풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
OS 정리-Chap 1-컴퓨터 시스템의 소개
1. 컴퓨터 시스템의 소개
IT COOK BOOK 운영체제 (개정 3판, 구현회 저, 한빛 아카데미) 를 정리한 내용입니다.
01 컴퓨터 하드웨어의 구성
컴퓨터 시스템은 다음 두 가지로 이루어진다.
- 데이터를 처리하는 물리적인 기계장치 하드웨어(hardware)
- 어떤 작업을 지시하는 명령어로 작성한 프로그램 소프트웨어(software)
운영체제(OS, Operating System)은 컴퓨터 하드웨어를 관리하는 소프트웨어
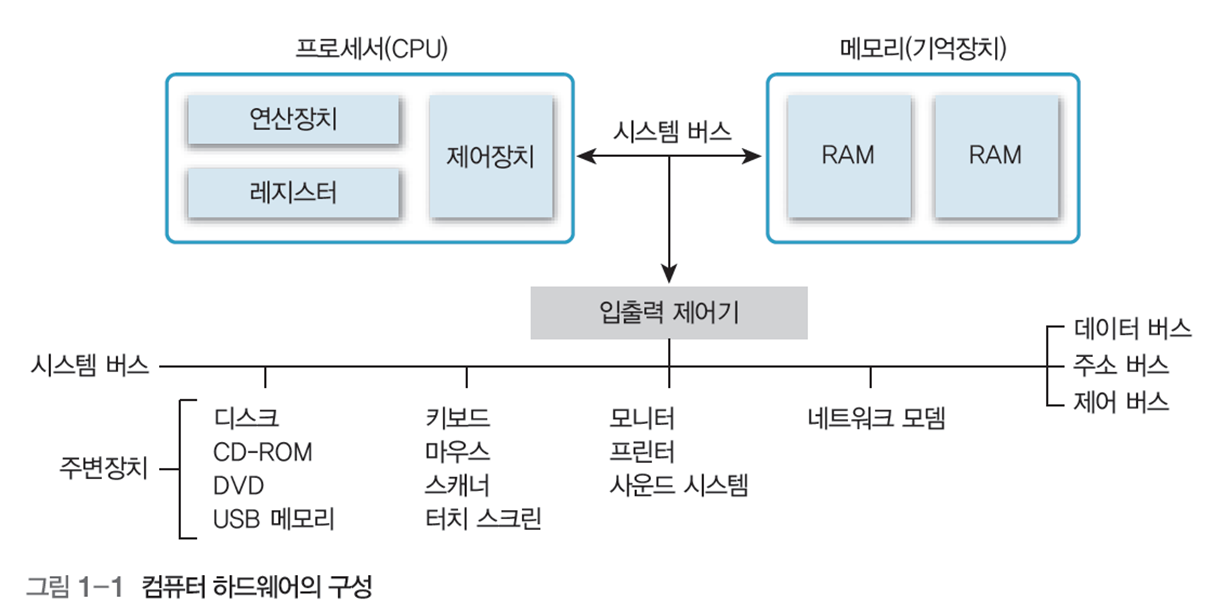
그중 컴퓨터 하드웨어는 크게 프로세서, 메모리(기억장치), 주변 장치로 구성되고, 시스템 버스로 연결된다.
1 프로세서(processor)
중앙 처리 장치(CPU, Central processing unit)이라고도 하며, 컴퓨터 하드웨어에 부착한 모든 장치의 동작을 제어하고 명령을 실행한다.
프로세서의 수가 많을 수록 병렬 처리로 처리속도를 높일 수 있다.
프로세서의 수에 따라 1개인 싱글 코어부터 8개인 옥타 코어까지 다양하다.
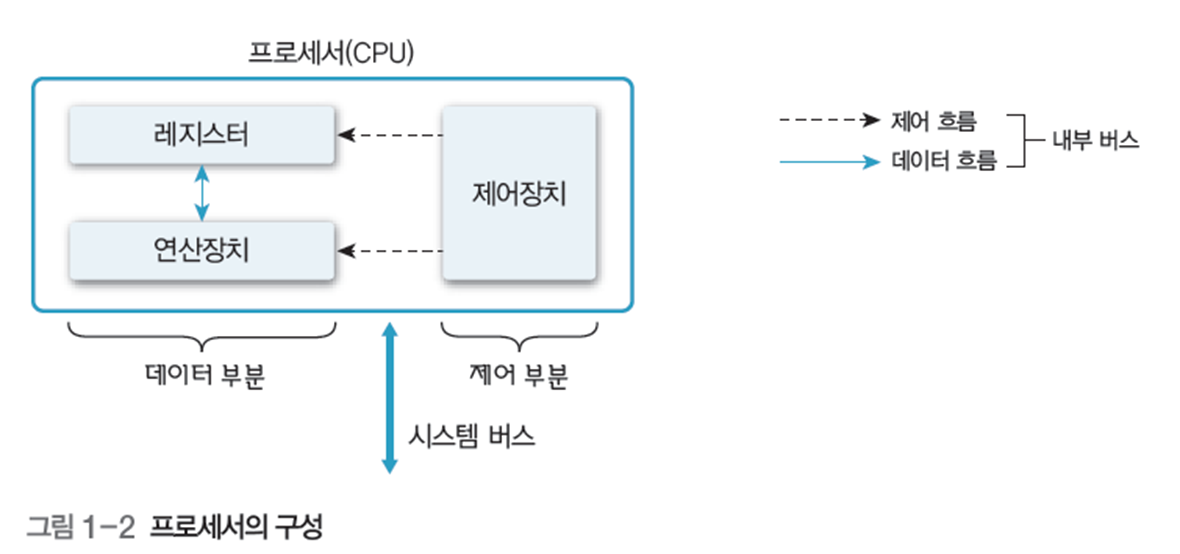
프로세서는 그림 1-2와 같이 연산장치와 제어장치, 레지스터로 구성되고, 내부 버스(시스템 버스)로 연결됨.
레지스터(Register)는 다음과 같이 구분한다.
- 용도에 따라 구분
- 전용 레지스터
- 범용 레지스터
- 사용자의 정보 변경 가능 여부에 따라 다음과 같이 사용자 가시 레지스터와 사용자 불가시 레지스터로 구분한다.
사용자 가시 (user-visible) 레지스터: 사용자가 운영체제, 응용 프로그램 등을 통해 정보를 변경 가능
- 사용자 가시 레지스터는 추가로 저장하는 정보 종류에 따라 표(1-1)와 같이 세분화된다.
| 종류 | 설명 |
|---|---|
| 데이터 레지스터(DR, Data Register) | 함수 연산에 필요한 데이터를 저장, 값, 문자 등을 저장하므로 산술 연산이나 논리 연산에 사용하며 연산 결과로 플래그 값 저장 |
| 주소 레지스터(AR, Address Register) | 주소나 유효 주소를 계산하는 데 필요한 주소의 일부분을 저장, 주소 레지스터에 저장한 값(값 데이터)를 사용해 산술 연산 |
또한, 주소 레지스터는 용도 별로 추가로 아래와 같이 구분할 수 있다.
| 종류 | 설명 |
|---|---|
| 기준 주소 레지스터 | 프로그램을 실행할 때 사용하는 기준 주소 값을 저장, 페이지나 세그먼트처럼 블록화된 정보에 접근하는 데 사용됨 |
| 인덱스 레지스터 | 유효 주소를 계산하는 데 사용하는 주소 정보를 저장 |
| 스택 포인터 레지스터 | 메모리에 프로세서 스택을 구현하는데 사용, 보통 반환 주소, 프로세서 상태 정보, 서브루틴의 임시 변수를 저장 |
- 기준 주소 : 하나의 프로그램이나 일부처럼 서로 관련 있는 정보를 저장하며, 연속된 저장 공간을 지정하는 데 참조할 수 있는 주소
- 많은 프로세서와 주소 레지스터를 통해 큐 포인터로도 사용됨.
사용자 불가시 (user-invisible) 레지스터: 사용자가 정보를 변경할 수 없는 레지스터, 프로세서의 상태와 제어를 관리
| 종류 | 설명 |
|---|---|
| 프로그램 카운터(PC, Program Counter) | 다음에 실행할 명령어의 주소를 보관하는 레지스터, 계수기로 되어있어 실행할 명령어를 메모리에서 읽으면 명령어의 길이만큼 증가해 다음 명령어를 가리키며, 분기 명령어는 목적 주소로 갱신 |
| 명령어 레지스터(IR, Instruction Register) | 현재 실행하는 명령어를 보관하는 레지스터 |
| 누산기(ACC, ACCumulator) | 데이터를 일시적으로 저장하는 레지스터 |
| 메모리 주소 레지스터(MAR, Memory Address Register) | 프로세서가 참조하려는 데이터의 주소를 명시하여 메모리에 접근하는 버퍼 레지스터 |
| 메모리 버퍼 레지스터(MBR, Memory Buffer Register) 혹은 메모리 데이터 레지스터(MDR, Memory Data Register) | 프로세서가 메모리에서 읽거나 메모리에 저장할 데이터 자체를 보관하는 버퍼 레지스터 |
아래 그림 1-3은 프로세서와 레지스터의 구조를 더욱 자세히 표현한 것이다.
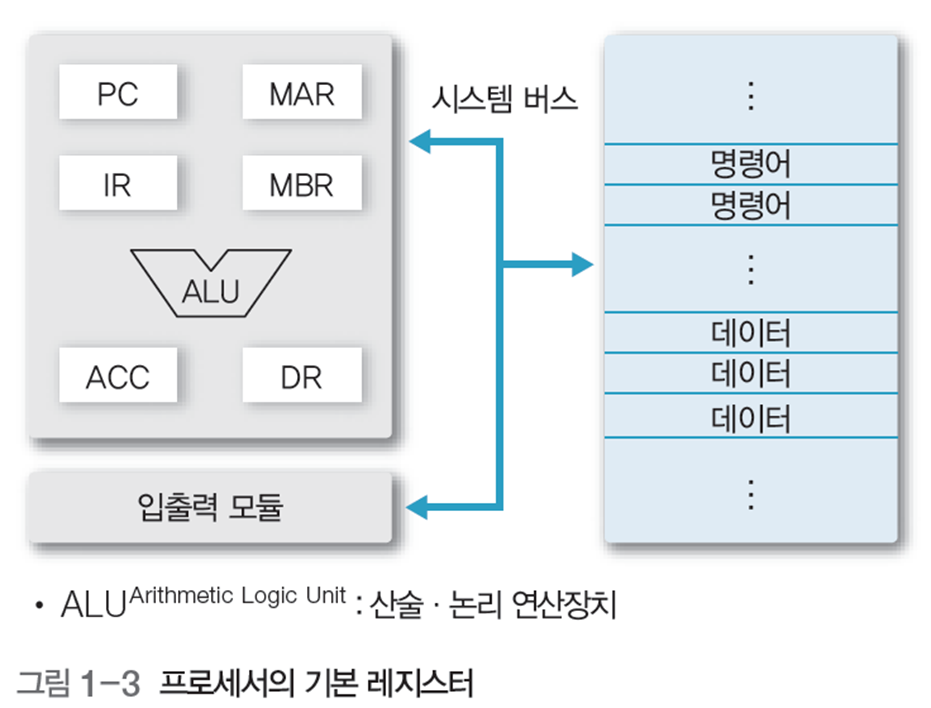
2 메모리
메모리의 입출력 속도는 컴퓨터에 지대한 영향을 주지만 속도가 빠른 메모리는 상당히 비싸므로, 그림 1-4와 같이 메모리 계층 구조를 구성하여 비용, 속도, 용량, 접근 시간 등을 상호 보완한다.
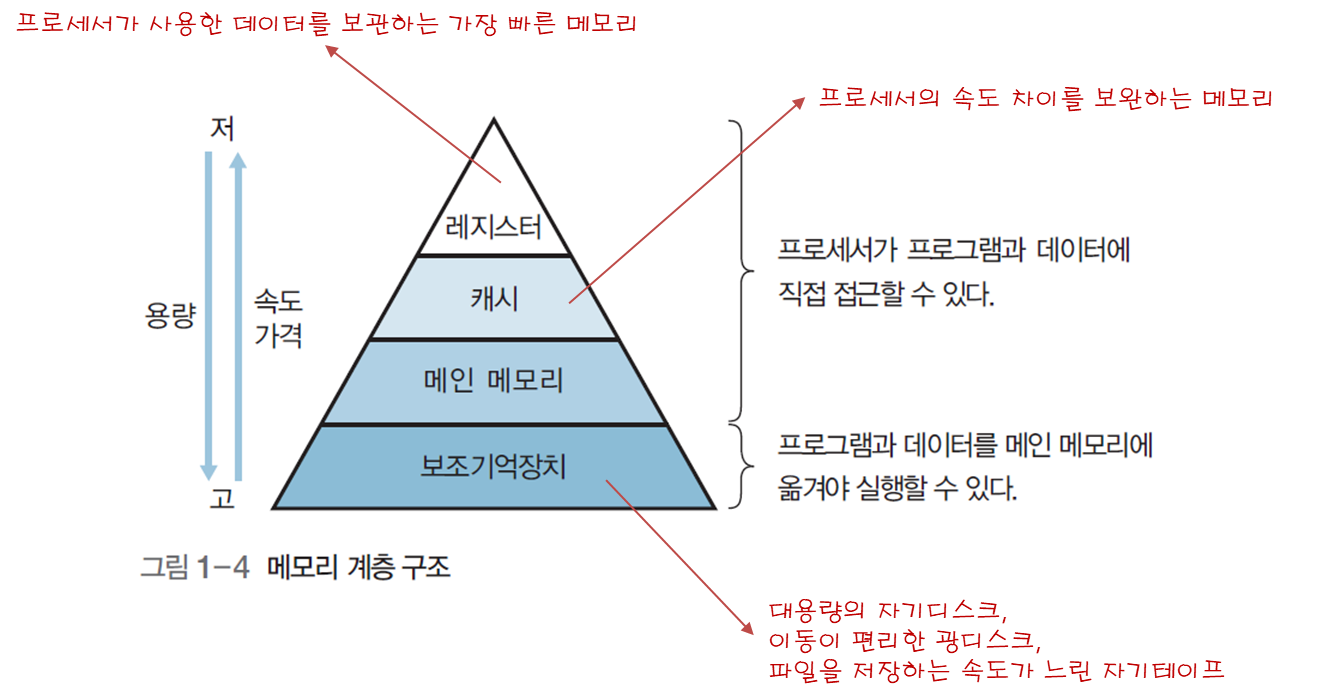
불필요한 프로그램과 데이터는 보조기억 장치에 저장했다가 실행, 참조 시에만 메인 메모리로 옮기는 원리로 비싼 메모리의 필요 용량을 줄일 수 있다.
또한 캐시나 레지스터 등을 이용해 프로세서와 메인 메모리와의 속도 차이를 보완하여 시스템 성능을 늘릴 수 있다.
2.1 레지스터
프로세서 내부에 있으며, 프로세서가 사용할 데이터를 보관하는 가장 빠른 메모리, 앞선 레지스터 분류 참조
2.2 메인 메모리

프로세서 외부에 존재하며 즉작적으로 수행할 프로그램과 데이터를 저장하거나 프로세서의 처리 결과를 저장함.
프로세어와 보조 기억장치 사이에서 입출력 속도 병목 현상을 해결하기도함.
입출력 장치들 또한 보조기억장치가 아닌 메인 메모리와 정보를 주고 받는다.
주기억장치 또는 1차 기억장치라고 하며, SRAM(Static RAM) 보다는 저장 밀도가 높고 가격이 싼 DRAM(Dynamic RAM)을 이용한다.
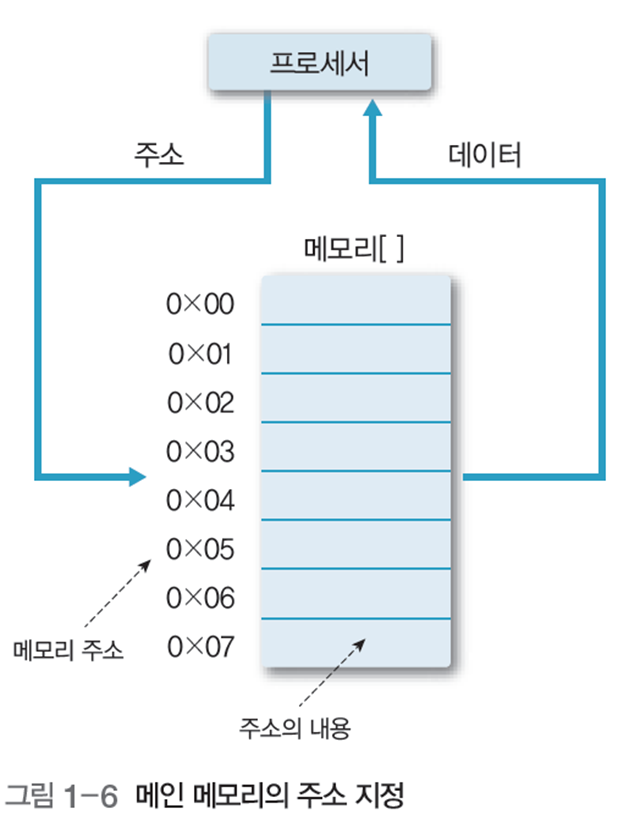
메인 메모리는 다수의 셀로 구성되며, 각 셀은 비트로 구성됨.
셀이 k비트이면 총 $2^k$개의 표현이 가능하며, 셀 여러개로 데이터를 저장한다.
셀은 주소로 참조하며, n비트이면 주소 범위는 0~$2^n -1$까지이다.
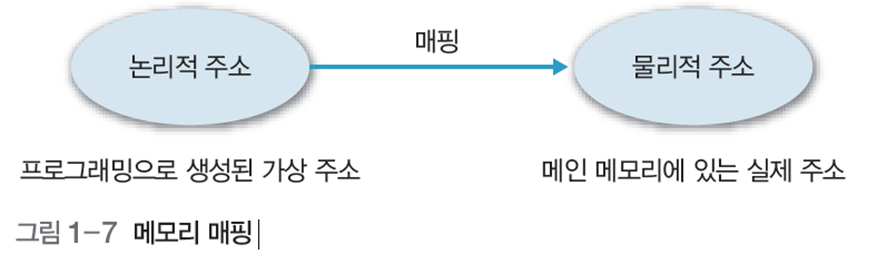
- 컴퓨터 메모리 내의 주소를 물리적 주소라고 하며, 프로그래밍 시 이를 직접 사용하지 않음
- 대신 프로그램은 수식이나 변수에 값을 할당함.
- 컴파일러가 프로그램을 기계 명령어로 바꾸는 와중에 수식과 변수에 주소를 할당
- 이 과정을 매핑(mapping) 혹은 사상이라고 한다.
- 이 주소를 논리적 주소(가상 주소, 프로그램 주소)라고 하며, 이 값들을 별도의 주소 공간에 저장한다.
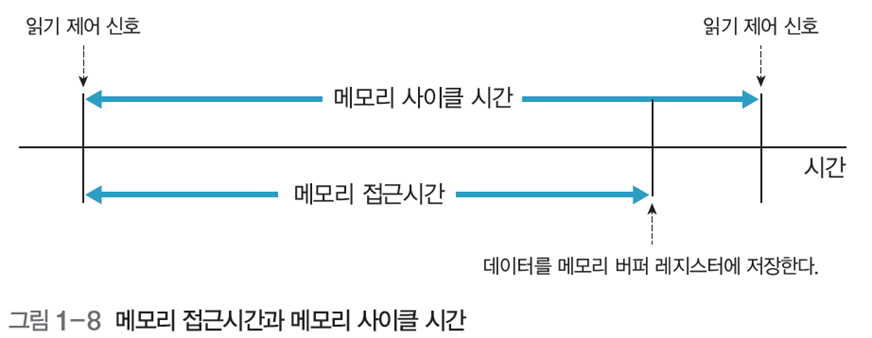
메모리 속도는 메모리 접근 시간과 메모리 사이클 시간으로 표현
- 메모리 접근 시간: 명령이 발생한 후 목표 주소를 검색하여 데이터 쓰기(읽기)를 시작할 때까지 걸린 시간
- 메모리 사이클 시간 : 두 번의 연속적인 메모리 동작 사이에 필요한 최소 지연 시간, 보통 접근 시간 보다 김
2.3 캐시(cache)
프로세서 내부나 외부에 존재하며, 처리 속도가 빠른 프로세서와 상대적으로 느린 메인 의 속도 차이를 보완하는 고속 버퍼
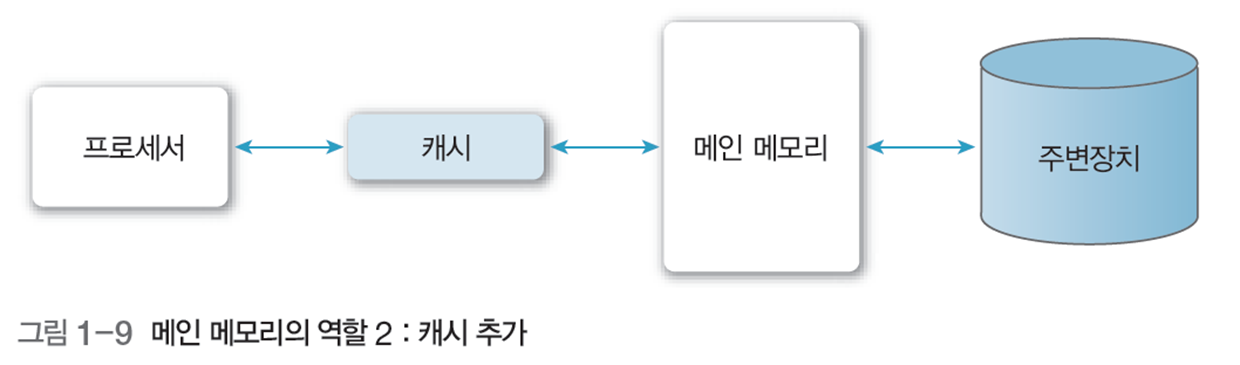
캐시는 그림 1-10과 같이 메인 메모리에서 데이터를 블록 단위로 가져와 프로세서에 워드 단위로 전달하여 속도를 높임.
또한 대역폭을 확대하여 프로세서와 메모리의 속도 차이를 줄임
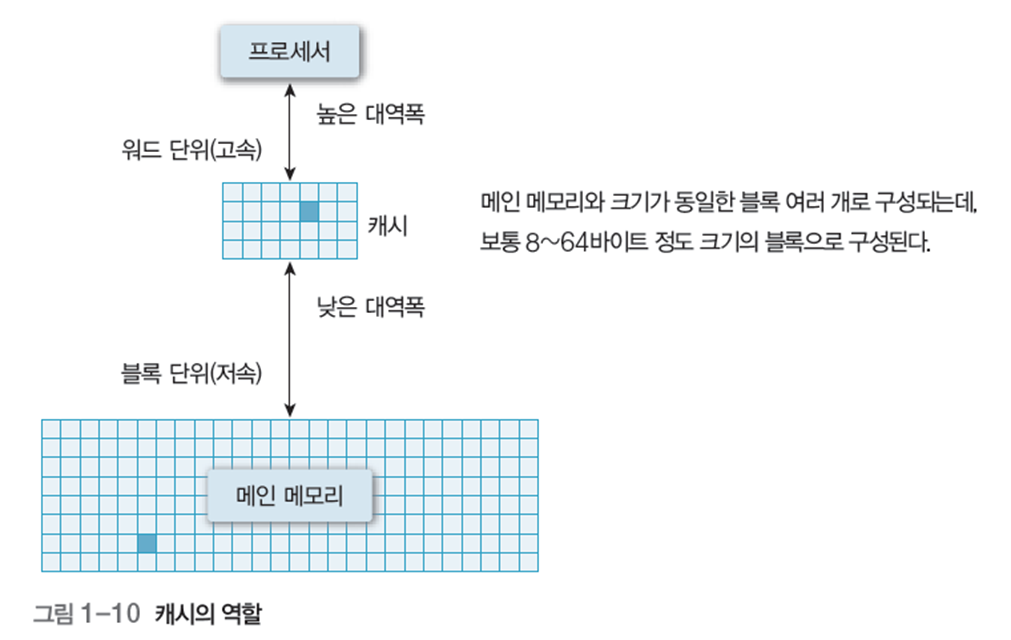
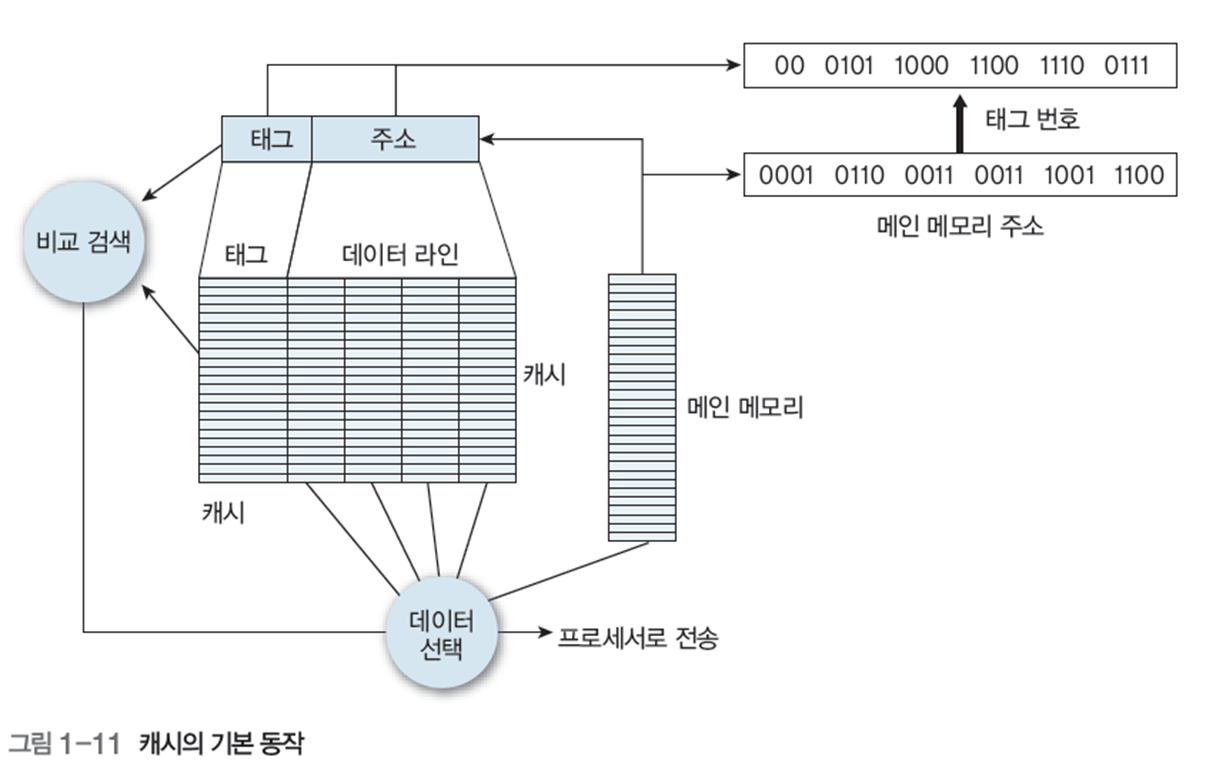
그림 1-11은 캐시 동작의 구체적 순서이다.
캐시는 주소 영역을 한번 읽어 들일 수 있는 크기로 나눈 후 각 블록에 번호를 부여하여 이 번호를 태그로 저장해 놓는다.
- 프로세스가 필요한 데이터를 메인 메모리에 찾기 전에 캐시에 존재하는 지 확인
- 접근 하려는 주소 24비트(0001 0110 0011 0011 1001 1100) 중 처음 22 비트로 캐시의 모든 라인에 접근하여 일치를 확인함
- 일치하는 라인이 존재하면 주소의 나머지 2비트(00)을 이용해 해당 라인의 4개 바이트 중 하나를 가져옴
- 해당 바이트의 값이 원하는 데이터임
캐시의 성능은 캐시 적중율에 달려있다.
- 캐시 적중(Cache hit)은 프로세서가 참조하려는 정보가 존재할 때
- 캐시 실패(Cache miss)는 존재하지 않을 때이다.
블록의 크기는 캐시의 성능을 좌우하며, 이는 메모리의 지역성이라는 특징 때문이다.
[[OS 정리-Chap 8-가상 메모리#2 지역성(구역성, 국부성, locality)]]을 참조
지역성은 블록이 크면 캐시의 히트율이 올라가지만, 전송 부담과 캐시 데이터 교체가 늘어나므로 적절한 크기를 찾아야 한다.
2.4 보조기억장치
주변 장치 중 프로그램과 데이터를 저장하는 하드웨어, 2차 기억 장치 또는 외부 기억 장치라고 하며, 자기 디스크, 광 디스크, 자기 테이프 등이 존재
보통 자기 디스크로 된 하드디스크를 많이 사용하지만, 최근에는 메모리 기술이 발달하면서 SSD도 많이 사용한다.
- SSD(Solid State Disk): 메인 메모리로 많이 사용하던 플래시 메모리를 컨트롤러와 함께 사용하는 저장 장치, 입출력 속도가 아주 빠르다.
- NVRAM(Non-Volatile RAM): 외부 전원이 꺼지거나 상실되더라도 내용이 보존되는 RAM
3 시스템 버스(system bus)
하드웨어를 물리적으로 연결하여 서로 데이터를 주고받을 수 있게 하는 통로
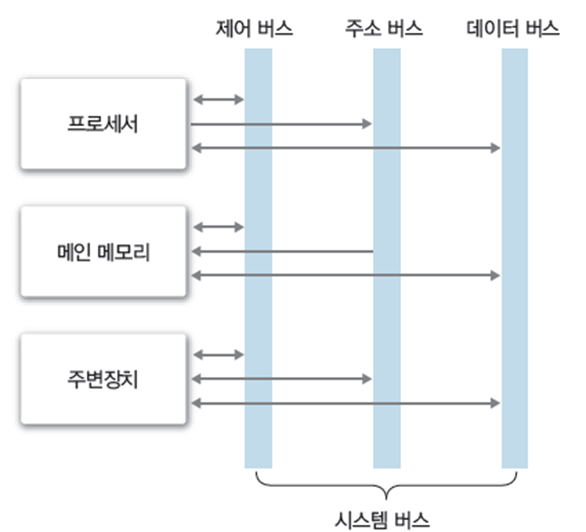
컴퓨터 내부의 데이터 입출력 신호, 프로세서 상태 신호, 인터럽트 요구, 클록 신호 등을 전달하는 역할이며, 기능에 따라 표 1-3 처럼 나뉜다.
| 종류 | 설명 |
|---|---|
| 데이터 버스 | 프로세서와 메인 메모리, 주변 장치 사이에서 데이터를 전송, 데이터 버스 구성 배선 수에 따라 전송하는 비트 수가 결정되며 이를 워드라고 함. |
| 주소 버스 | 프로세서가 시스템의 구성 요소를 식별하는 주소 정보를 전송, 배선 수가 프로세서와 접속 할 수 있는 메인 메모리의 최대 용량을 결정 |
| 제어 버스 | 프로세서가 시스템의 구성 요소를 제어하는 데 사용, 제어 신호로 연산장치의 연산 종류와 메인 메모리의 읽기나 쓰기 동작을 결정 |
4 주변 장치
프로세서와 메인 메모리를 제외한 나머지 하드웨어 구성 요소
입력 장치, 출력 장치, 저장 장치가 존재
02 컴퓨터 시스템의 동작
컴퓨터 시스템으로 작업 처리 시, 다음 순서에 따라 동작하며, 제어 장치가 이 동작을 제어
- 입력 장치로 정보를 입력 받아 메모리에 저장
- 메모리에 저장한 정보를 프로그램 제어에 따라 인출하여 연산 장치에서 처리
- 처리한 정보를 출력 장치에 표시하거나 보조 기억 장치에 저장
1 명령어의 구조
명령어는 실행할 산술, 논리 연산의 동작을 명시하는 문장, 이들의 집합이 프로그램이다.
명령어의 구성
- 프로세서가 실행할 연산인 연산 부호 : 왠만하면 한개
- 명령어가 처리할 데이터
- 데이터를 저장한 레지스터나 메모리 주소인 피연산자 : 여러 개일 수 있음
명령어는 프로세서에 따라 고정 길이나 가변 길이로 구성

- 연산 부호(OPcode, OPeration code): 프로세서가 실행할 동작인 연산을 지정, 비트 수가 n이면 최대 $2^n$개의 연산 종류가 존재한다.
- 산술 연산(+, -, *, \), 논리 연산(AND, OR, NOT, XOR), 시프트, 보수 등이 존재
- 피연산자(operand) : 연산할 데이터 정보를 저장, 레지스터, 메모리, 가상 기억장치, 입출력 장치 등에서 가져온다. 데이터 값 그 자체 혹은 데이터 주소를 기입함

- 그림 1-14는 명령어의 구조 예시이며, 피연산자가 2개인 경우 이다.

명령어는 운영체제 실행 이후 (그림 1-15)처럼 메인 메모리에 저장되며, 한 번에 하나씩 프로세서에 전송되어 실행된다.
- 피연산자 수에 따라 0-주소 명령어, 1- 주소 명령어, 2-주소 명령어 등이 존재
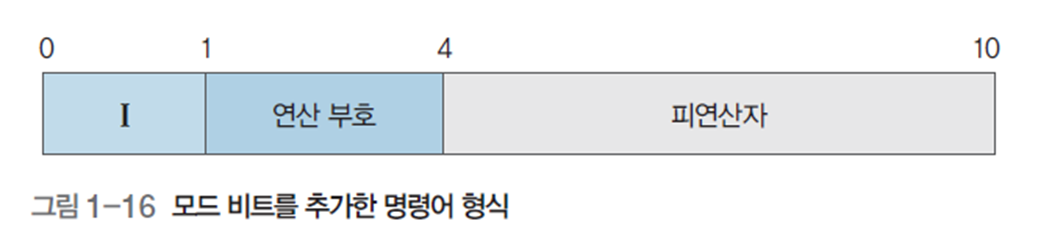
그림 1-16의 모드비트(mode bit)는 피연산자의 내용이 직접 주소(0) 혹은 간접 주소(1)임을 나타낸다.
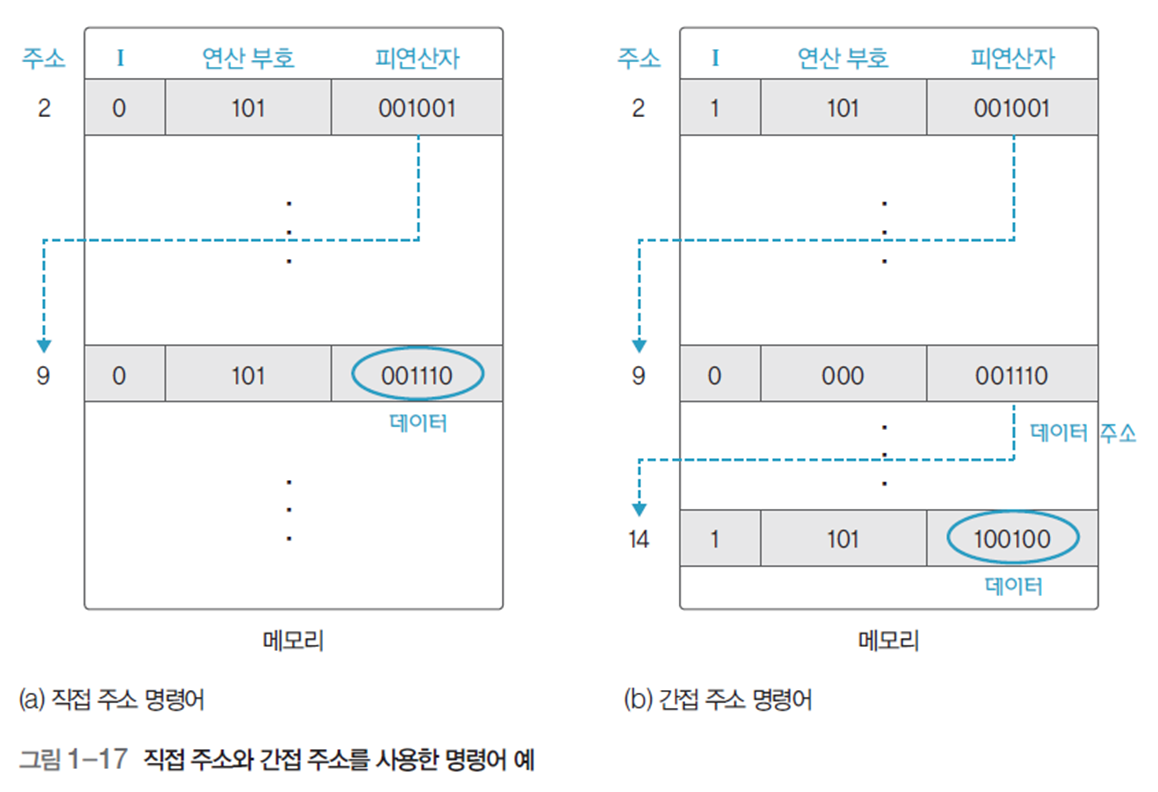
그림 1-17은 모드가 1비트, 연산 부호가 3비트, 피연산자가 6비트인 명령어이다.
(b)를 보면 알다시피, 직접 주소의 경우 1번의 참조를, 간접 주소의 경우 2번의 참조가 필요하다는 것을 알 수 있다.
2 명령어의 실행
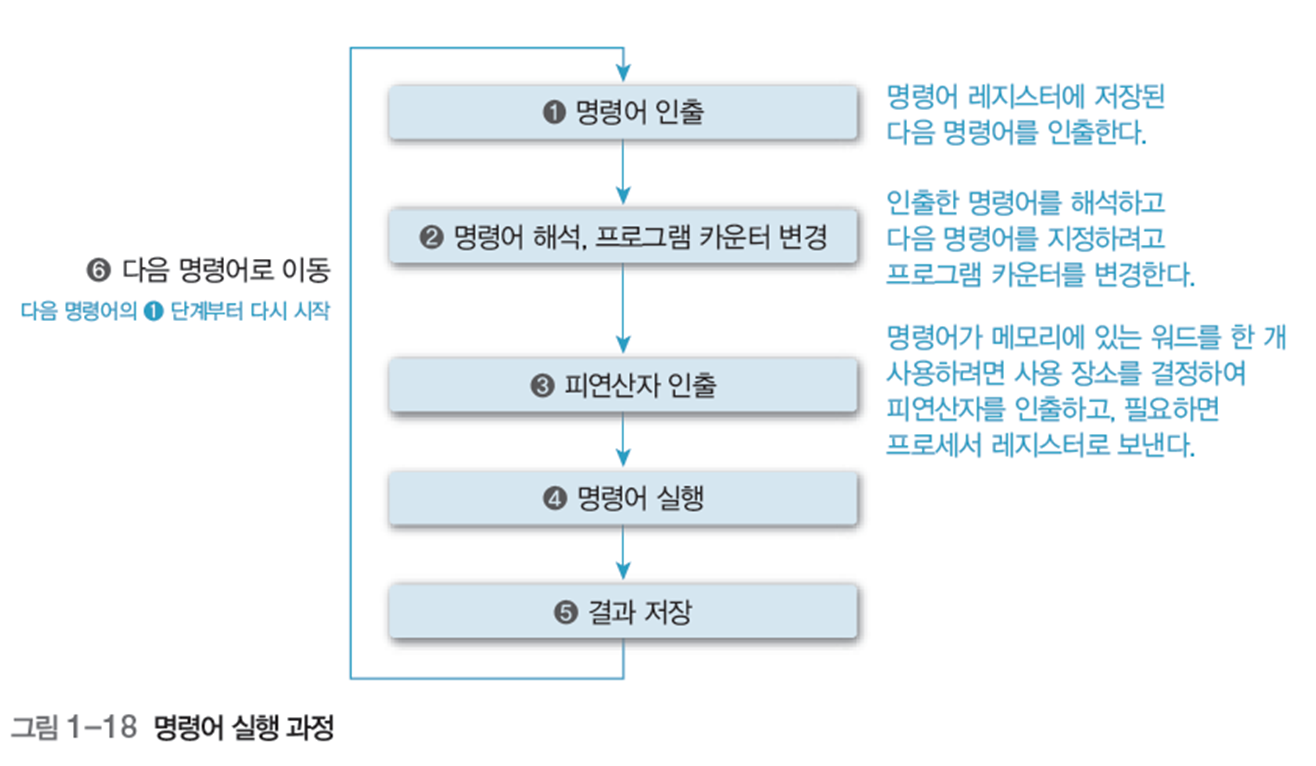
그림 1-18은 명령어의 실행 과정이다.
명령어 인출-해석-실행 사이클, 인출-실행 사이클, 명령어 실행 주기라고 한다.
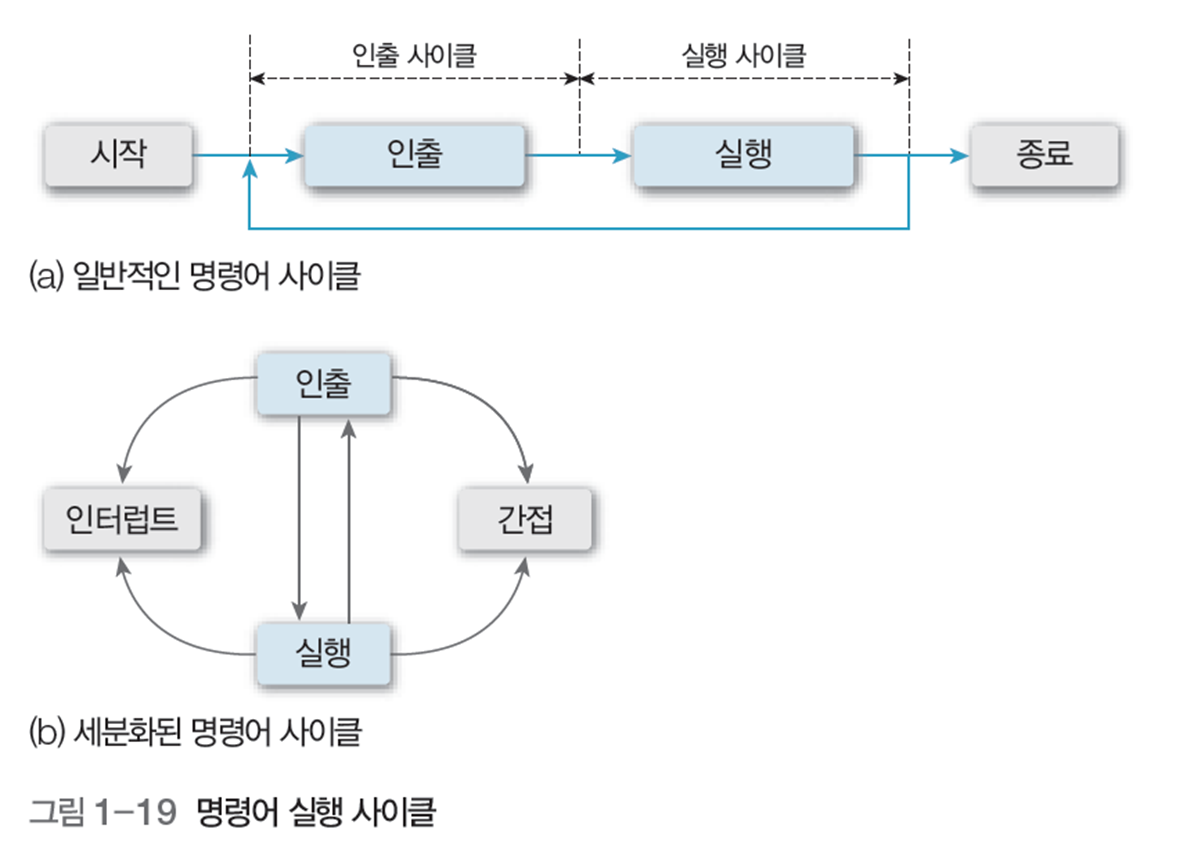
명령어 실행 사이클은 인터럽트 여부, 간접 주소 여부 등에 따라 다양하게 변하며, 이 과정을 반복한다.
2.1 인출 사이클(fetch cycle)
- 명령어 실행 사이클의 첫번째 단계
- 메모리에서 명령어를 읽어 명령어 레지스터에 저장하고, 다음 명령어를 실행하려고 프로그램 카운터를 증가 시킴
- 이때 소요되는 시간은 명령어 인출 시간
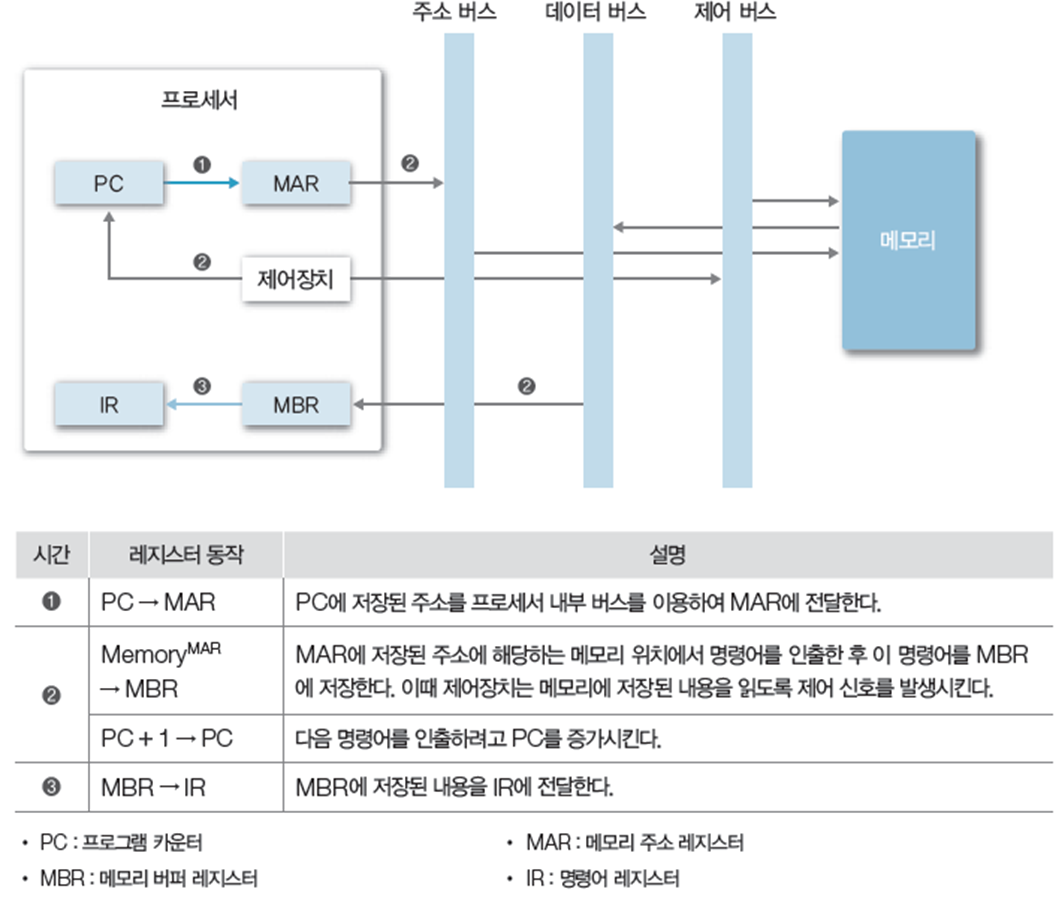
2.2 실행 사이클(execution cycle)
- 인출한 명령어를 해독하고 그 결과에 따라 제어 신호를 발생 시켜 명령어 실행
- 이때 소요되는 시간을 실행 시간이라고 한다.
2.3 간접 사이클(indirect cycle)
가져온 명령어를 즉시 수행하는 직접 주소와 달리, 한번 더 메모리에서 유효 주소를 읽어옴
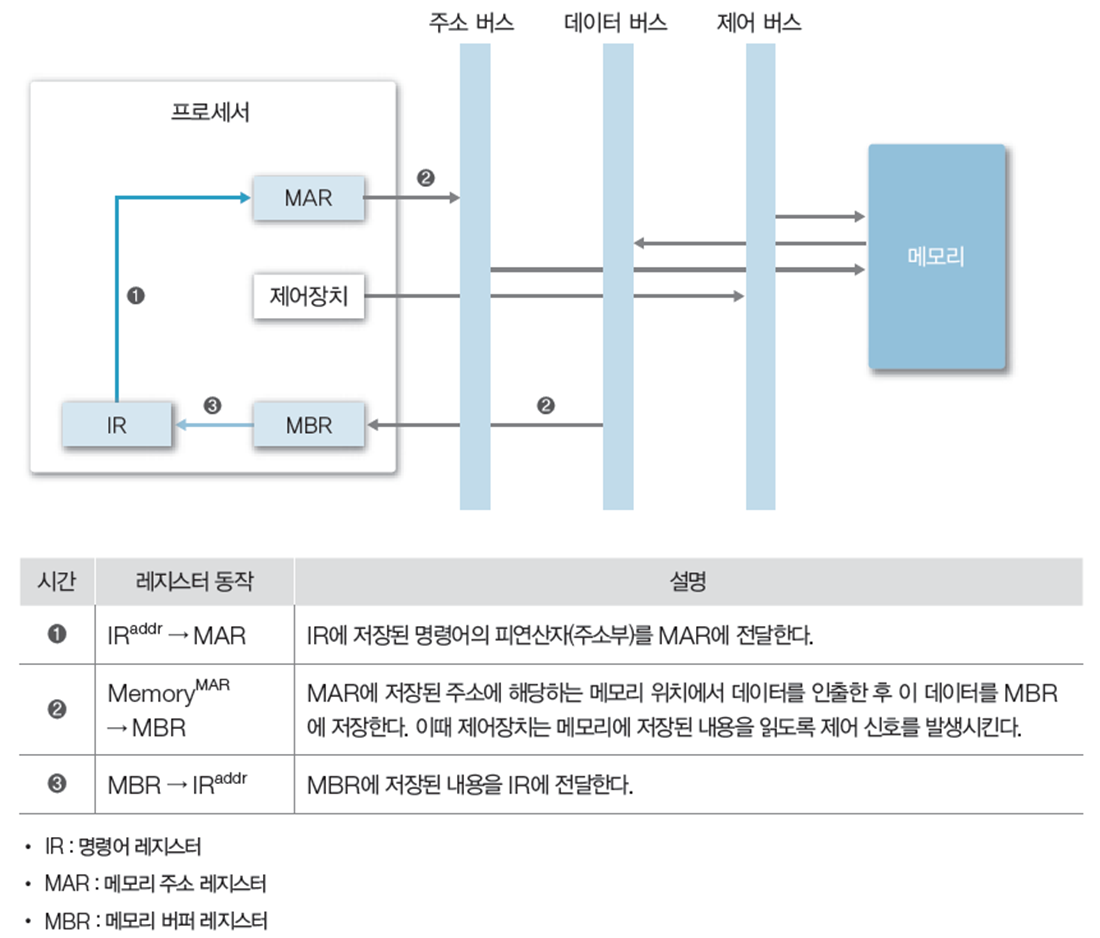
위 그림은 한번만 실행되는 것처럼 보이며, 위 과정을 두 번 반복해야 간접 사이클인듯 하다.
2.4 인터럽트 사이클(interrupt cycle)
인터럽트란?
- 프로세서가 프로그램을 수행하는 동안 컴퓨터 시스템의 내부나 외부에서 발생하는 예기치 못한 사건
- 현재 실행 중인 프로그램을 중단하고 다른 프로그램의 실행을 요구하는 명령어
- 컴퓨터에 설치된 입출력 장치나 프로그램 등에서 프로세서로 보내는 하드웨어 신호
- 갑작스런 정전, 잘못된 명령어 수행, 입출력 작업 완료 등에 사용됨
- 시스템 처리 효율 향상, 실행 순서 변경, 다중 프로그램을 가능케 함.
- 프로세서는 매 실행 사이클 완료 후 인터럽트 요구를 검사
- 인터럽트 존재 시, 현재 수행 중인 프로그램 주소(프로그램 카운터의 값)을 스택이나 메모리의 0번지 같은 곳에 저장
- 인터럽트 처리 루틴의 시작 주소를 프로그램 카운터에 적재하고 인터럽트 처리
- 다시 스택이나 메모리 0번지의 프로그램 주소를 되돌리고 계속 수행
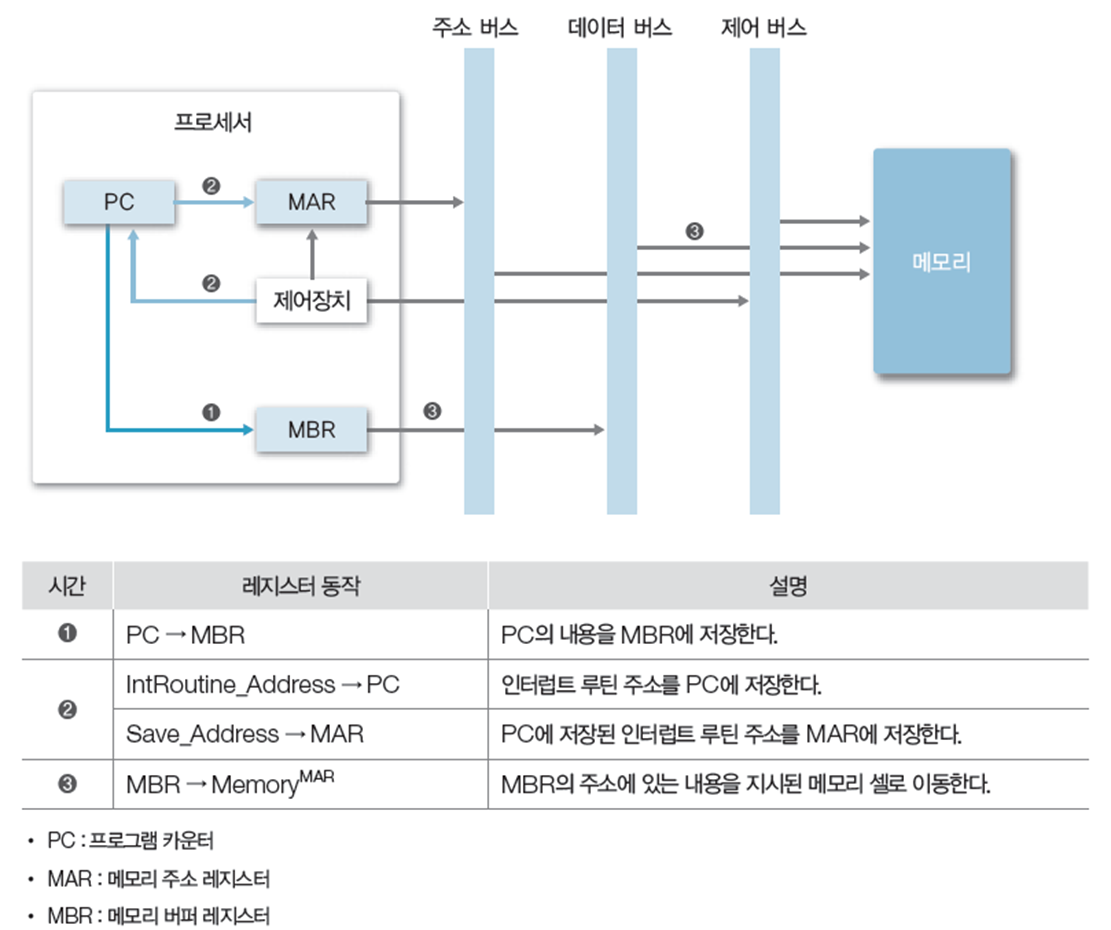
3 인터럽트 명령어
인터럽트의 필요성 사용 예시
- 각 장치는 사용 가능한지 알려주기 위해 1 비트의 상태 비트를 가지고 있음
- 프로세서는 장치를 사용하기 전에 폴링(polling)으로 각 장치의 상태 비트를 검사
- 이때 주기적으로 장치를 검사하면 비효율적이므로 장치의 인터럽트를 통해 각 장치의 상태 비트를 업데이트
제어 버스 중에 인터럽트 요청 회선(IRQ, Interrupt ReQuest line)은 이러한 인터럽트를 보내는 회선이다.
인터럽트는 인터럽트 요청과 인터럽트 서비스 루틴으로 구분할 수 있다.
- 인터럽트 서비스 루틴(interrupt service routine) : 인터럽트 요청 신호에 따라 수행하는 루틴
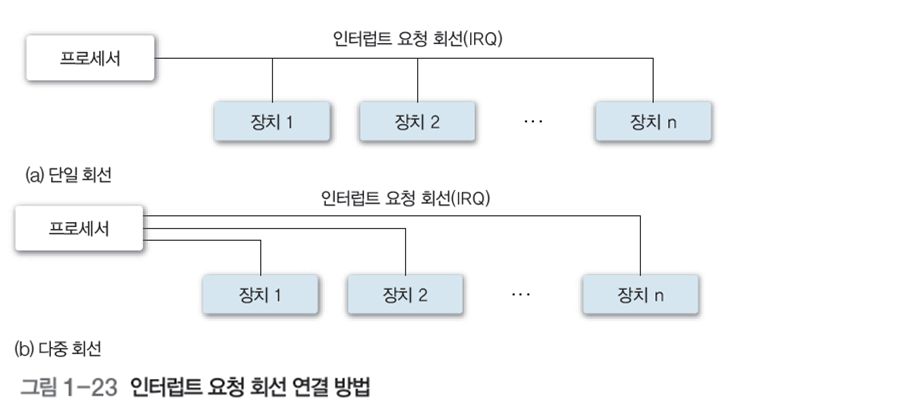
인터럽트 요청 회선의 연결 방법은 그림 1-23처럼 단일 회선과 다중 회선으로 나뉜다. - 단일 회선 : 인터럽트 요청이 가능한 모든 장치를 공통의 단일 회선으로 프로세서에 연결하는 방법, 각 인터럽트를 요청한 장치를 구분할 방법이 필요
- 다중 회선 : 모든 장치에 고유의 회선이 존재하는 방법, 인터럽트 요청 장치 구분 쉬움
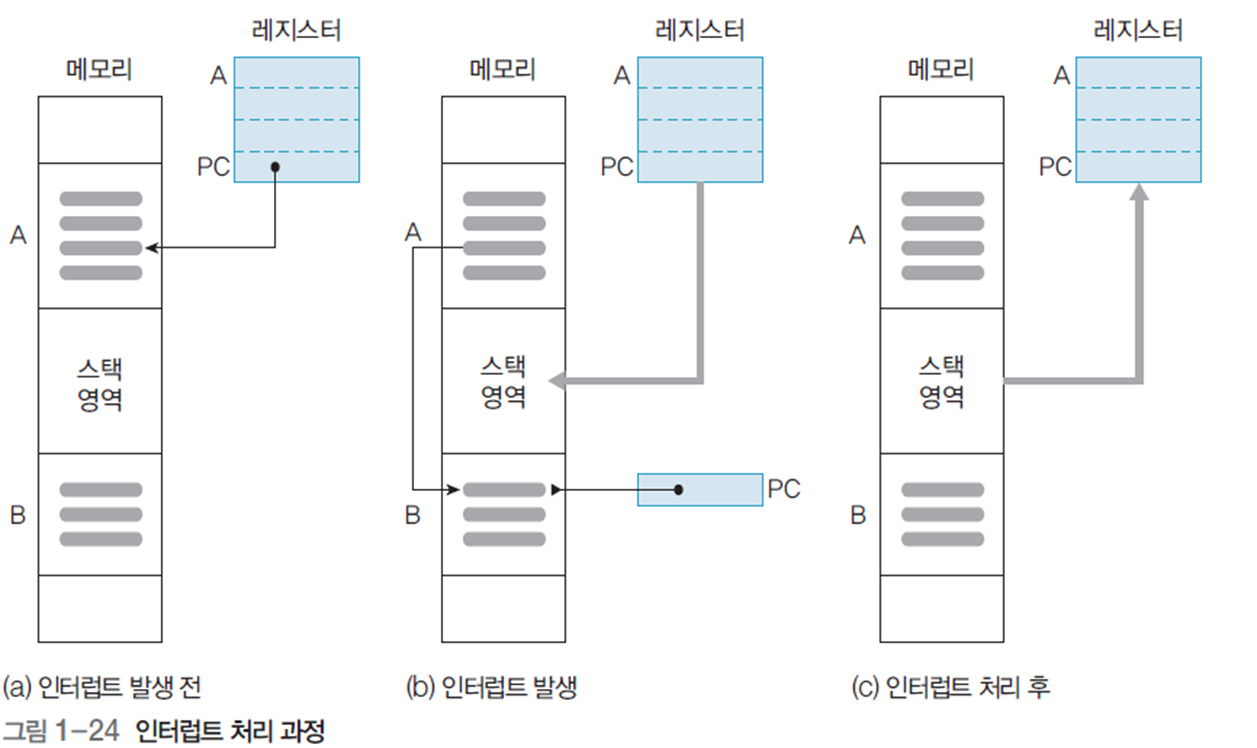
그림 1-24는 인터럽트 처리 과정의 예시이다.
앞선 [[#2.4 인터럽트 사이클(interrupt cycle)]]처럼, 기존의 명령어를 스택 영역에 저장하고, 인터럽트 처리 후 재 진행한다.
인터럽트와 서브루틴의 차이
PC 값을 저장하고 재적재하는 방식이 서브루틴과 비슷하나 몇몇 다른 점이 있다.
- 서브루틴은 자신을 호출한 프로그램이 요구한 기능 수행
- 인터럽트는 장치가 요구한 기능 수행
- 현재 실행 중인 프로그램과 관계없을 수 있음
- 따라서 인터럽트는 프로그램 카운터 뿐만 아니라 영향을 미칠 수 있는 기존 프로그램의 상태 워드와 모든 정보를 저장해두었다가 재적재한다.
_articles/computer_science/OS/IT_COOK_BOOK_OS_정리/OS 정리-Chap 1-컴퓨터 시스템의 소개.md