풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
한국어 언어 모델 다루기-KLUE
- 01. 인공지능과 자연어 처리
- 02. 자연어 전처리
- BERT 언어모델
- BERT Pre-Training
- 05. BERT 언어모델 기반의 단일 문장 분류
- BERT 언어모델 기반의 두 문장 관계 분류
- 문장 토큰 분류
- GPT 언어 모델
KLUE(한국어 언어 모델 학습 및 다중 과제 튜닝)
Naver AI Boostcamp의 KLUE 강의를 정리한 내용입니다.
01. 인공지능과 자연어 처리
인공지능과 자연어 처리에 대하여
인공지능 : 인간의 지능이 가지는 학습, 추리, 적응, 논증 따위의 기능을 갖춘 컴퓨터 시스템
ELIZA (1966) : 기계에 지능이 있는지 판별할 수 있는 튜링 테스트(이미테이션 게임)을 적용할 수 있는 최초의 Human-like AI
자연어 처리에는 문서 분류, 기계 독해, 챗봇, 소설 생성, 의도 파악, 감성 분석 등의 응용 분야가 있다.
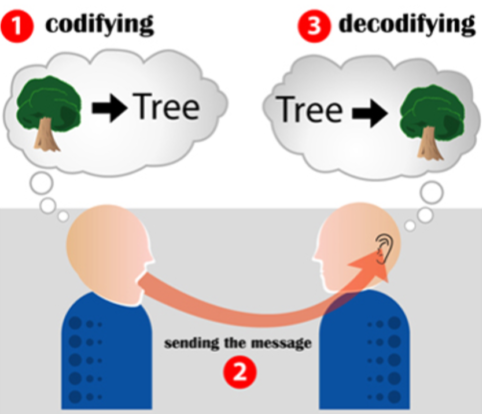
인간의 자연어 처리 (대화)의 경우
- 화자는 자연어 형태로 객체를 인코딩
- 메세지의 전송
- 청자는 본인 지식을 바탕으로 자연어를 객체로 디코딩
하는 과정을 거친다.
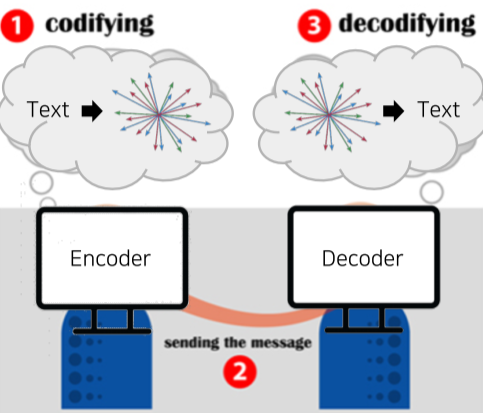
비슷하게 컴퓨터의 자연어 처리는
- Encoder는 벡터의 형태로 자연어를 인코딩
- 메세지의 전송
- Decoder는 벡터를 자연어로 디코딩
하는 과정을 거친다.
즉, 자연어 처리는 컴퓨터를 이용하여 인간 언어의 이해, 생성 및 분석을 다루는 인공 지능 기술

대부분의 자연어 처리 문제는 분류 문제로 생각할 수 있으며, 분류를 위해 데이터를 수학적으로 표현되어야 한다.
이를 위해 가장 먼저,
- 분류 대상의 특징 (Feature)을 파악(Feature extraction)
- 특징을 기준으로 분류 대상을 그래프 위에 표현 뒤, 대상들의 경계를 수학적으로 나눔(Classification)
- 새로 들어온 데이터를 기존 Classification을 통해 그룹 파악 가능
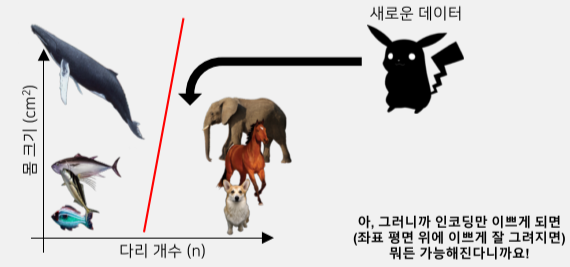
과거에는 위의 과정을 사람이 직접 했지만 이제는 컴퓨터가 스스로 Feature extraction과 Classification 하는 것이 기계학습의 핵심이다.
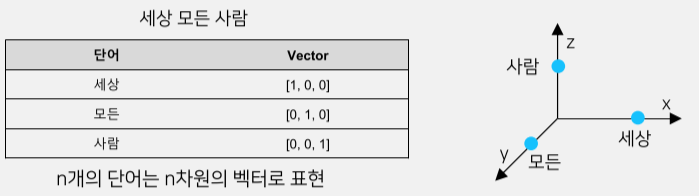
자연어를 좌표 평면 위에 표시하는 방법으로 one-hot encoding 방식이 있지만 단어 벡터가 sparse 해지므로 해당 방식은 의미를 가지지 못한다.
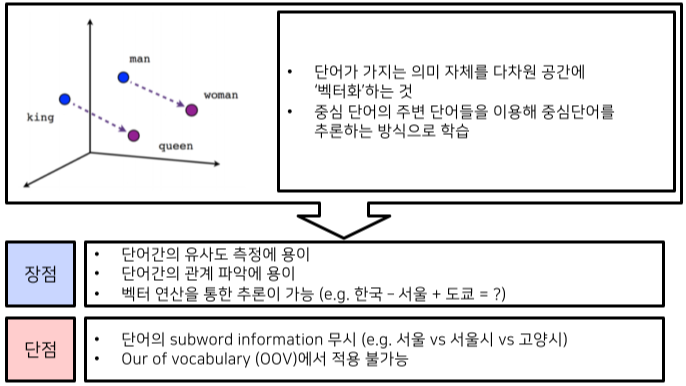
Word2Vec 알고리즘은 자연어의 의미를 벡터 공간에 임베딩하여, 단어의 의미를 포함
- 비슷한 의미의 단어는 비슷한 Word2Vec 벡터를 가진다.
- 예를 들어, ‘개’와 ‘고양이’는 ‘먹는다’ 보다 비슷한 벡터를 가진다.
subword information : 서울시는 서울을 포함하는 단어이다.
- Word2Vec은 이러한 것을 무시함
Out of Vocabulary(OOV) : 학습하지 않은 단어는 전혀 예측할 수 없음.
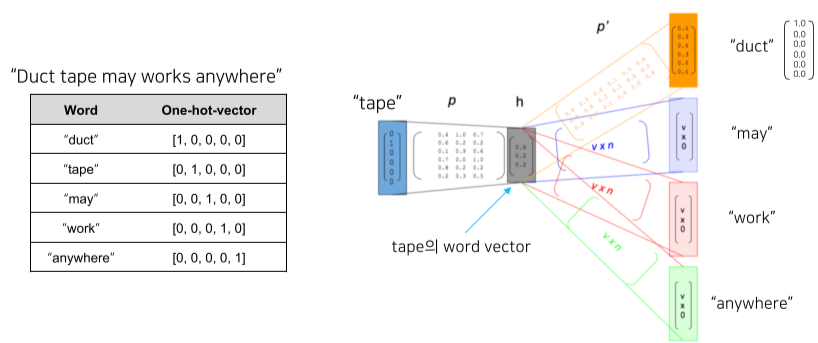
Skip-gram 방식이라는 주변부의 단어를 예측하는 방식으로 학습한다.

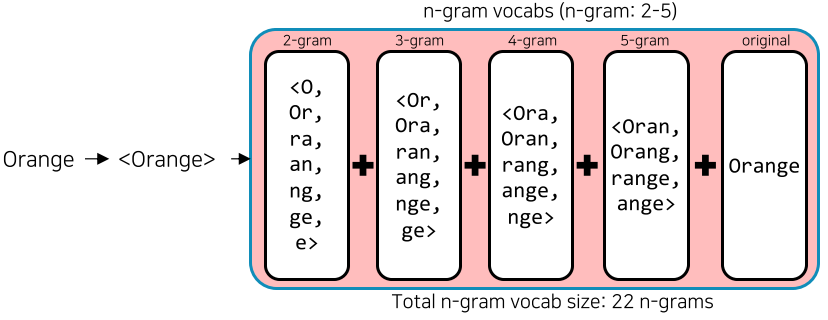
위의 단점을 보완하기 위해 FastText라는 새로운 임베딩 방법이 존재
- Facebook에서 공개, word2vec과 유사하나 단어를 n-gram으로 나누어 학습 수행
- n-gram 2-5일시, “assumption” = {as,ss,su, …, ass,ssu,sum, ump,…,assumption}
- 별도의 n-gram vector를 형성하며, 입력 단어가 vocabulary 사전에 있을 경우 word2vec과 비슷하게 return 하지만, OOV일 경우 n-gram vector 들의 합산을 return
FastText는 Word2Vec에 비해 오탈자, OOV, 등장 회수가 적은 학습 단어에 대해 강세
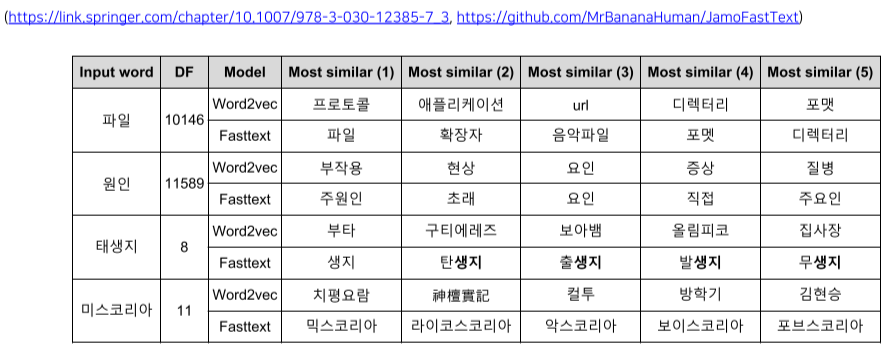
단, Word2Vec이나 FastText 같은 word embedding 방식은 동형어, 다의어 등에 대해서 embedding 성능이 좋지 못하며, 주변 단어를 통해 학습이 이루어지므로 문맥 고려가 불가능하다는 단점이 있다.
딥러닝 기반의 자연어 처리와 언어 모델
모델(model)이란, 어떤 상황이나 물체 등 연구 대상 주제를 도면이나 사진 등 화상을 사용하거나 수식이나 악보와 같은 기호를 사용하여 표현한 것.
- 일기예보 모델, 데이터 모델, 비즈니스 모델, 물리 모델 등이 존재
자연 법칙을 컴퓨터로 모사함으로써 시뮬레이션 가능, 미래의 state를 올바르게 예측하는 방식으로 모델 학습이 가능
Markove 기반의 언어 모델, 혹은 마코프 체인 모델(Markov Chain Model)은 초기 언어 모델로, 다음의 단어나 문장이 나올 확률을 통계와 단어의 n-gram을 기반으로 계산
최근의 딥러닝 기반의 언어 모델은 해당 확률을 최대로 하도록 네트워크를 학습하며, RNN (Recurrent Neural Network) 기반의 언어 모델이 그러하다.
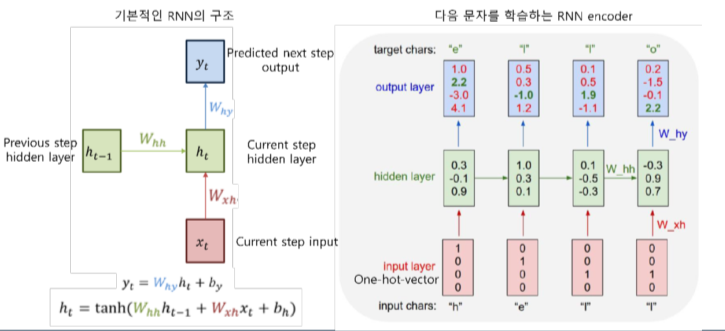
RNN은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이룸(directed cycle)
이전 state 정보가 다음 state를 예측하는데 사용됨으로써, 시계열 데이터 처리에 특화
마지막 출력은 앞선 단어들의 문맥을 고려해 만들어진 최종 출력 vector (Context vector라고 함)이며, 이 위에 classification layer를 붙이면 문장 분류를 위한 신경망 모델이 됨.
Seq2Seq(Sequence to Sequence)
RNN 구조를 통해 Context Vector를 획득하는 Encoder와 획득된 Context vector를 입력으로 출력을 예측하는 Decoder layer를 이용한 RNN 구조
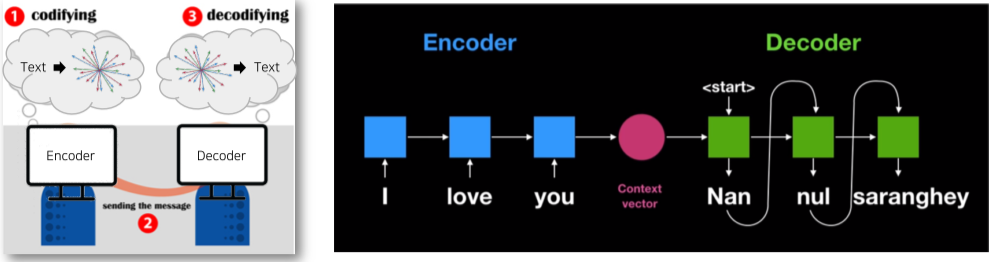
Seq2Seq 구조는 모든 자연어처리 task에 적용가능하다.
단, RNN의 경우 입력 sequence의 길이가 매우 길 경우, 앞단의 단어의 정보는 희석이 되며, 고정된 context vector 사이즈로 인해 긴 sequence에 대한 정보를 함축하기 어려움
또한, 모든 token이 영향을 미치니, 중요하지 않은 token 도 영향을 줌
이를 방지하기 위해 Attention이 개발됨
Attention
문맥에 따라 동적으로 할당되는 encode의 Attention weight로 인한 dynamic context vector를 획득
이를 통해 Seq2Seq의 encoder, decoder 성능을 비약적으로 향상시킴, 단 여전히 느림
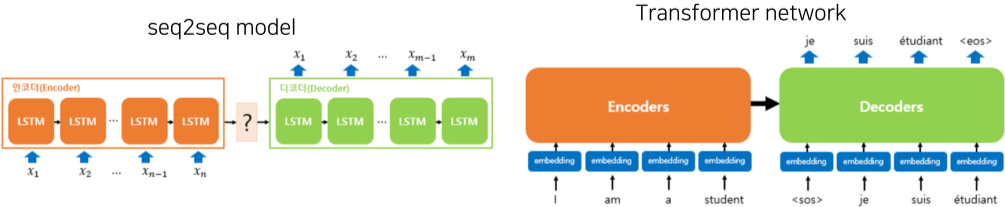
Self-attention 구조의 경우, hidden state가 순차적으로 RNN에 전해지는 것이 아니라 모든 RNN이 서로의 output에 영향을 주게끔 설계되어 더욱 빠르다.
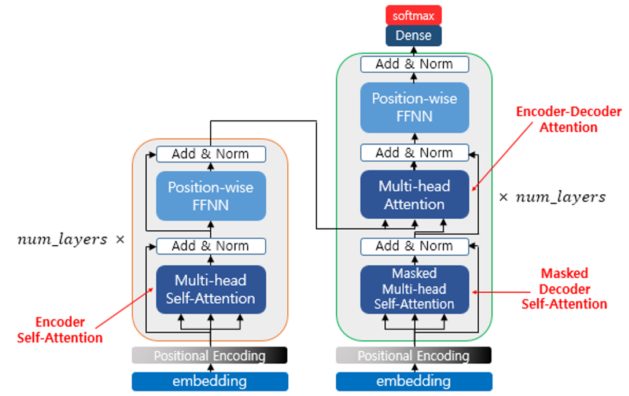
이를 응용한 구조가 Transformer 구조이며, 각자 따로 RNN 구조를 가지던 Seq2Seq model과 달리, 하나의 네트워크를 공유함.
이 Transformer 구조로 인해 다양한 구조와 언어 모델이 생성됨
02. 자연어 전처리
자연어 전처리
전처리 : 원시 데이터(raw data)를 기계 학습 모델이 학습하는데 적합하게 만드는 프로세스
Task의 성능을 확실하게 올릴 수 있는 방법
자연어 처리 Task 의 단계는 다음과 같다.
1. Task 설계
2. 필요 데이터 수집
3. 통계학적 분석 : 아웃라이어 제거(Token 너무 길거나 짧거나), 빈도 확인(사전(dictionary) 정의)
4. 전처리 : 개행문자, 특수문자, 공백, 중복 표현, 이메일, 링크, 제목, 불용어, 조사, 문장 분리 제거
5. Tagging : Lable 붙여주기
6. Tokenizing : 자연어를 어떤 단위로 살펴 볼 것인가? 어절? 형태소? WordPiece?
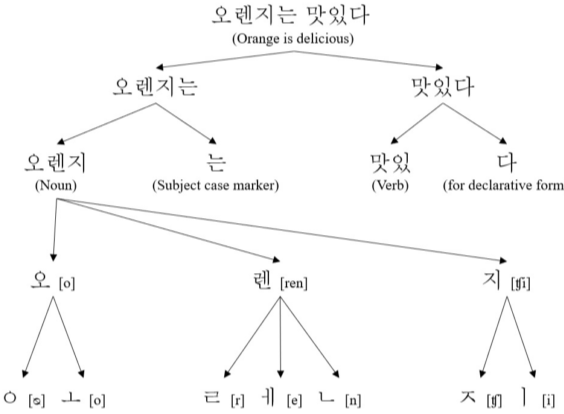
7. 모델 설계
8. 모델 구현
9. 성능 평가
10. 완료
Python의 upper, lower, strip, split 등의 string 관련 함수로 전처리를 쉽게 할 수 있다.
자연어 토크나이징
토큰화(Tokenizing)란?
주어진 데이터를 토큰(Token)이라 불리는 단위로 나누는 작업
토큰이 되는 기준은 어절, 단어, 형태소, 음절, 자소 등 다양할 수 있음
한국어 토큰화의 특징
영어는 합성어(New york)와 줄임말(It’s) 같은 예외를 제외하고, 띄어쓰기를 기준으로 토큰화하면 잘 작동한다.
하지만 한국어는 조사나 어미를 붙여 말을 만드는 교착어(ex)그, 그가, 그는, 그를)이므로 어절이 의미를 가지는 최소단위인 형태소로 분리함
ex) 안녕하세요 -> 안녕/NNG, 하/XSA, 세/EP, 요/EC
BERT 언어모델
BERT 언어모델 소개
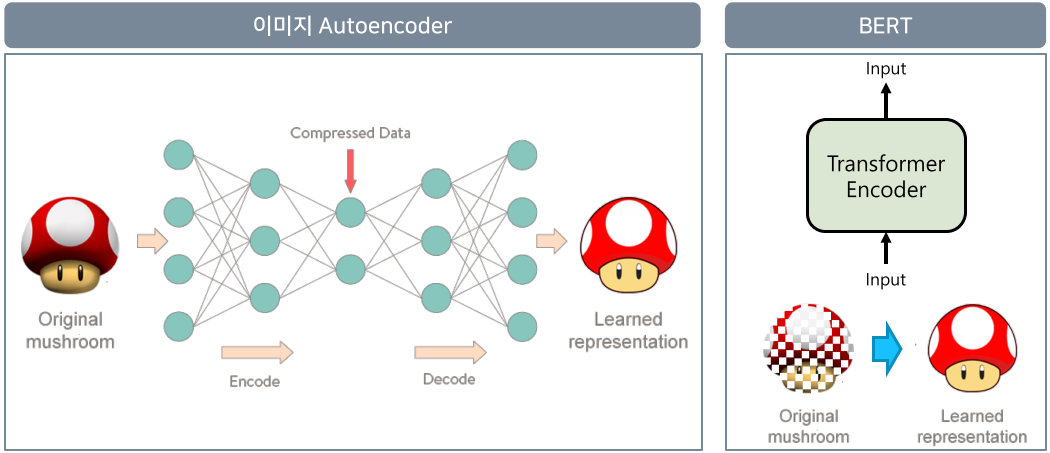
이미지에서 Autoencoder는 encoder단에서 이미지의 정보를 요약된 형태로 바꾼 뒤, Decoder를 통해 이미지의 대략적인 특징을 알 수 있게 복원한다.
이때 중간 layer의 Compressed Data 부분의 정보를 가져오면 이미지의 context vector 값(즉, 이미지의 대표 특징)을 알아볼 수 있다.
마찬가지로 BERT는 Transformer의 Encoder, Decoder 기능을 이용할 뿐만 아니라 기존의 Input 정보에 마스킹(Masking)을 추가하여 Decoder의 복원을 어렵게하여 더욱 학습이 잘되게 한다.
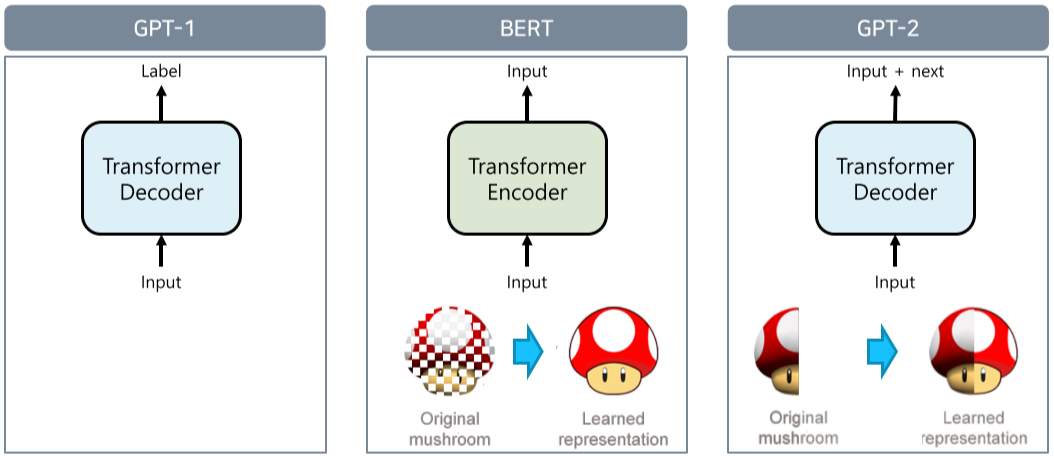
GPT-1이 평범한 Transformer을 이용하는 것을 시작으로 BERT, GPT-2는 마스킹 대신 언어의 일부를 자른 뒤, 나머지 부분을 복원하는 방식으로 진행된다.
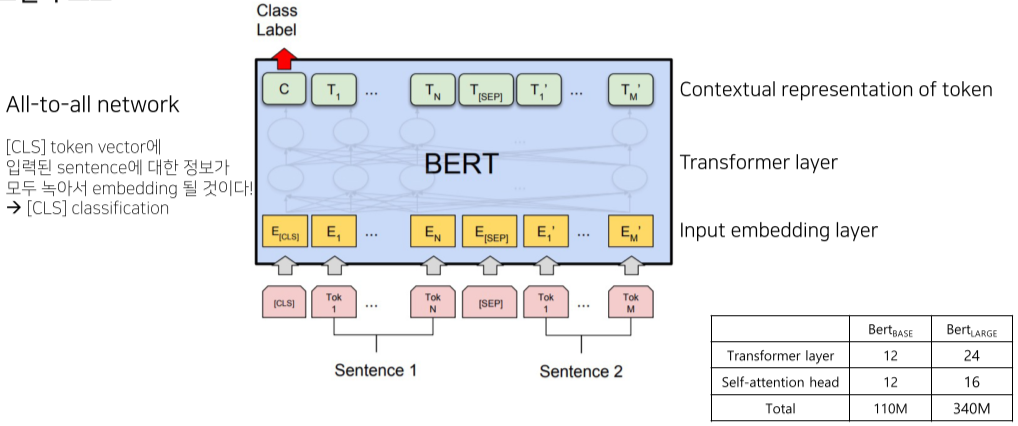
BERT 모델(Base의 경우)는 12개의 Transformer layer가 all-to-all로 연결된 형태이며, 이때 Input으로 2개의 문장이 <SEP> 토큰으로 구별된 채로 입력된다.
output으로 Class Label의 경우 BERT가 판단한, 두 문장의 관계(2문장은 1문장 다음에 올만한 문장인가? 아니면 관계없는 별개읜 문장인가?)를 판단한 Class Label이 있으며, 이렇게 나온 Vector들이 두 문장들의 특성을 잘 표현하는 벡터라고 판단하고 Classification layer을 얹어 Pretraining한다.
Corpus 양이 상당히 많으며, 빈도수를 기준으로 학습한다.(WordPiece tokenizing)
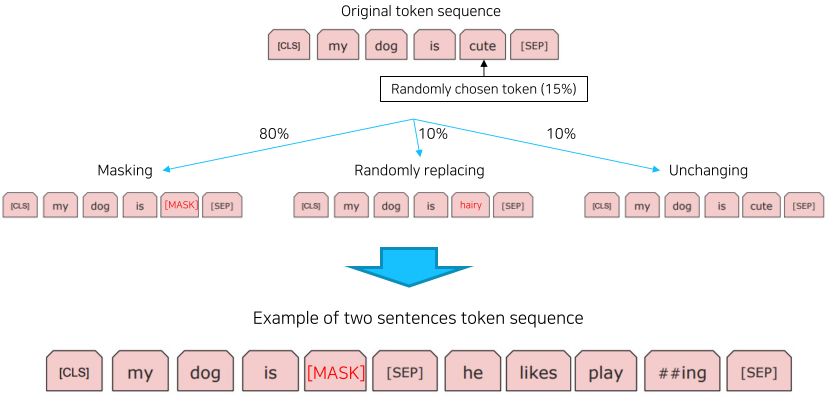
학습은 기존의 연결된 2문장을 절반의 확률로 랜덤한 다른 문장으로 바꿔 학습하며, 이때 15% 확률로 마스킹 또한 포함한다.
마스킹을 할때에는 또 80% 확률로 Mask 토큰, 10%로 랜덤한 단어로 변경, 10% 마스킹하지않는 것으로 진행된다.
다양한 실험으로 성능을 증명하였으며, 다음과 같다.

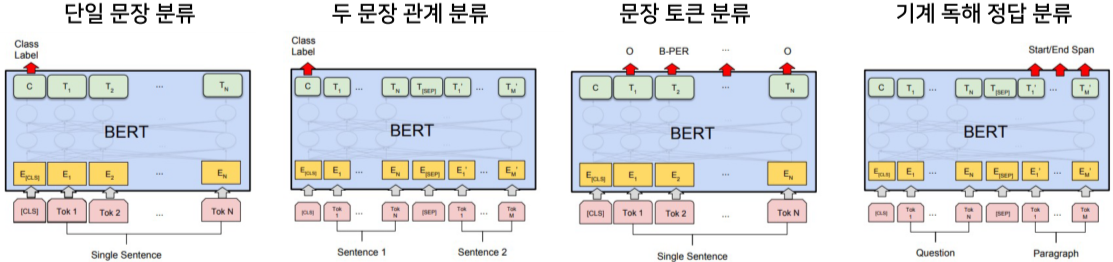
BERT의 구조를 조금 바꿈으로 여러가지 분류를 시행할 수 있다.
144개 국어를 커버할 수 있는 BERT Multi-lingual pretrained model로 많은 Task를 할 수 있다.
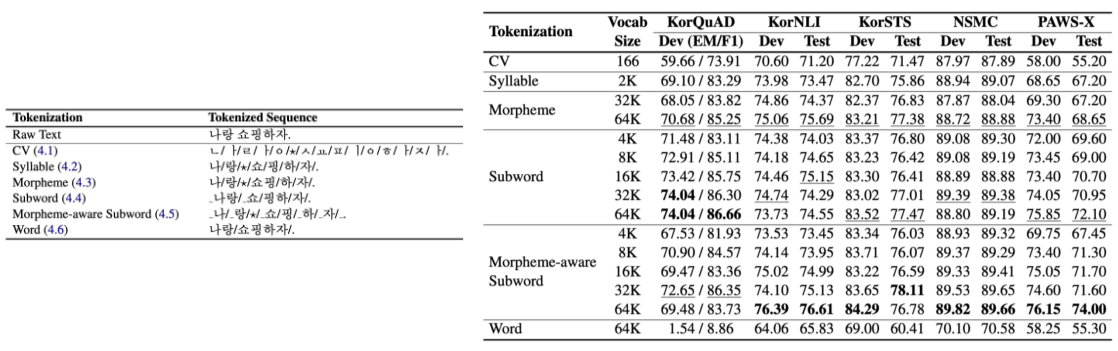
이때, Tokenizing 방식을 바꾸거나 Input에 토큰을 추가로 사용하는 방법으로 성능을 향상시킬 수 있으므로, 고민이 필요하다.
BERT Pre-Training
특정 도메인 특화 Task의 경우, PreTrained 모델을 재학습 시키면, 성능이 더욱 향상한다.
BERT의 학습 단계는 다음과 같다.
- Tokenizer 생성
- 데이터셋 확보 :
- 데이터셋 생성 : 데이터를 입력가능한 꼴로 바꾸는 것, 토큰 등의 삽입, 마스킹 등
- 데이터로더 생성: 입력방법을 결정
- 개인정보, 저작권 등을 유의해서 생성하자.
- Next sentence prediction(NSP)
- Masking
05. BERT 언어모델 기반의 단일 문장 분류
1. KLUE 데이터셋 소개
한국어 자연어 이해 벤치마크(Korean Language Understanding Evaluation, KLUE)
문장분류, 관계 추출, 문장 유사도, 자연어 추론, 개체명 인식, 품사 태깅, 질의 응답, 목적형 대화, 의존 구문 분석 등의 task 유형이 존재

이때, 의존 구문 분석은 단어들 사이의 관계를 분석하는 task 이다.
지배소는 의미의 중심이 되는 요소를 의미하며, 의존소는 지배소가 갖는 의미를 보완, 수식 해주는 요소이다.
어순과 생략이 자유로운 한국어와 같은 언어에서 주로 연구 된다.
지배소는 항상 의존소 보다 뒤에 있는 후위언어 이며, 지배소는 하나만 가지며, 교차 의존 구조(서로 지배 또는 의존하는 구조)는 없다.
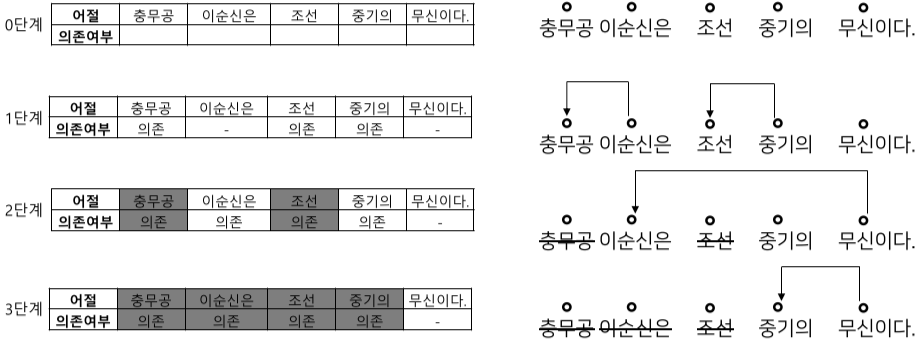
Sequence labeling 방식으로 처리 단계를 나눈다.
- 앞 어절에 의존소가 없고
- 다음 어절이 지배소인 어절을 삭제하는 방법으로 의존 관계를 생성
이를 통하여 자연어 형태를 그래프로 구조화해서 표현이 가능하며, 그 그래프를 통해 대상에 대한 정보 추출이 가능(누가 충무공인가? 이순신은 어디 사람인가?)
2. 단일 문장 분류 task 소개
주어진 문장이 어떤 종류의 범주에 속하는지를 구분하는 task
- 감정 분석(Sentiment Analysis), 2. 주제 라벨링(Topic Labeling), 언어감지(Language Detection), 의도 분류(Intent Classification) 등에 사용됨
구체적으로는 혐오 발언 분류, 기업 모니터링, 대용량 문서 분류, VoC, 번역기, 챗봇 등…
kor_hate : 한국의 혐오 표현에 대한 데이터셋
kor_sarcasm : 한국의 비꼰 표현의 데이터셋
kor_sae : 예/아니오로 답변 가능한 질문 중 금지, 요구 , 강한 요구, 육하원칙 분류
kor_3i4k : 평서문, 질문, 명령 등을 분류
3. 단일 문장 분류 모델 학습
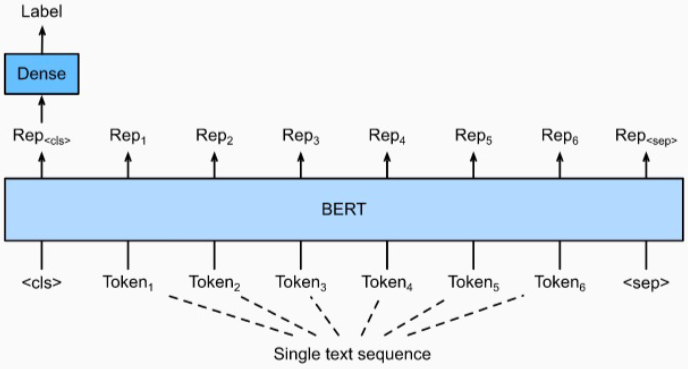
BERT의 [CLS] token의 vector를 classification 하는 Dense layer 사용

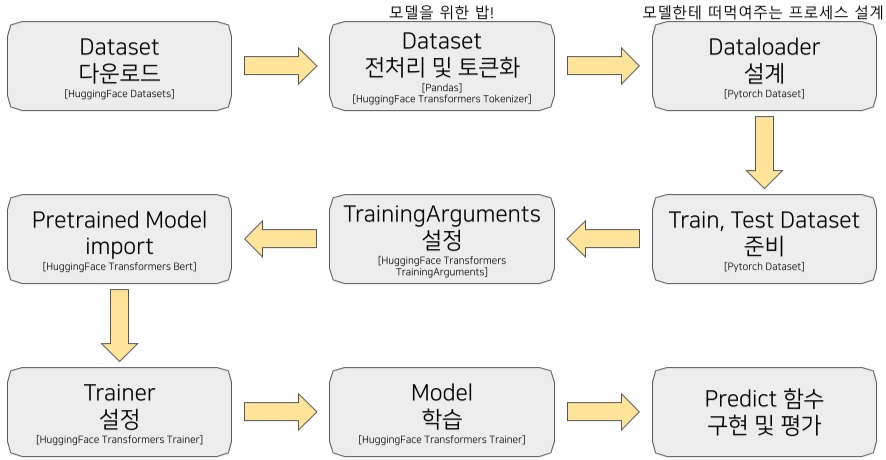
BERT 언어모델 기반의 두 문장 관계 분류
두 문장 관계 분류 task 소개
주어진 2개의 문장에 대해, 두 문장의 자연어 추론과 의미론적인 유사성을 측정하는 task
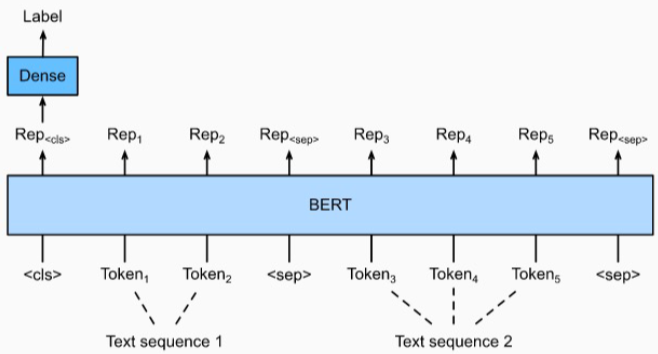
Natural Language Inference (NLI)
-
언어 모델이 자연어의 맥락을 이해할 수 있는지 검증하는 task
-
전제문장(Premise)과 가설문장(Hypothesis)을 Entailment(함의), Contradiction(모순), Neutral(중립)으로 분류
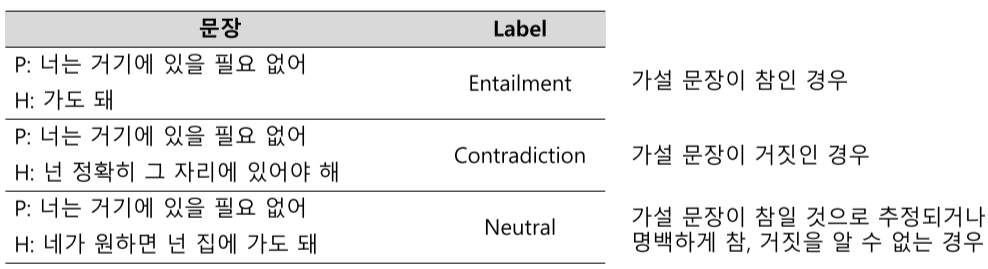
Semantic text pair
- 두 문장의 의미가 서로 같은 문장인지 검증하는 task
- ex) 무협 소설 추천 해주세요 != 판타지 소설 추천해주세요
- ex) Gmail과 네이버 메일 중 뭐 쓸래? == 두개 중에 골라줘 네이버랑 지메일
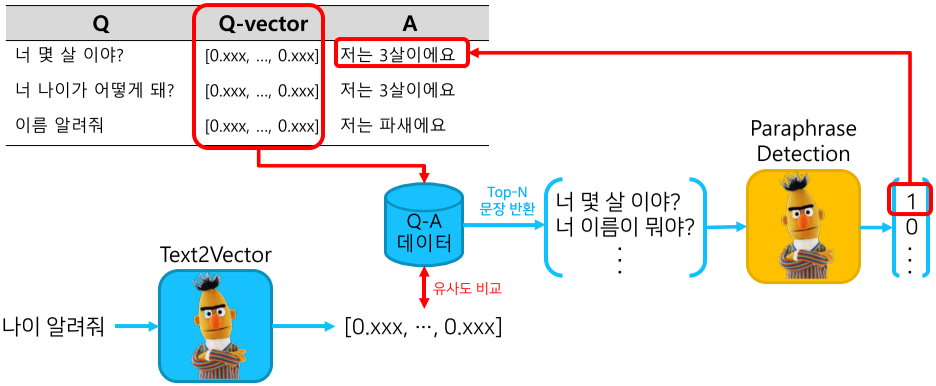
IRQA(Information Retrieval Question and Answering) 챗봇 시스템 구조
문장 토큰 분류
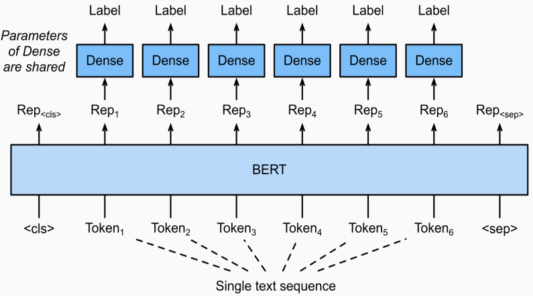
주어진 문장의 각 token이 어떤 범주에 속하는지 분류하는 task
Named Entity Recognition(NER, 개체명 인식)
개체명 인식은 문맥을 파악해서 인명, 기관명, 지명 등과 같은 문장 또는 문서에서 특정한 의미를 가지고 있는 단어 또는 어구(개체) 등을 인식하는 과정을 의미함.
동음이의어, 문맥 차이 등에 의해 문맥에 따라 개체명이 달라질 수 있음
Part-of-speech tagging (POS TAGGING, 품사 태깅)
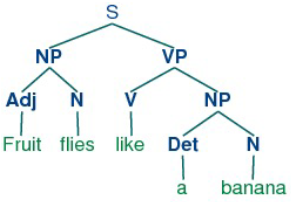
품사란 단어를 문법적 성질의 공통성에 따라 언어학자들이 몇 갈래로 묶어 놓은 것,
품사 태깅은 주어진 문장의 각 성분에 대하여 가장 알맞는 품사를 태깅하는 것
형태소 태깅 또한 POS Tagging임.
pororo library를 이용하면 한국어 Task를 쉽게 해결할 수 있음.
kor_ner

문장 토큰 분류를 위한 한국어 NER 데이터셋
한국해양대학교 자연어 처리 연구실에서 공개했으며, 일반적으로 pos tagging도 함께 존재

Entity tag는 [BIO] Tagging으로 이루어져 있으며 B는 개체명의 시작(Begin), I는 내부(Inside), O는 다루지 않는 개체명(Outside)을 의미함
ex) B-PER : 인물 개체명의 시작, I-PER : 인물명 개체명의 내부 분을 뜻함
BERT multilingual 모델 활용의 경우, WordPiece tokenizer가 잘못 판단할 수도 있으므로 음절단위로 tag를 매핑해주는 것을 추천(애시당초 음절단위로 학습했다고 함.)
GPT 언어 모델
Generation Pre-trained Transformer의 약자, Genereation 분야에 강점을 가지고 있음
BERT와 달리 단일 방향으로 주어진 단어 다음에 가장 올 확률이 높은 단어를 예측함.
Transformer의 Encoder를 활용한 BERT와 달리 Decoder를 활용함.
순차적으로 단어를 예측하여 문장을 생성
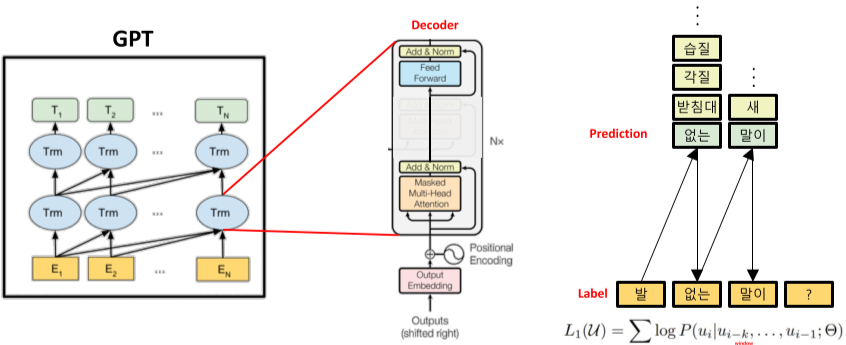
시기적으로 BERT보다 일찍 나왔으며, 기존의 문장의 Context vector를 생성하고 이를 통해 분류하는 성능이 뛰어남
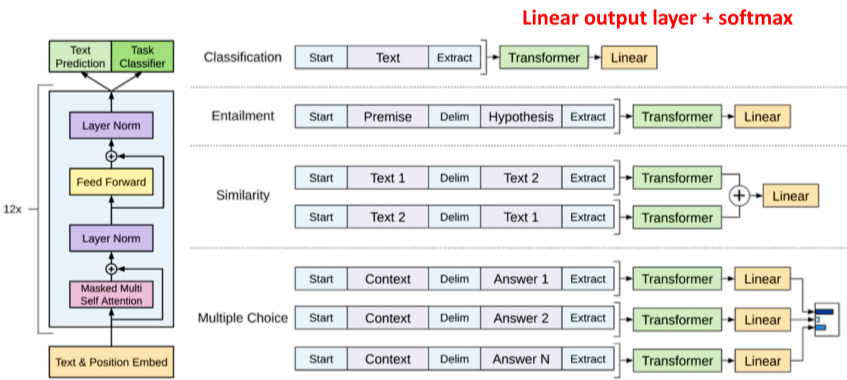
덕분에 적은 양의 데이터에서도 높은 분류 성능을 나타내며, 다양한 자연어 task에서 SOTA 달성, Pre-train 언어 모델의 새 지평을 엶
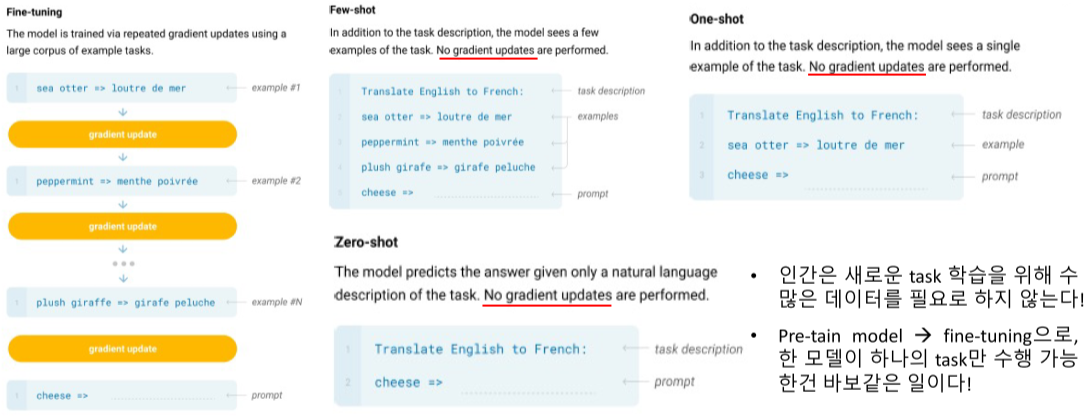
특정 task를 위해 fine-tuning된 모델은 다른 task에서 사용 불가, GPT는 이를 막기 위해 fine-tunnig을 하지 않아도 다중의 task를 수행할 수 있게 만들려 했다.
GPT2는 GPT1에서 조금의 decoder layer 변경과 커다란 parameter 수 증가의 차이를 가지며, 최신의 GPT3는 100배정도 데이터셋과 parameter 수를 늘렸으며, initializer와 구조를 조금 바꿨다.
Awesome GPT-3에서 성능확인 가능
Weight update가 없으므로, 새로운 지식에 대한 학습이 없으며, 시기에 따라 달라지는 문제, 최신의 정보가 필요한 문제는 대응 불가
즉, GPT-3에 사용한 데이터셋의 지식만 가지고 있음
모델 사이즈가 너무 크고, 멀티 모달 정보 활용이 필요함.
_articles/AI/NLP/한국어 언어 모델 다루기-KLUE.md