풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
기계 독해 기본
- 1. MRC Intro & Python Basics
- Extraction-based MRC
- Generation-based MRC
- Passage Retrieval - Sparse Embedding
- Passage Retrieval -Dense Embedding
- Passage Retrieval - Scaling Up
- Linking MRC and Retrieval
- Reducing Training Bias
- Closed-book QA with T5
- QA with Phrase Retrieval
기계 독해(MRC) 기본
Naver AI boostcamp 기계 독해 강의를 정리한 내용입니다.
1. MRC Intro & Python Basics
Introduction to MRC
Machine Reading Comprehension(MRC. 기계독해)란?
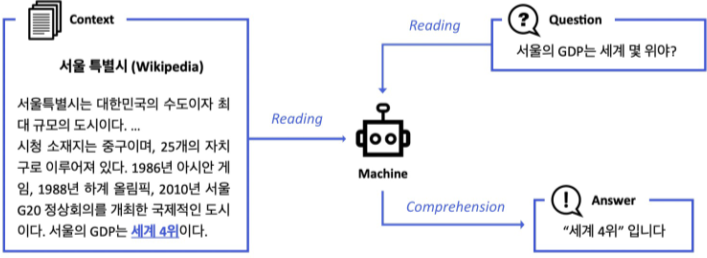
주어진 지문(Context)를 이해하고, 주어진 질의 (Query/Question)의 답변을 추론하는 문제

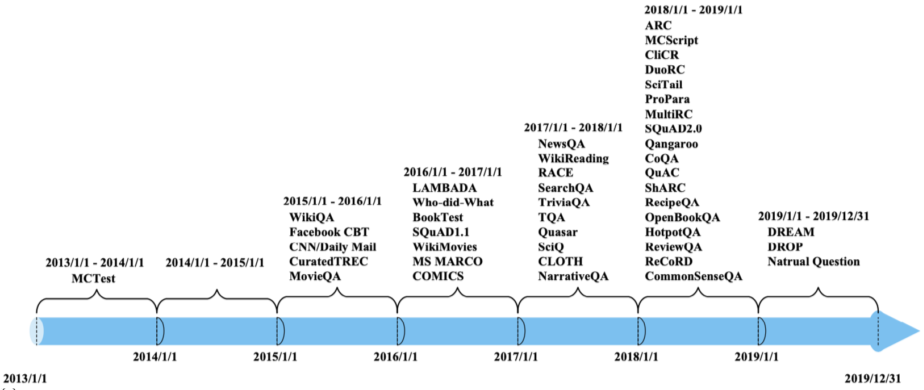
- 1) Extractive Answer Datasets
-
질의 (qeustion)에 대한 답이 항상 주어진 지문 (context)의 segment (or span)으로 존재
MRC 종류로 Cloze Tests(CBT), Span Extraction(SQuAD, KorQuAD, NewsQA) 등이 존재

- 2) Descriptive/Narrative Answer Datasets
-
답이 지문 내에서 추출한 span이 아니라, 질의를 보고 생성된 sentence (or free-form)의 형태
MRC 종류로 MS MARCO, Narrative QA 등이 존재

- 3) Multiple-choice Datasets
-
질의에 대한 답을 여러 개의 answer candidates 중 하나로 고르는 형태
MRC 종류로 MCTest, RACE, ARC, 등이 존재
MRC의 해결해야할 점

-
단어들의 구성이 유사하지는 않지만 동일한 의미의 문장을 이해 (paraphrasing)
- 대명사가 지칭하고 있는 것이 무엇인가?(Coreference Resolution)
-
답변이 존재하지 않는 경우는?
- 여러 문서에서 supporting fact를 찾아야 답을 알 수 있는 경우(Multi-hop reasoning)
MRC의 평가 방법
1) Exact Match / F1 Score : For extractive answer and multiple-choice answer datasets
- Exact Match (EM) or Accuracy : 예측한 답과 Ground-truth가 정확히 일치하는 샘플의 비율, (Number of correct samples) / (Number of whole samples)
- F1 Score : 예측한 답과 ground-truth 사이의 token overlap을 F1으로 계산
- F1 = $\frac{2\times Precision \times Recall}{Precision+Recall}$, $Precision=\frac{num(same\ token)}{num(pred\ tokens)}$, $Recall=\frac{num(same\ token)}{num(ground_tokens)}$
예를 들어, 답이 5 days, 예측이 for 5days 이면, EM은 0이지만 F1: 0.8이다.
2) ROUGE-L / BLEU : For descriptive answer datasets, Ground-truth와 예측한 답 사이의 overlap을 계산
- ROUGE-L Score : 예측한 값과 ground-truth 사이의 overlap recall (ROUGE-L => LCS (Longest common subsequence) 기반)
- BLEU (Bilingual Evaluation Understudy) : 예측한 답과 ground-truth 사이의 Precision (BLEU-n => uniform n-gram weight)
Unicode & Tokenization
Unicode란, 전 세계의 모든 문자를 일관되게 표현하고 다룰 수 있도록 만들어진 문자셋으로, 각 문자마다 숫자 하나에 매핑됨.

인코딩이란, 문자를 컴퓨터에서 저장 및 처리할 수 있게 이진수로 바꾸는 것
UTF-8(Unicode Transformation Format)란, 현재 가장 많이 쓰는 인코딩 방식, 문자 타입에 따라 다른 길이의 바이트를 할당한다.
1 byte: Standard ASCII
2 bytes: Arabic, Hebrew, most European scripts
3 bytes: BMP(Basic Multilngual Plane) - 대부분의 현대 글자 (한글 포함)
4 bytes: ALL Unicode characters - 이모지 등
한국어의 경우, 모든 한글 경우의 수를 따진 완성과, 조합하여 나타낼 수 있는 조합형으로 나뉘어 분포되어 있다.

토크 나이징은 텍스트를 토큰 단위로 나누는 것으로, 단어, 형태소, subword 등 여러 기준이 존재한다.
Subword 토크나이징은 자주 쓰이는 글자 조합은 한 단위로 취급하고, 자주 쓰이지 않는 조합은 subword로 쪼갠다.
- ##은 디코딩 (토크나이징의 반대 과정)을 할 때 해당 토큰을 앞 토큰에 띄어쓰기 없이 붙인다는 것을 의미
BPE(Byte-Pair Encoding)은 데이터 압축용으로 제안된 알고리즘으로, NLP에서 토크나이징용으로 활발하게 사용되고 있다.
- 사람이 직접 짠 토크나이징보다 성능이 좋은 경우가 많음
- 가장 자주 나오는 글자 단위 Bigram (or Byte pair)를 다른 글자로 치환한다.
- 치환된 글자를 저장해둔다, 1로 다시 반복
ex) aaabdaaabac -> Z=aa, ZabdZabac -> Y=ab, Z=aa, ZYdZYac -> X=ZY, XdXac
Looking into the Dataset
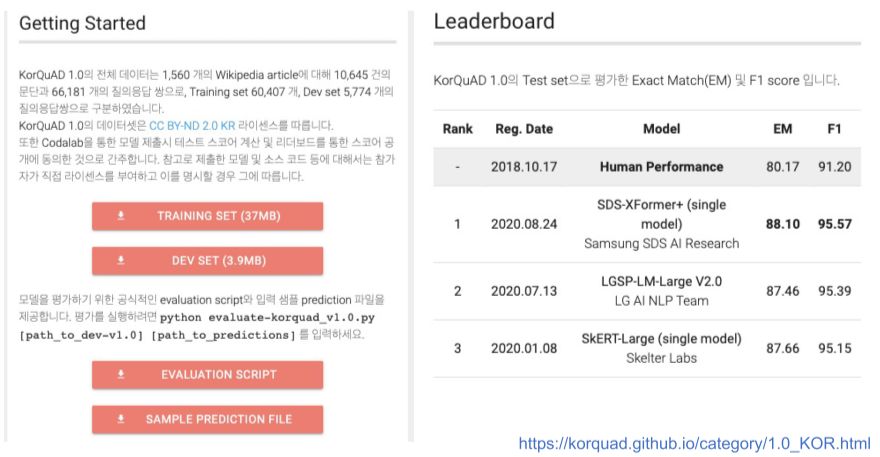
KorQuAD란, LG CNS가 AI 언어지능 연구를 위해 공개한 질의응답/기계독해 한국어 데이터셋
- 인공지능이 한국어 질문에 대한 답변을 하도록 필요한 학습 데이터셋
- 위키피디아 문서 + 크라우드 소싱을 통해 제작한 질의응답 쌍으로 구성되어 있음
- 누구나 데이터를 내려받고, 학습한 모델을 제출하고 공개된 리더보드에 평가 받을 수 있음
- 2.0은 보다 긴 분량의 문서, 복잡한 표와 리스트 등을 포함하는 HTML 형태로 표현
Title과 Context, Question-Answer Pairs로 이루어져 있다.

HuggingFace datasets 라이브러리에서 ‘squad_kor_v1’, ‘squad_kor_v2’로 불러올 수 있음
- 여러 라이브러리에 호환됨, memory-mapped, cached 등의 메모리 공간 부족, 전처리 과정 등을 피할 수 있음
- 기본적인 데이터셋 함수 구현되어 있음.

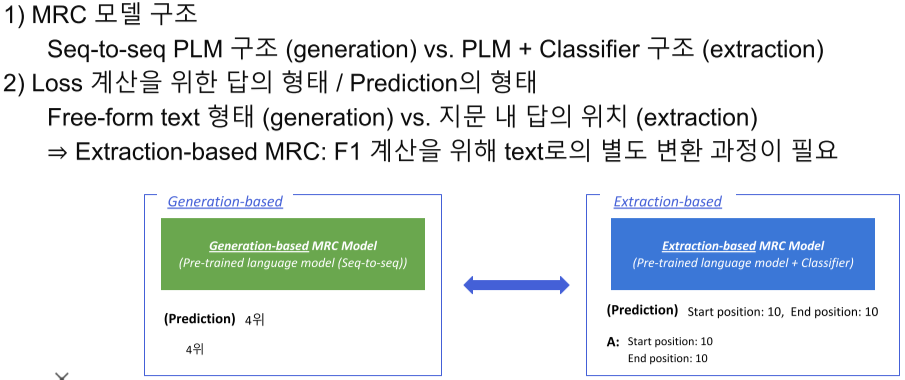
Extraction-based MRC
Extraction-based MRC
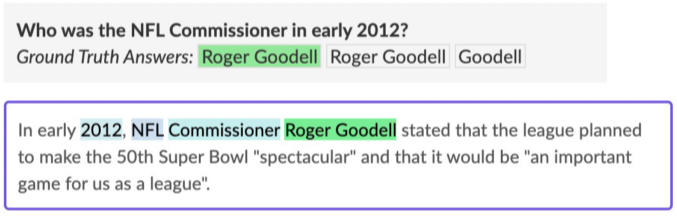
질문(question)의 답변(answer)이 항상 주어진 지문(context)내에 span으로 존재하는 문제
MRC 데이터 셋으로 SQuAD, KorQuAD, NewsQA, Natural Questions 등이 존재한다.
- Hugging Face Dataset에서 구하면 쉽다.
Text를 생성하는 것이 아니라, 답의 시작점과 끝점을 찾는 문제가 된다.
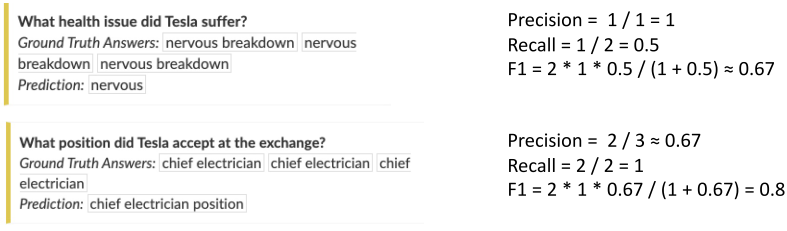
분류(Classification) 문제와 비슷하며, 주로 이전에 배웠던 F1 score나 EM을 지표로 삼는다.
- 답이 여러개가 될 수 있을 때는 보통 가장 높은 것을 인정해준다.
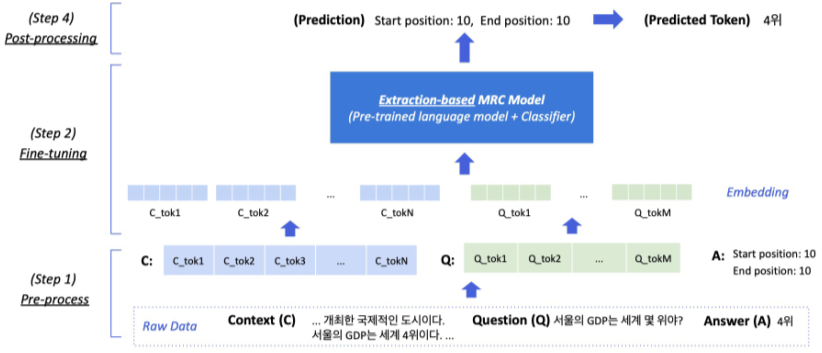
Pre-processing
다음과 같은 예시의 data를 전처리한다고 생각하자.

Tokenization 단계
텍스트를 작은 단위(Token)으로 나누는 단계
띄어쓰기, 형태소, subword 등 여러 단위 토큰 기준이 사용되지만 최근 Out of Vcabulary(OOV) 문제를 해결하고 정보학적으로 이점을 가진 Byte Pair Encoding(BPE)을 주로 사용함
BPE 방법론에는 WordPiece Tokenizer가 존재.
“미국 군대 내 두번째로 높은 직위는 무엇인가?” => [‘미국’, ‘군대’, ‘내’, ‘두번째’, ‘##로’, ‘높은’, ‘직’, ‘##위는’, ‘무엇인가’, ‘?’]
Tokenizing과 Speicial Token을 이용해 Tokenizing 하면 결과가 다음과 같다.


Attention Mask
입력 시퀀스 중에서 attention을 연산할 때 무시할 토큰을 표시
0은 무시, 1은 연산에 포함되며, 보통 [PAD]와 같은 의미가 없는 특수토큰을 무시하기 위해 사용

input_ids 또는 input_token_ids

입력된 질문의 형태를 인덱스의 형태로 바꾸어 학습을 용이하게 만든다.
Token Type IDs
입력이 2개 이상의 시퀀스(예: 질문 & 지문),일때, 각각에게 ID를 부여하여 모델이 구분해서 해석하도록 유도

모델 출력값
정답은 문서내 존재하는 연속된 단어토큰(span)이므로, span의 시작과 끝 위치를 알면 정답을 맞출 수 있음
Extraction-based에서 답안을 생성하기 보다, 시작위치와 끝위치를 예측하도록 학습한. 즉 Token Classification 문제로 치환.

Fine-tuning
BERT의 output vector의 각 element는 해당 token이 답의 시작 또는 끝일 확률을 나오게 만든다.
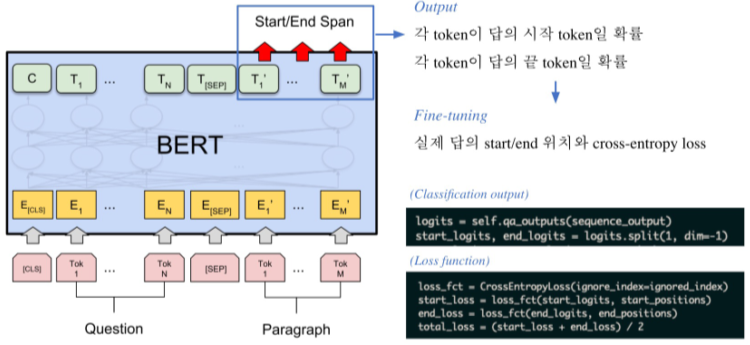
Post-processing
불가능한 답 제거
- End position이 start position보다 앞에 있는 경우 제거 (예상 답변 부분의 앞부분이 뒷부분 보다 뒤에 있을 경우)
-
예측한 위치가 context를 벗어난 경우 제거(ex) question이 있는 곳에 답이 태깅)
- 미리 설정한 max_answer_length 보다 길이가 더 긴 경우
최적의 답 찾기
-
Start/end position prediction에서 score(logits)가 가장 높은 N개를 각각 찾는다.
-
불가능한 start/end 조합 제거
-
가능한 조합들 중 score의 합이 큰 순서대로 정렬
-
Score가 가장 큰 조합을 최종 예측으로 선정
-
Top-k 가 필요한 경우 차례대로 내보낸다.
Generation-based MRC
Generation-based MRC

주어진 지문과 질의(question)을 보고, 답변을 생성하는 Generation 문제
지표는 동일하게 EM과 F1을 쓸 수 있다, 추가적으로 ulgi? blue? 같은 다른 지표를 사용할 수도 있다.
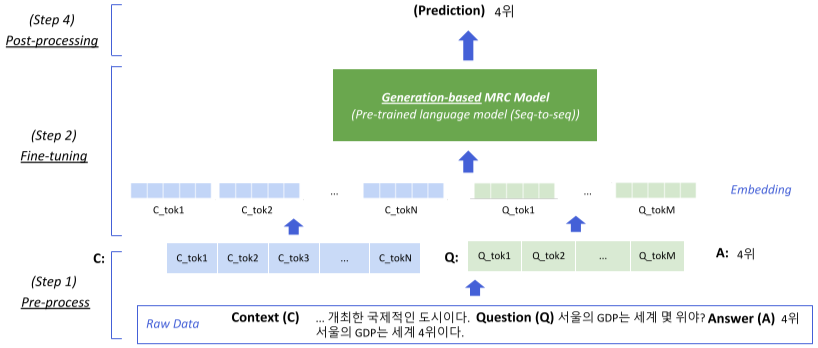
Extraction base와 달리 seq 2seq 구조를 이용하며, output의 형태 또한 답의 위치가 아닌 생성된 답을 사용하게 된다.
Pre-processing
오히려 Extraction base 보다 더욱 쉬워졌다.
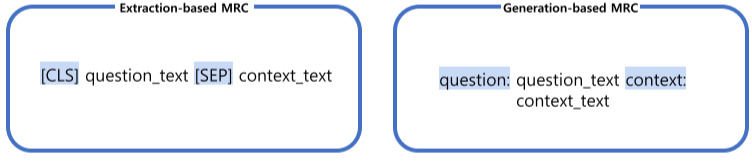
입력의 경우, 동일하게 WordPiece Tokenizer를 활용하며, Special Token 사용이 조금 다르다.
Extraction-based MRC에선 CLS, SEP, PAD 토큰을 사용 했지만
Generation-based MRC에서는 토큰을 자연어를 이용한 텍스트 포맷으로 사용한다.
Attention mask는 이전 BERT와 같지만 우리가 사용할 Generation-based MRC를 위한 BART 모델의 경우 입력에 token_type_ids가 존재하지 않는다, 즉, 여러 입력 sequence 간의 구분이 없음.
- 직접 제공하지 않아도 모델이 충분히 구분 가능하고, 성능 차이가 없어서 지워짐.
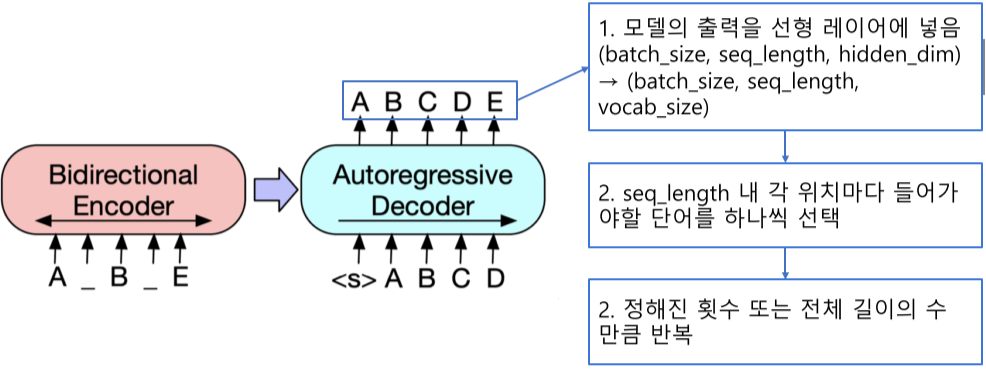
Model
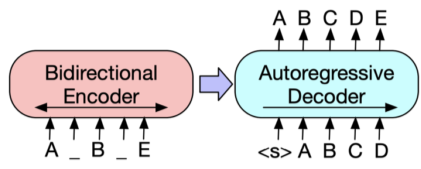
BART
기계 독해, 기계 번역, 요약, 대화 등 sequence to sequence 문제의 pre-training을 위한 denoising autoencoder (noise(mask)를 없애는 방식으로 학습하는 것)
BART의 인코더는 BERT처럼 bi-directional이며, BART의 디코더는 GPT처럼 uni-directional (autoregressive)
- 아래 1일 경우 정보가 주워진다는 의미이다.
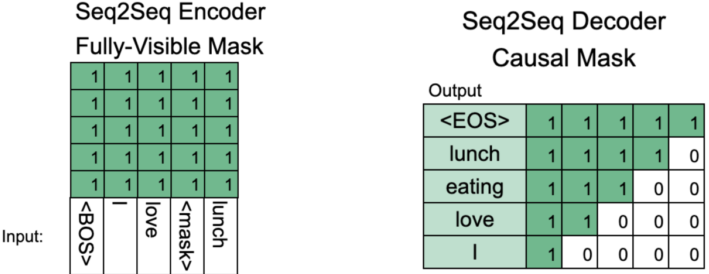
Pre-training BART
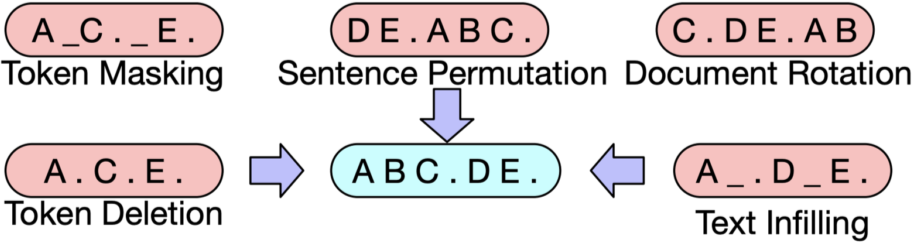
BART는 텍스트에 노이즈를 주고 원래 텍스트를 복구하는 문제를 푸는 것으로 Pre-training함
Post-processing
Decoding
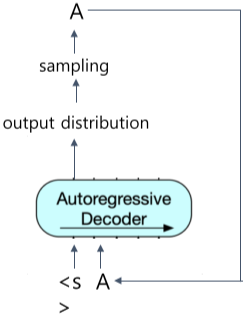
디코더에서 이전 스텝에서 나온 출력이 다음 스텝의 입력으로 들어감, 이를 autoregressive라고 함
맨 첫 입력은 문장 시작을 뜻하는 스페셜 토큰
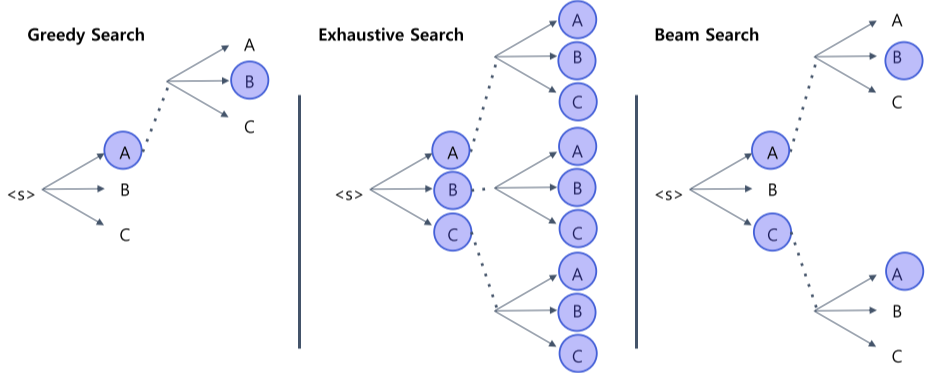
output을 생성할 때는 대부분 Beam Search 방법을 사용한다.
Passage Retrieval - Sparse Embedding
Introduction to Passage Retrieval
Passage Retrieval
Database 등에서 질문(query)에 맞는 문서(Passage)를 찾는 것
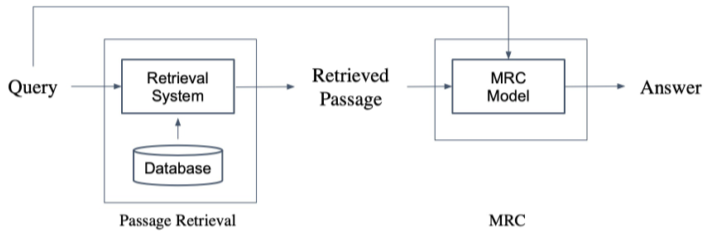
이를 MRC와 결합하여 Open-domain Question Answering 같은 2-stage 질문 답 찾기 등이 가능하다.
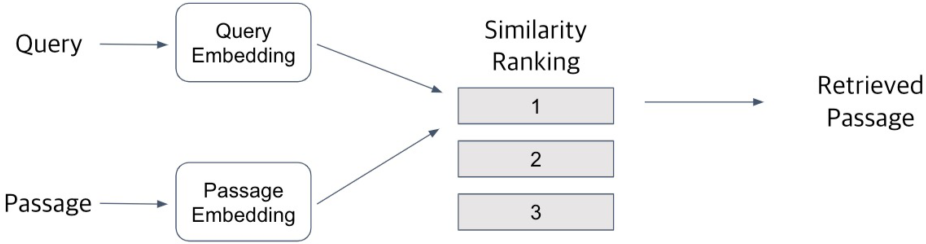
Query(실시간)와 Passage(또는 문서, 미리 해놓음)를 임베딩한 뒤 유사도로 랭킹을 매기고, 유사도(inner product 또는 공간상의 거리)가 가장 높은 Passage를 선택
Passage Embedding and Sparse Embedding
Passage Embedding Space
Passage Embedding의 벡터 공간이며, 벡터화된 Passage를 이용하여 Passage 간 유사도 등을 알고리즘 계산 가능
Sparse Embedding
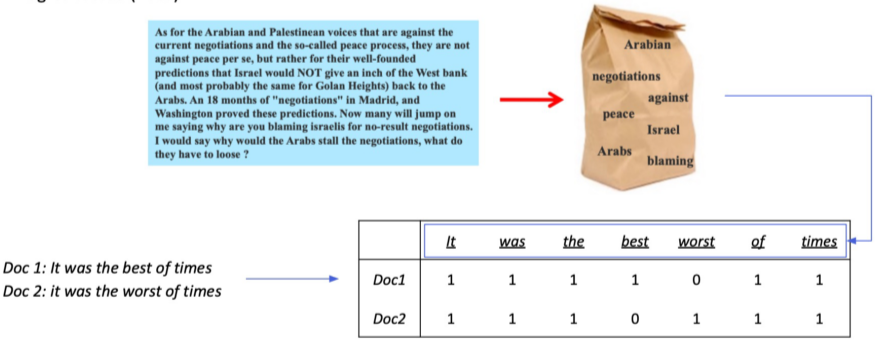
Dense하지 않고 0이 아닌 숫자가 드문 embedding 방법, Bag-of-Words(BoW)가 예시이다.
위의 경우가 BoW의 방법으로, 단어의 종류만큼의 차원을 가진 벡터에서 단어가 존재할 경우 해당 단어의 차원을 1로 놓아 문서를 표현하는 방법이다.
단어나 문서의 길이가 너무 많으면 차원의 수가 엄청 커진다.
- BoW를 구성하는 방법 -> n-gram 방법
- unigram(1-gram): It was the best of times => It, was, the, best, of, time
- bigram(2-gram): It was the best of times => It was, was the, the best, best of, of times(2개씩 짝지어 단어로, 기하급수적으로 vocab 사이즈(차원 수)가 크지만, 더욱 정확한 Embedding 값을 가져올 수 있다. )
- Term value를 결정하는 방법(ex)TF-IDF)
- Term이 document에 등장하는지 (binary)
- Term이 몇번 등장하는지 (term frequency), 등
특징으로,
- Dimension of embedding Vector = number of terms
- 등장하는 단어가 많아질수록 차원 수 증가
- N-Gram의 n이 커질수록 증가
- Term overlap을 정확하게 잡아 내야 할 때 유용(즉, 정확히 해당 단어가 필요하다면 잡아낼 수 있음).
- 반면, 의미(semantic)가 비슷하지만 다른 단어인 경우 비교가 불가(즉, 비슷한 의미를 가진 단어는 찾을 수 없음)
TF-IDF (Term Frequency - Inverse Document Frequency)
TF와 IDF를 고려하여 Embedding 하는 방법
TF(Term Frequency)
해당 문서 내 단어의 등장 빈도, 많이 등장할 수록 높다.
보통 다음과 같은 방법으로 측정한다.
- Raw count, 그냥 등장 숫자 세기, 잘 안사용한다.
- Adjusted for doc lengh: raw count/ num words (TF), 비율로 측정
- OTher variants: binary, log normalization, etc.
IDF (Inverse Document Frequency)
단어가 제공하는 정보의 양, 주로 명사나 형용사가 포함되며, 정보를 많이 가지는 단어일 수록 크다.
로그(모든 다큐먼트 갯수/등장한 다큐멘터 수)로 구한다
한 문서의 등장 빈도인 TF와 무관하다.
\(IDF(t) = log\frac{N}{DF(t)}\\
Document\ Frequency (DF) : Term\ t가\ 등장한\ document의\ 개수\\
N: 총\ document의\ 개수\)
Combine TF & IDF
TF와 IDF를 곱한 값, 높을 수록 정보를 많이 담고 있는 단어이다.
TF-IDF(t, d): TF-IDF for term t in document d,
\(TF(t,d)\times IDF(t)\)
a, the 같은 관사는 TF가 높아도 IDF가 0에 가까우므로 낮게 된다.
고유명사 등은 IDF가 아주 커지면서 TF-IDF 값이 크게 된다.
TF-IDF를 이용해 유사도 구하기
Lab.[MRC-2]TF-IDF 참조
목표: 계산한 TF-IDF를 가지고 사용자가 물어본 질의에 대해 가장 관련있는 문서를 찾자.
- 사용자가 입력한 질의를 토큰화
- 기존에 단어 사전에 없는 토큰들은 제외
- 질의를 하나의 문서로 생각하고, 이에 대한 TF-IDF 계산
- 질의 TF-IDF 값과 각 문서별 TF-IDF 값을 곱하여 유사도 점수 계산
- 가장 높은 점수를 가지는 문서 선택
BM25
TF-IDF의 개념을 바탕으로, 문서의 길이까지 고려하여 점수를 매김
- TF 값에 한계를 지정해두어 일정한 범위를 유지하도록 함
- 평균적인 문석의 길이보다 더 작은 문서에서 단어가 매칭된 경우 그 문서에 대해 가중치를 부여
- 실제 검색 엔진, 추천 시스템 등에서 아직까지도 많이 사용되는 알고리즘
Passage Retrieval -Dense Embedding
Introduction to Dense Embedding
Passage Embedding은 구절(Passage)을 벡터로 변환하는 것을 의미하며,

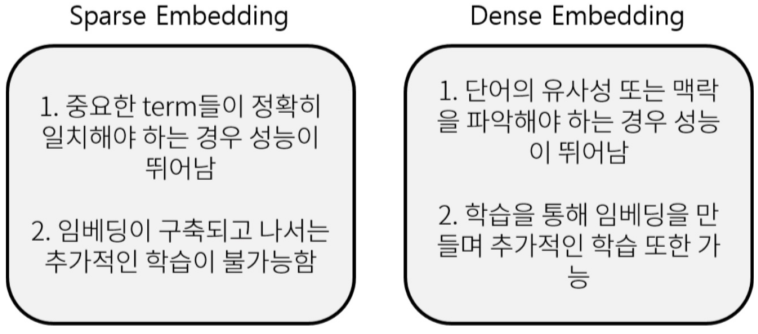
Sparse Embedding은 TF-IDF가 대표 예시로, 단점으로 차원의 수가 크고 비슷한 단어의 유사성을 고려하지 못한다.
(Compressed format으로 차원의 수 문제는 해결가능 하다)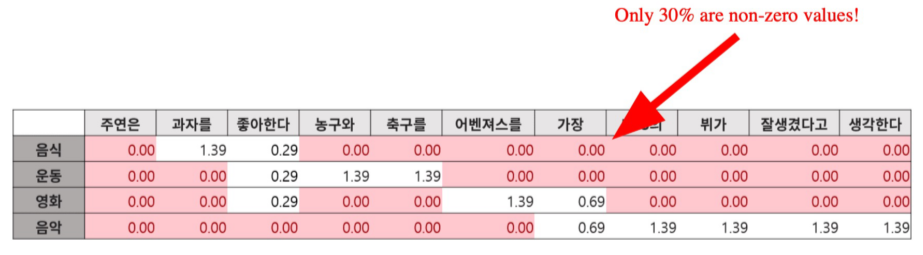
Dense Embedding
Sparse Embedding의 단점을 보완하기 위해 나타남
- 더 작은 차원의 고밀도 벡터 (length = 50 - 1000)
- 각 차원이 특정 term에 대응되지 않음
- 대부분의 요소가 non-zero

Dense는 Sparse에 비해 vector들의 유사성을 파악하기 쉽고, 알고리즘 또한 더욱 많은 것을 적용할 수 있다.
각자의 장점을 고려해서 둘다 동시에 사용하거나 서로 보완한다.
주로 두가지 모델을 이용해 Context의 벡터를 구하는 모델과 question의 벡터를 구하는 모델을 이용해 dot product, space similarity 등을 계산하여 유사도를 비교해 결정한다.
Training Dense Encoder
context를 Dense Embedding으로 Encoding 하는 Dense Encoder의 모델로, BERT, ELMo와 같은 Pre-trained language model(PLM)이 자주 사용하며, [CLS] token이 encoding된 output이 해당 context의 최종 Embedding output으로 사용된다.
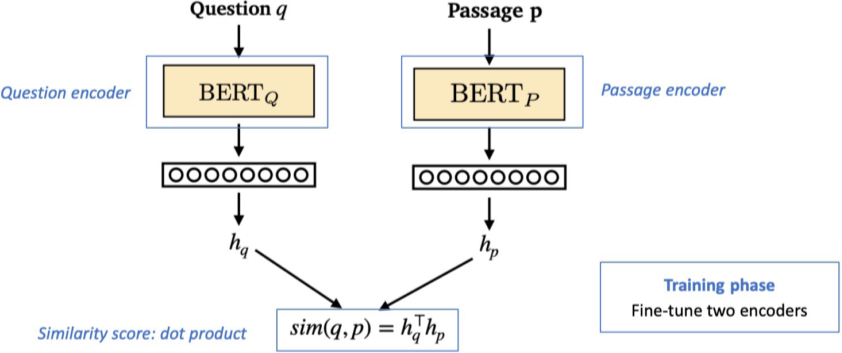
연관된 question과 passage dense embedding(또는 inner product) 간의 거리의 좁음, 즉, similarity를 높이는 것이 목표이며, 이를 통해 question/passage의 연관성을 알 수 있다.
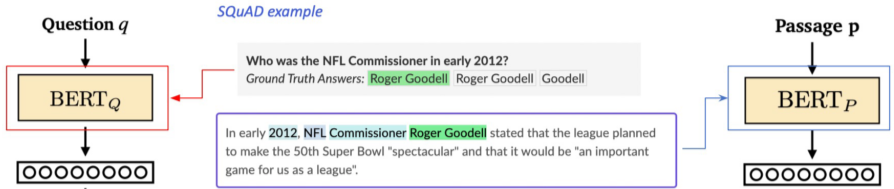
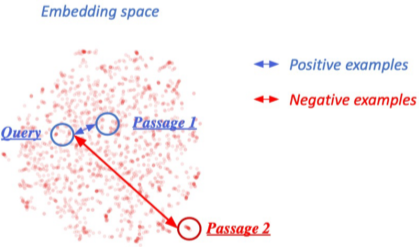
1) 연관된 question과 passage 간의 dense embedding 거리를 좁히는 것 (higher similarity) -> positive
2) 연관 되지 않은 question과 passage 간의 embedding 거리는 멀어야 함 -> Negative
- 이를 학습하기 위해 Negative sampling을 통해 학습한다
- Corpus 내에서 랜덤하게 뽑거나, 높은 TF-IDF 스코어를 가지지만 답을 포함하지 않는 샘플 같은 헷갈리는 샘플을 뽑는다.
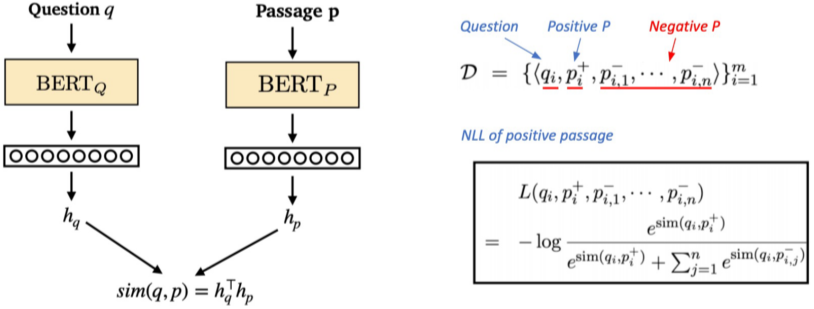
이때 loss로 Positive passage에 대해서 negative log likelihood (NLL) loss를 사용한다.
분모에는 모든 passage의 similarity score, 분자에는 positive sample의 score를 놓은 뒤, negative log를 취하여 계산된다.
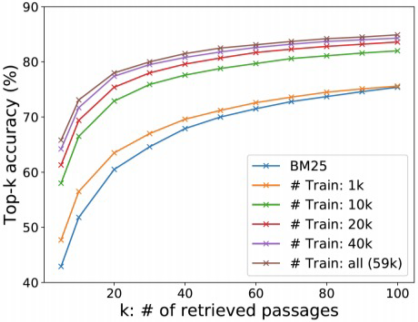
또한 Top-k retrieval accuracy(retrieve된 passage 중에 답을 포함하는 passage의 비율)을 계산해서 성능을 측정한다.
Passage Retrieval with Dense Encoder
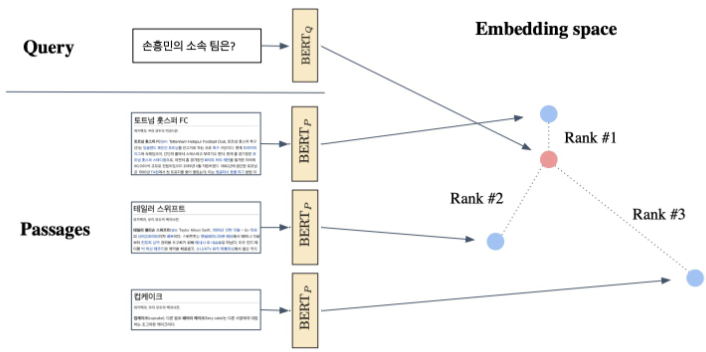
- From dense encoding to retrieval
Inference: Passage(미리 embedding되있음)와 query를 각각 embedding한 후, query로부터 가까운 순서대로 passage의 순위 매김
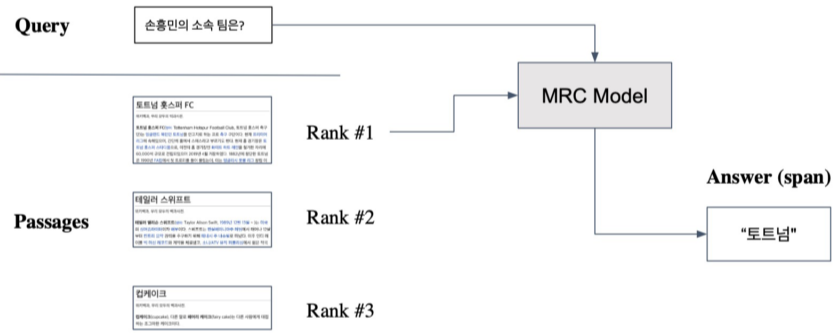
- From retrieval to open-domain question answering
Retriever를 통해 찾아낸 Passage을 활용, MRC 모델로 답을 찾음.
이러한 과정을 학습 방법 개선(DPR 등)이나 인코더 모델 개선 (더 좋은 모델), 데이터 개선 등으로 성능을 향상 시킬 수 있다.
Passage Retrieval - Scaling Up
Passage Retrieval and Similarity Search
MIPS(Maximum Inner Product Search)
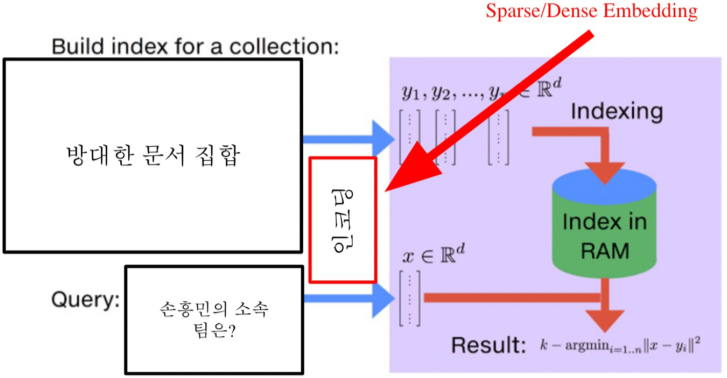
주어진 질문(query) 벡터 q에 대해 Passage 벡터 v들 중 가장 질문과 관련된 벡터를 찾아야함
이때 현업에서는 주로 inner product로 구하는 경우가 많음.(좀더 효율적임)
\(argmax_{vi\in V}q^T_{v_i}\\
argmax:검색(search),\ 인덱싱된\ 벡터들\ 중\ 질문\ 벡터와\\ 가장\ 내적값이\ 큰\ 상위\ k개의\ 벡터를\ 찾는\ 과정 \\
q^T_{v_i}:인덱싱(indexing),\ 방대한\ 양의\ passage\ 벡터들을\ 저장하는\ 방법\)
이전에 배운 방법은 brutre-force(exhaustive) search 방법으로, 저장해둔 모든 Sparse/Dense 임베딩에 대해 일일이 내적값을 계산하여 가장 값이 큰 Passage를 추출
문제는 검색해야할 데이터가 방대(위키피디아만 500만개, 그이상 수십억, 조단위 까지 커질 수 있음)
즉, 더이상 모든 문서 임베딩을 일일히 보면서 검색할 수 없음
Tradeoffs of similarity search
즉, 모두 완벽하게 할 순 없고 다음 3가지 중에 Trade-off 해야한다.
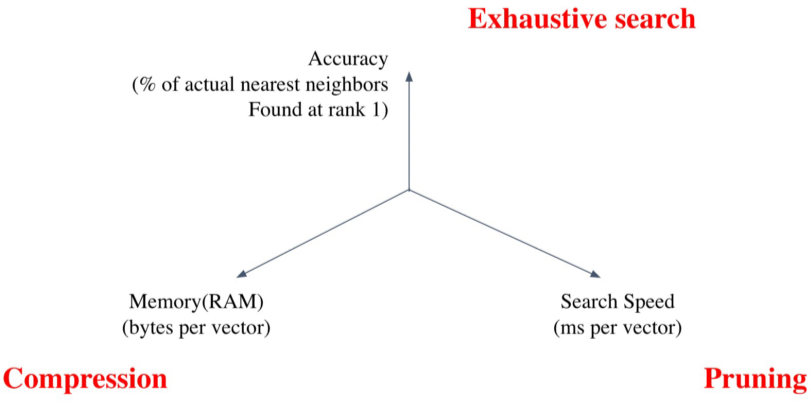
1) Search Speed : 쿼리 당 유사한 벡터를 k개 찾는데 걸리는 시간, Pruning으로 개선할 수 있다.
- 일반적으로 속도를 빠르게 하면 정확도가 떨어진다.
2) Memory Usage : 벡터를 저장할 공간, Compression으로 개선할 수 있다.
3) Accuracy : 검색결과의 질, Exhaustive search로 개선할 수 있다.
또한, 코퍼스(corpus)의 크기가 커질수록 탐색 공간이 커지고 검색이 어려워지며, Memory space 또한 많이 요구 됨
- 그래도 Dense Embedding의 경우 Sparse Embedding 보단 낫다.
Approximating Similarity Search
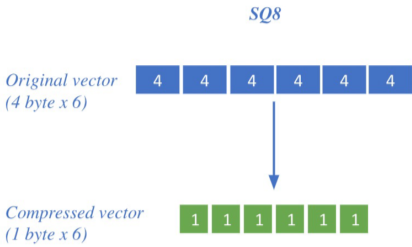
Compression - Scalr Quantization(SQ)
Vector를 압축하여, 하나의 Vector가 적은 용량을 차지하도록 함,
압축량이 클수록 메모리 사용량은 줄고 정보 손실을 늘어난다.
상단 그림의 4byte의 float point를 1-byte의 unsigned integer로 압축하는 Scalar quantization이 예시
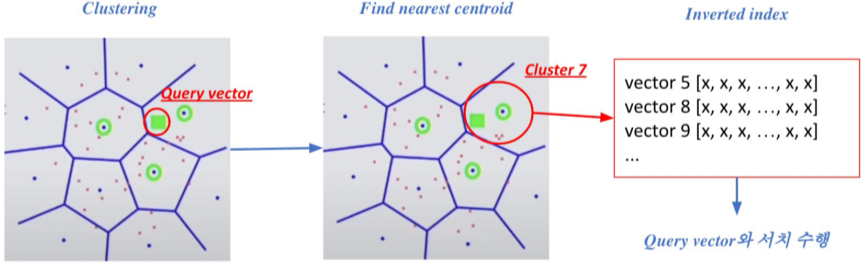
Pruning - Inverted File (IVF)
Search space를 줄여 search 속도 개선(dataset의 subset만 방문)
=> Clustering + Inverted file을 활용한 search
1) Clustering: 전체 vector space를 k 개의 cluster로 나눔 (ex. k-means clustering)
2) Inverted file (IVF) : Vector의 index = inverted list structure
=> (각 cluster의 centroid id)와 (해당 cluster의 vector들)이 연결되어있는 형태
즉,
- 주어진 query vector에 대해 근접한 centroid 벡터를 찾음
- 찾은 cluster의 inverted list 내 vector들에 대해 서치 수행
Introduction to FAISS
FAISS란, similarity search와 dense vector의 clustering에 사용되는 라이브러리다.
Passage Retrieval with FAISS
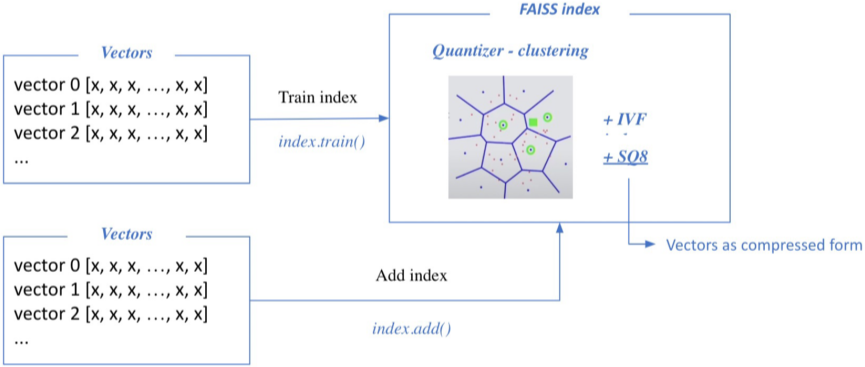
1) Train index and map vectors
- Train phase과 add phase로 나뉜다.
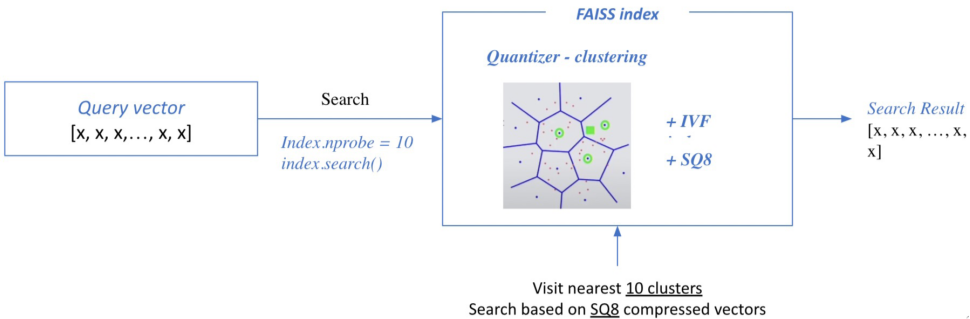
2) Search based on FAISS index
Scaling up with FAISS
실습
Linking MRC and Retrieval
Introduction to Open-domain Question Answert (ODQA)
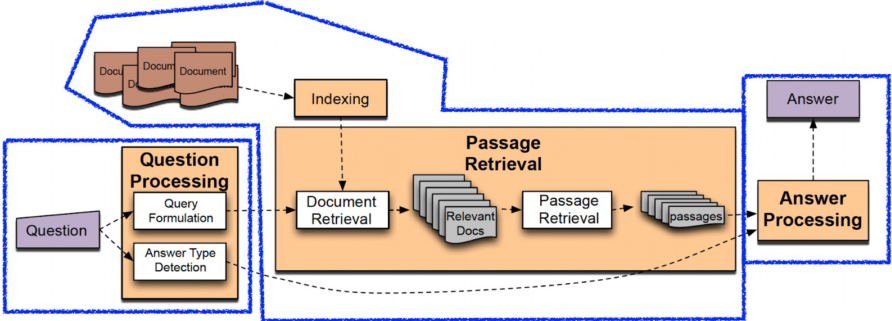
ODQA는 지문이 따로 주어지지 않으며 방대한 World Knowledge에 기반해서 질의 응답
Question processing + Passage retrieval + Answer processing 이 합쳐진 형태
1) Question processing
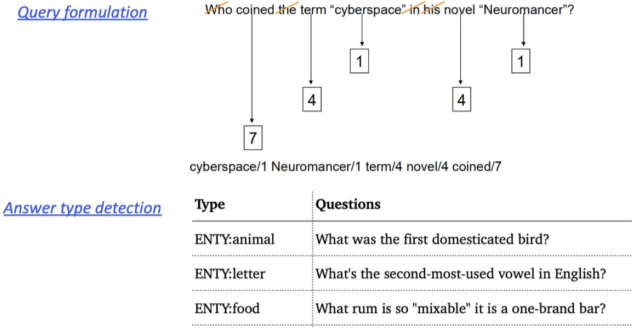
Query formulation: 질문으로부터 키워드를 선택 / Answer type selection (ex. LOCATION : country)
2) Passage retrieval
기존의 IR 방법을 활용해서 연관된 document를 뽑고, passage 단위로 자른 후 선별 (Named entity/Passage 내 question 단어의 개수 등과 같은 hand-crafted feature 활용)
3) Answer processing
Hand-crafted features와 heuristic을 활용한 classifier, 주어진 question과 선별된 passage들 내에서 답을 선택
Retriever-Reader Approach
Retriever-Reader 접근 방식은 데이터베이스에서 관련있는 문서를 검색한 뒤, 검색된 문서에서 질문에 해당하는 답을 찾아내는 방식
즉 Retriever의 입력은 문서셋(Document corpus)와 질문(qeury)이며 출력은 관련성 높은 문서(document)이다.
- 이때 TF-DF, BM25를 활용하면 학습하지 않고, Dense embedding일 경우 학습이 필요하다.
Reader의 입력은 Retrieved된 문서(document)과 질문(query)이며, 출력은 답변(answer)이다.
- sQuAD와 같은 MRC 데이터셋으로 학습하며, 학습데이터 추가를 위해 Distant supervision을 활용한다.
Distant supervision
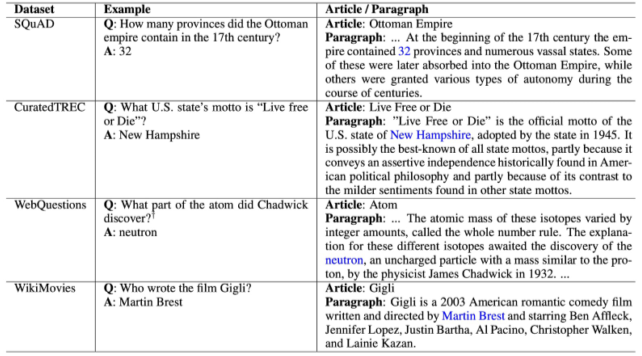
질문-답변만 있는 데이터셋 (CuratedTREC, WebQuestions, WikiMovies)에서 MRC 학습 데이터 만들기, Supporting document가 필요함.
- 위키피디아에서 Retriever를 이용해 관련성 높은 문서를 검색
- 너무 짧거나 긴 문서, 질문의 고유명사를 포함하지 않는 등 부적합한 문서 제거
- answer가 exact match로 들어있지 않은 문서 제거
- 남은 문서 중에 질문과 (사용 단어 기준) 연관성이 가장 높은 단락을 supporting evidence로 사용함
Inference
- Retriever가 질문과 가장 관련성 높은 5개 문서 출력
- Reader는 5개 문서를 읽고 답변 예측
- Reader는 예측한 답변 중 가장 score가 높은 것을 최종 답으로 사용함
Issues and Recent Approaches
Different granularites of text at indexing time
위키피디아에서 각 Passage의 단위를 문서, 단락, 또는 문장으로 정의할지 정해야 함. 이렇게 정한 단위 기준을 Granularity라고 함.
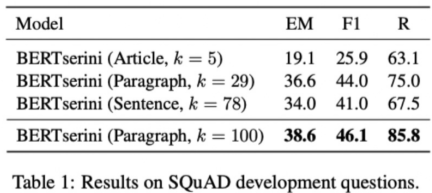
또한, Retriever 단계에서 몇 개의 문서를 정할지 고려해야하며(top-k), Granularty에 따라 k가 달라짐.
(e.g article -> k=5, paragraph -> k=29, sentence -> k=78)

Single-passage training VS Multi-passage training
Single-passage : 현재 우리는 k개의 passages들을 reader이 각각 확인하고 특정 answer span에 대한 예측 점수를 나타냄, 그리고 이 중 가장 높은 점수를 가진 answer span을 고르도록 함
이 경우 각 retrieved passages들에 대한 직접적인 비교라 볼 수 없으며, 이를 방지하기위해 Multi-passage가 등장
Multi-passage는 retrieved passages 전체를 하나의 passage로 취급하고, reader 모델이 그 안에서 answer span 하나를 찾도록 하는 것,
단, 문서가 너무 길어지므로 GPU에 많은 메모리가 할당되야 하며, 처리해야하는 연산량이 많아짐
Importance of each passage
Retriever 모델에서 추출된 top-k passage들의 retrieval score를 reader 모델에 전달, 단순히 reader가 span만 보고 판단하지 않고 context의 적절성도 고려함
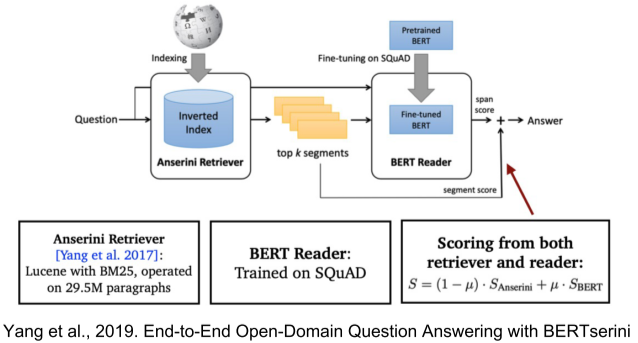
Reducing Training Bias
Definition of Bias
Bias의 종류
- 학습에서의 Bias :
- 학습할 때 과적합을 막거나 사전 지식을 주입하기 위해 특정 형태의 함수를 선호하는 것 (inductive bias)
- 경향과 의도를 위해 일부러 집어넣는 경우가 많음
- A Biased World :
- 현실 세계가 편향되어 있기 때문에 모델에 원치 않는 속성이 학습되는 것 (historical bias)
- 성별과 직업 간 관계 등 표면적인 상관관계 때문에 원치 않는 속성이 학습되는 것 (co-occurrence bias)
- Gender Bias : 특정 성별과 행동을 연관시켜서 예측 오류가 발생(의사의 사진은 높은 확률로 여성을 남성으로 잘못 판단함.)
- Bias in Data Generation :
- 입력과 출력을 정의한 방식 때문에 생기는 편향 (specification bias)
- 데이터를 샘플링한 방식 때문에 생기는 편향 (sampling bias)
- 리터러시 다이제스트 잡지의 정반대의 여론 조사 결과 : 잡지 정기 구독자, 자동차 등록자, 사교클럽 명단 등에서 샘플 채취-> 부자들만 샘플을 채취한 것이 원인으로, 예측 실패
- 어노테이터의 특성 때문에 생기는 편향 (annotator bias)
Bias in Open-domain Question Answering
Retriever-Reader Pipeline에서 Reading Comprehension 부분의 bias에 집중함.
만약 reader 모델이 한정된 데이터셋에서만 학습된다면, Reader는 항상 정답이 문서 내에 포함된 데이터쌍만(Positive)을 보게 됨
특히 SQuAD와 같은 (Context, Query, Answer)이 모두 포함된 데이터는 positive가 완전히 고정되어 있음
예를 들어 Inference 시 만약 데이터 내에서 찾아볼 수 없었던 새로운 문서를 주면, Reader 모델을 문서에 대한 독해능력이 떨어져 정답을 내지 못함(ex) 학습시에 문학과 관련 주제만 주어졌는데, 실제 Inference 때에는 공학관련 지문들이 나온다면?)
이를 막기 위해
-
Train negative examples
훈련 시, 잘못된 예시를 보여줘야 retriever이 negative한 내용들은 먼 곳에 배치할 수 있음, 또한, negative sample 또한 다양성을 고려해야 함.
Corpus 내에서 랜덤하게 뽑거나 좀더 헷갈리는 negative 샘플들 뽑기 위해 높은 BM25/ TF-IDF 매칭 스코어를 가지지만, 답을 포함하지 않는 샘플을 뽑거나, 같은 문서에 나온 다른 Passage/Question 선택
-
Add no answer bias
입력 시퀀스의 길이가 N일 시, 시퀀스의 길이 외 1개의 토큰이 더 있다고 생각하기,
훈련 모델의 마지막 레이어 weight에 훈련 가능한 bias를 하나 더 추가
Softmax로 answer prediction을 최종적으로 수행할 때, start end 확률이 해당 bias 위치에 있는 경우가 가장 확률이 높으면 이는 “대답 할 수 없다”라고 취급
Annotation Bias from Datasets
Annotaion Bias란, ODQA 학습 시 기존의 MRC 데이터셋 활용시, ODQA 세팅에는 적합하지 않음 bias가 데이터 제작 (annotation) 단게에서 발생 가능
예를 들어 SQuAD나 TriviaQA는 질문을 하는 사람이 답을 아는 상태로 tagging 했으므로, 너무 쉬운 학습이 된다.
또한, SQuAD는 고작 500개의 article에서 데이터를 추출했다.
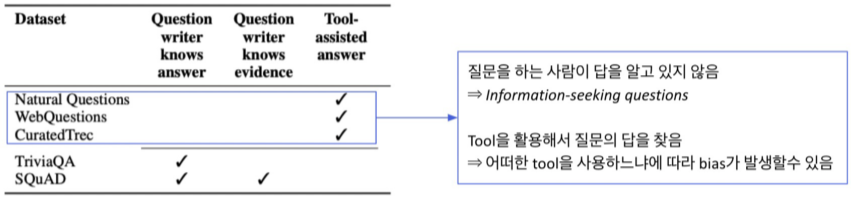
데이터셋 별 성능 차이가 annotation bias로 인해 발생 가능
(BM25 : Sparse embedding / DPR : dense embedding)

이를 막기 위해, Annotation bias를 고려하고 데이터를 모아야 한다.
Natural Questions dataset : Supporting evidence가 주어지지 않은, 실제 유저의 question들을 모아서 dataset을 구성
SQuAD : Passage가 주어지고, 주어진 passage 내에서 질문과 답을 생성하므로, ODQA에 applicable하지 않은 질문들이 존재한다(미국의 대통령은 누구인가? => 어느 시기냐에 따라 다름).
Closed-book QA with T5
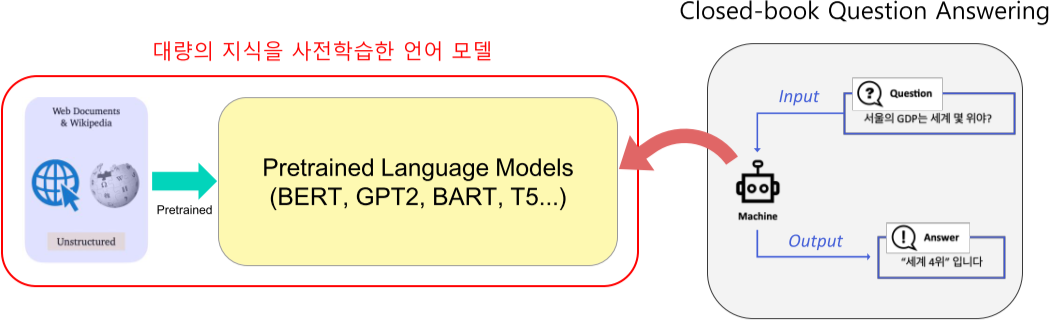
Closed-book Question Answering
사전학습을 통해 대량의 지식을 학습 한 뒤, 굳이 Retriever 단계를 거치지 않고 모델 내부의 Knowledge storage를 통해 Answering 하는 것
GPT-2를 통해 Zero-shot QA를 해보면 어느 정도 대답이 가능함
| Open-book QA | Closed-book QA | |
|---|---|---|
| 지식을 찾는 방식 | 대량의 지식 소스를 특정 문서 단위로 나누어 Dense/Sparse 형태로 표현한 후, query가 들어오면 가장 그와 관련된 문서를 search | 대량의 지식 소스(위키피디아 등)를 기반으로 사전학습된 언어 모델이 그 지식을 기억하고 있을 것이라 가정함. Search 과정 없이 바로 정답을 생성함 |
| 문제점 | 지식 소스를 저장하기 어려움, 검색하는 시간 소요 | 사전학습된 언어 모델이 얼마나 지식을 잘 기억하고 있는지가 매우 중요함, 학습 시간이 길고 parameter수가 큼, 해석하기 어려움 |
Text-to-Text Format
Text-to-Text format : 모든 종류의 문제를 Text 대 Text로 매핑되는 문제로 바꿈
Closed-book QA as Text-to-Text Format
Generation-based MRC와 유사하지만 Context가 없이 질문만 들어가며, Retriever 단계가 없다.
사전학습된 언어 모델은 BART와 같은 seq-to-seq 형태의 Transformer 모델을 사용함
Text-to-Text format에서는 각 입력값(질문)과 출력값(답변)에 대한 설명을 맨 앞에 추가함.
Text-to-Text Format
Text-to-text problem은 input으로 text를 받아서, output으로 새로운 text를 생헝하는 문제이며, 다양한 text processing problem이 text-to-text 문제로 변형될 수 있다.
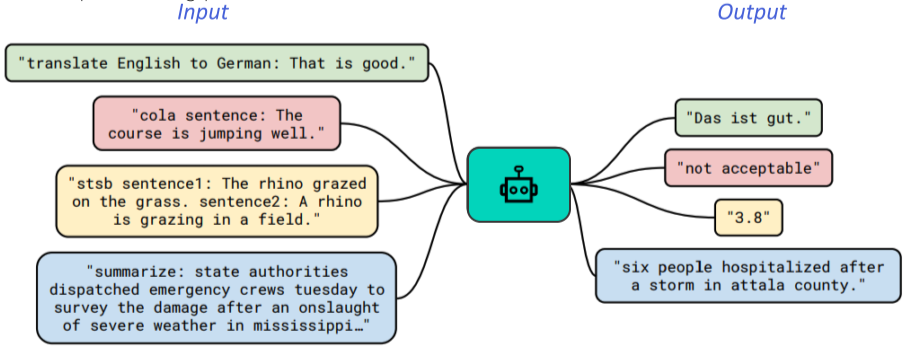
Text-to-Text format 문제의 예시
- Task-specific prefix를 추가하여 특정 task에 알맞은 output text를 생성하도록 함
- Machine translation의 경우, prefix로 translate A to B (A: source language/ B: target language)를 통해 가능
- “translate English to German: That is good” => “Das ist gut.”
- Text classification(MNLI)
- 두개의 sentence가 주어지고 이 둘의 관계를 예측하는 task (neutral, contradiction, entailment)
- Input: “mnli hypothesis:
premise: " - Output: “neutral” or “contradiction” or “entailment”
- Input: “mnli hypothesis:
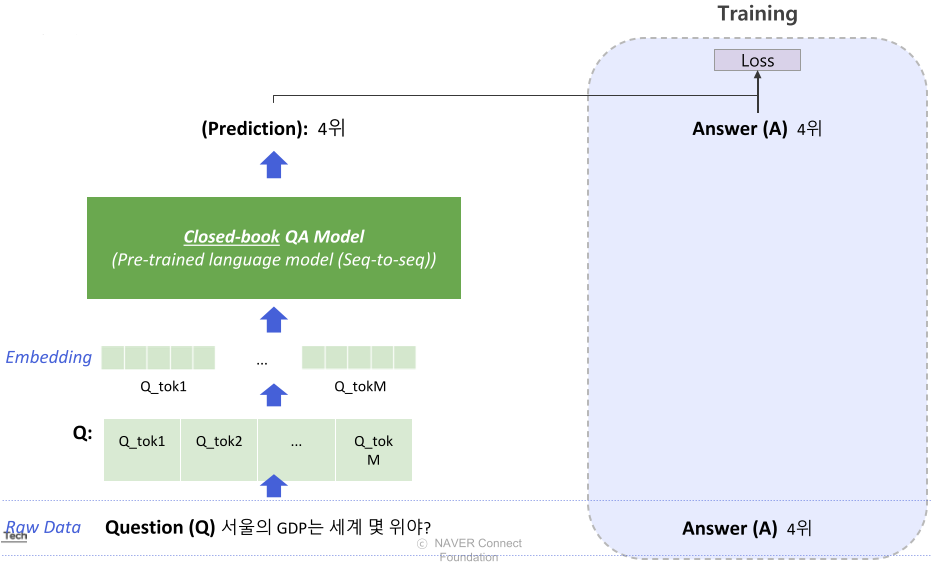
T5
Text-to-Text format이라는 형태로 데이터의 입출력을 만들어 거의 모든 자연어처리 문제를 해결하도록 학습된 seq-to-seq 형태의 Transformer 모델
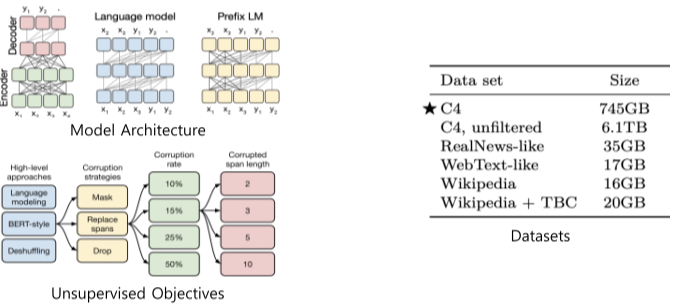
T5의 Pre-training 모델의 경우 다양한 모델 구조, 사전학습 목표, 사전학습용 데이터, Fine-tuning 방법 등을 체계적으로 실험함, 가장 성능이 좋은 방식들을 선택하여 방대한 규모의 모델을 학습 시킴
T5-xlarge의 경우 parameter수가 11B라는 방대한 크기를 자랑함
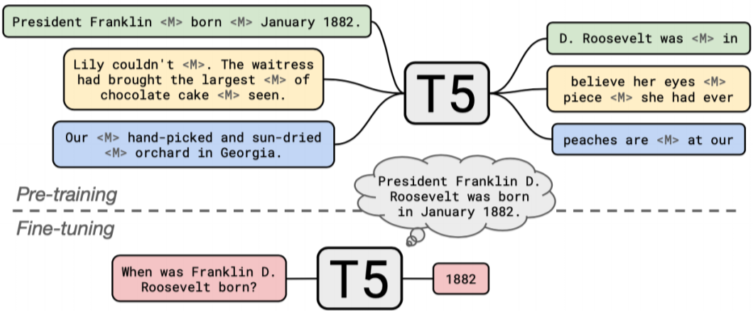
pre-trained 된 T5를 활용 시, Fine-tuning된 MRC 데이터셋(TriviaQA, WebQuestions, Natural Questions)의 QA pair만(context 제외)를 활용하고, Task-specific prefix(어느 데이터셋, 즉 어느 task인가?)을 추가 한뒤, 답이 여러개일 경우도 고려해서 학습 시킴
ex) Input: trivia question :how many legs does a ladybird have? Trget: six
Experiment Results & Analysis
Dataset : Open-domain QA 데이터셋 또는 MRC 데이터셋에서 지문을 제거하고 질문과 답변만 남긴 데이터셋을 활용
Salient Span Masking : 고유 명사, 날짜 등 의미를 갖는 단위에 속하는 토큰 범위를 마스킹한 뒤 학습
Fine-tuning : Pre-trained T5 체크포인트를 Open-domain QA 학습 데이터셋으로 추가 학습

대부분 Open-book 모델보다 성능이 뛰어나며, 모델 크기가 커질수록 성능이 증가했으며, 특히 Salient Span Masking이 성능을 크게 끌어올림
또한, 오답의 62% 가량이 실제 오답이며, 나머지 38%는 중복 답안(Incomplete Annotation), 각기 다른 시기, 관점, 질문의 해석에 따라 정답이 될 수 있거나(Unanswerable), 정답의 다른 표현을 낸 경우(Phrasing Mismatch)이므로 실제 성능은 더욱 증가한다.
Closed-book QA의 한계로,
- 모델의 크기가 너무 커서 계산량이 많고 속도가 느림 -> 더 효율적인 모델 필요
- 모델이 어떤 데이터로 답을 내는지 알 수 없음 -> 결과의 해석 가능성(interpretability)를 높이는 연구 필요
- 모델이 참조하는 지식을 추가하거나 제거하기 어려움
QA with Phrase Retrieval
Phrase Retrieval in Open-Domain Question Answering
기존의 Retriever-Reader 방식은 다음과 같은 한계를 갖는다.
- Error Propagation: 5-10개의 문서만 reader에게 전달
- Query-dependent encoding: query에 따라 정답이 되는 answer span에 대한 encoding이 달라짐
2단계로 이루지 말고 바로 context에서 정답을 search하는 방법인 Phrase Indexing 고안
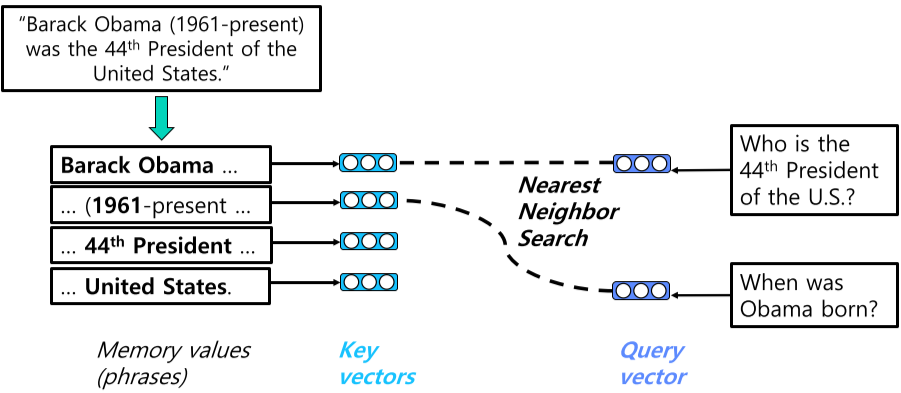
미리 계산된 key vector와 Query vector를 비교하여 답을 구하게 된다.
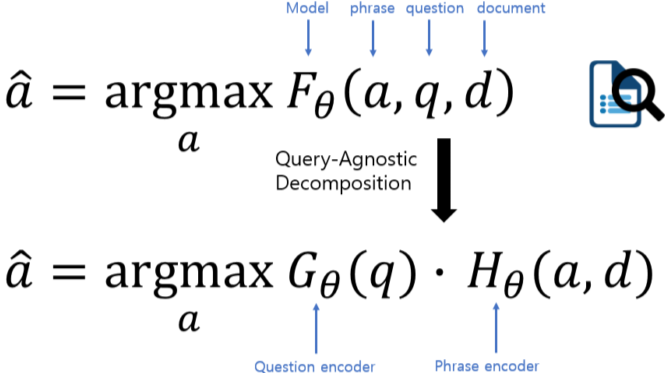
기존의 a,q,d 조합 중 가장 점수가 높은 것을 찾는 방법(F 함수)에서 아래의 Query만(G 함수) 다시 계산하는 방법올 바꾸어 더욱 효율적이다.
다만 실제로 F 함수를 G와 H 함수로 정확히 대체할 수 없어 Approximation 하는 방법을 사용하며, 이때 실제 F 함수값과 G, H 함수 값의 차이인 Decomposition Gap이 성능 하락의 주요 원인이 된다.
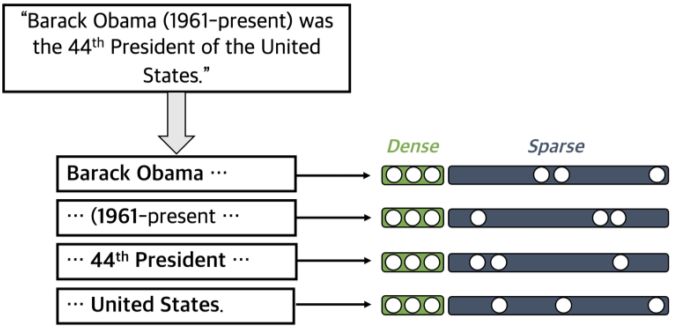
이때, 각 phrase를 vector space 상에 잘 mapping 하기 위해 Dense와 Sparse 임베딩을 둘다 이용하게 된다.
Dense-sparse Representation for Phrases
Dense vectors는 통사적, 의미적 정보를 담는 데 효과적이며,(유연함)
Sparse vectors는 어휘적 정보를 담는 데 효과적이므로, (명확함)
이 둘을 전부 이용하여 phrase (and question) embedding을 할 수 있다.
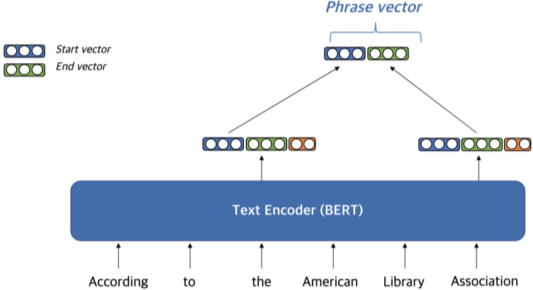
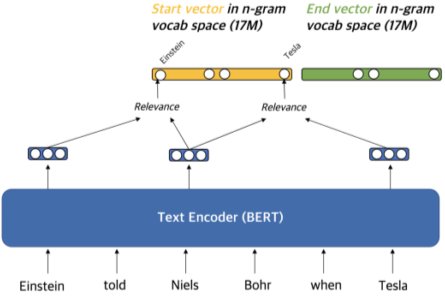
Dense vector를 만드는 방법
- Pre-trained LM (e.g. BERT)를 이용
- Start vector와 end vector를 재사용해서 메모리 사용량 줄임
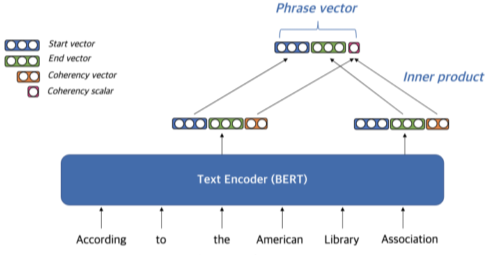
Coherency vector 생성법
- phrase가 한 단위의 문장 구성 요소에 해당하는지를 나타냄
- 구를 형성하지 않는 phrase를 걸러내기 위해 사용함
- Start vector와 end vector를 이용하여 계산
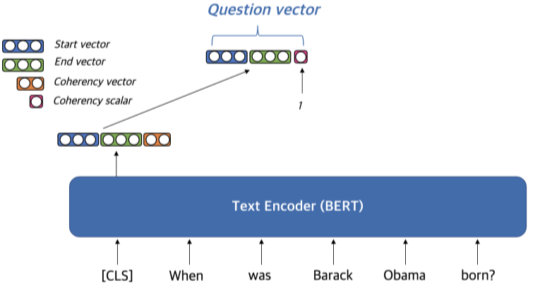
Question embedding 생성법
- Question을 임베딩할 때는 [CLS] 토큰 (BERT)을 활용
Sparse vector를 만드는 방법
- 문맥화된 임베딩(contextualized embedding)을 활용하여 가장 관련성이 높은 n-gram으로 sparse vector 구성
Scalability Challenge
Wikipedia 같은 대량의 phrases를 처리하기 위해, Storage, indexing, search의 scalabilty가 고려되어야 하며,
Storage의 경우 Pointer, filter, scalar quantization을 활용하여 1/130 수준 까지 줄일 수 있음
Search 속도의 경우 FAISS를 활용해 dense vector에 대한 search를 먼저 수행 후, sparse vector로 reranking
Experiment Results & Analysis
Phrase retrieval 방식은 발표 당시에는 약간의 성능 상승과 대단히 큰 inference speed를 자랑했었지만, Decomposability gap이 불러오는 효과로 최근 발표된 Retrieval-Reader 방식의 연구들 보다 성능이 뒤쳐지며, Storage 용량을 크게 필요로 한다는 단점을 가지게 된다.
_articles/AI/NLP/기계 독해 기본.md