풀스택 웹🌐 개발자 지망생 🧑🏽💻
➕ 인공지능 관심 🤖
Categories
-
┣
▶ COMPUTER_SCIENCE
📂: 7 -
┣
▶ WEB
📂: 3 -
┣
▶ ETC
📂: 3-
┃
┣
ETCS
📄: 10 -
┃
┣
SUBBRAIN 개발기
📄: 5 -
┃
┗
YOS 개발기
📄: 1
-
┃
┣
-
┗
▶ AI
📂: 9-
┣
AITOOLS
📄: 3 -
┣
CV
📄: 2 -
┣
DEEP_LEARNING
📄: 1 -
┣
DATA_VIS
📄: 2 -
┣
GRAPH
📄: 1 -
┣
LIGHTWEIGHT
📄: 1 -
┣
MATH
📄: 1 -
┣
NLP
📄: 3 -
┗
STRUCTURED_DATA
📄: 2
-
┣
이미지 분류 개념
- EDA(Exploratory Data Analysis, 탐색적 데이터 분석)
- Dataset
- Generalization
- Data Generation
- Model
- Training & Inference
- Ensemble(앙상블)
- Hyperparametr Optimization
- Experiment Toolkits & Tips
이미지 분류(Image Classification Competition) 개념
네이버 AI BoostCamp의 P stage 이미지 분류 강의를 정리하였습니다.
## Competition with AI Stages
Competition이란?


여러 회사, 단체 등에서 상금을 내걸고 데이터를 제공하여 원하는 결과를 얻는 가장 좋은 방법을 모색한다.
- 데이터 뿐만 아니라 컴퓨팅 자원을 지원할 때도 있다.
Kaggle이 competition platform으로 대표적이며, 국내에서는 DACON 이 존재한다.
| Pipeline | |
|---|---|
| ML pipeline | 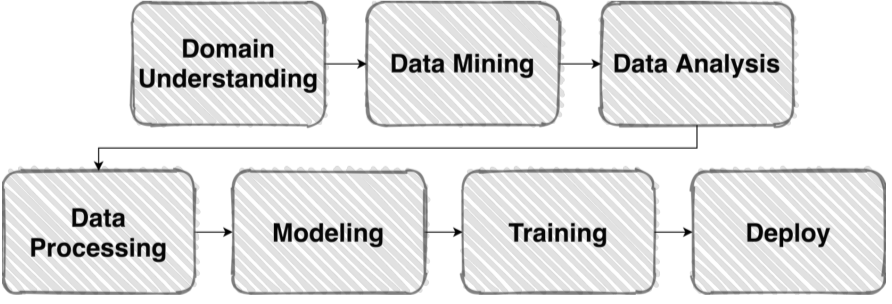 |
| Competition pipeline | 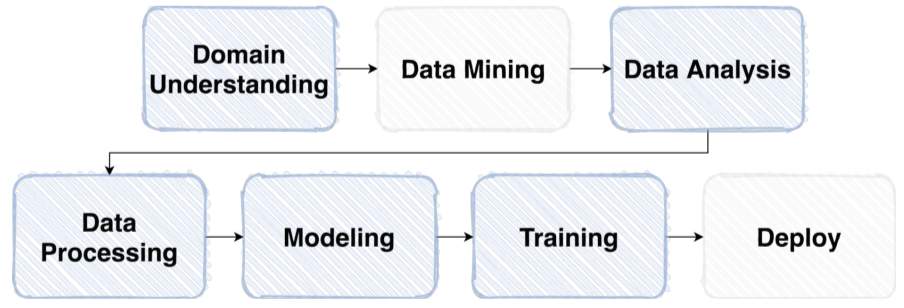 |
실제 머신러닝 업무의 Pipeline과 Competition의 Pipeline이 비슷한 경우가 많기 때문에 Competition을 통해 ML 실력을 갈고 닦기 좋다!
Overview

문제에 대한 정의, 요구사항과 직면하고 있는 문제점 등에 대해서 자세히 알 수 있다.
위의 경우, 단순히 악성 댓글을 파악하는 문제가 아니라, 악성댓글 파악 중 야기되는 정치적 이슈에 대한 설명이 포함되어 있다.
위의 overview를 자세히 보는 것으로 내가 풀어나가야할 문제에 대한 방향성을 얻어낼 수 있으며, 이러한 행위를 Problem Definition(문제 정의)라고 한다.
이러한 문제 정의 행위로는
- 내가 무슨 문제를 풀어야 하는가?
- Input과 Output은 무엇인가?
- 이 솔루션은 어디서 어떻게 사용되어지는가?
등의 예시가 있다.
Data Description
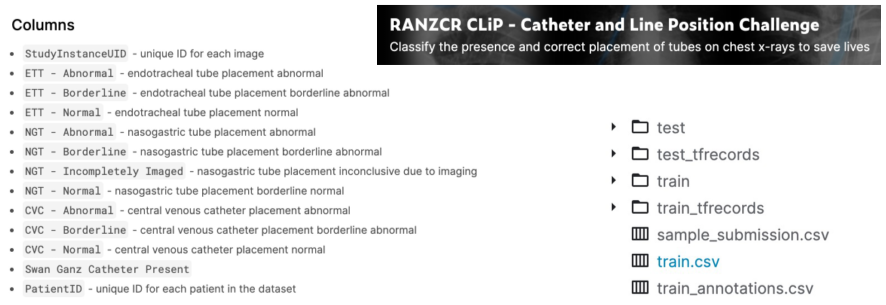
File 형태, Metadata Field 소개 및 설명이 적혀있는 부분
데이터 스팩의 요약본, EDA, 문제정의 등에 중요하다.
Notebook
데이터 분석, 모델 학습, 테스트 셋 추론의 과정을 서버에서 연습 가능
단순히 연습용이 아니라, 일부 Competition의 경우는 회사에서 이러한 방식으로 Computing power를 제공하는 경우도 있으며, 성능을 강제하기 위해 사용이 강요되는 경우도 있다.
Submission
자신이 제출했던 테스트 예측 결과물들의 정보를 확인하고, 제출할 결과물을 선택할 수 있다.
Leaderboard
자신의 제출물의 순위를 확인할 수 있다.
Discussion
Kaggle 등에서는 Discussion에서 다양한 정보를 주고 받는 문화가 발달함.
정보를 공유함으로, 경쟁자의 점수가 올라갈 수 있음에도 불구하고, 등수를 올리는 것 보단 문제를 해결하고 싶은 마음으로 올리는 경우가 많음.
하지만 경연 종료 1~2주 전에는 보통 Critical한 정보의 공유는 멈춰지는 경우가 많다.
ML에 관한 정보뿐만 아니라, 도메인 지식, CS 지식 등도 공유된다.
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)
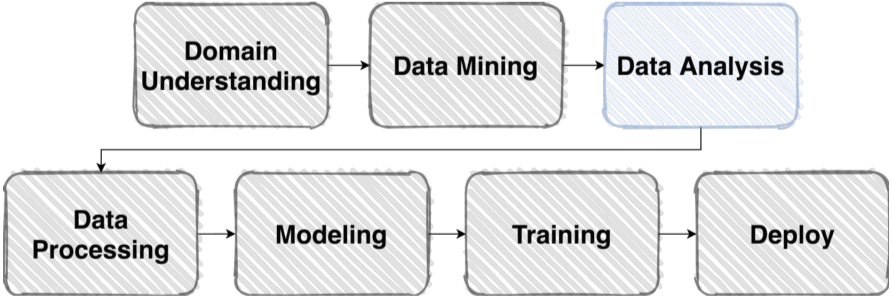
EDA는 ML pipeline 중 Data Analysis 부분에 해당한다
EDA란?
EDA(Exploratory Data Analysis, 탐색적 데이터 분석), 데이터를 이해하기 위한 노력
데이터의 구성, 형태, 쓰임새 등을 분석하는 것
- 주제와 연관성, 데이터 타입의 특성, 메타데이터의 분포 등이 있다.
머신러닝 파이프라인에 많은 것에 영향을 주게 된다.
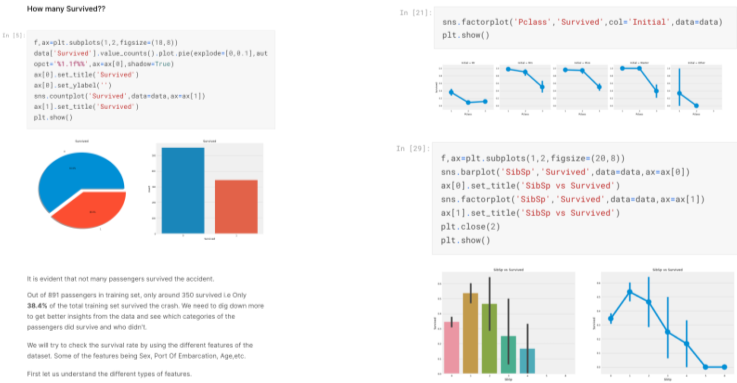
EDA 결과물의 예시, 데이터 이해가 목적이므로 정해진 툴이나 절차 없이 궁금한 점을 찾아보는 과정이다.
또한, 한번으로 끝나는 과정이 아니며, 언제나 의문이 생기면 EDA는 pipeline 과정 중간에 언제나 돌아올 수 있다.
툴로는 python, excel 등이 존재
Image Classification
이미지란, 시작적 인식을 표현한 인공물(Artifact)

채널이 3개인 경우 RGB(Red, Green, Blue), 채널이 4개인 겨우 CMYK(Cyan, Magenta, Yellow, Black), 또는 RGBA(+alpha)를 표현한 경우가 많다.
uint8(unsinged integeter 8bit)로 표현하는 경우가 많으며, 0~255까지 256의 범위를 가진다.
Dataset
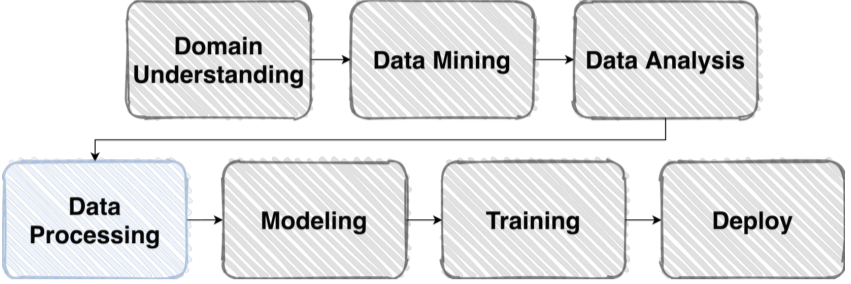
Dataset 형성, Data Generation은 Data Processing의 과정이다.
Raw Data를 모델이 사용할 수 있는 Dataset으로 만들면 다양한 모델이나 쓰임새에 쉽게 사용할 수 있을 뿐만 아니라 인간이 쉽게 이해할 수 있다.
Pre-processing
Pre-processing(전처리)는 pipeline에 시간과 중요성, 비중 모두 커다란 부분을 차지하고 있다.

Competition data는 제대로된 Data를 주는 편이지만, 수집한 데이터의 경우 절반 이상을 날려야 하는 경우가 많음.
이미지의 전처리의 경우, 다음과 같은 예시가 있다.
- Bounding box

이미지의 중요한 부분을 Crop한 뒤 Resize하여 학습시킬 모델을 더욱 명확히 함
좌측 상단과 우측 하단의 좌표를 이용해 Bounding box를 그릴 수 있음
- Resize
계산효율을 위해 적당한 크기로 이미지 사이즈 변경
이미지 사이즈가 바뀌어도 성능에 영향은 미미한 경우가 많다.
- 이미지 채도, 대비 변경
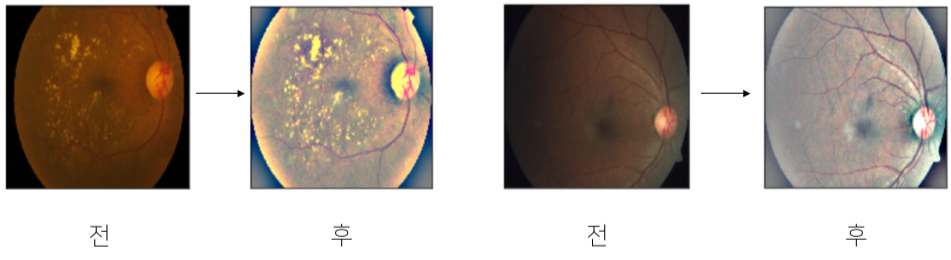
상단은 홍채 사진을 더욱 뚜렷히 바꾼 것
명확하지 않은 사진을 채도, 대비, 명도,등을 바꾸어 선명하게 바꿈
전처리가 성능의 향상을 보장하진 않는다.
Generalization
Bias & Variance
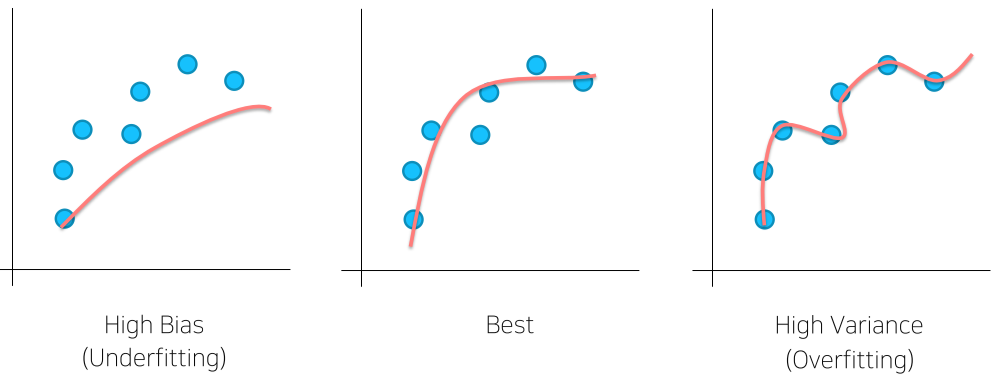
Underfitting : 학습이 부족하여 제대로 구별할 수 없음
Overfitting : noise를 포함해서 모든 학습이 너무 많이되어 너무 자세하게 구분함
일반화, 즉 학습한 데이터셋 이외의 Input에서는 부정확한 결과를 내게 됨
Train/Validation
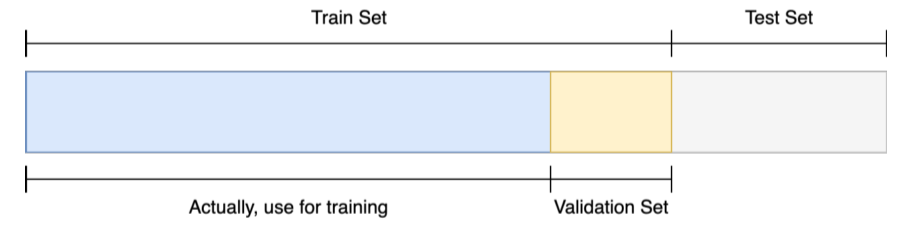
훈련 셋 중 일정 부분을 따로 분리하여 검증 셋으로 활용
학습 가능한 데이터양이 줄어들지만, 학습되지 않은 Validation Set의 분포를 통해 일반화 성능을 검증할 수 있다.
검증 절차를 통해 Generalization(일반화) 성능을 늘릴 수 있다.
Data Augmentation

데이터를 일반화하는 과정, 주어진 데이터가 가질 수 있는 Case(경우), State(상태)를 다양하게 함.
이미지의 경우 다양한 필터, 채도, 색상 변경, 이미지 회전, Crop 등, 원본 이미지를 변경하는 것을 통하여 데이터를 늘림.
문제가 만들어진 배경과 모델의 쓰임새를 살표보아 Data Augmentation의 힌트를 얻을 수 있다.
(ex)밤과 낮에 따로 촬영될 수 있는가? -> 명도 변경)
torchvision.transforms 에서 Image에 적용 가능한 다양한 함수를 살펴볼 수 있다.

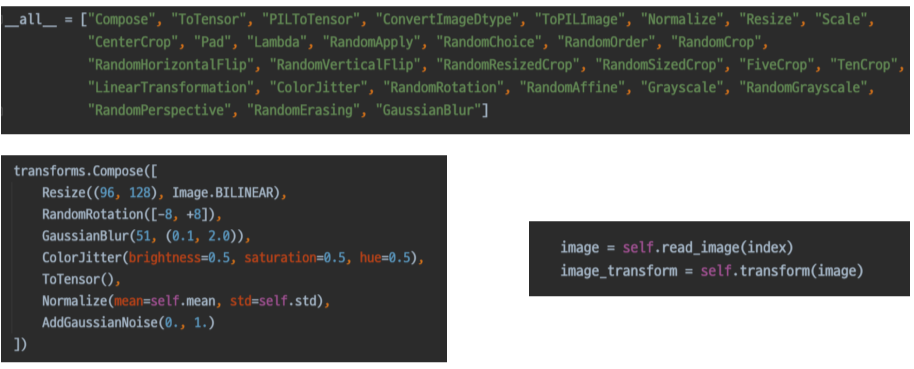
Albumentations라는 Library는 좀 더 처리가 빠르고 다양한 기능을 제공함

Data Generation
데이터 전처리, Augmentation 등의 출력 결과가 모델의 성능, 시간 등에 영향을 주는 경우가 많다.
Data Feeding
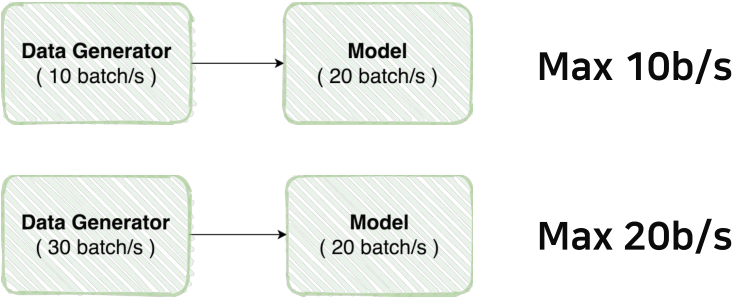
모델의 학습속도와 이전 단계가 느리다면 전체적인 학습속도가 느려질 수 밖에 없다.
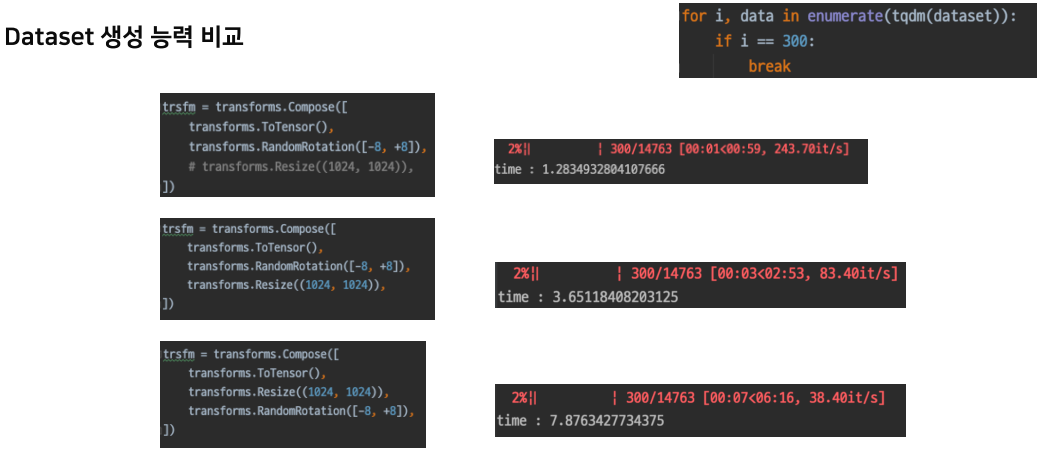
단순히 Data Augmentation의 순서가 달라지는 것 많으로도 성능이 달라진다.
데이터셋 생성능력을 비교하여 적절한 성능을 정해보자.
torch.utils.data
Dataset
pytorch에서 정의할 수 있는 데이터셋 생성 방법은 다음과 같다.
from torch.utils.data import Dataset
class MyDataset(Dataset): # torch.utils.data.Dataset 상속
def __init__(self): # MyDataset 클래스가 처음 선언되었을 때 호출
print("Class init!!")
pass
# test = MyDataset() 결과: # Class init!!
def __getitem__(self, index): # MyDataset의 데이터 중 index 위치의 아이템을 리턴
return index
# test[2341] 결과: # 2341
def __len__(self): # MyDataset 아이템의 전체 길이
print("length is 3")
return 3
# len(test) 결과: # lenth is 3 # 3
이를 통해 Vanilla 데이터를 원하는 형태로 출력 가능
DataLoader
Dataset을 효율적으로 사용할 수 있도록 관련 기능 추가
train_loader = torch.utils.data.DataLodaer(
train_set,
batch_size=batch_size, # batch 사이즈
num_workers=num_workers, # 병렬 코어 갯수
drop_last=True # batch 사이즈에 맞지 않는 마지막 batch 버림
)
이외에도 shufle, sampler, batch_sampler, pin_memory 등 여러 기능이 있다.
collate_fn : batch 단위 마다 실행할 함수 넣어주기
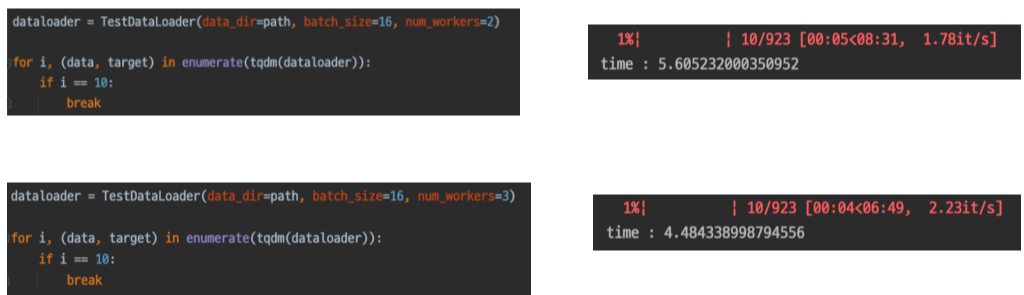
num_workers 사용 결과
너무 큰 값을 사용하면, 딥러닝 이외의 시스템에서의 사용하는 연산이 간섭하여 오히려 성능이 떨어진다고 함.
Model
모델은 데이터셋을 Input으로 받아 원하는 출력을 만들어 준다.
객체의 정보적 표현을 모델이라고 한다.
Design Model wtih Pytorch

사용성 좋고 연구에 편리한(Pythonic) Low level 오픈소스 머신러닝 프레임워크
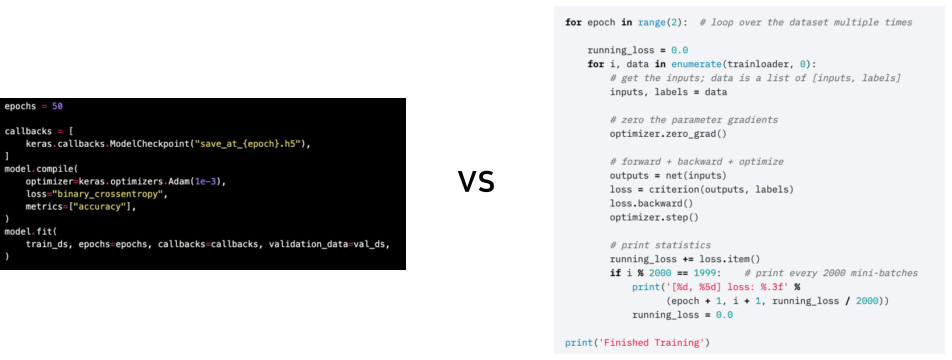
좌 keras 코드와 우 pytorch 코드를 비교하면 좀더 Low level에 가까운 것을 알 수 있다.
이를 통해 원리의 이해와 customizing이 좀더 쉽다.
nn.Module

Pytorch 모델의 모든 레이어는 nn.Module 클래스를 따른다.
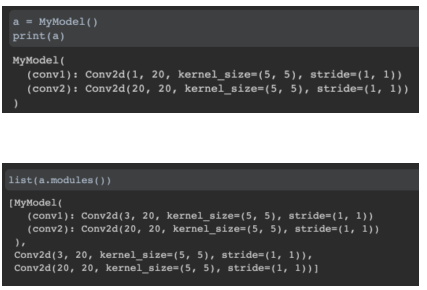
modules 함수를 통해 내부에 nn.Module를 상속하는 layer들을 확인할 수 있다.
nn.Module 클래스는 일종의 정보를 저장하는 저장소 역할을 하며 이를 상속받아 layer(모델, layer 등)를 만든다.
- 이때 모델 내부의 conv layer 같은 layer들은 child 모듈이라고 하며, nn.Module을 상속받은 모든 클래스의 공통된 특징이다.
- 이 특징을 통해 연결된 모든 module을 확인할 수 있다.
이후 이 모델이 호출 되었을 때는 forward() 함수가 불러진다.
이때 input을 넣어주며, 또는 직접 모델명.forward(input)으로 불러도 된다.
- 최상위 nn.module의 forward() 함수 실행으로 정의된 모듈 각각의 forward()가 모두 실행된다.
Parameter
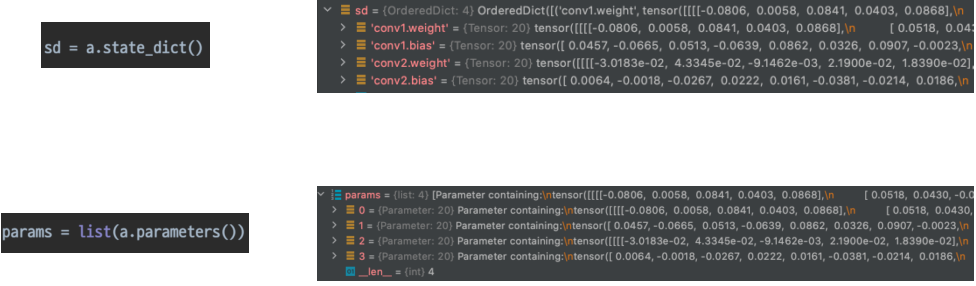
module 내부에는 Tensor 기반의 parameter를 가지고 있을 수 있다.
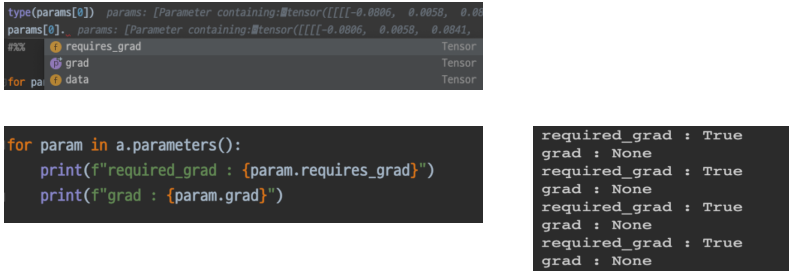
parameter는 또한, data, grad, requires_grad 등의 변수를 가지고 있으며
-
data : paremater의 수치
-
grad : loss에 의해 정해진 gradient 값
-
requires_grad : boolean, 해당 parameter를 backpropagation 시 업데이트 할 것인가?
이런 식으로 파이토치는 형식과 구조를 파악하고 응용하기 쉬우며 디버깅도 쉽다
Pretrained Model
대량의 데이터셋, 오래 걸리는 학습 시간, 복잡한 레이어 구축 등을 고려하면 처음부터 모델의 모든 것을 만드는 것은 힘들다.
그러므로 YOLO와 같이 미리 만들어지고 학습된 Pretrained Model을 내 Task에 맞게 다듬어서 사용하면 이러한 노력을 줄이면서도 성능을 보장할 수 있다.

Pretrained model의 발전에는 일반화가 뛰어나고 데이터의 양과 질이 뛰어난 오픈소스 데이터셋인 IMAGENET의 등장에서 부터 시작되었다.
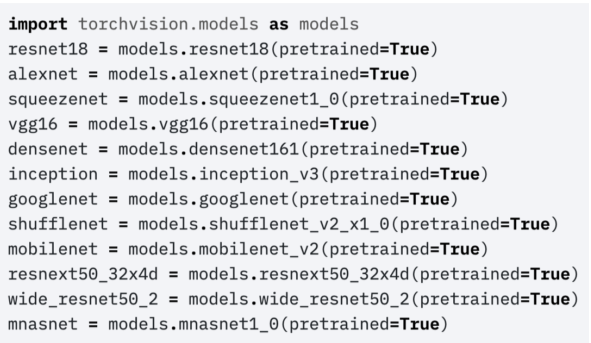
TorchVision 등에서 손쉽게 이용 가능하며, pretrained=True로 설정시, 구조 뿐만 아니라 학습한 weight 또한 같이 가져온다.
Transfer Learning
앞서 가져온 Pretrained model을 우리가 원하는 용도로 사용하기 위해 학습하는 것을 Transfer Learning이라고 한다.
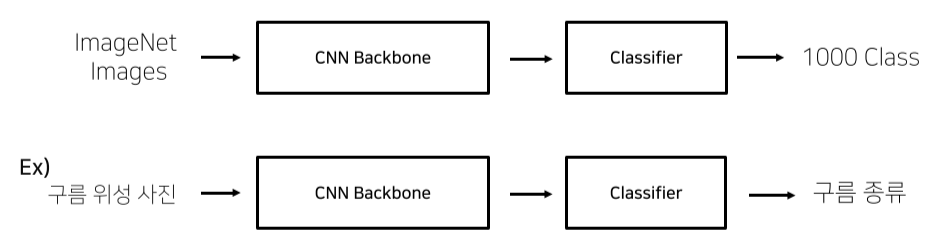
나의 Task와 비교하여 적절한 Transfer Learning 방법을 고려해야 한다.
- 학습데이터가 충분한 경우
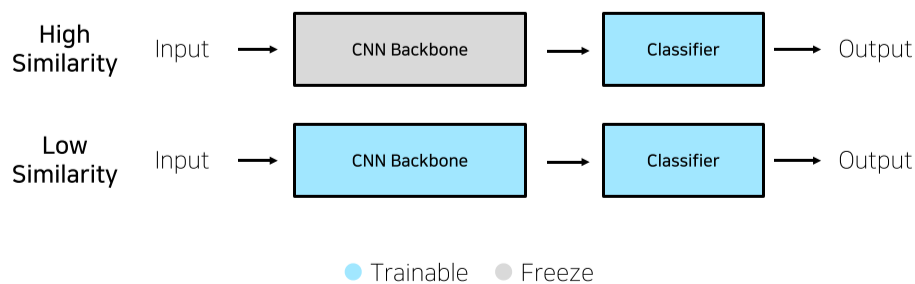
Task가 ImageNet과 비슷할 경우, Classifier만 학습시킨다.(feature-extraction, 특색 추출)
Task가 ImageNet과 비슷하지 않을 경우, Classifier뿐만 아니라 CNN Backbone또한 다시 학습시킨다.(Fine-tuning, 미세 조정)
- 이때 구조만 살리고 처음부터 하는 것이 아니라, 기존의 weight를 가지고 있는 채로 다시 학습하는 것이다.(보통 성능이 더욱 좋다.)
- 학습 데이터가 충분하지 않은 경우
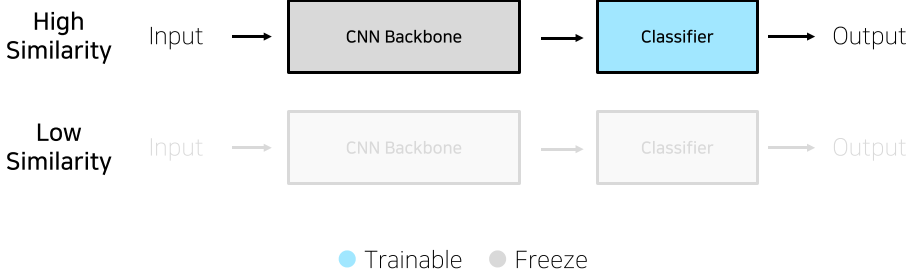
Task가 ImageNet과 비슷할 경우, Classifier만 학습시킨다.
Task가 ImageNet과 비슷하지 않을 경우, 성능이 그리 높지 않으므로 추천하진 않는다.
Training & Inference
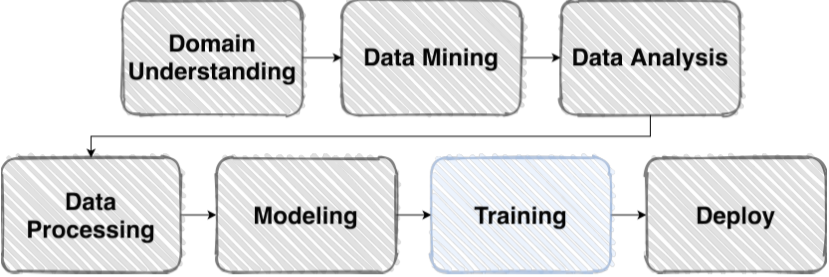
Loss, Optimizer, Metric
Training에 필요한 요소는 크게
- Loss
- Optimizer
- Metric
으로 나뉜다.
Loss
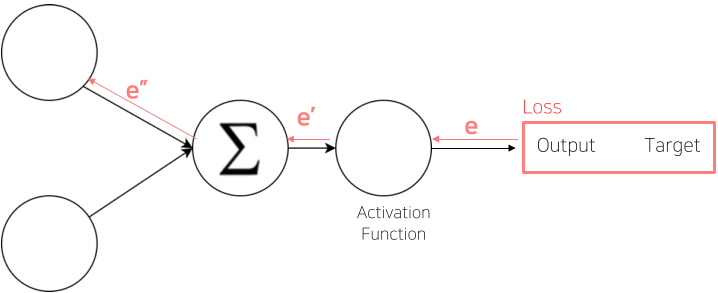
Loss 값은 정답인 Target과 예상값인 Output의 차이를 Loss 함수(Cost 함수, Error 함수)를 통하여 구한다.
- Loss 함수는 목적이나 Task 등에 따라 잘 골라줘야 한다.
이후 Error Backpropation을 통해 가중치가 업데이트 되게 된다.
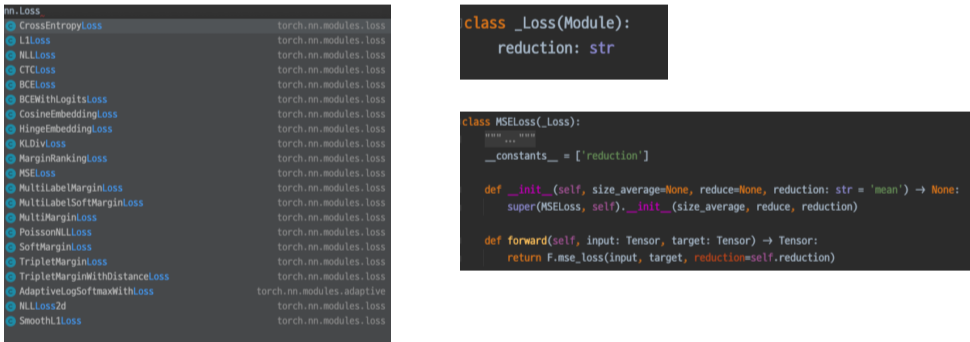
nn 패키지 내부의 Loss함수 또한 Module을 상속하고 있으며, 이를 통해 모델 등의 child Module이 되어 보여지거나 Forward가 존재하는 등의 특징을 갖는다.
그래서 커스텀 Loss를 만들려면 Module을 상속해야 함.
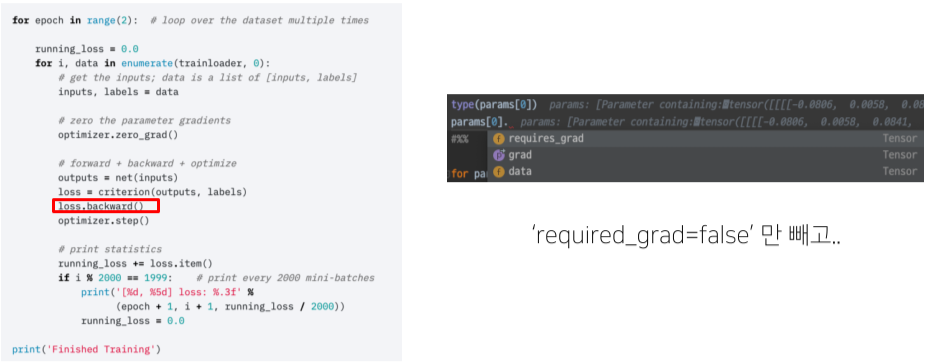
criterion(관용적인 변수명)에 loss 함수를 정의한 뒤 output과 labels를 넣어 구한 loss의 backward 함수가 실행되면 모델의 파라미터 grad가 업데이트된다.
업데이트하지 않고 Freeze하고 싶으면 requires_grad를 false로 설정하면 된다.
- 이때 모델(net)->output->criterion->loss 순으로 연결이 되는 체인을 통하여 backpropation이 가능하게 된다.
Loss 함수에 조금 과정을 추가한 특별한 Loss 또한 존재한다.
Focal Loss : Class Imbalance 문제를 해결하기 위해 맞춘 확률이 높은 Class는 조금의 Loss를, 맞춘 확률이 낮은 Class는 Loss를 훨씬 높게 부여
Label Smoothing Loss : Class target label을 Onehot 표현으로 사용하기 보다는 조금 Soft하게 표현해서 일반화 성능을 높임
- 즉 [0, 1, 0, 0, 0] 같은 형태 대신 [0.025, 0.9, 0.025, 0.025, …] 같은 형태
Optimizer
Optimizer는 Loss 함수의 결과물인 Loss와 방향과 Learnig rate에 따라 weight를 업데이트 한다.
\(w'=w-\eta\frac{\part E}{\part w}\\
\eta:Learning\ rate(학습률),\ \frac{\part E}{\part w}:방향, E: error\)
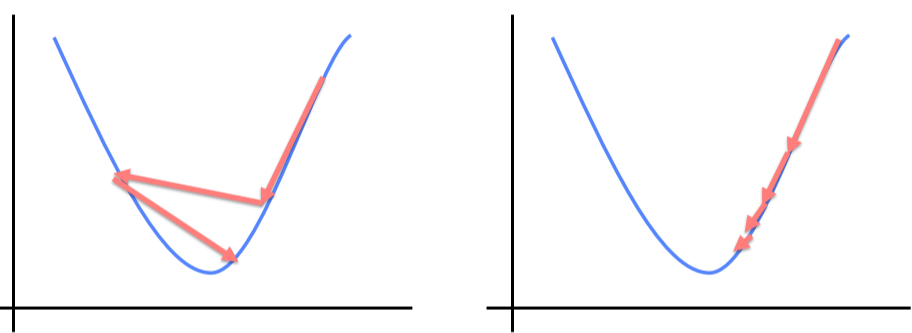
Optimizer는 LR scheduler를 통해 Learning rate를 학습 중에 동적으로 조절할 수 있다.
Scheduler의 종류는 다음과 같다.
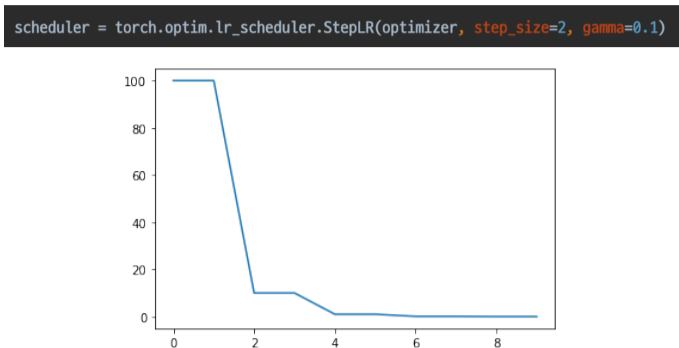
- StepLR
특정 Step 마다 LR 감소
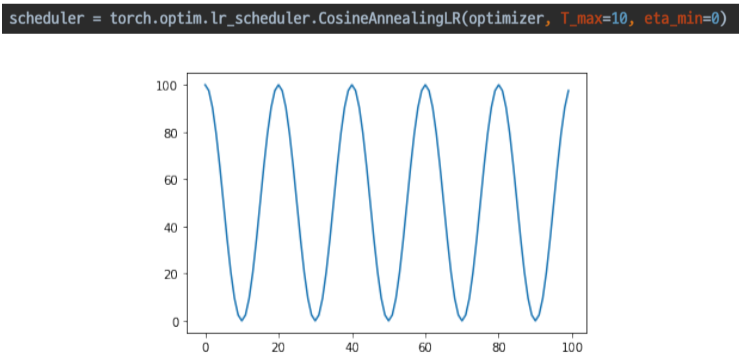
- CosineAnnealingLR
Cosine 함수 형태처럼 LR을 급격히 변경
변화를 급격하게 주어, Local minimum에 빠지는 경우를 막음
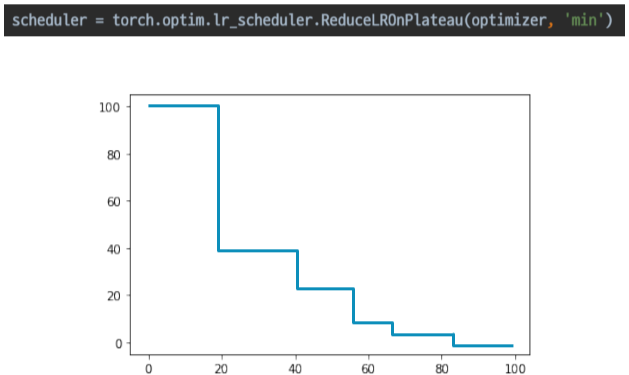
- ReduceLROnPlateau
일반적으로 많이 사용함, 더 이상 성능 향상이 없을 때 LR 감소
Metric
학습된 모델을 객관적으로 평가할 수 있는 지표가 필요

R…은 ROCAOC
여러 Task, 목적, 데이터 상태 등에 따라 여러 Metric의 종류가 있다.
Ranking : 추천 시스템에 사용되는 경우가 많음.
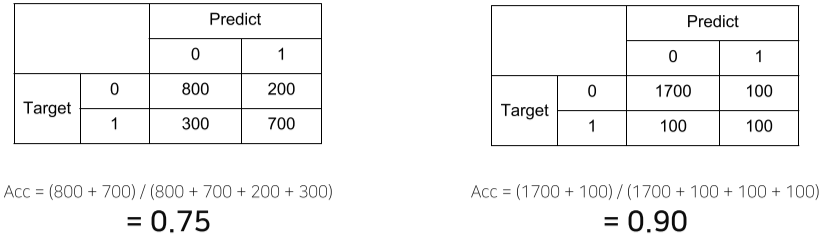
상단의 예시처럼, 데이터의 편향 등에 따라 정확도가 다르게 나올 수 도 있다.
Classification의 경우,
그러므로 Class 별로 밸런스가 적절히 분포되었을 시, Accuracy,
Class 별 밸런스가 좋지 않을 경우 F1-Score를 사용하는게 좋다.
Training Process
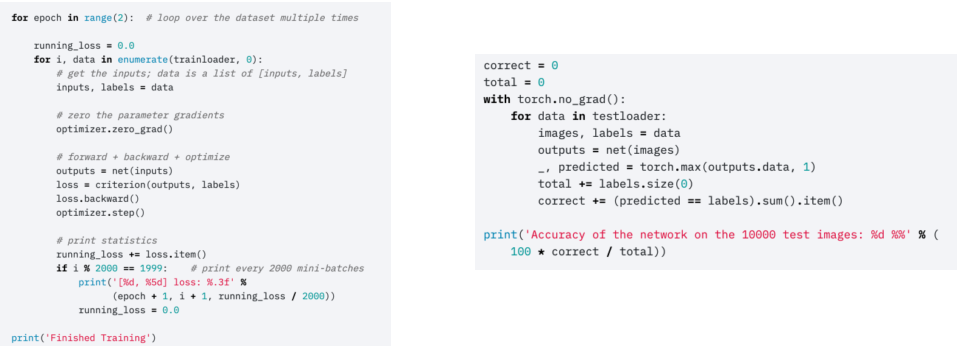
pytorch는 머신러닝의 과정을 잘알 수 있게 끔 구성되었다
우리는 앞서 Dataset, Model, Loss, Optimizer, Metric 등 Training을 하기 위한 준비에 대해 배웠다.
Training을 할때 코드를 이해해 보자.
- Model.train()
모듈을 상속한 객체를 training 모드로 바꿔준다.
training/evaluation 모드의 차이에 따라 Dropout이나 BatchNormalzation 등의 행동이 조금 달라지게 된다.
- optimizer.zero_grad()
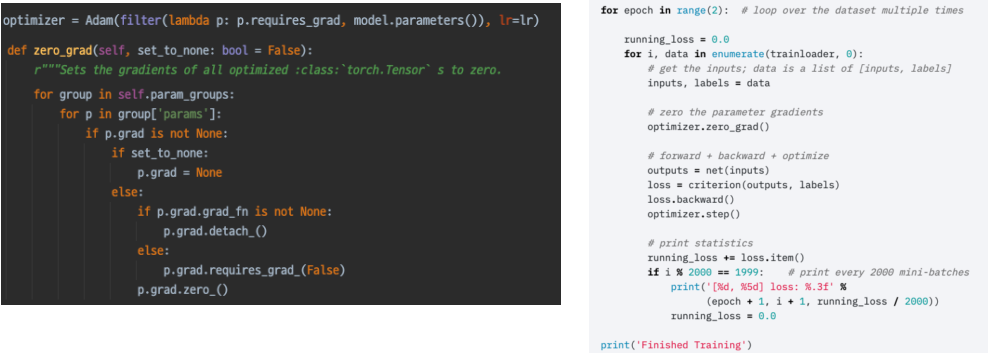
optimizer가 이전 batch 사용했던 Parameter들의 grad를 초기화해준다.
기본값이 아닌 이유는 Loss를 쌓아서 사용하는 방법도 존재하기 때문
- loss = criterion(outputs, labels)
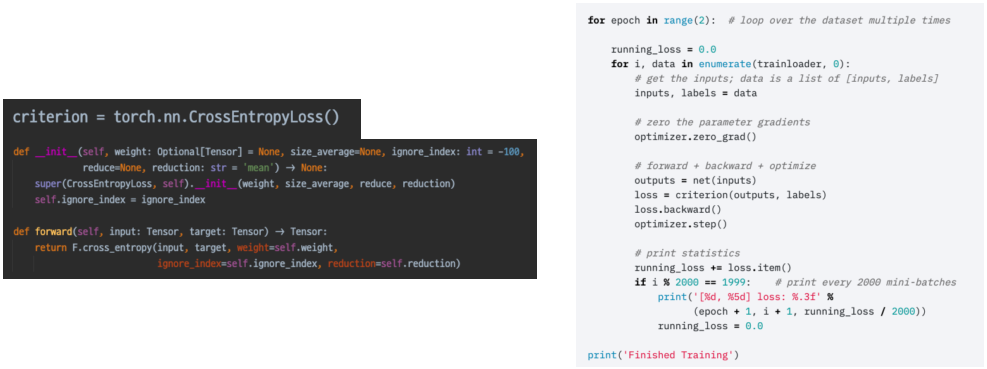
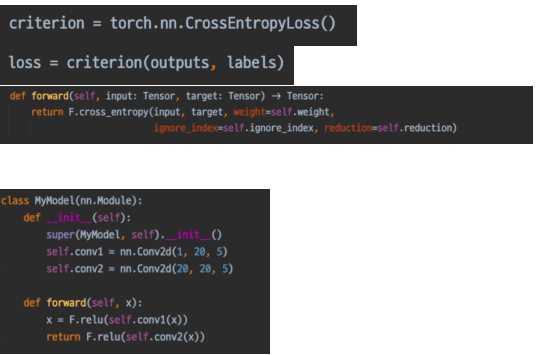
loss 함수 또한 Module을 상속하므로 input 부터 output 까지 연결되는 체인이 생겨난다.
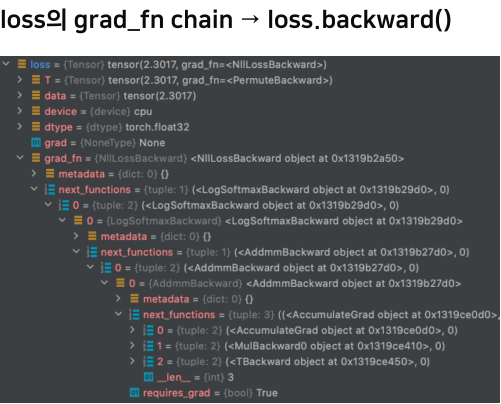
loss의 grad_fn chaing에 loss의 backward() 함수가 들어가 있으며, 내부에 next_fucntion을 통해 다음 layer와 죽 연결되어 있음을 확인할 수 있다.
- optimizer.step()
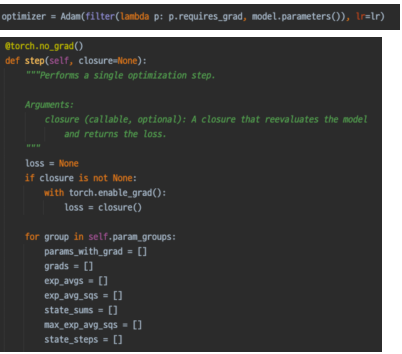
step()를 실행하면 optimizer가 loss backward를 통해 업데이트된 gradient를 이용하여 weight들을 업데이트한다.
정확한 내부 로직은 optimizer 마다 다르다.
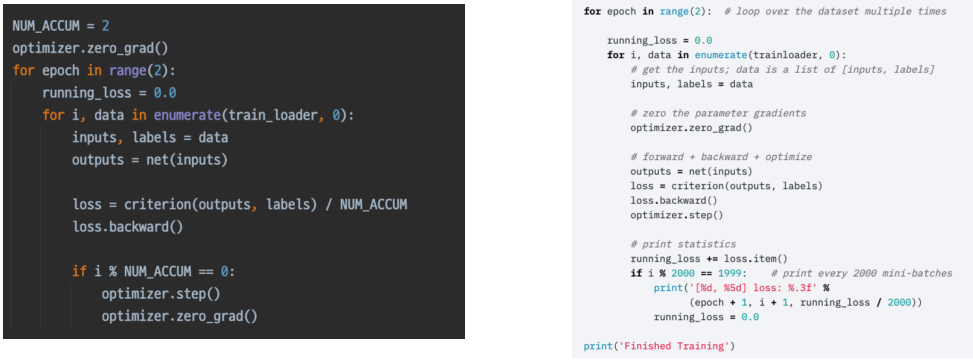
Gradient Accumulation은 optimizer의 step가 zero_grad를 특정 배수 epoch에만 실행한다.
batch size를 늘리는 것 과 같은 효과를 내면서 동시에 batch size를 늘렸을 때의 성능 요구를 줄였다.
Inference Process
- model.eval()
모델을 evaluation 모드로 바꾼다. 위의 train()과 같은 이유
- with torch.no_grad():
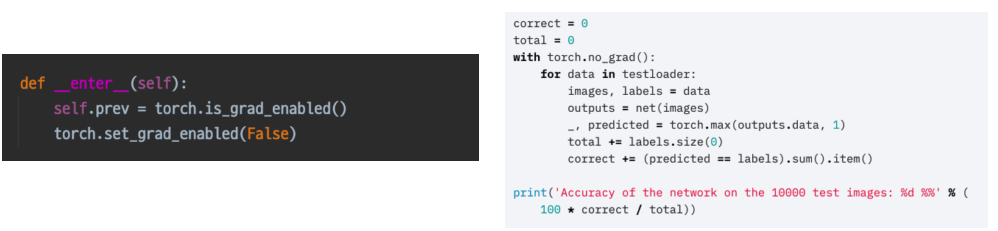
with torch.no_grad()내부 로직일때는 모든 parameter들이 require_grad=False 인 상태와 같아진다.
Inference 중일때는 내부 parameter가 업데이트 되지 않는다.
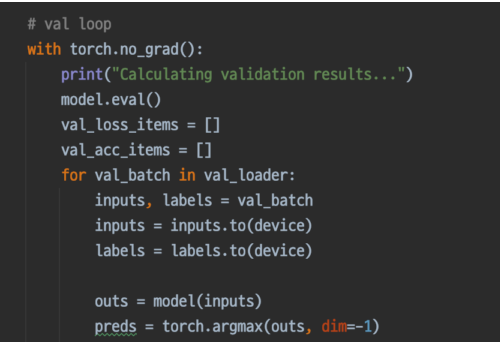
Validation data로 Inference 하는 코드가 검증 코드이다.
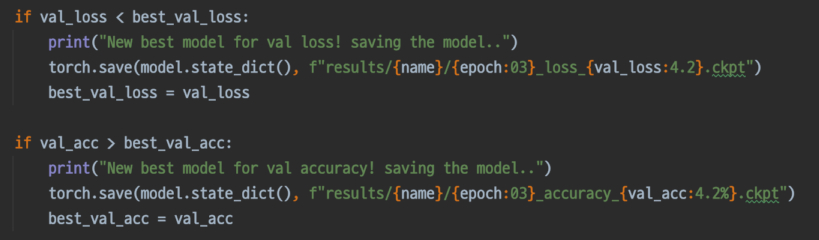
checkpoint는 inference 결과를 보고 모델을 저장하면 된다.
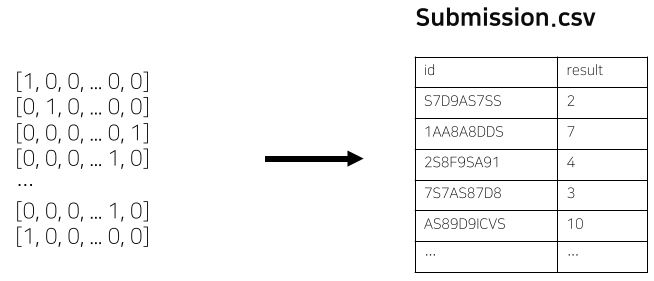
마지막으로 eval의 결과를 submission으로 바꾸어 제출하면 된다.

PyTorch Lightning을 이용하면 코드를 좀더 간결하고 읽기 쉽게 사용할 수 있다.
Ensemble(앙상블)
싱글 모델보다 더 나은 성능을 위해 서로 다른 여러 학습 모델을 사용하는 것
효과는 있지만, 학습, 추론 시간이 배로 소모됨
딥러닝은 Overfitting이 생길 경향이 상당히 많다.
앙상블의 기법은 Begging, Stacking, Boosting 등의 기법이 있으며
Underfitting(High Bias)을 해결하기 위해 Boosting이 주로 자주 사용된다.
- 정형데이터 등에서도 gradient Boosting이나 XGBoost 같은 방법이 사용된다.
Overfitting(High Variance)를 해결하기 위해 Begging이 주로 사용된다.
- 여러 정답을 취합해서 평균을 내는 방법, Random forest 등이 있음
Model Averaging(Voting)
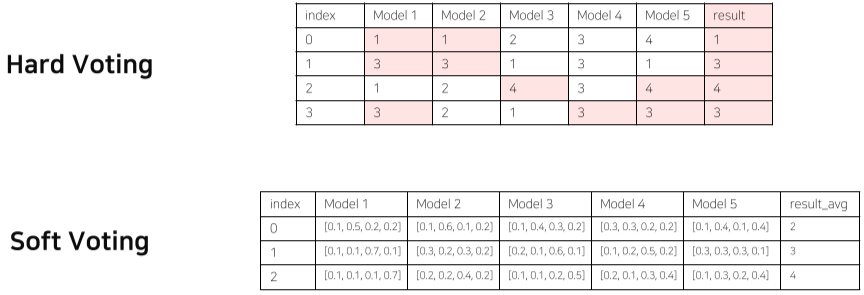
앙상블에서 사용하는 방법, 서로 다른 특색을 가진 모델이 애매한 결과들을 냈을 때, 투표를 통하여 답을 구하는 것
- One-hot vector로 voting하는 Hard Voting(다수결)이 있고,
- 가중치들의 합으로 결정하는 Soft Voting이 있다.
- 일반적으로 성능이 더욱 좋다.
Cross Validation(CV)
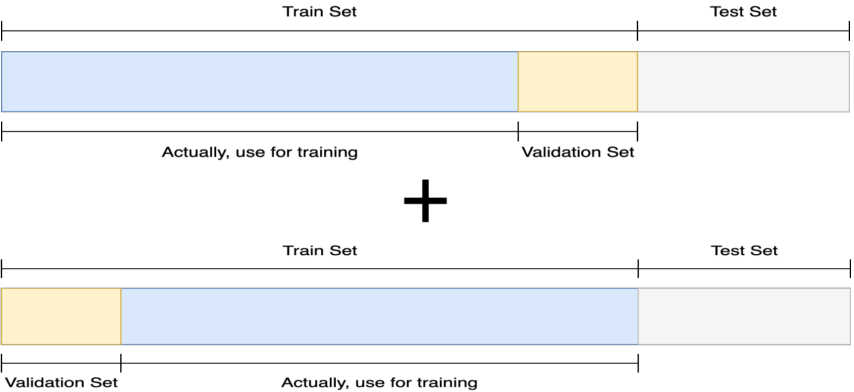
기존에 Training에 사용하지 않던 Validation set을 학습 시 마다 다른 분포를 사용하여 학습에 이용해 보는 방법
Stratified K-Fold Cross Validation
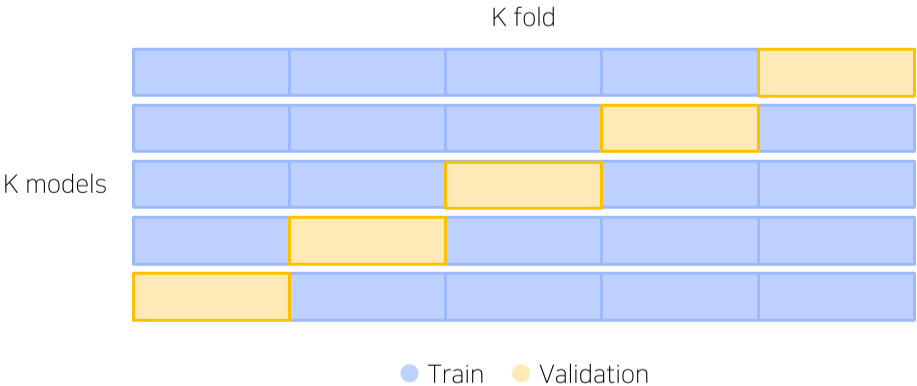
Validation이 생성될 수 있는 모든 경우의 수와 고른 Class 분포까지 고려한 CV
단, K(일반적으로 5개)개 만큼의 모델이 생성되므로, 학습시간이 그만큼 커진다.
TTA(Test Time Augmentation)
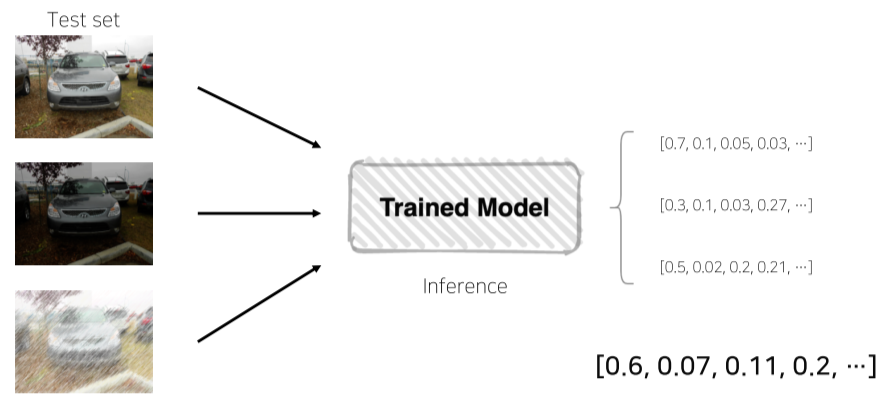
Test data set을 Augmentation 호 모델 추론, 출력된 여러가지 결과를 앙상블
Hyperparametr Optimization
시스템의 매커니즘에 영향을 주는 주요한 파라미터들을 찾아내는 것
- Learning rate, Batch size, Hidden Layer 갯수, Loss 파라미터, Dropout, k-fold, Regularization, Optimizer 파라미터 등이 있다.
사실, Ensemble 만큼이나 시간과 자원이 많이 필요하지만 성능 상승은 미비하다.
Grid search, Random search, Beysian Optimization 등의 방법이 있음
- Beysian Optimization: 이전 결과를 바탕으로 최적의 방법을 찾아가는 방법
Optuna library

파라미터 범위를 주고 그 범위 안에서 정해진 Trials 만큼 시행하도록 도와줌
Experiment Toolkits & Tips
Training Visualization
Tensorboard
기존에는 Tensorflow 용이였지만 Pytorch에도 포팅됨, 학습과정을 기록하고 트래킹 가능한 툴
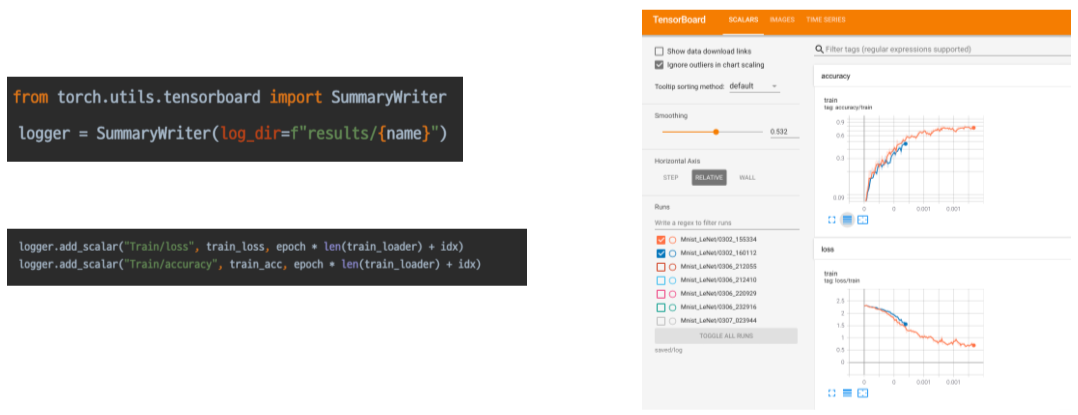
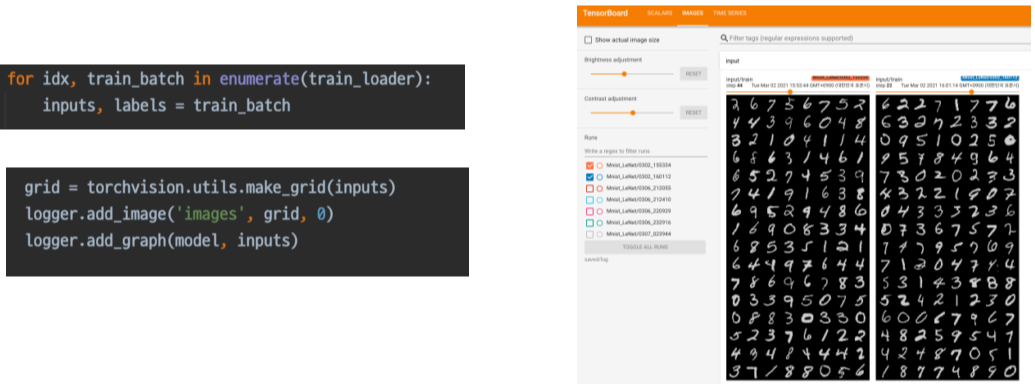
데이터 확인 등도 가능
tensorboard --logdir PATH(log가 저장된 경로) --host ADDR(default localhost) --port PORT(포트 번호)
위와 같은 번호로 사용 가능
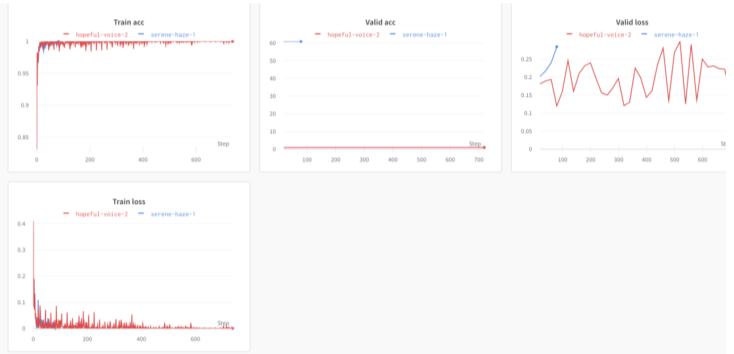
Weight and Bias(wandb)
딥러닝 로그계의 깃허브

Jupyter Notebook : Cell 마다 사용가능함, EDA시 많이 활용

Python IDLE : 디버깅 쉬움, 코드 실행이 안정적임, 자유로운 실험 핸들링
그 외의 팁
- 데이터 분석 코드 시, 코드 자체보단, 필자의 설명글을 유심히 보자

-
언제나 활용가능하도록 코드를 자세히 이해하자
-
paperwithcode.com 에서 최신 논문과 코드까지
-
자신의 지식을 자주 공유하자.
_articles/AI/CV/이미지 분류 개념.md