풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
컴퓨터비전 기본
- Image Classification 1
- Annotation data efficient learning
- Image classification 2
- Semantic segmentation
- Object detection
- CNN Visualization
- Instance/panoptic segmentation and landmark localization
- Conditional Generative Model(cGAN)
- Multi-modal learning: Captioning and Speaking
- 3D undersanding
컴퓨터비전(Computer Vision, CV) 기본
네이버 AI 부스트 캠프의 CV 강의를 정리한 내용입니다.
Image Classification 1
Course overview
Artificial Intelligence(AI) : 사람의 지능을 컴퓨터 시스템으로 구현하는 것
사람의 학습은 오감을 조합해서 사용하는 multi-modal perception과 비슷하다.
뿐만 아니라 사회적 감각(표정 살피기, 관계 맺기, 의도 파악하기) 등의 복합적 감각이 존재
이중 시각적 능력이 기초적이고 중요한 능력이다.
[img. 복잡한 인간의 인지]
| 인간의 시각적 처리 VS 컴퓨터의 시각적 처리 |
|---|
 |
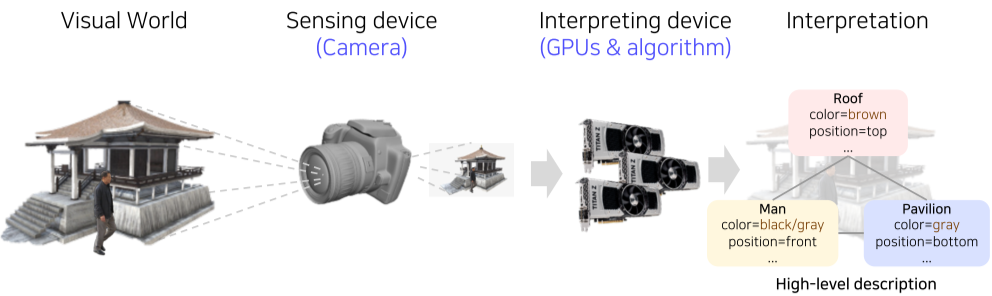 |
[fig. 사진의 representation(자료구조, 여기서는 처리 결과) 구하기]
또한, 우리의 시각적 능력 또한 이런 머신러닝 구조의 CV와 비슷하다.
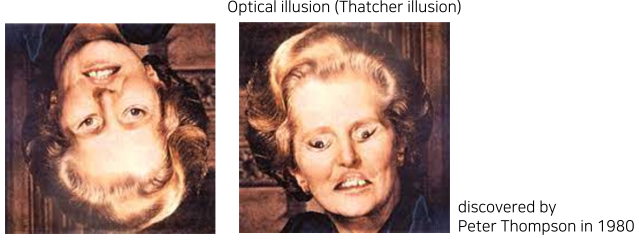
[img. 대처 환각, 거꾸로 된 사람은 많이 보지 못하기 때문(= 학습 편향)에 어색함을 느끼지 못한다.]
| Machine Learning vs Deep Learning |
|---|
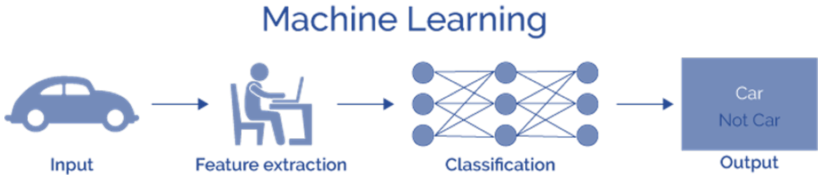 |
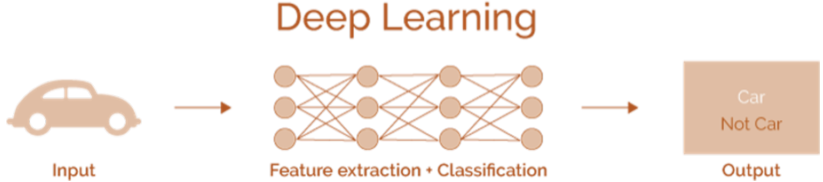 |
[img. 특징 추출까지 처리가 가능해진 Deep Learning 분야]
특징 추출을 사람이 설계하지않고 Gradient-Descend를 통해 End-to-End로 학습함으로, 편향과 오류를 줄여 최근 CV기술이 고도화 됨
이번 강의에서
- 기본적인 CV Task
- CV의 딥러닝 기술
- 시각 정보 + 다른 감각 데이터의 융합
- Conditional generative model
- Visualization Tool
등을 배울 것이다.
Image classification(영상 분류)
Classifier (분류기) 업무는 입력된 영상의 카테고리, 클래스를 분류하는 mapping 업무이다.
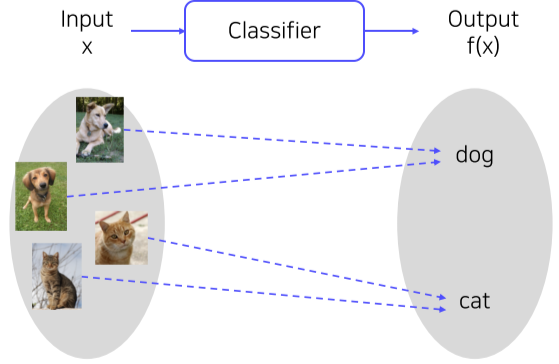
[img. Classifier 예시]
만약, 대량의 이미지 데이터가 있다면, 비슷한 사진끼리 모아 구별하는 k-Nearest Neighbors(k-NN)를 통하여 구별할 수 있다.
- query data point의 주변 reference point를 이용해 구분하는 방법
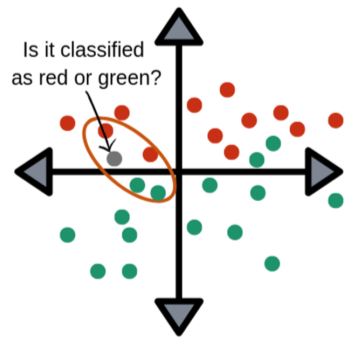
[img. K-NN 예시 이미지]
하지만, 데이터 수가 너무 많으면 많은 만큼 시간과 메모리가 부족하게 된다.
이를 방지하기 위해 Neural Networks를 이용해 Compress 된 모델을 통해 구별하게 된다.
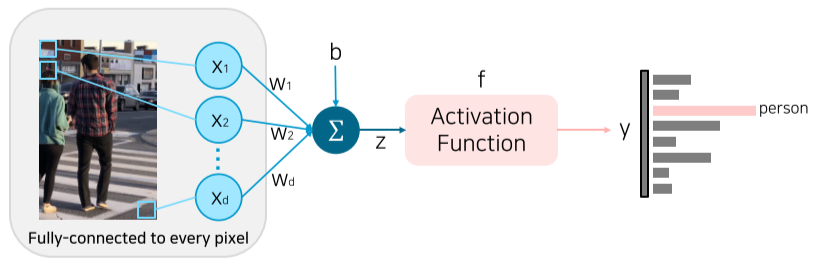
[img. 1층의 fully-connected layer을 이용한 구분]
영상의 모든 픽셀을 Input으로 넣어 구분할 수도 있지만, 이 역시 성능과 메모리 소모가 크다.
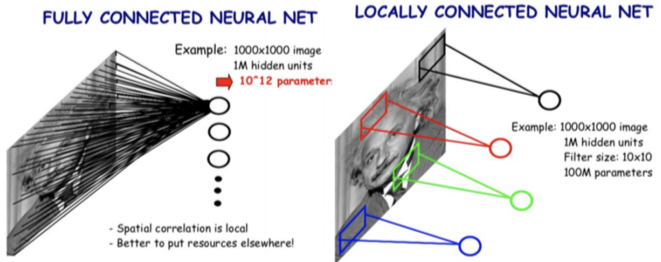
[img. FCN과 CNN의 비교]
CNN은 전체 pixel이 아닌 이미지의 일부를 지역적으로 Window Sliding 방식으로 하나의 feature로 추출하고(Local feature learning), 파라미터 공유를 통하여
- 성능과 메모리의 요구를 줄이고
- 오버피팅을 줄일고
- 사진 일부만으로도 사진을 구별할 수 있게 됬다.
이러한 장점 덕분에 많은 Computer Vision 업무에 기본이 됨.
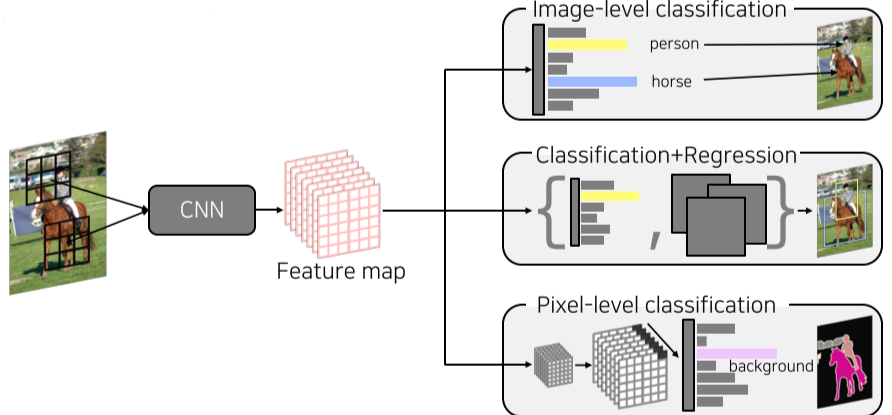
[img. CNN의 여러 사용]
CNN architectures for image classification 1
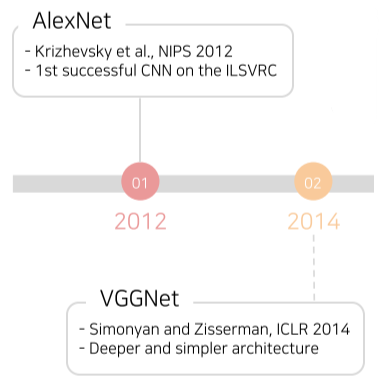
[img. AlexNet과 VGGNet의 등장]
- 딥러닝 CV의 등장을 알린 두 모델
- AlexNet
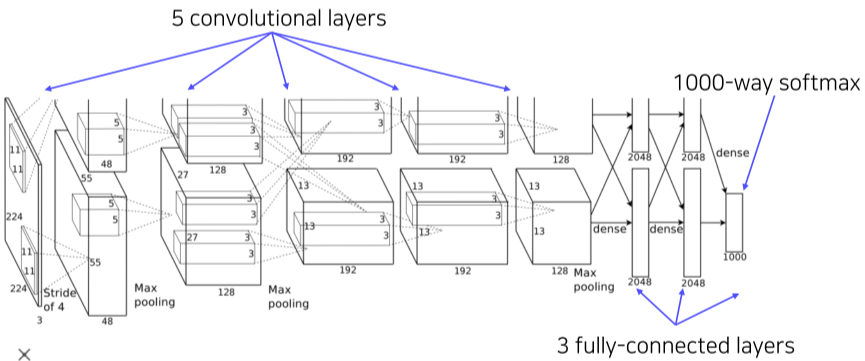
[img. AlexNet의 구조]
- 최초의 심플한 CNN 구조인 LeNet-5의 구조에서 더 깊은 층, 더 많은 데이터셋, ReLU 활성 함수와 drop out과 같은 regularization 기술을 이용한 모델
- 당시 GPU 메모리의 한계로 인해 2갈래로 나누어 학습한 뒤 중간에 Activation map으로 Cross Communication 해줌
nn.conv2d(3, 96, kernel_size=11, stride=4, padding=2) # 11x11 Conv(96), stride 4 Layer
# 이미지 크기가 커지면서, Receptive field를 크게 만들어주기 위해 11x11로 시작, 최근에는 더이상 사용 안함
nn.ReLU(inplace=True)
nn.MaxPool2d(kernel_size=3, stride=2)# 3x3 MaxPool, stride 2 Layer
nn.conv2d(96, 256, kernel_size=5, padding=2) # 5x5 Conv(256), stride 2 Layer
nn.ReLU(inplace=True)
nn.MaxPool2d(kernel_size=3, stride=2)
nn.conv2d(256, 384, kernel_size=3, padding=1)# 3x3 Conv(384), pad 1 Layer
nn.ReLU(inplace=True)
nn.conv2d(384, 384, kernel_size=3, padding=1)
nn.ReLU(inplace=True)
nn.conv2d(384, 256, kernel_size=3, padding=1)
nn.ReLU(inplace=True)
nn.MaxPool2d(kernel_size=3, stride=2)
torch.flatten(x, 1) # Fully connected Layer에 넣기 전에 다차원의 Tensor를 1차원 Tensor으로 길이를 길게 늘어 뜨리기(벡터화)
# AlexNet에서 사용한 방법
# nn.AdaptiveAvgPool2d((6,6))
# 비슷한 방법이지만, 길게 늘어뜨리지 않고 평균을 내어 같은 길이의 1차원으로 바꿈
nn.Dropout() # Dense(4096)
nn.Linear(256*6*6, 4096) # 2stream 구조가 아니라 1개로 통합했으므로 2048 *2 = 4096
nn.ReLU(inplace=True)
nn.Dropout()
nn.Linear(4096, 4096)
nn.ReLU(inplace=True)
nn.Linear(4096, 1000)
[code. AlexNet의 코드구현]
- 시간이 흘러 GPU 메모리가 늘어나 2 stream 구조로 구현하지 않음
- LRN(Local Response Normalization) 구현 안함
- 더이상 사용하지 않는 방법, Batch normalization으로 대체됨
- Activation map 이후, 명암을 normalization 해주는 역할
Receptive field란?
layer output 값을 만들기위해 Input image에서 CNN layer가 참조한 공간, 클 수록 이미지의 많은 부분을 참조한 것이다.
여러 층이 중첩되도 처음 image에서 확인한 부분이 Receptive field이다.
위 구조에서는 전체를 11x11 conv로 Input 이미지 전부를 Receptive field로 삼았다.
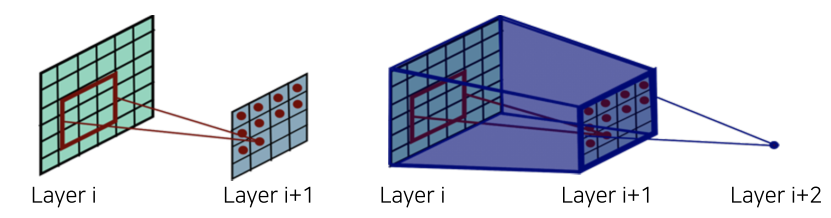
[img. Receptive Field 도식화]
KxK conv stride 1 layer와 PxP pooling layer를 통과한 경우의 Receptive field의 크기는
(P+K-1)x(P+K-1)이다.
- VGGNet
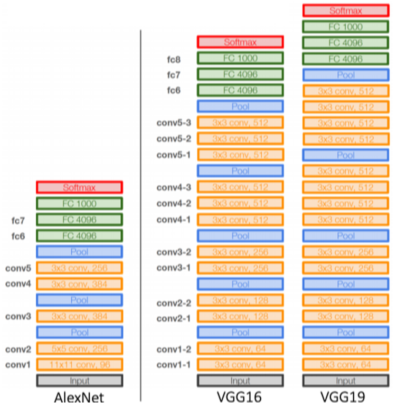
[img. VGGNet의 구조]
- AlexNet보다 깊고(16, 19Layer)
- 더욱 심플한 구조이며
- Loca Response Normalization(LRN) 사용 안함
- conv filter layer와 max pooling layer의 크기를 각각 3x3, 2x2만 한하여 사용(가장 큰 특징)
- 이를 stack하여 큰 Receptive Size를 얻으면서 더 깊고 복잡하면서 파라미터 수는 줄여 성능과 정확도를 동시에 잡을 수 있다.
- 더욱 좋은 성능과 일반화(Generlization)을 내는 모델
이외에는 AlexNet과 비슷하다.
- ReLU 사용, Input에서 224x224 RGB 이미지를 Normalization(RGB 평균값을 RGB 값에서 빼줌)하여 넣어줌
Annotation data efficient learning
- 질좋은 데이터셋은 성능에 큰 영향을 미치지만 확보하거나 만드는데 큰 어려움이 따른다.
- CV에서의 데이터 부족 완화 방법을 알아보자.
Data augmentation
손쉽게 데이터셋을 늘릴 수 있는 방법
| 여러 물체 | 장소 | 공원 | |
|---|---|---|---|
| 그림 |  |
 |
 |
| 편향 | 겹쳐 보면 정면에 특정 각도로 물체들이 위치 | 장소 사진들을 겹쳐보면 해안선, 물체, 건물 등의 위치가 겹침 | 사람을 위주로 찍게 되어 중앙에 사람이 위치 |
[fig. 편향의 예시]
Dataset들은 인간의 필요에 의해 편향된 채로 촬영되게 되며, 이는 현실의 데이터와 괴리를 준다.
| Samples in the training set | Real data distribution |
|---|---|
 |
 |
애매한 데이터들이 여러 class와 겹치는 방식인 현실 데이터와 달리 sample data들은 확실하고 명확한 경우가 많으므로 이로 인해 모델에 혼란이 올 수 있다.
예를 들면, 많은 사람들이 밝은 조명 아래에서 사진을 찍는다, 그리고 달은 어두운 밤하늘에만 찍힌다. 만약 이를 데이터셋으로 학습한 모델이 어두운 곳에 찍힌 사람을 보면, 달로 착각할 수도 있다.
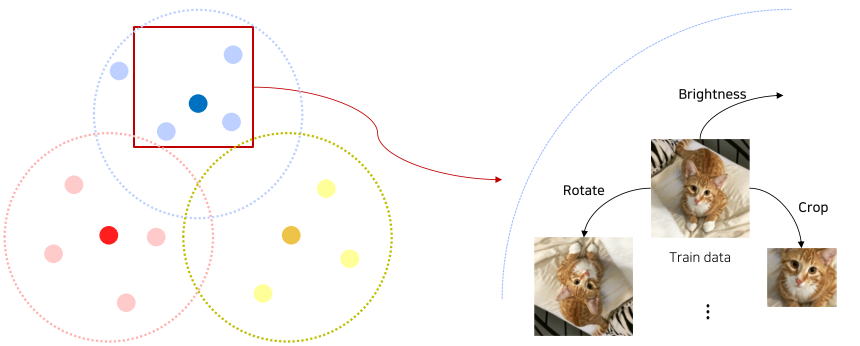
[img. Augmenation의 예시]
이를 막기위해, 밝기 바꾸기, 회전, crop, 일부 가리기, 채도 변경 등의 방법으로 이미지를 바꾸어 현실 데이터와 비슷하게 만들면서 데이터셋 크기를 늘릴 수 있다.
OpenCV, NumPy 등에서 library로 활용할 수 있다.
 |
 |
 |
| Rotate, Flip | Brightness adjustment | Crop |
 |
 |
 |
| Rotate, Flip | Affine transformation | CutMix |
[table. 여러 종류의 augmentation 종류]
def brightness_augmentation(img):
# numpy array img has RGB value(0~255) for each pixel
img[:,:,0] = img[:,:,0]+100 # add 100 to R value
img[:,:,1] = img[:,:,1]+100 # add 100 to G value
img[:,:,2] = img[:,:,2]+100 # add 100 to B value
img:[:,:,0][img[:,:,0]>255] = 255 # clip R values over 255
img:[:,:,1][img[:,:,1]>255] = 255 # clip G values over 255
img:[:,:,2][img[:,:,2]>255] = 255 # clip B values over 255
return img
[code. 밝기 조절 Augmentation 코드]
img_rotated = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
img_flipped = cv2.rotate(image, cv2.ROTATE_180)
[code. 회전, 뒤집기 Augmentation 코드]
y_start = 500 # y pixel to start cropping
crop_y_size = 400 # cropped image's height
x_start = 300 # x_pixel to start cropping
crop_x_size = 800 # cropped image's width
img_cropped = image[y_start:y_start+crop_y_size, x_start : x_start + crop_x_size, :]
[code. Crop Augmentation 코드]
rows, cols, ch = image.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv2.getAffineTransform(pts1, pts2)
shear_img = cv2.warpAffine(image, M, (cols,rows))
[code. Affine Transformation Augmentation]
Affine Transformation : 사각형 이미지를, 기울어진 평행 사변형(parallelogram)의 형태로 바꿈 + rotation 함
- shear transformation 이라고도 함
RandAugment
- Augmenation의 종류, 강도(얼마나 밝은가, 얼마나 기울어졌는가 등)에 따라 모델 성능이 달라지므로, 이를 parameter로 사용할 수 있다.
- 랜덤으로 Augmentation을 적용한 뒤, 평가하는 과정을 거침

[img. ShearX & AutoContrast 9 Randaug 예시]
- 적용할 Augmentation, 적용 강도, 2가지가 Parameter로 적용
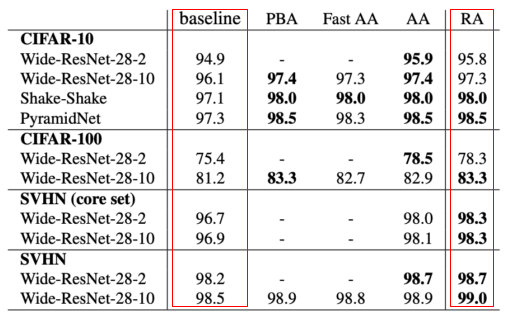
[img. RandAugmentation 사용에 의한 성능 향상]
Leveraging pre-trained information
pre-trained 된 모델을 활용하는 방법
Transfer learning
Transfer learning: 한 데이터셋에서 배운 지식을 다른 데이터셋, 다른 Task에서 활용하는 기술
- 이를 통하여 작은 데이터셋으로도 높은 정확도를 자랑한다.
- Transfer knowledge from a pre-trained task to a new task(같은 Layer, 다른 Task에 활용)
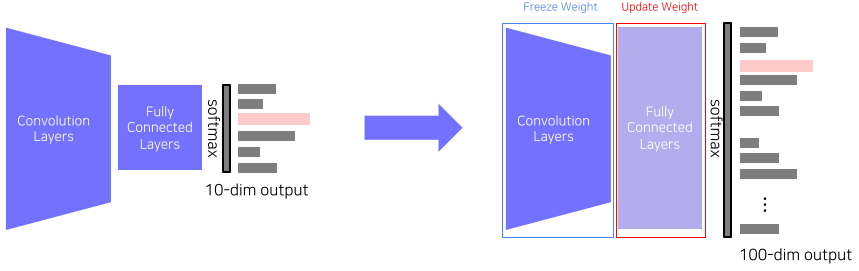
[img. Transfer model(좌)를 원하는 업무에 맞게 FCL을 변경]
- 마지막 Fully connected Layer만 바꾼 뒤, 이전 Convolution Layer의 Weight는 그대로 둔채 바꾼 층만 학습 시켜 활용하는 방법
- pre-trained 모델의 feature가 그대로 유지됨
- Fine-tuning the whole model
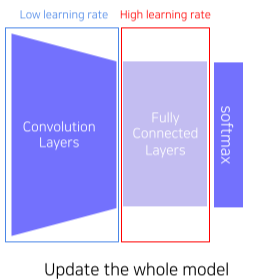
[img. FCL을 변경 후 Convolution Layer도 Low lr로 학습]
- 마지막 층을 바꾼 뒤, 기존 층은 낮은 Learnig rate, 새로운 층은 High learning rate를 유지하며 학습
- 자신의 Task에 맞게 기존 모델을 조금 수정가능
Knowledge distillation
pre-trained 모델의 예측값을 활용해 다른 모델을 학습시키는 방법
Teacher-student learning
보통 두가지 목적으로 쓰임
- 더 경량화된 모델을 만들어, 기존 모델 보다 경량화에 사용
- unlabeld dataset의 pseudo-labelling에 사용(레이블링 안된 데이터셋에 라벨링)
학습 구조에 따라 2가지로 나뉜다.
- Teacher-student network structure
- student 모델(보통, Teacher Model보다 경량화되어 있다.)이 Teacher 모델의 output을 따라하게끔 학습시킴
- Unsupervised learning으로, label 되지 않은 dataset을 사용한다.
- 두 결과를 비교하여 KL divergence Loss를 통해 Loss 값을 구한뒤, student model로만 backpropagation이 진행되게 된다.
- KL div Loss: 2개의 분포의 거리(=얼마나 비슷한가)를 측정
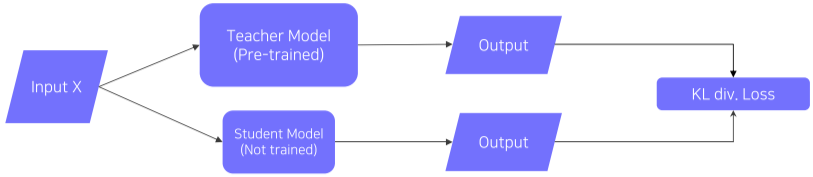
[img. Teacher-student network structure]
- Knowledge distillation
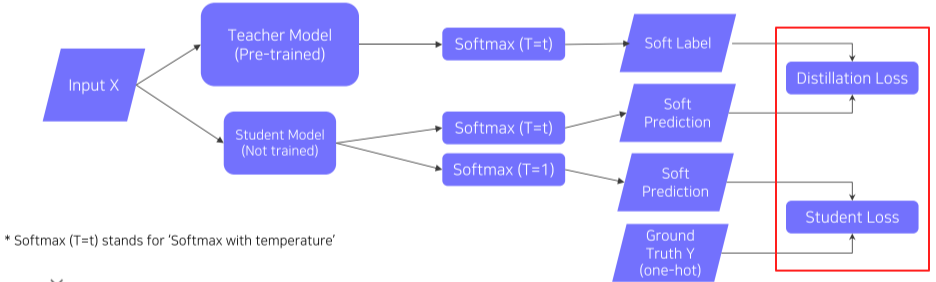
[img. Knowledge distillation structure]
- Labeled된 데이터셋을 사용할 때 사용하는 구조
- Student Model과 Teacher Model의 차이를 Distillation Loss, Student Model과 Ground Truth(Label)과의 차이를 Student Loss라 정의 한다.
- 이때 Student 모델은 Soft label을 이용한 Soft Prediction을 이용한다.
- Hard label(One-hot vector) : dataset의 label값처럼, 하나의 명확한 정답을 가짐
- Soft label: model의 softmax를 통과한 뒤 기본 출력값, 여러 정답에 float 값을 가지는 가중치같은 형태
- 이를 이용해 단순 정답이 아닌, 어느 정도로 정답에 근접했는가 등의 추가적인 정보를 사용하여 학습할 수 있다.
\(Hard\ label:\begin{pmatrix}Bear\\Cat\\Dog\end{pmatrix}=\begin{pmatrix}0\\1\\0\end{pmatrix}\\
Soft\ label:\begin{pmatrix}Bear\\Cat\\Dog\end{pmatrix}=\begin{pmatrix}0.14\\0.8\\0.06\end{pmatrix}\)
[math. Hard label과 Soft label의 예시]
- 또한 Knowledge distilation에서의 Distillation Loss를 구할 때, Softmax 함수에 temperature(T)를 이용하여 기존의 output보다 Smoothing한 결과를 사용할 수 있다.
- 이를 이용해 좀더 결과값에 많은 정보를 포함할 수 있다.
- 예를 들어 기존의 softmax(5,10) = (0.0067, 0.9933)이라면
- t=100인 softmax(5,10) = ( 0.4875, 0.5125)로 비슷한 값을 smoothing 된다.
- 전자의 결과의 0,0067은 무시될 정도로 작은 정보지만 후자의 경우는 무시못할 정보가 된다.
\(Normal\ Softmax(=Hard\ Prediction):\frac{\exp(z_i)}{\sum_j\exp(z_j)}\\
Softmax\ with\ temperature\ T(=Soft\ Prediction):\frac{\exp(z_i/T)}{\sum_j\exp(z_j/T)}\)
[math. softmax with temperature]
- Distillation Loss를 구할 때, Teacher Model의 soft Label의 세부정보(Semantic information)은 고려하지 않는다.
- 교육받고 바꿔야할 모델은 Student Model 이기 때문에
Distillation Loss의 경우, Teacher model vs Student model의 차이를 의미
- KL divergence loss 사용: 비교 하는 두 값이 0~1사이의 값들의 분포이므로
Student Loss의 경우, 실제 답과 student model의 정답을 비교
- CrossEntropy 사용: True label의 경우 one-hot vector 형태이므로
마지막으로 위에서 구한 두 loss들의 가중치 합을 통해 loss를 구한 뒤, student model만, Backpropation을 한다.
Leveraging unlabled dataset for training
Semi-supervised learning
- labeled된 적은 수의 데이터와, label되지 않은 많은 양의 데이터를 활용하는 방법
- 즉 unsupervised + Fully supervised = semi-supervised
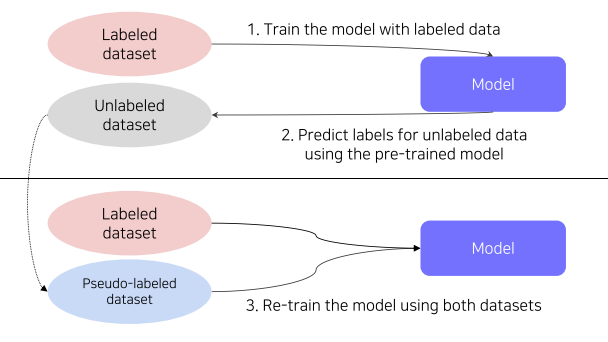
1) 레이블링된 데이터셋으로 모델 형성
2) 형성된 모델로 레이블링되지 않은 데이터셋 레이블링
3) 그렇게 레이블링된 데이터셋과 기존의 라벨링된 데이터셋으로 새로운 모델 형성
Self-training
앞서 배웠던 Data Augmentation, Knowledge distillation, Semi-supervised learning을 이용한 방법
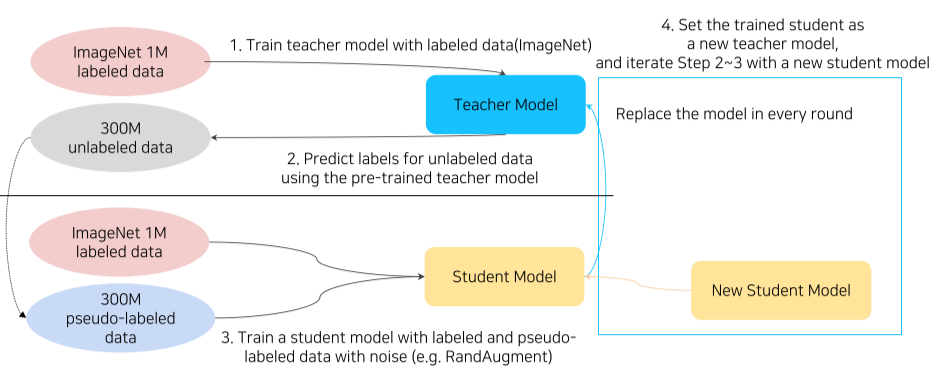
[img. self-training의 단계]
- lable된 데이터셋으로 Teacher model을 형성한다.
- 해당 Teacher model로 unlabled된 model을 Pseudo-labeled data로 만든다.
- lable된 데이터셋 + pseudo-lable된 데이터셋을 augmentation 한 것을 통하여 새로운 Teacher model을 형성한다
- 이때 주로 사용하는 augmentation 방법이 RandAugment
- 새로 형성된 Teacher 모델로 2번부터 4번까지 반복한다.
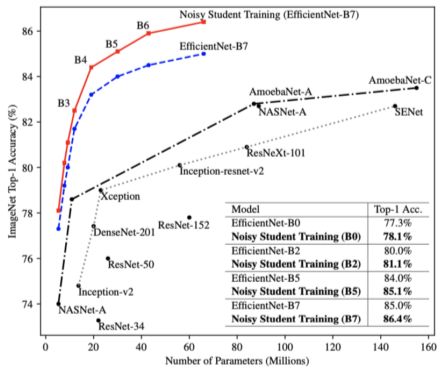
[img. 압도적인 성능을 자랑하는 self-training 모델(빨간색)]
Image classification 2
Problems with deeper layers
성능 향상을 위해 딥러닝 layer의 층을 높게 쌓으면서 다음과 같은 문제가 생겼다
- Gradient vanishing/exploding 문제
- Computationaly complex
- 한때 overfitting 문제로 착각했던 Degradation problem
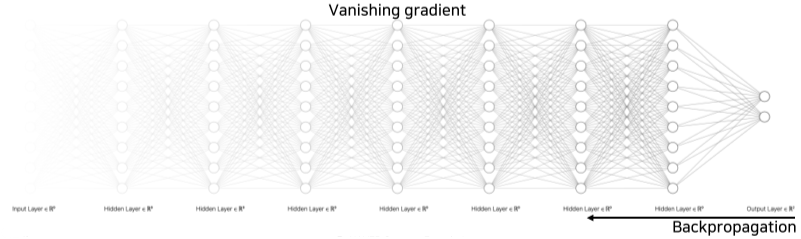
[img. Vanishing gradient 문제의 도식]
CNN architectures for image classification 2
GoogLeNet
2015년에 발표된 Inception 모듈을 활용한 CV 모델
Inception module이란?
-
이전 층에서의 결과값에 여러개의 필터를 적용한 뒤, Concatenate하는 layer
- 1x1, 3x3, 5x5 Convolution filter, 3x3 max pooling layer를 적용
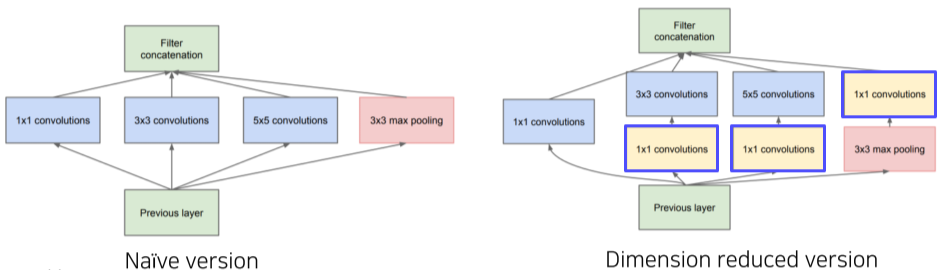
[img. Inception module의 예시]
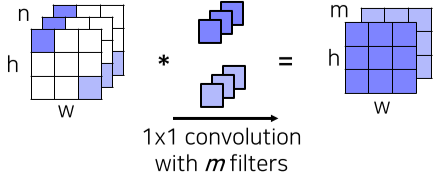
이때, 여러 필터의 적용에 의해 parameter수가 증가하자, 1x1 convolution layer(Bottleneck layer)을 추가하여 파라미터 수를 줄이는 시도를 함
- 우측의 Dimension Reduced version에 추가된 1x1 convolution layer를 의미
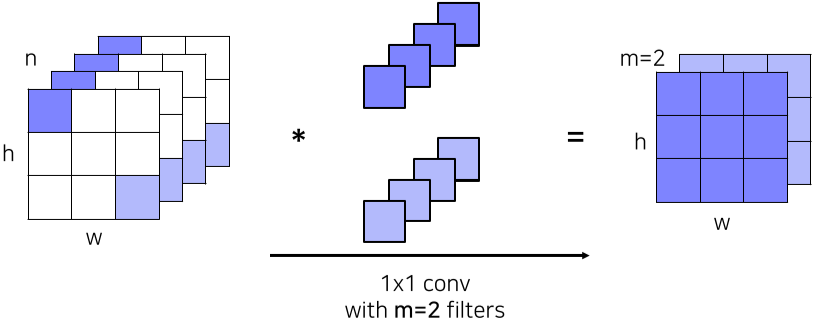
[img. 1x1 convolution layer의 연산 결과]
GoogLeNet의 전체적인 구조를 살펴보면 다음과 같다.
- Stem network: 기본적인 convolution network
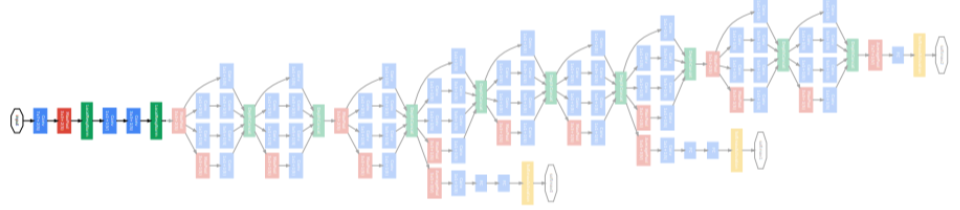
[img. Stem network 부분]
- Stacked inception modules: 위에 설명한 Inception 모듈을 쌓아놓은 부분
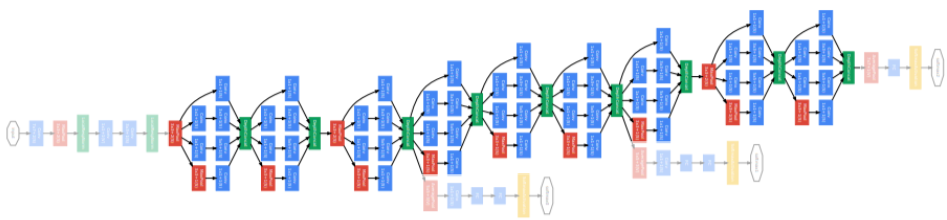
[img. Stacked inception modules 부분]
- Auxiliary classifiers
- Vanishing gradient 문제를 해결하기 위한 부분
- 중간의 결과값을 한번 예측값으로 삼고, loss 값을 계산하여 중간부터 backpropagation을 진행한다
- training에서만 사용하고 testing 단계에서는 사용하지 않는다.
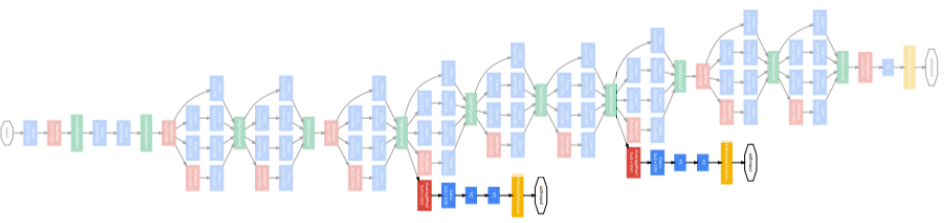
[img. Auxiliary classifiers 부분]
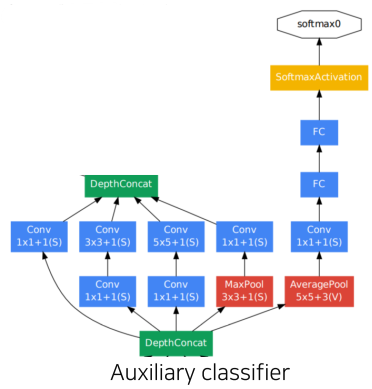
[img. 더욱 자세한 Auxiliary classifier]
ResNet
현재까지 기본 backbone으로 쓰이곤 하는 좋은 모델
- 최초로 인간 보다 나은 성능을 달성(에러율 기준)
- 기존의 모델보다 압도적으로 깊은 층의 갯수(152 Layer)
기존의 연구에서는 층이 깊을 수록 오히려 성능이 떨어지는 문제를 Overfitting 문제라고 오판하였다.
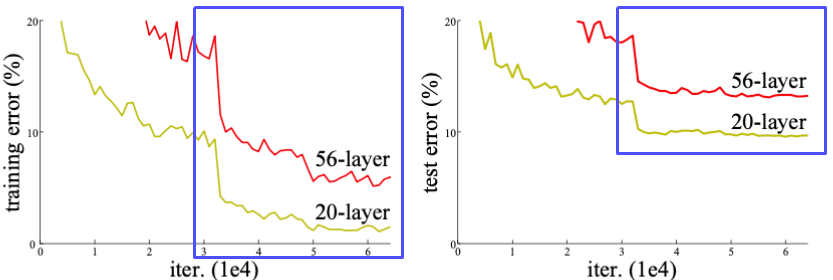
[img. 층의 갯수에 따른 에러율, 높을 수록 안좋음]
Overfitting의 문제였다면, training error는 점점 나아져야하고, test error가 나빠져야 하지만, 둘다 성능이 나빠졌기 때문이다.
따라서 Resnet에서는 이를 Overfitting이 아닌 Optimization(최적화)의 문제라고 보았다.
ResNet의 연구 가설은 다음과 같다.

[img. Residual block과 Plain layer의 차이]
기존의 Plain layer의 경우 층이 깊어질 수록 복잡해진 H(x)에 X를 보존하면서 학습하기 힘들었다.
하지만 Residual block에서는 identity X를 F(X)에 더한 것을 H(X)로 삼으면서, X의 정체성이 뚜렷히 남은 상태에서, 분할정복 통해 최적화된 학습을 할 수 있다.
- 분할정복-> (F(x), X의 weight를 따로 구해서 더하면 되니까?)
- Target function : $H(x)=F(x)+x$
- Residual function : $F(x)=H(x)-x$
이를 위해 Shortcut connection 또는 Skip connection을 통해 x를 layer을 넘어 더해주어 Backpropagation 시 뛰어넘어 gradeint를 구할 수 있게 하였다.
- 이를 통해 Gradient vanishing 문제를 해결함
| Residual 구조 | 경로를 풀어본 구조 |
|---|---|
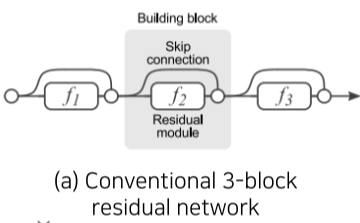 |
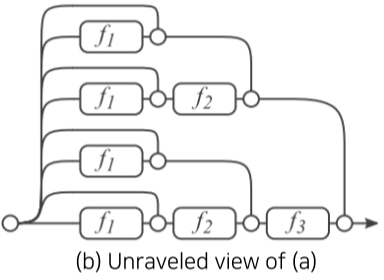 |
[img. 같은 Residual 구조의 경로 풀이]
이론상, Residual 구조를 통하여 생기는 경로는 층이 깊이 n에 따라 $O(2^n)$개 만큼 증가한다.
이 경로를 통해 backpropagation이 가능하므로 복잡한 학습을 해결 가능하다.
ResNet의 전체적인 구조는 다음과 같다.
- He initialization conv layer

[img. Resnet의 첫 시작 부분]
- 첫 layer의 output은 앞으로 계속 identity connection을 통하여 더해질 것이므로, 최적화를 위해 단순하고 작은 크기의 output을 내놓아야 한다.
- 따라서 He initialization이라는 간단하고 ResNet을 위해 고안된 initialization을 이용한다.
- Stacked residual blocks 부분

[img. Stack residual blocks]
- 모두 3x3 conv layer로 이루어져 있으며, Batch normalization이 매 layer 끝에 이루어진다
- 일정 블록 이후(색이 바뀌는 부분), 채널 수는 2배로 늘리고, 채널 해상도는 stride를 2로 잡아 줄이는 구간이 존재함
- Output FC layer

[img. Sing FC layer]
- 하나의 average pooling과 Fully connected layer을 통하여 classfication을 진행
ResNet 코드
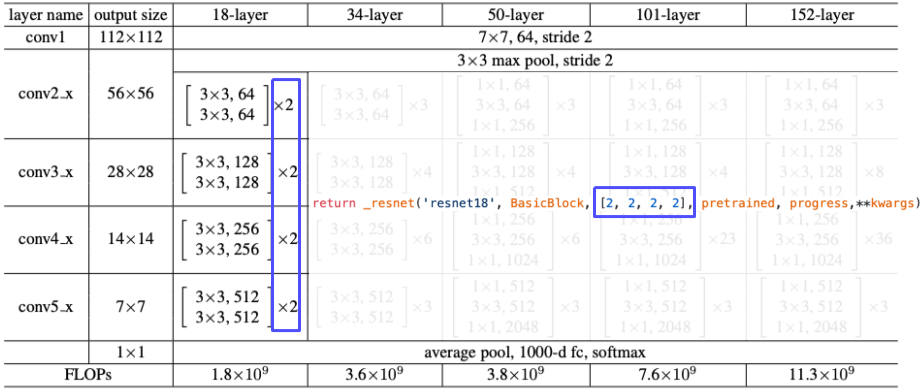
[img. ResNet code stack 수 정의 부분 ]

[img. ResNet code 첫시작, He initialization 부분 ]

[img. ResNet code, stacked residual 부분 ]
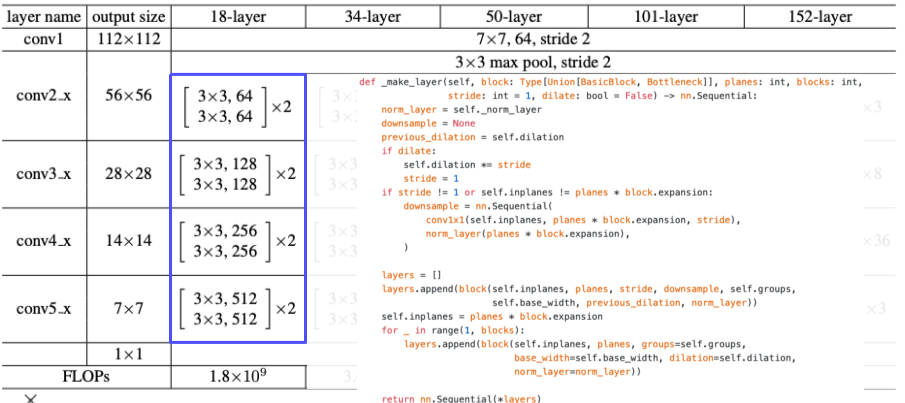
[img. ResNet code, Layer 생성 코드]
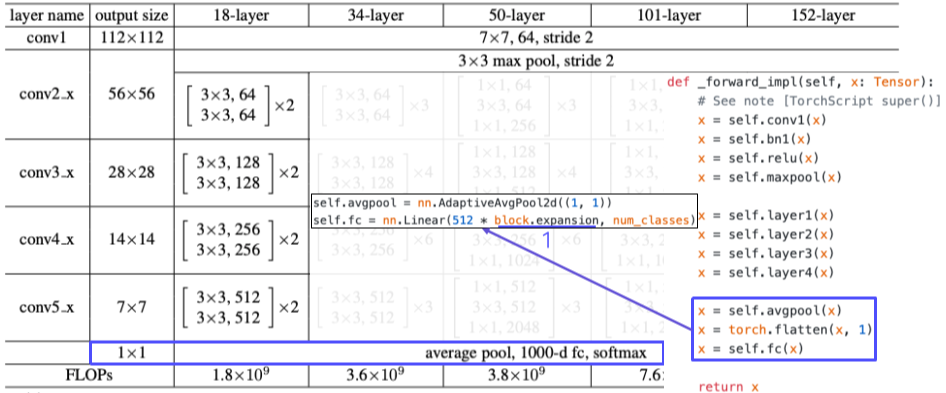
[img. ResNet code, 마지막 FC층 부분]
Beyond ResNets
- DenseNet
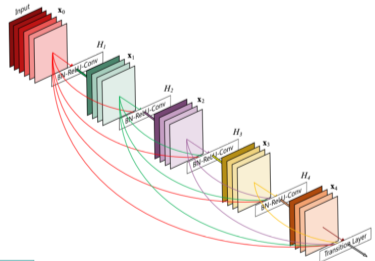
[img. DenseNet 이미지]
- ResNet과 달리 layer의 output이 이후의 모든 layer의 결과값에 Channel 축을 중심으로 Concatenate되서 합해진다.
- Cocatenate하므로 기존의 값들이 보존된다
- SENet
- Activation의 결과가 명확해지도록 ouput의 채널축에 가중치를 주는 Attention across channel 방식
- feature의 중요도와 관계가 명확해짐
- Squeeze: global average pooling을 통하여 채널의 공간정보를 없애고(축의 정보 등) 분포를 구함
- Excitation: FC layer 하나로 채널간의 연관성(Weight=attention score)를 구함
- 중요도가 떨어지면 0에 가깝게 중요한 것은 크게 하여 feature의 강조와 무시를 함
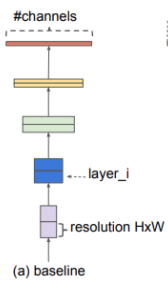
- EfficientNet
- 기존의 Network 알고리즘을 정리함
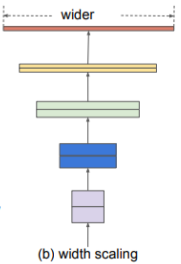
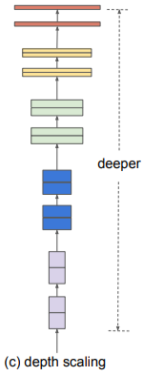
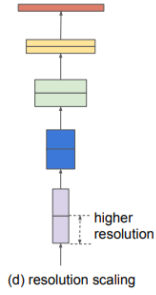
| 기본 Network | Width Scailing | Depth Scailing | Resolution Scaling | Compound Scailing |
|---|---|---|---|---|
 |
 |
 |
 |
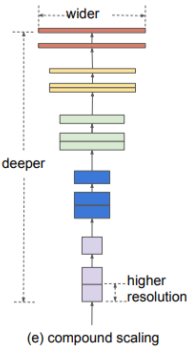 |
| 기준 | 채널의 수를 늘리는 방식 | 층의 수를 늘리는 방식 | Input의 해상도를 높게 주는 방식 | 앞의 방법들을 복합한 방식 |
| _ | GoogLeNet 등 | DenseNet 등 | _ | EfficientNet |
[table. 기존의 Network의 분류]
-
각 Scailing들은 파라미터 수, 학습 epoch, 데이터셋의 수에 따라 성능이 오르지않는 구간이 나오는데(saturation), 이를 모두 팩터(어느 정도 비율로 복합하는가)를 주고 복합하여 성능을 크게 상승시킴
-
사람이 찾은 효율적인 다른 구조들, NAS 알고리즘 구조(Neural Architecture Search, 컴퓨터가 효율적인 구조를 찾는 알고리즘)보다 성능이 압도적으로 좋다.
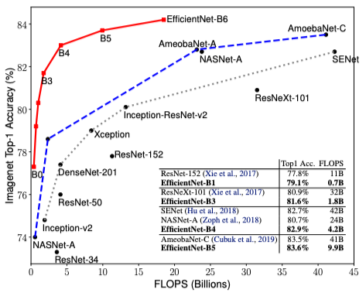
- 적은 연산으로도 성능이 크게 올라 EfficientNet이다.
- Deformable convolution

- 동물, 사람, 등의 형태가 변할 수 있는 사물에 효율적인 구조
- feature를 나타내는 weight와, 이 weight의 위치를 어떠한 방향으로, 어떻게 변형시킬 지 결정하는 offsets를 학습하는 형식
- 기존의 정사각형 형태의 Receptive field와 달리 물체의 형태에 따라서 Receptive field 모양이 변함
Summary of image classification
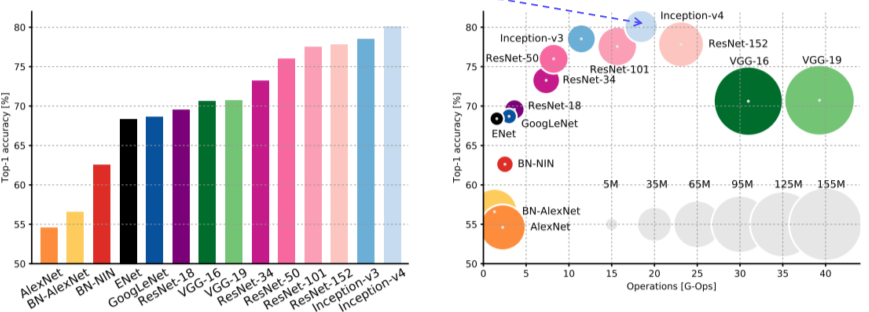
[img. 앞서 배운 모델들의 비교, 면적은 모델의 크기]
- AlexNet은 심플하지만 메모리 사용량이 크고 성능이 좋지 않다
- VGGNet은 성능이 낫지만 메모리와 연산을 많이 잡아 먹는다
- GoogLeNet의 최신 구조는 크기도 적고 성능도 좋지만, 구조가 복잡하다
- ResNet은 특출난 것이 없다
- GoogLeNet이 여러모로 좋지만 구조가 너무 복잡하여 VGGNet, ResNet을 기본 모델로 많이 사용한다.
Semantic segmentation
Semantic segmentation
이미지 각 픽셀의 어떠한 category에 속하는지 구분하는 문제(ex) 사람 영역, 자동차 영역)
같은 class의 다른 instance에는 관계가 없으며 이를 위한 instance segmentation가 있다.

[img. Semantic segmentation의 예시]
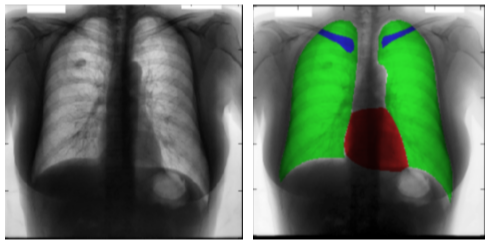 |
|---|
 |
[table. 의료 사진, 자율 주행, 영상 합성 등에서 활용]
Semantic segmentation architectures
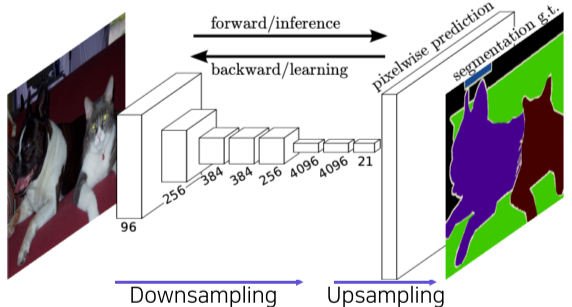
Fully Convolutional Networks(FCN)
Semantic segmentation을 위한 첫 End-to-End architecture
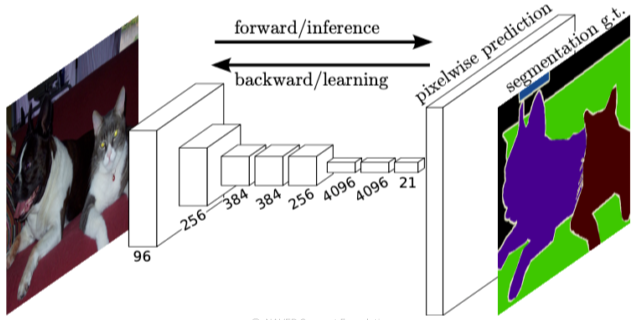
[img. FCN 구조]
- End-to-End 구조: 입력층부터 출력층까지 모두 미분가능하여 입력과 출력 pair만 있으면 모델을 학습할 수 있는 구조를 의미. 입력 사이즈 등의 제한이 없음
- 이전에는 완전학습 하기에 제한이 있었음
- ex) AlexNet을 이용한 semantic segmentation의 경우, 학습 시의 이미지 해상도와 test 시의 이미지 해상도가 다르면 안됬음.
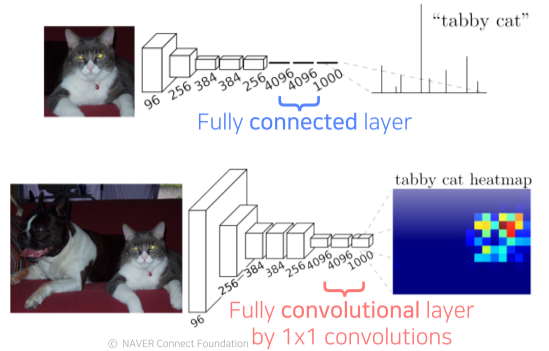
[img. Fully connected layer vs Fully convolutional layer 구조 비교]
| Fully connected layer(FCL) | Fully convolutional layer |
|---|---|
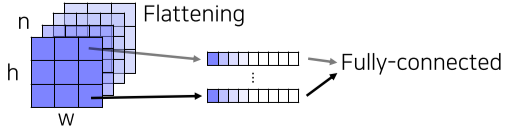 공간 정보를 고려하지 않는 모습 |
 |
| fixed dimensional vector를 받아 fixed dimensional vector 출력, 보통 하나로 정해진 feature vector를 출력 | activation map을 받아 activation map 출력, 보통 1x1 conv layer로 구현하며, feature vector들이 포함된 convolutional feature map 출력 |
[table. Fully connected layer vs Fully convolutional layer 세부 비교]
다만 Receptive field를 살핀 뒤 feature를 찾아 작은 크기의 결과를 내는 conv layer와 pooling layer로 인해 출력 이미지의 해상도가 작아짐 => 이를 해결하기 위해 Upsampling layer가 나타남
Upsampling layer이란?
[img Upsampling이 추가된 FCN]
작아진 결과물을 크게 만들어주기 위해 Upsampling layer을 사용
3가지 방법 중 Unpooling 방법을 제외하고 2가지 방법이 이용됨
- Transposed convolution
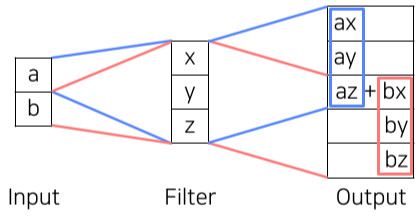
[img. Transpose convolution의 원리]
줄어든 이미지의 픽셀을 필터만큼 곱한 뒤, kernel 사이즈와 strider 크기에 따라 곱연산하여 더한다, 중첩 되는 부분은 덧셈연산이 일어난다.

[img. Transpose convolution의 문제점]
kernel 사이즈와 strider 크기에 주의하지 않으면, 겹쳐서 덧셈이 일어나는 부분에 의해 checker 무늬가 나타나게 된다.
- Upsample and convolution
위 문제를 해결하기 위해 upsampling과 convolution을 같이 사용하여 중첩하는 부분뿐만 아니라 골고루 영향을 받게 해준다.
Transpose와 달리 layer을 하나가 아닌 2개로 분리하여 주로 영상처리에 사용하는interpolation 알고리즘(Nearest-neighbor(NN), Bilinear 등)을 사용하고 convolution을 이용하여 학습 가능하게 만든다.

[img. 개선된 convolution]
해상도를 낮추며 진행되는 conv layer 특성상, 층의 깊에 따른 특성은 다음과 같다.
| 낮은 레이어층, 해상도 높음, Receptive field 작음 <====> 높은 레이어층, 해상도 낮음, Receptive field 큼 |
|---|
 |
| 디테일, 로컬 변화에 민감<====>전반적 의미적 정보를 포함 |
[table. 층의 깊이에 따른 output 값의 특징]
결국 우리가 필요한건 구조의 깊은 부분의 의미적 부분(classify 해야하므로)과 구조의 얕은 부분의 디테일한 부분(고해상도로 픽셀을 선정해야 하므로)이 둘다 필요하므로 다음과 같은 방법으로 해결하였다.
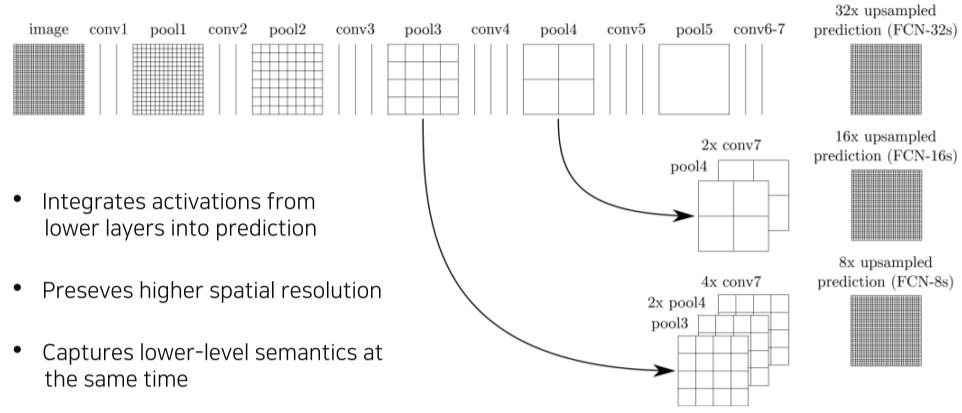
[img. FCN-Ns 모델들의 비교]
마치 DenseNet이나 ResNet 처럼,
- 중간의 결과 값을 upsampling 한 뒤,
- 최종결과물을 upsampling한 것들을
- Concatenate하여 출력하면 좋은 결과가 나오며,
얼마나 많은 층에서 결과값을 가져오느냐에 따라 FCN-32s, FCN-16s, FCN-8s 모델로 나누어진다.
- 숫자가 작아질 수록 더 많은 층의 결과값을 가져온 모델
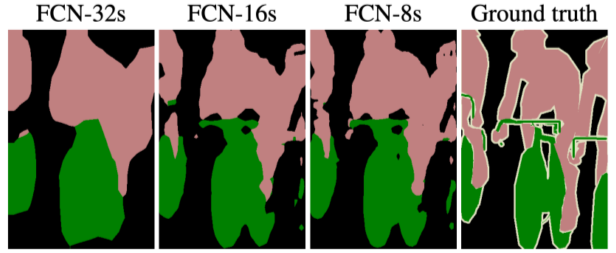
[img. FCN-Ns 모델들의 비교, 중간값을 많이 가져온 모델일 수록 정확한 결과가 나옴]
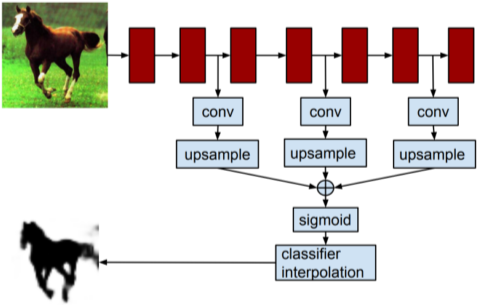
Hypercolumns for object segmentation
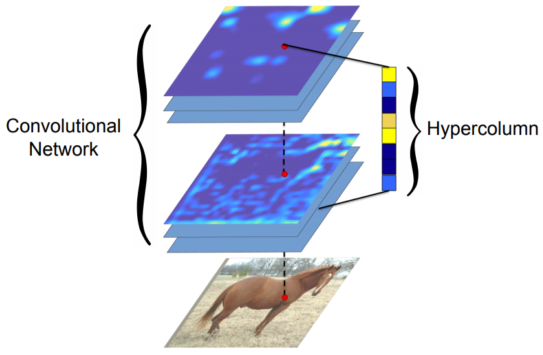 |
 |
|---|---|
| HyperColumn이라는 모든 Conv layer의 결과값을 각 픽셀 별로 쌓아 만든 vecotr를 이용함 | 물체의 bounding box를 추출하고 사용한다는 점이 다름 |
[table. FCN과 비슷한 내용을 담은 HyperColumn 논문]
U-Net
영상의 일부분만 쓰는 관련된 TASK의 경우 아직도 많이 활용되는 network
Fullay convolutional network가 기반이며, skip connection을 통하여 앞선 network 보다 더욱 정교한 결과를 만들 수 있음
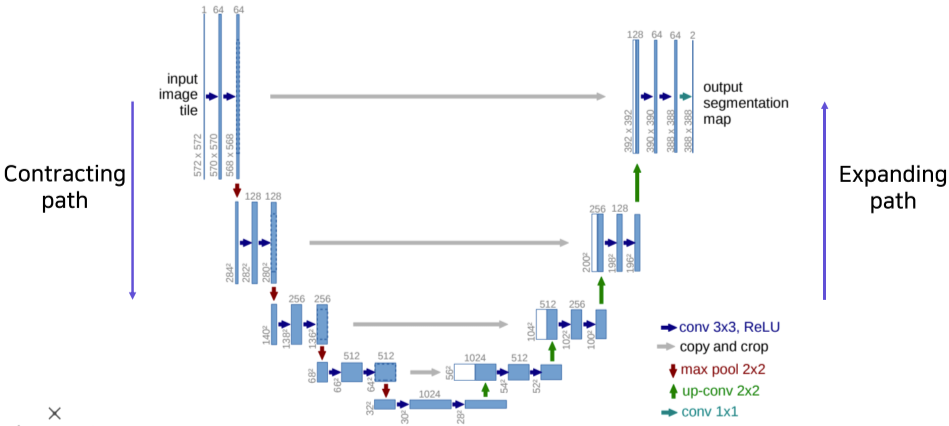
[img. U자 모양이라 U-Net]
크게 2가지 부분으로 나뉜다.
- Contracting path 부분
- 입력 영상을 3x3 convolution을 이용해 max pool을 이용해 해상도를 낮추고 대신 2배씩 feature channel을 늘림
- 이를 통해 전체적인 의미, 문맥(holistic context)를 확보하는 부분이며 일반적인 FCN과 다를바 없음
- Expanding(Upsampling, decoding) path 부분
-
2x2 up-convolution을 통하여 반대로 점진적으로 채널 수는 절반으로, 해상도는 2배로 늘림
-
추가로 이전 낮은 층의 layer의 activation map을 Skip connection으로 가져와 concatenating하여 사용함
-
이를 통해 detail하고 local한 feature map을 받아 사용할 수 있음
-
이때 concatenate하려면 해상도가 맞아야 하는데, 홀수이면, Downsample시, 일부 값을 버리게 되며, 다시 Upsample시 해상도가 달라지므로 해상도 크기가 홀수가 안되게 해야함.
- ex) 7x7 =DownSample(divide 2)=> 3x3 (1은 버림) =UpSample(multiple 2)=> 6x6
- 7x7과 6x6 해상도가 맞지 않아 Concatenate 불가
-
U-Net Pytorch 코드
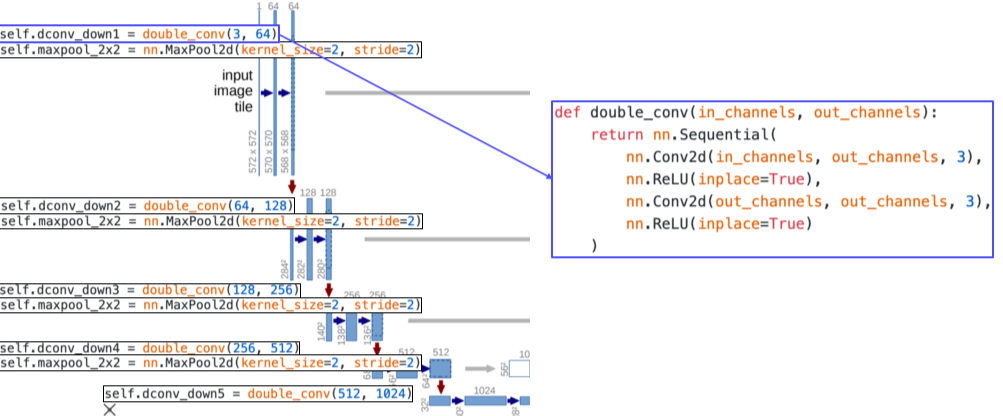
[img. U-Net Contracting Path code]
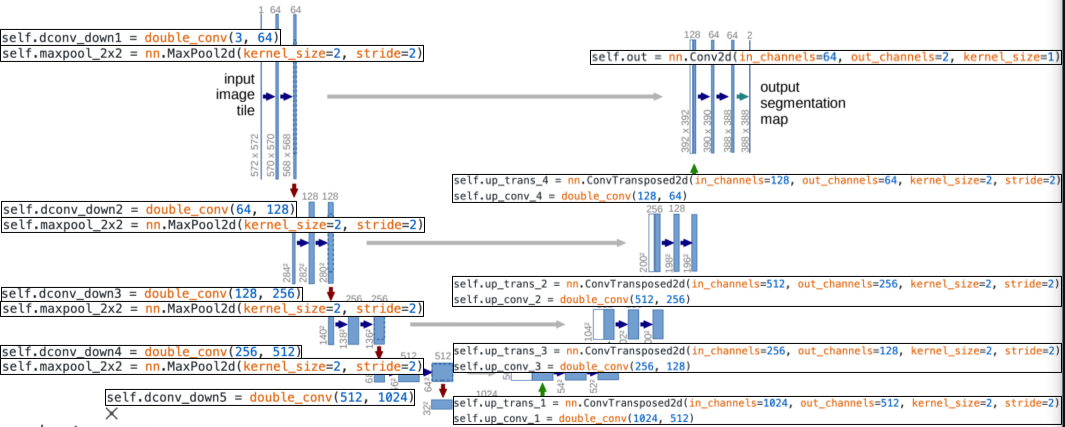
[img. U-Net Expanding Path code]
DeepLab
널리 사용되는 CRFs, Atrous Convolution의 사용이 특징인 network, Deeplab v3+가 최신.
CRFs(Conditional Random Fields)
후처리로 사용됨, 픽셀 간의 관계를 그래프로 표현한 뒤, 최적화하여 경계를 찾는 원리
score map과 경계선이 맞도록 경계선 내외부의 확산을 반복한다.
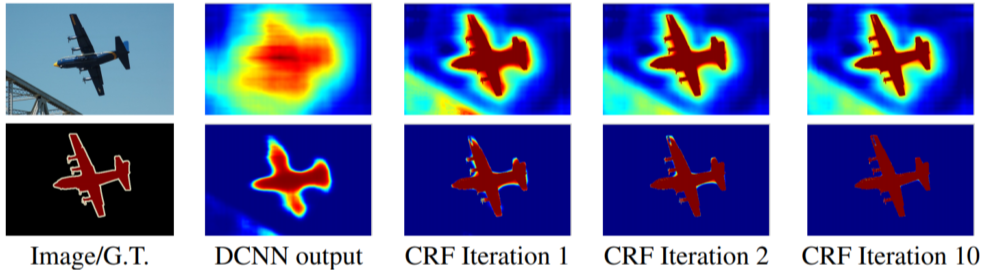
[img. CRFs 예시]
Atrous convolution(또는 Dilated convolution)
커널크기를 정하고, 정의한 Dilation factor 만큼 커널을 띄어 계산하는 Convolution 방법
같은 parameter 수와 연산량으로 더욱 큰 Receptive size를 얻을 수 있다.
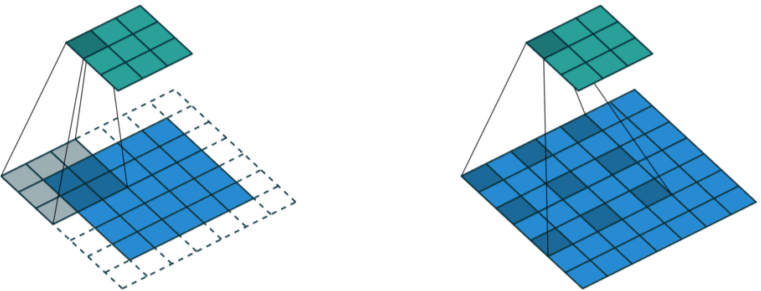
[img. 좌측이 기존의 conv, 우측이 astrous conv]
Depthwise separable convolution
입력 이미지 해상도가 클 경우, 너무 처리가 오래 걸리자, Dilated convolution + Depthwise separable convolution = Astrous separable convolution을 이용한다.
Depthwise separable convolution는 일반 convoution을 2개의 절차로 나누어 진행한다.
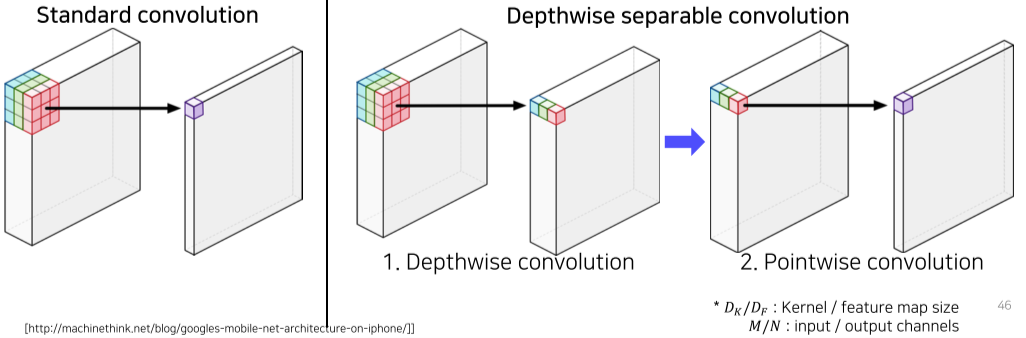
[img.Standard vs Depthwise separable convolution의 차이]
이로 인해 파라미터 수가 $D_k^2MND_F^2$에서 $D_k^2MD_F^2+ MND_F^2$로 감소하였다.
DeepLab v3+의 구조
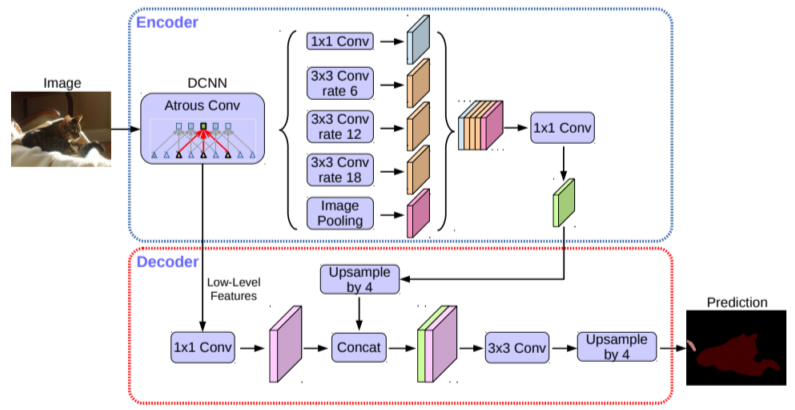
[img. 최신 DeepLab v3+의 구조 ]
- DCNN 부분에서 Dilated convolution을 통하여 feature map을 구함
- Encdoer 중간 부분에 있는 Astrous spatial pyramid pooling을 이용해 다양한 scale의 정보를 Dilated conv로 여러 feature를 추출한 후 하나로 합쳐 1x1convolution으로 하나로 합친다.
- Decoder 부분에서 Low-Level Features와 Upsampling한 Pyramid pooling feature를 Concat한 뒤, 결과값을 낸다.
Semantic segmentation 뿐만 아니라, instance segmentation(Class 뿐만 아니라 객체 또한 탐지), panoptic segmentation(배경 정보+ instance segmentation)으로 성장하고 있다.
 Original Image |
 Semantic segmentation |
|---|---|
 Instance segmentation |
 Panoptic segmentation |
[table. Image 인식 Tasks]
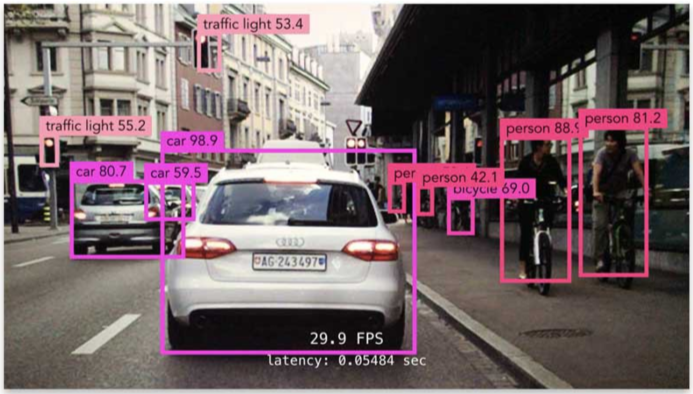
Object detection
Object detection

[img. Object detection의 예시]
Classification + Box localization의 Task
즉, 바운딩 박스의 위치 + 물체의 소속까지 예측해야함, 고수준의 문제

[imgs. 자율 주행, OCR 등의 산업에 사용됨]
Two-stage detector(R-CNN family)
Traditional methods- hand-crafted techniques 1. Gradient-based detector
과거에는 경계선의 특징으로 사람의 직관과 직접 설계한 알고리즘으로 Object Detection을 함
| Average Gradient | max (+) SVM weight | max (-) SVM weight | Original Image | R-HOG descriptor | R-HOG w/ (+) SVM | R-HOG w/ (-) SVM |
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
[img. Gradient-based detector]
- HOG : histogram of Oriented Gradients
- SVM : Support Vector Machine, 심플한 Linear 모델
- 결정 경계, 즉 그래프 내에 분류를 위한 기준선을 정의하는 모델
Traditional methods- hand-crafted techniques 2. Selective search(Box-proposal algorithm)
최근의 초기 Object Detection에서 자주 사용한 기술로, 다양한 물체 후보군에 대해서 영역을 특정하여 Bounding-box를 제안해줌
| 순번 | 1 | 2 | 3 |
|---|---|---|---|
| 구분 |  |
 |
 |
| 예시 |  |
 |
 |
| 설명 | Over-segmentation (비슷한 색, 분포끼리 영역 나눔) |
비슷한 영역끼리 합침 | Bounding box를 추출 |
[table. Selective search 예시]
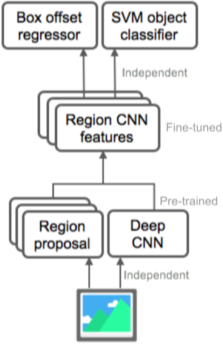
R-CNN
딥러닝 기반, Alex Net 보다 압도적인 성능
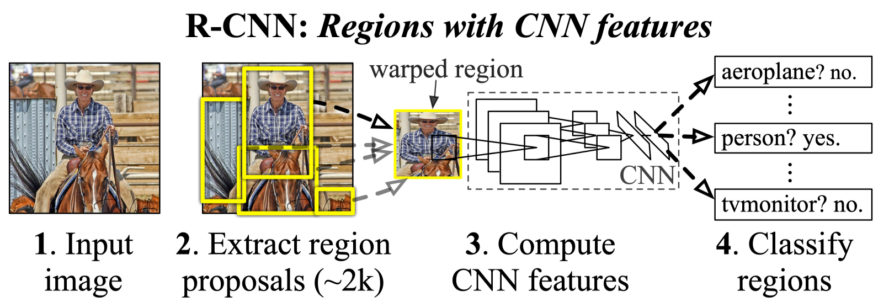
[img. R-CNN의 과정]
- 이미지 입력
- 위의 Selective search 등의 bounding box 알고리즘으로 Region Proposal(최대 2천개까지)을 구함
- 이미지 사이즈를 늘려서 해상도를 맞추고 미리 학습된(Pre-trained) CNN에 입력
- SVM을 이용해 Classification
bounding box detection의 성능의 한계와 각각 bounding box 일일이 Classification 하므로 속도가 느림
Fast R-CNN
R-CNN과 달리 이미지의 학습된 feature를 재활용해서 속도를 향상(최대 ~18배 빠름)
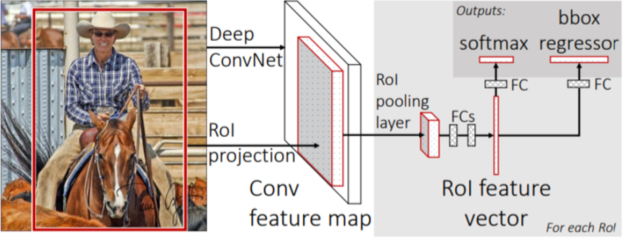
[img. Fast R-CNN의 과정]
- CNN을 통하여 feature map을 미리 뽑아냄
- Fully Convolutional Network를 이용해 해상도 고정 문제를 해결했으므로 warping 안함
- 이렇게 뽑은 feature map을 RoI pooling layer에서 관심영역(RoI, Region of Interest)만 뽑아 resize함
- FC layer와 함께 결합된 bbox regressor와 softmax를 통해 각각 더욱 정교한 바운딩박스와 classification을 함
여전히 바운딩 박스 검출(Region Proposal) 성능에 한계를 가짐.
Faster R-CNN
Region Proposal 또한 딥러닝 기반으로 바꾼 최초의 End-to-End Object Detection 모델, 즉 모두 학습 가능함
Intersection over Union(IoU)
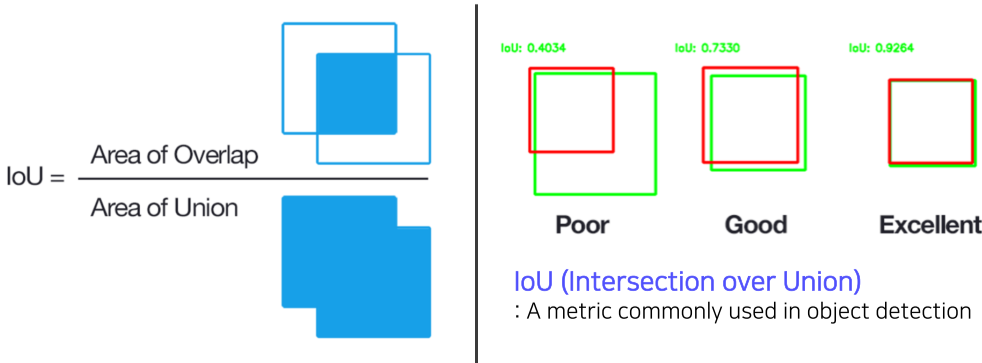
[img. IoU의 정의]
IoU (Intersection over Union) : 얼마나 bounding box가 잘 정합되어있는가를 정의
Anchor Box
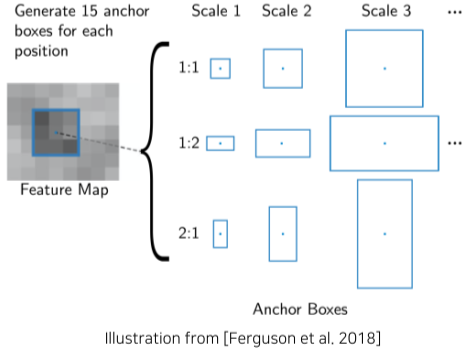
[img. Anchor Box 예시]
각 위치에서 발생할 만한 박스 후보군들을 크기와 비율 별로 미리 정의해놓으며 이를 Anchor Box라고 함
Faster R-CNN에서는 보통 9개로 정의 해놓고, 더 많이 정의도 가능
각각 Anchoer box와 실제 값(Ground-Truth)의 IoU를 비교하여 정답인 Positive sample과 negative sample을 정의하여 학습시킴
- 보통 IoU가 0.7 이상이면 +, 0.3 이하면 -
Region Proposal Network(RPN)
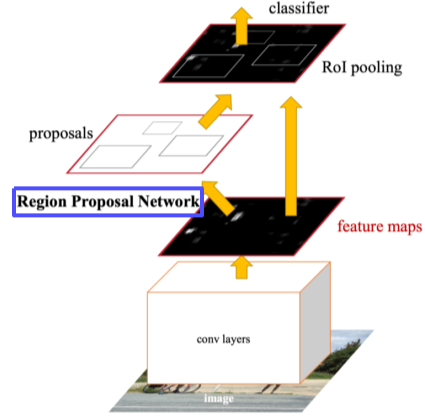
[img. Region Proposal Network(RPN)]
특히, 기존의 느린 Region proposal 알고리즘을 딥러닝 기반 RPN으로 바꿨음
그 이외에는 기존의 Fast R-CNN과 비슷함
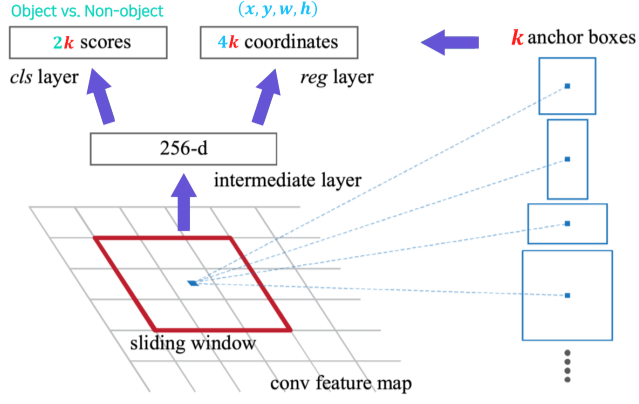
[img. 자세한 RPN 과정]
- Sliding Door 방식으로 Window 마다 k 개의 anchor box 고려
- 256 차원 feature map 추출
- feature map에서 Classification을 위해 2k개의 score 를 추출, 동시에 바운딩 박스의 크기, 위치를 위해 4k개의 값을 추출
- 계산속도를 늘리기 위해 Anchor box로 rough하게 정의한 후, 정교하게 바운딩박스 추출
- Classification에서는 Cross Entropy loss, 바운딩 박스 추출은 Regression loss 사용
- Anchor box 종류에 따른 Loss도 따로 있음
Non-Maximum Suppressions (NMS)
RPN에 의해 많은 Bounding box가 제안되며, 이후 NMS를 통해 최적의 Bounding box만 필터링한다.
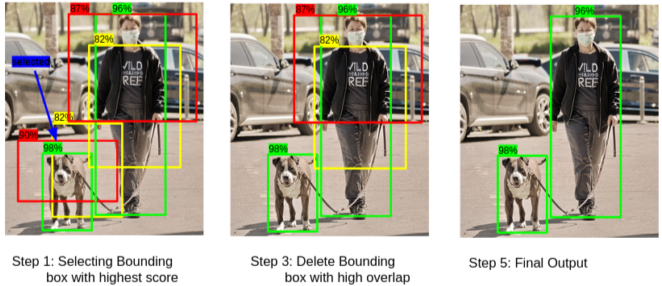
[img. NMS steps]
- 가장 높은 점수의 box를 선택
- IoU를 다른 박스와 비교
- IoU가 50 이상인 박스들 제거
- 그다음 높은 점수의 box를 선택
- 2~4 반복
| R-CNN | Fast R-CNN | Faster R-CNN |
|---|---|---|
 |
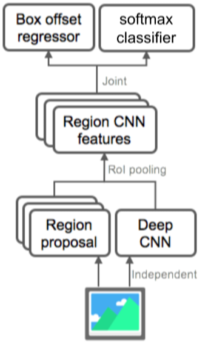 |
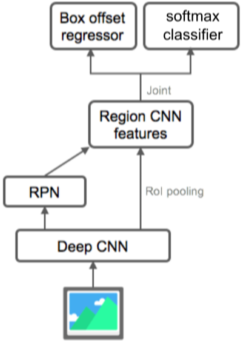 |
[table. R-CNN Family 구조 비교]
R-CNN Family은 Two-stage Detector의 대표 모델들이다.
Single-stage detector
Single-stage detector은
정확도가 조금 뒤떨어지지만 리얼 타임 Detection 가능할 정도로 높은 속도에 중점을 둠
RoI pooling layer를 사용하지 않고, 간단한 구조와 빠른 속도를 자랑하는 경우가 많음
| One-stage detector | Two-stage detector |
|---|---|
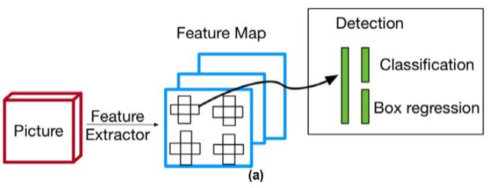 |
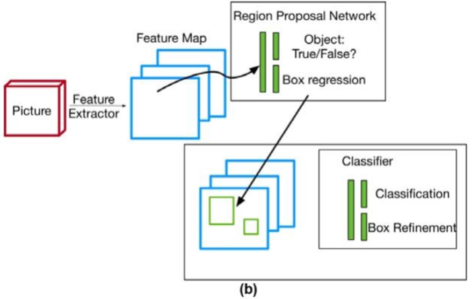 |
[tables. one-stage vs two-stage]
YOLO(You only look once)
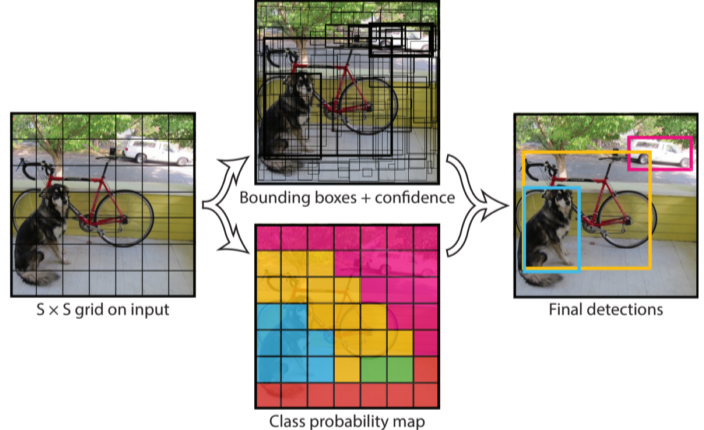
[img. YOLO 과정]
- Input을 S 크기의 그리드로 나눔
- 각 박스에 대하여 Boundig box와 Confidence를 예측
- 이때, Ground truth와 IoU를 비교하여 학습함
- 동시에 각 위치에서의 Class Score를 추가로 예측
- NMS를 통해 Bounding box 추출
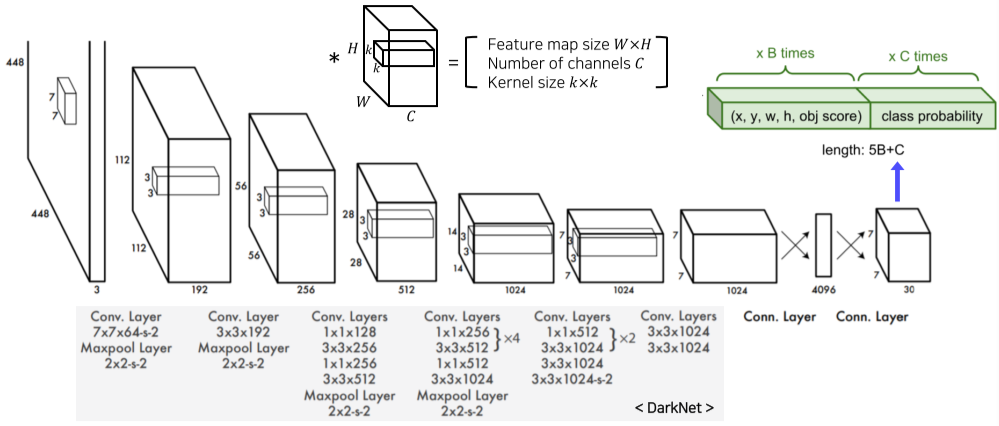
[img. YOLO의 구조]
일반 CNN 구조와 비슷하며 SxSx30의 아웃풋이 나옴
(채널수 30 = class probability 20 + x,y,w,h 각각 2채널)
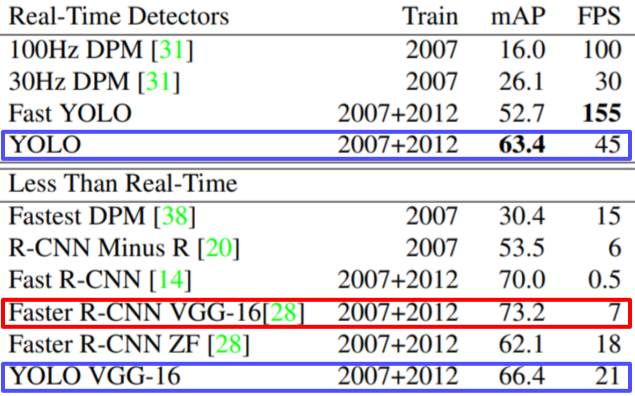
[img. YOLO 성능비교]
Two-stage에 비해 성능은 떨어지지만 훨씬 빠르다.
- 성능이 떨어지는 이유는 맨 마지막 Layer에서 한번만 Prediction 하므로
Single Shot Multibox Detector(SSD)
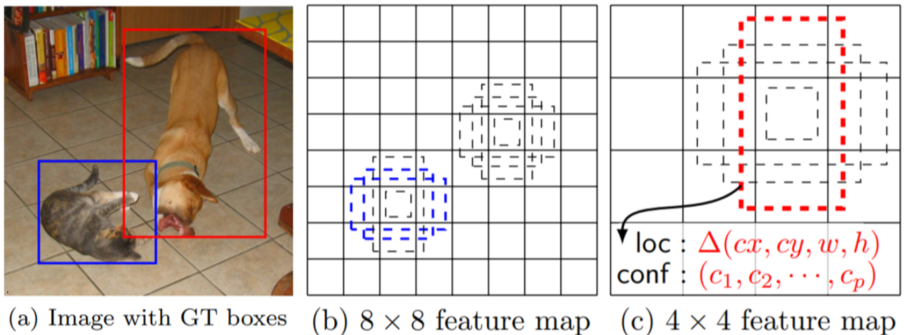
[img. SSD 예시]
feature map들의 다른 해상도마다 적절한 크기의 Bounding box를 설정하게 해줌
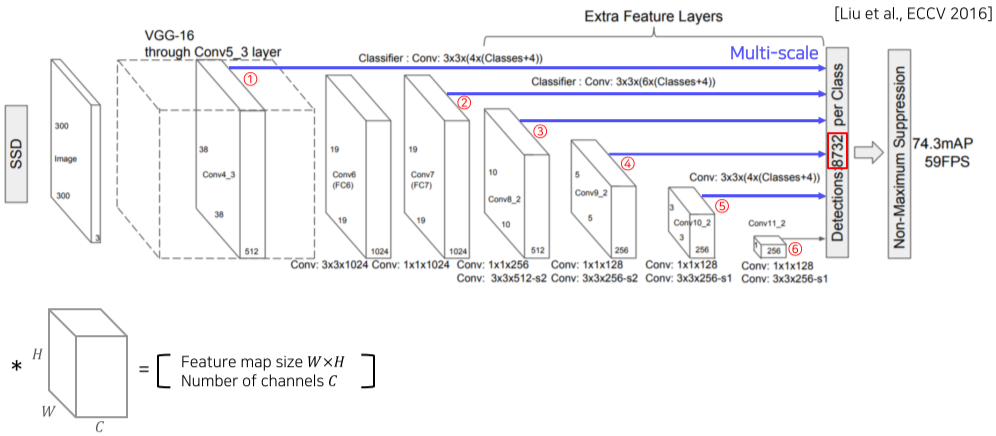
[img. SSD의 구조]
VGG-16을 backbone으로, 다양한 Scale의 conv를 통과시켜 여러 해상도에 대응함

[img. SSD 전체 anchor box 갯수 계산]
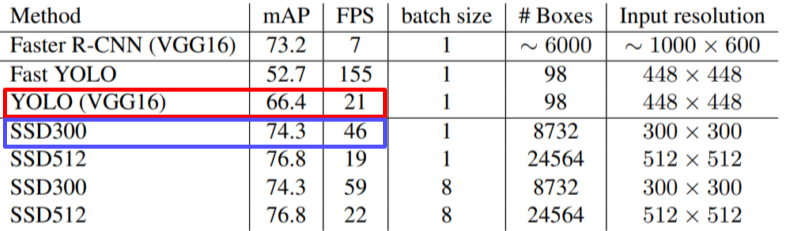
[img. SSD 성능 비교]
속도와 성능이 YOLO 뿐만 아니라 R-CNN 계열 보다도 좋다.
Single-stage detector vs. two-stage detector
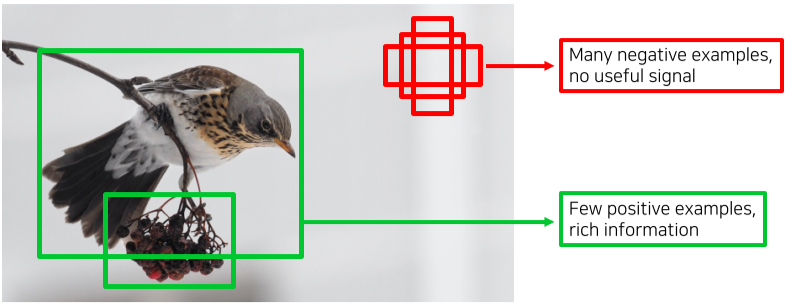
[img. Class imbalance Problem 예시]
Class Imbalance Problem : Single stage detector의 문제, 결과값에 필요없는 negative anchor box가 positive anchor box보다 훨씬 많은 문제
Focal Loss
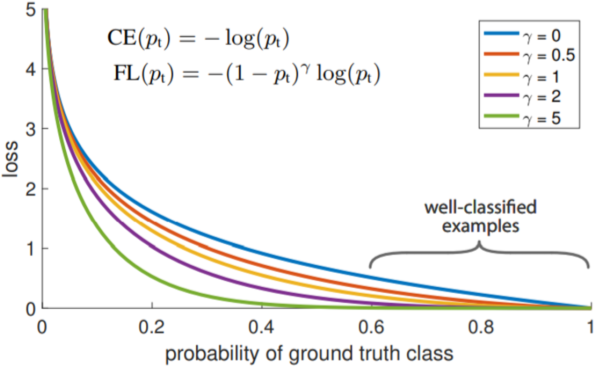
[img. Focal loss 그래프]
위의 Class Imbalance Problem를 해결하기 위해 제안됨
cross entropy loss의 연장선으로, 추가적인 확률 텀이 붙게 된다.
CE와 비교하여 $\gamma$값에 따라 정답의 경우 Loss를 더욱 낮게, 오답의 경우 Loss에 더욱 가중을 주게 된다.
\(Cross\ Entropy\ Loss:CE(p_t)=-log(p_t)\\
Focal\ Loss:FL(p_t)=(1-p_t)^\gamma CE(p_t)=-(1-p_t)^\gamma\)
[math. Focal loss의 수식]
RetinaNet과 Feature Pyramid Networks(FPN)
RetinaNet = FPN + class/box subnet
U-Net과 비슷한 구조로, low level의 feature와 high level의 feature를 합하여 class와 box_bounding을 각 위치에서 수행
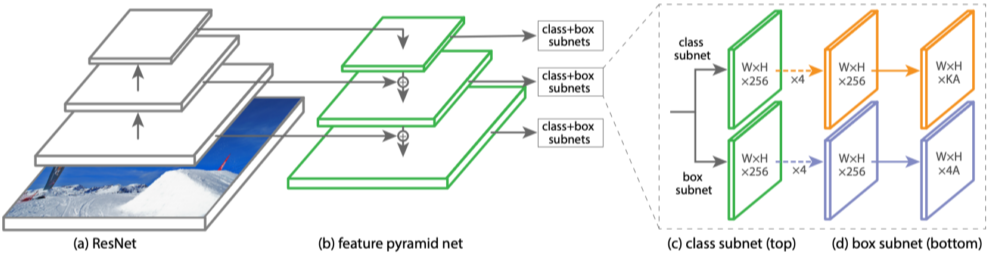
[img. RetinaNet 구조]
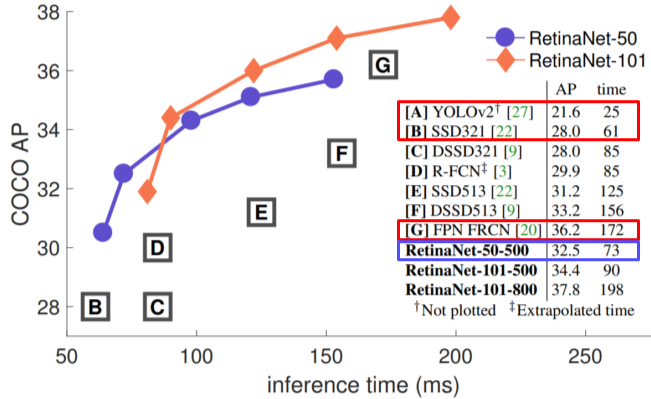
[img. RetinaNet 성능]
비슷한 속도에 높은 성능을 보이며, 속도를 희생시키면 성능을 더 올릴 수 있음
Detection with Transformer
DETR(DEtection TRansformer)
NLP에서 큰 혁신을 보여준 Transformer 구조를 Object Detection에 활용한 구조,
DETR은 facebook에서 개발
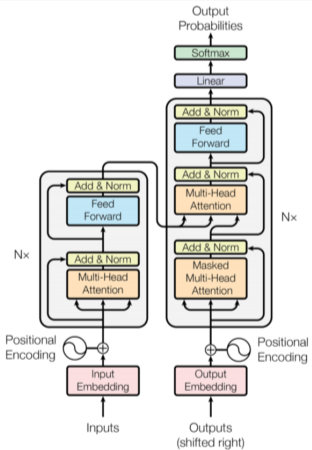
[img. Transformer 구조]
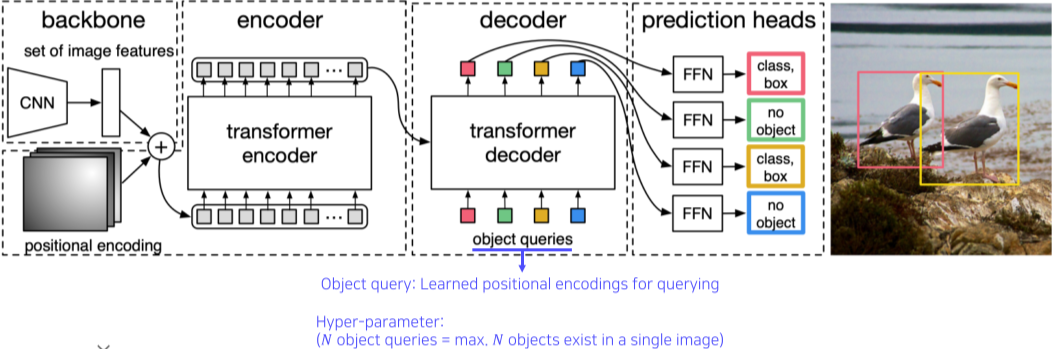
[img. DETR 구조]
CNN의 feature와 pixel의 positional encoding을 합하여 encoder에 넣어준 후, N개의 Object queries와 함께 decoder에 넣어준 후, 각 픽셀의 class, bounding box를 출력해주는 구조
[img. bounding box 이외의 방법들]
이외에도 CornerNet, CenterNet 등 Bounding box 대신 중심점, 양 끝점을 찾는 연구 등이 진행되는 중
CNN Visualization
CNN을 시각화하는 것
Visualizing CNN
[img. CNN is a black box]
많은 경우 CNN의 내부 로직 등을 알 수 없거나, 신경쓰지 않고 개발하는 경우가 많다.
어째서 이러한 결과가 나왔는가? 무엇이 문제인가? 어떻게 하면 개선 가능한가? 등을 알아보기 위해 Black box 상태이 CNN 내부를 알아볼 필요가 있다.
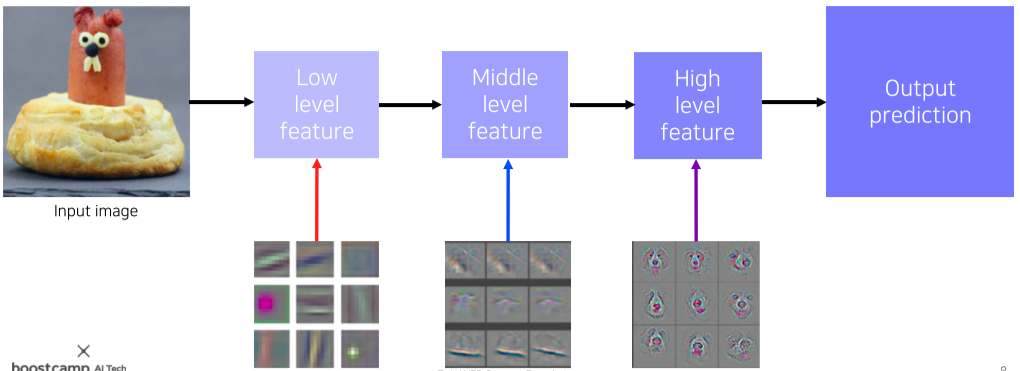
[img. ZFNet 예제]
ZFNet 등에서는 각 level의 feature를 확인하여 학습을 파악할 수 있어서 이를 통해 성능을 개선시킬 수 있었다.
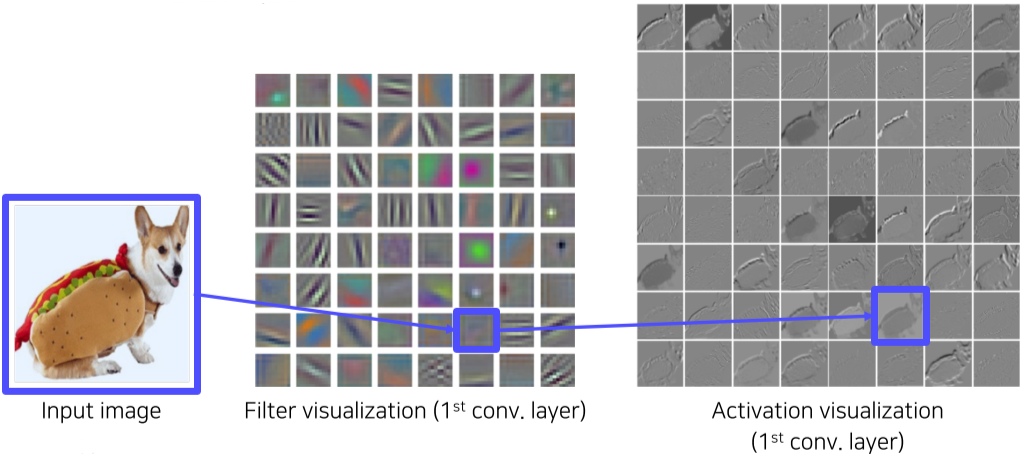
[img. 간단한 Filter weight visualization]
저차원인 1번째 conv layer의 경우 3채널 또는 1채널로 이루어져있어 상단과 같이 직관적으로 Visualization이 가능하지만, layer가 깊어지면(고차원이 되면) 채널 수가 늘어나면서 인간이 이해 가능한 형태의 visualization이 불가능하다.

[img. Types of neural network visualization]
왼쪽으로 갈수록 모델에 대한 이해, 오른쪽을 갈수록 데이터 분석
Analysis of model behaviors
고차원 layer의 feature들을 분석하는 방법을 알아보자
고차원 Embedding feature analysis 1번째 방법 - 예제 검색 방법

[img. Nearest neighbors (NN) in a feature space]
NN-search의 경우 feature space에서 가장 가까운 사진들을 비교(예제 검색)함으로써 분석이 가능하다.
상단의 코끼리 사진들을 보아, 잘 clustering 된걸 알 수 있으며, 하단의 강아지 사진으로 pixel 위치(강아지 형태, 위치)가 바뀌어도 모델이 잘 찾아낸다는 것을 알 수 있다.
이러한 예제 검색 방법의 Step은 다음과 같다.
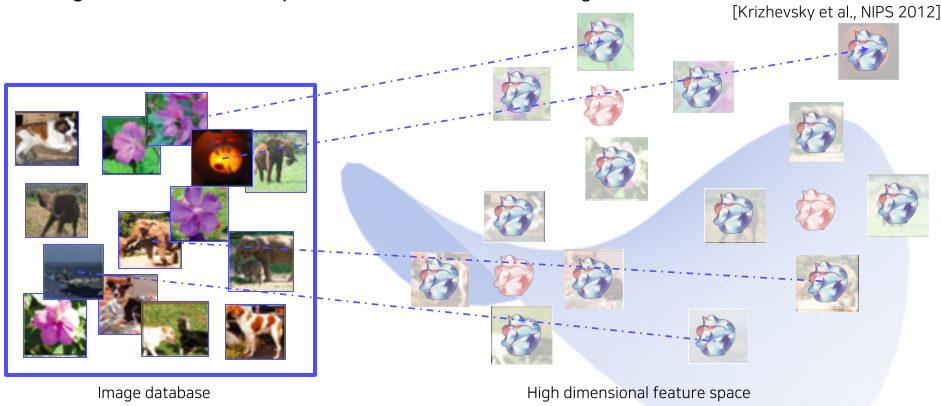
- 신경망을 통하여 Database에서 각 Input의 고차원 feature를 뽑아내 High dimensional feature space에 위치시킨다.
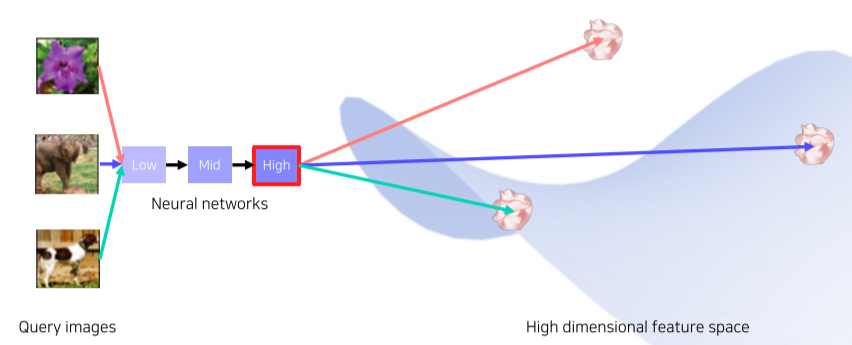
[img. feature 추출 및 DB 위치]
- 검색하고 싶은 Input의 고차원 feature를 뽑아 낸 뒤 마찬가지로 High dimensional feature space에 위치시킨다.
[img. Input 사진들의 feature의 위치]
- 가장 가까운 이웃의 feature를 가져온 뒤, 매칭되는 Input을 가져온다.
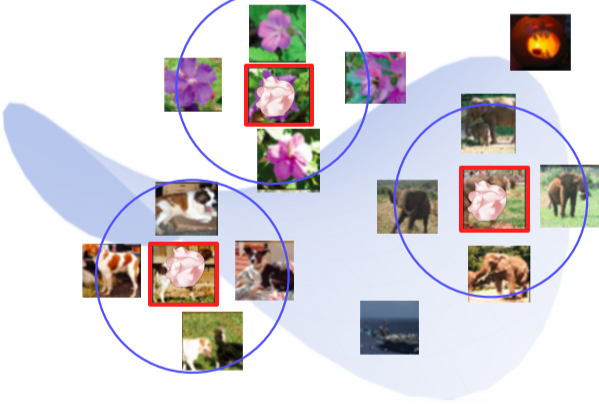
[img. 사진과 가장 가까운 이웃들]
- 그 Input들과 비교하여 Visualization 한다.
단, 이 방법은 전체적인 형태가 아닌 일부 예제만 파악한다는 단점이 있음
고차원 Embedding feature analysis 2번째 방법 - Dimensionality reduction(차원 축소)
우리가 사는 3차원(시간을 포함하면 4차원) 공간에 맞게 고차원 공간을 낮추는 방법
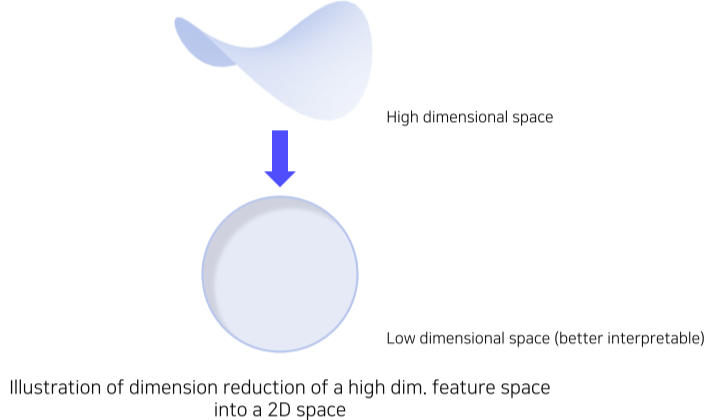
[img. 고차원 공간을 저차원 공간으로 변형]
대표적인 방법으로 t-SNE가 있다
t-distributed stochastic neighbor embedding(t-SNE)

[img. t-SNE를 통한 숫자 손글씨 구분(MNIST) feature space의 visualization]
-
고차원 데이터를 2차원으로 매핑한 결과
-
3,5,8의 cluster가 한껏 뭉쳐있는 걸로 보아 CNN이 비슷하다고 느낀다는 것을 알 수 있다.
중, 고차원 해석: Activation investigation 1-Layer activation
Layer의 Activation을 분석하여 모델의 특성을 파악하는 방법

[img. AlexNet의 Activation 분석]
특정 Activation의 채널(hidden node)을 masking 한뒤 overlay하여 무슨 일을 하는 노드인가 알아볼 수 있다.
중차원 해석: Activation investigation 2-Maximally activating patches
각 채널의 hidden node의 가장 큰 값을 가지는 patch(activation)를 가져와 나열하는 것

[img. hidden node 별 image patch]
이를 통해 각 히든 노드가 찾는 부분(=하는 일)을 알 수 있다.
국부적이므로 중차원 정도 해석에 어울린다.
1) 특정 layer의 특정 channel을 고른다.
2) input 이미지를 집어 넣은 후 선택한 채널의 activation 값을 저장한다
3) 최대 activation value의 Receptive field를 Input에서 crop하여 image patch로 만든다.
결과 해석: Activation investigation 3-Class visualization
예제 데이터 사용없이 네트워크가 기억하는 이미지가 무엇인지 판단
ex)이 CNN은 특정 클래스의 이미지를 대략 어떻게 생겼다고 기억하고 있는가?

[img. CNN이 기억하고 있는 개와 강아지의 모습]
편향 등을 알아볼 수도 있다. (ex) 위 새 사진은 많은 데이터가 나무와 함께 찍힘)
\(I^*=\underset{I}{argmaxf(I)}-Reg(I) =\\
I^*=\underset{I}{argmaxf(I)}-\lambda \left\|I\right\|^2_2\\
\lambda \left\|I\right\|^2_2, Reg(I):Regularizaion\ term\\
I: 영상\ 입력, f(I):CNN\ 모델\)
[math. Gradient ascent, 일종의 Loss]
Gradient ascent를 통하여 Visualization을 위한 이미지를 합성하게 된다.
$argmaxf(I)$를 통하여 Input image I를 돌며 각 클래스의 가장 높은 스코어를 얻는다.
너무 큰 스코어 값이 나오는 것을 막고, 이해할 수 있는 형태로 바꾸기 위해 Regularizaion term 추가
최대 스코어값을 찾으려는 과정이므로 Gradient ascent이며, 부호만 바꾸면 Gradient descent이므로 해당 알고리즘을 그대로 사용할 수 있다.
1) 임의의 영상(검정, 하양, 회색 혹은 랜덤한 이미지)을 CNN에 넣어 관심 class의 prediction score를 추출
- 처음 주는 영상부터 바뀌기 시작하므로 초기값의 설정에 따라 완성 이미지가 바뀐다.
2) Backpropagation으로 gradient maximizing하여 관심 class의 prediction score가 높아지는 방향으로 입력단의 이미지를 업데이트해준다.
3) 업데이트된 영상으로 1~2를 계속 반복한다
Model decision explanation
모델이 특정 입력을 어떤 각도로 해석하는 가에 대한 설명
Saliency test 계열
주어진 영상의 제대로 판정되기 위한 각 영역의 중요도를 판별
이때 중요도가 표시된 그림을 Saliency map이라고 한다.
Occlusion map
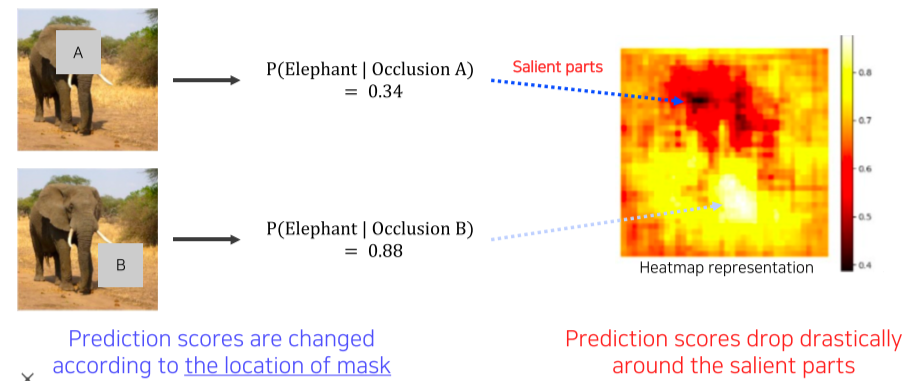
[img. Occlusion map 예시]
특정 픽셀을 가려서 바뀌는 Predicdtion score 값을 Heatmap 형식으로 표현한 것
영상의 가린 부분에 따라, 많이 떨어지면 중요한 영역이며 적게 떨어지면 덜 중요한 부분이다.
이 떨어진 정도를 표시하여 표현할 수 있다.
via backpropagtion

[img. backpropagation을 이용한 saliency map 예시, 밝은 부분이 판단에 중요한 영역]
앞서 했었던 Class visualization의 Gradient ascent와 비슷
랜덤 이미지가 아닌 특정 이미지를 classification을 한 뒤, class score에 대한 backpropagation으로 관심 영역의 점수를 표시하는 방법
1) 입력 영상을 넣어 특정 class의 score를 얻어낸다
2) Backpropagation으로 Input까지 진행해 gradient를 얻어낸다.
3) gradient의 절대값 또는 제곱값을 하여 얻어낸 gradient의 크기를 이미지형태로 얻는다
- 이를 gradient magnitude map이라고 한다.
- 이를 여러번 반복하여 더욱 정확한 Saliency map를 얻어낼 수 있다.
backpropagation을 이용한 더 진보적인 visualization 방법으로 Deconvolution이 있다.
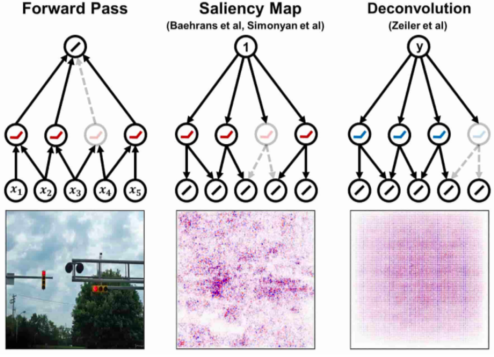
[img. Dconvolution의 결과물]
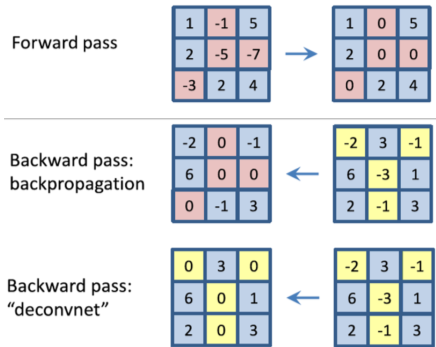
[img. ReLU의 작용과 deconvnet의 차이]
보통 CNN의 경우 Forward pass 시 음수는 ReLU 함수를 통과하며 0으로 마스킹되며,
Backward pass 시 이를 기억하여, 해당 픽셀을 다시 0으로 마스킹한다.
하지만 deconvnet은 backward 시 Forward pass때 처럼 음수가 0으로 마스킹된다.
\(ReLU:h^{l+1}=max(0,h^l)\\
backpropagation:\frac{\partial L}{\partial h^l}=[(h^l>0)]\frac{\partial L}{\partial h^{l+1}}\\
deconvnet:\frac{\partial L}{\partial h^l}=[(h^{l+1}>0)]\frac{\partial L}{\partial h^{l+1}}\)
[math. 기존의 pass와 deconvnet의 pass의 수식화]
또한, 기존의 방법과 deconvnet의 And 연산하여 만든 Guided Backpropagation 또한 가능하다.
 |
|---|
| $\frac{\partial L}{\partial h^l}=[(h^{l+1}>0)\&(h^{l+1}>0)]\frac{\partial L}{\partial h^{l+1}}$ |
[table. Guided backpropagation]

[img. Guided backpropagation과 다른 방법들 비교]
수학적으로 구한 것이 아니라 경험적으로 구했지만 결과는 괜찮게 나온다고 한다.
forward 시 결과를 미친 양수 pixel과 backward 시 ‘이 부분은 증폭하라’의 의미를 가진 양수 pixel만 받아들인 결과 => 즉 classification에 긍정적 영향을 끼친 pixel만 표시되게 됨
Class activation mapping(CAM)
어떤 부분을 참조하여 결과가 나왔는지 보여줌.
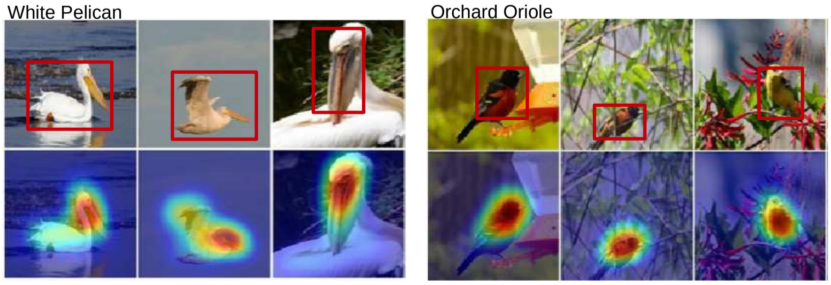
[img. CAM 예시]
기존의 CNN 구조를 조금 바꾸어야 한다.
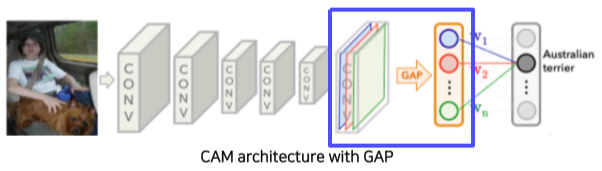
[img. CAM을 쓸 수 있게 개조된 CNN]
기존의 출력 이전의 FC Layer 대신 Conv Layer 이후에 Global average pooling (GAP) Layer와 FC layer 한 층이 삽입된다.
이후 Classification에 대해 재학습된다.
\(S_c=\overset{Channels}{\sum_k}w_k^c\overset{GAP\ feature}{F_k}\overset{GAP}{=}\sum_kw_k^c\sum_{(x,y)}\overset{Feature\ map\\before\ Gap}{f_k(x,y)}=\\
\sum_{(x,y)}\ \ \overset{CAM_c(x,y)}{\sum_kw_k^cf_k(x,y)}\\
S_c:Score\ of\ the\ class\ c\\
k: 마지막\ conv\ layer\ channel\ 수\)
[math. CAM이 포함된 CNN 구조 유도]
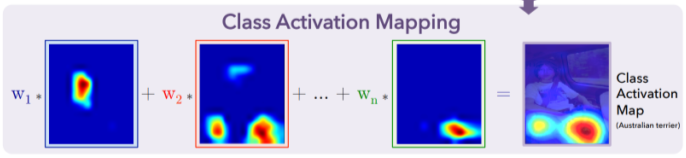
[img. GAP layer 부분의 작용]
(+) 성능이 좋아 가장 많이 사용되는 Visualization 방법
(+) 공간 정보를 주지(supervision?) 않아도 공간에 대한 정보가 나타남
이를 통해 bounding box를 쳐주면 object detection으로 사용 가능
- Weakly supervised learning이라고 함
(-) 구조를 바꾸고 재학습을 해야하며, 이 과정에서 성능이 바뀔 수 있다는 점이 단점
Grad-CAM
구조를 바꾸지 않아도 활용할 수 있는 CAM 구조

[img. Grad-CAM의 예시]
(+) CAM과 비슷한 성능, 구조를 바꾸지 않아도 됨
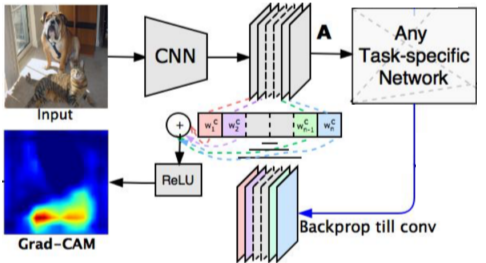
[img. Grad-CAM의 구조]
$\overset{CAM_c(x,y)}{\sum_kw_k^cf_k(x,y)}$ 부분에서 $w_k^c$(importance wieghts)만 구하면 맵을 그릴 수 있다.
Backpropagation을 Input 이미지가 아닌 관심을 가지는 activation map까지만 진행하며, 그렇게 구한 importance weight ($\alpha_k^c$)와 activation map($A^k$)를 선형결합하여 ReLU를 씌워 양수값만 사용
\(\overset{Global\ average\ pooling}{\alpha^c_k=\frac{1}{Z}\sum_i \sum_j \frac{\partial y^c}{\partial A_{ij}^k}}\\
L^c_{Grad-CAM}=ReLU(\sum_k\alpha^c_kA^k)\\
\alpha^c_k: importance\ weight\ of\ the\ k-th\ feature\ map\ w.r.t\ the\ class\ c\\
\frac{\partial y^c}{\partial A_{ij}^k} : Gradients\ via\ backprop\)
[math. Grad-CAM 수식]
영상 인식 뿐만 아니라 CNN 구조만 존재하면 어떤 Task에도 활용 가능
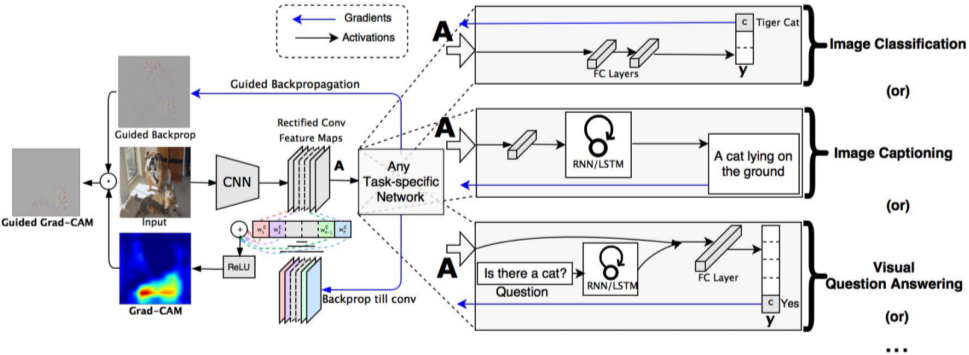
[img. Grad-CAM 활용 예시와 Guided Grad-CAM]
추가로 Guided Backprop을 추가하고, Grad-CAM을 내적하여 Guided Grad-CAM을 구하는 것이 일반화 되어있다.
- Guided Backprop(sharp 하지만 class 구분 불가) + Grad-CAM (Rough하고 smooth하지만 class 구분 가능) = Guided Grad-CAM (서로 단점 보완)

[img. SCOUTER 예시]
최근에는 해석 결과에 대한 질문에 대해 답을 줄 수 있는 Visualization 방법(SCOUTER)도 등장함
Visualization 기술을 응용해 GAN에 이용하여 명령을 내릴 수 있음(GAN dissection)

[img. 표시한 부분에 문을 생성하는 예시]
Instance/panoptic segmentation and landmark localization
Semantic segmentation, Object Detection은 더욱 어려운 Task로 고도화되면서 연구가 줄어듦
Original Image |
Semantic segmentation |
|---|---|
Instance segmentation |
Panoptic segmentation |
[table. Image 인식 Tasks]
Instance segmentation, Panoptic segmentation은 자율주행 등, 산업 등에서 많이 쓰임
Instance segmentation
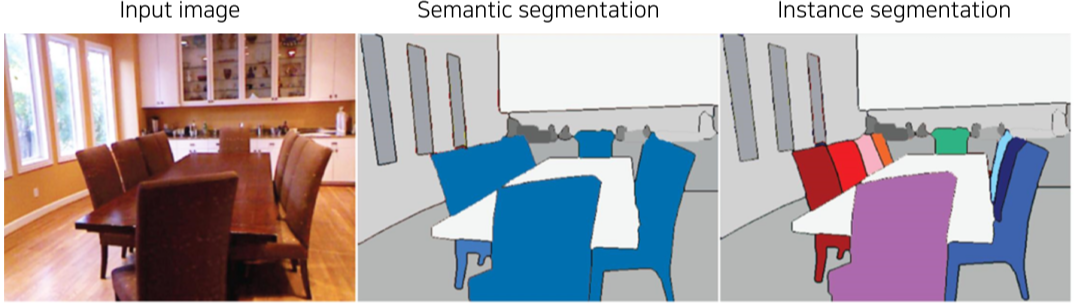
[img. Instance segmentation vs Semantic segmentation]
같은 물체 class 라도 Instance가 다르면 구분해야하는 문제, 실제 응용사례 많이 사용됨
Object Detection 모델들의 연장해서 많이 사용 됨.
Mask R-CNN
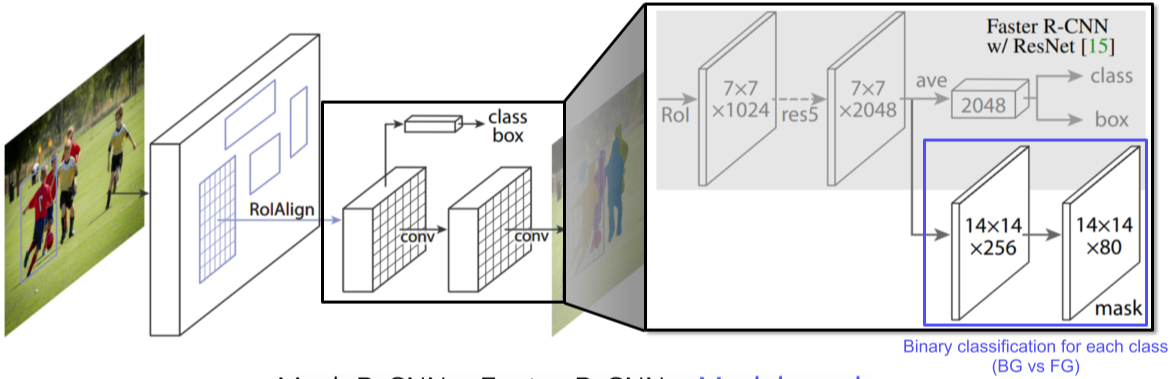
[img. Mask R-CNN = Faster R-CNN + Mask branch]
Faster R-CNN과 여러 모로 비슷하지만 개선을 많이 시킴
- RoI pooling 대신, 정교한 소수점 좌표도 가져올 수 있는 RoIAlign pooling layer 사용
- 마지막 layer에 병렬로 mask branch라는 Fully convolutional Network가 추가되어 Output을 Upsampling 뒤, class 수만큼의 채널(여기서는 80개)에 Binary classification
- class 예측결과를 가져와 참조할 mask를 정함
[img. R-CNN family의 추가]
그림의 예시 branch 대신, Key point branch 라는 것을 추가하면 사람의 자세를 추정하는 Task도 가능
YOLACT(You Only Look At CoefficienTs)
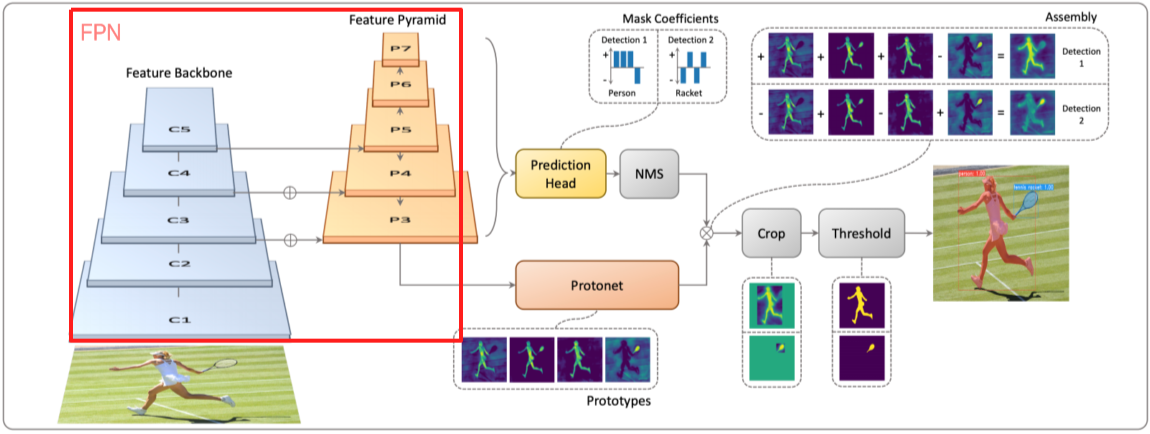
[img. YOLACT 구조]
실시간 Instance segmentation model
- Feature Pyramid 구조를 이용해 고해상도이며,
- Protonet 부분에서 Mask의 저해상도의 Prototype Soft segmentation component를 추출한 뒤,
- Prediction Head에서 각 Class 간의 Mask Coefficients를 구하여 이를 이용해 2번의 prototype와 선형결합(Weighted Sum)하여 detection에 적합한 Class별 Mask Map을 만들어준다.
- 이후 Crop과 Threshhold를 통해 결과를 도출
YolactEdge
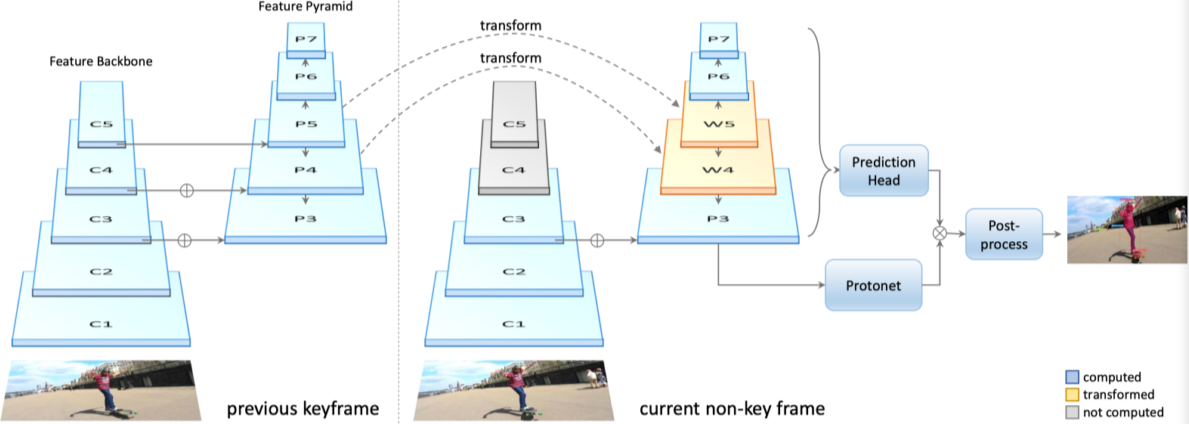
[img. YolactEdge 구조]
위의 YOLACT를 더욱 경량화하여 영상 처리를 소형기기들에 사용가능한 모델
이전 frame의 feature를 다음 keyframe에 활용하여 연산량 줄임 (성능 비슷, 속도 빠름)
아직은 현실에 사용하기 힘든 성능
Panoptic segmentation
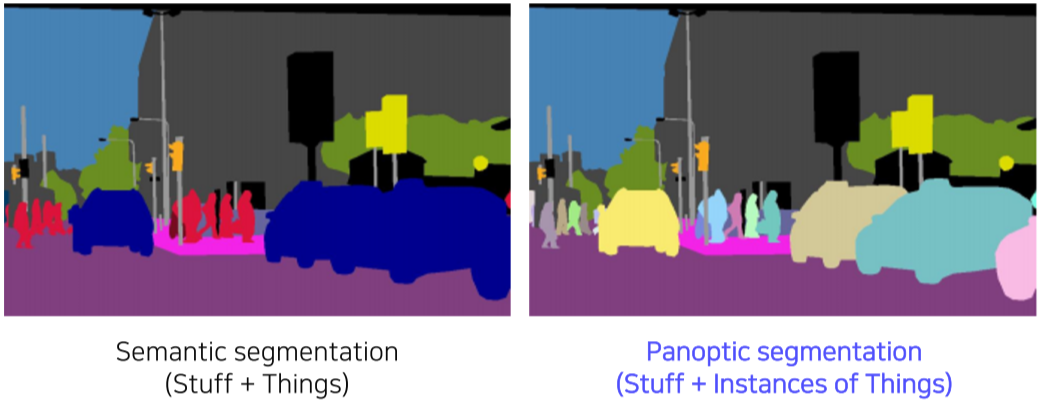
[img. Panoptic segmentation vs Semantic segmentation]
배경정보 + instnace 구분 가능
UPSNet
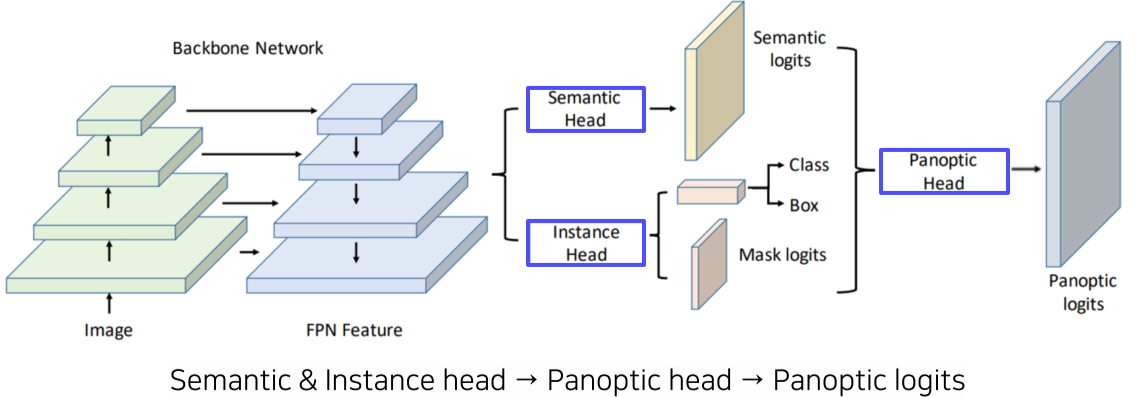
[img. UPSNet 예시]
FPN(feature pyrmid network) 구조에 병렬로 구성된 semeantic Head와 Instance head 그리고 이를 병합하는 Panoptic Head로 구성된 구조
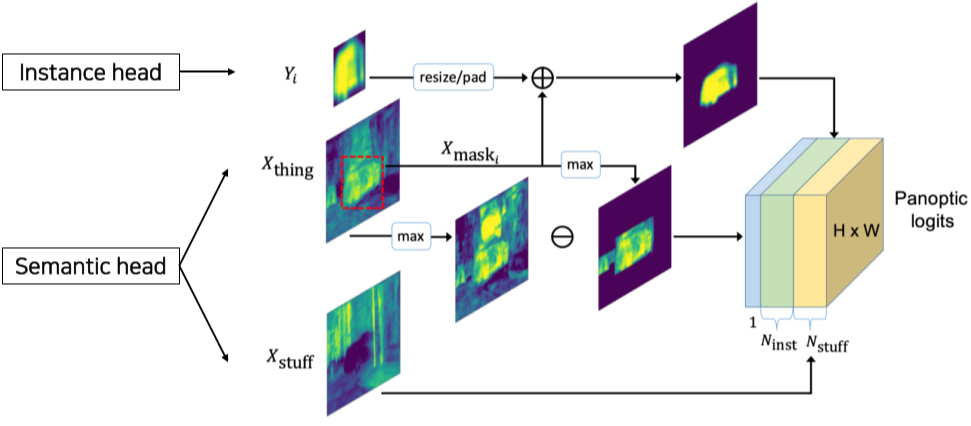
[img. Panoptic Head의 자세한 구조]
Instance head의 Instance Mask Output의 경우 리사이징과 패딩을 거친 후 Semnatic head의 물체 mask와 합해진 뒤, output 채널로 concat
- 이를 통해 위치를 알 수 있음
Semantic head의 물체 mask Output의 경우, 위의 Instance mask와 사용된 결과들은 Max된 뒤 기존 물체 mask에서 빠진 뒤 1채널로 output에 추가됨
- 모두 빠지고 남은 물체 mask는 Unknown mask가 된다.(class에 정의되지 않은 물체)
Semantic head의 배경정보 Mask Output은 그대로 Output 채널에 추가됨
VPSNet
영상에 사용가능한 Panoptic segmetnation 모델
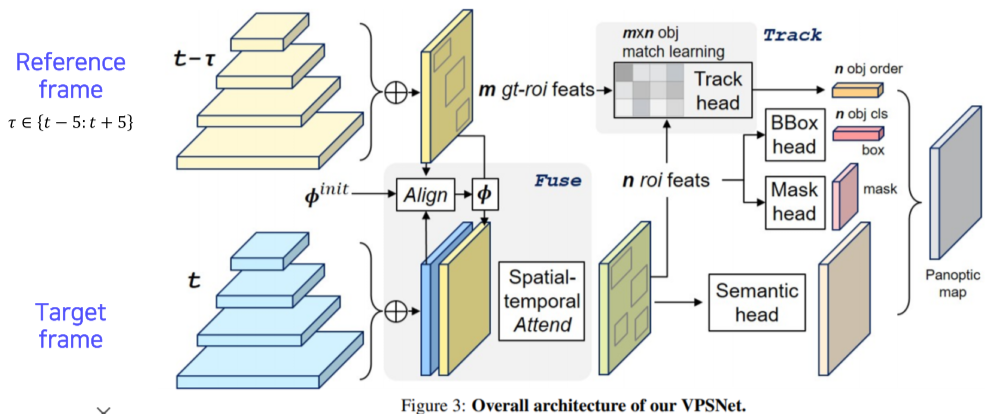
[img. VPSNet 구조]
-
두 프레임간의 모션맵(해당 픽셀이 다음 프레임에 어디로 위치가 바뀌었는가?)를 이전 프레임 feature map에 적용하여 feature의 움직임을 tracking한 뒤, FPN을 통해 뽑은 해당 featrue map에 합쳐서 사용
-
Track head를 통해 이전 프레임과 현재 프레임 간의 RoI feature 연관성을 찾아낸다.
-
이후 UPS Net과 비슷함
Landmark localization

[img. Landmark localization 예시]
key point 혹은 landmark 라고 불리우는 영상에서 중요한 부분을 정의하여 위치와 class를 추적하는 것
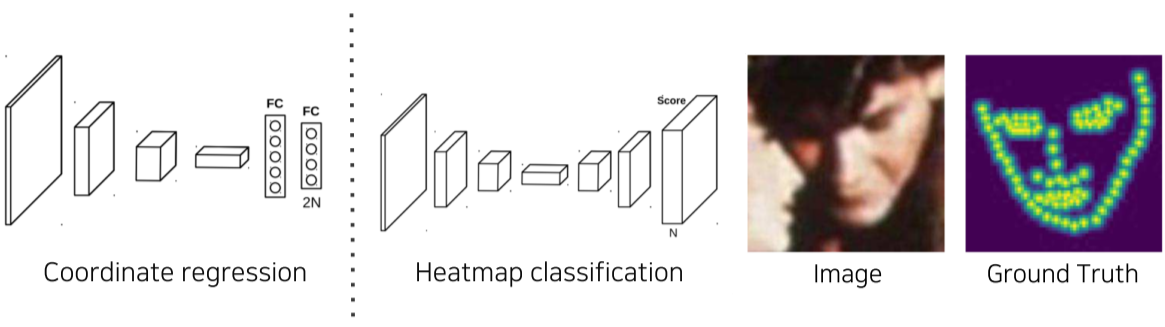
[img. Coordinate regression vs Heatmap classification]
기존의 box bounding 찾던 방법(Coordinate regression)으로 keypoint를 찾으려고 하니 문제가 있었고 Heatmap classification이 좀더 정확하지만 계산량이 큼
- 각 채널에 keypoint를 할당하고 class로 생각함
Gaussian Heat map을 형성하기 위해 Landmark location을 다음과 같이 변형한다.
\(G_\sigma(x,y) = \exp\left(-\frac{(x-x_c)^2+(y-y_c)^2}{2\sigma^2}\right)\\
(x_c, y_c):center\ location\)
[math. points to Gaussian 수식]
쉽게 말해 해당 location 좌표를 평균점으로 삼고 주변에 Gaussian을 씌운다.
Heatmap 형식을 사용하면 generalization 성능이 좋아짐.
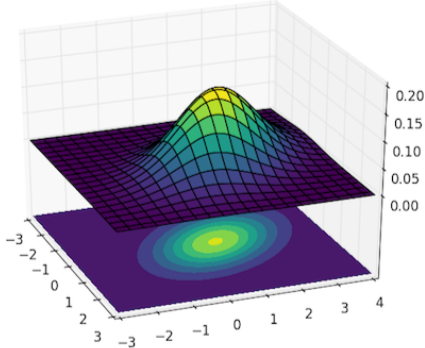
[img. Gaussian 도식]
# Generate gaussian
size = 6 * sigma + 1 # 출력 해상도 크기
# 모든 영상 좌표의 배열
x = np.arrange(0, size, 1, float)
y = x[:, np.newaxis]
x0 = y0 = size // 2 # 중간이 평균점이라고 가정
# numpy의 행렬 덧셈의 경우 sx1, 1Xs가 더해지면 sxs 행렬이 나옴
# The gaussian is not normalized, we want the center value to equal 1
if type == 'Gaussain':
g = np.exp(- ((x - x0) ** 2 + (y - y0) ** 2) / (2 * sigma ** 2))
elif type == 'Cauchy':
g = sigma / (((x - x0) ** 2 + (y - y0) ** 2 + sigma ** 2) ** 1.5)
[code. Gaussian 코드 구현 ]
반대로 가우시안의 결과값을 좌표평면으로 바꾸어서 결과값을 보여주는 수식도 필요하다.
Hourglass network
Landmark를 위한 특별한 구조
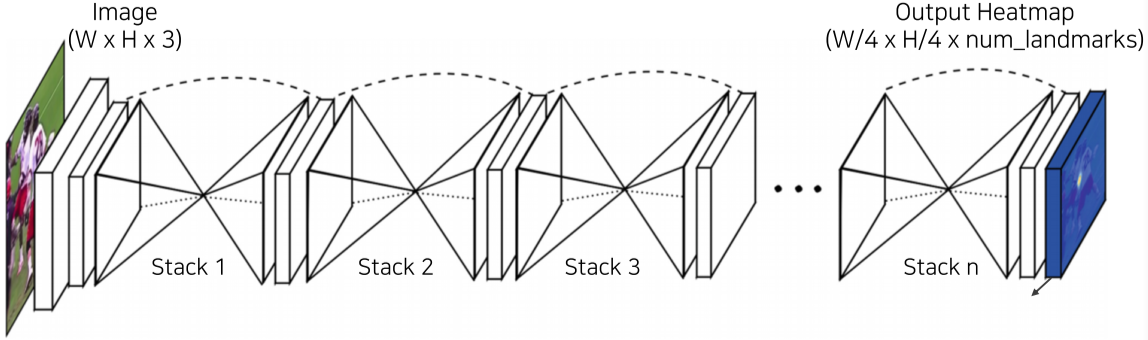
[img. Stacked hourglass 구조]
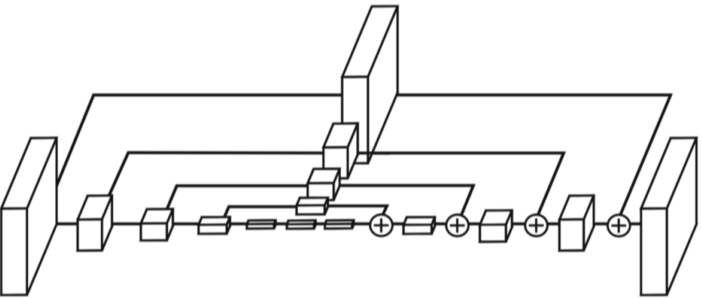
[img. 확대한 hourglass 구조]
UNet 구조를 여러 스택 쌓은것과 비슷한 구조
- 다만 Concat이 아니라 합으로 되어있으며, 그냥 skip해서 주어지는 것이 아니라 convolution layer를 하나 통과함
- UNet보다 FPN구조와 좀더 유사함
크기를 줄여 Receptive field를 늘린 구조
DensePose

[img. image의 UV Map 표현]
몇 개 픽셀이 아닌 신체 전부 같은 아주 Dense한 landmark를 구하여 3D UV map 생성 가능
- 3D 모델을 만드는 방법은 다른 방법임.
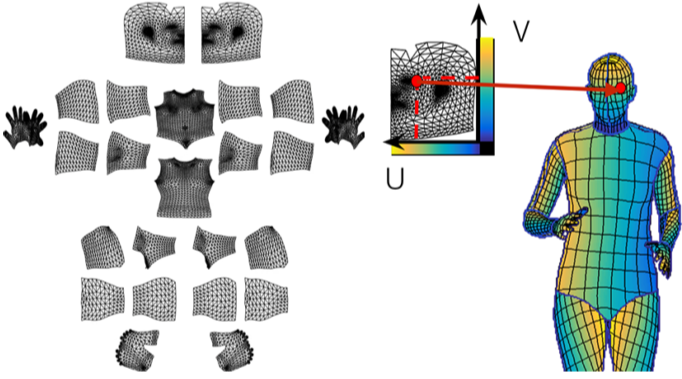
[img. UVMap 예시]
UV map : 3D 매쉬의 평면 표현
각 pixel의 점의 정체성이 영상 내부에서 유지되면서 위치만 바뀐다.
즉 아주 많은 Landmark 검출은 곧, UV map 생성이다.
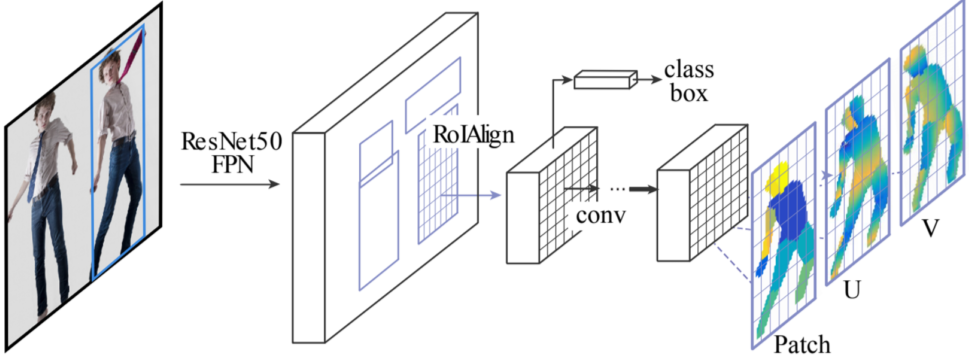
[img. DensePose의 구조]
DensePose R-CNN = Faster R-CNN + 3D surface regression branch
- Patch: 각 body part의 sementation map(팔,다리,머리)
Mask R-CNN과도 비슷하다.
데이터 표현방법과 데이터셋을 제공한 논문
RetinaFace
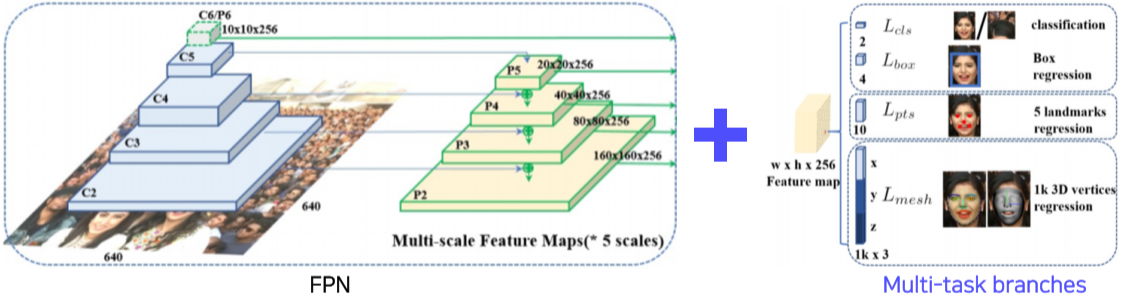
[img. RetinaFace의 구조]
FPN 구조에 다양한 branch 도입해 Multi task가 가능하게 한 모델
여러 Task로 학습 시, 적은 데이터로도 Backbone 네트워크 학습이 강하고 성능좋게 잘 학습된다.
Extension pattern : CV에서의 디자인 패턴 중 하나, 다른 구조도 branch를 추가하여 여러 Task에 활용 가능
Detecting objects as keypoints
Bounding box를 찾을 때, keypoint(중앙, 코너)를 시작점으로 찾는 구조들
CornerNet
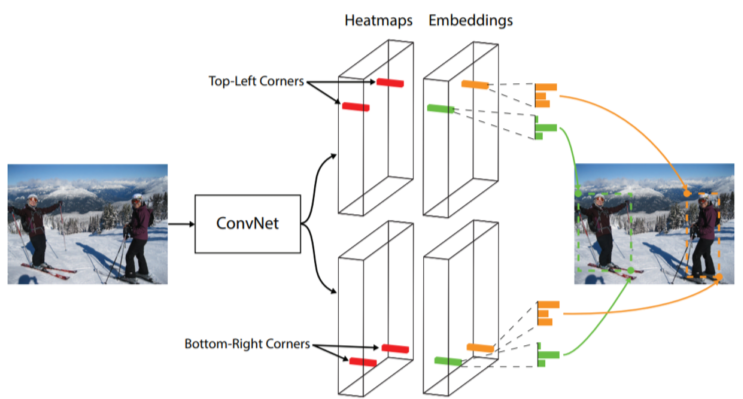
[img. CornerNet 구조]
좌측 상단, 우측 하단의 점 2개를 찾아 Bounding box로 삼는 구조
병렬적으로 2개로 나눈 뒤, 먼저 Heatmap에서 점의 위치를 찾고, 그 점의 class을 의미하는 Embedding을 찾은 뒤 결합한다.
single-stage 구조이며, 성능은 조금 떨어지지만 속도가 빠르다.
CenterNet

[img. Centernet 1 예시]
성능을 개선하기위해 중앙점 또한 검출함

[img. CenterNet 2 예시]
어차피 중앙점까지 3개를 구할 꺼면 width, height, center point로 검출 정보를 바꾼 모델
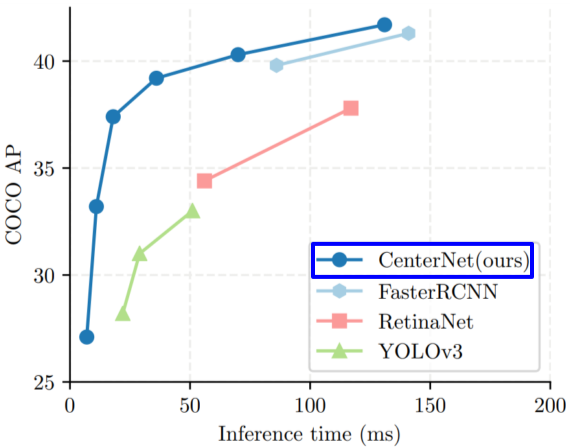
[img. 성능 비교]
CenterNet이 성능과 속도면에서 우위를 보인다.
Conditional Generative Model(cGAN)
사용자가 컨트롤 가능한 Generative Model을 의미
Conditional generative model(cGAN)

[img. Generative Model VS Conditional Generative Model]
랜덤한 결과를 생성하는 Generative Model과 달리 Conditional Generative Model은 주어진 조건에 따라 생성한다.
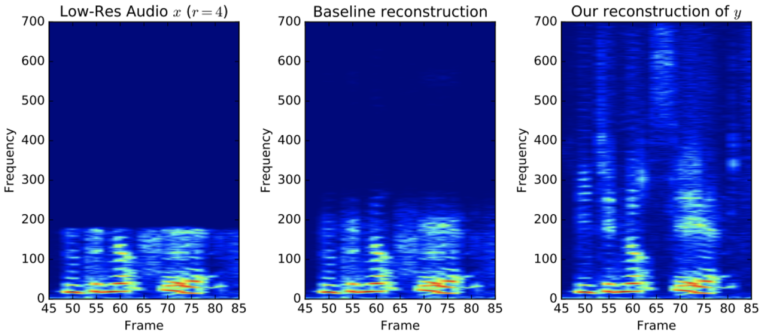
[img. Low quality audio -> high quality audio]
오디오 음질 향상, 인공지능 뉴스 등 여러 방면에 활용 가능
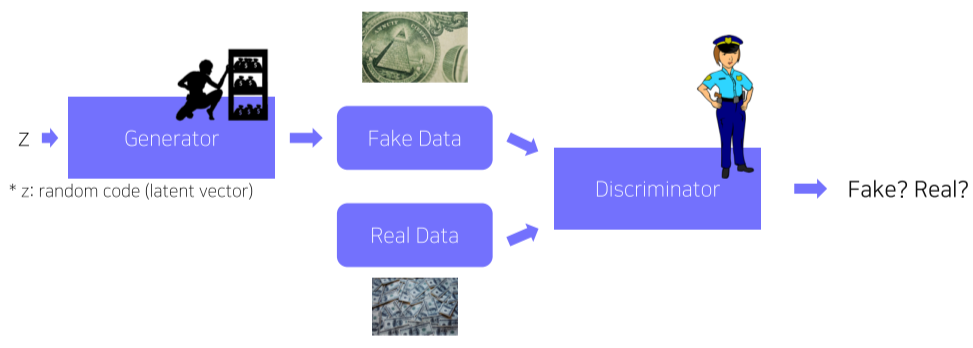
[img. GAN의 원리]
보통 위조 지폐범(Generator)과 지폐 감별자(Discriminator)로 비유하며, Generator는 실제 데이터와 비교하여 가짜 데이터를 생성하고 Discriminator는 이를 가짜인지 진짜인지 구별해본다.
Discriminator가 감별해내면 해당 loss가 Generator를 학습시키고, Generator가 Discriminator를 속이면 Discriminator가 해당 Loss로 학습되는 상호 보완적인 모델이다. (Adversarial Training, 적대적 학습법)
이러한 Adversarial Training을 이용하는 Generative model을 Generative Adversarial Network 즉, GAN이라고 부른다.
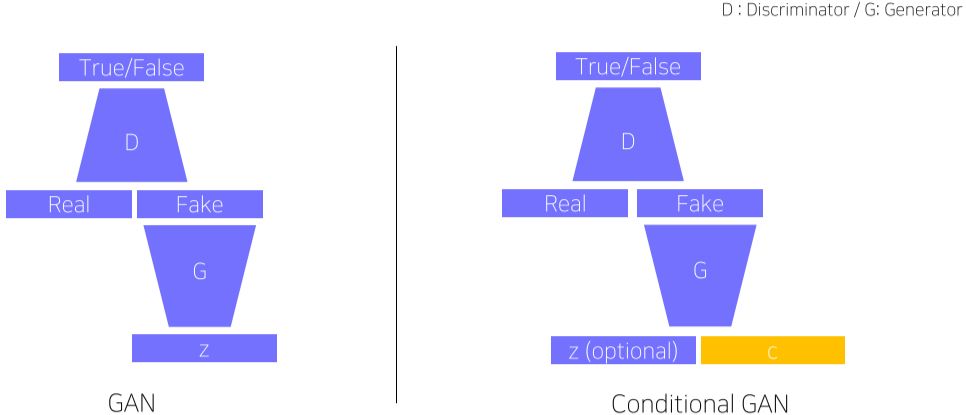
[img. Basic GAN vs Conditional GAN(cGAN)]
기본 GAN의 경우 Generator에 랜덤한 z를 넣고 생성한 결과를 Discrminator가 판별하는 구조
Conditional GAN은 z는 옵션으로 넣고 C라는 조건을 넣어주는 부분이 다르다.

[img. Conditional GAN를 이용한 이미지의 화풍 바꾸기]
이외에도 그림의 화질을 좋게 바꾸는 Super resolution, 흑백이나 채색 되지 않은 그림 채색 등의 일에 사용된다.
예를 들어 저해상도 이미지를 고해상도로 바꾸는 Super resolution이 대표적인 cGAN 활용의 예시이다.
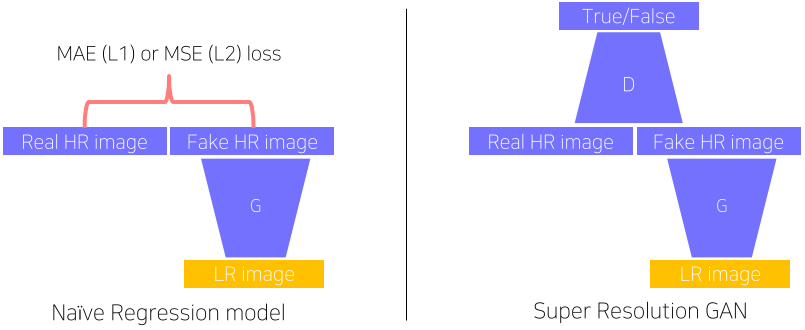
[img. Super Resoultion에 사용되던 과거 구조(Naive Regression Model)와 GAN 구조]
Low Resolution 이미지를 GAN에서는 High Resolution 이미지로 바꾸고 이를 Discriminator가 학습하면서 이루어진다.
과거에는 Naive Regression model이라는 좀더 단순한 Loss를 Discriminator 대신 사용한 구조를 사용했다.
| MSE VS GAN 결과물 비교 | MAE/MSE loss | ||
|---|---|---|---|
 |
$MAE = \frac{1}{n}\sum^n_{i=1} | y_i-\hat{y}_i | \MSE=\frac{1}{n}\sum^n_{i=1}(y_i-\hat{y}_i)^2$ |
[tables. GAN loss vs MAE/MSE loss]
MAE는 결과와의 차이의 크기를 loss로, MSE는 결과와의 차이의 제곱을 loss로 사용한다.
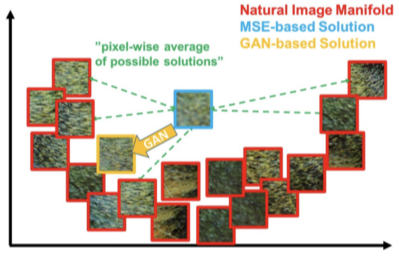
MAE/MSE 같은 Regression의 결과물은 blurry한 결과가 나오는데, 두 loss 모두 이미지의 픽셀들의 평균을 포함하는 loss 이기 때문이다.
GAN은 Discriminator를 속이기 위해 에러가 치우쳐도 현실에 가깝게 만든다.
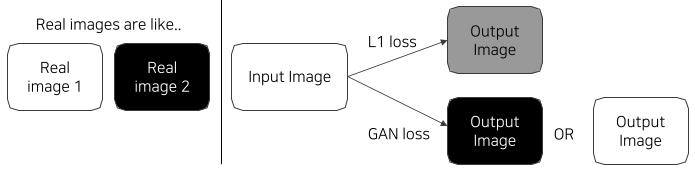
[img. 채색을 예시로든 loss의 차이]
진짜 이미지가 흰색 아니면 검은색이 정답이라면 L1 loss는 그 사이 평균 값이면서, 존재하지 않은 회색 이미지를, GAN loss는 그 둘중에 하나인 검정 아니면 흰 이미지를 만든다.

[img. MSE loss를 쓴 SRResNet과 GAN loss를 SRGAN의 차이에 주목]
Image translation GANs
Image translation이란, 한 이미지 스타일을 다른 이미지 도메인 혹은 다른 스타일로 변화시키는 문제.
크게 보자면 위의 Super resolution 또한 Image translation의 한 종류

[img. Image Translation 예시]
Pix2Pix
Image translation을 CNN Laeyr가 포함된 학습 구조로 처음 정리한 연구
\(G^* = arg\ \underset{G}{min}\ \underset{D}{max}\ \mathcal{L}_{cGAN}(G,D)+\lambda\mathcal{L}_{L1}(G)\\
where\ \mathcal{L}_{cGAN}(G,D)=\mathbb{E}_{x,y}[\log D(x,y)]+\mathbb{E}_{(x,y)}[\log(1-D(x,G(x,z))]\\
and\ \mathcal{L}_{L1}(G)=\mathbb{E}_{x,y,z}[\left\|y-G(x,y)\right\|_1]\\
x:ground-truth,\ y: output,\ z:random\ factor\)
[math. Pix2Pix의 Loss, Total loss(GAN loss + L1 loss)]
L1 Loss를 적당한 조건으로, GAN loss를 더해 Realistic한 출력을 만들도록 바꾼 Total loss를 사용함
- MAE L1 Loss는 y-G(x,y)로 결과와 실제 이미지를 직접 비교하지만 GAN loss는 Discriminator를 통해 간접적으로 비교한다.
- 그러므로 GAN로 Realistic하고 L1 Loss으로 의도와 비슷한 이미지를 만들 수 있다.
- 또한, 당시에는 GAN의 연구가 많이 진행되지 않아서 학습이 안정적이지 않았다.
또한 GAN Loss 부분은 cGAN이므로 z 뿐만 아니라 조건인 x가 같이 들어감

[img. loss 종류에 따른 결과 비교]
CycleGAN
위의 Pix2Pix는 Supervised learning 방법을 사용해서 pairwise data가 필요하지만 이러한 데이터셋을 얻는 것이 어려워서 CycleGAN이 등장했다.
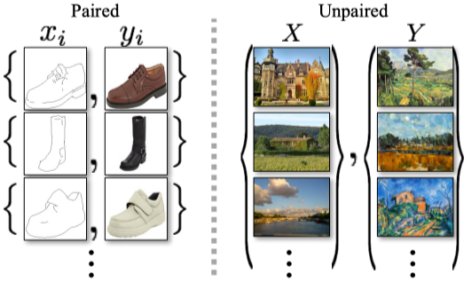
[img. paired vs unpaired data]
CycleCAN을 이용하면 도메인 간의 관계가 없어보이고, 1:1 대응하는 pair가 없는 두 데이터셋으로도 image translation을 할 수 있다.
- 응용범위와 데이터셋 확보방법이 늘어남

[img. CycleGAN 결과물 예시]
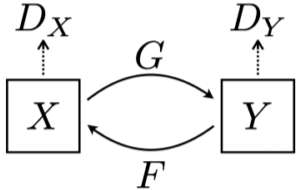
Cycle이라는 이름에서 알 수 있듯이, CycleGAN의 Loss는 데이터셋 X,Y에 대하여, X -> Y로 가는 방향의 Loss와 Y -> X로 가는 방향의 Loss를 Cycle 돌듯이 동시에 학습 시킨다.
추가로 Cycle-consistency loss 텀은 X->Y->X로 돌아왔을 때, 변한 X가 원본 X와 비슷하게 만들도록 하는 Loss이다.
\(L_{GAN}(X\rightarrow Y)+L_{GAN}(Y\rightarrow X) + L_{cycle}(G,F)\\
where\ G/F\ are\ generators\)
[math. CycleGAN loss = GAN loss (in bot direction) + Cycle-consistency loss]
[img. Cycle-consistency loss 텀이 존재 하지 않을 시의 CycleGAN Loss 설명]
Cycle-consistency loss 텀이 존재 하지 않을 시의 구조이다.
- G, F: generator
- $D_x, D_y$: discriminator
- GAN loss : $L(D_x)+L(D_Y)+L(G)+L(F)$
- 일종의 2개의 GAN이다.
하지만 이런 GAN loss만 사용시 Mode Collapse 문제가 발생한다.
- Input의 상관없이 하나의 Output만 계속 출력하는 문제
- 즉 Input과 Output이 서로 영향을 미치지 않음(양방향 모델이기 때문에)
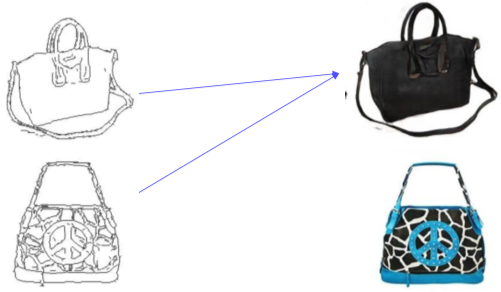
[img. Mode Collapse 문제]
이를 해결하기 위해 Cycle-consistency loss가 등장하였다.
- Style 결과 뿐만아니라 content도 유지시켜 줌
X에서 Y, 그리고 다시 X로 돌아왔을 때 원본 X와 같아야 한다(contents 유지).
supervision이 없는 self-supervision 방법(레이블링 필요 없음)
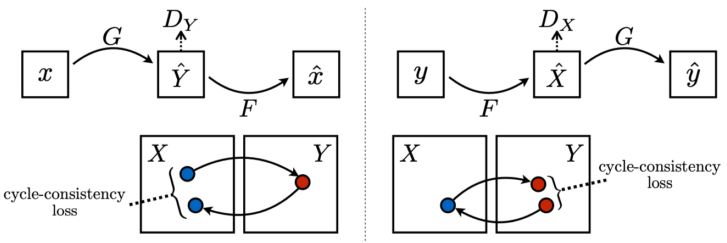
[img. X->Y->X와 Y->X->Y 처럼 돌아왔을 때의 Cycle-consistency loss]
Perceptual loss
GAN은 Discriminator, Generative 모델이 번갈아가며 학습되어야 하므로 학습하기 쉽지 않다.
더 쉬운 방법을 알아보기 위해 Perceptual loss가 나타났다.
Peceptual loss는 높은 질의 결과를 얻기위해 제안된 방법이다.
GAN loss(Adversarial loss)의 경우,
- 트레이닝과 코딩이 힘듬(두 모델을 반복, 왕복 학습해야하므로)
- 대신, pre-training network 필요 없어, 데이터만 있으면 다양한 상황에 활용 가능
Peceptual loss의 경우,
- 학습과 코딩이 편함(평범한 foward & backward computation), 따라서 더 빠름
- 대신 learned loss를 위해 pre-trained network가 필요
pretrained-network의 filter를 visualization 해보면, 사람의 visual perception 과 비슷하다.
이미지에서 filter들이 방향성, edge, 색깔 등을 찾아 peceptual space로 변환한다.

[img. pretraine된 network의 low level layer에서의 filter]

[img. perceptual loss의 결과물 예시]
Perceptual loss를 활용해 Input 이미지를 원하는 Style로 바꾸는 Image Transform Net의 예시를 보면,
여기서는 VGG-16을 Loss Network로 사용하며, 이를 이용해 feature를 activation map 형태로 뽑아낸다.
이때 Loss Network는 Pretrained-Network이므로 고정되어 업데이트 되지 않으며, 그 앞단에 있는 Image Transform Net을 업데이트하기 위해 Backpropagation을 진행하여 업데이트한다.
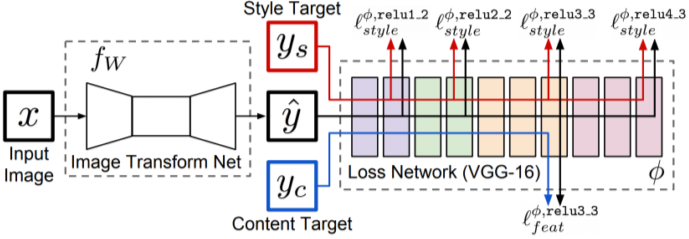
[img. Perceptual loss를 활용하는 Image Transform Net 구조]
이 때, Style Target과 Content Target 2개에 관한 Loss를 구하게 되는데, 각각 Feature Reconstruction loss, Style Reconstruction loss라고 한다.
- Feature Reconstruction loss
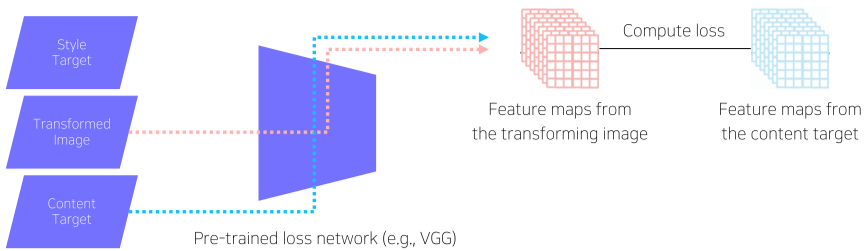
[img. Feature Reconstruction loss의 원리]
중간 레이어에 feature 1개를 뽑는다.
Transformed Image net의 결과물인 $\hat{y}$가 Content Target과 얼마나 일치하는지 측정하는 Loss로, 일반적으로 원본 이미지 x를 Input으로 loss network에 넣어얻어낸 feature와 loss network에서 얻어낸 $\hat{y}$의 feature를 비교하여 L2 Loss로 계산한다.
이후 , 이 값으로 Backpropgation을 하여 Transformed Image Net을 학습시킨다.
- Style Reconstruction loss
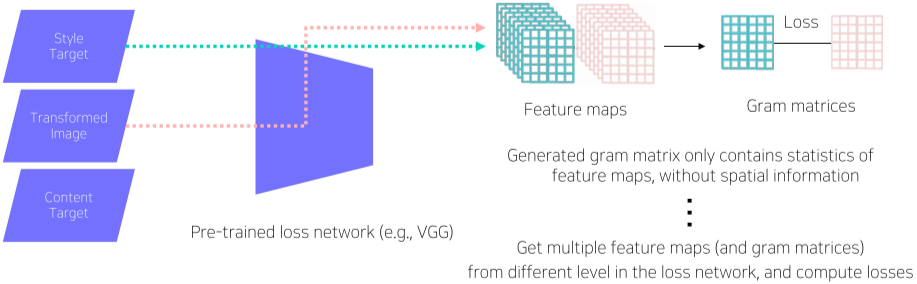
[img. Style Reconstruction loss의 원리]
Feature Reconstruction loss와 비슷하게, Style Target과 $\hat{y}$의 Feature를 뽑아낸다.
다른 점은 이때, Feature를 직접 비교하는게 아니라, 전체적인 Style을 비교하기 위해, Gram matrices라는 feature map의 통계적 특징을 담아낸 feature의 channel size X channel size의 tensor를 비교하여 L2 Loss를 계산한다.
Gram matrices란?
- Gram matrices는 Feature의 공간적 정보를 없애기 위해 pooling을 이용하며, Feature 채널들을 channel X (Height*Width) 형태로 바꾼 뒤, 내적하여 곱해서 얻는다.
- diagonal component(행렬의 행좌표와 열좌표가 같은 부분)은 자기자신의 통계적 특성을 의미하며, 그 이외에는 해당 채널과 다른 채널의 연관성을 의미한다.
- 공분산 행렬 구하기
- 즉 Gram Matrices는 채널간의 관계와 통계적 특성이 포함된 정보임
- 각 feature의 채널은 일종의 detection 역할을 하기 때문에, Gram Matrices는 이 스타일은 어떤 detection들이 많이 나타나는 가?를 분석한 것이다.
Task에 따라 스타일과 관계없는 일이라면, Style reconstruction loss 대신 Feature reconstuction loss를 사용하지 않은 경우를 사용하지 않을 수도 있다.
Various GAN applications
GAN의 예시를 알아보자.
- Deepfake

[img. 사람 얼굴 생성기, 가짜 연설 생성기]
이를 오남용할 수 있으므로, 이러한 Deepfake를 방어하기 위해 여러 시도 또한 이루어지고 있다.
Face de-identification

[img. Face de-identification]
프라이버시 침해 방지를 위해 인간은 차이를 알지 못하지만 컴퓨터는 혼돈을 가질 수 있게끔, 조금의 변경을 하는 연구도 진행중
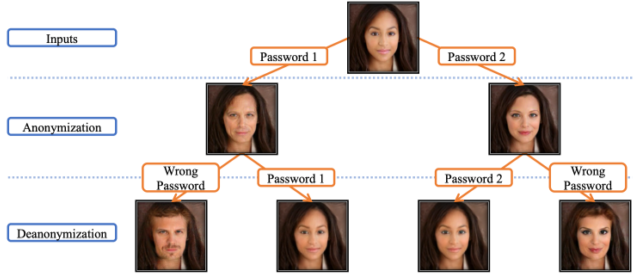
[img. password를 이용해 침해 방지 예시]
기타 비디오를 통해 포즈를 따라하게 만드거나, CG 생성, 게임 등에도 사용 가능
Multi-modal learning: Captioning and Speaking
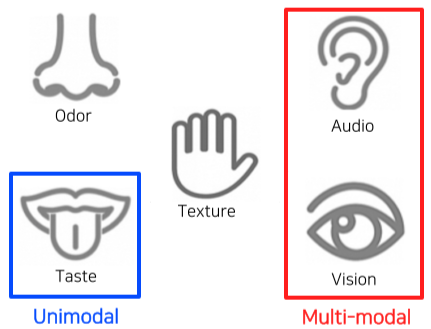
[img. Unimodal vs Multi-modal]
Multi-modal learning : 다른 특성을 가진 데이터들을 함께 활용하는 학습(ex) Text + Sound)
Overview of multi-modal learning
multi-modal learning의 어려움
- 데이터의 표현 방법이 모두 다름
- 이미지 : H X W X 3 배열, Text : Word Embedding + Positional Encoding 등
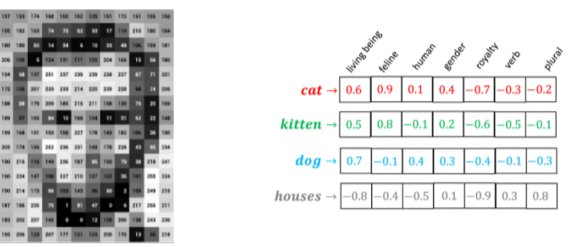
[img. 데이터 표현 차이]
- 정보량의 불균형, feature space의 불균형.
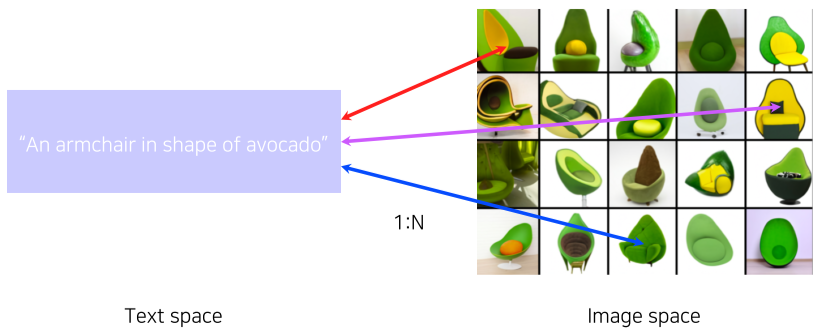
[img. 아보카도 모양 가구에 대한 글 하나는 여러 이미지를 포함할 수 있다]
- 특정 modality에 편향된 모델이 생성될 수 있음
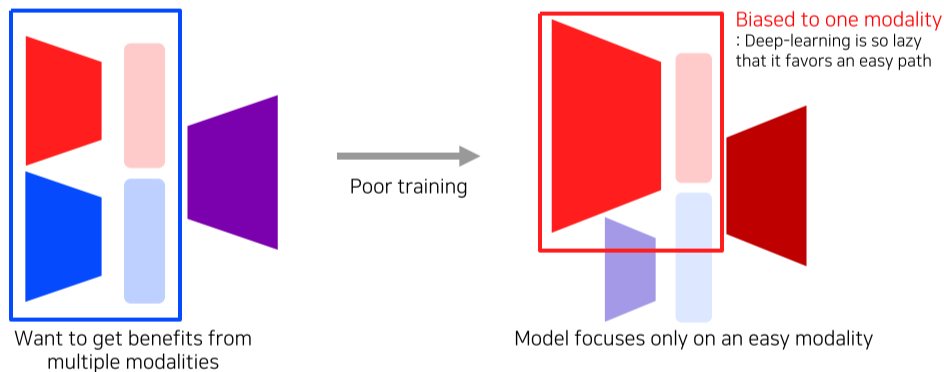
[img. 주어진 데이터가 동일해도 참조하는 modality의 비율은 달라질 수 있음]
- 예를 들어, 동물 Classification Task에서 사진과 울음소리, 동물에 대한 설명이 적혀있는 글을 줘도, 사진만 보고 동물 Class를 결정할 수 있음
- 딥러닝은 쉬운 길만 선택하려하기 때문
Multi modal learning의 여러 패턴
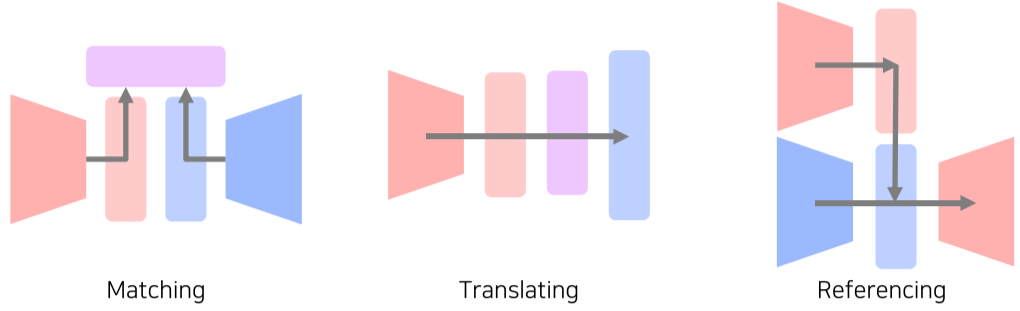
[img. Multi modal learning의 여러 패턴]
- Matching
- 서로 다른 Modality를 같은 Space로 보내어 서로 Matching
- Translating
- 서로 다른 Modality를 다른 Modality로 변환
- Referencing
- 어떤 Modality 정보를 Input으로 같은 Modality의 결과물로 변환할 때, 다른 Modality를 참조하여 성능을 향상
Multi-modal tasks (1) - Visual data & Text
Text embedding
Ascii 코드를 사용하는 Character 관점에서는 사용하기 힘들고, Word 레벨의 embedding을 Input으로 이용함.
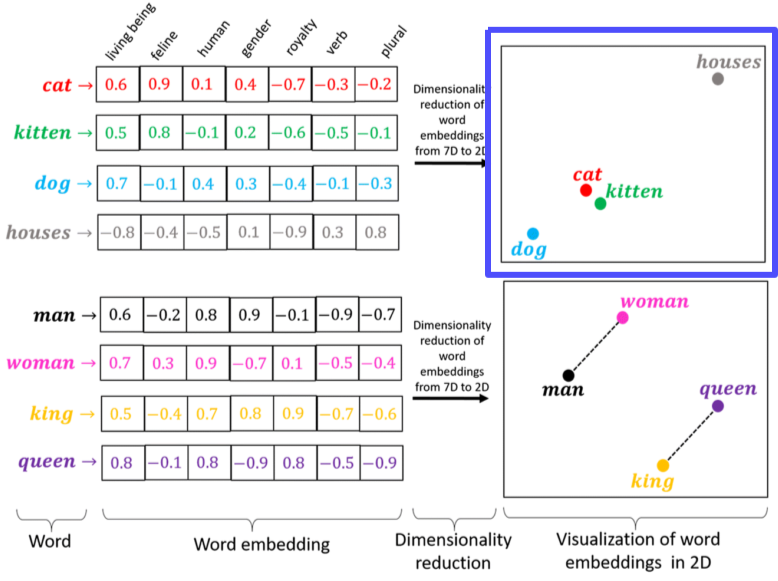
[img. Word embedding 예시]
각 Word embedding은 단어의 대략적인 의미와 연관성을 가진 feature를 표현한는 Vector의 형태이다.
이를 차원공간에 표현하면 비슷한 의미를 가진 단어는 비슷한 곳에 위치하며, 비슷한 관계를 가진 단어쌍 벡터 둘의 방향(차이 벡터) 또한 비슷한 방향을 가지게 된다. (일반화가 되어 있음)
Word embedding 생성 방법 : word2vec
대표적으로 Skip-gram model이라는 방법이 있다.
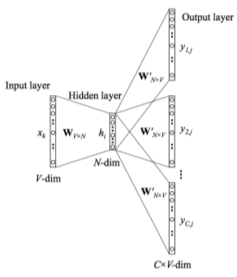
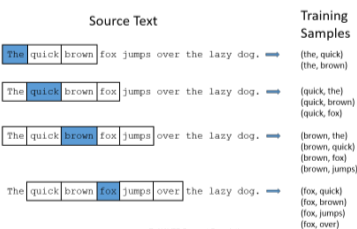
[img. Skip-gram model의 예시]
Input으로 단어의 one hot vector(V차원)를 의미하며, 이를 W와 곱하여 N-차원의 embedding vector가 나오게 된다.
- 이때 one-hot vector에 의해 W의 한 Row만 slicing 되게 된다. 즉 W는 embedding vecotr의 Row들의 집합이다.
이후 그 Embedding vector를 이용해 해당 단어의 주변에 나타난 n개의 단어들을 예측하는 Task로 학습한다.
- 나타나는 주변 단어를 통하여 관계성을 학습할 수 있다.
Joint embedding
서로 다른 Modality의 Matching을 하기 위한 공통된 Embedding 벡터를 학습하기 위한 방법
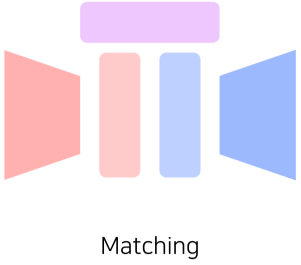
[img. Joint embedding은 Multi-Modality learning에서 Matcing 패턴을 위해 사용 ]
Image tagging
Image tagging은 사진에 tag를 지정하거나, 반대로 tag를 통해 사진을 가져오는 Task이다.

[img. Image Taggin의 예시]
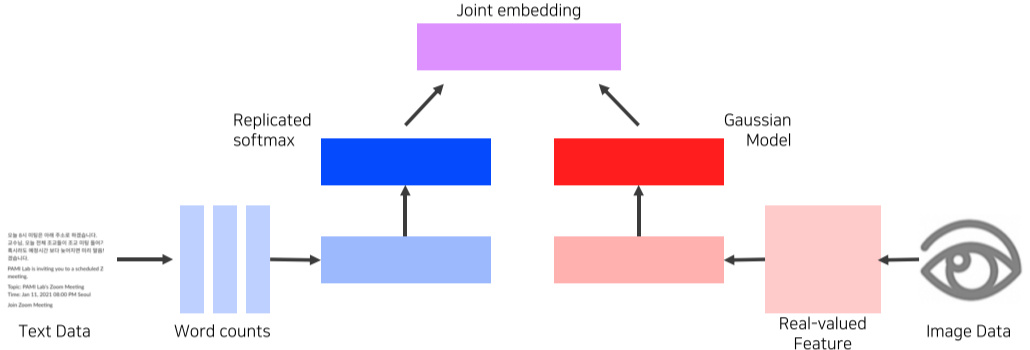
[img. Text와 Image의 matching 예시]
위의 예시의 경우 각각 Text와 Image를 feature vector와 한 후, 그 이후 서로 다른 모델을 통하여 같은 차원의 (d-dimension) vector로 바꾼 뒤, 그 둘을 통하여 Joint embedding vector를 학습한다.
이때 Joint embedding Vector는 두 다른 Modality 데이터의 연관성, 거리를 의미한다.
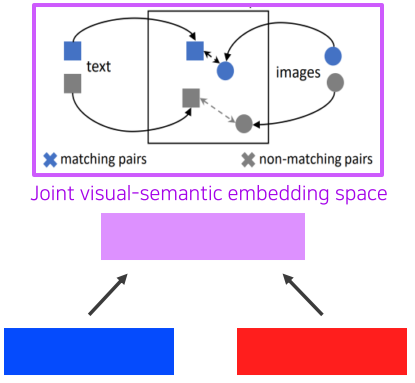
[img. joint visual-semantic embedding space 내부]
이렇게 구한 joint embedding vector 둘의 두 차원 상의 거리를 관련이 있는 Label은 가깝게, 관련 없으면 멀게 되도록 학습한다.
- 이런 Distance 기반으로 학습하는 것을 Metric learning이라고 한다.

[img. Multi-modal analogy]
또한, 이렇게 학습된 embedding을 이용하여 Multi-modal analogy라는 property 생겨난다.
- 서로 다른 Modality embedding를 포함하여, embedding 더하거나 빼서 가장 가까운 embedding을 데이터 형태로 가져올 수 있다.
- 예를 들어 위의 이미지처럼 개 사진에 개 단어를 빼고 고양이 단어를 추가하면, 고양이 사진들이 나타난다.
- 심지어, 각 첫번째 사진들의 입력한 사진의 배경과 비슷하다.

[img. 레시피를 통해 사진을 예상하는 application 예시]
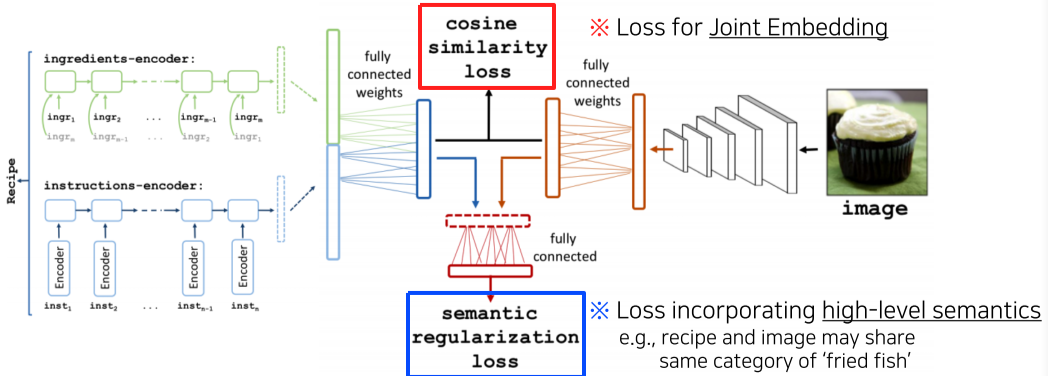
[img. 위 어플리케이션의 구조]
-
Text는 encoder를 통하여 instruction과 Ingredient를 하나의 output으로 concat 한 뒤, FCL을 통하여 d 차원의 vector로 만든다.
- Image는 conv layer을 통하여 feature를 뽑아낸 결과를 FCL을 통하여 d0 차원의 vector로 만든다.
- 두 embedding vector를 cosine similarty loss로 loss를 구하여 학습하며, 또는 추가 정보를 제공하여 더욱 좋은 성능의 semantic regularization loss를 이용하여 학습할 수 있다.
Cross modal translation
[img. modal 간의 변환을 하는 Translating]

[img. Image captioning ]
Image Captioning
Image Captioning은 이미지의 설명 Text를 생성하는 대표적인 cross modal translation Task이다.
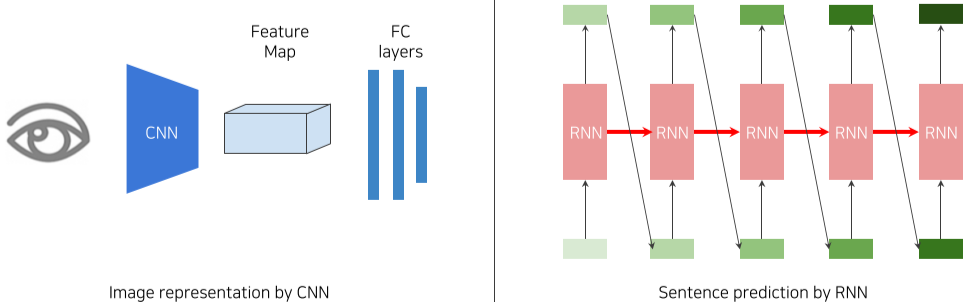
[img. Image 분석을 위한 CNN과 Text 생성을 위한 RNN으로 이루어져있다.]
Image Captioning 에서는 CNN과 RNN 구조가 필요하며 대표적인 구조로 Show and tell이 있다.
- Encoder 구조로 ImageNet에 의해 pre-train된 CNN model을 사용하여 이미지를 vector로 바꾼 뒤,
- 이를 Decoder인 LSTM RNN의 Condition으로 제공하고, 시작 토큰(보통 0이나
토큰)을 준 뒤, - 해당 LSTM의 Output을 다음 LSTM의 Input으로 주는 과정을 반복한다.
-
토큰이 나올때 까지 반복하여 결과물은 만든다.
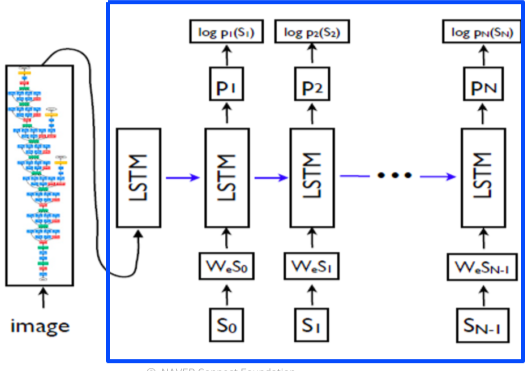
[img. Show and Tell 구조, 좌측의 CNN과 우측 RNN을 활용]
Show and Tell은 단 한번의 Image 분석 뒤에 태깅을 하나, 실제로는 단어 마다 Image에서 중요시 해야할 feature가 다를 수 있다.
Show, attend, and tell 이라는 구조는 attend 구조를 통하여 단어별로 attention을 달리하여 순차적으로 단어를 생성 시, 이미지에서 feature의 가중치를 바꿔가며 할 수 있다.

[img. show, attend, and tell의 attention]
- CNN을 이용하여 Input Image의 14x14 feature map을 생성한다.
- 기존의 Vector 형태가 아니라는 점이 특징
- 해당 feature map을 RNN에 입력하여 단어를 생성할 때마다 다른 attention으로 단어를 생성
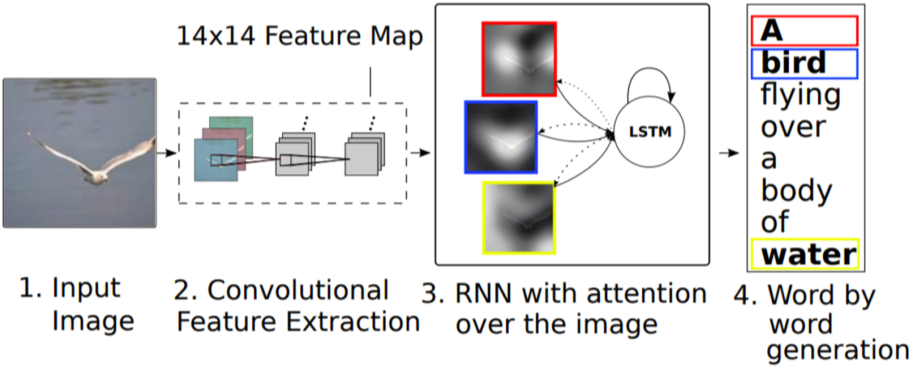
[img. Show, attend, and tell 구조]
Show, attend, and tell 구조의 경우, 사람이 사진을 인식할 때 전체적인 부분을 보는 것이 아닌, 일부에 관심(attention)을 가중하여 본다는 것에 착안되었다.
1) Input image를 CNN을 통해 얻은 feature map과,
2) 위 featuremap을 RNN에 넣어 얻은 spatial attention
1)과 2)을 결과물을 inner product(weighted sum)하여 얻은 soft attention embedding(z) 벡터를 얻어낸다.
- 사실, Translating 보다는 Reasoning의 Cross modal reasoning에 더 가깝다.
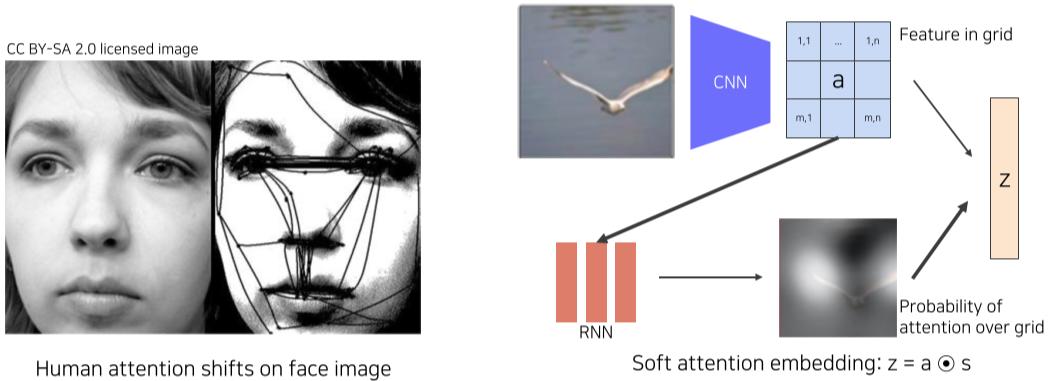
[img. 사람이 사진을 인식할 때 보는 부분 (좌), attention 결합 방법]
RNN에서 결과를 내는 과정을 좀 더 자세히 살펴보면,
- Feature map을 hidden stat로 첫번째 RNN 모듈 h0에 넣어주고 spatial attention s1을 얻는다.
- 이렇게 얻은 s1과 feature map을 inner product하여 얻은 z1 vector를 start token y1과 함께 두번째 RNN 모듈 h1에 넣어준다.
- 그 결과 첫번째 단어 d1(‘A’)와 두번째 spatial attention s2가 나온며, 이를 다시 feature map과 합쳐 soft attention embedding z2를 만든다.
- 이 이후 세번째 RNN 모듈 h2에는 z2와 이전에 출력한 단어 y2(또는 d1, ‘A’)를 함께 넣어주고, End Token 나올때 까지 반복한다.
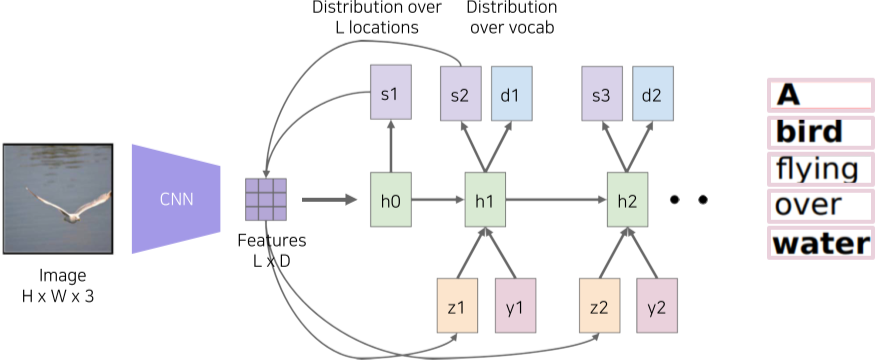
[img. RNN의 단어 build 과정]
또한, 반대로 Text를 통하여 Image를 생성하는 것이 가능하며, 이때, 여러 Output Image가 나오는 것이 가능하므로 Conditional GAN을 이용한다.

[img. Text-to-image by generative model]
Text to image 모델의 Generator의 경우
Text의 Vector가 주어지면, 이를 Gaussian Random factor와 결합하여 다양한 output이 나오도록 해준 뒤, Decoder를 거쳐서 image를 생성해준다.
Discriminator의 경우
Input된 Image를 encoder로 뽑은 feature map과 위에 사용했던 Text Vector를 합친 벡터를 label된 데이터와 비교하여 판단함.
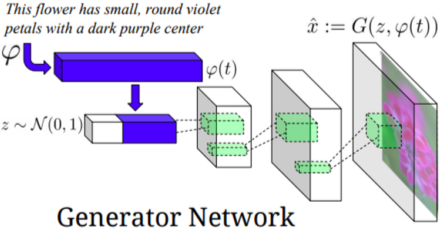 |
|---|
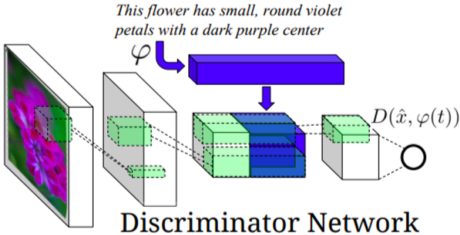 |
[img. . Text-to-image Generator와 Discriminator 구조]
Cross modal reasoning
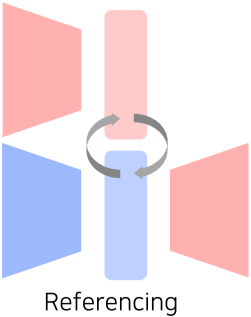
[img. Modality간의 Referencing을 이용하는 Cross Modal reasoning]
Visual question answering
영상과 질문을 받으면 이를 통해 답을 도출하는 Task
각각 Text와 Image에서 추출한 같은 차원의 vector를 point-wise multiplication을 통하여 Joint embedding 한 뒤, 이 vector를 FCL을 통하여 답을 도출한다.
모든 구조에서 학습이 가능한 End-to-End 구조이다.
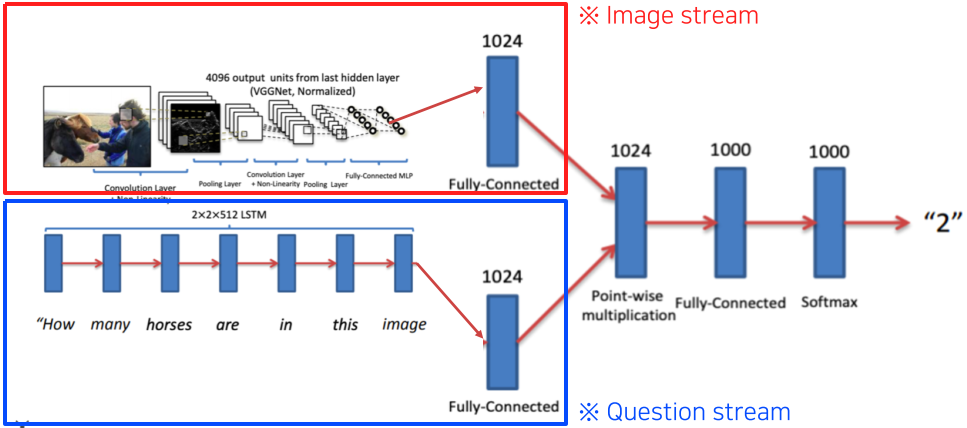
[img. Visual question answering 구조]
Multi-modla tasks(2) - Visual data & Audio
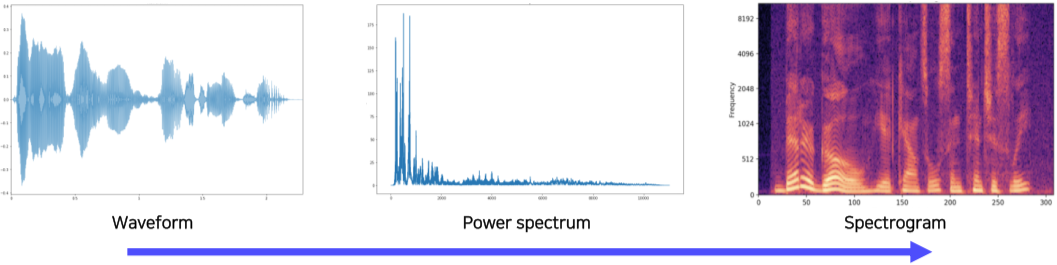
Sound representation
Sound data는 자연상태에서 1차원 Waveform 형태로 존재하지만, 우리가 사용하기 위해서는 Spectrogram이나, MFCC 등의 형태로 바꿔줘야 한다.
[img. Sound data의 다양한 형태]
- Fourier transform
대중적으로 많이 사용되는 소리의 형태인 Spectrogram으로 변환을 위한 방법
wave 형태의 data를 분석하여 각 frequency 별 세기를 기록한 것이 Power spectrum 형태이다.
- Power spectrum : 주파수와 세기에 대한 그래프
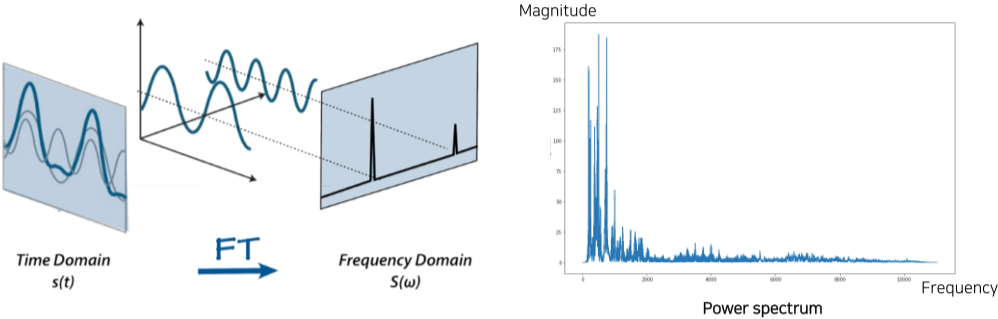
[img. Fourier transform]
Waveform에 Fourier transform이용하면 하나의 파장으로 표현가능 하나, 시간에 대한 정보가 사라지게 된다.
구체적으로 이를 방지하기 위해 아주 작은 시간 구간 t에 대해서만 FT하여 Spectrogram으로 바꾸는 Short-Time Fourier transform(STFT)라는 방법이 사용된다.
- Hamming window의 형태처럼 Boundary 부분은 조금, 가운데 부분은 강조하는 식으로 element wise 곱을 해준다.
- 이때 window가 달라질 때마다(= 정의한 시간 t가 지날때마다) 값이 확달라지게 되는데, 이를 막기 위해 window가 조금씩 겹치게 하면서 Spectrum을 구하게 된다.
- 하단의 예시는 시간 t인 A를 20~25ms로 잡고, B를 10ms로 잡았으니 각 window들은 10~15ms(A-B)만큼 이전과 이후 window들과 겹치면서 변환이 진행된다.
- 이렇게 구한 Spectrum들을 stack하여 Spectrogram을 구하게 된다.
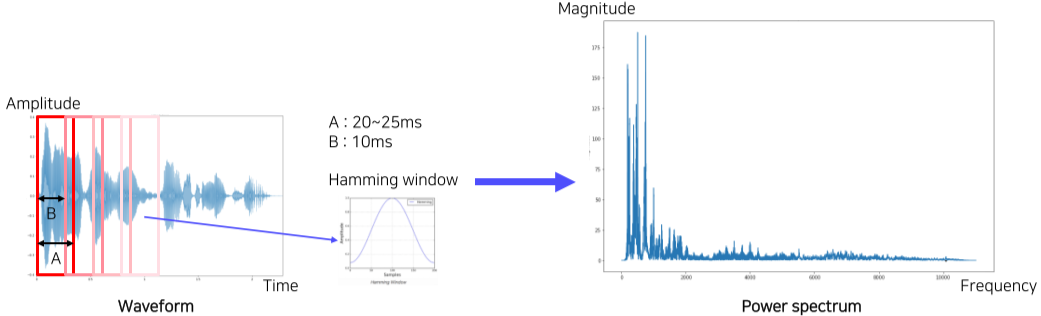
[img. STFT의 예시]
Spectrogram은 시간축과 Frequecy 축으로 표현한 그래프에 강도(세기, Magnitude)를 색으로 표현한 3차원 그래프이다.
- Dimension을 조금 낮추면 Melspectrogram, MFCC 등의 다른 표현 방법도 있다.
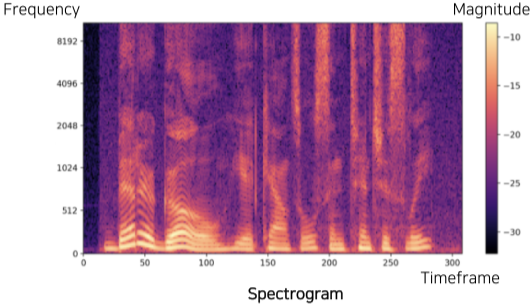
[img. Spectrogram. 시간별로 색이 대비되는 부분은 windowing의 흔적이다.]
Application- Scene recognition by sound
Sound-Image Task 중 Matching에 해당하는 Scene recognition by sound task를 알아보자

[img. Scene recognition by sound, 영상에 대한 sound 태깅 Task]
SoundNet
오디오 표현에 대한 학습을 처음 제시함, Teacher-student 학습 모델
- label되지 않은 영상을 프레임별로 pretrained된 Object detection과 Scene detection 모델들에게 각각 Input으로 넣고 output을 얻는다.
- Raw waveform을 CNN layer에 넣어준 뒤, 위의 output dimension과 같은 차원의 two head output을 얻는다.
- 이때, Spectrogram이 아니라 Raw Waveform을 쓴 이유는 단순히 연구 초기라 모르고 안썼다고 한다.
- 1의 output과 2의 output을 KL loss를 통해 loss를 얻은 뒤, 1번 모델들은 fixed한 채로 2번 모델을 학습시킨다. (Teacher-student 학습)
- 이렇게 학습된 2번의 모델을 다른 Task에 적용할 때에는 중앙의 pool5의 output인 feature vector를 task에 맞게 layer를 추가로 쌓아 사용한다.
- 주로 이렇게 Pre-trained 모델로 사용하기 위해 학습시킨다.
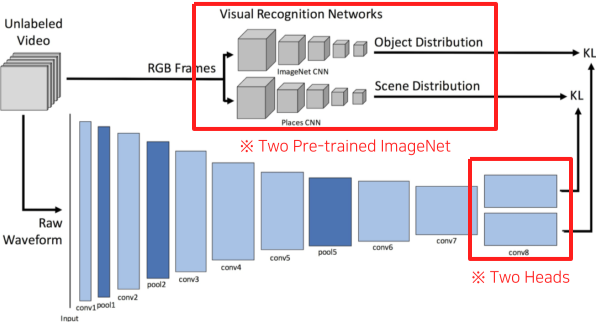
[img. SoundNet의 구조]
Cross modal translation
1. Speech2Face
음성을 통하여 사람의 얼굴을 상상하는 Network
각각 담당 Task에 대하여 Pretrained된 모델을 활용하는 Module 구조를 활용
사람이 말하는 영상을 그대로 쓰면 되므로 annotation이 필요없는 self-supervised 모델
이때 사용된 Pretrained 모델로
- Face Recognition : VGG-Face Model
- 얼굴 사진을 4096-D의 Face Feature vector로 바꿔 줌
- Face Decoder : facenet
- 얼굴 사진을 Landmark location을 이용하여 무표정으로 바꿔줌
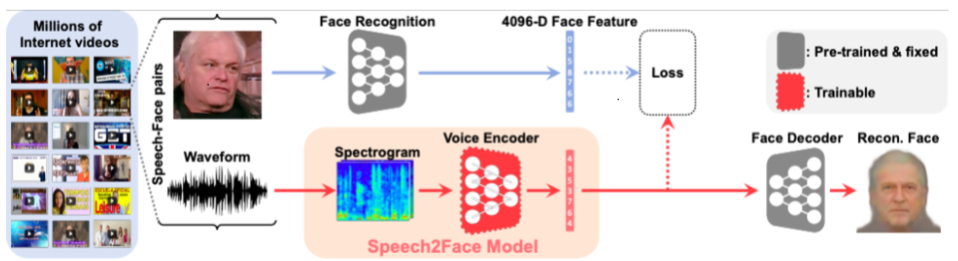
[img.Speech2Face 구조]
이후,
- Spectrogram 형태로 바꾼 사운드 데이터를
- Voice Encoder에 넣어 앞서 구했던 Face Recogntion의 Feature dimension과 같은 vector를 생성하고
- Face feature와 비교하여 Loss를 구하여 학습한다.
- 이때, 학습되는 것은 Speech2Face Model인 Voice Encoder 부분이며, 기타 Pretrained 된 부분은 업데이트하지 않는다.
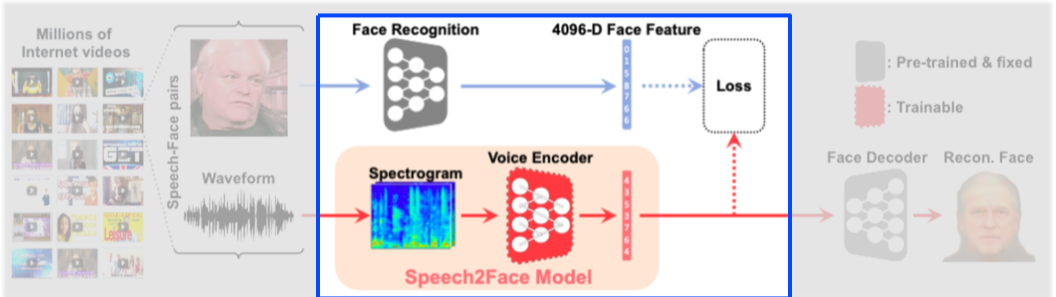
[img. Speech2Face에서 학습되는 부분]
- Image-to-speech synthesis
사진에 대한 묘사를 음성으로 출력해주는 Task, Module network 구조를 활용
[img. Image-to-speech Task]
- Input Image를 14x14 feature map으로 형성 후 Attention을 활용한 RNN 구조에 hidden state로 사용한다.
- 기본적으로 Show, Attend, and Tell 구조와 같지만, subword unit이라는 토큰 비슷한 것이 output 이다.(Learned Units)
- 해당 Unit을 Unit-to-Speech Model인 Tacotron 2를 이용해 subword를 음성으로 변환한다.
- 원본 Tacotron 2는 TTS(Text To Speech) 모델, 즉, text를 input으로 받지만 여기서는 subword를 받는다는 점이 다르다.

[img. Image to speech Task]
이때, 위의 두 모델을 학습시키기 위해, Pre-trained model(ResDAVEnet-VQ)을 이용해 speech를 Unit으로 바꾸고 이를 Learned Units의 Ground-Truth로 사용한다.
1) 즉 Image-to-Unit Model은 Ground-Truth Unit과 비교하여 Loss로 나와야 하고,
2) Unit-to-Speech Model은 Ground-Truth Unit을 Input으로 받으면 Pre-trained model(ResDAVEnet-VQ)의 Input Speech가 나와야 한다.
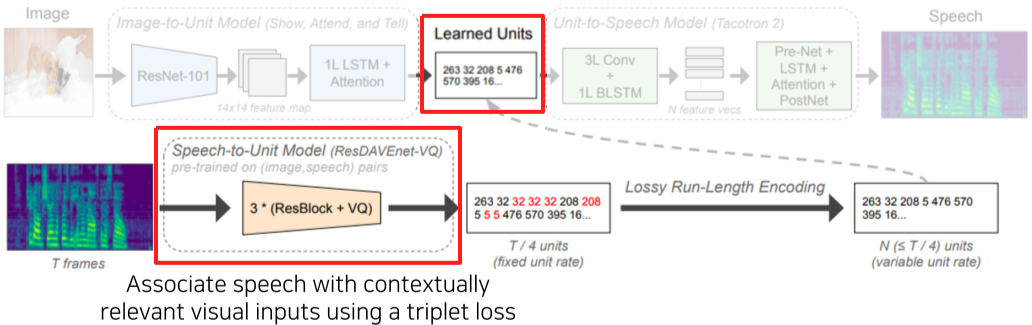
[img. 학습을 위한 Speech-to-Unit Model]
Cross modal reasoning
Sound source localization
사운드가 주어지면 해당 사운드가 사진의 어떤 Object가 내는지 예측하는 Task
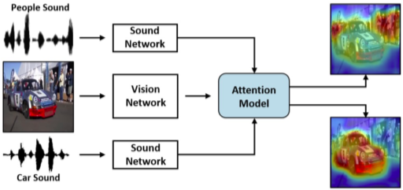
[img. Sound source localization은 Cross modal Referencing에 속한다.]
label된 데이터의 여부에 따라 3가지 버전이 있으며 기초적인 과정은
1) image Input을 통해서 Visual net에서 WxHxF image feature map을 내보낸다.
2) audio Input을 통해서 Audio net에서 1x1xF audio feature map을 내보낸다.
3) image feature map의 각 pixel 마다 audio feature map을 내적하여 관계성(attention)을 파악하고, 이 결과물 map이 Localization Score map이다.
여기서 부터는 각 버전에 따라 다르다.
- Fully supervised version : label이 된 데이터셋이 있는 경우
4) 결과물로 나온 Localization Score를 Ground-truth Loclization score와 비교하여 loss를 구한 뒤, Backpropagation 한다.
- unsupervised verison: label된 데이터셋이 없음
- 비디오에는 보통 Sound가 포함되어 있다는 점을 annotation으로 활용
4) 1)에서 구했던 WxHxF image feature map을 결과물이었던 Localization Score map과 Weighted sum pooling하여 1x1xF의 Attended visual feature를 만든다.
5) Audio net에서 만든 1x1xF audio feature map과 비교해서 metric learn Loss를 구한다.
- 같은 비디오에서 나온 소리면 positive pair
- 다른 비디오에서 나온 소리면 negative pair로 이용한다.
- 여러 영상에서 특정 사운드가 나올 때마다 비슷한 image feature map이 나온다면, 그 image feature map의 가중치가 높은 지점이 sound source이기 때문
- semisupervised version: label된 데이터셋이 있지만 Audio net output과도 비교함
4) 1. 2. 방법을 전부 사용하여 loss를 2개를 구하고 맞춰본다.
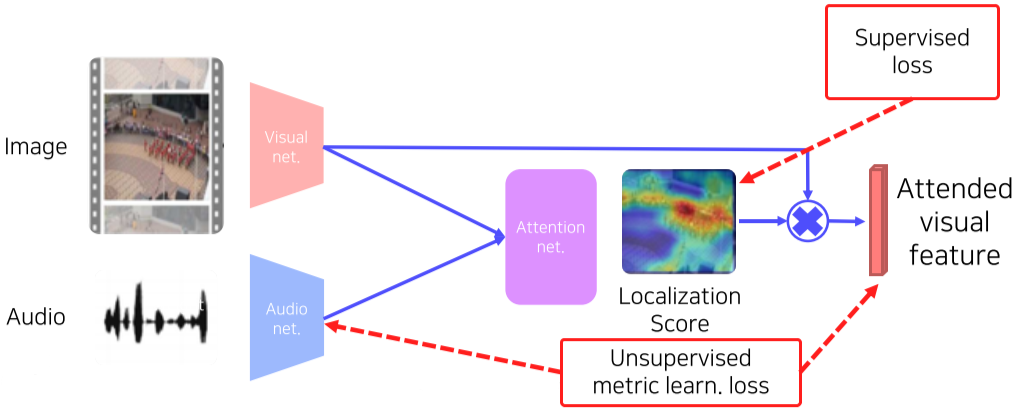
[img. Sound source localization의 여러가지 버전]
Speech separation
동시에 말하는 사람들의 말을 각각 1사람씩 말하는 Audio를 가져오는 Task
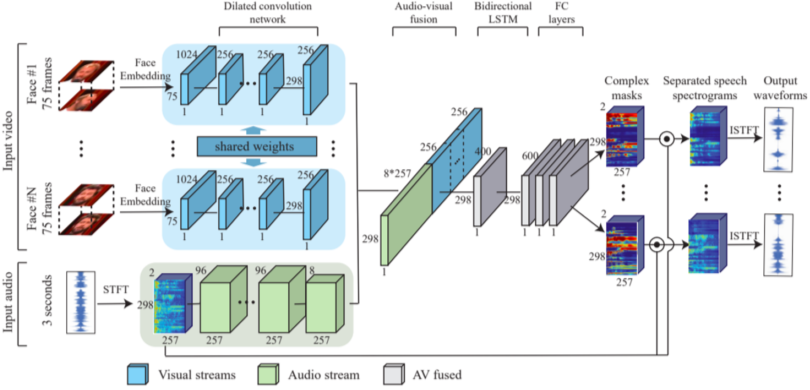
[img. Speech separation]
Dataset 필요한 Supervised Learning이며, 이때 데이터셋은 단순히 목소리 2개를 겹쳐서 만들 수 있다.
| 과정 | 도식 | 설명 |
|---|---|---|
| Visual stream |
 |
N개의 나눌 사람 만큼, Face Embedding을 통해 각자 feature를 구한다. |
| Audio stream |
 |
Audio Spectrogram으로 speech feature를 구한다. |
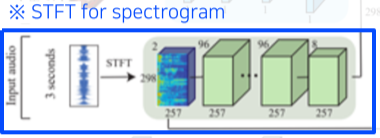
| Audio-visual fusion |
 |
위에서 구한 feature들을 concat한 뒤, N개의 complex mask를 뽑아낸다. |
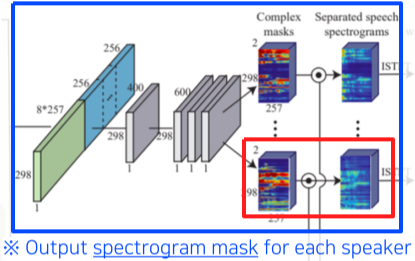
| output | 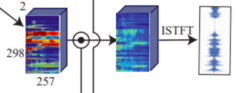 |
오리지널 spectrogram과 mask를 곱해 필터링 결과 spectrogram을 ISTFT로 waveform으로 바꾼 뒤, 원본과 비교해서 L2 Loss를 구하여 학습 |
[table. Speech separation 과정]
이외에도 Cross modal task로, Lip movements generation, Tesla self-driving 등이 있다.
3D undersanding
Seeing the world in 3D perspective
우리는 3D 세상에 살고 있기 때문에, 3D 공간에 대한 이해가 중요하다.
| 예시 | 영역 |
|---|---|
 |
VR |
 |
AR |
 |
3D Print |
 |
Medical |
 |
Bio |
[img. 3D를 활용하는 영역의 예시]
빛은 직진성을 띄기 때문에 3D의 형태는 2차원에 표현이 가능하며, 우리가 실제로 3D 물체를 인식하는 방법은 3D world를 2D space에 projection하는 image이다.

[img. 원근에 대한 연구와 과거와 현재의 결실]
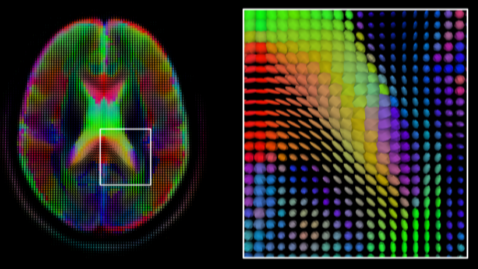
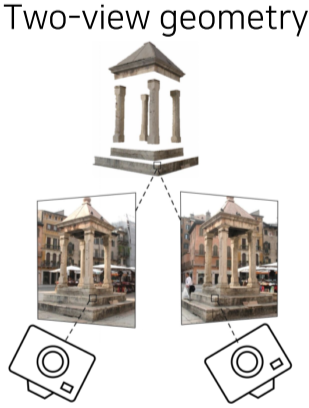
3차원 공간을 2차원 공간에 표현하는 것을 Projection을 통하여 가능했다면, 반대로 2차원 공간의 정보를 이용해 3차원 공간으로 표현하는 것은 Triangulation으로 가능하다.
- 2장 이상의 이미지에서 3D pint의 한 점의 pixel 이동값과 이미지를 촬영했던 위치를 알고 있으면 Triangulation을 통해 이론상 3D 모델을 예측할 수 있다.
[img. Triangulation의 예시]
2차원 이미지는 각 픽셀을 의미하는 2차원 array에 RGB 값을 저장함으로써 표현 가능하다.
3차원 데이터의 표현은 여러가지 방법이 있다.
| 3D 데이터 표현 예시 | ||
|---|---|---|
 |
 |
 |
| Multi-view images | Volumetric(voxel) | Part assembly |
| 2차원 이미지 여러장 | 3차원 array | 기본 3D 도형의 집합 |
 |
 |
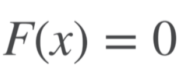 |
| Point cloud | Mesh (Graph CNN) | Implicit shape(function) |
| 3차원 Point 들의 집합 | Vertex의 삼각 edge | 고차원의 함수 |
[img. 3D의 다양한 표현 방법들]
3D datasets
ShapeNet
대용량 3D model 데이터셋(51,300개, 55 카테고리)

[img. ShapeNet의 object들]
PartNet(ShapeNetPart2019)
ShapeNet의 개량, 추가로 Detail이 annotation 되어있음(ex)자동차 모델 -> 자동차 바퀴, 창문, 천장 등이 따로 나눠짐)
(26,671개의 3D model 총 573,585개의 part로 나눠짐)
[img. PartNet 예시들]
SceneNet
500만개의 랜덤하게 Generation된 RGB-Depth Indoor image들

[img. SceneNet, 랜덤하게 만들어짐]
ScanNet
RGB-Depth 250만개의 실제 Indoor scan data
[img. ScanNet]
Outdoor 3D scene datasets
주로 자율주행을 위한 야외 데이터셋들, Lidar로 스캔한 것이 많음

[img. Outdoor 3D scene 모음]
3D tasks
2차원 classification이나 object detection, semantic segmentation 등, 3D에도 같은 Task가 있다.
자율주행, 의료, 제조업 등에 활발히 사용 중
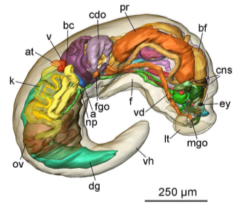

[img. 3D task의 예시]
Mesh R-CNN
2D image를 입력으로 감지된 object의 3D 메쉬를 출력
Mask R-CNN 구조를 변경해서 구현
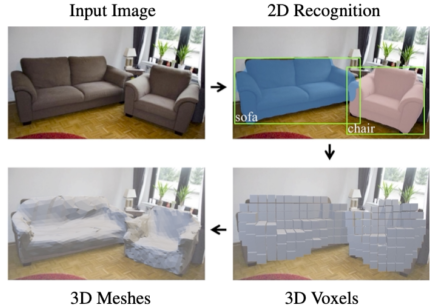
[img. Mesh R-CNN 예시]
Mesh R-CNN은 기존의 Mask R-CNN에 3D mesh를 출력하는 3D branch가 추가된 형태
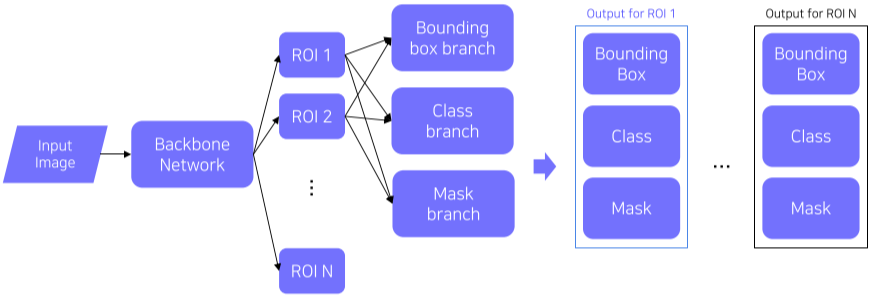
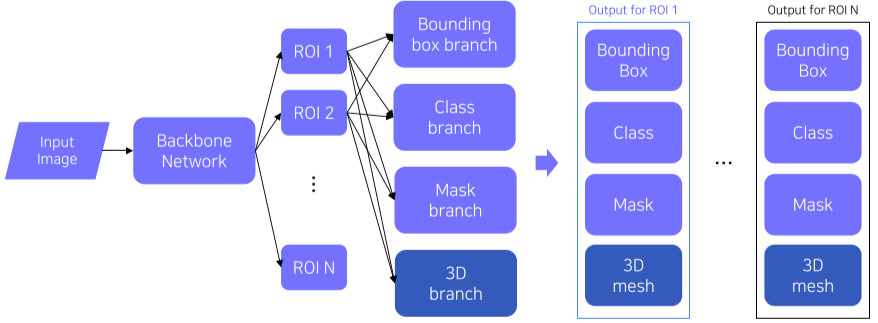
[imgs. Mask R-CNN VS Mesh R-CNN]
3D mesh를 생성하는 문제를 조금더 작은 여러개의 부 문제로 나누어 해결하여 더 좋은 성능을 낼 수 있다.
- normal map, depth map, silhouette 검출 -> 3D 오브젝트 생성
- Depth 탐지-> Spherical map(어느 한점을 중심으로 물체를 보았을 때의 이미지) 생성 -> voxel화 -> 3D mesh화
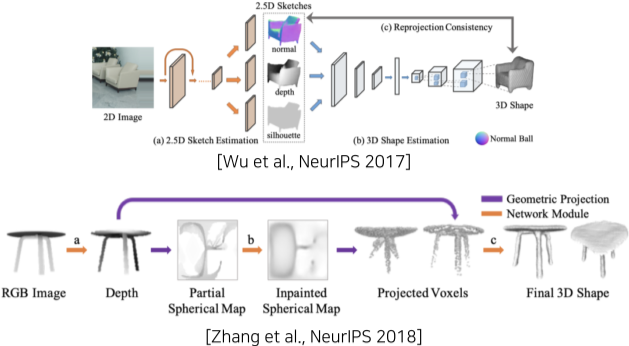
[img. 더 복잡하고 정확한 3D mesh 생성법]
3D application example- Photo refocusing
사진의 depth map을 이용하여 사진의 focus를 바꾸는 application
Photo refocusing 또는 post-refocusing이라고도 함.

[img. 앞의 조각상에 focusing 된 사진]
depth map은 depth sensor나 neural network를 이용해 검출 가능하다.

[img. 사진의 depth map]
구현 과정
- depth thrshold range 최소치 ~ 최대치($D_{min}\sim D_{max}$)를 정하기
- 즉 $D_{min}\sim D_{max}$까지만 focus하고 나머지는 blur 처리하겠다는 의미
우리의 경우 0~255로 표현함

[img. depthmap 예시]
- depth map thresholding으로 masking
- focusing할 focusing area와 blur 처리할 defocsing area로 마스킹
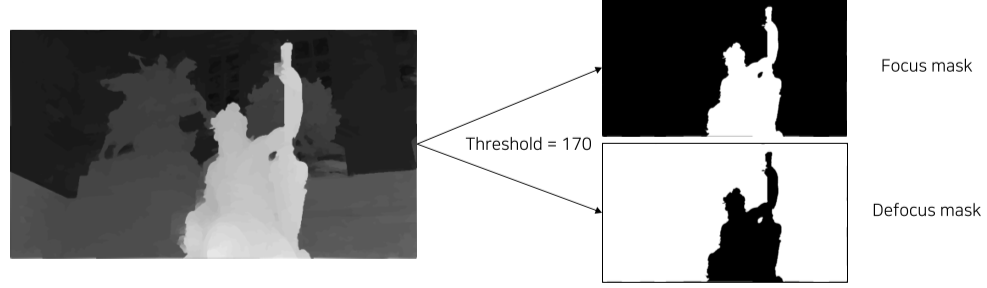
[img. Threshold가 170일 때의 masking]
focus_mask = depth_map[..., :] &#62; threshold_value
defocus_mask = depth_map[..., :] &#60;= threshold_value
[img. masking code 예시]
- blurr버전의 image를 생성
- Depth에 따라 adaptive하게 적용하는 방법도 있음

[img. Blur kernal을 이용한 image]
blurred_image= cv2.blur(original_image, (20, 20))
[code. cv2를 이용한 blur 처리]
- Masked focused image와 Masked defocused image를 생성하고 이미지 blending을 통해 refocused된 이미지 생성
- 간단한 image array의 연산으로 생성 가능

[img. Masked images]
focused_with_mask = focus_mask * original_image
defocused_with_mask = defocus_mask * blurred_image
[code. Masked Image 생성 코드]

[img. 결과물 blend]

[img. Threshold에 따른 blur 차이]
_articles/AI/CV/컴퓨터비전 기본.md