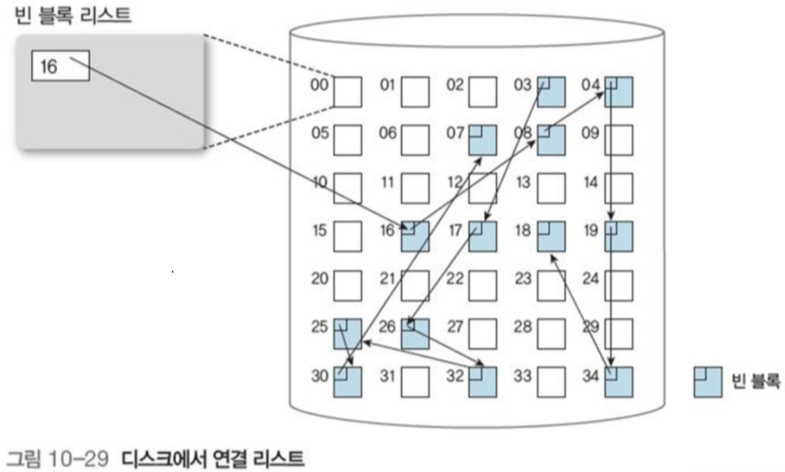
3.3 인덱스 블록(그룹핑)
빈 블록의 포인터를 인덱스 블록에 보관해 서로 연결하는 방법
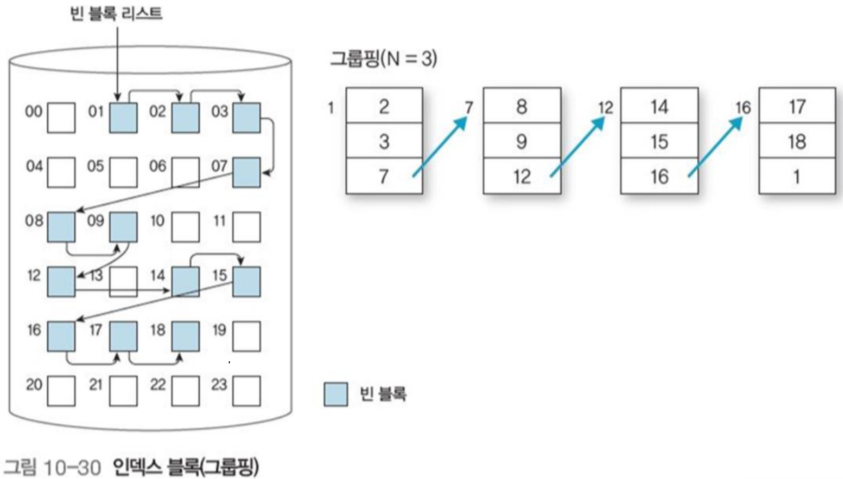
인덱스 블록은 빈 블록 중에 선정되며, 다른 빈 블록의 인덱스를 저장하는 역할을 한다.
그리고 인덱스 블록의 마지막 인덱스 또한 다른 인덱스 블록이 된다.
이 방법을 통해 사용 가능한 블록 주소를 여러개 쉽게 찾을 수 있고, 빈 블록을 활용하여 메모리 소모도 줄인다.
04 파일 보호
1 파일 보호의 필요성
컴퓨터 시스템은 다수의 사용자가 사용하는 파일들을 다음으로부터 보호해야 한다.
- 물리적인 손상 : 헤드 파손, 먼지, 온도, 전원 장애
- 부적합한 액세스
파일이 허용하는 액세스 종류는 다음과 같다.
- 읽기
- 쓰기
- 실행하기
- 추가하기
- 삭제하기
파일 이름 다시 지정, 복사, 편집 등은 위 기능을 조합해서 가능하다.
보호 방법은 파일 자체 보호와 액세스 경로 보호로 나뉨
하지만 액세스 경로 보호가 좀더 일반적인데, 디렉토리를 보호하면 파일은 자동으로 보호되기 때문
2 파일 보호 방법
2.1 파일 명명(file naming)
액세스하려는 파일의 명명 권한이 없는 사용자를 제외하여 파일을 보호
이는 파일명을 알지못하면 접근 및 사용이 힘든다는 점을 이용함.
- 하지만 파일 이름을 추측하거나 정해져있는 경우 추측이 쉽다는 단점이 있음
2.2 암호(비밀번호, password)
각 파일마다 암호를 정하여 제한
- 단, 수많은 파일마다 암호를 정하는 것은 현실적으로 불가능하고, 하나의 암호로 통일하면 보안이 취약해짐
다중 암호로 보완해야함
2.3 액세스 제어(access control)
사용자에 따라 액세스할 수 있는 파일이나 리스트를 두어 사용자 신원에 따라 서로 다른 액세스 권한 부여
액세스 요구시 이를 참조해서 보호
- 리스트의 길이가 너무 크다
- 수많은 사용자에게 수많은 파일의 액세스 리스트에 등록하면 크기가 어마어마해짐
- 디렉터리 항목이 고정 크기이므로 액세스 리스트 크기를 유동적으로 조절하기 힘듦
2.4 액세스 그룹(access group)
액세스 제어의 단점을 보완하기 위해 각 파일과 연관된 사용자를 다음 세가지로 분류하여 해결
- 소유자 : 파일 생성한 사용자
- 그룹 : 파일을 공유하고 비슷한 액세스가 필요한 사용자의 집합
- 모든 사람 : 시스템에 있는 모든 다른 사용자
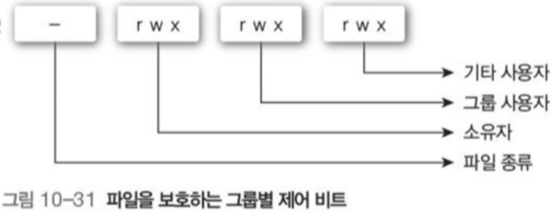
유닉스의 경우 그림 10-31처럼 각 그룹을 읽기, 액세스, 쓰기를 rwx 3비트로 표현한다.
파일당 총 9비트로 보호 정보를 사용한다.
2.5 사용자 권한(user permission) 지정
사용자가 계정을 받을 때부터 특정한 디렉터리와 파일만 액세스할 수 있도록 시스템 관리자가 허락하고 그 외의 영역은 액세스를 불허하는 방법
예를 들어 읽기 권한만 받았다면 파일의 읽기만 가능하고 삭제 등을 행하지 못한다.
+ 침입자의 손상 정도를 줄일 수 있다.
아래는 네트워크와 호스트 컴퓨터 시스템 관리자에 대한 사용자 권한이다.
|권한|설명|
|—|—|
|삭제|파일 삭제 허용|
|생성|새로운 파일 생성 허용|
|쓰기|파일에 새 정보 저장 및 수정 허용|
|읽기|파일을 열어 정보 읽기 허용|
|검색|권한 검색 명령을 이용하여 파일 검색을 허용|
_articles/computer_science/OS/IT_COOK_BOOK_OS_정리/OS 정리-Chap 10-파일 관리.md