풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
자연어처리 기본
- Intro to Natural Language Processing(NLP)
- Recurrent Neural Networks(RNNs)
- Sequence to Sequence with Attention
- Tansformer
- Self-supervised Pre-training Models
자연어처리(Natural Language Processing, NLP) 기본
NAVER AI boost camp 수업을 정리한 내용입니다.
Intro to Natural Language Processing(NLP)
- 컴퓨터가 주어진 단어나 문장, 문단, 글을 이해하는 NLU(Natural Language Understading)
-
이런 한 글을 생성할 수 있는 NLG(Natural Language Generation)로 이루어짐
- NLP의 영역(ACL, EMNLP, NAACL 등에서 연구)
- 우리가 주로 다룰 분야
- Low-level parsing
- Tokenization: 문장을 이루는 각 단어를 정보 단위(Token)로 쪼개나가는 것
- stemming: 단어의 다양한 표현 변형을 없애고 의미만 남기는 것
- 맑고, 맑지만, 맑았는데, 맑은 = 맑다.
- word and phrase level
- Named entity recognition(NER) : 고유 명사 인식
- (Newyork times는 newyork + times가 아니다)
- part-of-speech(POS) tagging : 단어의 품사, 성분이 무엇인가?(명사, 목적어, 형용사 등)
- Named entity recognition(NER) : 고유 명사 인식
- Senetence level
- 문장의 감정분석, 기계번역
- Multi-sentence and paragraph level
- Entailment prediction : 두 문장의 모순관계, 논리적 내포를 확인
- 문장이 앞서 했던 말과 다른가?
- 질의 응답, 문서 요약
- dialog systems: 챗봇
- Entailment prediction : 두 문장의 모순관계, 논리적 내포를 확인
- Text mining의 영역(KDD, WSDM, WWW 등에서 연구중)
- 트랜드 분석, 상품 반응 분석, SNS 사회과학 분석 등
- Information retrieval(검색 기술)
- 많이 성숙해진 상태, 상대적으로 느림,
- 추천 시스템, 개인화 광고 등
NLP의 트랜드
- 문장의 단어들을 vector로 표현하여 그래프 내의 점으로 바꾸어 처리하게 됨(Word Embedding).
- 자연어 처리에서 RNN 모델을 위한 LSTM, GRU 유닛이 사용되다 최근 구글의 attention module과 Transformer model의 발표로 성능이 크게 늘어남.
- 더이상 rule base 기계 번역은 딥러닝 base 기계번역에 성능으로 뒤쳐지고 있음.
- 최근에는 자가 지도 학습 또는 pretrained model을 통하여 더 이상 labeling이 필요하지 않은 BERT, GPT-3 같은 기술이 나타남.
- 다만 이러한 기술들은 대규모의 컴퓨팅 능력과 데이터가 필요함.
Bag-of-Words and NaiveBayes Classifier
- Bag-of-Words는 딥러닝 기반 이전 시대 때, 단어와 문서를 숫자형태로 나타내는 표현 기법
- NaiveBayes Classifier : Bag-of-Words 방식을 이용한 전통적인 문서 분류 기법
Bag-of-Words Representation
-
Bag-of-Words의 과정
- 주어진 문장의 단어가 각각 포함되어있는 사전(vocabulary) 생성
- “Jon really really loves this movie”, “Jane really likes this song”에서
- Vocabulary: {“John”, “really”, “loves”, “this”,”movie”,”Jane”,”likes”,”song”} 생성
- 사전에 포함된 유일한 단어들을 one-hot vector로 인코딩
- Vocabulary: {“John”, “really”, “loves”, “this”,”movie”,”Jane”,”likes”,”song”}
- 차례대로 one-hot vector 형식으로 인코딩
- 예를 들어 John:[1 0 0 0 0 0 0 0], really: [0 1 0 0 0 0 0 0] … song: [0 0 0 0 0 0 0 1]
- word- embedding 방법과의 차이점
- 모든 vector쌍의 거리는 $\sqrt 2$, cosine similarity 는 0으로 계산된다.
- 주어진 문장의 단어가 각각 포함되어있는 사전(vocabulary) 생성
-
이렇게 구성된 문장이나 단어는 one-hot vector들의 합으로 표현할 수 있다.
- 예시 1. “John really really loves this movie”
- John + really + really + loves + this + movie: [1 2 1 1 1 0 0 0]
- 예시 2. “Jane really likes this song”
- Jane + really + likes + this + song: [0 1 0 1 0 1 1 1]
- 예시 1. “John really really loves this movie”
NaiveBayes Classifier for Document Classification
- NaiveBayes Classifier란, Bag of words 방법으로 표현된 문서를 구분할 수 있는 전통적인 방법
- d개의 문서와 C의 문서분류 집합이 있다고 가정하고, c 분류는 C 문서분류 집합의 원소일 때, 각각의 클래스에 d문서가 속할 확률 분포는 아래와 같이 표현된다.
[math. Bayers’ Rule Applied to Documents and Classes ]
-
P(d)는 d document가 뽑힐 확률 이며, 고정된 값으로 볼 수 있어서 무시할 수 있음
-
단어들 w로 이루어진 c 분류의 d 문서에서 특정 분류 c가 고정일 때, 문서 d가 나타날 확률은
-
$P(d c)P(c) = P(w1,w2,\dots,w_n c)P(c)\rightarrow P(c)\prod_{w_i\in W}P(w_i c)$ - 각 단어(w~1~,w~2~,…,w~n~)가 나타날 확률을 독립적이라고 가정
-
NaiveBayes 분류 예시
| Doc(d) | Document(words, w) | Class(c) | |
|---|---|---|---|
| Training | 1 | Image recognition uses convolutional neural networks | CV |
| 2 | Transformer can be use for image classification task | CV | |
| 3 | Language modeling uses transformer | NLP | |
| 4 | Document classification task is language task | NLP | |
| Test | 5 | Classification task uses transformer | ? |
[fig. NaiveBayes 예시]
- 위 표의 상황에서 class의 속할 확률은
- $P(c_{cv})=\frac{2}{4}=\frac{1}{2}$
- $P(c_{NLP}) = \frac {2}{4}=\frac {1}{2}$
- 이며, 이때 각 단어가 나타날 확률은
-
$P(w_k c_i)=\frac {n_k}{n}$, where n~k~ is occurreneces of w~k~ in documents of topic c~i~
| Word | Prob | Word | Prob | ||
|---|---|---|---|---|---|
| $P(w_{“classification”} | c_{CV})$ | $\frac {1}{14}$ | $P(w_{“classification”} | c_{NLP})$ | $\frac {1}{10}$ |
| $P(w_{“task”} | c_{CV})$ | $\frac {1}{14}$ | $P(w_{“task”} | c_{NLP})$ | $\frac {2}{10}$ |
| $P(w_{“uses”} | c_{CV})$ | $\frac {1}{14}$ | $P(w_{“uses”} | c_{NLP})$ | $\frac {1}{10}$ |
| $P(w_{“transformer”} | c_{CV})$ | $\frac {1}{14}$ | $P(w_{“transformer”} | c_{NLP})$ | $\frac {1}{10}$ |
[fig. 각 단어가 class 내에 나타날 확률들]
- document d~5~=”Classification task uses transformer”를 통하여 class에 속할 확률을 구해보면
-
$P(c_{CV} d_5)=P(c_{CV})\prod_{w\in W}P(w c_{CV})=\frac{1}{2}\times \frac{1}{14}\times \frac{1}{14}\times \frac{1}{14}\times \frac{1}{14}\times = 0.000013$ -
$P(c_{NLP} d_5)=P(c_{NLP})\prod_{w\in W}P(w c_{NLP})=\frac{1}{2}\times \frac{1}{10}\times \frac{2}{10}\times \frac{1}{10}\times \frac{1}{10} = 0.0001$
-
- 여기서 가장 높은 확률인 분류를 뽑아 확정하게 된다(argmax).
- 다만 학습 데이터에 없는 단어가 포함될 경우 다른 단어들이 있더라도 확률이 0이 되버리므로 regularization 같은 다른 방법을 강구해야함.
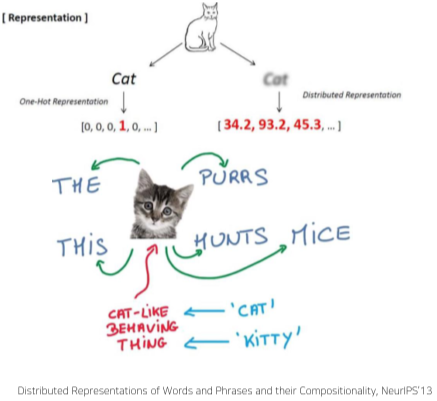
Word Embedding: Word2Vec, GloVe
- Word2Vec과 GloVe는 하나의 차원에 단어의 모든 의미를 표현하는 one-hot-encoding과 달리 단어의 distributed representation을 학습하고자 고안된 모델.
- 문장을 단어라는 단위 정보로 이루어진 sequence data라고 가정했을 때, 각 단어들을 공간상의 한 점이나 벡터로 표현하는 기술을 Word Embedding이라고 한다.
- 예를 들어 cat과 kitty는 비슷한 의미를 가지므로 비슷한 좌표값이나 벡터를 가지고 있겠지만, hamburger는 전혀 다른 좌표나 벡터에 있을 것이다.
Word2Vec
[img. Word2Vec 의 예시]
- 같은 문장에 자주 포함되는 단어들은 관련성이 많다는 가정 하에 Word Embedding을 진행하는 알고리즘
- 예를 들어 “The furry cat hunts mice.” 에서 cat은 furry하고 mice를 hunts 하므로 연관이 있다.
- 문장 내의 단어 w가 나타날 때, 그 주위에 각각의 단어가 나타날 확률분포를 구하여 이용한다.
- Skipgram 방법과 CBOW 방법 두가지로 나뉨 (실습 2_word2vec.ipynb) 참조
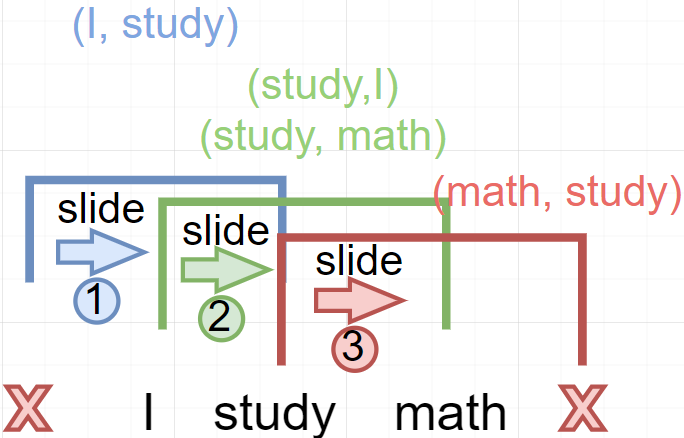
Word2Vec Algorithm과 예제
- 주어진 문장을 Tokenization한 후, 사전(Vocabulary) 생성하고 단어별 one-hot 벡터 생성
- Sentence: “I study math.”
- Vocabulary: {“I”, “study”, “math”}
- Input: “study” [0, 1, 0]
- Output: “math” [0, 0, 1]
- Sliding Window 기법을 이용해 앞 뒤로 나타난 단어들의 쌍들로 학습 데이터 구성.
[img. Window size가 1인 Sliding Window 기법의 그림]
-
2 layer 구성의 심층 신경망을 통해 word embedding 한다.
-
Input layer, output layer 차원 수 : vocabulary 단어 수(one-hot vector 차원)
-
hidden layer 차원 수 : hyper parameter(word embedding 차원 수)
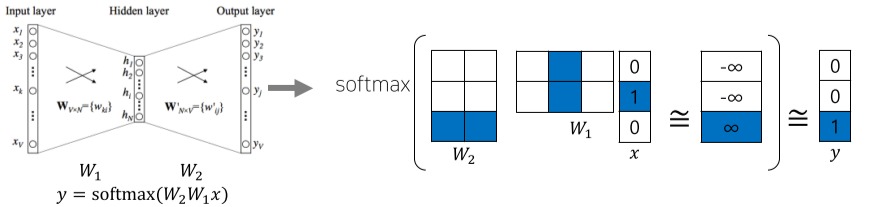
[img. 2 layer 신경망의 word embedding 원리]
- input vector “study”의 경우, [0,1,0]의 벡터를 가지고 있으며, hidden layer의 차원수가 2라고 가정할 때.
- linear transform matrix W~1~의 경우 3차원의 벡터를 2차원의 벡터로 바꿔야 하므로 2X3 차원을 가진다.
- W~1~의 input vector가 one-hot vector 이므로 내적을 구하기 보단 one-hot vector의 인덱스에 해당하는 W~1~의 Column을 가져오는 형식으로 계산한다.
- linear transform matrix W~2~의 경우 다시 3차원의 벡터를 가져야 하므로 3X2 차원을 가진다.
- softmax 함수를 통과시키기 전의 이상적인 logic값은 ground-truth의 내적값은 $\infin$, 그 이외의 내적 값은 $-\infin$이 되어야 결과값도 one-hot vector의 형태로 나온다.
-
-
softmax 함수를 통과시켜 word embedding 값을 가져온다.
- 이를 통하여 의미론적 관점에서 단어간의 유사도를 알 수 있는 word vector를 구할 수 있다.
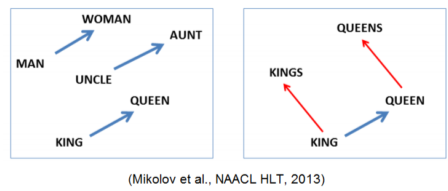
[img. 단어 간의 관계가 비슷하면 두 단어의 벡터의 방향도 유사하다.]
- https://ronxin.github.io/wevi/ 에서 Word2Vec을 시연해볼 수 있다.
- https://word2vec.kr/search/ 에서 한국어 Word2Vec 결과값을 알아볼 수 있다.
- Word2Vec으로 문맥에 어색한 단어를 찾아내는 Intrusion Detection 또한 가능하다.
- Word2Vec을 이용해 다음과 같은 분야에 활용해 성능을 향상시킬 수 있다.
- 기계번역
- PoS tagging
- 고유명사 태깅
- 감정 분석
- Image Captioning
- 기타 등등
GloVe: Another Word Embedding Model
-
Global Vectors for Word Representation
- Word2Vec과 함께 많이 쓰이는 Word Embedding 방법
- 카운트 기반 방법론(LSA)과 예측 기반의 방법론(Word2Vec) 두 가지를 모두 사용하는 방법론
- (입력어의 임베딩 벡터와 출력어의 임베딩 벡터의 내적값)과 (윈도우에서 두 단어 i, j의 동시 출연 빈도에 log를 씌운 것)을 loss 함수로써 fitting하여 word embedding 값을 구하는 방식
- $u_i$: 입력어의 임베딩 벡터, $v_j$: 출력어의 임베딩 벡터, $P_{ij}$: 윈도우 기반 두 단어 i, j의 동시 등장 빈도
[math. GloVe의 손실함수]
- 윈도우 기반 동시 등장 빈도($P_{ij}$)는 전체 단어 집합 들의 단어들이 윈도우 크기 내에서 단어가 등장한 횟수를 의미하며, 보통 전체 단어들의 등장 빈도를 행렬로 다음과 같이 표현한다.
- “I like deep learning”, “I like NLP”, “I enjoy flying” 세 문장이 주어지고 윈도우 크기가 1일 때,
| 카운트 | I | like | enjoy | deep | learning | NLP | flying |
|---|---|---|---|---|---|---|---|
| I | 0 | 2 | 1 | 0 | 0 | 0 | 0 |
| like | 2 | 0 | 0 | 1 | 0 | 1 | 0 |
| enjoy | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| deep | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| learning | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| NLP | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| flying | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
[fig. 예제의 윈도우 기반 동시 등장 행렬(Window based Co-occurrence Matrix) https://wikidocs.net/22885]
- 중복 되는 계산이 적어 상대적으로 빠를 수 있고, 적은 데이터로도 성능이 좋다.(실제 성능은 비등비등)
- https://nlp.stanford.edu/projects/glove/ 오픈소스 glove 모델
Recurrent Neural Networks(RNNs)
Basics of Recurrent Neural Networks(RNNs)
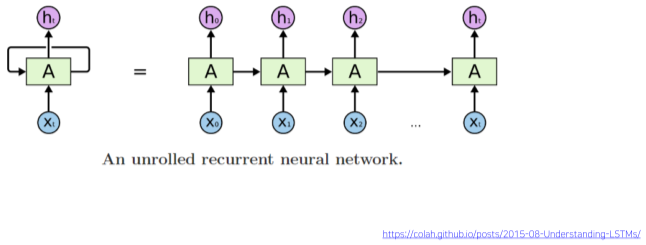
[img. RNN의 구조, 좌측은 Rolled RNN, 우측은 UnRolled RNN이다.]
-
Sequence 입력 벡터 X과 이전 time step의 RNN 모듈에서 계산한 $h_{t-1}$을 입력으로 받아, 현재의 $h_t$를 출력하는 구조.
수식과 구조 구성 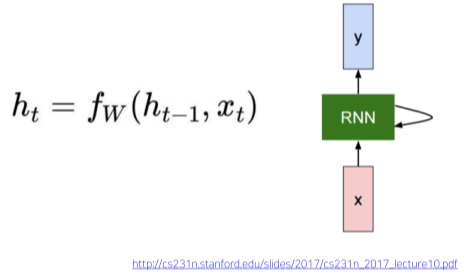
\(h_{t-1}:\ 이전\ hidden-state\ vector\\x_t:\ 해당 모듈의\ input\ vector\\h_t:\ 생성된\ hidden-sate\ vector\\\cdot 최종\ output(y_t)\ 출력시\ h_t를\ 바탕으로 계산 \\f_W:\ 파라미터\ W를\ 포함한\ RNN 함수\\y_t:\ 해당\ 모듈의\ output\ vecotr\) [fig. RNN에서의 hidden state 계산과 구성 요소]
-
매 time step 마다 같은 함수와 Parameter 구성을 공유함
[math. RNN의 자세한 $f_W$함수]
-
Hidden State Vector($h_t$)의 차원수는 Hyper parameter이다.
- 즉, 개발자 판단하에 주어져야 함.
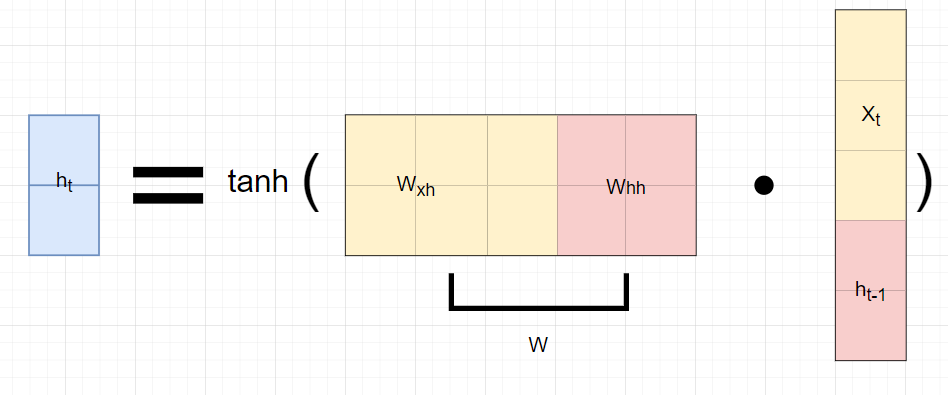
[img. $W$의 차원 수는 $h_{t-1}$ 차원수 X ($h_{t-1}$ 차원수 + $x_t$ 차원수)가 된다.] -
마지막으로 output $y_t$의 경우 binary classification이면 1차원으로 바꾼 뒤 sigmoid 함수를 이용하며, Multi Class classification이면 n개의 차원으로 바꾼 뒤 SoftMax Layer를 통과 시킨다.
Types of RNNs
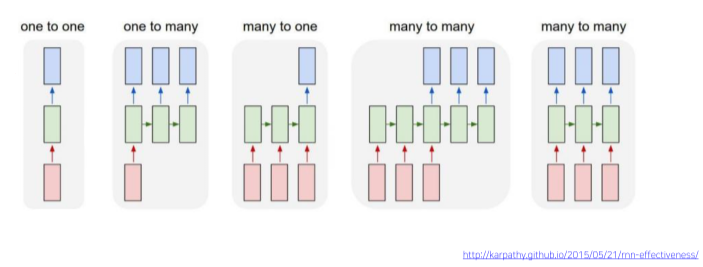
[img. 여러 종류의 RNN 구조]
-
one-to-one 구조
- 키, 몸무게, 나이를 통해 저혈압, 정상혈압, 고혈압을 판단
- Time Step이 존재하지 않음
-
one-to-many 구조
- Input이 첫 time step에 한번, 출력은 매번,
- 나머지 Input은 무의미한 같은 차원의 zero vector가 들어간다.
- Image Captioning
-
many-to-one 구조
-
Input은 매번, Output은 마지막 한번
-
감정 분석
-
-
sequence-to-sequence 구조 1
- Input이 일부 time step에, output이 또 일부 time step에 존재
- 기계번역
-
sequence-to-sequence 구조 2
- Input과 Output이 매번 존재
- video classification per frame
Character-level Language Model
- Language Model이란, 문자열이나 단어를 입력받고, 그 다음에 나올 문자나 단어를 출력하는 모델
RNN 예시(hello Language Model)
- 사전(Vocabulary) 구축 및 one-hot vector 생성
- 사전(Vocabulary)
- 주어진 문장에서 정보 단위(단어 또는 여기서는 글자)들이 유일하게 이루어진 사전을 구축한다.
- 예시의 “hello”의 경우 “[h, e, l, o]”라는 Vocabulary가 구축됨.
- one-hot vector 생성
- index 부분이 1인 사전의 갯수 만큼의 dimension을 가지는 one-hot vector 생성
- 마지막 “o”의 경우 그 뒤로 예측해야할 필요 없으므로 생성하지 않아도 좋다.
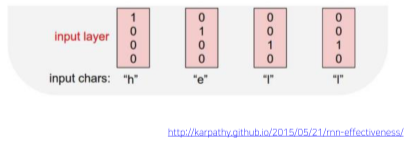
[img. hello의 one-hot vector]
-
선형결합과 비선형 함수 tanh를 이용한 $h_t$ 학습
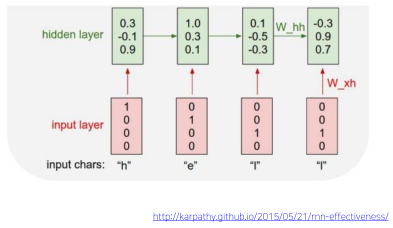
[img. $h_t$의 dimension이 3이라고 가정하고 학습]
- $h_t=tanh(W_{hh}h_{t-1}+W_{xh}x_t+b)$ b: bias
- 최초의 RNN 모델의 경우 $h_{t-1}$입력이 없으므로 h와 같은 차원의 zero vector를 채워준다.
- 자세한 방법은 위의 RNN의 구조 참조
-
output 출력
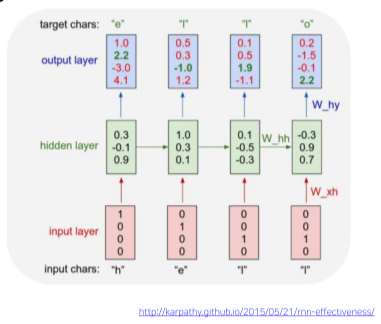
[img. output vector 출력]
- 각 RNN 모듈의 output은 hidden state($h_t$)에 $W_{hy}$를 곱한 후 bias를 더해서 구하게 된다.
- $Logit = W_{hy}h_t+b$
- 이후 Output을 softmax 함수에 통과 시켜 가장 큰 값을 결과값으로 확정한다.
- 이후 ground-truth(실제 값)의 one-hot vector와 비교하여 loss를 줄이는 방향으로 학습시킨다.
-
학습이 끝난 뒤 Test inference 시행
-
최초의 Time step에만 입력을 넣어주고, 이후 Time step 부터는 이전 모듈의 output을 Input으로 넣어주어 추론한다.
-
다음날 주식을 예측하는 RNN 모델이 그 다음날, 다음 다음날에도 예측 가능한 이유
-
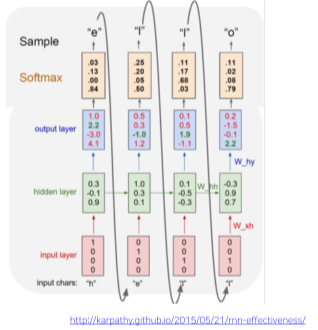
[img. 출력을 다음 모듈의 input으로 넣어주는 Inference 구조]
RNN 예제

[img. 셰익스피어 희곡 생성]

[img. 영화 대본 생성]

[img. C언어 code 생성]
Backpropagation through time (BPTT)
- 모든 RNN Time step에 대해 Backpropagtion 또는 ForwardPropagtion을 진행하는 것은 성능상 한계가 있다.
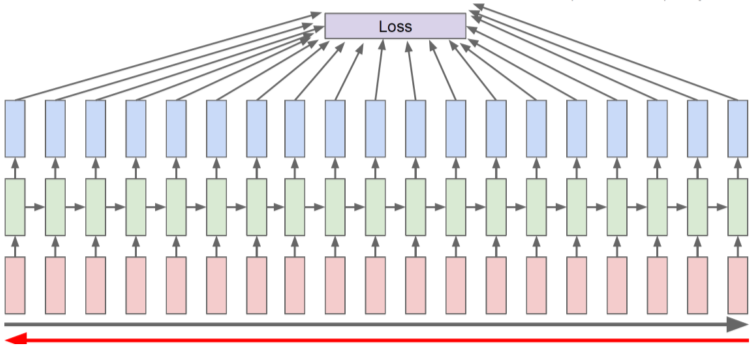
[img. RNN에서의 Forward와 backpropagation]
- Truncation : 전체를 propagation 하면 너무 느리므로 구간 별(chunks of the sequence)로 잘라서 한다.
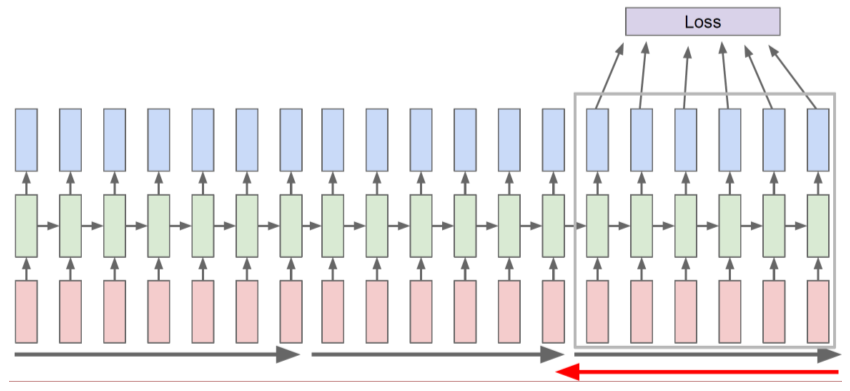
[img. Truncation : 구간별로 잘라서 propagation]
- Hidden state Vector($h_t$)는 이전 처리 결과, 문맥 등의 필요한 정보를 포함하고 있다.
- 이러한 Hidden State Vector의 변화를 분석하는 것으로 RNN의 특성을 알 수 있다.

[img. Hidden state의 변화를 시각화한 것.]
Vanishing/Exploding Gradient Problem in RNN
- RNN에는 Long-term problem과 Vanishing/Exploding Gradient Problem을 가지고 있다.
- 가중치가 계속 곱해져서 Gradient가 기하급수적으로 커지거나 작아지는 문제
| math | propagation |
|---|---|
| $h_t = tanh(w_{xh}x_t+w_{hh}h_{t-1}+b), t=1,2,3\For\ w_{hh}=3,w_{xh}=2,b=1\h_3=tanh(2x_3+3h_2+1)\h_2=tanh(2x_2+3h_1+1)\h_1=tanh(2x_1+3h_0+1)\\dots\h3=tanh(2x_3+3tanh(2x_2+3h_1+1)+1)$ | 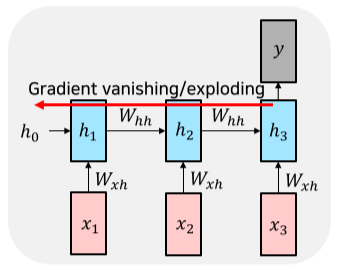 |
[fig. hidden state 중첩에 따른 $W_{hh}$의 중첩 ]

[gif. LSTM과 RNN의 cell 진행에 따른 gradient 감소 비교]
Long Short-Term Memory(LSTM) and Gated Recurrent Unit(GRU)
- 기존의 RNN 모델에 비해 Vanishing/Exploding gradient 문제를 해결하고, 성능 상에 더 좋은 결과를 보인다.
Long Short-Term Memory(LSTM)
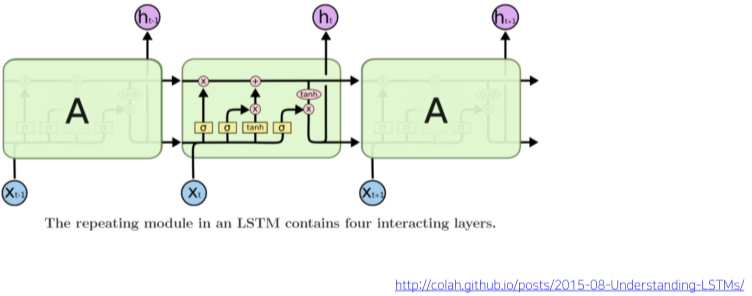 \
\
[img. LSTM 구조의 도식화]
- 정보를 좀 더 오래 남기게 하고 기존의 RNN 모델을 개선한 모델.
- Vanishing/Exploding Gradient Problem, Long-Term dependency 문제를 해결한 모델
- Hidden state vector($h_t$)를 기억 소자로 보고, 단기 기억을 길게 기억하도록 개선하여 LSTM이라고 이름 붙임.
- 이전 Time step에서 넘어오는 정보(Cell state($C_t$), Hidden state($h_{t-1}$) )가 2개이며, 총 Input은 3개이다.
- ${C_t, h_t}= LSTM(x_t,C_{t-1},h_{t-1})$
- $C_t$ : Cell state vector, 핵심 정보
- $h_{t-1}$: Hidden state vector, Cell state 정보를 필요한 것만 Filtering 한 정보.
Long short Term Memory의 구성과 동작 과정
- 입력을 받은 후 선형 변환 후 나온 결과물에 4개의 activation 함수를 통과 시켜 gate값들을 만든다.
- 이렇게 나온 gate 들은 Cell state 및 Hidden State를 계산할 때의 중간 결과물 역할을 한다.
| LSTM 구성 | 수식 |
|---|---|
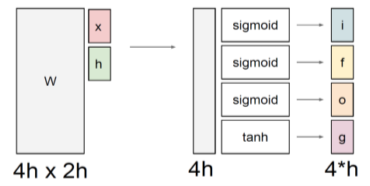 |
$\begin{pmatrix}i \f\o\g \end{pmatrix}=\begin{pmatrix}\sigma \\sigma\\sigma\tanh \end{pmatrix}W\begin{pmatrix}h_{t-1}\x_t\end{pmatrix}\c_t=f\odot c_{t-1}+i\odot g\h_t=o\odot tanh(c_t)$ |
[fig. LSTM 내부의 연산, $x_t, h_t$의 dimension을 h라고 가정]
- i: Input gate, Whether to write to cell
- f: Forget gate, Whether to erase cell
- o: Output gate, How much to reveal cell
- sigmoid를 통해 나오는 Input gate, Forget gate, Output gate는 0~1사이를 가지며 다른 벡터와 곱해져 0~1 사이의 일부로 축소해주는 역할을 함(gate)
- g: Gate gate, How much to write to cell
Gate 들의 구체적인 예시
- gate들은 이전의 $c_{t-1}$을 적절하게 가공하는 역할을 함
- Forget gate
| 수식 | 도식 |
|---|---|
| $f_t=\sigma(W_f \cdot [h_{t-1},x_t]+b_f)$ | 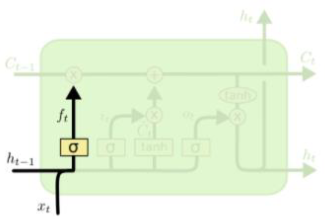 |
[fig. forget gate 수식과 그림]
- forget gate는 sigmoid 함수를 통해 $h_{t-1}$과 $x_t$의 일부 데이터를 축소하는 역할
- Gate gate & Input gate
| 수식 | 도식 |
|---|---|
| $i_t=\sigma(W_i\cdot [h_{t-1},x_t]+bi)\ (input\ gate) \\widetilde{C_t}=tanh(W_c\cdot [h_{t-1},x_t]+b_C)\ (gate\ gate)\C_t=f_t\cdot C_{t-1}+i_t\cdot \widetilde{C_t}\ (input\ gate \times gate\ gate)$ | 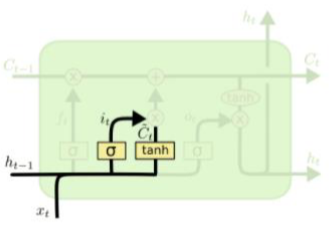 |
[fig. Input gate와 Gate gate의 수식과 그림]
- Input gate와 Gate gate의 결과물을 곱한 뒤, 해당 결과물을 Forget gate와 이전 Cell state를 곱한 것을 더하여 현재의 Cell state를 만들게 된다.
- 2번의 선형변환를 거친 현재 입력정보($h_{t-1}, x_t$)를 이전 Cell state와 합쳐 새로운 state를 만드다는 의미이다.
- Output gate
| 수식 | 도식 |
|---|---|
| $o_t=\sigma(W_o[h_{t-1},x_t]+b_o) \ h_t=o_t\cdot tanh(C_t)$ | 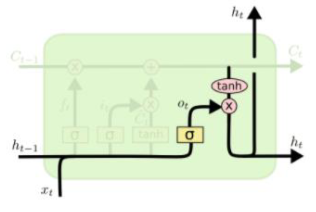 |
[fig. Output gate의 수식과 그림]
- 생성한 Output gate의 결과를 tanh함수를 통과시켜, 현재 필요한 정보만 filtering한 뒤, 현재 Cell state와 곱하여 Hidden state를 만든다.
- tanh 함수를 미분할 시 미분값이 sigmoid에 비해 커서 vanishing/exploding gradient problem을 해결할 수 있다.
Gated Recurrent Unit(GRU)
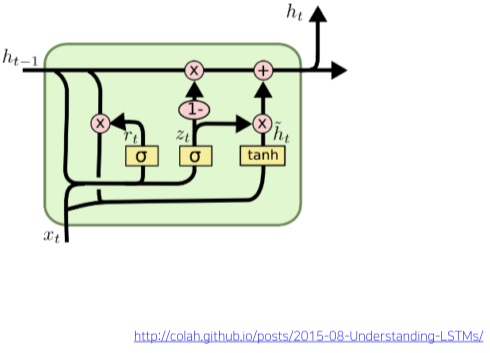
[img. GRU 구조]
- LSTM을 간소화하여 더욱 적은 메모리 요구량과 빠른 계산 시간을 가능하게 한 모델
- LSTM과 달리 Cell state가 존재 하지 않고, hidden state 벡터 하나만 다음 Time step으로 보낸다.
-
LSTM과 더불어 많이 사용되며 성능상 뒤지지 않으면서 빠르게 계산이 가능하다.
- GRU의 $h_{t-1}$이 LSTM의 Cell state 이전 time step 들의 정보와 결과값을 함께 포함한다.
- $z_t=\sigma(W_z\cdot [h_{t-1},x_t])$ (Input gate)
- $r_t=\sigma(W_r\cdot [h_{t-1},x_t])$
- $\widetilde{h_t}=tanh(W\cdot[r_t\cdot h_{t-1},x_t])$ (LSTM의 Gate gate 역할)
- $h_t=(1-z_t)\cdot h_{t-1}+z_t\cdot \widetilde{h_t}$
- c.f) $C_t=f_t\cdot C_{t-1}+i_t\cdot \widetilde{C_t}$ in LSTM,
- Input gate와 Forget gate의 대신인 1 - Input gate한 값으로 hidden state를 구한다.(가중 평균의 형태)
- 내부적으로 1개의 gate로 통합하면서 계산량을 줄임
Backpropagation in GRU
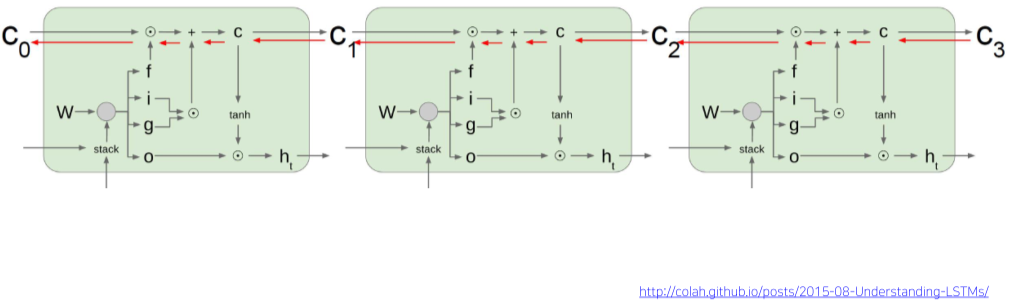
[img. GRU propagation]
- 곱셈이 아니라 덧셈으로 연산해서 Vanishing/Exploding gradient problem을 해결함
- $h_t=(1-z_t)\cdot h_{t-1}+z_t\cdot \widetilde{h_t}$
- Long term dependency 문제 해결
Summary on RNN/LSTM/GRU
- RNN은 다양한 길이를 가질 수 있는 Sequence data에 특화된 유연한 형태의 딥러닝 모델 구조
- Vanilla RNN은 간단한 구조지만 학습시 문제가 많고 학습이 잘 안된다.
- LSTM과 GRU는 long term problem과 vanishing\exploding gradient 문제를 해결했음
- 중첩되는 가중치를 곱셈이 아닌 덧셈으로 처리하여 문제 해결
Sequence to Sequence with Attention
Seq2Seq & Encoder-decoder & attention
Sequence to Sequence & Encoder-decode
Sequence to Sequence는 Sequence data를 입력으로 받은 후 Sequence data를 출력하는 many to many 모델을 말한다.
자연어 처리, 기계 번역 등이 이에 해당한다.
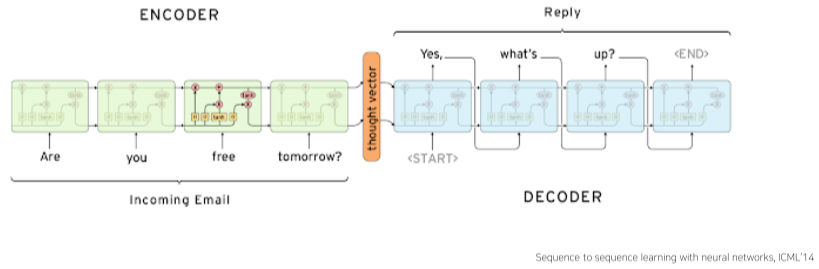
[img. 챗봇의 LSTM Encoder Decoder 예시 ]
Encoder-Decoder 모델이 대표적이며, Encoder는 입력 문장을 받아 처리하는 모델이며, Decoder는 출력 문장을 처리하며, 서로 가중치를 공유하지 않는다.
Encoder의 입력 처리 정보가 담긴 마지막 $h_t$(hidden state)는 Decoder 모델의 첫번째 Input $h_t$(hidden state) vector가 된다.
Decoder는 첫번째 Input으로 Start Token(미리 정의된 특수 문자,
Decoder의 출력이 끝나면 End Token(미리 정의된 특수 문자2,
Attention
기존의 Seq2Seq model의 단점은 다음과 같다.
- Hidden state($h_t$)의 차원이 고정되어 있어, 여러 정보를 우겨넣어야 하는 점
- Time step이 지나갈 수록 내포하고 있는 정보가 소실 되거나 유실되는 점
이러한 문제를 해결하기 위해 Input Sequence를 거꾸로 주는 방법 등이 제시되었다.
이를 해결하기 위해 Attention 모듈의 아이디어는
마지막 Hidden state($h_t$) 하나만 전달해주는 것이 아니라, 매 Time step에서 계산한 $h_0\dots h_t$까지 전체적으로 Decoder에 전해준 뒤, Decoder의 각 Time step에서 선별적으로 필요한 Hidden state를 가져간다.

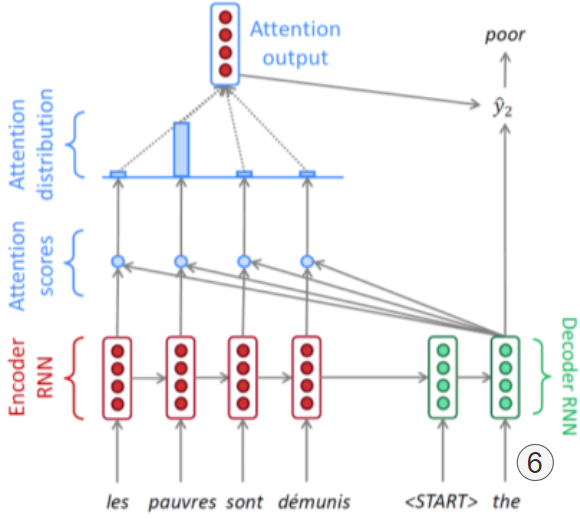
[img. Attention 모듈 동작 과정]
자세한 Attention 모듈 동작 과정
기계번역 예시를 통해 Attention 모듈 동작 과정을 알아보자.
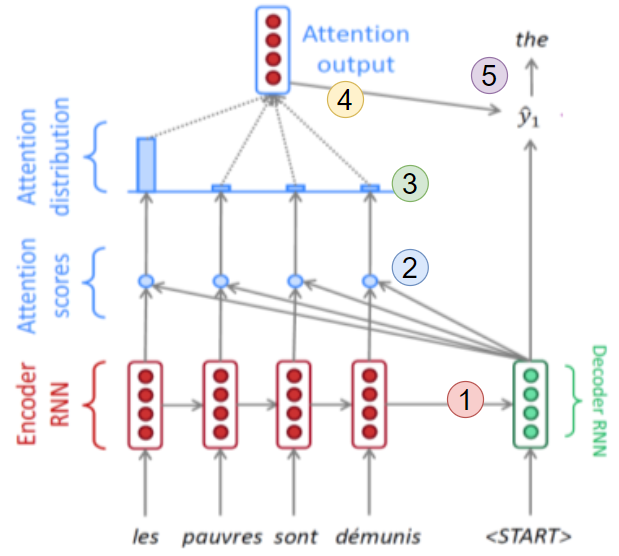
[img. Attention 모듈 예시 1~5 ]
- Encoder 모듈이 모든 과정을 끝내고 마지막 Hidden state와 Start Token을 Decoder의 첫번째 모듈이 Input으로 받는다, 이때, Encoder 각 Time step에서의 hidden state($h_0,\dots,h_{t-1}$)들 또한 기억되어 있다.
- 첫번째 Decoder Hidden state의 결과값 $h_{y0}$를 Encoder의 각 Time step의 Hidden state들과 내적하여 Attention scores를 구한다.
- 예시를 들자면 무작위의 정수 값이 나온다.{7,1,-1,2}
- 이때 Attention scores를 구하는 방법은 내적뿐만 아니라 다른 방법도 있다. 아래의 Attention Mechanism 참조
- 해당 Attention Scores를 softmax 함수를 통과시켜 Attention distribution으로 바꿔준다.
- 합이 1인 같은 차원의 결과값이 나온다. {0.83,0.05,0.02,0.1}
- 이 값은 일종의 어떤 가중치이며, 어느 시점의 hidden state를 얼만큼 참조해야하는가? 의 의미를 가진다.
- Attention distribution의 가중 평균을 구하여 하나의 Encoder Hidden state vector, Attention output을 구한다.
- Attention output은 Attention distribution 만큼 정보를 사용해 만든 정보이며, Context vector라고도 부른다.
- 2번부터 4번까지 과정을 실시하는 부분을 Attention module이라 부른다.
- 이렇게 나온 Attention Output과 원본 Output를 Concatenation하여 예측 값($\hat{y_1}$)을 출력한다.
[img. Input을 이전 예측값이 아니라 실제값에서 가져오면 Teacher forcing이다. ]
- 1번부터 5번까지의 과정을 다음 Time step에서도 반복한다.
- 이때, 이전 예측 결과값을 Input으로 넣어주지 않고, Ground Truth에서 가져온 실제값을 넣어주는 사진에서의 방식을 Teacher forcing이라고 한다.
- 첫 예측부터 틀리고, 틀린 예측 값을 다음 Input으로 넣어주면 무더기로 틀리면서 시간낭비를 하기 때문에 보통은 초반 학습에는 Teacher forcing을 이용하고, 예측 정확도가 올라가면 이전 예측값을 넣어주는 원래 방식으로 돌린다.
다양한 Attention 메커니즘
\[score(h_t,\overline{h}_s)=\begin{cases}h_t^\top \overline{h}_s&dot\\h_t^\top W_a\overline{h}_s&general\\v_a^\top \tanh(W_a[h_t;\overline{h}_s]) & concat\end{cases}\\\overline{h}_s : Encoder에서의\ Hidden\ state,\\ h_t^\top: Decoder\ Hidden\ state가\ 행렬\ 연산을\ 위해\ 행과\ 열이\ 뒤바뀐\ 형태\\ (a \times b \rightarrow b \times a)\][math. attention의 score를 구하는 3가지 방법 ]
- Dot ($h_t^\top \overline{h}_s$)
- 기본적인 방식, 두 Hidden state를 내적한다.
- General($h_t^\top W_a\overline{h}_s$)
- 학습가능한 파라미터 $W_a$를 넣어 score 계산 방법 또한 Back propagation을 통해 학습되게 한다.
- Concat($v_a^\top \tanh(W_a[h_t;\overline{h}_s])$, Bahdanau attention)
- 두 벡터를 Concatenation하여 하나의 벡터로 만들고, $W_a$와 tanh 함수, Scalar 값으로 바꿔줄 벡터 $v_a^\top$을 통하여 작은 Multi Layer Network를 만들어 학습되게 한다.
General이나 Concat 방식 처럼 학습 가능한 파라미터가 포함되면 다음 그림과 같은 Propagation을 진행되게 된다.
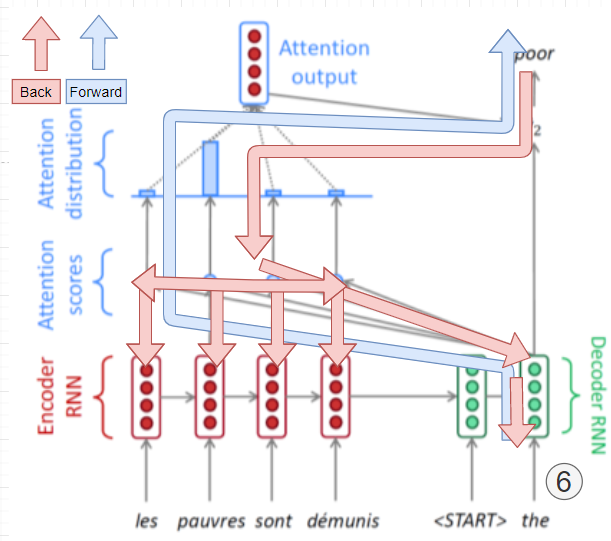
[img. Attention 모듈이 포함된 model의 propagation 진행]
Attention의 장점
- hidden기계 번역 분야(NMT)에서 성능 향상
- bottleneck(병목) 문제 해결
- Bottleneck 현상: 고정된 크기의 벡터에 너무 많은 벡터 정보를 압축시키면서 정보가 손실, 변형 되며 성능이 악화되는 현상
- Vanishing gradient Problem 완화
- Back Propagation 시, 먼 거리를 거치지 않고, 특정 Time step에 도달하므로 가중치 중첩이 적다.
- 가중치의 변경 해석을 통해 예측방법을 해석할 수 있게 해줌.
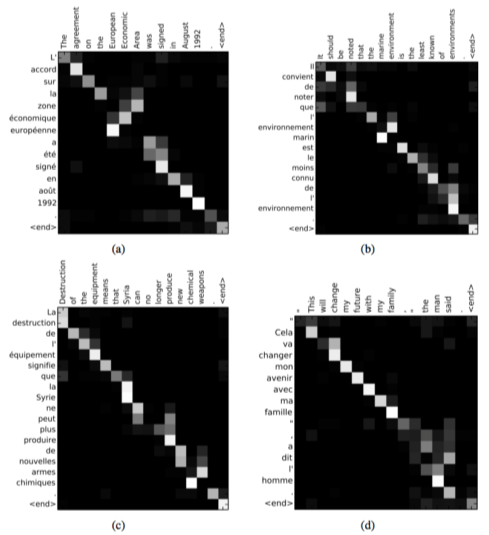
[img. x축 프랑스 단어, y축 해석한 영단어를 토대로 얼마나 정보를 참조했는 가를 그래프로 표현 가능]
Beam search
- 자연어 처리를 위한 Seq2Seq 모델의 Test에서 더욱 좋은 성능을 나오게 하는 알고리즘
Decoding 결과값 예측 방법 및 문제점
Decoder가 예측값을 생성할 때, 3가지 방법이 있다.
- Greedy decoding(탐욕 알고리즘)
가장 확률이 높은 예측을 예측값으로 바로 내보내는 방법이다.
가장 빠르다는 장점이 있지만, 한번 예측이 틀리면 그 뒤로 정정할 방법이 없다.
즉, 가장 높은 확률의 단어 뒤로는 가장 낮은 확률인 틀린 단어 들만 존재할 경우를 방지할 수 없다.
- Exhaustive search(완전 탐색)
레퍼런스 길이가 T인 문장에 단어들의 정답 확률을 $y_0,\dots,y_{t-1}$이라 할 때,
\(P(y|x)=P(y_1|x)P(y_2|y_1,x)P(y_3|y_2,y_1,x)\dots P(y_T|y_1,\dots,y_{T-1},x)=\prod^T_1P(y_t|y_1,\dots,y_{t-1},x)\)
[math. 레퍼런스 길이가 T인 문장의 정답 확률 ]
| $P(y | x)$가 가장 높은 값이 되도록 하기위해, 가능한 모든 단어쌍을 확인해보는 방법이 있다. |
하지만 이 방법의 경우 사전(Vocabulary size)가 V이고, 문장의 길이가 t라고 할때 무려 $O(V^t)$의 시간이 걸리며, 성능상 불가능한 경우가 많다.
위 두가지 방법을 절충안 방안이 세번째 방안인
- Beam search
가장 확률이 높은 beam size k개 만큼의 가지치기를 하여 가장 확률이 높은 단어(또는 hypothese)을 선택하는 방법이다.
\(score(y_1,\dots,y_t)=logP_{LM}(y_1,\dots,y_t|x)=\sum_{i=1}^tlogP_{LM}(y_i|y_1,\dots,y_{i-1},x)\)
[math. 가치치기로 생성된 경우의 수의 확률을 구하는 수식]
- 0~1 사이인 확률 값에 log 함수를 씌워 덧셈으로 계산하게 하여 계산 용이 + 너무 작은 수로 수렴하는 것 막음
- 또한 hypothesis의 확률 값이 0~1사이 이므로 음수들이 나오게 되며, 이값들의 합이 가장 큰 값이 가장 좋은 값이다.
beam size인 k를 조절하여 원하는 성능에 타협할 수 있다는 장점이 있지만, 이 방법은 최적의 결과를 보장하지 않는다는 단점이 있다.
Beam search의 예시
k가 2일 때, Reference가 “
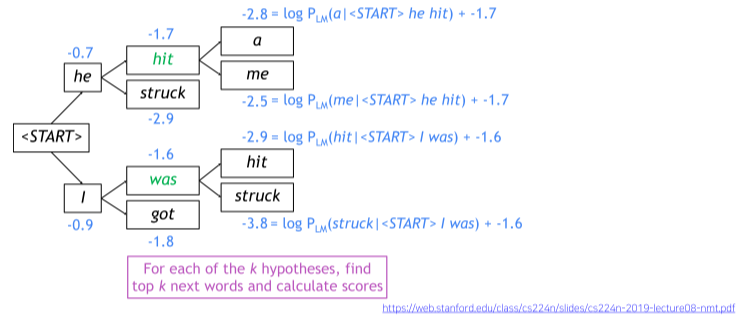
[img. Beam Searching 과정]
- [he, hit, me]까지 진행한 -2.5가 최고 점수임을 확인할 수 있다.
Beam search의 종료와 점수 평가
Greedy decoding(algorithm)의 경우
하지만 beam search의 경우, k가 1 초과일 경우, 가지치기로
그러므로, 예측의 종료를 위해 최대 Time step(또는 문장의 길이) T를 정하고, 그 이상 부터는 예측 하지 않거나, 또는 n개의 종료된 가지(hypothesis), 즉 n개의
- 여기서 T와 n은 predefined, 즉 미리 정의해 줘야한다.
- 종료될 때까지,
토큰이 나와 종료된 가지는 따로 마련한 저장공간에 점수와 내용을 저장해 놓고, 종료된 후, 점수를 비교하게 된다.
이때, 그저 점수를 비교하면, 상대적으로 문장의 길이가 짧은 경우가 유리하게 되므로, 문장의 길이로 나누어 주어, 전체 단어의 평균 확률이 높은 가지를 고르게 한다.
\(score(y_1,\dots,y_t)=\frac{1}{t}\sum_{i=1}^tlogP_{LM}(y_i|y_1,\dots,y_{i-1},x)\\where\ t = number\ of\ hypothese\)
[math. 길이 Normalize가 적용된 score 계산법]
BLEU score
- 자연어 생성 결과의 품질의 척도를 구하는 방법에 대해 알아보자.
단순히 문장의 Index끼리 비교를 하면, 문장의 길이가 다를 경우 0점으로 평가될 수 있다.
| 문장 | |
|---|---|
| Reference | I love you baby, and it’s a quite alright |
| Predicted | oh, I love you baby, and it’s a quite alright |
[fig. “oh” 한 단어가 들어가 Index가 뒤로 밀린 경우의 문장]
이를 위해 단순비교 이외의 평가방법들을 사용해야 한다.
정밀도(precision), 재현율(recall), 조화평균(F-measure)
주어진 문장이
Reference: Half of my heart is in Havana ooh na na
Predicted: Half as my heart is in Obama ooh na,
일때,
\(precision=\frac{\#(correct\ words)}{length\_of\_prediction}=\frac{7}{9}=78\%\\
recall=\frac{\#(correct\ words)}{length\_of\_reference}=\frac{7}{10}=70\%\\
F-measure=\frac{precision\times recall}{\frac{1}{2}(precision+recall)}=\frac{0.78\times0.7}{0.5\times(0.78+0.7)}=73.78\%\)
[math. 주어진 문장에 대한 정밀도, 재현율, 조화평균 ]
- 정밀도(precision)는 검색된 결과들 중 관련 있는 것으로 분류된 결과물의 비율이고, 재현율(recall)은 관련 있는 것으로 분류된 항목들 중 실제 검색된 항목들의 비율이다.
- 산술 평균 $\geq$ 기하 평균 $\geq$ 조화 평균이 성립하므로, 오류에 좀더 가중을 주기 위해 조화평균을 사용한다.
- 산술 평균 : (a + b) / 2
- 기하 평균: $(a*b)^\frac{1}{2}$
- 조화 평균: $\frac{1}{\frac{\frac{1}{a}+\frac{1}{b}}{2}}$
하지만 이 척도는 Sequence data의 순서의 오류를 고려하지 않아 부적절하다.
예를 들자면, 주어진 문장이
Reference: Half of my heart is in Havana ooh na na
Model 1 Predicted: Half as my heart is in Obama ooh na,
Model 2 Predicted: Havana na in heart my is Half ooh of na,
일때,
| Metric | Model 1 | Model 2 |
|---|---|---|
| Precision | 78% | 100% |
| Recall | 70% | 100% |
| F-measure | 73.78% | 100% |
[fig. 세가지 척도로 평가 시 잘못되는 예시]
적절하지 못한 결과를 보여줌을 알 수 있다.
BLEU score
BiLingual Evaluation understudy(BLEU)는 자연어 처리 결과를 평가하기 위해 만들어졌다.
\(BLEU=min(1,\frac{length\_of\_prediction}{length\_of\_reference})(\prod^4_{i=1}precision_i)^\frac{1}{4}\)
[math. BLEU 계산 수식]
- 기하평균을 이용하여 조화평균 보다는 오류에 관대하게 하였다.
- N-gram overlap을 이용하여 단어의 순서 또한 평가에 반영하게 하였다.
- recall 대신 precision을 평가에 사용하는 이유는, 기계 번역 등에서는 단어의 수, 문장의 길이 등이 정확히 맞지 않아도 올바른 결과인 경우가 있기 때문에, reference의 길이에 강요받지 않기 위해서 이다.
- ex) 나는 정말 니가 많이 좋아 , 난 정말 니가 좋아 :arrow_right: 길이가 다르지만 둘다 옳은 번역이다.
- 문장의 길이가 짧은 경우 의미를 모두 담지 않은 경우가 있으므로 brevity penalty를 주지만, 그렇다고 해서 결과값이 길수록 점수가 높아지는 것을 막기위해 min 함수를 씌워 1이 최대값으로 주게 하였다.
BLEU 계산 예시
주어진 문장이
Reference: Half of my heart is in Havana ooh na na
Model 1 Predicted: Half as my heart is in Obama ooh na,
Model 2 Predicted: Havana na in heart my is Half ooh of na,
일때,
| Metric | Model 1 | Model 2 |
|---|---|---|
| Precision (1-gram) | 7/9 | 10/10 |
| Precision (2-gram) | 4/8 | 0/9 |
| Precision (3-gram) | 2/7 | 0/8 |
| Precision (4-gram) | 1/6 | 0/7 |
| Brevity penalty | 9/10 | 10/10 |
| BLEU | $0.9\times (1/54)^{\frac{1}{4}} \approx 33\%$ | 0 |
[fig. BLEU 계산 예시]
Tansformer
RNN을 사용하지 않고 attention 만으로 Sequetial data를 입력 받고 예측하는 모델
Transform introduction
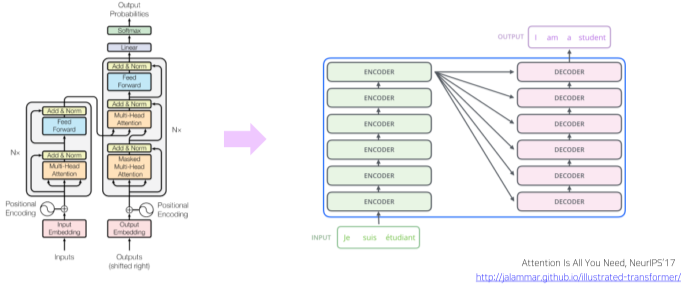
[img. Transform 모델 구조]
Transform과 Attention 모델은 같은 논문에서 처음 소개되었음.
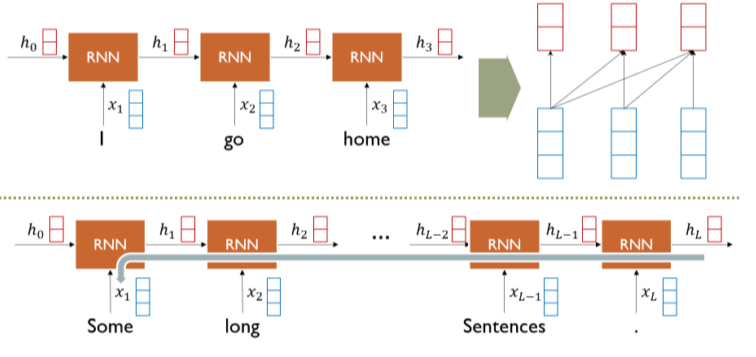 *
*
[img. 기존의 RNN]
기존의 외방향 RNN은 다음과 같은 문제가 있었다.
- 전달되는 hidden State가 쌓일 수록 병목 현상(bottle neck) 때문에 멀리 있는 과거 정보(context)가 변형되거나 소실 되는 문제
- 반대 방향 Back propagation 시 Vanishing/Exploding gradient Problem을 가지고 있었다.
- Sequential data 순서 반대 방향(즉, 미래에 나올)의 정보는 해당 Time step에서 참고할 수 없음.
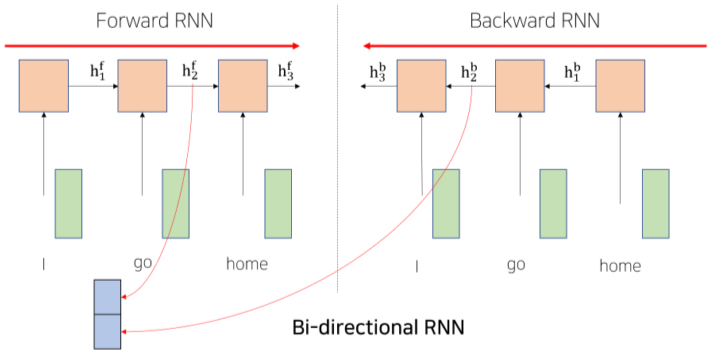
[img. Bi-directional RNN]
양방향 RNN(Bi-directional RNN)은 별개의 다른 방향의 RNN 모델 2개를 생성하여, 각 Time step에 2개의 Hidden state를 Concat하여 2배의 Dimension을 가진 Vector를 가지는 대표적인 Encoding Vector를 형성한다.
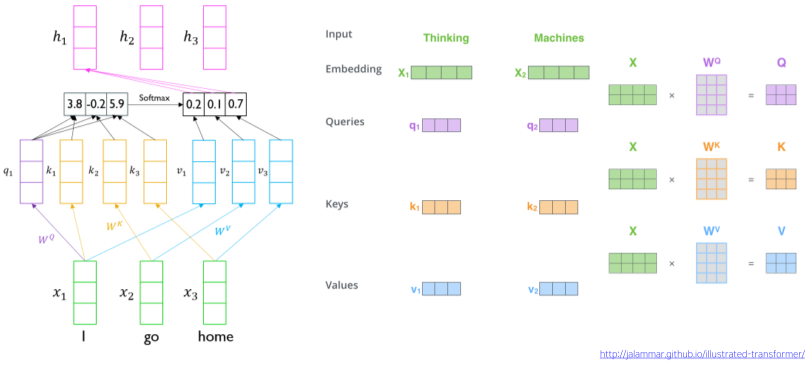
[img. Traonsform attention 구조에서 context vector를 구하는 과정]
Encoder와 Decoder 내부에서는 앞서 배웠던 Attention 모듈과 비슷한 Self-attention 모듈을 통하여 Output vector를 형성하게 된다.
앞선 Attention 모듈과의 차이점은 Self-attention은 Decoder에서 Encoder의 hidden state를 자기 자신의 Input vector와 사용한 것과 다르게 자기 자신의 Input Vector만으로 Output vector를 형성한다는 점이다.
이때 Self Attention 구조가 아닌, 단순 Input Vector의 내적으로 구성시, 자기 자신의 Input에만 과도하게 가중치를 부여하는 단점이 있다고 한다.
Self-Attention 과정은 다음과 같다.
- 각자 Embedding된 Input Vector들($X_1,\dots,X_t$)로 이루어진 행렬 X를 $W^Q$와 내적하여 Query Vector 들로 이루어진 행렬 Q를 구한다.
- 같은 행렬 X를 $W^K$와 내적하여 Key Vector로 이루어진 행렬 K를 구한다.
-
같은 행렬 X를 $W^V$와 내적하여 Values Vector로 이루어진 행렬 V를 구한다.
-
Q와 $K^T$의 내적한 결과에 Softmax 함수를 처리 한 뒤, V를 내적하여 Context Vector들로 이루어진 행렬 Z를 구한다.
-
Z는 Value Vector들의 Weighted Sums
- $K^T$는 Q와 내적하기 위해 K 행렬의 차원 을 Transform 한것. $(a\times b)\rightarrow(b\times a)$
- 이때 Q와 K의 차원 수($d_k)$는 같아야 하고, V의 차원수($d_v$)는 달라도 된다.
- 하지만 보통은 편의를 위해 일부러 차원수를 모두 같게 한다.
- 그저 내적만 하지 않고, k의 차원수(=q의 차원수)의 루트값으로 나눠주는 방법도 있다. 아래 Scaled Dot-Product Attention 참조
-
이 과정을 수식으로 표현하면 다음과 같다.
\(A(q,K,V)=\sum_i\frac{\exp(q\cdot k_i)}{\sum_j\exp(q\cdot k_j)}v_i\\
A(Q,K,V)=softmax(QK^T)V\\
where\ Q: query\ vector가\ 모인\ 행렬, K^T: K의\ 차원을\ Transform\)
[math. Dot-Product Attention의 수식과 간단한 버전]
|  |
|
| :———————————————————-: |
| $(|Q|\times d_k)\cdot s(d_k\times |K|)\cdot(|V|\times d_v)=(|Q|\times d_v)$ |
[fig. Self-attention 과정을 그림으로 표현한 것]
- softmax 함수의 기본 수행은 Row-Wise이다.
| 수식 | 도식 |
| ——————————————– | ———————————————————— |
| $A(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$ | 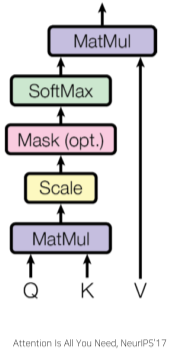 |
|
[fig. Scaled Dot-Product Attention ]
이때 k의 차원수가 커지면 Q와 K의 내적값의 분산값이 커지게 되고, 이렇게 분산값이 큰 Vector에 Softmax 함수를 사용하면 결과로 확률분포 또한 극단적으로 나오게 되며, 이렇게 극단적으로 나온 확률분포는 Vanishing Gradient Problem을 일으킨다.
이를 막기 위해 내적값들에 softmax 함수 이전에 $\sqrt{d_k}$로 나누어 분산을 줄이는 방법을 Scaled Dot-Product Attention이라고 한다.
Transformer(cont’d)
Multi-Head Attention
Self-Attention 모듈을 좀더 유연하게 확장한 모듈
| 수식 | 도식 |
|---|---|
| $MultiHead(Q,K,V)=Concat(head_1,\dots,head_k)W^O\where\ head_i = Attention(QW_i^Q,KW_i^K,VW_i^V)$ | 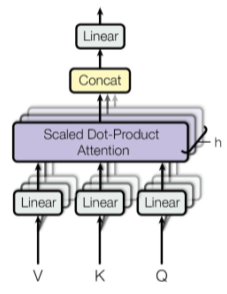 |
[fig. Multi-Head Attention]
Multi-Head Attention은 앞서사용한 Scaled Dot-Product를 구하는 과정을 각기 다른 여러 Parameter($W^Q_i,W^K_i,W^V_i$)을 이용해 여러 겹으로 진행한 모델이다.
위의 Scaled Dot-product Attention의 $W^Q, W^K, W^V$와 다른 듯?
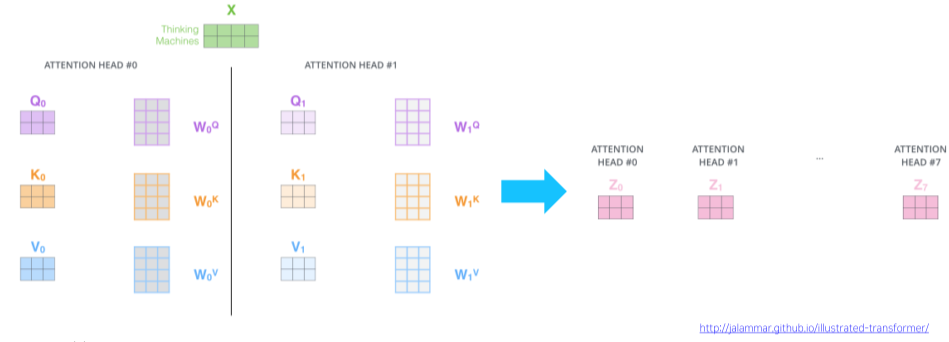
[img. 각 헤드별 Attention 결과]
이때 각 층을 Attention Head라고 하며, 각기 다른 Output Vector $Z_i$가 나오게 된다.
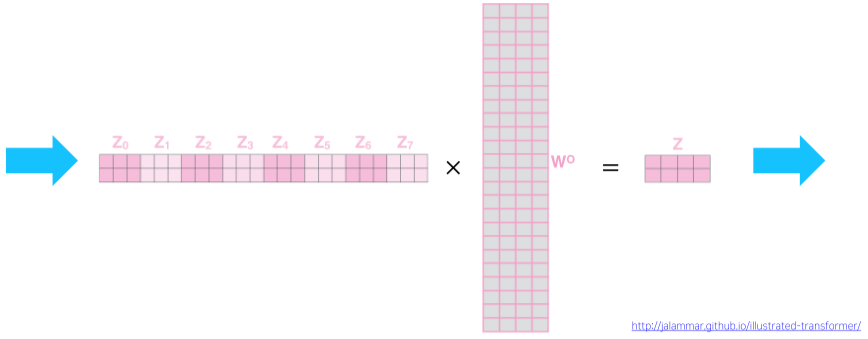
[img. 최종 Ouput Vector Z의 도출]
각 Attention Head에 나온 Output Vector를 1개의 다차원 벡터로 Concat 한 뒤, 추가로 선형 변환하여 최종 Output Vector Z를 구하게 된다.
| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
| ————————– | ———————- | ——————— | ——————- |
| Self-Attention | $O(n^2\cdot d)$ | $O(1)$ | $O(1)$ |
| Recurrent | $O(n\cdot d^2)$ | $O(n)$ | $O(n)$ |
| Convolutional | $O(k\cdot n\cdot d^2)$ | $O(1)$ | $O(\log_k(n))$ |
| Self-Attention(restricted) | $O(r\cdot n\cdot d)$ | $O(1)$ | $O(n/r)$ |
- n : 입력 Sequence data 길이
- d : hyper parameter 차원
- k : CNN kernel Size
- r : 최대 이웃거리 (restricted self-attention)
[fig. 모델에 따른 계산 복잡도 도표]
각 층에서의 연산에서 Self-Attention 구조는 Recurrent와 다르게 Query vector와 Key vector의 내적을 구하는 과정에서 O($n^2\cdot d$)만큼의 성능이 걸리고 Recurrent는 각 input마다 순차적으로 일을 처리하므로 O($n\cdot d^2$)만큼의 시간이 걸린다.
일반적으로 n은 입력 데이터에 따라 유동적으로 변하므로 Self-Attention 구조의 변동성이 더 크다고 할 수 있지만, 이전 Hidden state가 Input으로 주어져야 다음 Hidden state를 계산할 수 있어 $O(n)$의 시간이 드는 RNN과 달리 Self-Attention 구조는 동시에 진행할 수 있어, 컴퓨터 코어 수만 많다면 병렬적으로 상수 시간 내에 진행할 수 있어 빠르다.
또한 Back propagation 진행시, 정보 접근 시에도 무조건 순차적으로 진행되는 RNN과 달리 곧바로 파리미터에 접근할 수 있어서 Self-Attention 구조가 더욱 빠르다.
Self-Attention Block과 Residual Connection
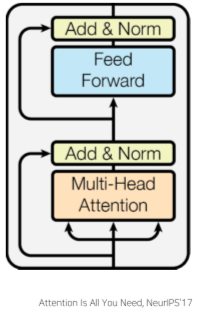
[img. 하나의 Self-Attention block]
이러한 Attention 구조의 공통적인 Attention 과정과 후처리 부분을 블록화하여 하나의 모듈처럼 사용하곤 한다. (정확히는 Encoder 부분)
- 크게 Feed-forward 부분과 Multi-head attention 두 구조로 나뉜다.
이때 CNN에서 본 것과 같이 Input 값을 Attention 처리하지 않고 Skip하여 완성된 Output Vector값에 행렬합을 해주는 것을 Residual connection이라고 하며 한 Block에 2번 처리된다.
\(LayerNorm(x+sublayer(x))\)
[math. Residual connection 수식]
CNN과 같은 장점인 Vanishing Gradient Problem을 해결할 수 있다.
이때 중요한 점은 행렬간의 덧셈이 성립되기 위해 Attention 처리된 Output Vector는 원본 Input과 같은 차원을 가져야 한다는 점이다.
Layer Normalization
학습 안정화와 성능 향상을 위해 Layer Normalization을 한다.
크게 2단계로 나뉘는데,
- Vector들의 평균과 분산값을 0과 1로 바꾸는 Normalization 과정
- 학습가능한 Parameter를 집어넣기 위해 파라미터가 포함된 선형 함수에 집어넣는 Affine Transformation 과정
으로 이루어져있다.
Residual Connection과 같이 2번 시행된다.
\(\mu^l=\frac{1}{H}\sum^H_{i=1}a^l_i,\ \ \sigma^l=\sqrt{\frac{1}{H}\sum^H_{i=1}(a_i^l-\mu^l)^2},\ \ h_i=f(\frac{g_i}{\sigma_i}(a_i-\mu_i)+b_i)\\
\mu : 평균,\ \sigma : 표준\ 편차,\ h_i:Result\ Vector\)
[math. Layer Normalization의 수식]
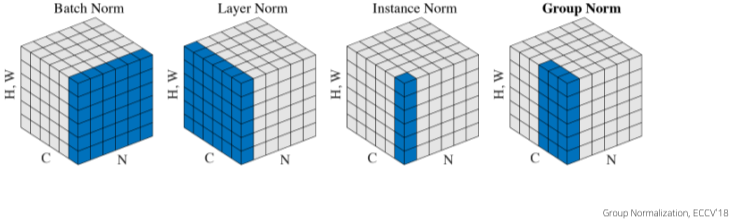
[img. Layer Normalization 이외의 방법들]
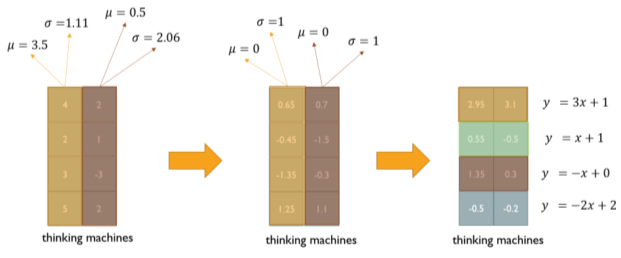
[img. Layer Normalization 예시]
Positional Encoding
RNN과 달리 Attention은 Hidden state가 순차적으로 주어지지 않고, 모든 hidden state를 동시에 이용할 수 있다.
이 때문에 병렬 처리, Gradient 문제, 병목 문제 해결 등 여러 장점을 가지고 있지만, 하나의 모순이 있다.
바로, Sequential data의 순서를 학습과정 중에 고려하지 않는다는 점이다.
- RNN의 경우, 접근할 수 있는 hidden state는 바로 이전 hidden state이므로, 각기 output이 주어진 정보가 다르므로 순차성에 따른 구별이 간다.(뒤로 갈수록 hidden state에 많은 정보가 담기니까)
- 하지만 Attention은 동시에 모든 hidden state 또는 Input에 접근하므로 구별이 없다.(구별하게 되는 hidden state 또는 Input별 가중치는 Input이 주어진 뒤로 계산된다.)
이를 해결하기 위해 Input 값의 위치에 따라 Vector에 구별이 가는 특별한 값을 더해주는 방법이 Positional Encoding이다.
\(PE_{(pos,2i)}=\sin(pos/10000^{2i/d_{model}})\\
PE_{(pos,2i+1)}=\cos(pos/10000^{2i/d_{model}})\\\)
[math. Positional Encoding 수식]

[img. Positional Encoding 그래프]
sin함수와 cos함수 주기의 차이성, 또, 같은 함수 순번에도 주기를 다르게 주어 순서에 따라 특별한 값을 Input vector에 더해준다.
보통 맨처음 Input 시점에 한번만 진행된다.
Warm-up Learning Rate Scheduler
Gradient Descent, Adam등의 과정에서 Hyper parameter인 Learning Rate 값을 고정하지 않고 변동을 주는 방법이다.
\(learning\ rate = d^{-0.5}_{model}\cdot \min(\#step^{-0.5},\#step\cdot warmup\_steps^{-1.5})\)
[math. Learning rate 변경 수식 ]
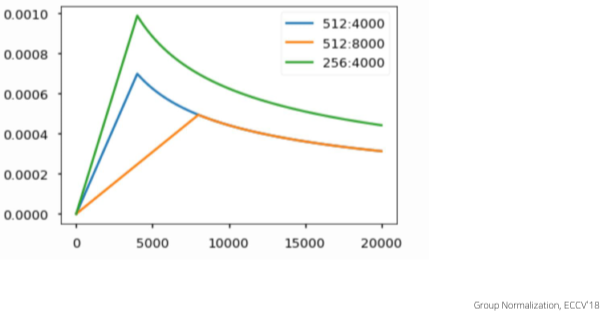
[img. Learning rate 변경의 예시]
경험적으로 위와 같은 그래프를 사용한다.
High-Level View, Visualization
Encoder에 Attention Block을 쌓아서 High-Level를 만들 수 있어서, Visualization을 통해 볼 수 있다
Decoder의 Multi-Head Attention에서 Encoder에서 가져온 Key 행렬과 Value 행렬에 준 가중치를 layer별로 확인하여, 모델의 추론을 Visualization할 수 있다.
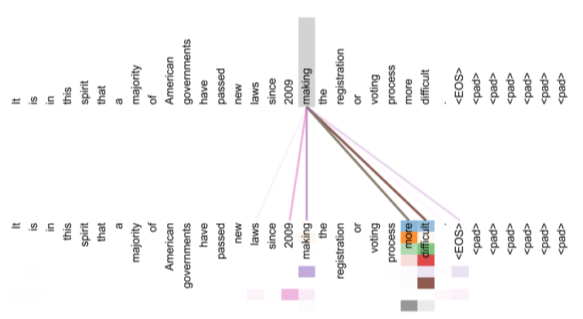
[img. 각 layer 별 참조한 단어에 대한 Visualization]
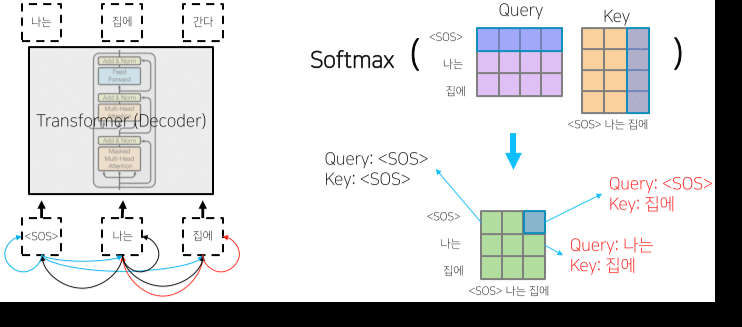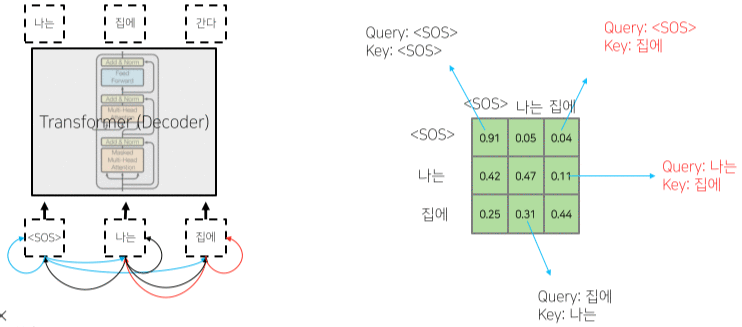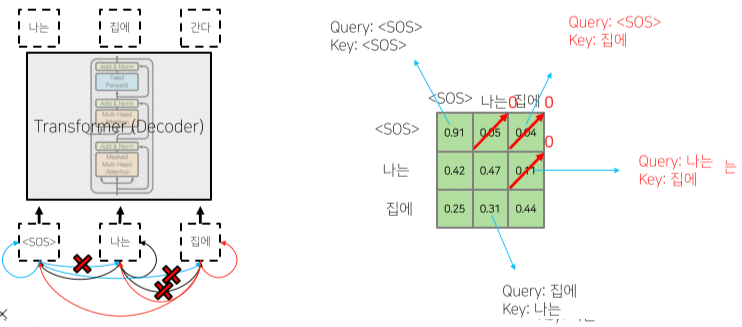
Decoder & Masked Self-Attention
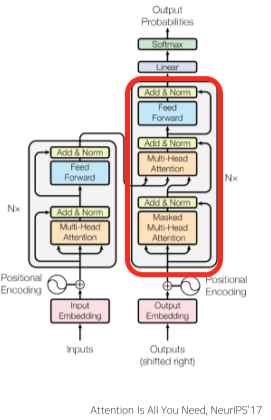
[img. Encoder-Decoder 구조]
Decoder 부분에서는 2번의 Self-Attention을 진행하게된다.
-
Masked decoder 부분
- 단순 추론 뿐만 아니라 Query 행렬과 Key 행렬의 내적 연산 Softmax output의 일부분을 마스킹한 뒤, 다시 Normalization 하여 내보내는 부분.
- 이를 통해 아직 추론하지 않아 접근할 수 없는(생성되지 않은) 이후의 Sequential data에 가중치를 주는 것을 막는다.
-
Encoder-Decoder 부분
- Key 행렬과 Value 행렬을 Encoder에서 가져와서 Decoder에서 보내준 Query 행렬과 Attention 하는 부분.
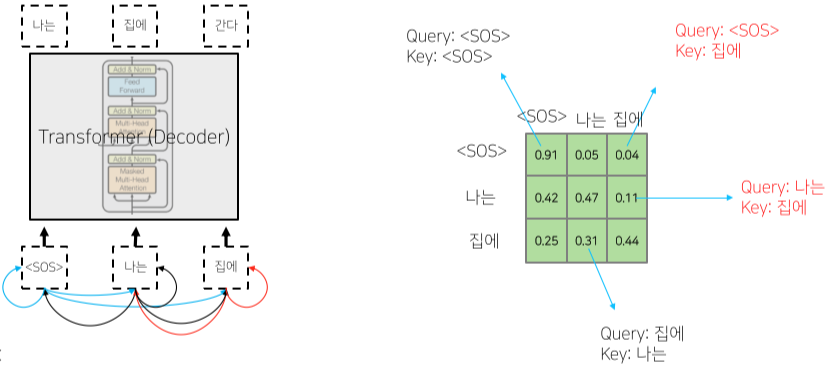
[img. Query 행렬과 Key 행렬 내적의 결과]
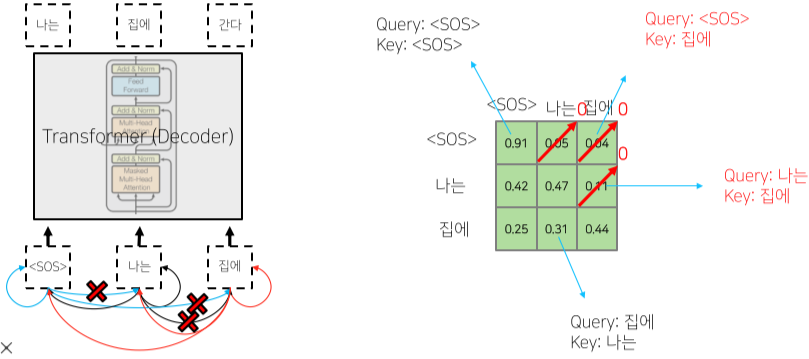
[img. 마스킹 ]
**[gif. 첫
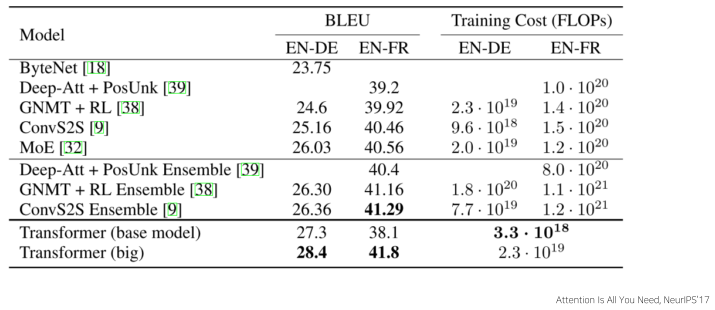
[img. Transformer와 성능 비교]
낮은 성능처럼 보이지만 BLEU 기준의 결과이므로, 비슷한 결과물들 또한 점수가 낮게 나오므로 실제로는 상용으로 쓰는 수준의 성능이다.
Self-supervised Pre-training Models
Self-supervised(자기지도 학습)
- Task를 풀기 위해 자동으로 데이터를 라벨링하는 학습
Pre-training(사전훈련)
- 여러 Task로 Transfer Learning 될 수 있도록, 하나의 Task로 모델의 Parameter를 훈련시키는 것,
Fine Tuning(미세 조정)
- 미리 개발, 훈련된 모델을 용도에 맞게 파리미터, Layer 구조 등을 변경하는 것
Transfer Learning(전이 학습)
- 미리 개발, 훈련된 모델을 용도에 맞게 나의 데이터셋 등으로 재학습시키는 과정
Self-Supervised Pre-Training Models
Transfer Learning, Self-supervised Learning, Transformer를 사용해 NLP에서 압도적인 성능을 보여준 두 모델을 알아보자.
- Transformer 모델은 좋은 성능으로 NLP 분야 뿐만 아니라 여러 분야에서 쓰이고 있다.
- 최근에는 Self-attentio 층을 24층 이상으로 쌓은 뒤 self-supervised learning framework에서 학습 후, Transfer learning 형태로 fine tuning한다.
- natural language generation에서 greedy decoding 수준에서 벗어나지 못하고 있다.
GPT-1
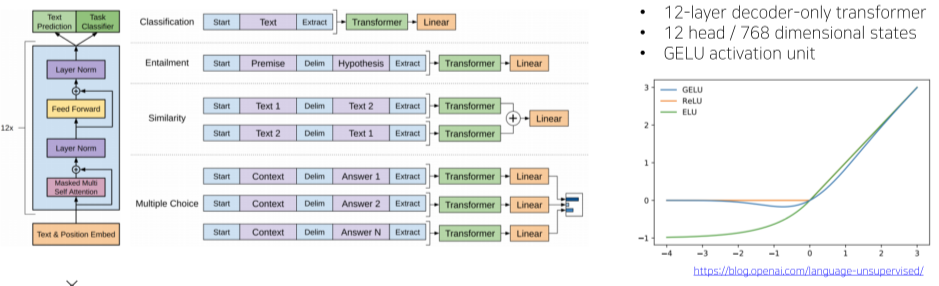
[img. GPT-1 모델]
Pretrained model의 시초격, OPEN-AI에서 개발. Transformer 모델의 구조 특히 Decoder 구조를 따름
다양한 special token을 통해 fine-tuning간의 transfer learning을 효율적으로 바꿈
- Start 뿐만 아니라, Delimiter, Extranction Token 등 다양한 Special Token을 통하여 여러 문제 해결 가능
여러 자연어 처리(classification, similarity, entailment 등)를 큰 변화 없이 처리 가능한 통합적인 모델
12개의 self-attention decoder-only transformer 모델층으로 이루어짐
여러 방안으로 사용할 때는 미리 여러 데이터로 학습된 GPT-1 모델(pre-training)을 transfer learning의 형태로 사용 시에는 후반의 일부 layer을 용도에 맞게 교체하고, Learning rate를 적게주어 조금만 학습 시키는 방식(fine-tuning)으로 사용.
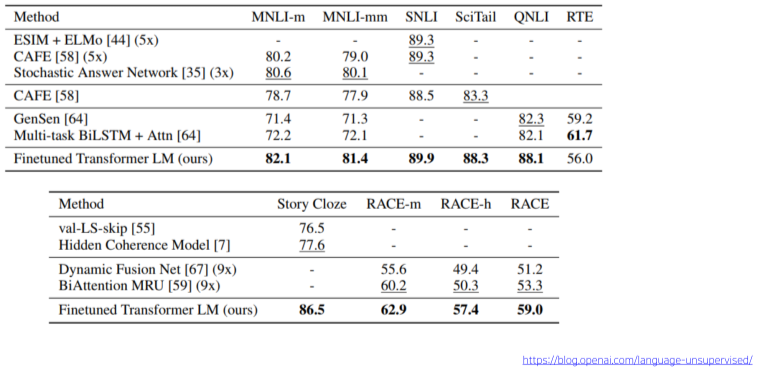
[img. GPT-1 성능 결과]
BERT
가장 널리 쓰이는 NLP Pre-trained 모델, Encoder 구조만 활용
GPT는 단방향의 Masked Attention 구조를 활용하는 반면, BERT는 아래의 MLM을 활용하여 양방향 Self-attention 구조이다.
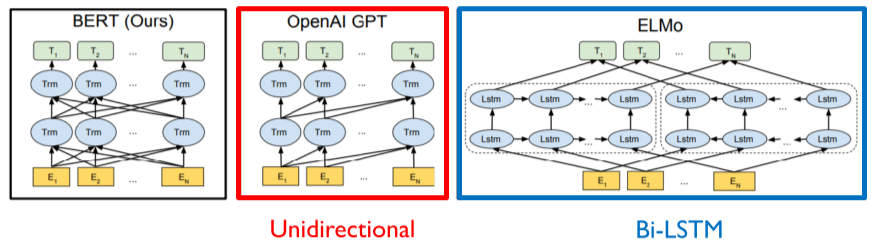
[img. 다양한 모델들 비교]
- ELMO: Transformer 이전에 LSTM 기반 Encoder로 Pre-trained 된 모델
- 최근의 모델들은 ELMO에서 LSTM Encoder를 대체한 형태
기존의 모델들은 앞에 나온 단어 부터 순차적으로 문맥을 판단하지만, 실제 독해에서는 앞 뒤 모두의 문맥을 파악해야 한다.
Masked Language Model(MLM): BERT에서의 Pre-Training 학습 방법 형태, 문장에서 일부 단어를 [MASK] 토큰으로 바꾼 뒤, 앞뒤 문맥을 파악하여 맞추는 형식으로 학습
- 어느 정도 비율의 단어들을 마스킹할 것인가?는 Hyperparameter이다.
- 보통 15%정도로 시작하며 너무 많이 마스킹 하면 문맥이 제대로 파악하지 못해 학습이 안되고, 너무 적게 마스킹하면 Training이 오래 걸린다.

[img. MLM 예시]
단, Mask된 단어는 그대로 마스킹된 채로 학습하면 실제 데이터는 마스킹되어있지 않기 때문에 괴리가 있는 결과가 나오기때문에, 실제로는 마스킹하기로 한 단어의 80%는 마스킹, 10%는 임의의 다른 단어로 교체, 10%는 그대로 두는 형식으로 학습시킨다.
Next Sentence Prediction (NSP)
문장 간의 관계에 대한 예측하여 학습하는 것, BERT의 Pre-Training 학습 방법 중 하나
- 어떤 문장이 특정 문장 다음 문장으로 올만한 문장인가? 연관있는 문장인가? 아니면 그냥 랜덤 문장인가?
- 아래와 같이 data를 생성하여 교육 시킨다.
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
[code. NSP Input 예제 ]
- [CLS] 토큰 : GPT의 Extractor 토큰, 문장의 예측을 위한 선언용?
- [SEP] 토큰 : 문장 사이에 구별을 위한 토큰, 문장의 끝을 알림
- Label : 포함된 두 문장의 관계에 대한 Label
Summary
구조는 Transform 구조와 유사하며,
BERT BASE의 경우 SELF-ATTENTION LAYER 12개, ATTENTION HEAD 12개, 인코딩 벡터 차원 수는 768개이며, 경량화되어 있으며,
BERT LARGET의 경우 SELF-ATTENTION LAYER 24개, ATTENTION HEAD 16개, 인코딩 벡터 차원 수는 1024개
INPUT SEQUENCE의 경우
-
단어를 SUBWORD라는 단위로 잘개 쪼개는 WordPiece embeddings 라는 방법을 사용한다.(ex) Pretraining -> pre, training)
-
앞서 설명했던 Poisitional Encoding 방법을 변형한 미리 학습한 최적화된 값(Learned positional embedding)을 이용한다.
- [CLS](Classification embedding), [SEP](Packed sentence embedding) TOKEN
- Segment Embedding
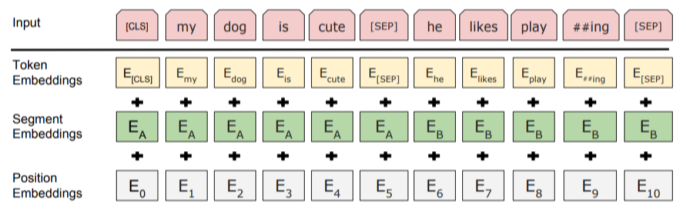
[img. Segment embedding의 사용]
- 일종의 문장별로 구분하기 위한 소속 문장 속성이 추가된 Embedding
- Token + Segment + Position Vector를 서로 더해준다.
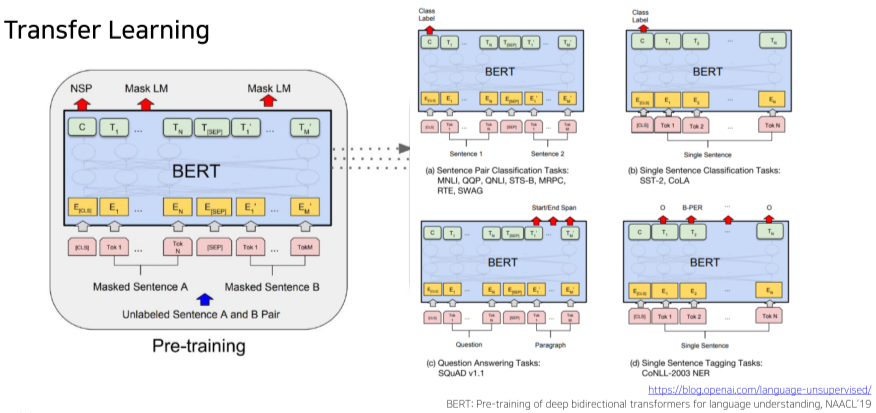
[img. BERT의 Transfer Learning을 위한 Fine-Tuning 과정]
- Input Layer와 Output Layer을 달리하여 특정 Downstream Task를 위한 모델로 만들 수 있다.
- Masked token의 prediction을 위한 Layer를 제거한 후, 우리 Task를 위한 Layer로 바꾼 뒤, 기학습된 Transfomer encoder의 parameter들은 작은 Learning rate를 사용하여 조금만 학습이 되게 한다.
| BERT | GPT | |
|---|---|---|
| Training-data size | BookCorpus + Wikipedia(2,500M words) | BookCorpus(800M words) |
| Training special tokens during training | [SEP],[CLS], sentence A/B embedding during pre-training | - |
| Batch size | 128,000 words | 32,000 words |
| Task-specific fine-tuning | task-specific fine-tuning learning rate(task 별로 다름) | 5e-5 고정 |
| Masked token를 통해 앞뒤 모든 단어 접근 가능 | 오직 이미 나온 단어만 접근 가능 |
[fig. BERT vs GPT]
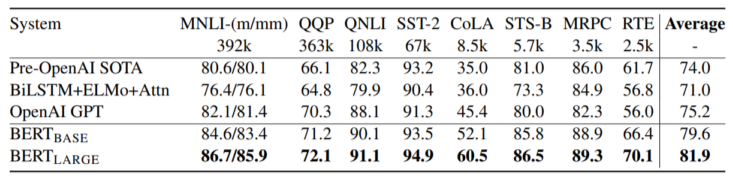
[img. GLUE data, BERT 성능 비교]
Machine Reading Comprehension(MRC)란, 기계독해하여 질의응답(Question Answering)하는 Task
Daniel and Sandra journyed to the office, Then they went to the garden. Sandra and John travelled to the kitchen. After that they moved to the hallway.
q: where is daniel?
a: garden
[code. MRC 예제]
SQuAD 같은 MRC 데이터셋에서 BERT 모델은 언제나 순위권에 많이 존재한다.
- SQuAD 1.1
- 질문과 데이터셋을 sentence로 생각하고 [CLS] 토큰으로 붙인 후, 단어들을 Fully connected layer를 통해 스칼라 값을 얻어낸 후, 답변이 존재하는 문구의 시작 위치 단어와 끝 위치 단어를 찾아내는 방식
- SQuAD 2.0 : BERT 변형 모델이 많이 존재
- toekn 0 CLS 토큰을 no answer 로 사용 하여 답이 없는 경우도 방지
- On SWAG
- 질문 + 선택지들을 [CLS] 토큰과 함께 각각 concat한 뒤, 나오는 Encoding vector를 Fully connected layer을 통과해서 나온 Scalar 값으로 판단.
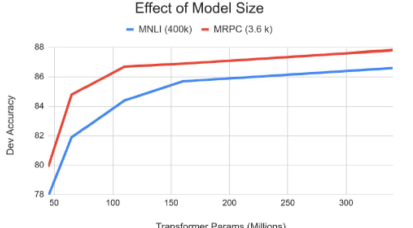
- Ablation Study
[img. Model Size vs 성능]
- Model의 Parameter 크기가 클수록 성능이 좋아진다.
Advanced Self-supervised Pre-training Models
- 좀더 경량화, 고도화된 Pre-training Model
GPT-2

[img. GPT-2 결과 예시]
GPT-1과 구조가 크게 다르지 않으며, layer가 더 싶고 training data가 더 많아진 형태
- 일부 Layer normlization의 위치 이동
- residual layer의 weight를 residual layer의 수 루트값에 반비례하게 줄여줌.(=영향력 약화)
다음 단어를 예측하는 방법으로 학습시킴, dataset 퀼리티를 늘리기 위해 text들을 걸렀음
- Reddit이라는 커뮤니티에서 좋아요가 3개 이상인 외부링크의 document를 수집
- 전처리로 Bytpe pair encoding 적용, subword 수준의 word embedding.
- 구현 방법은 [NLP-Assignment]Byte_Pair_Encoding,ipynb 참조
down-stream task에서 zero-shot setting, 추가 parameter나 구조 변경없이 사용 가능
decaNLP가 동기가 됨. : 모든 language task는 Question Answering으로 통합할 수 있다.
- 기계 번역: 이 문장의 한국어 버전은 무엇인가?
- 문서 요약: 이 문서의 요점은 무엇인가?
- 감정 분석: 그래서 화자는 이 물건을 좋아하는가? 싫어하는가?
- 이 원리를 통해 zero-shot setting, 별다른 모델변경, 학습(fine-tuning) 없이 down-stream task 가능,
GPT-2 예시

[img. GPT-2 문서 요약]
별다른 fine-tuning 없이 문서 마지막에 TL;DR:(Too long, didn’t read) 이란 단어를 추가하면 다음에 요약한 문장을 생성해줌.

[img. GPT-2 기계 번역]
- 문장에 wrote in French: 라고 붙이자 불어로 번역해줌
GPT-3
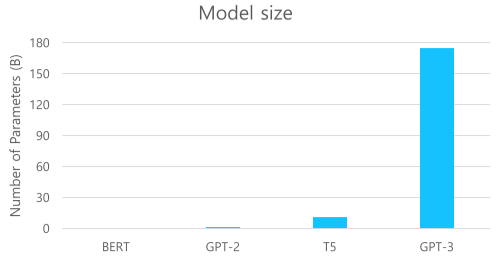
[img. GTP-3 parameter 수 비교]
GPT-2에 비해 모델 구조 등에 특별한 변화보다, Parameter 수, Dataset, Batch size를 비교할 수 없을 정도로 크게 바꿔줌
96 Attention layers, Batch size of 3.2M
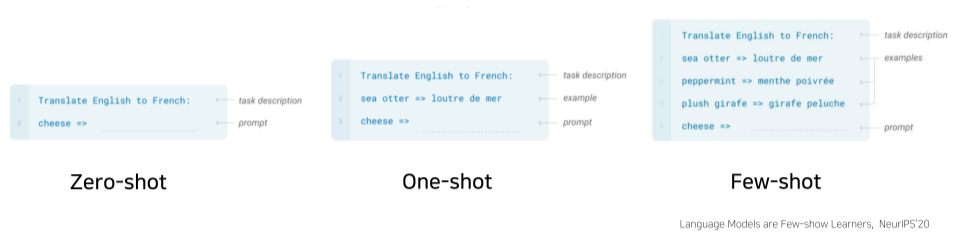
[img. shot]
Zero-shot setting으로도 충분히 downstream-task가 가능하지만 one-shot, Few-shot 처럼 example을 줌으로 더욱 성능을 향상할 수 있다.
- Zero-shot: Question answering 기반으로 문장을 주고 번역
- One-shot: 하나의 번역 예시를 보여주고 번역
- Few-shot: 여러 개의 번역 예시를 보여주고 번역
- zero-shot으로도 model parameter의 수가 커질 수록 성능이 증가하지만, shot이 늘어날 수록 급격하게 성능이 좋아짐.
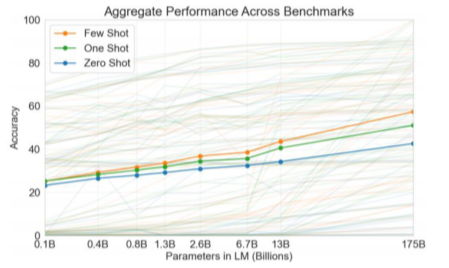
[img. shot별 성능 향상]
ALBERT
경량화된 BERT, Lite BERT라는 의미
점점 모델이 거대해지면서 메모리의 한계와 느려진 학습 속도를 해결하기 위해, 다음과 같은 방법을 이용했다.
-
Factorized Embedding Parametrization
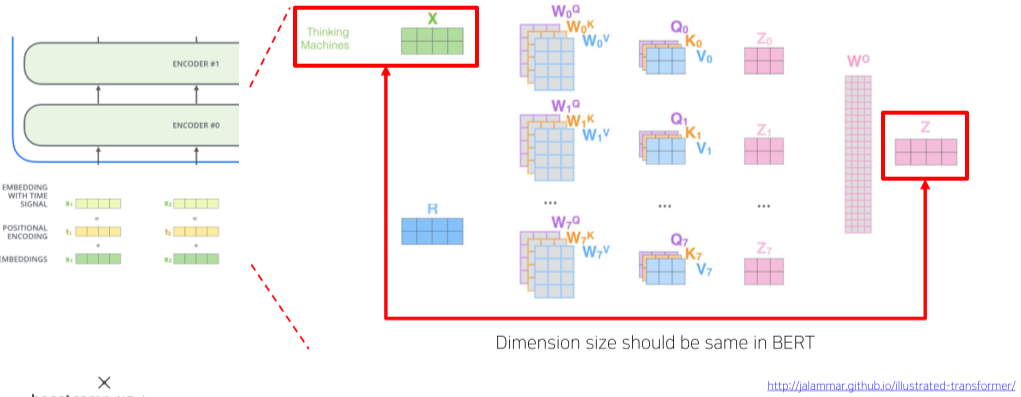
[img. Factorized Embedding Parametraiztion]
Residual connection은 skip하며 layer 사이마다 더해지므로 일정크기의 dimension의 유지가 강제된다.
이 dimension이 너무 작으면, 정보가 많이 안담기며, 너무 크게 잡으면 Parameter 수가 늘어나고, 시간이 너무 오래걸린다.
ALBERT에서는 embedding의 차원 크기를 줄이면서 정보의 소실을 줄이고, Residual 합이 가능한 방법을 쓴다.
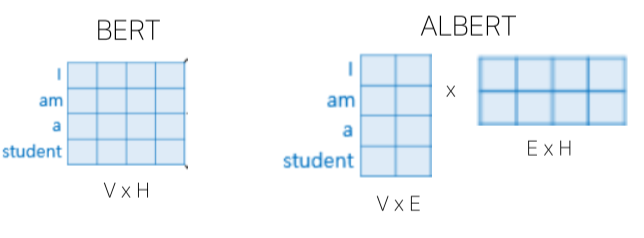
[img. BERT VS ALBERT]
- V : Vocabulary size, H : Hidden-state dimension, E : Word embedding dimension
- ALBERT는 작은 크기의 word embedding에 추가로 dimension을 늘려주는 layer을 추가하여 Residual net 이전에 차원 크기를 불려서 해결했다. (Row rank matrix factorization)
-
Cross-layer Parameter Sharing
-
Multihead-self-attention 구조는 각각 head마다 학습시켜야할 선형변환 행렬($W_Q,W_V,W_K,W_o \times $ head 수 등)들이 존재하는데, 이를 head마다 구분하지 말고 공유하는 하나의 행렬로 바꾸는 구조를 의미
-
Shared-FFN : feed-forward network parameter만 공유
-
Shared-attention : attention layer의 parameter 공유
-
All-shared: 위 두개 전부 공유
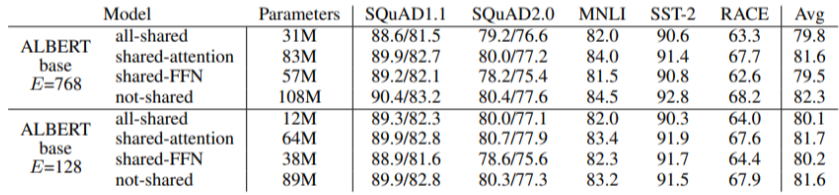
[img. share 했을 시에 성능 비교, Parameter는 크게 줄어들고, 성능은 조금 하락]
-
-
Sentence Order Prediction
- BERT의 Next Sentence Prediction task가 비효율적이라 판단하여 Masked Language Model만 실시
- 대신 같은 문서에서 2개의 문장의 순서를 뒤바꾸거나 그대로 둔 뒤, 정상적인 순서인지 맞추는 학습(Sentence Order Prediction)을 실시함.
- BERT의 NSP는 다른 문서에서 가져온 Negative sample의 경우, 너무 쉽고, 같은 문서에서 가져온 Postive sample의 경우 문맥이 아니라, 단어의 빈도 등으로 맞추는 등의 문제가 있었음

[img. 기존 BERT와 비교시, 오히려 SOP의 성능이 가장 높다.]
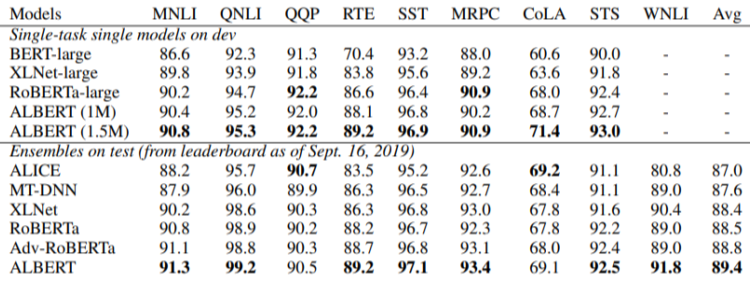
[img. GLUE 성능 비교 결과]
- ALBERT 성능이 좋다.
ELECTRA
Efficiently Learning an Encoder that Classifies Token Replacements Accurately의 준말
BERT, GPT의 학습 방식과 달리 Generoator란 단어 복원기를 통해 Masking된 단어를 다시 복원한 뒤, 그 결과를 ELECTRA의 Discriminator를 통하여 원본과 비교하여, 복원된 단어인지, 원래 masking 안된 원본인지 구별하는 방법(GAN, +generative adversal network)이다.
학습은 Generator, Discriminaotr 둘다, 실제 test 에는 Discriminator만 사용
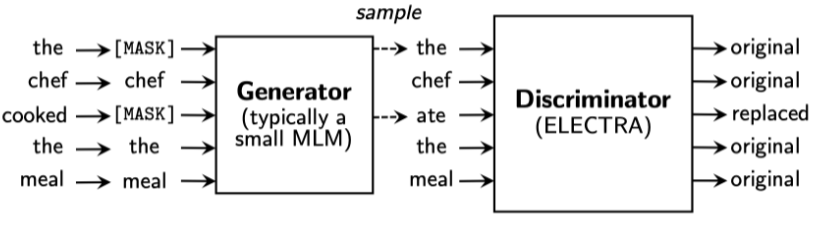
[img. ELECTRA의 학습 방법]
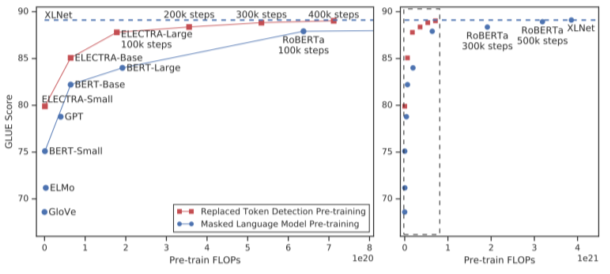
[img. ELECTRA와 다른 모델 비교]
- 학습 시킬수록 다른 모델에 비해 성능이 좋다는 것을 알 수 있다.
Light-weight Models
기존의 모델들이 너무 무거워서 가볍게 만들기 위한 가성비 모델, 임베딩 머신, 스마트 폰 등에 사용
- DistillBERT
- Hugging face의 논문
- Teacher-student 모델
- Teacher model은 파라미터, 레이어 수가 비교적 더크며 student가 Teacher의 결과(softmax 결과)을 모방하도록 함
- TinyBERT
- Teacher-student model과 비슷하나 parameter와 hidden state 등, 중간 결과 까지도 비슷하게 하도록 모방하는 모델
Fusing Knowledge Graph into Language Model
- 주어진 문장 뿐만 아니라 상식 또는 외부지식(Knowledge Graph)에서 지식을 가져와 처리하는 방법
- ERNIE
- KagNET
_articles/AI/NLP/자연어처리 기본.md